Работа с виртуальными каталогами IIS
Читайте также
Работа с виртуальными дисками
Работа с виртуальными дисками Особо следует отметить возможности Virtual PC 2004 по работе с виртуальными жесткими дисками. К таковым, в частности, относятся возможность подключения к каждой ВМ до трех виртуальных жестких дисков и поддержка трех типов таких дисков: диска
Работа с виртуальными дисками
Работа с виртуальными дисками Возможности VMware по работе с виртуальными жесткими дисками по «численным показателям» превышают возможности Virtual PC 2004, В частности, вы можете подключить к каждой ВМ до четырех виртуальных жестких дисков с интерфейсом IDE и до семи дисков с
Панель управления виртуальными машинами
Панель управления виртуальными машинами
Элементы управления виртуальными машинами распределены по трем областям основного окна VMware (см.
Работа с виртуальными дисками
Работа с виртуальными дисками Возможности Parallels по работе с виртуальными жесткими дисками уступают возможностям и Virtual PC, и VMware. Вы можете подключить к каждой ВМ до четырех виртуальных жестких дисков с интерфейсом IDE, но при этом ни один из них нельзя использовать для
Управление каталогами
Управление каталогами Создание и удаление каталогов осуществляется при помощи двух простых функций. BOOL CreateDirectory(LPCTSTR lpPathName, LPSECURITY_ATTRIBUTES lpSecurityAttributes) BOOL RemoveDirectory(LPCTSTR lpPathName) lpPathName является указателем на завершающуюся нулевым символом строку, которая содержит путь к
1.
 4.4. Работа с файлами и каталогами с помощью оболочки GNOME
4.4. Работа с файлами и каталогами с помощью оболочки GNOME
1.4.4. Работа с файлами и каталогами с помощью оболочки GNOME На рабочем стаде GNOME сразу после установки системы вы найдете три пиктограммы (рис. 1.52):• Компьютер — используется для «прогулок» по файловой системе, просмотра содержимого сменных носителей;• Домашняя папка
Работа с каталогами
Работа с каталогами Класс QDir обеспечивает независимые от платформы средства работы с каталогами и получение информации о файлах. Для демонстрации способов применения класса QDir мы напишем небольшое консольное приложение, которое подсчитывает размер дискового
50. Делайте деструкторы базовых классов открытыми и виртуальными либо защищенными и невиртуальными
50. Делайте деструкторы базовых классов открытыми и виртуальными либо защищенными и невиртуальными
РезюмеУдалять или не удалять — вот в чем вопрос! Если следует обеспечить возможность удаления посредством указателя на базовый класс, то деструктор базового класса
Делайте деструкторы базовых классов открытыми и виртуальными либо защищенными и невиртуальными
РезюмеУдалять или не удалять — вот в чем вопрос! Если следует обеспечить возможность удаления посредством указателя на базовый класс, то деструктор базового класса
Правило 7: Объявляйте деструкторы виртуальными в полиморфном базовом классе
Правило 7: Объявляйте деструкторы виртуальными в полиморфном базовом классе Существует много способов отслеживать время, поэтому имеет смысл создать базовый класс TimeKeeper и производные от него классы, которые реализуют разные подходы к хронометражу:class TimeKeeper
14.8. Работа с файлами, каталогами и деревьями
14.8. Работа с файлами, каталогами и деревьями
При выполнении рутинных задач приходится много работать с файлами и каталогами, в том числе с целыми иерархиями каталогов. Немало материала на эту тему вошло в главу 4, но кое-какие важные моменты мы хотим осветить
Немало материала на эту тему вошло в главу 4, но кое-какие важные моменты мы хотим осветить
2.2.1.4 Разделение потоков между виртуальными процессорами.
2.2.1.4 Разделение потоков между виртуальными процессорами. Для каждого класса поддерживаются три очереди потоков, которые разделяются всеми виртуальными процессорами данного класса: Очередь готовых к выполнению потоков.Очередь спящих потоков. В нее помещается,
Работа с каталогами файловой системы
Каюты круизного лайнера оснастят виртуальными окнами Николай Маслухин
Каюты круизного лайнера оснастят виртуальными окнами Николай Маслухин Опубликовано 06 февраля 2014
Крупнейшая туристическая компания Royal Caribbean International, обладающая действительно шикарным круизным флотом, представила новый лайнер.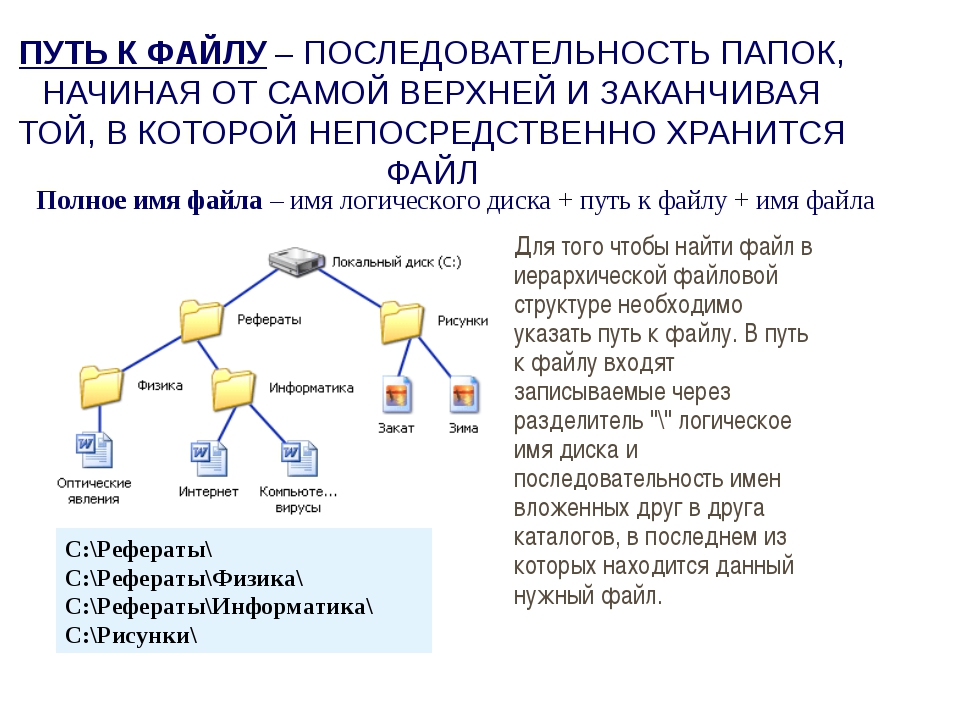 Помимо полетов в
Помимо полетов в
Болтуны всех стран, объединяйтесь! Мгновенный обмен сообщениями и борьба с виртуальными границами
Болтуны всех стран, объединяйтесь! Мгновенный обмен сообщениями и борьба с виртуальными границами Автор: Илья Щуров VoyagerЛюдям нужно общение. Люди хотят говорить, говорить здесь и сейчас, говорить со всем миром, невзирая на границы и расстояния. Поэтому такие технологии,Глава 6 Работа с файлами и каталогами
Глава 6 Работа с файлами и каталогами ? Что нужно знать о файлах?? Каталоги.? Создание, копирование и перемещение файлов и
c_sharp_stream [IT-ЗАМЕТКИ]
Назад
Источник
Пространство имен System.
Многие типы из пространства имен System.IO сосредоточены на программных манипуляциях физическими каталогами и файлами. Дополнительные типы предоставляют поддержку чтения и записи данных в строковые буферы, а также области памяти.
Эти классы позволяют сохранять и извлекать элементарные типы данных (целочисленные, булевские, строковые и т.п.) в двоичном виде.
Этот класс предоставляет временное хранилище для потока байтов, которые могут затем быть перенесены в постоянные хранилища
Эти классы используются для манипуляций структурой каталогов машины.
Этот класс предоставляет детальную информацию относительно дисковых устройств, используемых данной машиной
Этот класс обеспечивает произвольный доступ к файлу (т.е. возможности поиска) с данными, представленными в виде потока байт.
Этот класс позволяет отслеживать модификации внешних файлов в определенном каталоге.
Этот класс обеспечивает произвольный доступ к данным, хранящимся в памяти, а не в физическом файле
Этот класс выполняет операции над типами System.String, содержащими информацию о пути к файлу или каталогу в независимой от платформы манере
Эти классы используются для хранения (и извлечения) текстовой информации из файла. Эти классы не поддерживают произвольного доступа к файлу
Подобно классам StreamWriter/StreamReader, эти классы также работают с текстовой информацией.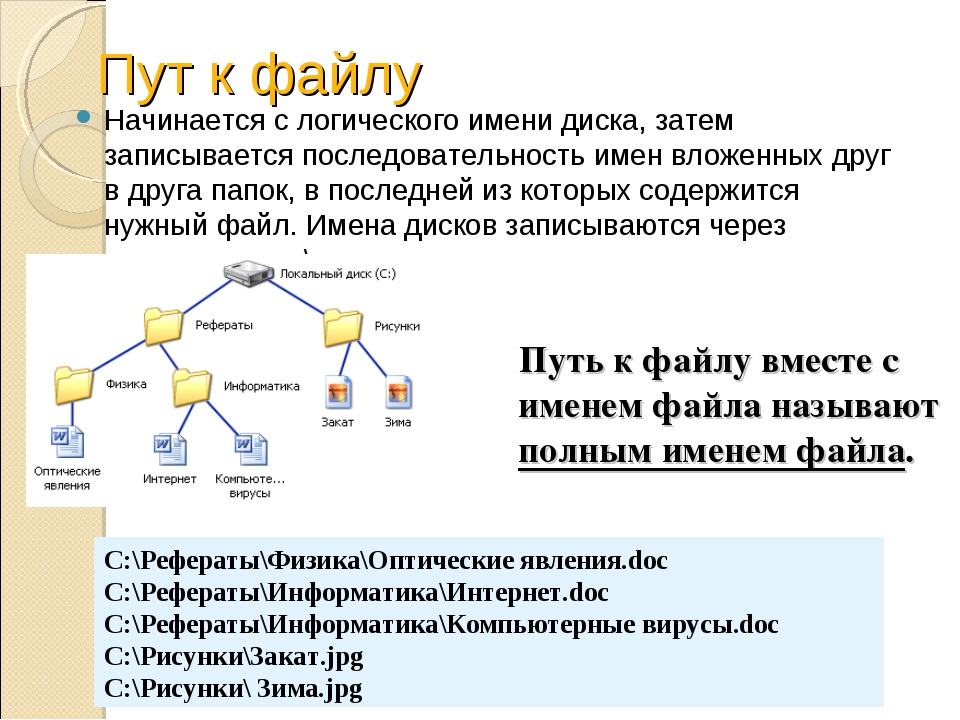 Однако лежащим в основе хранилищем является строковый буфер, а не физический файл
Однако лежащим в основе хранилищем является строковый буфер, а не физический файл
Дополнительная инфа
Данные классы предназначены для работы с папками и файлами:
Directory и DirectoryInfo – для работы с папками, а File и FileInfo – с файлами. Отличие этих классов в том, что классы Directory и File — статические, а DirectoryInfo и FileInfo позволяют создавать объекты. Назначение же и тех и других одинаковое.
Path это статический класс.NET, облегчающий работу с путями.
| Название метода | Назначение |
|---|---|
| Path.ChangeExtension | Позволяет изменить расширение файла в пути. |
| Path.Combine | Позволяет объединить две части пути папке и имя файла. |
| Path.GetDirectoryName | Вычленяет из полного пути путь к папке (безоконечного разделителя \) |
Path. GetExtension GetExtension | Вычленяет из полного пути расширение файла(с лидирующей точкой) |
| Path.GetFileName | Вычленяет из полного пути имя файла с расширением. |
| Path.GetFileNameWithoutExtension | Вычленяет из полного пути имя файла без расширения. |
| Path.GetFullPath | Возвращает полный путь по относительному. |
| Path.GetInvalidFileNameChars | Возвращает массив символов, которые не могут быть использованы в имени файла. |
| Path.GetInvalidPathChars | Возвращает массив символов, которые не могут быть использованы в пути. |
| Path.GetInvalidFileNameChars | Возвращает массив символов, которые не могут быть использованы в имени файла. |
| Path.GetPathRoot | Возвращает корень (диск, с оконечным разделителем /) данного пути. |
| Path.GetRandomFileName | Генерирует корректное случайное имя файла (с расширением). |
Path. GetTempFileName GetTempFileName | Генерирует уникальное имя файла во временной папке и возвращает полный путь к нему. |
| Path.GetTempPath | Возвращает полный путь к временной папке. |
| Path.HasExtension | Возвращает булевое значение – есть ли расширение у файла (true) или нет (false). |
| Path.IsPathRooted | Возвращает булевое значение – абсолютный ли путь (true) или нет (false). |
Класс Drivelnfo позволяет получить информацию о дисковом устройстве компьютера. Интерес представляют относительно немного частей этой информации — обычно класс Drivelnfo применяется лишь для получения общего объема использованного и свободного пространства.
| Член | Описание |
|---|---|
| TotalSize | Получает общий объем устройства в байтах. Это включает сумму выделенного и свободного места |
| TotalFreeSpace | Получает общий объем свободного пространства в байтах |
| AvailableFreeSpace | Получает общий объем доступного пространства в байтах. Доступное пространство может быть меньше, чем общее свободное пространство, если для вас установлена квота свободного дискового пространства, которое может использовать процесс ASP.NET Доступное пространство может быть меньше, чем общее свободное пространство, если для вас установлена квота свободного дискового пространства, которое может использовать процесс ASP.NET |
| DriveFormat | Возвращает имя файловой системы, используемой на устройстве (такое как NTFS или FAT32) |
| DriveType | Возвращает значение из перечисления DriveType, которое указывает, является ли диск фиксированным, сетевым, CD-ROM, RAM или съемным диском. (Если определить тип диска не удалось, возвращает Unknown.) |
| IsReady | Возвращает признак готовности устройства для операций чтения или записи. |
| Name | Возвращает букву имени диска (наподобие С: или E: |
| VolumeLabel | Получает или устанавливает описательную метку тома устройства. Если это устройство формата NTFS, метка может содержать до 32 символов. Если метка не установлена, свойство вернет null Если метка не установлена, свойство вернет null |
| RootDirectory | Возвращает рбъект Directorylnfo, описывающий корневой каталог дискового устройства |
| GetDrives() | Возвращает массив объектов DriveiInfо, представляющий все логические устройства данного компьютера |
Класс FileStream представляет собой поток файла. Он позволяет производить операции чтения и записи из файлов (как синхронные, так и асинхронные). Данный класс поддерживает метод Seek, что позволяет перемещать текущее положение курсора в файле.
Пример использования данного класса:
namespace FileStreamExample
{
class Program
{
static void Main(string[] args)
{
Console.Write("Введите путь к файлу:");
string filePath = Console.ReadLine();
// Использование блока using позволяет правильно разрушить FileStream
using (FileStream fs = new FileStream(filePath,FileMode. Create, FileAccess.ReadWrite, FileShare.ReadWrite))
{
// Получаем данные для записи в файл
Console.WriteLine("Введите строку для записи в файл:");
string writeText = Console.ReadLine();
// Преобразуем строку в массив байт,
// т.к. FileStream умеет работать только с байтами
byte[] writeBytes = Encoding.UTF8.GetBytes(writeText);
// Запишем данные в файл
fs.Write(writeBytes, 0, writeBytes.Length);
// Сохраним данные из буфера на диск
fs.Flush();
// Теперь прочитаем данные из файла
// для этого нужно сначала установить курсор на начало файла
fs.Seek(0, SeekOrigin.Begin);
// Теперь прочитаем данные в другой массив байт
byte[] readBytes = new byte[(int)fs.Length];
fs.Read(readBytes, 0, readBytes.Length);
// Преобразуем байты в строку
string readText = Encoding. UTF8.GetString(readBytes);
Console.WriteLine("Данные, прочитанные из файла: {0}",readText);
}
Console.Read();
}
}
}
Create, FileAccess.ReadWrite, FileShare.ReadWrite))
{
// Получаем данные для записи в файл
Console.WriteLine("Введите строку для записи в файл:");
string writeText = Console.ReadLine();
// Преобразуем строку в массив байт,
// т.к. FileStream умеет работать только с байтами
byte[] writeBytes = Encoding.UTF8.GetBytes(writeText);
// Запишем данные в файл
fs.Write(writeBytes, 0, writeBytes.Length);
// Сохраним данные из буфера на диск
fs.Flush();
// Теперь прочитаем данные из файла
// для этого нужно сначала установить курсор на начало файла
fs.Seek(0, SeekOrigin.Begin);
// Теперь прочитаем данные в другой массив байт
byte[] readBytes = new byte[(int)fs.Length];
fs.Read(readBytes, 0, readBytes.Length);
// Преобразуем байты в строку
string readText = Encoding. UTF8.GetString(readBytes);
Console.WriteLine("Данные, прочитанные из файла: {0}",readText);
}
Console.Read();
}
}
} Create, FileAccess.ReadWrite, FileShare.ReadWrite))
{
// Получаем данные для записи в файл
Console.WriteLine("Введите строку для записи в файл:");
string writeText = Console.ReadLine();
// Преобразуем строку в массив байт,
// т.к. FileStream умеет работать только с байтами
byte[] writeBytes = Encoding.UTF8.GetBytes(writeText);
// Запишем данные в файл
fs.Write(writeBytes, 0, writeBytes.Length);
// Сохраним данные из буфера на диск
fs.Flush();
// Теперь прочитаем данные из файла
// для этого нужно сначала установить курсор на начало файла
fs.Seek(0, SeekOrigin.Begin);
// Теперь прочитаем данные в другой массив байт
byte[] readBytes = new byte[(int)fs.Length];
fs.Read(readBytes, 0, readBytes.Length);
// Преобразуем байты в строку
string readText = Encoding.
