Типы физического соединения таблиц в Microsoft SQL Server. Описание Nested Loops, Merge и Hash Match | Info-Comp.ru
Приветствую всех посетителей сайта Info-Comp.ru! Сегодня мы с Вами поговорим о том, как происходит соединение таблиц в Microsoft SQL Server на физическом уровне, т.е. с помощью каких алгоритмов. В частности, мы рассмотрим такие типы соединения как: Nested Loops, Merge и Hash Match.
Содержание
- Введение
- Типы физического соединения таблиц
- Nested Loops Join
- Merge Join
- Hash Match Join
Введение
В языке T-SQL существуют следующие виды соединения таблиц:
INNER JOIN – внутреннее соединение
LEFT JOIN – левое внешнее соединение
RIGHT JOIN – правое внешнее соединение
FULL JOIN – полное внешнее соединение
CROSS JOIN – перекрестное соединение
На физическом уровне в Microsoft SQL Server эти соединения реализуются с помощью специальных алгоритмов:
Nested Loops
Merge Join
Hash Match
Какой из этих алгоритмов применить к тому или иному соединению, Microsoft SQL Server определяет в процессе построения плана выполнения запроса, так как в зависимости от условий каждый из этих алгоритмов может быть эффективнее остальных. Иными словами, в каких-то условиях эффективнее будет Nested Loops, а в каких-то Merge или Hash Match.
Иными словами, в каких-то условиях эффективнее будет Nested Loops, а в каких-то Merge или Hash Match.
В плане выполнения запроса соединение таблиц обозначается с помощью следующих физических операторов, т.е. если Вы видите ту или иную иконку, значит, данные были соединены с помощью соответствующего алгоритма
Иконка | Название оператора |
| Nested Loops | |
| Merge Join | |
| Hash Match |
Какие еще существуют физические операторы и как они обозначаются в плане выполнения запроса, мы рассматривали в отдельной статье.
Заметка! Описание операторов плана выполнения запроса в Microsoft SQL Server.
Ну а сейчас давайте подробно рассмотрим каждый тип физического соединения таблиц в Microsoft SQL Server.
Типы физического соединения таблиц
Некоторые могут спросить: «А зачем нам вообще знать, как работает физическое соединение таблиц в Microsoft SQL Server?».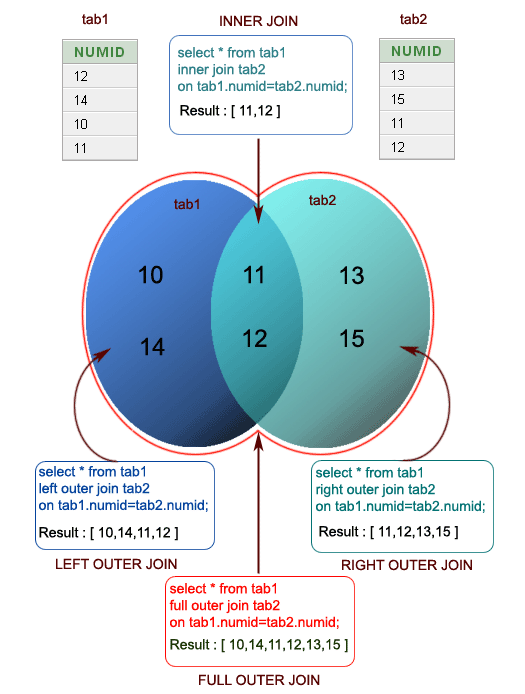 Все дело в том, что если у Вас достаточно много задач, связанных с оптимизацией, то понимание внутренних процессов, понимание того, как работает тот или иной оператор в плане выполнения запроса, поможет Вам в случае необходимости скорректировать запрос и сделать его более эффективным.
Все дело в том, что если у Вас достаточно много задач, связанных с оптимизацией, то понимание внутренних процессов, понимание того, как работает тот или иной оператор в плане выполнения запроса, поможет Вам в случае необходимости скорректировать запрос и сделать его более эффективным.
Кроме этого, на собеседованиях на позиции, которые связаны с разработкой на T-SQL, очень часто любят спрашивать, как работает физическое соединение таблиц, иными словами, если Вы идете на позицию «T-SQL разработчик», то Вас, наверное, в 95% случаях спросят про физическое соединение таблиц Nested Loops, Merge и Hash Match.
Поэтому знание и понимание того, как фактически происходит соединение данных в Microsoft SQL Server, очень полезно.
Дополнительно рекомендую почитать про архитектуру обработки запросов в Microsoft SQL Server.
Заметка! Архитектура обработки SQL запросов в Microsoft SQL Server.
Nested Loops Join
Nested Loops – это оператор вложенных циклов, который отражает тип физического соединения данных.
Принцип работы Nested Loops следующий: SQL Server для каждого значения одного набора данных ( обычно, где меньше записей), ищет соответствующее значение в другом наборе данных.
Иными словами, SQL Server берет первое значение из первой таблицы (она называется внешней) и сравнивает его последовательно со всеми значениями во второй таблице (она называется внутренней), если находит соответствие, то запись включается в итоговый набор данных. Когда значение из первого набора данных сравнилось со всеми знамениями из второго набора, то берётся второе значение первого набора и снова происходит сравнение со всеми значениями из второго набора и так происходит до тех пор, пока каждое значение из первой таблицы, т.е. внешней, не будет сравнено с каждым значением из второй таблицы, т.е. внутренней.
