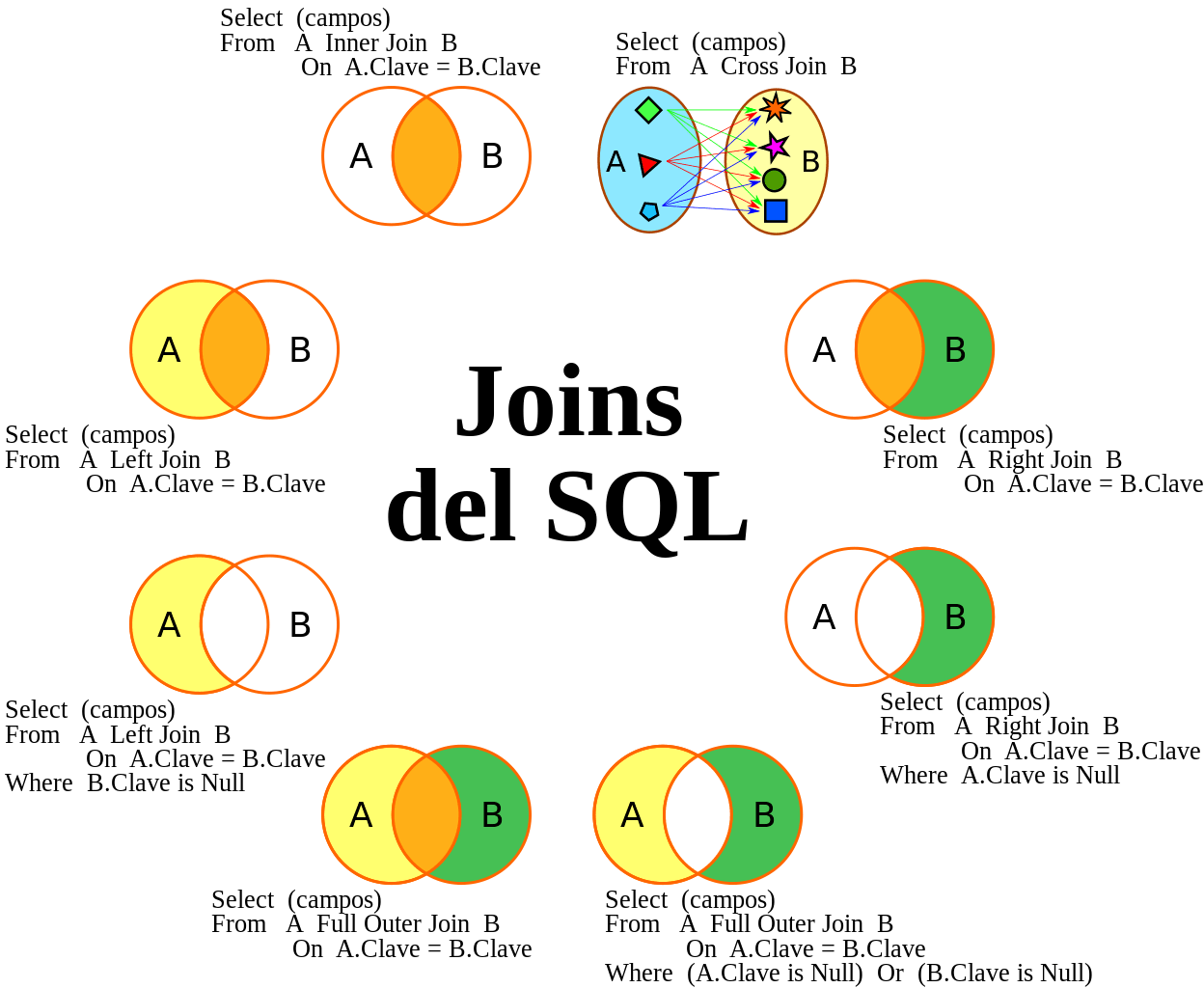
Использование оператора INNER JOIN
Об объекте
Учебные материалы
Правила описания синтаксиса команд SQL
Выборка данных
Сортировка выбранных данных
Фильтрация данных (предложение WHERE)
Создание вычисляемых полей
Агрегирующие функции
Итоговые данные (предложение GROUP BY)
Объединение таблиц
Внутреннее объединение
Использование предложения WHERE
Использование оператора INNER JOIN
Внешние объединения
Подзапросы
Комбинированные запросы
Вопросы для самопроверки
Практические задания
Список литературы
Приложение
Использование оператора INNER JOIN
Синтаксис оператора SELECT для выполнения операции внутреннего объединения имеет вид:
SELECT [DISTINCT]
[<table1>.
FROM <table1> [INNER] JOIN <table2> [таблица_1.]
ON <column_name><join_condition>…][таблица_2.]<column_name>
Оператор SELECT здесь точно такой же, как и при использовании предложения WHERE, но предложение FROM другое. Здесь отношение между двумя таблицами является частью предложения FROM, указанного как INNER JOIN. При использовании такого синтаксиса предложение объединения указывается с использованием специального предложения ON вместо предложения WHERE. Фактическое предложение, передаваемое в ON, то же самое, которое передавалось бы в предложение WHERE*.
Ниже представлены запросы из предыдущего раздела, написанные с применением INNER JOIN.
Примеры
Получить список клиентов из Сиэтла, с указанием номеров действующих договоров.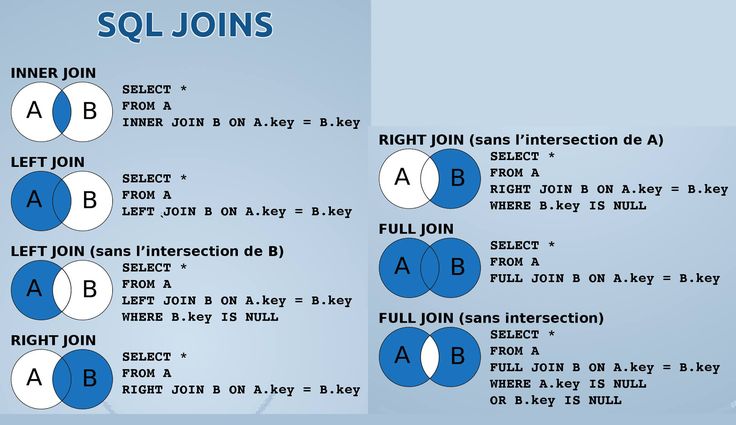
SQL:
SELECT contract_id, lastname, name
FROM tbl_clients
JOIN tbl_contract ON tbl_clients.client_id = tbl_contract.client_id
WHERE
retire_date IS NULL AND region=’Seattle’
Подсчитать количество договоров, заключенных на пользование каждой из предлагаемых услуг. Полученный список отсортировать по названию услуги.