Create, FileAccess.ReadWrite, FileShare.ReadWrite))
{
// Получаем данные для записи в файл
Console.WriteLine("Введите строку для записи в файл:");
string writeText = Console.ReadLine();
// Преобразуем строку в массив байт,
// т.к. FileStream умеет работать только с байтами
byte[] writeBytes = Encoding.UTF8.GetBytes(writeText);
// Запишем данные в файл
fs.Write(writeBytes, 0, writeBytes.Length);
// Сохраним данные из буфера на диск
fs.Flush();
// Теперь прочитаем данные из файла
// для этого нужно сначала установить курсор на начало файла
fs.Seek(0, SeekOrigin.Begin);
// Теперь прочитаем данные в другой массив байт
byte[] readBytes = new byte[(int)fs.Length];
fs.Read(readBytes, 0, readBytes.Length);
// Преобразуем байты в строку
string readText = Encoding. UTF8.GetString(readBytes);
Console.WriteLine("Данные, прочитанные из файла: {0}",readText);
}
Console.Read();
}
}
}
UTF8.GetString(readBytes);
Console.WriteLine("Данные, прочитанные из файла: {0}",readText);
}
Console.Read();
}
}
}Особого внимания заслуживает конструктор FileStream:
FileStream fs = new FileStream(filePath, FileMode.Create,FileAccess.ReadWrite, FileShare.ReadWrite);
Первым параметром передается путь к файлу (с именем и расширением) в виде переменной или литерала String.
Второй параметр данного конструктора – переменная типа FileMode (перечисление). Он описывает, каким образом файл должен быть открыт операционной системой.
| Перечислитель | Описание |
|---|---|
| FileMode.Append | Открывает файл, если он существует, и перемещает курсор в конец файл.Если файл не существует – создает новый файл. FileMode.Append можно использовать только вместе с FileAccess.Write. |
| FileMode.Create | Создает новый файл, если файл уже существует, то он будет переписан. |
| FileMode.CreateNew | Создает новый файл, если файл уже существует, то будет вызвано исключение IOException. |
| FileMode.Open | Открывает существующий файл, если файла не существует,то будет вызвано исключение FileNotFoundException. |
| FileMode.OpenOrCreate | Открывает существующий файл, если файла не существует,то будет создан новый файл. |
| FileMode.Truncate | Открывает существующий файл и усекает его размер до нуля. |
Третий параметр переменная типа FileAccess Он описывает, каким образом осуществляется доступ к файлу.
| Перечислитель | Описание |
|---|---|
| FileAccess.Write | только на запись |
| FileAccess.Read | только на чтение |
| FileAccess.ReadWrite | запись и чтение |
Последний параметр – переменная типа FileShare этот параметр позволяет
управлять доступом, который другие объекты FileStream могут осуществлять к этому файлу.
| Перечислитель | Описание |
|---|---|
| FileShare.Delete | Разрешает удаление файла. |
| FileShare.Inheritable | Разрешает наследование дескриптора файла дочерними процессами. В Win32 непосредственная поддержка этого свойства не обеспечена. |
| FileShare.None | Отклоняет совместное использование текущего файла. Любой запрос на открытие файла не выполняется до тех пор, пока файл не будет закрыт. |
| FileShare.Read | Разрешает последующее открытие файла для чтения. |
| FileShare.ReadWrite | Разрешает последующее открытие файла для чтения или записи. |
| FileShare.Write | Разрешает последующее открытие файла для записи. |
Не всегда удобно работать с байтовыми массивами. И для этого существуют классы-обертки.
Такими классами обертками для работы с символами и строками могут служить классы System.IO.StreamReader и System. IO.StreamWriter.
IO.StreamWriter.
namespace FileStreamExample
{
class Program
{
static void Main(string[] args)
{
Console.Write("Введите путь к файлу:");
string filePath = Console.ReadLine();
FileStream fs = new FileStream(filePath, FileMode.Create,FileAccess.ReadWrite, FileShare.ReadWrite);
StreamWriter sw = new StreamWriter(fs, Encoding.UTF8);//Указываем кодировку UTF-8
Console.WriteLine("Введите строку для записи в файл:");
string writeText = Console.ReadLine();
// Запишем данные в поток
sw.Write(writeText);
// Сохраним данные из буфера на диск и закроем поток
sw.Dispose();
fs.Dispose();
// Теперь прочитаем данные из файла
StreamReader sr = new StreamReader(filePath, Encoding.UTF8);
string readText = sr.ReadToEnd();
sr.Dispose();
Console.WriteLine("Данные, прочитанные из файла: {0}", readText);
Console. Read();
}
}
} Read();
}
}
}
Read();
}
}
}При работе с этими классами стоит обратить внимание на следующие моменты. У объектов типа StreamWriter есть булевое свойство AutoFlush, установив которое в true можно не вызывать каждый раз метод Flush() после записи очередного блока данных в поток.
У объектов типа StreamReader стоит обратить внимание на булевое свойство EndOfStream, которое показывает, не достигли ли мы конца потока. Также у них определено несколько методов для чтения:
Read – читает следующий символ, либо массив символов;
ReadBlock – читает массив символов;
ReadLine – читает строку от текущей позиции до символа перехода на новую строчку.
ReadToEnd – читает поток от текущей позиции до конца.
Данные классы предназначены для записи простых типов данных в поток в виде двоичных значений, а также строк в определенной кодировке. Они выступают в виде обертки для других, базовых потоков.
Они выступают в виде обертки для других, базовых потоков.
namespace FileStreamExample
{
class Program
{
static void Main(string[] args)
{
// Получаем путь к файлу
Console.WriteLine("Введите путь к файлу:");
string filePath = Console.ReadLine();
using (FileStream fs = new FileStream(filePath, FileMode.Create,FileAccess.ReadWrite, FileShare.ReadWrite))
{
BinaryWriter bw = new BinaryWriter(fs);
Console.Write("Введите строку для записи в файл:");
string writeText = Console.ReadLine();
int writeNum = -1;
while (true)
{
try
{
Console.WriteLine("Введите целое число для записи в файл:");
writeNum = Convert.ToInt32(Console.ReadLine());
break;
}
catch
{
Console. WriteLine("Ошибка! Не удалось преобразовать строку в целое число!");
}
}
bw.Write(writeText);
bw.Write(writeNum);
// Сохраним данные из буфера на диск
bw.Flush();
// Установим курсор на начало файла
fs.Seek(0, SeekOrigin.Begin);
BinaryReader br = new BinaryReader(fs);
// Данные читать нужно в том же порядке, в котором они и записывались в поток
Console.Write("Строка, прочитанная из файла:");
Console.WriteLine(br.ReadString());
Console.Write("Целое число, прочитанное из файла:");
Console.WriteLine(br.ReadInt32());
}
Console.Read();
}
}
} WriteLine("Ошибка! Не удалось преобразовать строку в целое число!");
}
}
bw.Write(writeText);
bw.Write(writeNum);
// Сохраним данные из буфера на диск
bw.Flush();
// Установим курсор на начало файла
fs.Seek(0, SeekOrigin.Begin);
BinaryReader br = new BinaryReader(fs);
// Данные читать нужно в том же порядке, в котором они и записывались в поток
Console.Write("Строка, прочитанная из файла:");
Console.WriteLine(br.ReadString());
Console.Write("Целое число, прочитанное из файла:");
Console.WriteLine(br.ReadInt32());
}
Console.Read();
}
}
}
WriteLine("Ошибка! Не удалось преобразовать строку в целое число!");
}
}
bw.Write(writeText);
bw.Write(writeNum);
// Сохраним данные из буфера на диск
bw.Flush();
// Установим курсор на начало файла
fs.Seek(0, SeekOrigin.Begin);
BinaryReader br = new BinaryReader(fs);
// Данные читать нужно в том же порядке, в котором они и записывались в поток
Console.Write("Строка, прочитанная из файла:");
Console.WriteLine(br.ReadString());
Console.Write("Целое число, прочитанное из файла:");
Console.WriteLine(br.ReadInt32());
}
Console.Read();
}
}
} Объекты класса BinaryWriter имеют всего один метод для записи (Write), который имеет несколько перегруженных вариантов, принимающих объекты различных типов данных.
Объекты же класса BinaryReader имеют несколько методов, которые предназначены для чтения различных типов данных.
При их использовании необходимо обратить внимание на то, что данные с помощью BinaryReader’a необходимо читать в том же порядке, в котором они были записаны BinaryWriter’ом.
Работа с каталогами в Python > Путь разработчика
Создайте библиотеку кнопок XAML в C#В этом примере показано, как можно создать библиотеку кнопок XAML с возможностью повторного использования в WPF. Пример Создание шаблона кнопки WPF в C# ис…
06 06 2021 22:50:36
Операции Java LinkedListСвязанные списки относятся к простейшим и наиболее распространенным структурам данных. Массивы и связанные списки аналогичны, так как они хранят коллекции…
04 06 2021 18:39:57
Преимущества и недостатки JavaScript Как и все языки компьютера, JavaScript имеет определенные преимущества и недостатки. Преимущества JavaScript: Быстрый для конечного пользователя: сценарий…
Преимущества JavaScript: Быстрый для конечного пользователя: сценарий…
01 06 2021 17:17:46
Вопросы по Python — 1Почему язык назывался Python? Python фактически получил свое название от серии комедии BBC с семидесятых годов « Летающий цирк Монти Пайтона». Дизайнеру пон…
29 05 2021 2:23:22
Закрыть всплывающие окна Mozilla Firefox в C#Некоторые средства браузера пытаются заблокировать всплывающие окна рекламы, но в последнее время некоторые из них пробираются через мою систему, поэтому я…
27 05 2021 17:44:26
Что такое поток Daemon в JavaДемон-поток — это поток поставщика услуг, который предоставляет услуги пользовательскому потоку. Демона, который работает в фоновом режиме и в основном соз…
25 05 2021 16:10:21
Исключение специальных символов в JavaScriptУправляющий символ позволяет вам выводить символы, которые обычно не могут быть доступны, как правило, потому что браузер интерпретирует его по-разному с т…
24 05 2021 18:34:34
Почему выбирают Java?Java является «простой, объектно-ориентированной и знакомой». Его синтаксис и организация программы, безусловно, намного проще, чем конкурирующие языки, та…
Его синтаксис и организация программы, безусловно, намного проще, чем конкурирующие языки, та…
23 05 2021 9:36:50
Циклы For и While в PythonЦиклы — одна из самых важных функций в программировании. Петли предлагают быстрый и простой способ сделать что-то многократно. Он может выполнять > блок…
21 05 2021 21:40:57
Тип заливки в JavaИзменение значения из одного типа данных в переменную другого типа называется преобразованием типа данных. Существует два типа литья, Примитивное литье тип…
17 05 2021 2:14:46
Сравнение строк в JavaКласс Java String имеет ряд методов сравнения строк. Ниже приведены некоторые из часто используемых методов: Операторы == для сравнения, а не значения, рав…
15 05 2021 14:25:21
Программа Hello World в C#В этой статье мы узнаем несколько версий программы Hello World на C#. Пример: 1 Обсуждение кода: Каждый Основной метод должен содержаться внутри класса (в…
11 05 2021 16:37:48
Метод «bind» в JavaScript? Метод bind() сохраняет контекст «this» и текущих параметров для будущего выполнения. Как правило, он используется для сохранения контекста выполнения для ф…
Как правило, он используется для сохранения контекста выполнения для ф…
10 05 2021 7:32:54
Имитация движения мыши и кликов в C#Эта программа использует функцию API mouse_event для имитации движения мыши и моделирования щелчка мыши. Обработчик события Paint программы рисует круги во…
09 05 2021 8:22:44
Как открыть и закрыть файл в PythonPython имеет встроенную функцию open(), чтобы открыть файл, он возвращает что-то, называемое файловым объектом. Файловый объект содержит методы и атрибуты,…
08 05 2021 15:46:47
Анимация проблемы Башни Ханоя в C#Следующий метод AnimateMovement перемещает диск по прямой линии из текущего местоположения в новый. Код вычисляет количество пикселей в секунду, которое он…
07 05 2021 16:20:57
Как рандомизировать двумерные массивы в C#В этом примере используется следующий метод расширения для рандомизации двумерных массивов. Чтобы рандомизировать двумерные массивы, код начинается с получ…
06 05 2021 8:48:40
Как использовать блокировки в JavaПри написании такого многопоточного кода вы должны уделять особое внимание при одновременном доступе к совместно используемым изменяемым переменным из неск…
03 05 2021 4:29:40
Как аннотации работают на Java?Аннотации Java используются для предоставления метаданных для Java-кода, хотя они не являются частью самой программы. Метаданные — это данные о данных. Так…
01 05 2021 13:47:59
Введение в потоки Thread в JavaВ чем разница между Reader и InputStream в Java Процесс представляет собой экземпляр выполняемой компьютерной программы. Процесс может выполняться процессо…
30 04 2021 18:32:34
Координаты чертежа карты без искажений в C#Сообщение Легко отображать координаты чертежа в C# позволяет вам легко сопоставить прямоугольник при рисовании координат прямоугольника в координатах устро…
29 04 2021 23:36:25
Использование памяти дисплея в C#Эта программа отображает общее и бесплатное использование физической, виртуальной и файловой памяти компьютера. Когда он запускается, следующий код отображ…
27 04 2021 20:13:11
Как получить длину строки в JavaДлина() объекта String возвращает длину этой строки. Длина строки Java такая же, как и юникодные кодовые единицы строки. Синтаксис: Нет параметра для lengt…
25 04 2021 10:34:55
Что такое undefined x 1 в JavaScript?Часть стандарта ECMA, JavaScript-консоли будут отображать объекты в виде массивов, когда объекты похожи на массивы. Например: для объекта, содержащего стро…
21 04 2021 9:25:30
Является ли Java «pass-by-reference» или «pass-by-value»?Прежде всего, мы должны понимать, что подразумевается под передачей по значению или передачей по ссылке. передается по ссылке Когда параметр передается по…
20 04 2021 16:22:34
Кортеж (Tuple) в PythonКортеж представляет собой совокупность неизменных Python объектов, разделенных запятыми. Кортежи похожи на списки, но мы не можем изменить элементы кортежа…
18 04 2021 1:33:49
Команды для работы с файлами и каталогами.
Определение типа файлов
В ОС Solarisсуществует много различных типов файлов. Используйте командуfileдля определения некоторых типов файлов.
Эта информация важна, когда вы хотите открыть или прочитать файл. Знание типа файла помогает вам решить, какую команду или программу необходимо использовать для работы с файлом.
Формат команды
File имя_файла(ов)
Результат выполнения команды fileчасто, но не обязательно представляет собой одно из следующих:
— Текст – Примеры, включая текст формата ASCII, английский текст, текст команд и выполняемые скрипты командного интерпретатора.
— Данные – Файлы данных, создаваемые приложениями. В некоторых случаях показывается тип данных, например, для документов FrameMaker. Если командаfileне может определить тип файла, она показывает, что это просто файл данных.
— Исполняемый или двоичный – Примеры, включая файлы 32-битного исполняемого и внешне-связанного формата (ELF) кода и другие динамически связанные исполняемые файлы. Этот тип файлов показывает, что файл – команда или программа.
Далее представлен пример определения текстового файла:
$ file dante
dante: commands text
Вывод содержимого текстового файла:
Команда cat(соединение) выводит на экран содержимое одного или более текстовых файлов. Она часто используется для вывода небольших текстовых файлов, т.к.catпоказывает все содержимое файла на экране без пауз.
Вы также можете использовать команду catдля создания короткого текстового файла без использования текстового редактора.
Формат команды
сat [имя_файла… ]
cat >имя_файла
Соединение нескольких файлов
Используйте команду catдля соединения содержимого двух файлов в один новый файл, например:
$ cat filename1 filename2 > newfile1
Замечание – Имя файла после знака “>” не должно быть таким же, как любое имя файла перед знаком “>”, иначе команда catвыдаст следующее сообщение об ошибке:cat:input/outputfiles‘имя_файла’identical.
Извлечение годных для печати строк
Команда stringsнаходит годные для печати строки в двоичном файле данных. Это позволяет вам читать текстовые строки, встроенные в двоичный файл, которые можно использовать для программирования.
Метасимволы
Существуют еще два полезных метасимвола в командном интерпретаторе – это символ перенаправления вывода (>) и символ конвейера (pipe) (|).
Символ перенаправления (>) берет вывод команды и направляет его в указанный файл.
Символ конвейера (|) используется в командной строке для направления вывода одной команды на вход другой команде.