Таким образом, у нас два цикла, внешний и внутренний, отсюда и название – вложенные циклы.
В таком виде Nested Loops работает не очень эффективно, однако эффективность повышается, если данные внутренней таблицы отсортированы по соединяемому столбцу, например, если по нему создан индекс.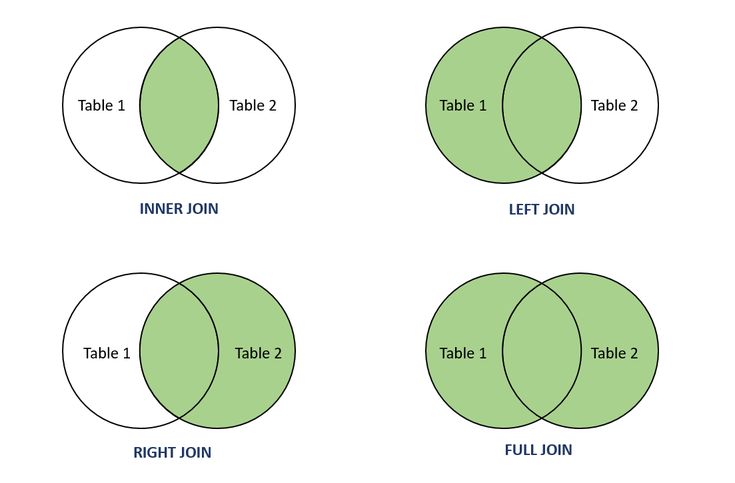
Заметка! Основы индексов в Microsoft SQL Server.
Таким образом, количество сравнений уменьшается за счет того, что значения отсортированы, а общая скорость работы повышается.
Тип физического соединения таблиц Nested Loops обычно возникает, когда мы соединяем наборы данных, где один из наборов имеет небольшой размер, а другой набор данных сравнительно большой и индексирован по соединяемым столбцам. Nested Loops встречается достаточно часто, так как является самой быстрой операцией соединения на небольшом объеме данных.
Примечание! Если два набора данных имеют достаточно большие размеры, то данный способ соединения будет крайне неэффективен.
Merge Join
Merge – соединение слиянием.
Данный тип физического соединения данных является самым быстрым, однако, он требует, чтобы оба набора данных были отсортированы, например, есть индексы по соединяемым столбцам.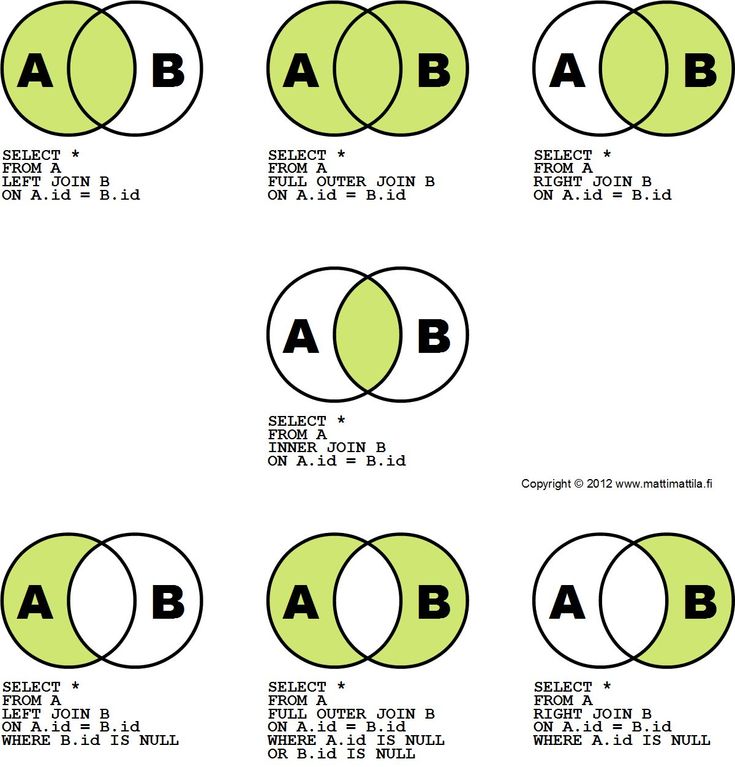
Merge наиболее эффективен в тех случаях, когда два набора данных достаточно велики, и как уже было отмечено, отсортированы по соединяемым столбцам.
Принцип работы данного типа соединения следующий: SQL Server получает первые строки из каждого набора входных данных и сравнивает их. Затем он продолжает сравнение следующих строк из второго набора, до тех пор, пока значения соответствуют значению из первого набора данных. Как только значения больше не совпадают, SQL Server переходит к следующей строке в наборе с меньшим значением и продолжает выполнять сравнения.
Например, для операций внутреннего соединения строки возвращаются в том случае, если они равны. Если они не равны, строка с меньшим значением не учитывается, и из этого набора входных данных берется следующая строка и снова происходит сравнение. Этот процесс повторяется, пока не будет выполнена обработка всех строк, т.е. пока этот, назовем его, курсор, не дойдет до конца.