SQL:
SELECT service, СOUNT(contract_id)
ROM tbl_service
INNER JOIN tbl_contract ON tbl_service.service_id =
tbl_contract.service_id
WHERE retire_date IS NULL
GROUP
BY service
Получить список клиентов и услуг, с указанием номеров договоров. Список отсортировать по фамилиям клиентов.
SQL:
SELECT lastname, name, contract_id, service
FROM tbl_service
INNER
JOIN tbl_contract ON tbl_service.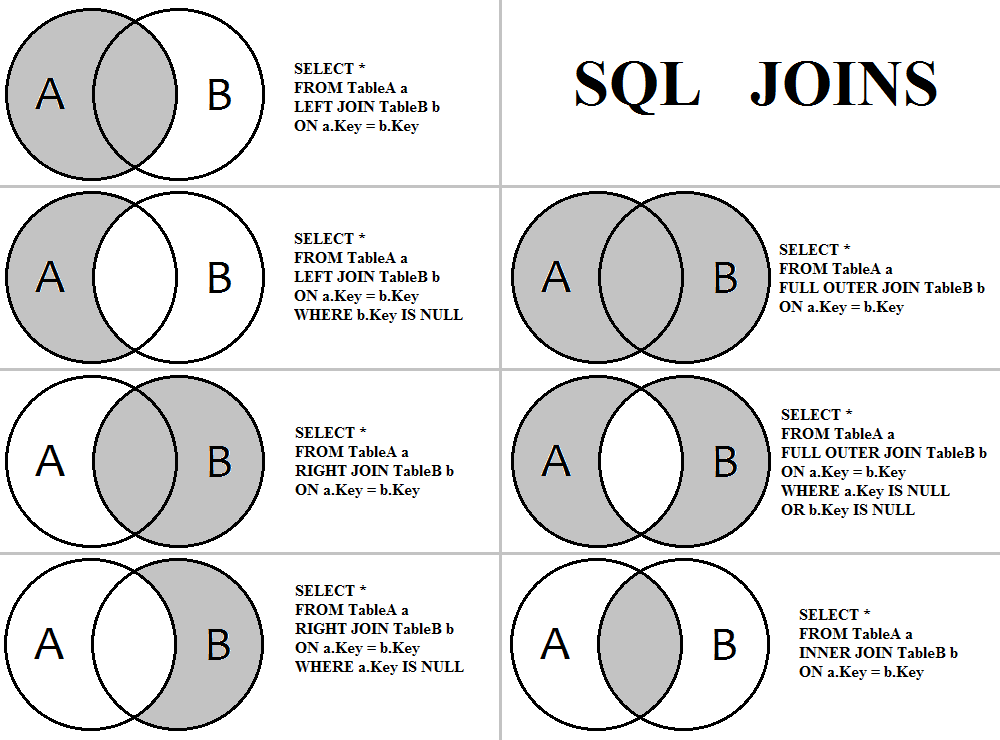 service_id = tbl_contract.service_id
service_id = tbl_contract.service_id
INNER JOIN
tbl_clients ON tbl_contract.client_id=tbl_clients.client_id
WHERE retire_date IS NULL ORDER BY lastname
Вычислить сумму, которую должен платить каждый клиент за пользование услугами.
SQL:
SELECT lastname, name, SUM(price)
FROM tbl_service
INNER JOIN tbl_contract ON tbl_service.service_id =
tbl_contract.service_id
WHERE retire_date IS NULL
GROUP BY lastname ORDER BY lastname
* — Согласно спецификации ANSI, для создания объединений предпочтительнее использовать синтаксис INNER JOIN
« Previous | Next »
Объединение таблиц при запросе (JOIN) в SQL
С помощью команды SELECT можно выбрать данные не только из одной таблицы, но и нескольких. Такая задача появляется довольно часто, потому что принято разносить данные по разным таблицам в зависимости от хранимой в них информации. К примеру, в одной таблице хранится информация о пользователях, во второй таблице о должностях компании, а в третьей и четвёртой о поставщиках и клиентах. Данные разбивают на таблицы так, чтобы с одной стороны получить самую высокую скорость выполнения запроса, а с другой стороны избежать ненужных объединений, которые снижают производительность.
Такая задача появляется довольно часто, потому что принято разносить данные по разным таблицам в зависимости от хранимой в них информации. К примеру, в одной таблице хранится информация о пользователях, во второй таблице о должностях компании, а в третьей и четвёртой о поставщиках и клиентах. Данные разбивают на таблицы так, чтобы с одной стороны получить самую высокую скорость выполнения запроса, а с другой стороны избежать ненужных объединений, которые снижают производительность.
Чем больше столбцов в таблице — тем сильнее падает скорость выборки из неё. Поэтому стараются делать в каждой таблице не больше 5-10 столбцов. Но чем сильнее данные разбиваются на разные таблицы, тем больше придётся делать объединений внутри запросов, что тоже снизит скорость получения выборки и увеличит нагрузку на базу.