Просмотр содержимого файла
Для просмотра содержимого большого текстового файла используйте команду more. При использовании этой команды содержимое текстового файла показывается на экране не все сразу, а по частям, при показе каждой из которых внизу экрана появляется следующее сообщение:
—More—(n%)
n% — это процент уже показанной части файла. Когда содержимое файла показывается полностью, то появляется приглашение командной строки.
Команда moreиспользуется при показе страниц встроенного руководства так, что клавиши управления прокруткой, представленные в табл. 4-1, такие же, какие используются для управления показом страниц встроенного руководства.
Замечание – Использования команд catилиmoreдля чтения двоичных файлов может привести терминал или окно к остановке. Если это произойдет, то закройте окно терминала и откройте новое или выберитеReset->SoftResetиз менюCDE Options.
Формат команды
More [ имя_файла… ]
Используйте команду для чтения текстовых, а не двоичных файлов.
Клавиши управления прокруткой
В строке —More— вы можете использовать клавиши, описанные в табл. 4-1, для управления возможностями прокрутки.
Табл. 4-1 Клавиши управления прокруткой для команды more
Клавиша | Описание |
Пробел | Прокрутка на следующий экран |
Return | Прокрутка на одну строку вниз |
b | Возврат на один экран |
f | Прокрутка вперед на один экран |
h | Вывод меню помощи и описания возможностей |
q | Выход и возврат в командную строку командного интерпретатора |
/string | Поиск «вперед» строки string |
n | Поиск следующего вхождения строки string |
Просмотр больших файлов
Используйте команду pgдля просмотра файла, длина которого больше чем один экран.
Эта команда делает паузы после показа каждого экрана текста и выводит знак «:» в конце страницы. Нажмите клавишу Returnдля вывода следующего экрана или используйте клавиши прокрутки, представленные в табл. 4-2.
Команда pgвыводит приглашение “EOF:”, когда достигнут конец файла. Нажмите клавишуReturnдля возвращения в приглашение командной строки.
Формат команды
Pgимя_файла(ов)
Клавиши прокрутки
В табл. 4-2 показаны клавиши, используемые для управления прокруткой экрана.
Табл. 4-2 Клавиши прокрутки для команды pg
Клавиша | Описание |
Return | |
l <Return> | |
d <Return> | |
.<Return> | |
+ /шаблон/ <Return> | |
$ <Return> | |
h <Return> | |
q <Return> |
Вывод количества строк, слов и символов файла
Команда weпоказывает количество строк, слов и символов, содержащихся в файле.
Формат команды.
wc[ -lwcm ] [имя_файла … ]
Использование команды wc с параметрами
Вы можете использовать следующие параметры с командой we:
-1Вывод количества строк
-wВывод количества слов
-с Вывод количества байт
-тВывод количества символов
Использование команды we без параметров
При использовании команды weбез параметров будет выведено количество строк, слов и символов, содержащихся в файле, например:
$ wc dante
33 223 1320 dante
$
Определение количества строк в файле
Для определения количества строк в файле выполните следующую команду:
$ wc — l dante
33 dante
$
Создание пустых файлов
Используйте команду touchдля создания пустого файла. Если в системе уже существует файл или каталог с таким же именем, как и у создаваемого, тогда командаtouchобновляет его время изменения и доступа на текущее.
Формат команды
touchимя_файла …
В командной строке при создании новых файлов вы можете указывать как абсолютный, так и относительный пути доступа.
Создание пустых файлов
Для создания пустого файла выполните следующее:
$ cd -/practice $ touch mailbox project projection research
$ ls
mailbox project
projection research
Перенаправление и вывод содержимого файла используя команду tee
Используйте команду teeв потоке для получения данных на входе и записи их как в стандартное устройство вывода, так и в указанный файл.
Команда teeкопирует стандартный ввод в стандартный вывод, записывая копию информации в файл (Рис. 4-1).
Рис. 4-1Командаtee
Формат команды
tee [-а ]имя_файла …
Дублирование данных
В следующем примере вывод команды lsзаписывается в файлlogfileи также выводится на экран по мере его заполнения.
Добавление данных к файлу
Если вы используете параметр -а с командой tee,то новая информация будет добавляться к файлу, а не перезаписывать его имеющееся содержимое.
Например:
Создание каталогов
Используйте команду mkdirдля создания каталогов. Вы можете создавать каталоги, используя как абсолютные, так и относительные пути доступа.
Эта команда позволяет вам указывать более чем одно имя каталога в одной командной строке, создавая несколько каталогов одновременно.
Формат команды
mkdir [-р ]имя_каталога …
Создание нового каталога
В этом примере команда mkdirсоздаёт новый каталог в домашнем каталоге пользователяuser1.
Замечание —Помните, что символ тильда (-),обозначающий ваш домашний каталог, доступен во всех командных интерпретаторах, за исключениемBourne.
Чтобы создать каталог, вы должны иметь соответствующие права доступа (права доступа обсуждаются в главе 6).Если у вас нет нужных прав доступа, то при попытке создать каталог вам будет выведено сообщение об ошибке, похожее на следующее:
Создание многоуровневой структуры каталогов
Для одновременного создания многоуровневой структуры каталогов используйте параметр -р. В следующем примере команда mkdir-р создаёт каталогpractice2 как подкаталог текущего каталога.
В то же самое время команда создаёт подкаталог dir1 в каталогеpractice2и каталогadminв каталогеdir1.
Копирование файлов и каталогов
Команда ср копирует файлы и каталоги.
Копирование файлов
Команда ср копирует содержимое файла в другой файл, также она копирует несколько файлов с возможностью предотвращения перезаписи существующих файлов.
Формат команды
ср [-ir ]файл_источник файл_назначения ср [ -ir ]файл_источник … каталог_назначения
Копирование файла в другой файл
Следующий пример показывает, как копировать один файл в новый в том же каталоге.
Копирование нескольких файлов
Следующий пример показывает, как копировать несколько файлов в каталог, отличный от текущего:
Предотвращение перезаписи существующих файлов при копировании
Используйте команду ср с параметром -iкак предупреждение. Параметр — iвыдаёт приглашение для подтверждения перед перезаписью любого существующего файла новым.
• Отвечая yes,вы подтверждаете перезапись.
• Отвечая по, вы предотвращаете перезапись командой ср существующего файла.
Например:
Копирование каталогов
Используйте команду ср с параметром -г для копирования каталога и его содержимого в другой каталог. Если этот каталог не существует, он будет создан командой ср.
Формат команды
ср -irисходный_каталог(и) каталог_назначения
При использовании параметра -iкоманда ср спрашивает подтверждения перед перезаписью существующего каталога или файла.
Копирование содержимого каталога в новый каталог
Следующий пример показывает, как копировать существующий каталог и всё его содержимое в новый в текущем рабочем каталоге.
Если вы не используете параметр -г, получите сообщение об ошибке:
Следующий пример показывает, как копировать каталог в другой, который не находится в текущем рабочем каталоге:
Перемещение и переименование файлов и каталогов
Используйте команду mvдля перемещения или переименования файла или каталога. Эта команда не воздействует на содержимое файла или каталога, она изменяет только метоположение или заменяет старое имя на новое.
Старое имя соответствует исходному файлу, а новое имя -новому. Если каталог назначения не существует, он будет создан.
Формат команды
mv [ -i ]источник каталог__назначения
mv [ -i ]источник… каталог_назначения
Параметр -iвыдаёт приглашение для подтверждения перед перемещением с перезаписью любого существующего файла новым.
• Отвечая yes,вы подтверждаете перенос и перезапись.
• Отвечая nо, вы предотвращаете перезапись командой mvфайла назначения.
Переименование файлов в текущем каталоге
Следующий пример показывает, как переименовать файл в текущем каталоге:
Перемещение файлов в другой каталог
Следующий пример показывает, как переместить файл в другой каталог:
Если вы перемещаете один каталог, и каталог назначения не существует, то каталог переименовывается в каталог назначения.
Если вы перемещаете несколько каталогов, и каталог назначения не существует, тогда вам будет выведено следующее сообщение об ошибке: mv:target_directorynotfound.
Переименование каталогов
Следующий пример показывает, как использовать команду mvдля переименования каталогов в текущем каталоге:
Перемещение каталога вместе с его содержимым
Следующий пример показывает, как использовать команду mvдля перемещения каталога вместе с его содержимым в новый каталог:
Переименование файлов в другом каталоге
Следующий пример показывает, как использовать команду mvдля переименования файла в каталоге, отличном от текущего:
Удаление файлов и каталогов
После того как файлы становятся ненужными, вы можете удалить их, используя команду rm.
Удаление файлов
Вы можете использовать команду rmдля удаления одновременно одного или нескольких файлов.
Формат команды
rm[ -ir ]имя_файла . . .
Удаление нескольких файлов
Вы можете удалить несколько файлов одновременно, например:
Используйте команду rmcпараметром -iдля вывода предупреждения. Параметр -iвыводит приглашение для подтверждения перед удалением любого файла.
• Отвечая yes,вы подтверждаете удаление.
• Отвечая nо, вы запрещаете команде rmудалять файл.
Например:
Удаление каталогов
Вы можете удалить ненужные каталоги, используя команды rmdirиrm.
• Команда rmdirудаляет только пустые каталоги.
• Команда rm-г может удалять каталоги, содержащие файлы.
Формат команды
rmdirимя_каталога(ов) rm-r[i]имя_каталога(ов)
Предупреждение —Для получения подтверждения перед удалением любого файла используйте параметр -iкоманды rm.Этот параметр запускает команду в интерактивном режиме.
Удаление пустого каталога
Используйте команду rmdirдля удаления пустого каталога, например:
Интерактивное удаление каталогов
Используйте команду rm-irдля интерактивного удаления каталогов, например:
Удаление каталога с содержимым
Используйте команду rm–rдля удаления не пустого каталога, например:
Замечание —Вы не можете удалить каталог, пока находитесь в нём. Необходимо переместиться в вышестоящий каталог для удаления подкаталога.
Поиск файлов и текста
Поиск, файлов с использованием команды find
Используйте команду findдля поиска файлов в дереве каталогов. Эта команда даёт вам возможность искать файлы по заданному критерию, такому как имя файла, размер, владелец, время изменения или тип.
Команда findосуществляет рекурсивный поиск в дереве каталогов тех файлов, которые соответствуют критериям поиска.
Как только findнаходит файлы, которые соответствуют критериям поиска, то пути доступа к ним выводятся на экран.
Формат команды
findпутьвыражение(я) действие(я)
Первый аргумент в командной строке -это путь доступа, в котором начинается поиск. Это может быть как абсолютный, так и относительный путь.
Остальные аргументы задают критерий поиска, по которому будет вестись поиск файлов, и действия, которые будут производиться над найденными файлами.
С Табл. 5-1по Табл. 5-3на странице 5-5содержится описание аргументов, выражений и действий, используемых с командойfind.
Табл. 5-1Аргументы используемые с командойfind
Аргумент Описание
путь Путь к каталогу, в котором будет вестись поиск.
выражениеКритерий поиска, указанный одним или более параметрами. Указание многих параметров говоритfindпонимать как запрос «AND» и все перечисленные выражения должны возвратить истину.
Табл. 5-2Выражения, используемые с командойfind
Выражение Описание
-nameимя_файлаПоиск файлов по имени. Метасимволы допустимы, если указываются внутри » «.
-size[+|-]nПоиск файлов, размер которых больше чем+n, меньше чем -nили равны п. п, задаётся в 512-байтных блоках.
-atime [+1 — ]nПоиск файлов, к которым производился доступ более чем +nдней назад, менее чем -nдней назад или ровноnдней.
-mtime[+|-]nПоиск файлов, которые были изменены более чем +nдней назад, менее чем -nдней или ровноnдней.
-userloginIDПоиск всех файлов, которые принадлежат пользователю с именемlogin ID.
-typeПоиск по типу файла, например: f(файл) илиd(каталог).
-реrmПоиск файлов, которые имеют соответствующие права доступа.
Табл. 5-3Действия, используемые с командойfind
Действие Описание
-ехес команда [} \;Автоматическое выполнение указанной команды на каждый найденный файл. Множество квадратных скобок и {}разделяют имя файла от команды в выражении. Пробел, обратная косая черта и точка с запятой (\;)отделяют конец команды. Перед знаком обратной косой черты (\) должен стоять пробел.
-okкоманда {} \;Указывает на интерактивную форму-ехес. Это требует ввода перед тем, как командаfindвыполнит команду на файл, во всём остальном функциональность совпадает с действием -ехес.
-printУказывает командеfindвывести имя текущего найденного файла на экран терминала. Используется по умолчанию.
-lsВыводит имя текущего найденного файла вместе со статистикой, такой как номерinode, размер в килобайтах, права доступа, количество жёстких ссылок и информация о владельце.
Следующие примеры показывают возможности команды find.
• Для поиска файлов с именем core, начиная с каталогаroot (/), выполните команду:
$find/ -namecore
• Для поиска файлов с именем core, начиная с вашего домашнего каталога, с удалением всех найденых файлов выполните следующую команду:
$ find — -name core -ехес rm {} \;
• Для поиска всех файлов, начиная с текущего каталога, которые не изменялись за последние 90дней, выполните команду:
$find. -mtime +90
• Для поиска файлов, размер которых больше, чем 57блоков (512-байтовые блоки), начиная с домашнего каталога, выполните команду:
$ find ~ -size +57
• Для поиска файлов, имена которых заканчиваются на символы «tif», начиная с каталога /usr, выполните команду:
$ find /usr -name ‘*tif
Поиск, различий между файлами
В ОС Solarisсуществует несколько утилит, которые позволяют сравнивать два файла и выводить различия, если таковые будут найдены.
Поиск, различий с использованием команды cmp
Используйте команду cmp для сравнения файлов на предмет выявления различий. Эта команда печатает результаты, только если отличия между файлами найдены. Если не выведено никаких результатов, то, значит, файлы одинаковы.
Команда стр делает побайтовое сравнение каждого файла. Если байты в файлах различаются, то тогда команда cmp выводит номер байта и номер строки, где выявлено первое различие, и затем прекращает свою работу
Эта команда работает как с двоичными, так и с ASCIIфайлами.
Формат команды
cmp имя_файла 1 имя_файла2
Использование команды сmp для сравнения файлов, которые кажутся одинаковыми
В этом примере найдено первое несоответствие между двумя файлами. Это различие возникло на 27символе на строке 5.
Поиск текстовых различий с использованием команды di f f
Команда diff -это другая команда, которая используется для поиска различий между файлами.
Результатом выполнения этой команды будет вывод всех строк, где имеются различия между двумя текстовыми файлами с предоставленными вам рекомендациями о том, как отредактировать один файл для того, чтобы сделать его таким же как другой.
Формат команды,
diff-параметр имя_файла имя_файла
В Табл. 5-4показаны параметры, которые могут быть использованы с командой diff.
Табл. 5-4Параметры команды diff
Параметр Описание
-iИгнорирует регистр символов, например, А эквивалентно а.
-с Создаёт контекстный список различий.
Использование команды diff с параметром -с
При использовании команды diffс параметром -с для сравнения файлов результаты будут выводится в виде трёх секций.
Первая секция содержит имена сравниваемых файлов и их даты создания, затем каждое изменение, разделённое линией звёздочек (*).
Вторая секция содержит строки первого файла, которые отличаются от соответствующих строк второго файла. Строки, удалённые из первого файла, помечаются символом ‘-‘.В большинстве случаев три строки, представляющие первое различие, выводятся как контекстная информация.
В третьей секции содержатся строки второго файла, которые отличаются от соответствующих строк первого файла. Эти строки, добавленные во второй файл, помечаются символом ‘+’.Строки, которые перенесены из одного файла в другой, помечены в обоих файлах символом ‘!’.В большинстве случаев три строки, представляющие первое различие, выводятся как контекстная информация.
Ниже приведён пример использования команды diffдля сравнения файлов с параметром -с:
Сортировка данных
Команда sortсортирует текстовые строки в одном или более файлах и выводит результат на экран.
Команда sortпредоставляет быстрый и простой метод организации данных в числовом или алфавитном порядке.
По умолчанию sortиспользует символы пробела и табуляции для разделения различных полей в данных файла.
Формат команды
sort (-/+)параметры имя_файла(ов)
Параметры
Параметры, доступные с командой sort, используются для определения типа сортировки, а также поля, по которым будет производиться сортировка (Табл. 5-5).
Табл. 5-5Параметры, используемые с командойsort
Параметр Описание
-nПроизводит числовую сортировку.
(+ | -)nНачинает (+n) или заканчивает (-n) сортировку поля, следующего за полемп.
-г Меняет порядок сортировки.
-fИгнорирует регистр символов.
-М Сортирует первые три символа поля как сокращение имени месяца.
-dИспользуется словарная сортировка. Сравниваются только буквы, цифры и пробелы, все остальные символы игнорируются.
-о Вывод результатов в файл имя_файла. имя_файла
-bИгнорирует начальные пробелы при определении начальной и конечной позиций ограниченного ключа сортировки.
-tсимволИспользует символ как разделитель полей. Если параметр -tне указан, то по умолчанию в качестве разделителей полей используются символы пробела и табуляции.