Данный алгоритм эффективен, потому что SQL Server не должен возвращаться и читать какие-либо строки несколько раз, т.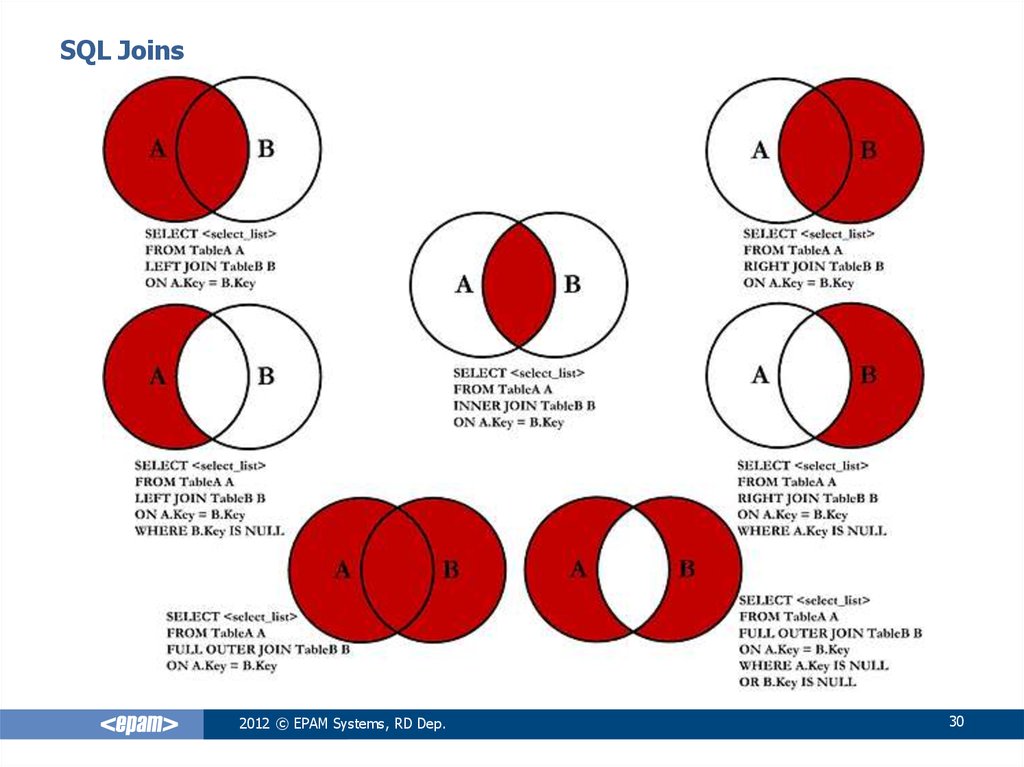 е. чтение данных происходит только один раз.
е. чтение данных происходит только один раз.
Заметка! Что нужно знать и уметь разработчику T-SQL.
Однако алгоритм становится менее эффективен, когда в наборах существуют повторяющиеся значения, т.е. когда происходит соединение слиянием «многие ко многим».
В таких случаях SQL Server записывает любые повторяющиеся значения из второй таблицы во временную таблицу в базе данных tempdb и выполняет сравнения там. Затем, если эти значения также дублируются в первой таблице, SQL Server сравнивает их со значениями, которые уже сохранены во временной таблице.
Примечание! Если оба набора данных велики и имеют сходные размеры, но не отсортированы, то соединение слиянием с предварительной сортировкой и хэш-соединение (Hash Match) имеют примерно одинаковую производительность. Однако хэш-соединения часто выполняются быстрее, если наборы данных значительно отличаются по размеру.
Hash Match Join
Hash Match – хэш-соединение.
Алгоритм соединения включает 2 фазы:
- Build
- Probe
В первой фазе «Build» строится хэш-таблица при помощи вычисления хэш-значения для каждой строки одного набора данных (обычно меньшего из двух). Эти хэши вычисляются на основе ключей соединения входных данных и затем сохраняются вместе со строкой в хеш-таблице.
После построения хэш-таблицы SQL Server начинает фазу «Probe». На этом этапе он для каждой строки другого набора данных, с помощью той же хэш-функции, вычисляет хэш-значение и осуществляет поиск совпадений по хэш-таблице. Если он находит совпадение для этого хеша, то затем он проверяет, действительно ли совпадают ключи соединения между строкой в хеш-таблице и строкой из второй таблицы (ему необходимо выполнить эту проверку из-за потенциальных хеш-коллизий
Стоит отметить, что иногда могут возникать ситуации, когда на этапе «Build» хеш-таблица не может быть сохранена полностью в памяти. В таких случаях SQL Server сохраняет некоторую часть данных в памяти, а остальную часть перенаправляет в tempdb.
В таких случаях SQL Server сохраняет некоторую часть данных в памяти, а остальную часть перенаправляет в tempdb.
Это происходит, когда объем данных превышает размер, который может храниться в памяти, или когда SQL Server предоставляет недостаточный объем памяти, необходимый для соединения Hash Match.
Способ физического соединения данных Hash Match возникает, когда мы обрабатываем большие, несортированные и неиндексированные наборы данных, при этом он делает это достаточно эффективно.