Приведём пример запроса с объединением данных из двух таблиц. Для этого предположим, что существует две таблицы.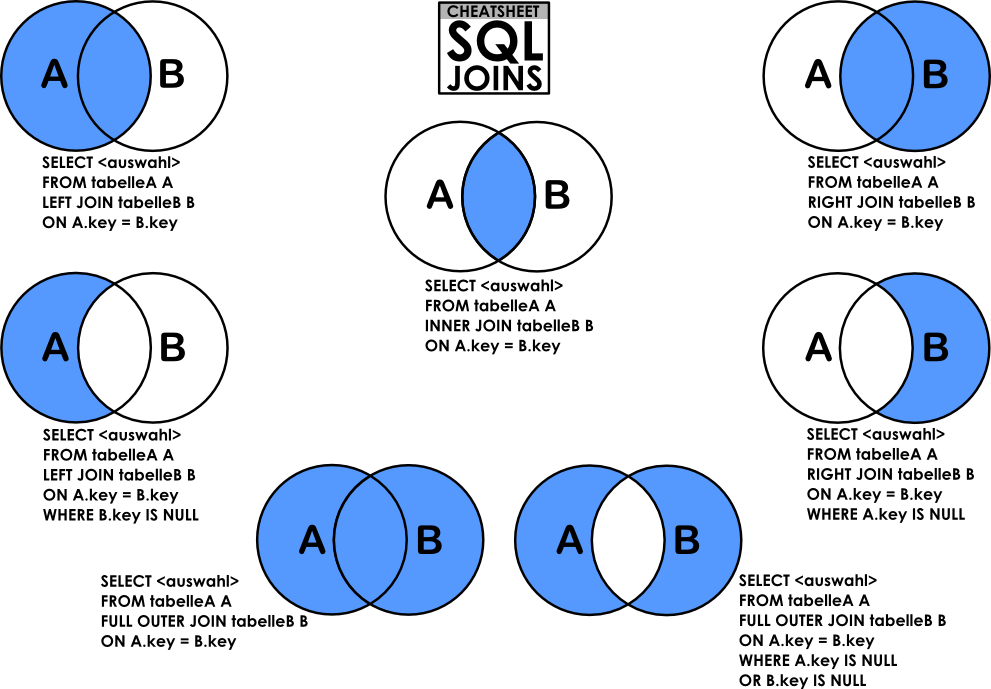 Первая таблица будет иметь название USERS и будет иметь два столбца: ID и именами пользователей:
Первая таблица будет иметь название USERS и будет иметь два столбца: ID и именами пользователей:
+-----------+ | USERS | +-----------+ | ID | NAME | +----+------+ | 1 | Мышь | +----+------+ | 2 | Кот | +----+------+
Вторая таблица будет называться FOOD и будет содержать два столбца: USER_ID и NAME. В этой таблице будет содержаться список любимых блюд пользователей из первой таблицы. В столбце USER_ID содержится ID пользователя, а в столбце PRODUCT находится название любимого блюда.
+-------------------+ | FOOD | +-------------------+ | USER_ID | PRODUCT | +---------+---------+ | 1 | Сыр | +---------+---------+ | 2 | Молоко | +---------+---------+
Условимся что поле ID в таблице USERS и поле USER_ID в таблице FOOD являются первичными ключами (то есть имеют уникальные значения, которые не повторяются).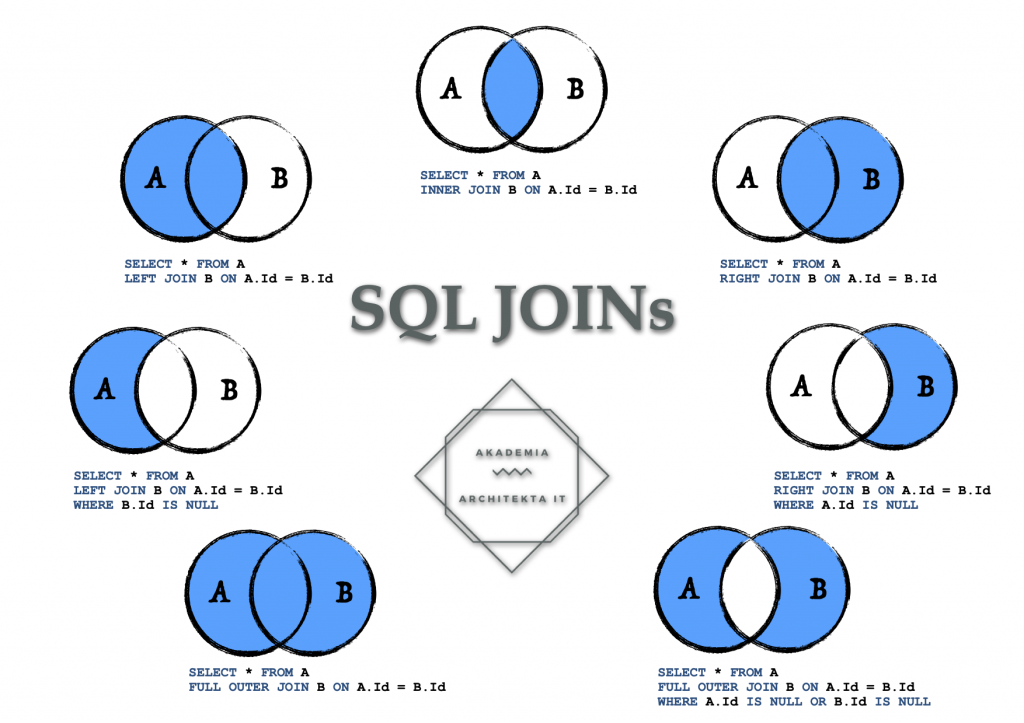 Теперь попробуем использовать логику и найти любимое блюдо пользователя «Мышь», используя обе таблицы. Для этого мы сначала посмотрим в первую таблицу и найдём ID пользователя под именем «Мышь», а затем найдём название продукта под таким же ID во второй таблице. Объединяющие SQL запросы работают по такой же логике: нужен столбец, в по которому таблицы могут быть объединены.
Теперь попробуем использовать логику и найти любимое блюдо пользователя «Мышь», используя обе таблицы. Для этого мы сначала посмотрим в первую таблицу и найдём ID пользователя под именем «Мышь», а затем найдём название продукта под таким же ID во второй таблице. Объединяющие SQL запросы работают по такой же логике: нужен столбец, в по которому таблицы могут быть объединены.
Продемонстрируем запрос, объединяющий таблицы по столбцам ID и USER_ID:
SELECT * FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID`;
Разберём команду по словам. Начинается она как обычная выборка из одной таблицы со слов «SELECT * FROM USERS». Но затем идёт слово INNER, которое означает тип объединения. Существует три типа объединения таблиц: INNER, LEFT, RIGHT. Все они связаны с тем, что некоторым строкам в одной таблице может не найтись соответствующей строки во второй таблице. В таком случае при использовании «INNER» из результатов запроса будет удалены все строки, которым не нашлась соответствующая пара в другой таблице.