Использование команды sort с разными параметрами
На следующих примерах показаны различные пути использования команды sortс разными параметрами:
$cat fileA
Annette 48486
Jamie 48481
Fred 48487
Sondra 48483
Janet 48482
$sort fileA
Annette 48486
Fred 48487
Jamie 48481
Janet 48482
Sondra 48483
$sort +1n fileA
Jamie 48481
Janet 48482
Sondra 48483
Annette 48486
Fred 48487
На первом примере показано содержимое файла fileA,выведенное на экран с помощью командыcat.
Первая команда sortосуществляет сортировку в алфавитном порядке, начиная с первого символа каждой строки.
Далее производится числовая сортировка по второму полю (sortпропускает один разделитель с синтаксисом +1).
Использование команды sort по разным полям в файле
Следующие примеры показывают, как использовать команду sort для сортировки данных по разным полям в файле.
$ ls -l f* > list
$ cat list
-rw-r—r— 1 useri staff 0 Feb 25 12 54 file.l
-rw-r—r— 1 useri staff 0 Feb 25 12 54 Eile.2
-rw-r—r— 1 useri staff 0 Feb 25 12 54 file.3
-rw-r—r— 1 useri staff 1696 Feb 22 14 51 filel
-rw-r—r— 1 useri staff 156 Mar 1 14 48 file2
-rw-r—r— 1 useri staff 218 Feb 22 14 51 file3
-rw-r—r— 1 useri staff 137 Feb 22 14 51 file4
-rw-r—r— 1 useri staff 56 Feb 22 14 51 fruit
-rw-r—r— 1 useri staff 57 Feb 22 14 51 fruit2
$
$ sort -rn +4 list -o num.list
$ cat num.list
-rw-r—r— 1 useri staff 1696 Feb 22 14 51 filel
-rw-r—r— 1 useri staff 218 Feb 22 14 51 file3
-rw-r—r— 1 useri staff 156 Mar 1 14 48 file2
-rw-r—r— 1 useri staff 137 Feb 22 14 51 file4
-rw-r—r— 1 useri staff 57 Feb 22 14 51 fruit2
-rw-r—r— 1 useri staff 56 Feb 22 14 51 fruit
-rw-r—r— 1 useri staff 0 Feb 25 12 54 file.3
-rw-r—r— 1 useri staff 0 Feb 25 12 54 file.2
-rw-r—r— 1 useri staff 0 Feb 25 12 54 file.l
$
$ sort +5M +6n list -o update.list
$ cat update.list
-rw-r—r— 1 useri staff 56 Feb 22 14 51 fruit
-rw-r—r— 1 useri staff 57 Feb 22 14 51 fruit2
-rw-r—r— 1 useri staff 137 Feb 22 14 51 file4
-rw-r—r— 1 useri staff 218 Feb 22 14 51 file3
-rw-r—r— 1 useri staff 1696 Feb 22 14 51 filel
-rw-r—r— 1 useri staff 0 Feb 25 12 54 file.l
-rw-r—r— 1 useri staff 0 Feb 25 12 54 file.2
-rw-r—r— 1 useri staff 0 Feb 25 12 54 file.3
-rw-r—r— 1 useri staff 156 Mar 1 14 48 file2 S
В первом примере вывод команды Is записывается в файл list. Содержимое этого файла выводится на экран с помощью команды cat.
Первая команда sort выполняет обратную числовую сортировку по пятому полю и записывает результат в файл num. list.
Во втором примере команда sort выполняет многоуровневую сортировку по полям 6 и 7 в файле list.
• Параметр +5M задаёт алфавитную сортировку по месяцу в шестом поле.
• Параметр +6n задаёт цифровую сортировку второго уровня по дням в седьмом поле.
• Параметр -о помещает результат в файл update, list.
Поиск, текста в файлах
ОС Solarisпредоставляет множество команд, используемых для поиска в содержимом одного или нескольких файлов заданного символьного шаблона. Шаблон может быть одним символом, строкой, словом или предложением.
По определению, символьный шаблон, используемый при поиске для сравнения одинаковых символов называется регулярным выражением (RE).
• Команда grер осуществляет глобальный поиск регулярных выражений в файлах и выводит все строки, содержащие регулярное выражение, на стандартное устройство вывода.
Замечание -Название командыgrер происходит из текстового редактораUNIX, который использует последовательность командg/re/p, которая означаетglobal/regularexpression/print.
• Команды egrepиfgrepявляются вариантамиgrер; еgrер использует расширенные регулярные выражения, а fgrep,в отличие от регулярных выражений использует фиксированные строки.
Использование команды grер
Команда grер осуществляет поиск в содержимом одного или нескольких файлов на предмет сравнения с регулярным выражением или символьным шаблоном. Если совпадение будет найдено, тоgrер выведет на экран каждую строчку, содержащую совпадение, изменение самого файла при этом не производится.
Формат команды
grерпараметр(ы) шаблон имя_файла(ов)
Параметры
Команда grер предоставляет большое количество параметров для изменения способа поиска или вывода результатов.
Некоторые часто используемые параметры описаны в Табл. 5-6.
Табл. 5-6Параметры командыgrер
Параметр Описание
-iЗадаёт режим игнорирования регистра, символы верхнего и нижнего регистров считаются идентичными.
-1Перечисляет только имена файлов, которые содержат найденные строки.
-nЗадаёт простановку относительного номера к каждой строке в файле.
-vМеняет условия поиска на обратные для выдачи только тех строк, которые не соответствуют шаблону
-с Задаёт вывод только количества строк, которые содержат шаблон.
-wЗадаёт поиск выражения как слова.
Примеры поиска с использованием регулярных выражений в команде grер
Далее представлены примеры использования команды grер по поиску с применением регулярных выражений:
• Для поиска всех строк, которые содержат «root», в файле /etc/group, выполните следующую команду:
$ gгер -п root /etc/group
1:root :0:root
3:bin: 2:root,bin,daemon
4:sys: 3:root,bin,sys,adm
5:adm: 4:root,adm,daemon
6:uucp :5:root,uucp
7:mail :6:root
8:tty: 7:root,tty,adm
9:Ip::8:root,Ip,adm
10:nuucp::9:root,nuucp
12 :daemon: : 12 :root,daemon
$
• Для поиска всех строк, которые не содержат «root», в файле /etc/group,выполните следующее:
$ grep -v root /etc/group
other::1:
staff::10:
sysadmin::14:
nobody::60001:
noaccess::60002:
nogroup::65534:
$
• Для поиска только тех файлов, которые содержат «root», выполните следующее:
$ cd /etc $ grep -l root group passwd hosts
group
passwd
$
Замечание— При поиске в нескольких файлах, в результатах поиска имя файла будет выводиться в каждой строке, где найдена искомая комбинация символов. При поиске только в одном файле выводиться будут только результаты.
• Для поиска «the» во всех файлах каталога /etcс выводом только имён файлов, где есть строки, содержащие «the» или «The», выполните следующее:
$ cd /etc
$ grep -li the *
aliases
asppp.сf
dacf.conf
device.tab
devlink.tab
dgroup.tab
fmthard
format
<output omitted>
syslog.conf
system
termcap
TIMEZONE
ttysrch
umountall
$
• Для поиска «root» в файле /etc/groupс выводом только количества строк, содержащих это слово, выполните следующую команду:
$ grep-с root group
10
$
• Для поиска «mar 1″в выводе командыls-laвыполните следующее:
$ Is -la I grep -i ‘mar 1′
drw——- i root root 0 Mar 1 11:05 initpipe
-r—r—r— 1 root root 806 Mar 1 13:39 mnttab
prw——- 1 root root 0 Mar 1 11:06 utmppipe
$
Если дата выражена одной цифрой, то ключ для команды grep должен иметь два пробела между месяцем и днём, например:
Маг 1.
Метасимволы регулярных выражений
Команда grep поддерживает несколько метасимволов в регулярных выражениях для определения шаблона. В Табл. 5-7содержится описание некоторых часто используемых метасимволов.
Табл. 5-7Метасимволы в регулярных выражениях
Метасимвол Значение Пример Результат
Знак начала ‘»pattern’ Выбор всех строк, строки начинающихся с
«pattern
$ Знак конца‘pattern$’ Выбор всех строк,
строки заканчивающихся на
pattern
Обозначает ‘р.. …п’ Выбор строк, один любой содержащих символ ‘р’ символ и через пять символов следующий за ним символ ‘п’
*Соответствует ‘[a-z]*’ Выбор алфавитных любому символов нижнего количеству регистра символов
Табл.a-mJattern’ Выбор строк, не
одному содержащих символы в символу не в диапазоне от ‘а’ до «т» диапазоне и следующих перед поиска «attern»
Примеры
Далее представлены примеры использования метасимволов в регулярных выражениях.
• Для вывода на экран всех строк файла /etc/passwd, начинающихся с «root», выполните следующую команду:
$grep‘»roof/etc/passwd
• Для вывода всех строк из файла /etc/passwdсодержащих символ ‘А’, следующие за ним три любых символа и заканчивающихся символом ‘п’, выполните следующую команду:
$ grep’А…п’ /etc/passwd
• Для вывода всех строк, которые оканчиваются на «adm» в файле /etc/group, выполните следующую команду:
$grep’adm$’ /etc/group
Использование команды egrep
Команда egrepосуществляет поиск в содержимом одного или нескольких файлов заданного шаблона с использованием расширенного набора метасимволов в регулярных выражениях.
Команда egrepиспользует несколько новых метасимволов регулярных выражений в добавление ко всем метасимволам, используемым с командой grep.
Формат команды
egrep [-параметры ] шаблон имя_файла …
Примеры использования команды egrep
В следующих примерах показаны различные способы использования команды egrep:
• Для поиска всех строк, содержащих символ «N» и следующие за ним символы ‘е’ или ‘о’ один или несколько раз, выполните следующую команду:
$ egrep ‘N(elo)+’ /etc/passwd
listen:x:37:4:Network Admin:/usr/net/nls:
nobody:х:60001:60001:Nobody:/:
noaccess.’x: 60002: 60002 :No Access User:/:
• Для поиска строк, содержащих «NetworkAdmin» или «uucpAdmin», выполните следующую команду:
$ egrep ‘(Network!uucp) Admin’ /etc/passwd
uucp:x:5:5:uucp Admin :/usr/lib/uucp:
nuucp:x:9:9:uucp Admin:/var/spool/uucppublic:/usr/lib/uucp/uucico listen:x:37:4:Network Admin:/usr/net/nls:
Использование команды fgrep
Команда fgrepосуществляет поиск в файле ключевого выражения как фиксированной строки. Её работа отличается от работыgrepиegrep, т.к. она обрабатывает все символы и любые метасимволы регулярных выражений, указанные в командной строке, как обычные символы. Для этой команды специальное значение имеют только два символа: знак вопроса (?)и знак доллара ($).
Используйте команду fgrepдля поиска словосочетаний в файлах, содержащих метасимволы.
Формат команды
fgrepпараметр(ы) шаблон имя_файла(ов)
Пример использования fgrep
Для поиска всех строк в файле, содержащих строку текста и символы, с помощью команды fgrepвыполните следующее:
$ fgrep ‘*’ /etc/system
Права доступа к файлам и каталогам
Обзор системы безопасности
Самая важная функция системы безопасности -это возможность запрещать доступ неавторизованным пользователям и управлять доступом авторизованных пользователей. Управление системой безопасности -это одна из главных задач системного администратора, но она также накладывает ответственность на пользователей.
ОС Solarisпредоставляет два базовых способа предотвращения неавторизованного доступа к системе и защиты её данных.
Первый способ основывается на идентификации пользователя при входе его в систему, проверяя его идентификатор входа (имя пользователя) и пароль на существование в файлах /etc/passwdи /etc/shadowсоответственно.
Второй способ -это автоматическая защита файлов и каталогов путём определения доступа к ним через набор стандартных прав доступа, определяемых при создании файлов и каталогов.
Замечание —ОСSolarisтакже предоставляет специальную учётную запись в каждой системе, называемуюroot. Пользовательroot, часто именуемый каксуперпользователь,имеет полный доступ к любой учётной записи и всем файлам и каталогам, ей принадлежащим. Пользовательrootможет изменять права доступа, наложенные на файлы и каталоги.
Просмотр прав доступа на файлы и каталоги
Просмотреть информацию о правах доступа на файлы и каталоги можно с помощью команды ls -1.
Первое информационное поле, выводимое этой командой, -это тип файла, далее следуют три класса пользователей и их права доступа.
• Тип файла —Обозначает, что элемент представляет файл или каталог.
• Пользователь (owner) — Содержит список прав доступа для владельца.
• Группа (group) — Содержит список прав доступа для группы пользователей.
• Другие (other) — Содержит список прав доступа для всех остальных пользователей.
Рис. 6-1иллюстрирует права доступа для каждого класса пользователей.
Рис. 6-1Права доступа для каждого класса пользователей
Категории прав доступа
В следующих разделах описаны категории прав доступа.
Тип файла
Первый символ в списке, выводимом командой ls -1,определяеттип файла.
Каталог представлен символом d. Обычный файл представлен дефисом (-).
Знак дефиса или тире (-),находящийся где-либо во множестве прав доступа, обозначает, что соответствующее право доступа отсутствует.
Права доступа владельца
Следующие три символа являются правами доступа владельца.Они обозначают, какой тип доступа имеет владелец на файл. На Рис. 6-1 на странице 6-4user, владелец этого файла, имеет на него права доступа на запись и чтение.
Группа
Второе множество -это три символа, образующиеправа доступа для группы.Они обозначают права доступа, которые даны или нет каждому пользователю, который входит в группу, которой принадлежит этот файл.
Группа -это множество пользователей, которым нужен доступ к одним и тем же файлам. Все пользователи в группе имеют доступ к файлам друг друга с правами доступа группы к этим файлам.
Системный администратор может создавать и управлять группами в файле /etc/groupи добавлять пользователей в группы в соответствии с доступом к разделяемым файлам.
На Рис. 6-1на странице 6-4файл принадлежит группеstaff, и все пользователи, которые входят в эту группу, имеют права доступа на чтение этого файла.
Остальные
Третье множество -это три символа, обозначающиеправа доступа для других пользователей,или для всех остальных.
Другие —это любой пользователь, который не являетсявладельцем файла и не входит в группу, которая является владельцем этого файла, но этот пользователь имеет доступ к системе. На Рис. 6-1на странице 6-4другие пользователи имеют права только на чтение файла.
Определение доступа к файлу или каталогу
Доступ к файлу или каталогу определяется идентификационным номером пользователя (UID)и идентификационным номером группы (GID).
• UID— определяет пользователя, который создал каталог или файл.
• GID— определяет группу пользователей, которая владеет
каталогом или файлом. Файл или каталог может принадлежать только одной группе в данное время.
Все файлы и каталоги содержат номер UIDи GID.ОСSolarisиспользует эти номера для выявления принадлежности файла или каталога тому или иному пользователю или группе.
Для просмотра этих номеров UIDи GIDиспользуйте командуls -n:
$ Is -n total 108
-rw-r—r— 1 11001 10 0 Feb 22 14:51 brands
-rw-r—r— I 11001 10 1320 Feb 22 14:51 dante
-rw-r—r— 1 11001 10 368 Feb 22 14:51 dante_l
Процесс определения прав доступа
Когда пользователь пытается получить доступ к файлу или каталогу, ОС Solarisсравнивает его номер UIDс номером UIDтого файла или каталога, к которому пользователь пытается получить доступ (Рис. 6-2на странице 6-8).
Если два числа равны, тогда используются права доступа владельца для определения типа доступа к этому файлу или каталогу.
Если номера UIDне равны, тогда GIDпользователя сравнивается сGIDфайла или каталога. Если эти номера совпадают, то применяются права доступа для группы.
Если GIDне совпадают, то используются права доступа, определённые дляостальныхпользователей.
Рис. 6-2Процесс определения прав доступа
Типы прав доступа
Доступ к файлу или каталогу защищён стандартным набором прав доступа, который автоматически назначается ОС Solarisпри создании файла или каталога.
Права доступа определяют, кто и что может делать с файлом и каталогом и представлены символами г (чтение), w(запись), х (выполнение) и -(нет права).
Когда пользователь создаёт новый файл или каталог, ОС Solarisавтоматически присваивает файлу права доступаrw-rw-rw- и каталогуrwxrwxrwx.
Замечание —Права на выполнение пользователь может дать файлам с помощью командыchmod, но эти права не даются файлу по умолчанию при его создании.
Права доступа чтение/запись/выполнение интерпретируются по разному в случае обычного файла и каталога. В Табл. 6-1описаны эти различия.
Табл. 6-1Права доступа и соответствующие символы
Право доступа | Символ права доступа | Файл | Каталог |
Чтение | r | Файл можно вывести на экран или скопировать | Содержимое можно вывести на экран с помощью ls |
Запись | w | Содержимое файла можно изменить | Если пользователь также имеет доступ на выполнение, файлы можно создавать или удалять |
Выполнение | x | Файл можно выполнить (только для скриптов командного интерпретатора или исполняемых файлов) | Пользователь может выполнять команду cdдля доступа к каталогу. Если пользователь также имеет доступ на чтение, то он может выполнять и командуlsна этот каталог. |
Замечание —Для каталога, в общем случае, вы должны устанавливать права доступа на чтение и выполнение.