Заметка! Всем тем, кто только начинает свое знакомство с языком SQL, рекомендую прочитать книгу «SQL код
» – это самоучитель по языку SQL для начинающих программистов. В ней очень подробно рассмотрены основные конструкции языка.
На сегодня это все, надеюсь, материал был Вам полезен, пока!
Объединение таблиц при запросе (JOIN) в SQL
С помощью команды SELECT можно выбрать данные не только из одной таблицы, но и нескольких. Такая задача появляется довольно часто, потому что принято разносить данные по разным таблицам в зависимости от хранимой в них информации. К примеру, в одной таблице хранится информация о пользователях, во второй таблице о должностях компании, а в третьей и четвёртой о поставщиках и клиентах. Данные разбивают на таблицы так, чтобы с одной стороны получить самую высокую скорость выполнения запроса, а с другой стороны избежать ненужных объединений, которые снижают производительность.
Такая задача появляется довольно часто, потому что принято разносить данные по разным таблицам в зависимости от хранимой в них информации. К примеру, в одной таблице хранится информация о пользователях, во второй таблице о должностях компании, а в третьей и четвёртой о поставщиках и клиентах. Данные разбивают на таблицы так, чтобы с одной стороны получить самую высокую скорость выполнения запроса, а с другой стороны избежать ненужных объединений, которые снижают производительность.
Чем больше столбцов в таблице — тем сильнее падает скорость выборки из неё. Поэтому стараются делать в каждой таблице не больше 5-10 столбцов. Но чем сильнее данные разбиваются на разные таблицы, тем больше придётся делать объединений внутри запросов, что тоже снизит скорость получения выборки и увеличит нагрузку на базу.
Приведём пример запроса с объединением данных из двух таблиц. Для этого предположим, что существует две таблицы. Первая таблица будет иметь название USERS и будет иметь два столбца: ID и именами пользователей:
Первая таблица будет иметь название USERS и будет иметь два столбца: ID и именами пользователей:
+-----------+ | USERS | +-----------+ | ID | NAME | +----+------+ | 1 | Мышь | +----+------+ | 2 | Кот | +----+------+Вторая таблица будет называться FOOD и будет содержать два столбца: USER_ID и NAME. В этой таблице будет содержаться список любимых блюд пользователей из первой таблицы. В столбце USER_ID содержится ID пользователя, а в столбце PRODUCT находится название любимого блюда.
+-------------------+ | FOOD | +-------------------+ | USER_ID | PRODUCT | +---------+---------+ | 1 | Сыр | +---------+---------+ | 2 | Молоко | +---------+---------+
Условимся что поле ID в таблице USERS и поле USER_ID в таблице FOOD являются первичными ключами (то есть имеют уникальные значения, которые не повторяются). Теперь попробуем использовать логику и найти любимое блюдо пользователя «Мышь», используя обе таблицы. Для этого мы сначала посмотрим в первую таблицу и найдём ID пользователя под именем «Мышь», а затем найдём название продукта под таким же ID во второй таблице. Объединяющие SQL запросы работают по такой же логике: нужен столбец, в по которому таблицы могут быть объединены.
Продемонстрируем запрос, объединяющий таблицы по столбцам ID и USER_ID:
SELECT * FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID`;
Разберём команду по словам. Начинается она как обычная выборка из одной таблицы со слов «SELECT * FROM USERS». Но затем идёт слово INNER, которое означает тип объединения. Существует три типа объединения таблиц: INNER, LEFT, RIGHT. Все они связаны с тем, что некоторым строкам в одной таблице может не найтись соответствующей строки во второй таблице. В таком случае при использовании «INNER» из результатов запроса будет удалены все строки, которым не нашлась соответствующая пара в другой таблице. Если же использовать вместо «INNER» слово «LEFT» или «RIGHT», то будут удалены строки, которые не нашли совпадение из первой (левой) или второй (правой) таблицы.
После слова «INNER» стоит слово «JOIN» (которое переводится с английского как «ПРИСОЕДИНИТЬ»). После слова «JOIN» стоит название таблицы, которая будет присоединена. В нашем случае это таблица FOOD. После названия таблицы стоит слово «ON» и равенство USERS.ID=FOOD.USER_ID, которое задаёт правило присоединения. При выполнении выборки будут объединены две таблицы так, чтобы значения в столбце ID таблицы USERS равнялось значению USER_ID таблицы FOOD.
В результате выполнения этого SQL запроса мы получим таблицу с четырьмя столбцами:
+----+------+---------+---------+ | ID | NAME | USER_ID | PRODUCT | +----+------+---------+---------+ | 1 | Мышь | 1 | Сыр | +----+------+---------+---------+ | 2 | Кот | 2 | Молоко | +----+------+---------+---------+
Предлагаем модифицировать запрос, потому что нам не нужны все четыре столбца.
SELECT `USERS`.`NAME`, `FOOD`.`PRODUCT` FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID`;
Теперь результат будет компактнее. И благодаря уменьшенному количеству запрашиваемых данных, результат будет получаться из базы быстрее:
+------+---------+ | NAME | PRODUCT | +------+---------+ | Мышь | Сыр | +------+---------+ | Кот | Молоко | +------+---------+
Если в двух таблицах имеются столбцы с одинаковыми названиями, то будет показан только последний столбце с таким названием. Чтобы этого не происходило, выбирайте определённый столбцы и используйте команду «AS» с помощью которой можно переименовать столбец в результатах выборки.