После слова «INNER» стоит слово «JOIN» (которое переводится с английского как «ПРИСОЕДИНИТЬ»). После слова «JOIN» стоит название таблицы, которая будет присоединена. В нашем случае это таблица FOOD. После названия таблицы стоит слово «ON» и равенство USERS.ID=FOOD.USER_ID, которое задаёт правило присоединения. При выполнении выборки будут объединены две таблицы так, чтобы значения в столбце ID таблицы USERS равнялось значению USER_ID таблицы FOOD.
В результате выполнения этого SQL запроса мы получим таблицу с четырьмя столбцами:
+----+------+---------+---------+ | ID | NAME | USER_ID | PRODUCT | +----+------+---------+---------+ | 1 | Мышь | 1 | Сыр | +----+------+---------+---------+ | 2 | Кот | 2 | Молоко | +----+------+---------+---------+
Предлагаем модифицировать запрос, потому что нам не нужны все четыре столбца.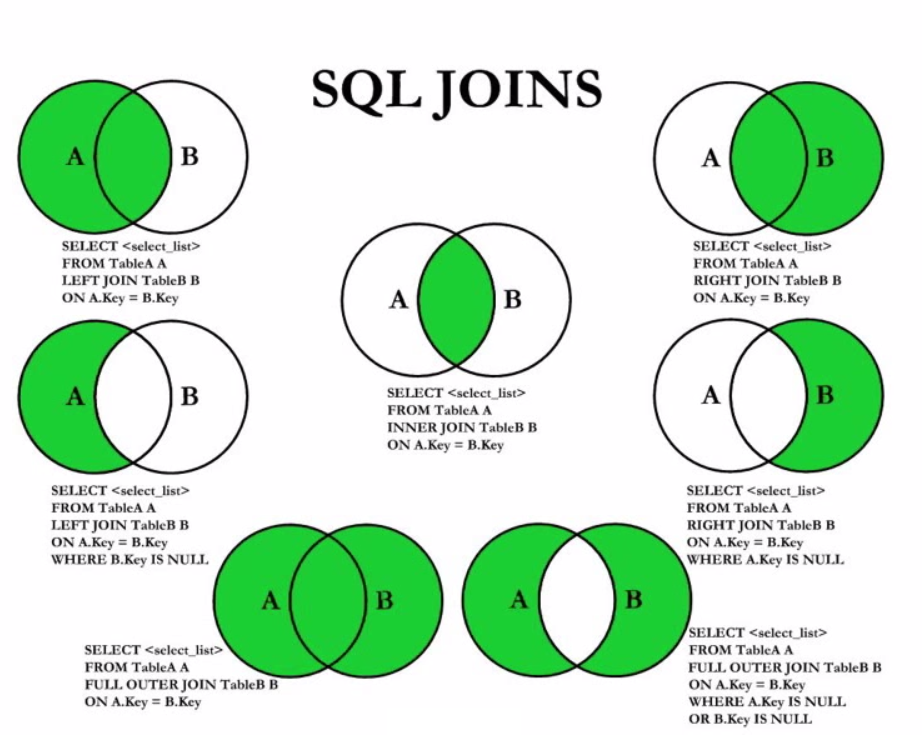 Уберём столбцы ID и USER_ID. Для этого вместо * в команде SELECT поставим название столбцов. Но необходимо сделать это, ставя сначала название таблицы и через точку название столбца. Чтобы получилось так:
Уберём столбцы ID и USER_ID. Для этого вместо * в команде SELECT поставим название столбцов. Но необходимо сделать это, ставя сначала название таблицы и через точку название столбца. Чтобы получилось так:
SELECT `USERS`.`NAME`, `FOOD`.`PRODUCT` FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID`;
Теперь результат будет компактнее. И благодаря уменьшенному количеству запрашиваемых данных, результат будет получаться из базы быстрее:
+------+---------+ | NAME | PRODUCT | +------+---------+ | Мышь | Сыр | +------+---------+ | Кот | Молоко | +------+---------+
Если в двух таблицах имеются столбцы с одинаковыми названиями, то будет показан только последний столбце с таким названием. Чтобы этого не происходило, выбирайте определённый столбцы и используйте команду «AS» с помощью которой можно переименовать столбец в результатах выборки.
Давайте теперь решим логическую задачу, которую поставили в начале статьи. Попробуем выбрать в этой объединённой таблице только одну строку, которая соответствует пользователю «Мышь». Для этого используем условие WHERE в SQL запросе:
SELECT `USERS`.`NAME`, `FOOD`.`PRODUCT` FROM `USERS` INNER JOIN `FOOD` ON `USERS`.`ID`=`FOOD`.`USER_ID` WHERE `USERS`.`NAME` LIKE 'Мышь';
Обратите внимание, что в условии WHERE название полей так же необходимо ставить вместе с названием таблицы через точку: USERS.NAME. В результате выполнения этого запроса появится такой результат:
+------+---------+ | NAME | PRODUCT | +------+---------+ | Мышь | Сыр | +------+---------+
Отлично! Теперь мы знаем, как делать объединение таблиц.
Была ли эта статья полезна? Есть вопрос?