Далее представлены примеры использования различных прав доступа на файлы и каталоги.
• Этот файл имеет права доступа чтение/запись/выполнение только для его владельца. Для всех остальных групп и пользователей доступ запрещён:
—rwx——
• Этот каталог имеет права чтение/выполнение только для владельца каталога и группы:
dr—xr—x—
• Этот файл имеет права чтение/запись/выполнение для его владельца и чтение/выполнение для группы и всех остальных пользователей:
-rwxr-xr-x
Изменение прав доступа
Вы можете изменить права доступа, установленные на вновь созданные файлы или каталоги, используя команду chmod. Только владелец этого файла или каталога, а также пользовательrootмогут использовать эту команду для изменения прав доступа.
Команда chmodможет изменять права доступа, указанные как с использованиемсимволической записи,так ивосьмеричной.
• При символической записи используется комбинация знаков и символов для добавления, удаления или установки прав доступа для каждого класса пользователей.
• При восьмеричной записи используются цифры,
представляющие каждое право и часто называется абсолютным режимом.
На Рис. 6-3на странице 6-12показаны взаимосвязи между правами доступа и файлами.
Рис. 6-3Символическая запись формата команды
Изменение прав доступа, используя символическую запись
Далее представлены примеры, показывающие, как изменять права доступа на файлы и каталоги, используя символическую запись.
• Изъятие прав на чтение у «других» пользователей:
$ ls -l dante
-rw-r—r— 1 useri staff 1320 Feb 22 14:51 dante $ chmod o-r dante $ la -1 dante
-rw-r—— 1 useri staff 1320 Peb 22 14:51 dante $
• Изъятие права на чтение у группы:
$ chmod g-r dante $ Is -I dante
-rw——- 1 useri staff 1320 Feb 22 14:51 dante
$
• Добавление прав на выполнение для владельца и на чтение группе и остальным пользователям:
$ chmod u+x,go+r dante $ la -I dante
-rwxr—r— 1 useri staff 1320 Feb 22 14:51 dante $
• Присвоение прав на чтение и запись для владельца, группы и «другим»:
$ chmod a=rw dante $ Is -I dante
-rw-rw-rw- 1 useri staff 1320 Feb 22 14:51 dante $
Восьмеричная (абсолютная)
Вы также можете задавать права доступа, используя комбинацию восьмеричных цифр. Используемые цифры -от 0до 7.
Формат команды
chmodвосьмеричные_цифры иыя_файла
Каждое право доступа представлено своим восьмеричным числом (Табл. 6-2).
Табл. 6-2Соответствие восьмеричных цифр правам доступа
Восьмеричное число Право доступа
4Чтение
2Запись
1Выполнение
Каждая восьмеричная цифра представляет множество прав, как это показано в Табл. 6-3.
Табл. 6-3Соответствие восьмеричных цифр множествам прав доступа
Восьмеричная цифра Множество прав доступа
7 r w x
6 r w –
5 r — x
4 r — —
3 — w x
2 — w –
1 — — x
О — — —
Комбинируя восьмеричные цифры, пользователь может быстро изменить права доступа для каждого класса пользователей. Первая восьмеричная цифра определяет права доступа владельца,вторая —права доступа группыи третья определяетправа доступа для остальных пользователей(Табл. 6-4/
Табл. 6-4Комбинированные значения и права доступа
Восьмеричные числа Права доступа
644rw-r—r—
751rwxr-x—x
775rwxrwxr-x
777rwxrwxrwx
При использовании восьмеричной записи chmodавтоматически заполнит все недостающие слева цифры нулями.
Изменение прав доступа с использованием восьмеричной записи
На следующих примерах показано, как изменять права доступа на файлы и каталоги, используя восьмеричную (абсолютную) запись.
Замечание —Каждый пример основывается на результатах предыдущих команд.
• Добавление владельцу, группе и другим права доступа только на чтение и выполнение:
$ Is -l dante
-rw-rw-rw- 1 useri staff 1320 Feb 22 14:51 dante
$ chmod 555 dante
$ ls -1 dante
-r-xr-xr-x 1 useri staff 1320 Feb 22 14:51 dante
$
• Изменение прав доступа владельца и группы и добавление доступа на запись:
$ chmod 775 dante
$ ls -I dante
-rwxrwxr-x 1 useri staff 1320 Feb 22 14:51 dante
$
• Добавление прав доступа группы только на чтение и выполнение:
$ chmod 755 dante
$ ls -l dante
-rwxr-xr-x 1 useri staff 1320 Feb 22 14:51 dante
$
Права доступа по умолчанию
В следующих разделах описываются различные типы прав доступа по умолчанию.
Фильтр umask
Фильтр umaskуправляет правами доступа, назначенными вновь созданным файлам и каталогам. Фильтрumask- это трёхзначное восьмеричное число, которое определяет права на чтение/запись/выполнение для владельца, группы и всех остальных.
Вывод umask
$umask
022 $
В ОС Solarisзначениеumaskпо умолчанию — 022.
Команда umaskработает как фильтр, накладывая начальные значения прав доступа, указанные системой при создании файла или каталога.
Первая цифра определяет права доступа по умолчанию для владельца, вторая -для группы и третья цифра -для остальных.
Начальные значения прав доступа по умолчанию, назначаемые системой при создании файла, — 666(rw-rw-rw-).
Начальные значения прав доступа по умолчанию, назначаемые системой при создании каталога, — 777(rwxrwxrwx).
Значение umaskавтоматически фильтруется или рассчитывается от начального значения прав доступа для определения прав доступа, по умолчанию назначаемых вновь созданным файлам и каталогам.
Алгоритм работы фильтра umask
Другой путь для определения, какие права доступа по умолчанию будут у вновь созданных файлов — это взять начальные значения определённые системой, которые представлены в символической записи:
rw-rw-rw-
Эти права, дающие доступна чтение-запись владельцу, группе и остальным пользователям в восьмеричной записи, выглядят следующим образом:
42-42-42-
Используйте значение umaskпо умолчанию 022,которое изымает (или запрещает) права на запись для группы и остальных пользователей.
Например:
rw-rw-rw-Начальные значения, определённые системой для нового файла.
—-w—w- Фильтрumaskпо умолчанию для вычитания.
rw-r—r— Права доступа по умолчанию, назначаемые вновь созданным файлам.
Когда отказ в правах доступа замаскирован в начальном значении, права доступа, присваиваемые вновь созданным каталогам, остаются.
Всем вновь созданным файлам присваивается доступ на чтение-запись для владельца и доступ на чтение для группы и остальных пользователей:
rw-r—r—
Вы можете применить такой же процесс при определении того, какие права доступа по умолчанию будут у вновь созданных каталогов.
В этом случае возьмите начальное значение, определённое системой и представленное в символической записи, как:
rwxrwxrwx
Оно соответствует правам доступа чтение/запись/выполнение для пользователя, группы, остальных и представлена в восьмеричном виде как:
Глава 2. Понятия и обзор LDAP
Если Вы уже понимаете, что из себя представляет LDAP, для каких целей он подходит, что такое схемы данных, объектные классы, атрибуты, правила соответствия, операционные объекты и вся эта кухня — можете пропустить этот раздел. Однако, если Вы собираетесь делать нечто большее, чем вслепую следовать рецептам HOWTO, Вы должны понимать все эти вещи.
LDAP и X.500 имеют много общих терминов, некоторые из них важны, некоторые — просто ерунда. Для Вашего удобства мы создали глоссарий. Термины в него включены либо потому, что они важны, либо потому, что они часто используются в литературе.
2.1 Краткая история LDAP
2.2 Обзор LDAP
2.3 LDAP и базы данных
2.3.1 Использование LDAP — резюме
2.4 Модель данных (объектная модель) LDAP
2.4.1 Структура дерева объектов
2.4.2 Объектные классы
2.4.3 Атрибуты
2.4.4 Описание дерева путём добавление записей (данных)
2.4.5 Навигация по дереву
2.5 Отсылки и репликация LDAP
2.5.1 Отсылки
2.5.2 Репликация
Небольшое замечание о чувствительности к регистру в LDAP: здесь есть некоторая путаница, по крайней мере, мы считаем это путаницей. По правде говоря, путаниц тут хватает на каждом шагу. Единственные чувствительные к регистру вещи в LDAP — это пароли и содержимое отдельных (очень малоизвестных) атрибутов, в зависимости от их правил соответствия. Всё. В этой и других документациях Вы будете встречать и objectclass, и objectClass, и даже ObjectClass. Все эти формы работают. Точка. После первых шести лет изучения LDAP (шутка, конечно, хватит и четырёх) Вы уже не будете хвататься за сердце всякий раз, когда Вам доведётся опечататься в каком-нибудь имени. Итак, использование «верблюжьей» нотации — это, возможно, и неплохая практика, но даже если Вы где-то ошибётесь, солнце не упадёт на землю.
О букве D в LDAP: официально буква D в аббревиатуре LDAP означает Directory (каталог) — Lightweight Directory Access Protocol. Связано это главным образом с историческими истоками LDAP (и его предшественника DAP), которые были ориентированы на взаимодействие с классическими приложениями для работы с каталогом адресов электронной почты типа «белые страницы». Однако, любая терминология в конечном итоге может начать загонять саму себя и тех, кто ею пользуется, в какие-то рамки. Не заблуждайтесь, рассуждая о LDAP, мы говорим о доступе к данным, и если термин Directory ограничивает Ваше мышление из-за существующих ментальных моделей каталогов (наше уж точно ограничивает, хотя, возможно, мы просто сами по себе умственно ограничены), то, размышляя о LDAP, просто мысленно заменяйте его термином Data (данные), и получится Lightweight Data Access Protocol. Только никому не говорите, а то прослывёте вероотступником.
2.1 Краткая история LDAP
Когда-то в тёмном и далёком прошлом (конец 70-х — начало 80-х) ITU (International Telecommunication Union) начал работу над почтовыми стандартами серии X.400. Для этого стандарта требовался каталог имён (и другой информации), который мог бы быть доступен по сети в иерархической манере, схожей с DNS (для тех из Вас, кто знаком с её архитектурой).
Эта потребность в глобальном сетевом каталоге сподвигла ITU к разработке стандартов серии X.500 и, в частности X.519, которые определяют DAP (Directory Access Protocol), протокол для доступа к сетевой службе каталогов.
Серии стандартов X.400 и X.500 разрабатывались как составная часть полного стека OSI и были большими, громоздкими и потребляли много ресурсов. Фактически, стандартная ситуация для ITU.
Перенесёмся в начало 90-х. IETF осознала необходимость доступа к глобальным службам каталогов (первоначально, во многом, по тем же самым причинам хранения адресов электронной почты, что и ITU), но не поднимая при этом всех этих ужасных перенагруженных протоколов (OSI), и начала работу над Lightweight Directory Access Protocol (LDAP). LDAP разрабатывался так, чтобы обеспечить почти столько же функциональности, что и оригинальный стандарт X.519, но с использованием стека протоколов TCP/IP, при этом оставляя возможность взаимодействия с каталогами, основанными на X.500. Действительно, взаимодействие с X.500 (DAP) и его отображение всё ещё является частью серии RFC о LDAP от IETF.
Большинство вопросов в спецификациях LDAP, вызывающих серьёзную головную боль, как раз связаны с обратной совместимостью с X.500 и концепцией глобальной службы каталогов. Самый показательный из них — соглашение об именовании корневой записи.
В широком смысле, LDAP отличается от DAP в следующих аспектах:
- В LDAP используется TCP/IP — DAP использует OSI в качестве транспортного/сетевого слоёв.
- Некоторое сокращение функциональности — неясные, дублирующиеся и редко используемые функции X.519 (конёк ITU) тихо и благополучно отброшены.
- Замена в LDAP некоторых из ASN.1-нотаций (X.519) текстовым представлением (LDAP URL и поисковые фильтры). В этом вопросе IETF не снискала нашей безграничной благодарности: значительное большинство ASN.1-нотаций всё ещё остаются в прежнем виде.
2.2 Обзор LDAP
Технически, LDAP — это всего лишь протокол, определяющий методы, посредством которых осуществляется доступ к данным каталога. Он также определяет и описывает, как данные представлены в службе каталогов (Модель данных или Информационная модель). Наконец, он определяет, каким образом данные загружаются (импортируются) и выгружаются (экспортируются) из службы каталогов (с использованием LDIF). LDAP не определяет, как происходит хранение и манипулирование данными. С точки зрения стандарта хранилище данных и методы доступа к нему — это «чёрный ящик», за который, как правило, отвечают модули back-end (механизмы манипуляции данными) какой-либо конкретной реализации LDAP (обычно в них используется некоторая форма транзакционной базы данных).
LDAP определяет четыре модели, которые мы перечислим и кратко обсудим, а затем Вы можете спокойно забыть о них, поскольку для понимания LDAP они мало что дают.
Информационная модель: мы склонны использовать термин модель данных, на наш взгляд он более интуитивный и понятный. Модель данных (или информационная модель) определяет, каким образом информация или данные представлены в системе LDAP. Это может совпадать или не совпадать с фактическим методом представления данных в хранилище на физическом носителе. Как упоминалось выше, вопрос хранилищ данных лежит за пределами стандартов LDAP.
Модель именования: определяет все вещи наподобие ‘dc=example,dc=com’, с которыми Вы сталкиваетесь в системах LDAP. Здесь мы максимально придерживаемся спецификации, поскольку эти термины используются очень широко.
Функциональная модель: при чтении, поиске, записи или модификации LDAP Вы используете функциональную модель — кто бы мог подумать!
Модель безопасности: Вы можете контролировать, причём весьма детально, кто, что и с какими именно данными может сделать. Это сложная, но мощная штука. Мы постепенно внедрялись в данную концепцию и посвятили ей отдельную главу. На начальном этапе можно забыть о безопасности. Вы всегда можете вернуться и модернизировать безопасность в LDAP. Если модернизация впоследствии будет невозможна, мы будем описывать реализацию безопасности по тексту. Эта модель также включает в себя защиту данных при передаче по сети, такую как TLS/SSL. Хорошая, но на редкость сложная штука.
Сфера стандартов LDAP показана на диаграмме ниже. Обозначенные красным вещи (1, 2, 3, 4) определены в протоколе (различных RFC, определяющих LDAP). Происходящее же в «чёрных ящиках» (или, в данном случае, в зелёных, жёлтых и сиреневых ящиках), а также показанное чёрной стрелкой обращение к базам данных (5) выходит за рамки стандартов.
Каждый компонент кратко описан здесь, немного подробнее ниже и в мельчайших деталях в последующих главах. Но для начала четыре важных момента:
LDAP не определяет, каким образом данные хранятся, только каким образом к ним осуществляется доступ. НО большинство реализаций LDAP используют стандартные базы данных в качестве механизмов манипуляции данными, и лишь OpenLDAP предлагает выбор поддерживаемых механизмов манипуляции данными.
Когда Вы общаетесь с сервером LDAP, Вы понятия не имеете, откуда поступают данные: на самом деле одна из ключевых задач стандарта — скрывать такой уровень детализации. Теоретически, данные могут поступать из одной ИЛИ НЕСКОЛЬКИХ локальных баз данных, либо одной или нескольких служб X.500 (в наши дни это большая редкость). Откуда и каким образом Вы будете получать данные — это детали реализации, они важны только на этапе определения рабочей конфигурации Вашего LDAP-сервера (серверов).
Две концепции, — доступ к службе LDAP и эксплуатация службы LDAP, — должны быть чётко разделены в Вашем сознании. Когда Вы проектируете каталог, сконцентрируйтесь на том, чего Вы хотите от него добиться, для чего он будет предназначен (организация данных) и не думайте о реализации. Затем, во второй фазе, во время составления рабочей конфигурации LDAP, сконцентрируйтесь на том, где данные будут располагаться, какие будут применяться системы хранения.
Ряд коммерческих продуктов баз данных предоставляет LDAP-представление (LDAP-обёртку или LDAP-абстракцию) реляционной базы данных или базы данных другого типа.
2.3 LDAP и базы данных
LDAP характеризуется как сервис «один раз записал — много раз прочитал». Другими словами, от данных, обычно хранящихся в каталоге LDAP, не ожидается, чтобы они менялись при каждом доступе. Для иллюстрации: LDAP не подходит для ведения учета банковских операций, так как они, по своей природе, изменяются почти при каждом доступе (бизнес-транзакции). С другой стороны, LDAP как нельзя лучше подходит для учёта различных аспектов деятельности банка, меняющихся значительно реже: списка отделений, часов работы, сотрудников и т.д.
Оптимизация на чтение
Во фразе «один раз записал — много раз прочитал» до конца не ясно, насколько много это много?
Где проходит грань разумного использования между LDAP и классическими, ориентированными на транзакции реляционными базами данных, к примеру, SQLite, MySQL, PostGreSQL? Если обновление происходит при каждом втором доступе, будет ли разумно использовать в таком приложении LDAP, или нужно, чтобы обновления происходили раз в тысячу или в миллион обращений?