Давайте теперь решим логическую задачу, которую поставили в начале статьи. Попробуем выбрать в этой объединённой таблице только одну строку, которая соответствует пользователю «Мышь». Для этого используем условие WHERE в SQL запросе:
SELECT `USERS`.`NAME`, `FOOD`.`PRODUCT` FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID` WHERE `USERS`.`NAME` LIKE 'Мышь';
Обратите внимание, что в условии WHERE название полей так же необходимо ставить вместе с названием таблицы через точку: USERS.NAME. В результате выполнения этого запроса появится такой результат:
+------+---------+ | NAME | PRODUCT | +------+---------+ | Мышь | Сыр | +------+---------+
Отлично! Теперь мы знаем, как делать объединение таблиц.
Была ли эта статья полезна? Есть вопрос?
Закажите недорогой хостинг Заказать
всего от 290 руб
типов SQL JOIN | Coursera
Если вы работаете с базами данных, в какой-то момент вам, вероятно, понадобится использовать SQL JOIN. Это руководство предлагает краткий обзор SQL JOIN и знакомит вас с некоторыми наиболее часто используемыми типами JOIN.
Определение и использование SQL JOIN
Начнем с обзора того, что такое база данных. База данных представляет собой набор различных таблиц, хранящих различные типы информации. Предложение JOIN используется при извлечении данных из связанных таблиц в базе данных. Предложение SQL JOIN является более сложным, чем простой запрос, извлекающий данные из одной таблицы, поскольку он извлекает данные из нескольких таблиц.
Типы SQL JOIN с примерами
Вы можете выбрать один из четырех типов SQL JOIN в зависимости от желаемых результатов; Внутреннее СОЕДИНЕНИЕ, левое внешнее СОЕДИНЕНИЕ, правое внешнее СОЕДИНЕНИЕ и полное внешнее СОЕДИНЕНИЕ. Посмотрите, как работает каждое из них, а также несколько примеров предложений SQL JOIN:
Inner
Inner JOIN объединяют две таблицы на основе общего ключа. Например, если у вас есть таблица со столбцом под названием «идентификатор пользователя», и каждый идентификатор пользователя уникален для пользователя, вы можете соединить эту таблицу с другой таблицей со столбцом «идентификатор пользователя», чтобы найти информацию, связанную с каждым пользователем. В этом примере показано, как использовать предложение Inner JOIN для соединения двух таблиц:
SELECT * FROM table1 INNER JOIN table2 ON table1.id = table2.id;
Left Outer
Left JOINs возвращают все строки из первой таблицы и только совпадающие строки из второй таблицы. В этом примере показано, как использовать предложение Left Outer JOIN для соединения двух таблиц:
SELECT * FROM table1 LEFT OUTER JOIN table2 ON table1.id = table2.user_id
Right Outer
Right JOIN логически противоположны Left СОЕДИНЕНИЯ — они возвращают все строки из второй таблицы и только совпадающие строки из первой таблицы. В этом примере показано, как использовать предложение Right Outer JOIN для соединения двух таблиц:
SELECT * FROM table1 RIGHT OUTER JOIN table2 ON table1.id = table2.user_id
Full Outer
Полные соединения объединяют левое и правое соединения, возвращая все строки из обеих таблиц, если существует хотя бы одна матч между ними. В этом примере показано, как использовать предложение Full Outer JOIN для соединения двух таблиц:
SELECT * FROM table1 FULL OUTER JOIN table2 ON table1.id = table2.user_id
Существует множество случаев использования SQL JOIN, и они имеет решающее значение при отображении отношений между таблицами в вашей базе данных.
Загрузка…
Введение в язык структурированных запросов (SQL)
Введение в язык структурированных запросов (SQL)
Мичиганский университет
Filled StarFilled StarFilled StarFilled StarFilled Star4,8 (4 897 оценок)
3 90 |
170 тыс. зарегистрированных студентов
Курс 2 из 4 по специализации «Веб-приложения для всех»
Зарегистрироваться бесплатно
Пример применения предложения SQL JOIN
Представьте себе таблицу, в которой хранится личная информация (имя, адрес, номер телефона), а в другой таблице хранится информация, относящаяся к должностям сотрудников. Предположим, что каждая строка в таблице сотрудников представляет одного сотрудника. В этом случае имеет смысл хранить личные данные сотрудников в другой таблице, поскольку лицо может быть представлено более одного раза (по одной строке на должность при смене ролей).
Допустим, вам нужно написать приложение, которое показывает имена и адреса сотрудников, а также их текущую должность, предыдущие должности и дату приема на работу. Чтобы получить эти данные из базы данных, вам необходимо соединить эти две таблицы вместе, используя некоторые общие для них атрибуты (например, идентификатор сотрудника).