Закажите недорогой хостинг Заказать
всего от 290 руб
SQL ВНУТРЕННЕЕ СОЕДИНЕНИЕ Запрос
Запрос INNER JOIN используется для извлечения совпадающих записей из двух или более таблиц на основе заданного условия.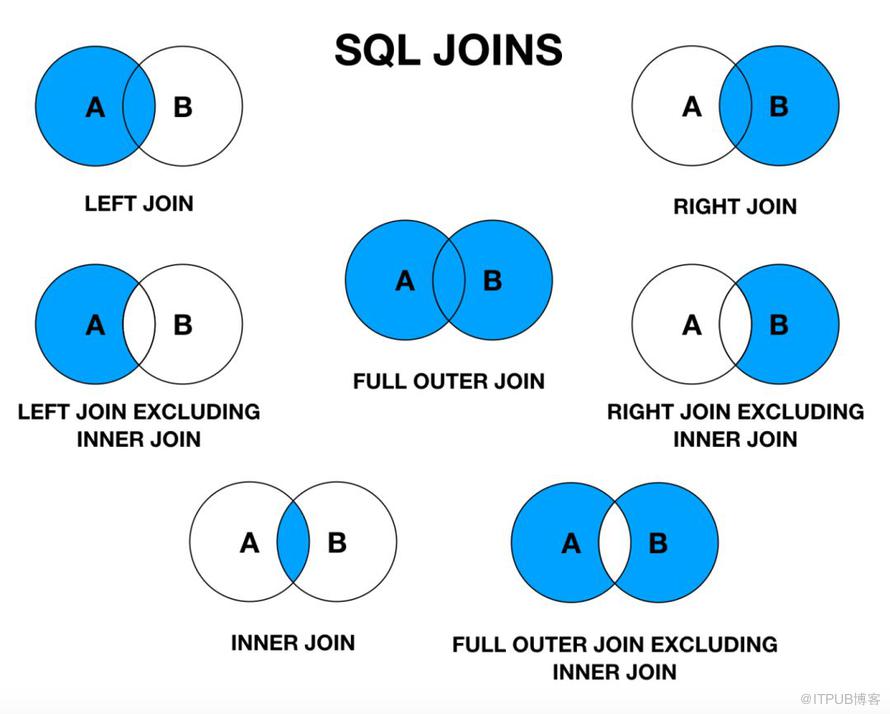
Синтаксис:
ВЫБРАТЬ table1.column_name(s), table2.column_name(s) ИЗ таблицы1 ВНУТРЕННЕЕ СОЕДИНЕНИЕ таблица2 ON table1.column_name = table2.column_name;
Для демонстрационных целей мы будем использовать следующие Сотрудник и .Таблицы отдела во всех примерах.
Таблица сотрудников
| Эмпид | Имя | Фамилия | Электронная почта | Зарплата | ИД отдела |
|---|---|---|---|---|---|
| 1 | ‘Джон’ | ‘Король’ | ‘[электронная почта защищена]’ | 33000 | 1 |
| 2 | ‘Джеймс’ | ‘Бонд’ | |||
| 3 | ‘Нина’ | ‘Кочхар’ | ‘[электронная почта защищена]’ | 17000 | 2 |
| 4 | ‘Лекс’ | ‘Де Хаан’ | ‘[электронная почта защищена]’ | 15000 | 1 |
| 5 | ‘Амит’ | ‘Патель’ | 18000 | 3 | |
| 6 | ‘Абдул’ | ‘Калам’ | ‘[электронная почта защищена]’ | 25000 | 2 |
Таблица отдела
| ИД отдела | Имя |
|---|---|
| 1 | ‘Финансы’ |
| 2 | «HR» |
Рассмотрим следующий запрос внутреннего соединения.
SELECT Сотрудник.EmpId, Сотрудник.Имя, Сотрудник.Фамилия, Отдел.Имя ОТ Сотрудника ВНУТРЕННЕЕ СОЕДИНЕНИЕ ON Сотрудник.ОтделId = Отдел.ОтделId;
Приведенный выше запрос внутреннего соединения объединяет таблицу Employee и таблицу Department и извлекает записи из обеих таблиц, где Employee.DeptId = Department.DeptId .
Он извлекает записи только из обеих таблиц, где DeptId в таблице Сотрудник соответствует DeptId таблицы Отдел .
Если DeptId имеет значение NULL или не соответствует, то эти записи не будут получены. Ниже приведен результат вышеуказанного запроса.
Таблица сотрудников
| Эмпид | Имя | Фамилия | Имя |
|---|---|---|---|
| 1 | ‘Джон’ | ‘Король’ | ‘Финансы’ |
| 3 | ‘Нина’ | ‘Кочхар’ | «HR» |
| 4 | ‘Лекс’ | ‘Де Хаан’ | ‘Финансы’ |
| 6 | ‘Абдул’ | ‘Калам’ | «HR» |
Обратите внимание, что отображаются только те записи, чей DeptId соответствует, а не те, DeptId которых является нулевым или не соответствует.
Неважно, какую таблицу вы возьмете первой в запросе. Следующий запрос отобразит тот же результат, что и выше.
SELECT Сотрудник.EmpId, Сотрудник.Имя, Сотрудник.Фамилия, Отдел.Имя ОТ Департамента ВНУТРЕННЕЕ СОЕДИНЕНИЕ Сотрудник ON Department.DeptId = Employee.DeptId;
Использование фразы INNER JOIN не обязательно. Вы можете использовать предложение WHERE для достижения того же результата, как показано ниже.
SELECT emp.EmpId, emp.FirstName, emp.LastName, dept.Name ОТ Отдела отдела, Сотрудник emp ГДЕ dept.DeptId = emp.DeptId;
Псевдонимы можно использовать как сокращения имен таблиц, как показано ниже.