Литература по этой теме крайне редка и имеет тенденцию придерживаться таких беспроигрышных LDAP-приложений, как адресные книги, которые изменяются, возможно, раз в столетие.
Простого ответа на этот вопрос нет, однако следующие замечания могут оказаться полезными:
Увеличение нагрузки при операциях записи происходит из-за обновления индексов. Чем больше индексов (для ускорения поиска), тем, по возможности, реже должны выполняться обновления каталога. Соотношение чтение:запись в хорошо оптимизированных на чтение каталогах должно быть 1000:1 и даже больше. Для умеренно оптимизированных каталогов (2-3 индекса) разумным будет соотношение 500:1 и выше.
Репликация LDAP генерирует несколько транзакций для каждого обновления, таким образом, желательно снизить практическую нагрузку, связанную с обновлениями (следует ориентироваться на соотношение чтение:запись 500:1 или выше).
Если объём данных велик (скажем, больше 100 000 записей), то даже при небольшом количестве индексов время обновления может быть значительным. Поэтому желательно снизить количество обновлений до минимально возможного (10 000:1 или выше).
Если объём данных относительно невелик (скажем, меньше 1000 записей, чего обычно хватает для большинства стандартных применений каталогов LDAP), индексов немного (не более 2-3) и отсутствует репликация, мы не видим рационального объяснения, почему Вы не можете использовать LDAP в форме, приближенной к транзакционной системе, то есть соотношение чтение:запись 5:1 или 10:1. При добавлении репликации более подходящим будет соотношение 50:1 или 100:1.
Мы полагаем, что настоящий ответ на этот вопрос (с уважением к памяти ушедшего от нас Douglas Noel Adams): оптимальное соотношение количества чтений к количеству записей составляет 42!
Представление организации данных
Применяемые для доступа к каталогам LDAP примитивы (элементы протокола LDAP) используют модель данных, которая (возможно) абстрагирована от её физической организации. Эти примитивы обеспечивают представление данных в виде объектной модели и не заботятся об актуальной структуре данных. В действительности, относительная простота LDAP происходит именно от этой характеристики. Конкретная реализация сервера LDAP будет выполнять отображение примитивов LDAP в физическую организацию данных, используя свой механизм манипуляции данными как «чёрный ящик» в чистом виде.
В этом резкий контраст со, скажем, SQL, поскольку в SQL-запросах, используемых для получения данных, присутствует полное и детальное представление структур данных, их организация в таблицы, объединения, наличие первичных ключей и т.д.
Синхронизация и репликация данных
Реляционные и транзакционные базы данных идут на крайние меры для обеспечения целостности данных во время циклов записи/обновления, используя такие техники, как транзакции, блокировки, откаты и другие методы. Для такого типа технологий баз данных это жизненно важные и необходимые требования. Данная экстремальная форма синхронизации данных также действует при репликации данных на несколько хостов или серверов. Все представления данных постоянно будут соответствовать друг другу.
Главный LDAP-сервер и подчинённые ему серверы (или равноправные ему серверы в среде с несколькими главными серверами (multi-master)) используют простой асинхронный процесс репликации данных. В связи с этим во время цикла репликации возможна рассинхронизация данных в главной и подчинённой (или равноправной) системах. Во время этого (обычно очень короткого) периода времени запрос к главному и подчинённому серверам может дать разные результаты. Если вследствие такого расхождения мир с треском расколется пополам, значит для подобного приложения LDAP не подойдёт. Если же Bob Smith на несколько секунд (или даже меньше) будет числиться в бухгалтерии на одном LDAP-сервере, а на другом — в отделе продаж, вряд ли это кого-то сильно огорчит. В эту категорию попадает удивительно большое количество приложений.
Примечание: Современные реализации LDAP, особенно те, которые поддерживают конфигурации с несколькими главными серверами (Multi-master), становятся всё более изощренными в репликации обновлений. Кроме того, высокоскоростные сети связи позволяют значительно быстрее выполнять операции репликации. Однако, подобные решения всего лишь уменьшают промежуток времени, в течение которого две какие-либо системы будут рассинхронизированы, они не устраняют саму природную особенность LDAP, заключающуюся в возникновении рассинхронизации, даже если в большинстве современных реализаций таковая длится всего лишь доли секунды.
2.3.1 Использование LDAP — резюме
Так в чём же преимущества LDAP (каталогов), и почему каждый здравомыслящий человек будет их использовать?
Прежде чем попытаться ответить на этот вопрос, давайте абстрагируемся от тактических соображений производительности. В целом, реляционные СУБД всё ещё значительно быстрее реализаций LDAP. По мере разработки служб каталогов второго поколения это положение меняется, и, хотя реляционные СУБД всегда будут оставаться быстрее LDAP, разрыв значительно сократился вплоть до точки, в которой различия становятся уже практически несущественными, если, конечно, Вы сравниваете подобное с подобным (единичные сетевые транзакции, а не обновление высокоиндексированного атрибута при каждой операции — в этом случае, не обессудьте, Вы получите (или не получите) ровно столько, сколько заслужили).
Так почему же нужно использовать LDAP? Вот наш список ключевых характеристик, которые делают высокий (всё ещё) уровень боли терпимым:
LDAP предоставляет стандартизированные как удалённый, так и локальный методы доступа к данным. Таким образом, вполне реально заменить одну реализацию LDAP на другую, совершенно не влияя на внешний интерфейс доступа к данным. Реляционные СУБД в основном реализуют стандарты локального доступа, такие как SQL, но удалённые интерфейсы всегда остаются проприетарными.
Поскольку в LDAP используются стандартизированные методы доступа к данным, клиенты и серверы LDAP могут разрабатываться отдельно или быть получены из разных источников. В продолжении этой темы, LDAP может быть использован для абстрактного представления данных, содержащихся в ориентированных на транзакции базах данных, скажем, для выполнения пользовательских запросов, позволяя пользователям прозрачно (для LDAP-запросов) обращаться к разным поставщикам транзакционных баз данных.
LDAP предоставляет метод, посредством которого данные могут быть перемещены (делегированы) в несколько мест, не затрагивая при этом внешнего доступа к этим данным. Используя метод отсылок LDAP, данные могут быть перемещены на альтернативные LDAP-серверы путём только изменения операционных параметров. Таким образом, можно построить распределенные системы, возможно, с данными, поступающими из отдельных автономных организаций, обеспечивая при этом для своих пользователей единое, последовательное представление этих данных.
Системы LDAP могут быть настроены на репликацию данных на один или несколько серверов LDAP или одному или нескольким приложениям только за счет операционных параметров, без необходимости добавления дополнительного кода или изменения внешнего доступа к данным.
Эти характеристики концентрируют внимание исключительно на стандартной природе доступа к данным LDAP, не учитывая отношения количества чтений к количеству записей, которое, как отмечалось выше, зависит от количества обслуживаемых операционных индексов. Они неявно сбрасывают со счетов использование систем LDAP для обработки транзакций, хотя есть тенденция, что некоторые реализации LDAP учитывают такие возможности.
2.4 Информационная модель (модель данных или объектная модель) LDAP
Каталоги LDAP используют модель данных, которая представляет данные как иерархию объектов. Это не означает, что LDAP является объектно-ориентированной базой данных. Как уже отмечалось выше, LDAP сам по себе является протоколом, позволяющим получить доступ к службам LDAP, и не определяющий, каким образом данные хранятся, — но операционные примитивы (чтение, удаление, модификация) работают с моделью (описанием/представлением) данных, имеющих (в основном) объектоподобные характеристики.
2.4.1 Структура дерева объектов
В этом разделе определяется сущность LDAP. Если Вы поймёте этот раздел и различные термины и отношения, с ним связанные, Вы поймёте LDAP.
В LDAP-системе данные представлены как иерархия объектов, каждый из которых называется записью. Полученная в результате древовидная структура называется Информационным деревом каталога (Directory Information Tree, DIT). Верхнюю часть данного дерева обычно называют корнем (root), (а также базой (base) или суффиксом (suffix)).
У каждой записи есть одна родительская запись (объект) и ноль или более дочерних записей (объектов). Каждая дочерняя запись (объект) является одноуровневой (братской) по отношению к другим дочерним записям своей родительской записи.
Каждая запись состоит из (является экземпляром) одного или нескольких объектных классов (objectClass). Объектные классы содержат ноль или более атрибутов (attribute). Атрибуты имеют имена (и, иногда, аббревиатуры или псевдонимы) и обычно содержат данные (наконец-то!).
Характеристики (свойства) объектных классов и их атрибутов описываются определениями ASN.1.
Уф! Теперь Вы знаете всё, что только можно знать о LDAP. Остальное — детали. Да, этих деталей, пожалуй, очень много. Но суть LDAP именно в этом.
Представленная ниже диаграмма иллюстрирует эти отношения:
Информационная модель (модель данных) LDAP DIT
Подытожим:
Каждая запись (1) состоит из одного или нескольких объектных классов (2).
У каждого объектного класса (2) есть имя. Объектный класс представляет собой контейнер для атрибутов (в его определении идентифицируются атрибуты, которые он может или должен содержать).
У каждого атрибута (3) есть имя, он является членом одного или нескольких объектных классов (2) и содержит данные.
При наполнении DIT каждая запись будет уникально идентифицирована в иерархии (относительно своей родительской записи) данными, которые содержатся в этой записи (в атрибутах, которые содержатся в её объектном классе (классах)).
Теперь можно смело брать выходной на остаток дня и хорошенько отпраздновать!
2.4.2 Объектные классы
Объектные классы являются, по существу, контейнерами атрибутов. Они описываются с помощью определений ASN.1. У каждого объектного класса есть уникальное имя. Существует огромное число предопределённых объектных классов, в каждом из которых полным-полно атрибутов для почти всех возможных применений каталогов LDAP. Однако, само собой разумеется, что среди всех этих предопределённых объектных классов нет того, который Вам просто необходим! У объектных классов есть ещё три характеристики:
Объектный класс определяет, должен (MUST) ли входящий в него атрибут присутствовать в записи (обязательный атрибут), или он может (MAY) присутствовать (необязательный атрибут).
Каждый объектный класс принадлежит к определённому типу: он может быть структурным (STRUCTURAL), вспомогательным (AUXILIARY) или абстрактным (ABSTRACT) (детально эти типы описаны в следующей главе). На этом этапе достаточно знать, что в записи должен быть один и только один структурный (STRUCTURAL) объектный класс и может быть ноль или более вспомогательных (AUXILIARY) объектных классов.
Объектный класс может быть частью иерархии, в этом случае он наследует все характеристики своего родительского объектного класса (классов) (включая все содержащиеся в них атрибуты).
Объектные классы являются контейнерами и управляют тем, какие атрибуты могут быть добавлены к каждой записи. В целом же они, как правило, остаются вне поля зрения, когда речь идет о доступе и опросе (поиске) по DIT. Здесь на первый план выходят атрибуты и записи.
Вот неполный список наиболее часто используемых объектных классов и их атрибутов.
Больше (значительно больше) об объектных классах, — но только если Вы хорошо разобрались с данным материалом (в любом случае, мы будем разбираться с этим в следующей главе), — в противном случае продолжайте читать здесь.
Об уникальности: Каждое используемое в LDAP имя является уникальным. Имя каждого объектного класса уникально среди объектных классов, но на этом дело не заканчивается. Уникальное имя объектного класса (или имя любого другого элемента LDAP) также является глобально уникальным именем во всём LDAP. Например, существует объектный класс с уникальным именем person (с ним мы будем пересекаться позже), но это имя также является глобально уникальным именем во всём LDAP. Не существует атрибута (или любого другого элемента) с именем person.
2.4.3 Атрибуты
Каждый атрибут имеет имя (а также может иметь короткое имя или псевдоним) и обычно содержит данные. Атрибуты всегда связаны (являются членами) с одним или несколькими объектными классами. У атрибутов есть ряд интересных особенностей:
Все атрибуты являются членами одного или нескольких объектных классов.
Каждый атрибут определяет тип данных, которые он может содержать (ключевое слово SYNTAX в определении атрибута).
Атрибуты могут быть частью иерархии, в этом случае дочерний атрибут наследует все характеристики родительского атрибута. В данном случае иерархия атрибутов используется для упрощения и сокращения определений атрибутов (в ASN.1) там, где у нескольких атрибутов имеются одинаковые общие свойства, такие как максимальная длина, чувствительность/нечувствительность к регистру символов, или что-то ещё. Никакого другого смысла в иерархии атрибутов нет.
Атрибуты могут быть необязательными (ключевое слово MAY) или обязательными (ключевое слово MUST), согласно определениям ASN.1 того объектного класса, членами которого они являются. Атрибут может быть необязательным в одном объектном классе и обязательным в другом. Это свойство определяется в рамках объектного класса.
В разных местах этой документации в записях-примерах подобраны совершенно различные атрибуты, что может показаться путаницей. На самом же деле так происходит из-за необязательного характера большинства атрибутов. Это позволяет при составлении записей использовать подход «выбирай и соединяй»: находим нужный нам атрибут, находим объектный класс, членом которого является этот атрибут (таких классов может быть несколько), и надеемся, что все остальные атрибуты из данного объектного класса, которые мы не хотим использовать, окажутся необязательными! Чтобы яснее это себе представить, попробуйте посмотреть здесь.
У атрибутов может быть одно (SINGLE-VALUE) или несколько (MULTI-VALUE) значений (как описано в их определениях ASN.1). SINGLE-VALUE означает, что только одно значение данных может быть задано для этого атрибута. MULTI-VALUE означает, что этот атрибут может появляться в записи несколько раз с разными значениями данных. Если атрибут описывает, скажем, адрес электронной почты, может быть одно, два или 500 включений этого атрибута в запись, каждое с разным адресом электронной почты (атрибут многозначный (MULTI-VALUE)) — это один из ряда методов работы с почтовыми псевдонимами, применяемых при построении каталога. Значением по умолчанию для атрибута является MULTI-VALUE (что позволяет иметь несколько значений).
У атрибутов есть имя и, иногда, псевдоним (как описано в их определениях ASN.1), например, атрибут с именем cn является членом объектного класса, называемого person (и многих других), и имеет псевдоним commonName. Для ссылки на этот атрибут может использоваться как commonName, так и cn.
На всех уровнях иерархии данные, содержащиеся в каком-то из атрибутов, могут использоваться для однозначной идентификации записи. Это может быть любой атрибут в записи. Это может быть даже комбинация двух или более атрибутов.
Атрибут (атрибуты), выбранные для хранения данных, составляющих уникальность записи, иногда называются атрибутом (атрибутами) именования или относительным уникальным именем (Relative Distinguished Name, RDN) — но подробнее об этом в следующем разделе.
Больше (значительно больше) об атрибутах, — но только если Вы хорошо разобрались с данным материалом (в любом случае, мы будем разбираться с этим в следующей главе), — в противном случае продолжайте читать здесь.
2.4.4 Описание дерева путём добавление записей (данных)
В конце концов мы хотим поместить немного данных в наш каталог и использовать-таки эту замороченную штуку.
Описание древовидной структуры и первоначальное наполнение данными осуществляется путем добавления записей (с ассоциированными с ними объектными классами и атрибутами), начиная от корневой записи DIT и двигаясь вниз по иерархии. Таким образом, родительская запись всегда должна быть добавлена перед тем, как пытаться добавить дочерние записи.
Записи состоят из одного или нескольких объектных классов (единственного структурного объектного класса и нуля или более вспомогательных классов), которые выступают в качестве контейнеров для атрибутов. Именно атрибуты, а не объектные классы, содержат данные.
Ранее мы определили, что при создании/наполнении DIT каждая запись будет уникально идентифицироваться (относительно своей родительской записи) в иерархии. Единственным уникальным элементом любой структуры данных являются данные. Чтобы однозначно идентифицировать запись, нам нужно определить уникальные данные среди тех, которые содержатся в ней. Данные, содержащиеся в записи, определяются в атрибутах (присутствующих в объектных классах), таким образом, нам нужно определить атрибут, содержащий данные, являющиеся уникальными. Напомним, что многие атрибуты являются многозначными, — они могут присутствовать в записи несколько раз с разным содержимым, — поэтому для создания абсолютной, несомненной уникальности нам нужно определить сразу и атрибут, и содержащиеся в нём данные. Это делается с использованием формата имя_атрибута=значение_(или_данные), который в терминологии LDAP зовётся утверждением значения атрибута (Attribute Value Assertion, AVA).
Для иллюстрации, если в данной записи (на данном уровне иерархии) уникальными данными является слово fred (да-да, мы знаем, пример так себе, маловероятно, чтобы это слово было уникальным, но вдруг мы находимся в Узбекистане?), и оно содержится в атрибуте с именем cn, то нашим AVA (утверждением значения атрибута) станет cn=fred. В данном случае, если мы хотим пооригинальничать или нам просто некуда девать время, мы можем записать его иначе: commonName=fred (у атрибута cn есть псевдоним commonName).