Пример электронной коммерции с использованием SQL JOIN
Представьте, что у вас есть интернет-магазин, и вы хотите знать, какие продукты покупают ваши клиенты. У вас будет две таблицы: одна с информацией о ваших клиентах, а другая с информацией о ваших продуктах. Вы можете использовать Внутреннее СОЕДИНЕНИЕ для получения всех записей, которые появляются в обеих этих таблицах, используя следующий синтаксис:
Выбрать * из заказов клиентов Внутреннее СОЕДИНЕНИЕ на customers. id = orders.customer_id;
Пример с кодом
Рассмотрим ситуацию, когда у вас есть две таблицы базы данных, одна из которых называется «Студенты», а другая — «Оценки». Таблица «Студенты» содержит одну запись для каждого студента: его идентификационный номер, имя, специальность и так далее. Таблица «Оценки» содержит одну запись для оценки каждого учащегося по разным курсам: идентификационный номер учащегося, курс, который они прошли, и их оценку по курсу.
В SQL вы должны написать запрос для поиска имен всех учащихся, получивших оценку 100, следующим образом:
ВЫБЕРИТЕ Студенты.ИмяСтудента ИЗ Студентов.
ПРИСОЕДИНЯЙТЕСЬ к оценкам ON Student.StudentID=Grades.StudentID.
ГДЕ Оценки.Оценка=100.
Объединение JOIN
Существует множество способов объединения результатов двух или более запросов. Вот наиболее распространенные:
Используйте оператор JOIN для объединения данных из нескольких таблиц в один оператор SELECT.

Используйте подзапрос для извлечения данных из одной таблицы на основе значений из другой таблицы.
Используйте оператор UNION для объединения данных нескольких таблиц (или запросов).
Оператор JOIN может использоваться с оператором любого другого типа, который поддерживает SQL, включая UPDATE и DELETE.
Советы по более подробному изучению SQL JOIN
Если вы хотите работать над SQL-проектами или получить работу с использованием SQL, вам, возможно, потребуется приобрести свои знания и навыки. Убедитесь, что вы учитесь из надежных материалов. Убедитесь, что тренер или инструктор обладает расширенными знаниями в области SQL. Читайте обзоры и анализируйте курсовую работу или структуру обучения.
Учебные пособия
В Интернете доступно множество учебных пособий, которые помогут вам изучить SQL. Эти учебные пособия часто бесплатны и предоставляются компетентными людьми в своей области. Обучение с помощью учебных пособий требует некоторого планирования. Если вы выберете этот путь, убедитесь, что вы следуете логической структуре обучения, чтобы изучить все основные строительные блоки для работы с SQL. Например, вам потребуется хорошее понимание баз данных.
Онлайн-курсы
Существует множество онлайн-курсов, с помощью которых можно изучать SQL. Некоторые из этих курсов бесплатны, а некоторые взимают плату. Некоторые из платных курсов являются комплексными и предлагают соотношение цены и качества. Курсы предоставляют вам структурированный процесс обучения и могут стать отличным способом накопления знаний.
Сертификаты
Существует множество сертификатов SQL на ваш выбор. Сертификаты позволяют продемонстрировать работодателям, что вы сдали экзамен, проверяющий ваши знания SQL, и могут быть особенно полезны, если ваше резюме не содержит большого опыта работы с SQL.
Следующие шаги
Если вы хотите больше узнать о SQL, подумайте о том, чтобы пройти один из курсов на Coursera. Курс «Введение в язык структурированных запросов» (SQL), предлагаемый Мичиганским университетом, — хорошее место для начала вашего пути. Пройдя этот курс, вы сможете шаг за шагом научиться создавать базу данных MySQL и больше узнать о языке SQL.
Статьи по теме
10 ИТ-вакансий начального уровня и что вы можете сделать, чтобы получить работу
Нужна ли мне степень в области информационных технологий? 4 вещи, которые следует учитывать
7 востребованных ИТ-навыков, которые помогут улучшить ваше резюме в 2022 году
Что вы можете сделать со степенью в области компьютерных наук?
Автор Coursera • Обновлено
Этот контент был доступен только в информационных целях. Учащимся рекомендуется провести дополнительные исследования, чтобы убедиться, что курсы и другие полномочия соответствуют их личным, профессиональным и финансовым целям.
Типы соединений SQL
- Краткий обзор типов соединений SQL
- Объяснение проблемы с соединениями SQL
- Внешние типы соединений SQL для спасения
- Как насчет правильного внешнего соединения SQL и полного внешнего соединения?
- Какой тип соединения SQL использовать?
- Общие проблемы с соединениями SQL
- Выполнение внутреннего соединения SQL вместо внешнего соединения
- Использование соединений SQL для «совпадений», которые не имеют смысла
- Путание значений NULL в данных с значениями NULL из-за несоответствия
В этой статье рассматриваются различные типы соединений SQL. Если вы новичок в этом вопросе, вы также можете ознакомиться со статьей о соединениях SQL. Обратите внимание, что соединения работают только с реляционными базами данных.
Краткий обзор типов соединений SQL
Соединение SQL указывает базе данных объединить столбцы из разных таблиц. Обычно мы соединяем таблицы, сопоставляя внешние ключи в одной таблице с первичными ключами в другой. Например, каждая запись в 9Таблица 0195 products имеет уникальный идентификатор в поле products.id : это первичный ключ. Чтобы соответствовать ключу, каждая запись в заказах имеет идентификатор продукта в поле orders.product_id : это внешний ключ. Если мы хотим объединить информацию о заказе с информацией о заказанном продукте, мы можем сделать внутреннее соединение:
ВЫБЕРИТЕ Orders.total как итог, products.title как заголовок ОТ заказывает продукцию INNER JOIN НА заказы.product_id = продукты.id
Очень важно, чтобы в соединении мы использовали Orders., а не product_id Orders.id : оба поля — просто числа, поэтому некоторые идентификаторы заказов будут соответствовать некоторым идентификаторам продуктов, но эти совпадения будут бессмысленными.