SELECT emp.EmpId, emp.FirstName, emp.LastName, dept.Name ОТ Отдела отдела ВНУТРЕННЕЕ СОЕДИНЕНИЕ Сотрудник ON dept.DeptId = emp.DeptId;
Повторите оператор INNER JOIN.. ON , чтобы включить в запрос еще одну таблицу. Например, следующий запрос внутреннего соединения объединяет три таблицы.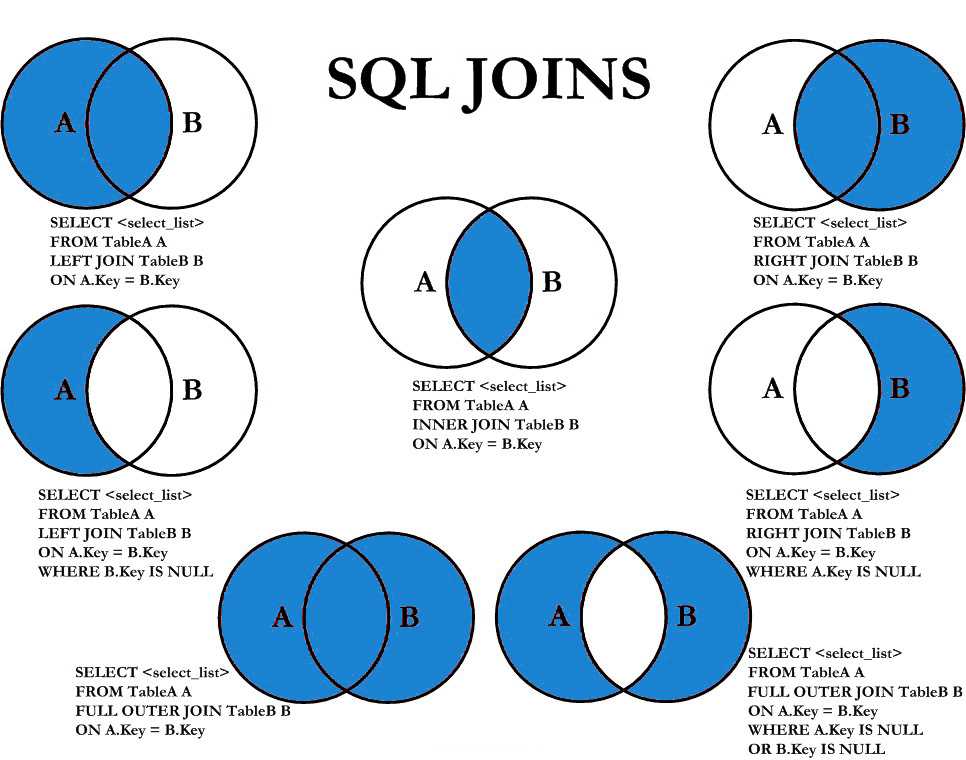
SELECT Сотрудник.EmpId, Сотрудник.Имя, Сотрудник.Фамилия, Консультант.Имя, Отдел.Имя ОТ Сотрудника ВНУТРЕННЕЕ СОЕДИНЕНИЕ ON Сотрудник.DeptId = Отдел.DeptId ВНУТРЕННЕЕ СОЕДИНЕНИЕ Консультант ON Consultant.DeptId = Department.DeptId;
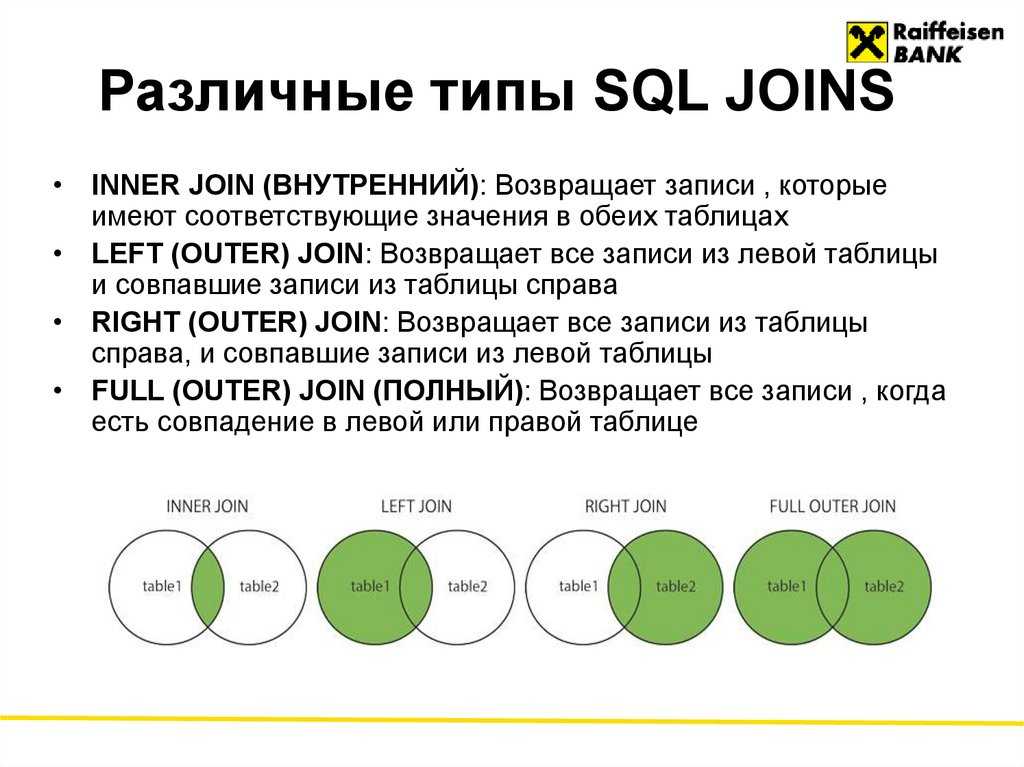
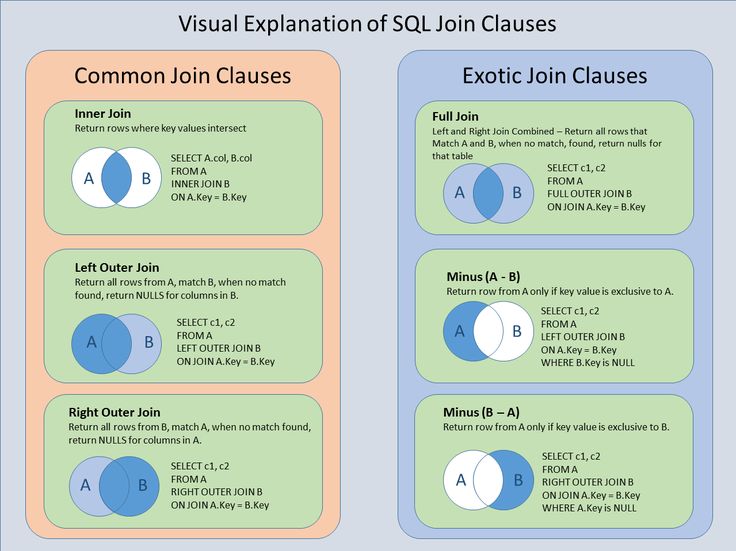
Внутреннее соединение SQL | Рабочие и различные типы соединений в SQL
Строки из двух или более таблиц объединяются для формирования набора строк во временной таблице с помощью предложения SQL JOIN. По крайней мере, если одно поле присутствует в двух или более таблицах и между ними существует связь, и если между двумя таблицами есть совпадающие значения, записи с совпадающими строками втягиваются во временную таблицу, и это называется внутренним соединением SQL. . Строки, не содержащие совпадающие значения, отклоняются, а временная таблица содержит только совпадающие значения. Наиболее распространенным соединением SQL является внутреннее соединение SQL. Первичный ключ одной таблицы соединяется с внешним ключом другой таблицы — наиболее распространенный сценарий внутреннего соединения SQL.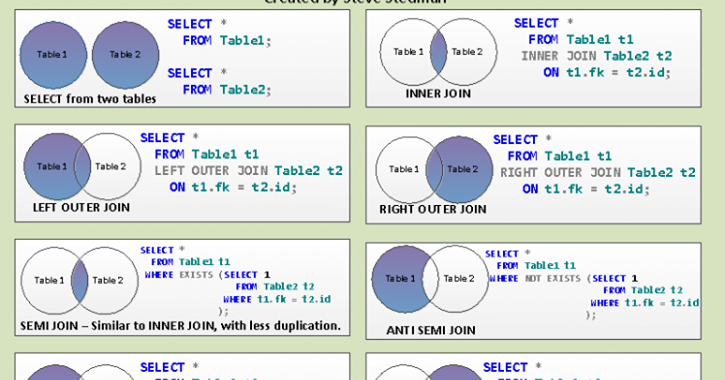
Синтаксис:
SELECT * FROM tab1 INNER JOIN tab2
ON tab1.col_name = tab2.col_name;
Где
- tab1 — первая таблица
- tab2 это вторая таблица
- tab1.col_name — имя столбца в первой таблице
- tab2.col_name — это имя столбца во второй таблице.