Но вдруг так случится, что cn=fred не будет абсолютно уникальным (Кто там хихикает на заднем плане? Мы всё слышим!), а значит не сможет быть уникальным идентификатором для данной записи. Мы можем либо изменить выбранное нами значение (в записи может оказаться несколько значений cn=value, из которых мы можем выбрать), либо изменить выбранный нами атрибут (может неплохо подойти sn=de Gamma, если, конечно, мы не в Португалии). Кроме того, мы можем использовать второе AVA для обеспечения уникальности. В этом случае мы сохраним наше cn=fred, но добавим AVA drink=tamarind juice (внесём элемент экзотики в наши серые будни). Тогда уникальное значение будет записываться как cn=fred+drink=tamarind juice. Уникальней просто некуда.
Добавление записей может происходить разными путями, один из которых — использовать файлы формата LDAP Data Interchange Files (LDIF), который полностью описан в одной из последующих глав. Файлы LDIF — это текстовые файлы, описывающие древовидную иерархию — информационное дерево каталога (Directory Information Tree, DIT), и данные, добавляемые в каждый атрибут. Ниже приведён простой пример LDIF-файла, описывающий корневое DN (dc=example,dc=com) и добавляющий три дочернии записи в ветку people.
Примечания:
На данном этапе не так важно досконально разбираться во всех значениях этого LDIF-файла. В примерах главы 5 охвачены подробности настройки LDIF-файлов, а в главе 8 LDIF-файлы разъясняются в красочных деталях. На данном этапе достаточно знать, что LDIF-файлы могут использоваться для создания DIT и выглядят примерно так, как приведено ниже (данный LDIF создаёт DIT со структурой, приведённой на русинке 2.4.4-1).
Добавление LDAP-записей может быть также выполнено с помощью LDAP-клиентов, таких как LDAP-браузеры общего назначения (смотрите LDAPBrowser/Editor) или специализированные приложения.
version: 1 ## указание версии не является строго необходимым (и некоторые реализации его отклоняют), ## но, в общем случае, это хорошая практика ## Определяем DIT ROOT/BASE/SUFFIX #### ## используется формат RFC 2377 (доменные имена) ## dcObject - это ВСПОМОГАТЕЛЬНЫЙ объектный класс и, кроме него, запись ## ДОЛЖНА иметь СТРУКТУРНЫЙ объектный класс (в данном случае, organization) # это последовательность ЗАПИСИ и ей предшествует ПУСТАЯ СТРОКА dn: dc=example,dc=com dc: example description: Лучшая компания в целом свете objectClass: dcObject objectClass: organization o: Example, Inc. ## ПЕРВЫЙ уровень иерархии - люди (people) # это последовательность ЗАПИСИ, она должна предваряться ПУСТОЙ строкой dn: ou=people, dc=example,dc=com ou: people description: Все люди в организации objectClass: organizationalUnit ## ВТОРОЙ уровень иерархии - записи людей # это последовательность ЗАПИСИ, она должна предваряться ПУСТОЙ строкой dn: cn=Robert Smith,ou=people,dc=example,dc=com objectclass: inetOrgPerson cn: Robert Smith cn: Robert sn: Smith uid: rsmith mail: [email protected] mail: [email protected] ou: sales ## ВТОРОЙ уровень иерархии - записи людей # это последовательность ЗАПИСИ, она должна предваряться ПУСТОЙ строкой dn: cn=Bill Smith,ou=people,dc=example,dc=com objectclass: inetOrgPerson cn: Bill Smith cn: William sn: Smith uid: bsmith mail: [email protected] mail: [email protected] ou: support ## ВТОРОЙ уровень иерархии - записи людей # это последовательность ЗАПИСИ, она должна предваряться ПУСТОЙ строкой dn: cn=John Smith,ou=people,dc=example,dc=com objectclass: inetOrgPerson cn: John Smith sn: smith uid: jsmith mail: [email protected] mail: [email protected] ou: accounting
Важное замечание: Строки в приведённом выше LDIF-файле, начинающиеся с ‘dn:’, по существу сообщают LDAP-серверу, каким образом структурировать или располагать запись в DIT (об этом в следующем разделе). В общем случае не важно, значение какого атрибута используется для этой цели, при условии уникальности ‘dn:’. В первой записи ВТОРОГО уровня (третьей записи LDIF-файла) приведённого примера для этой цели было выбрано «dn: cn=Robert Smith, ou=people, dc=example, dc=com». Точно также могло быть выбрано, скажем, «dn: uid=rsmith, ou=people, dc=example, dc=com». При LDAP-поиске может применяться любая комбинация атрибутов и запись будет найдена независимо от того, какое значение было использовано в ‘dn:’ при её создании. Однако, если запись планируется использовать для аутентификации пользователя, скажем, для входа в систему или организации технологии единого входа (Single Sign-On), значение ‘dn:’ становится чрезвычайно важным и определяет идентификатор входа в систему (в качестве которого, как правило, используется uid), или, на жаргоне, DN подсоединения. Иногда (особенно в контексте LDAP, используемого в Microsoft AD) имя записи называется DN принципала (Principal DN), хотя этот термин не используется в определениях стандартов LDAP. Дополнительная информация по этой теме.
Если данное примечание кажется вам белибердой, можете пока забыть о нём. Позже мы это подробнейшим образом осветим.
Мы расскажем о LDIF-файлах позже, поскольку они нам ещё понадобятся, а приведённый выше LDIF определяет следующую структуру:
Рисунок 2.4.4-1: Структура DIT, созданная LDIF-файлом
После того, как DIT определён и запущен в работу, в дальнейшем информацию в него можно добавлять с помощью LDIF, LDAP-браузера, web-интерфейса или другого программного интерфейса.
Используя LDIF-файлы, данные также можно экспортировать (сохранить) в качестве резервной копии или для других целей.
2.4.5 Навигация по дереву
После того, как мы поместили данные в наше дерево (DIT), обычно самое время начать с ними работать!
Для этого мы должны посылать команды (на чтение, поиск, модификацию и т.д.) нашему LDAP-серверу, а чтобы сделать это, мы должны быть в состоянии сообщить LDAP-серверу, где находятся данные (для записи) или хотя бы где они примерно находятся (для поиска/чтения).
Короче говоря, мы должны осуществлять навигацию (ориентироваться) в каталоге.
Но для начала давайте введём ещё немного существенной терминологии.
В предыдущем разделе мы определили, что каждая запись должна быть уникально идентифицируемой (относительно своей родительской записи) с использованием одного (или нескольких) AVA (утверждений значения атрибута), например, cn=fred или, как в примере выше, cn=Robert Smith. Из правила, что каждое идентифицирующее AVA (или несколько AVA) должны быть уникальными (относительно родительской записи) в иерархии, следует, что путь к любой записи на любом уровне также должен быть уникальным (он представляет собой сумму индивидуально уникальных записей).
Терминология LDAP в области адресации заставляет задуматься об ограниченности английского языка. До сих пор для описания AVA записи мы использовали термин уникальное (unique), достаточно распространённое и понятное английское слово. Мы можем также сказать, что каждая запись имеет различное (different) имя. Кроме того (начинается!), мы можем также несколько извилисто выразиться, что, в силу своей уникальной идентификации, каждая запись отлична (distinguished) от своих соседей. Мы у цели! Основоположники служб каталогов в своей бесконечной мудрости решили использовать слово «Distinguished» («Отличительное», обычно в русскоязычной документации переводится как «Уникальное» — примечание переводчика).
Итак, AVA, например, cn=Robert Smith, уникально идентифицирующее запись, называется относительным уникальным именем (Relative Distinguished Name, RDN), то есть именем, уникальным по отношению к родительской записи. Путь от корневой записи DIT (она же базовая запись или суффикс) к данной записи представляет собой сумму всех RDN (соединённых через запятую (,) в порядке слева направо от младшей до старшей) называется уникальным именем (Distinguished Name, DN). Красота! Какими бы ни были Ваши взгляды на достоинства (или недостатки) LDAP и X.500, способность групп их стандартизации генерировать уникальную (или отличительную) терминологию не подлежит сомнению.
Для иллюстрации, в DIT из нашего примера путь от корневой записи до записи, уникально идентифицируемой AVA cn=Robert Smith, идёт от (RDN) dc=example,dc=com через (RDN) ou=people, и заканчивается на (RDN) cn=Robert Smith. Итоговое DN будет записываться как cn=Robert Smith,ou=people,dc=example,dc=com.
Три дополнительных момента, пока Вы ещё способны воспринимать информацию.
Напоминаем, что для создания уникального идентификатора можно применять несколько AVA, в этом случае RDN может выглядеть так: cn=Robert Smith + uid=rsmith (обычно это называется многозначным RDN). Эквивалентное ему DN будет выглядеть так: cn=Robert Smith + uid=rsmith, ou=peope,dc=example, dc=com (наличие или отсутствие пробелов между RDN не существенно).
DN записи ou=people: ou=people,dc=example,dc=com. DN описывает путь к любой записи в DIT.
В dc=example, dc=com, очевидно, два RDN (dc=example и dc=com). Это стандартная и легитимная конструкция (в дальнейшем мы её обсудим), используемая для определения корневой записи (она же базовая запись или суффикс). (Если Вы в настроении помудрствовать лукаво на эту тему, можно было бы назвать эту конструкцию много-RDN-ной RDN, но, честное слово, не стоит).
Для навигации по DIT мы можем задать путь (DN) к месту, где находятся наши данные (cn=Robert Smith, ou=people,dc=example, dc=com приведёт нас к уникальной записи), либо мы можем задать путь (DN) к месту, где, как мы предполагаем, находятся наши данные (скажем, ou=people,dc=example,dc=com), а затем выполнить поиск по паре или нескольким парам атрибут=значение, чтобы найти целевую запись (или записи). Если мы хотим выполнить изменения в каталоге (модификацию на жаргоне LDAP), как правило, следует указывать уникальную запись. Однако, если мы устраиваем DIT допрос с пристрастием, достаточно лишь примерной точности — мы получим всё, что соответствует критериям поиска.
Следующая диаграмма иллюстрирует DN и RDN:
Дальнейшее объяснение с некоторыми рабочими примерами.
2.5 Отсылки и репликация LDAP
Одним из наиболее мощных аспектов LDAP (и X.500) является вложенная в них способность делегировать ответственность за поддержание части каталога другому серверу, сохраняя при этом общую картину каталога как единого целого. Таким образом, можно создать в каталоге компании делегирование ответственности (отсылку (referral) в терминологии LDAP) той части всего каталога, в которой описан конкретный отдел, LDAP-серверу этого отдела. В этом аспекте LDAP почти полностью отражает концепцию делегирования DNS, если эта концепция Вам знакома.
В отличие от системы DNS, в стандартах не предусмотрена возможность сообщить LDAP-серверу проследовать по отсылке (разрешить отсылку), LDAP-клиенту оставлена возможность напрямую обращаться к новому серверу, используя возвращённую отсылку. Равным образом, поскольку в стандарте не определена организация данных LDAP, возможность перехода LDAP-сервера по ссылке (разрешение ссылки) не противоречит стандартам и некоторые LDAP-серверы выполняют эту функцию автоматически, используя процесс, обычно называемый сцеплением (chaining).
OpenLDAP буквально следует стандартам и по умолчанию не выполняет сцепление, а всегда возвращает отсылку. Однако OpenLDAP может быть настроен на выполнение сцепления с помощью директивы overlay chain.
Встроенная функция репликации LDAP позволяет создать одну или несколько подчинённых копий каталога (DIT) от одной главной (и даже, в некоторых реализациях, распространять изменения между несколькими главными копиями DIT), таким образом, по сути, создаётся устойчивая структура.
Важно, однако, подчеркнуть разницу между LDAP и транзакционными базами данных. При выполнении обновления в главном каталоге LDAP, для обновления подчинённых копий каталога (или других главных копий в конфигурации с несколькими главными серверами) может потребоваться некоторое время (в компьютерной терминологии) — главный и подчинённый каталоги (или разные главные каталоги в конфигурации с несколькими главными серверами) могут быть рассинхронизированы в течение какого-то периода времени.
В контексте LDAP, временное отсутствие синхронизации DIT считается несущественным. В случае же транзакционной базы данных, даже временное отсутствие синхронизации считается катастрофическим. Это подчёркивает различия в характеристиках данных, которые должны храниться в каталоге LDAP и в транзакционной базе данных.
Конфигурация репликации и отсылок рассматривается далее, а также в приводимых примерах.
2.5.1 Отсылки LDAP
Рисунок 2.5-1 демонстрирует поисковый запрос с базовым DN dn:cn=thingie,o=widgets,dc=example,dc=com к LDAP-системе с отсылками, который полностью удовлетворяется первым LDAP-сервером (LDAP1):
Рисунок 2.5-1 — Запрос, удовлетворяемый только от LDAP1
Рисунок 2.5-2 демонстрирует поисковый запрос с базовым DN dn:cn=cheri,ou=uk,o=grommets,dc=example,dc=com к LDAP-системе с отсылками, ответ на который возвращается в результате серии отсылок к серверам LDAP2 и LDAP3, а LDAP-клиенты всегда следуют по отсылкам:
Рисунок 2.5-2 — Запрос, генерирующий отсылки к LDAP2 и LDAP3
Примечания:
- Все клиентские запросы начинаются с обращения к глобальному каталогу LDAP1.
- На сервере LDAP1 запросы любых данных, содержащие widgets в качестве RDN в DN, удовлетворяются непосредственно из LDAP1, например:
dn: cn=thingie,o=widgets,dc=example,dc=com
- На сервере LDAP1 запросы любых данных, содержащие grommets в качестве RDN в DN, генерируют отсылку на сервер LDAP2, например:
dn: cn=cheri,ou=uk,o=grommets,dc=example,dc=com
- На сервере LDAP2 запросы любых данных, содержащие uk в качестве RDN в DN, генерируют отсылку на сервер LDAP3, например:
dn: cn=cheri,ou=uk,o=grommets,dc=example,dc=com
Если LDAP-сервер сконфигурирован на выполнение сцепления (то есть на следование отсылкам, как показано альтернативными пунктирными линиями), то LDAP-клиенту будет отправлен один единственный ответ. Сцепление контролируется конфигурацией LDAP-сервера и значениями в поисковых запросах. Информация по сцеплению здесь.
На рисунках показано явное сцепление с использованием объектного класса referral. Серверы OpenLDAP могут быть настроены так, чтобы возвращать общую отсылку в случае, если запрашиваемый DN не был найден во время операции поиска.
2.5.2 Репликация LDAP
Функции репликации позволяют копировать обновления LDAP DIT на одну или несколько LDAP-систем в целях резервирования и/или повышения производительности. В этом контексте стоит подчеркнуть, что репликация работает на уровне DIT, а не на уровне LDAP-сервера, поскольку на одном LDAP-сервере может обслуживаться несколько DIT. Репликация происходит периодически, в течение промежутка времени, известного как время цикла репликации (по сути, это время, необходимое для отправки обновленных данных на сервер-реплику и получения подтверждения об успешном завершении операции). В общем случае, существуют методы уменьшения времени цикла репликации с помощью настроек, но обычно они приводят к снижению производительности или увеличению нагрузки на сеть. Исторически для выполнения репликации в OpenLDAP использовался отдельный демон (slurpd), но, начиная с версии 2.3, стратегия репликации коренным образом изменилась, были достигнуты серьёзные улучшения в гибкости и возможностях настройки времени цикла репликации. Существует два возможных типа конфигураций репликации, у каждого из которых есть несколько вариантов.
Главный-подчиненный (Master-Slave): В конфигурации главный-подчинённый обновляется одно единственное DIT (на жаргоне OpenLDAP оно называется главным (master) или поставщиком репликации (provider)), и эти обновления реплицируются или копируются на один или несколько указанных LDAP-серверов, на которых запущены подчинённые DIT (на жаргоне OpenLDAP они называются потребителями репликации (consumer)). Подчинённые серверы оперируют с доступной только для чтения копией главного DIT. Пользователи, которые выполняют только чтение, будут превосходно себя чувствовать, работая с серверами, содержащими подчинённые DIT, а пользователи, которым нужно вносить изменения в каталог, должны обращаться к серверу, содержащему главное DIT. При определённых условиях конфигурация главный-подчинённый позволяет существенно сбалансировать нагрузку. Однако, у неё есть два очевидных недостатка:
Если всем (большинству пользователей) дана возможность (требуется) вносить изменения в DIT, то либо им потребуется получать доступ к одному серверу (с подчинённым DIT) для осуществления чтения и к другому серверу (с главным DIT) для выполнения обновлений, либо они всегда будут обращаться к серверу, на котором запущено главное DIT. В последнем случае репликация выполняет только функцию резервного копирования.
Поскольку существует только один сервер, содержащий главное DIT, он представляет собой единую точку отказа для операций записи, которая может повлиять на работоспособность всей системы (хотя, в случае серьёзного сбоя, подчинённое DIT может быть переконфигурировано для работы в качестве главного).
Несколько главных (Multi-Master): В конфигурации с несколькими главными серверами могут обновляться несколько главных DIT, запущенных на одном или нескольких серверах, и результаты обновлений распространяются на другие главные серверы.