Объяснение проблемы с соединениями SQL
Даже если мы используем правильные поля, здесь есть ловушка для неосторожных. Легко проверить, что каждая запись в Orders содержит идентификатор продукта — количество нулевых значений в 9019.5 Orders.product_id возвращает 0:
ВЫБЕРИТЕ считать(*) ОТ заказы КУДА заказы.product_id IS NULL
| количество (*) | | -------- | | 0 |
Но что, если вещи не всегда совпадают с ? Например, предположим, что мы пытаемся выяснить, какие продукты не имеют отзывов. Если мы посмотрим на таблицу отзывов , в ней 1112 записей:
ВЫБЕРИТЕ считать(*) ОТ обзоры
| количество (*) | | -------- | | 1112 |
Каждый отзыв относится к продукту:
ВЫБЕРИТЕ считать(*) ОТ обзоры КУДА обзоры.
| количество (*) | | -------- | | 0 |
Но каждый ли товар имеет отзывы? Чтобы узнать, посчитаем количество товаров:
ВЫБЕРИТЕ считать(*) ОТ продукты
| количество (*) | | -------- | | 200 |
Затем мы можем объединить таблицы продуктов и обзоров и подсчитать количество различных продуктов в результате. (В реальной жизни мы, вероятно, использовали бы SELECT COUNT(DISTINCT product_id) FROM Reviews , чтобы получить этот номер, но использование INNER JOIN помогает нам проиллюстрировать идею.)
ВЫБЕРИТЕ count(различные продукты.id) ОТ продукты INNER JOIN отзывы НА products.id = отзывы.product_id
| количество (*) | | -------- | | 176 |
Только 176 из 200 товаров имеют отзывы. В результате, если мы подсчитаем количество обзоров для каждого продукта, мы получим количество отзывов только там, где были некоторые обзоры — наш запрос ничего не скажет нам о продуктах, у которых нет отзывов, потому что внутреннее соединение не найдет ни одного. соответствие при объединении таблиц. Этот запрос демонстрирует проблему:
ВЫБЕРИТЕ products.title как заголовок, count(*) как number_of_reviews ОТ продукты INNER JOIN отзывы НА products.id = отзывы.product_id ГРУППА ПО продукты.id СОРТИРОВАТЬ ПО число_от_отзывов ASC
| продукты.название | количество_отзывов | | ------------------------- | ----------------- | | Деревенская медная шляпа | 1 | | Невероятные бетонные часы | 1 | | Практичное алюминиевое покрытие | 1 | | Потрясающий алюминиевый стол | 1 | | ... | ... |
Мы упорядочили результат в порядке возрастания количества; как это показывает, наименьшее количество равно 1, когда оно должно быть 0,
Внешние типы соединения SQL для спасения
Хорошо: мы знаем, сколько товаров не имеют отзывов, но какие именно? Один из способов ответить на этот вопрос — использовать тип соединения SQL, известный как левое внешнее соединение, также называемое «левым соединением». Этот тип объединения всегда возвращает хотя бы одну запись из первой упомянутой нами таблицы (т. е. той, что слева). Чтобы увидеть, как это работает, представьте, что у нас есть две маленькие таблицы с именами 9.0195 краска и ткань . Таблица краска содержит три строки:
| бренд | цвет | | --------- | ----- | | Премьера | красный | | Премьера | синий | | Специальный | синий |
, в то время как таблица Fabric содержит всего две строки:
| вид | оттенок | | ------ | ----- | | нейлон | зеленый | | хлопок | синий |
Если мы сделаем внутреннее соединение этих двух таблиц, сопоставив paint.color с fabric.shade , только синих записей совпадают:
ВЫБЕРИТЕ * ОТ краска INNER JOIN ткань НА краска.цвет = ткань.оттенок
| краска.бренд | краска.цвет | ткань.вид | ткань.оттенок | | ----------- | ----------- | ----------- | ------------ | | Премьера | синий | хлопок | синий | | Специальный | синий | хлопок | синий |
В таблице ткань нет ничего красного, поэтому первая запись из краска не включается в результат. Точно так же ничего из краска зеленого цвета, поэтому нейлоновый материал из ткани также выбрасывается.