Работа внутреннего соединения SQL
Если в двух таблицах есть совпадающие значения, записи с совпадающими значениями возвращаются для формирования набора строк во временной таблице с помощью внутреннего соединения SQL. Графическое представление внутреннего соединения SQL представлено ниже:
- Заштрихованная синим цветом часть представляет совпадающие значения из обеих таблиц.
- Рассмотрим две таблицы, таблицу заказов и таблицу клиентов:
Таблица заказов
| IDord | IDCust | Ордваль |
| 1 | 123 | 12 |
| 2 | 456 | 34 |
| 3 | 789 | 56 |
| 4 | 012 | 78 |
Таблица клиентов
| IDCust | Пользовательское имя | Происхождение |
| 456 | Азбука | ИНДИЯ |
| 012 | ДЕФ | США |
| 809 | ГХИ | КИТАЙ |
| 134 | ДЖКЛ | ГЕРМАНИЯ |
- Столбец IDCust является общим как в таблице заказов, так и в таблице клиентов.
 IDCust — это связь между таблицей заказов и таблицей клиентов.
IDCust — это связь между таблицей заказов и таблицей клиентов. - Теперь мы создаем инструкцию SQL, содержащую внутреннее соединение, для извлечения только тех записей из таблиц заказов и клиентов, которые имеют совпадающие значения.
Код:
ВЫБЕРИТЕ заказы.IDord, заказы.IDCust, клиенты.Имя пользователя, клиенты.происхождение
ОТ заказов
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ клиентов ПО заказам.IDCust = customers.IDCust;
Вывод:
Пояснение к приведенной выше таблице: Таблица заказов состоит из трех столбцов: идентификатор заказа (IDord), идентификатор клиента (IDCust) и стоимость заказа (ordval). Таблица клиентов состоит из трех столбцов: идентификатор клиента (IDCust), имя клиента (Custname) и происхождение. Связь между двумя таблицами — это идентификатор клиента (IDCust).
Код:
ВЫБЕРИТЕ заказы.IDord, заказы.IDCust, customers. Custname, customers.origin
Custname, customers.origin
ИЗ заказов
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ клиентов ПО заказам.IDCust = customers.IDCust;
Объяснение к приведенному выше коду: Приведенные выше операторы SQL Выбирает столбцы идентификатора заказа (IDord), идентификатора клиента (IDCust), имя клиента и столбцы происхождения клиента из таблиц заказов и клиентов, имеющих совпадающие значения в идентификаторе клиента (IDCust), в результате в таблице, состоящей из двух записей и четырех столбцов идентификатора заказа (IDord), идентификатора клиента (IDCust), имени клиента и происхождения клиента. Внутреннее соединение SQL применяется к столбцу идентификатора заказа (IDord).
Примеры реализации внутреннего соединения SQL
Ниже приведены примеры реализации внутреннего соединения SQL:
Пример №1
Рассмотрим две таблицы.
Таблица маркировки
| Rollno | Имя ученика |
| 3 | Азбука |
| 4 | ДЕФ |
| 5 | ГХИ |
| 6 | ДЖКЛ |
- Столбец Rollno является общим как в таблице «Студенты», так и в таблице «Отметки».
 Rollno — это связь между таблицей заказов и таблицей клиентов.
Rollno — это связь между таблицей заказов и таблицей клиентов. - Теперь мы создаем инструкцию SQL, содержащую внутреннее соединение, для извлечения только тех записей из таблицы «Студенты и оценки», которые имеют совпадающие значения.
Код:
ВЫБЕРИТЕ учащиеся.Роллно, учащиеся.Тема, учащиеся.Оценки, Оценки.Имя учащегося
ОТ учащегося
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Оценки НА учащиеся.Роллно = метки.Роллно;
Вывод:
Пояснение к приведенному выше коду: В приведенном выше примере есть две таблицы: таблица ученика и таблица оценок. Таблица ученика состоит из трех столбцов: Roll number (Rollno), Subject и Marks. Таблица оценок состоит из двух столбцов: Номер списка (Rollno), Имя ученика (studentname). Отношение между двумя таблицами — это номер рулона (Rollno).