Однако, если мы выполним левое внешнее соединение, база данных сохранит каждую запись из левой таблицы, в которой нет соответствия. Поскольку в правой таблице нет совпадающих значений, SQL заполняет эти столбцы NULL :
ВЫБЕРИТЕ * ОТ краска LEFT JOIN ткань НА краска.цвет = ткань.оттенок
| краска.бренд | краска.цвет | ткань.вид | ткань.оттенок | | ----------- | ----------- | ----------- | ------------ | | Премьера | красный | НУЛЕВОЙ | НУЛЕВОЙ | | Премьера | синий | хлопок | синий | | Специальный | синий | хлопок | синий |
Сохранение всех записей из левой таблицы оказывается полезным в самых разных ситуациях. Например, если мы хотим увидеть, для каких красок не подходят ткани, мы можем выполнить левое внешнее соединение SQL:
.ВЫБЕРИТЕ * ОТ краска LEFT OUTER JOIN ткань НА краска.
| краска.бренд | краска.цвет | ткань.вид | ткань.оттенок | | ------------ | ----------- | ------------ | ------------ | | Премьера | красный | НУЛЕВОЙ | НУЛЕВОЙ | | Премьера | синий | хлопок | синий | | Специальный | синий | хлопок | синий |
Это легче читать, если мы выберем только строки, в которых значения из правой таблицы равны NULL :
ВЫБЕРИТЕ * ОТ краска LEFT OUTER JOIN ткань НА краска.цвет = ткань.оттенок КУДА ткань.оттенок имеет значение NULL
| краска.бренд | краска.цвет | ткань.вид | ткань.оттенок | | ------------ | ----------- | ------------ | ------------ | | Премьера | красный | НУЛЕВОЙ | НУЛЕВОЙ |
Мы можем использовать эту технику, чтобы получить список продуктов, у которых нет обзоров, выполнив левое внешнее соединение и сохранив только строки, где отзывов. product_id был заполнен NULL :
ВЫБЕРИТЕ продукты.название ОТ продукты LEFT OUTER JOIN отзывы НА products.
| продукты.название | | ----------------------- | | Маленькая мраморная обувь | | Эргономичное шелковое пальто | | Синергетический стальной стул | | ... |
Как насчет правильного внешнего соединения SQL и полного внешнего соединения?
Стандарт SQL определяет два других типа соединений SQL для внешнего соединения, но они используются гораздо реже — настолько реже, что некоторые базы данных их даже не реализуют. Правое внешнее соединение работает точно так же, как левое внешнее соединение, за исключением того, что оно всегда сохраняет строки из правой таблицы и заполняет столбцы из левой таблицы NULL , если совпадений нет. Довольно легко увидеть, что вы всегда можете использовать левое внешнее соединение вместо правого, поменяв местами таблицы; нет особой причины отдавать предпочтение одному перед другим, но почти все используют форму для левшей, поэтому мы предлагаем вам сделать то же самое.
Полное внешнее соединение сохраняет всю информацию из обеих таблиц. Если запись слева не совпадает с записью справа, база данных заполнит отсутствующие правые значения NULL , и если в записи справа отсутствует совпадение слева, она заполняет отсутствующие левые значения. Например, если мы сделаем полный внешний шов на красках и ткани , мы получим:
| краска.бренд | краска.цвет | ткань.вид | ткань.оттенок | | ------------ | ----------- | ------------ | ------------ | | Премьера | красный | НУЛЕВОЙ | НУЛЕВОЙ | | Премьера | синий | хлопок | синий | | НУЛЕВОЙ | НУЛЕВОЙ | нейлон | зеленый | | Специальный | синий | хлопок | синий |
Полные внешние соединения иногда полезны для поиска перекрытия между двумя таблицами, но за двадцать лет написания SQL я использовал их только на уроках, подобных этому.
Какой тип соединения SQL использовать?
Для обзора существует четыре основных типа соединений. Внутренние соединения сохраняют только совпадающие записи, а остальные три типа заполняют отсутствующие значения NULL , как показано на рис. 1. Некоторые считают левую таблицу главной или исходной таблицей; тип используемого вами соединения будет определять, сколько записей из этой исходной таблицы вы вернете, а также какие дополнительные записи вы вернете на основе столбцов, которые вы хотите получить из другой таблицы. Мы уже видели исключения из этого здесь (например, для каждого продукта было несколько обзоров), но это хороший признак того, что у вас есть хорошая основная таблица для начала.
В общем, вам действительно нужно использовать только внутренние соединения и левые внешние соединения. Какой тип объединения вы используете, зависит от того, хотите ли вы включить в результаты несовпадающие строки:
- Если вам нужны несопоставленные строки в основной таблице, используйте левое внешнее соединение.
- Если вам не нужны несовпадающие строки, используйте внутреннее соединение.
Еще один взгляд на соединения, которые абстрагируются от SQL, ознакомьтесь с нашей статьей о соединениях с использованием построителя запросов Metabase.
Общие проблемы с соединениями SQL
Выполнение внутреннего соединения SQL вместо внешнего соединения
Вероятно, это самая распространенная ошибка. Реальные данные часто имеют пробелы, и внутренние соединения будут отбрасывать записи без предупреждения, когда ключи не совпадают. Подсчет количества строк из одной таблицы, которые не совпадают с в другой, является хорошей проверкой безопасности; если они есть, вам следует подумать об использовании внешнего соединения вместо внутреннего.
Использование соединений SQL для «совпадений», которые не имеют смысла
Вес человека в килограммах и стоимость его последней покупки в долларах являются числами, поэтому можно выполнить соединение, сопоставив их, но результат (вероятно) будет бессмысленным. Менее легкомысленный пример возникает, когда одна таблица содержит несколько внешних ключей, которые ссылаются на разные таблицы, что может привести к объединению данных пациентов с регистрационными номерами транспортных средств вместо дат приема.