Код:
ВЫБЕРИТЕ учащиеся.Роллно, учащиеся.Тема, учащиеся.Оценки, Оценки.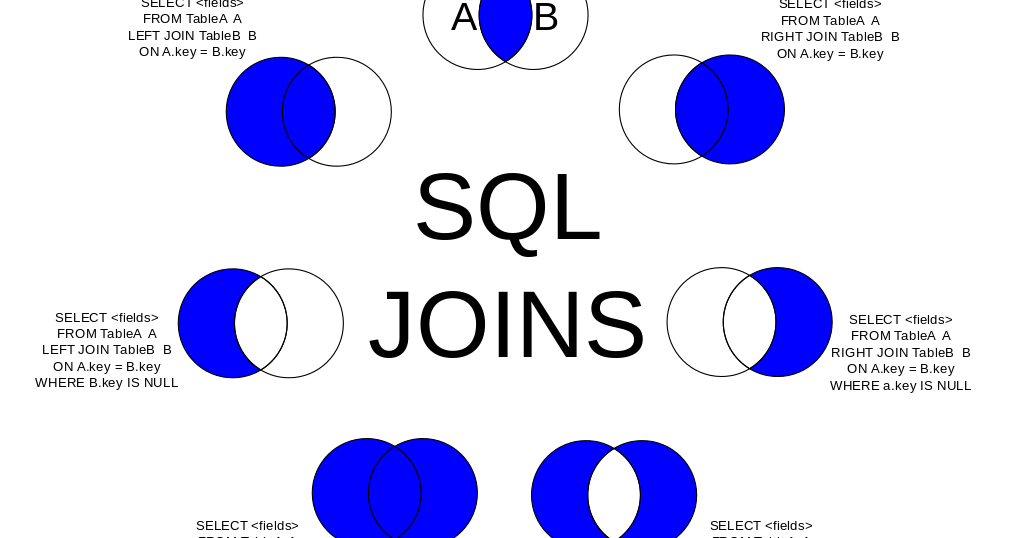 Имя учащегося
Имя учащегося
ОТ учащегося
ВНУТРЕННЕЕ СОЕДИНЕНИЕ Отметки НА учащихся.Роллно = метки.Роллно;
Объяснение к приведенному выше коду: Вышеприведенные операторы SQL Выбирает столбцы Номер списка (Rollno), Тема и Оценки и Имя учащегося (имя студента) от студентов и таблицы оценок, имеющие совпадающие значения в номере списка (Rollno), в результате чего таблица, состоящая из двух записей и четырех столбцов Roll number (Rollno), Subject, Marks и Studentname. Внутреннее соединение SQL применяется к столбцу Roll number (Rollno).
Пример #2
Рассмотрим две таблицы Company Table и Item Table
Company Table
| ID компании | Название компании | Город компании |
| 1 | А | Блор |
| 2 | Б | Майсур |
| 3 | С | Млор |
| 4 | Д | Тумкур |
Таблица позиций
| Идентификатор позиции | Название позиции | Идентификатор компании |
| 3 | Азбука | 3 |
| 4 | ДЕФ | 4 |
| 5 | ГХИ | 5 |
| 6 | ДЖКЛ | 6 |
- Столбец «Идентификатор компании» является общим как в таблице «Компания», так и в таблице «Элемент».
 Идентификатор компании — это связь между таблицей Company и таблицей Item.
Идентификатор компании — это связь между таблицей Company и таблицей Item. - Теперь мы создаем инструкцию SQL, содержащую внутреннее соединение, для извлечения только тех записей из таблиц Company и Item, которые имеют совпадающие значения.
Код:
ВЫБЕРИТЕ Company.Company ID, Company.Company name, Company.Company city, Item.Item ID, Item.item name
FROM Company
INNER JOIN Item ON Company.Company ID = Item.Company ID;
Вывод:
Объяснение к приведенному выше коду: В приведенном выше примере есть две таблицы: таблица компаний и таблица товаров. Таблица компаний состоит из трех столбцов: «Идентификатор компании», «Название компании» и «Город компании». Таблица товаров состоит из трех столбцов: идентификатор товара, название товара и идентификатор компании. Отношение между двумя таблицами — идентификатор компании.
Код:
ВЫБЕРИТЕ Company.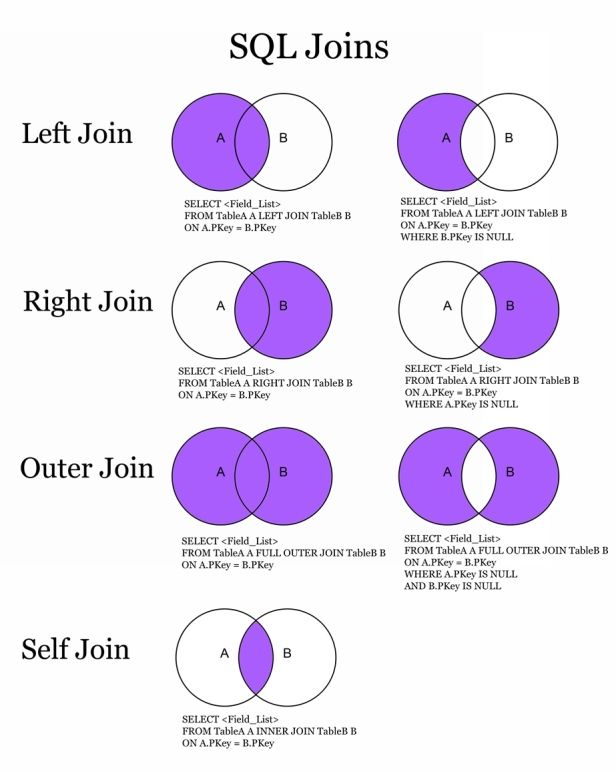 Company ID, Company.Company name, Company.Company city, Item.Item ID, Item.item name
Company ID, Company.Company name, Company.Company city, Item.Item ID, Item.item name
FROM Company
INNER JOIN Item ON Company.Company ID = Item.Company ID;
Пояснение к приведенному выше коду: Вышеуказанные операторы SQL Выбирает столбцы идентификатора компании, названия компании и города компании, столбцы идентификатора элемента и имени элемента из таблиц компаний и элементов, имеющих совпадающие значения в идентификаторе компании, в результате чего получается таблица, состоящая из две записи и пять столбцов Идентификатор компании, название компании и город компании, идентификатор элемента и название элемента. Внутреннее соединение SQL применяется к столбцу идентификатора компании.
Заключение
В этой статье мы узнали о различных типах соединений, их определениях и различиях, синтаксисе соединения, объяснении синтаксиса, работе, примерах реализации и объяснении их результатов после выполнения запросов.
Рекомендуемые статьи
Это руководство по внутреннему соединению SQL.