Исторически OpenLDAP довольно долго не поддерживал операции с несколькими главными серверами, но в версии 2.4 окончательно введены такие возможности. В этом контексте, наверное, стоит отметить две вариации общей проблемы конкуренции обновлений, специфичной для всех конфигураций с несколькими главными серверами. Эта проблема выявлена проектом OpenLDAP для своей конфигурации с несколькими главными серверами, но она относится ко всем системам LDAP:
Конкуренция значений. Если выполняется два обновления одного и того же атрибута в одно и то же время (в пределах времени цикла репликации) и при этом атрибуту назначаются разные значения, то, в зависимости от типа атрибута (SINGLE или MULTI-VALUED), результирующая запись может быть в неправильном или непригодном для использования состоянии.
Конкуренция удаления. Если один пользователь добавляет дочернюю запись в то же самое время (в пределах времени цикла репликации), когда другой пользователь удаляет оригинальную запись, то удалённая запись вновь появится.
Рисунок 2.5-3 показывает несколько возможных конфигураций репликации и объединяет их с отсылками из предыдущего раздела, чтобы показать всю мощь и гибкость LDAP. Следует отметить, что большинство конфигураций LDAP не настолько сложны.
Рисунок 2.5-3 — Конфигурации репликации
Примечания:
RO = только чтение, RW = чтение-запись
В случае LDAP1 клиент взаимодействует с подчинённой системой, доступной только для чтения. Для выполнения операций модификации (записи) клиенты должны обращаться к главной системе.
В случае LDAP2 клиент взаимодействует с главной системой, которая реплицируется на две подчинённые.
LDAP3 является системой с несколькими главными серверами и для выполнения операций чтения (поиска) и/или записи (модификации) клиенты могут обращаться к любому серверу. В данной конфигурации каждый главный сервер может, в свою очередь, иметь одно или несколько подчинённых DIT.
Глава 3 — Схема данных, объектные классы и атрибуты LDAP
Проблемы, комментарии, предположения, исправления (включая битые ссылки) или есть что добавить? Пожалуйста, выкроите время в потоке занятой жизни, чтобы написать нам, вебмастеру или в службу поддержки. Оставшийся день Вы проведёте с чувством удовлетворения.
Нашли ошибку в переводе? Сообщите переводчикам!
Работа с файлами и каталогами
Итак, чтобы войти в какой-нибудь каталог, нужно дважды щелкнуть на значке. Работа с файлами аналогична. Вообще многие действия выполняют ся так же, как и в Проводнике Windows.
Некоторые операции с файлами и каталогами можно осуществить с помощью контекстного меню.
· Открыть(Open) — открыть файл или папку.
· Проводник(Explore) — открыть Проводник Windows и уже с его помощью производить операции над файлами и папками (рис. 9.2).
Тем самым можно упростить выполнение операций копировать, удалить; проводить действия над файлами, папками на сервере быстрее и удобнее. Слева теперь находятся ссылки на папки на FTP-сервере, а также можно посмотреть содержимое папки Мой компьютер.
Рис. 9.2.Окно Проводника Windows: работа с-FТР-сервером
Копировать в папку(Copy to Folder) — скопировать файл в папку. При выборе этой команды появится специальное окно, в котором можно с легкостью выбрать папку для копирования. Вырезать(Cut). Копировать(Сору).
· Удалить (Delete)— удалить файл или папку. Правда для этого нужно иметь необходимые права доступа. При анонимном соединении в 99% случаев сделать это нельзя.
· Переименовать(Rename) — переименовать файл или папку. Также, если нет прав доступа, сделать это не представляется возможным.
· Свойства(Properties) — свойства. Вызывается окно (рис. 9.3), в котором можно посмотреть на свойства файла, каталога, а также права доступа, изменить их.
Вверху дается имя файла, которое вы можете изменить. Далее информация о размере, дате изменения архива. В поле Permissionsвы можете посмотреть информацию о том, что разрешено делать с файлом и кому:
· Владелец(Owner) — собственно владелец файла. И делать с ним он может что хочет: считывать, удалять, перезаписывать и т. д.
· Группа(Group) — специальная группа пользователей, которая наделяется определенными полномочиями. Например, загружать файлы на сервер.
· Все пользователи(All Users) — все пользователи, которые не входят в две предыдущие группы. Чаще всего они могут только загружать файлы с сервера на локальный компьютер.
Рис. 9.3. Окно Свойства: FTP
Загрузка файлов на сервер
Загрузка файлов на сервер может быть нужна в нескольких случаях. Первый — самый распространенный случай — когда вы создаете свой веб-сайт и хотите загрузить файлы на сервер.
При этом вы уже должны иметь имя входа (login) и пароль для доступа к FTP, знать его адрес и параметры работы с ним. Все это должен предоставить вам ваш хостинг-провайдер. Итак, зная все вышеперечисленное, вы набираете в адресной строке его адрес.
Через некоторое время появится окно авторизации (рис. 9.4), где вам будет предложено ввести имя входа (login) и пароль.
Если ваш сервер поддерживает анонимную работу, т. е. для пользователя, Не имеющего собственной учетной записи, установите флажокАнонимный вход(Login Anonymously). Таким образом, вход на сервер будет осуществлен.
Рис. 9.4.Окно Вход
Если пароль труден для запоминания, или просто не хочется каждый раз вводить его, установите флажок Сохранить пароль(Save Password). Он будет сохранен.
Далее нажмите кнопку Вход(Login). Если все указано верно, вы будете допущены на сервер.
Дело в том, что даже FTP-клиент, встроенный в Microsoft Internet Explorer 6.0 поддерживает механизм drag-and-drop (перетащить и бросить). Поэтому копировать файлы на сервер очень легко. Достаточно выбрать файл, группу файлов или каталог и перетащить их в окно обозревателя. Сразу же появится небольшое окно, в котором будет сообщаться о том, сколько уже загружено на сервер, какое время на это потребовалось.
Программа Проводник – средство, дающее возможность пользователю видеть в иерархической форме структуру, размещение папок и быстро переходить к какому-либо объекту (папке, файлу, ярлыку), а также выполнять ряд действий с папками и файлами.
Вызвать Проводник можно из Главного меню командой Пуск/Программы/Проводник или выбрав пунктПроводник в контекстных меню кнопки Пуск или папки Мой компьютер. Из окна папки Проводник можно вызвать следующим образом: выделить вложенную папку и дать команду Файл/Проводник.На экран будет выведено окно Проводника с открытой выбранной папкой.
Окно Проводника состоит из двух панелей. Левая панель показывает информационные ресурсы, представленные в виде иерархического дерева. Правая панель показывает содержимое текущей папки.
Процесс перемещения по папкам с целью открытия необходимой называют навигацией. Проводникявляется инструментом поиска – навигатором. Чтобы эффективно работать в среде Проводника, нужно знать приемы навигации в нем.
Вопрос 21
Бу́фер обме́на (англ. clipboard) — промежуточное хранилище данных, предоставляемое программным обеспечением и предназначенное для переноса или копирования между приложениями или частями одного приложения.
Приложение может использовать свой собственный буфер обмена, доступный только в нём, или общий, предоставляемый операционной системой или другой средой через определённый интерфейс.
Буфер обмена некоторых сред позволяет вставлять скопированные данные в различных форматах в зависимости от получающего приложения, элемента интерфейса и других обстоятельств. Например, текст, скопированный из текстового процессора, может быть вставлен с разметкой в поддерживающие её приложения и в виде простого текста в остальные.
Вставить объект из буфера обмена можно сколько угодно раз.
Как правило, при копировании информации в буфер его предыдущее содержимое пропадает. Но, например, Microsoft Office содержит несколько буферов, поэтому может хранить одновременно несколько фрагментов информации. Некоторые среды рабочего столавключают программу для ведения протокола последних значений буфера и извлечения уже перезаписанных
Вопрос 22
Фа́йловая систе́ма (англ. file system) — порядок, определяющий способ организации, хранения и именования данных на носителях информации в компьютерах, а также в другом электронномоборудовании: цифровых фотоаппаратах, мобильных телефонах и т. п. Файловая система определяетформат содержимого и физического хранения информации, которую принято группировать в видефайлов. Конкретная файловая система определяет размер имени файла (папки), максимальный возможный размер файла и раздела, набор атрибутов файла. Некоторые файловые системы предоставляют сервисные возможности, например, разграничение доступа или шифрование файлов.
Файловая система связывает носитель информации с одной стороны и API для доступа к файлам — с другой. Когда прикладная программа обращается к файлу, она не имеет никакого представления о том, каким образом расположена информация в конкретном файле, так же, как и на каком физическом типе носителя (CD, жёстком диске, магнитной ленте, блоке флеш-памяти или другом) он записан. Всё, что знает программа — это имя файла, его размер и атрибуты. Эти данные она получает от драйвера файловой системы. Именно файловая система устанавливает, где и как будет записан файл на физическом носителе (например, жёстком диске).
С точки зрения операционной системы (ОС), весь диск представляет собой набор кластеров (как правило, размером 512 байт и больше)[1]. Драйверы файловой системы организуют кластеры в файлы и каталоги (реально являющиеся файлами, содержащими список файлов в этом каталоге). Эти же драйверы отслеживают, какие из кластеров в настоящее время используются, какие свободны, какие помечены как неисправные.
Вопрос 23
Типы файлов бывают разные, как говорится в одной старой песне – черные, белые, красные. Но, естественно, что их основное отличие совсем не в цветах.
Текстовые, видео, музыкальные, архивные, системные, образы дисков, таблицы, презентации, справки, картинки – перечислять можно еще ой как долго, но все то, что я перечислил выше, является типами файлов.
Тип файла еще называют форматом. От типа файла зависит, какой программой будет обрабатываться выбранный файл. Само собой всплывает один интересный вопрос: «Как компьютер определяет, к какому типу относится файл?»
А ведь все сделано довольно просто – каждому файлу дополнительно присваивается расширение.
Расширение представляет собой три символа в конце названия файла, оно отделяется от названия точкой. Правда есть расширения с 2-мя и 4-мя символами, но с 3-мя наиболее распространенные.
Именно эти три маленьких символа в конце названия указывают операционной системе, в какой программе надо запускать файл. То есть это как бы намек компьютеру, на то, какой программой предпочтительнее открыть тот или иной файл. И когда вы дважды щелкаете по файлу, операционная система автоматически загружает программу для работы с данным типом файлов, и эта программа начинает автоматически работать с выбранным файлом.
Вопрос 24
Universal Viewer (ATViewer) — это универсальный файловый просмотрщик с большим набором поддерживаемых форматов. Доступны следующие режимы просмотра файлов: Текст, Двоичный, Шестнадцатеричный, Юникод, любые файлы неограниченного размера (можно просматривать файлы в том числе большие 4 Гб), RTF и UTF-8 тексты, все основные форматы изображений: BMP JPG GIF PNG TGA TIFF…, все мультимедийные форматы поддерживаемые MS Windows Media Player: AVI MPG WMV MP3…, все форматы поддерживаемые MS Internet Explorer: HTML XML DOC XLS…, все форматы поддерживаемые Lister-плагинами к Total Commander.
Вопрос 25
При помощи приложения google поиск при команды 2 раза ctrl
Вопрос 27
Архивация — это сжатие одного или более файлов с целью экономии памяти и размещение сжатых данных в одном архивном файле. Архивация данных — это уменьшение физических размеров файлов, в которых хранятся данные, без значительных информационных потерь.
Архивация проводится в следующих случаях:
· Когда необходимо создать резервные копии наиболее ценных файлов
· Когда необходимо освободить место на диске
· Когда необходимо передать файлы по E-mail
Архивный файл представляет собой набор из нескольких файлов (одного файла), помещенных в сжатом виде в единый файл, из которого их можно при необходимости извлечь в первоначальном виде. Архивный файл содержит оглавление, позволяющее узнать, какие файлы содержатся в архиве.
В оглавлении архива для каждого содержащегося в нем файла хранится следующая информация:
· Имя файла
· Размер файла на диске и в архиве
· Сведения о местонахождения файла на диске
· Дата и время последней модификации файла
· Код циклического контроля для файла, используемый для проверки целостности архива
· Степень сжатия
Любой из архивов имеет свою шкалу степени сжатия. Чаще всего можно встретить следующую градацию методов сжатия:
· Без сжатия (соответствует обычному копированию файлов в архив без сжатия)
· Скоростной
· Быстрый (характеризуется самым быстрым, но наименее плотным сжатием)
· Обычный
· Хороший
· Максимальный (максимально возможное сжатие является одновременно и самым медленным методом сжатия)
Лучше всего архивируются графические файлы в формате .bmp, документы MS Office и Web-страницы.
Что такое архиваторы?
Архиваторы – это программы (комплекс программ) выполняющие сжатие и восстановление сжатых файлов в первоначальном виде. Процесс сжатия файлов называется архивированием. Процесс восстановления сжатых файлов – разархивированием. Современные архиваторы отличаются используемыми алгоритмами, скоростью работы, степенью сжатия (WinZip 9.0, WinAce 2.5, PowerArchiver 2003 v.8.70, 7Zip 3.13, WinRAR 3.30, WinRAR 3.70 RU).
Другие названия архиваторов: утилиты — упаковщики, программы — упаковщики, служебные программы, позволяющие помещать копии файлов в сжатом виде в архивный файл.
В ОС MS DOS существуют архиваторы, но они работают только в режиме командной строки. Это программы PKZIP и PKUNZIP, программа архиватора ARJ. Современные архиваторы обеспечивают графический пользовательский интерфейс и сохранили командную строку. В настоящее время лучшим архиватором для Windows является архиватор WinRAR.
Вопрос 31
Реестр Windows или системный реестр (англ. Windows Registry) — иерархически построенная база данных параметров и настроек в большинстве операционных системMicrosoft Windows.
Реестр содержит информацию и настройки для аппаратного обеспечения, программного обеспечения, профилей пользователей, предустановки. Большинство изменений вПанели управления, ассоциации файлов, системные политики, список установленного ПО фиксируются в реестре.
Урок 7. программное обеспечение (по) компьютеров и компьютерных систем — Информатика — 10 класс
Информатика, 10 класс. Урок № 7.
Тема урока — Программное обеспечение (ПО) компьютеров и компьютерных систем
Урок посвящен теме «Программное обеспечение (ПО) компьютеров и компьютерных систем». В ходе урока школьники научатся классифицировать программное обеспечение, определять основные характеристики операционной системы, характеризовать имеющееся в распоряжении прикладное программное обеспечение, осуществлять основные операции с файлами и папками.
Ключевые слова:
— программное обеспечение (ПО),
— системное ПО,
— прикладное ПО,
— системы программирования,
— операционная система,
— файл,
— каталог (папка),
— файловая система и структура,
— путь к файлу,
— полное имя файла,
— маска имен файлов.
Учебник: Информатика. 10 класс: учебник / Л. Л. Босова, А. Ю. Босова. — М.: БИНОМ. Лаборатория знаний, 2016. — 288 с.
Изучая компьютер, у нас возникают вопросы: что самое важное в компьютере и что заставляет компьютер работать? Может процессор или Bios, а может оперативная память?
Мы с вами уже знаем, что компьютер это универсальное устройство для хранения, преобразования и передачи информации. Но сам компьютер не способен мыслить самостоятельно, как человек. Его надо научить — значит построить работу компьютера по инструкции, в которой указано, что надо делать. Такая инструкция должна содержать строгую последовательность команд на языке, понятном компьютеру. Каждая команда должна сообщать компьютеру, как надо обрабатывать данные для получения желаемого результата. Такая инструкция называется программой. Получается, что компьютер состоит из двух основных частей:
- Аппаратные средства (hardware) — это технические устройства.
- Программное обеспечение (software) — это программы (команды, записанные последовательно).
Совокупность всех программ, предназначенных для выполнения на компьютере, называют программным обеспечением (ПО) компьютера.
На уроке мы с вами узнаем:
— как классифицировать программное обеспечение;
— как определять основные характеристики операционной системы;
— как характеризовать имеющееся в распоряжении прикладное программное обеспечение.
И научимся осуществлять основные операции с файлами и папками.
Сфера применения конкретного компьютера определяется как его техническими характеристиками, таки установленными на нем ПО.
ПО современных компьютеров насчитывает тысячи программ.
Тем не менее, все ПО можно разделить на три группы:
- Системное ПО
- Прикладное ПО
- Системы программирования
Системное программное обеспечение предназначено, прежде всего, для обслуживания самого компьютера, для управления работы его устройства. Включает в себя операционную систему и сервисные программы.
Операционная система — комплекс программ, обеспечивающих согласованное функционирование всех устройств компьютера и предоставляющих пользователю доступ к ресурсам компьютера.
В настоящее время наиболее распространёнными ОС для персональных компьютеров являются Windows, Mac Os, Linux. Для смартфонов, планшетов и других мобильных устройств — Android, iOS, Windows Phone.
Рассмотрим основные функции, выполняемые ОС современного компьютера.
Управление устройствами
Для обеспечения согласованного функционирования аппаратного обеспечения компьютера в состав ОС входят драйверы — специальные программы, управляющие работой подключенных к компьютеру внешних устройств.
Управление процессами
Программу, выполняемую на компьютере в текущий момент, принято называть процессом. Даже когда мы просто ищем информацию в сети Интернет, компьютер производит незаметные для нас операции по контролю за состоянием устройств, по защите от вирусов и т. д.
Современные ОС, планируя работы и распределяя ресурсы, обеспечивают возможность параллельной обработки нескольких процессов. Это свойство ОС называется многозадачностью.
Пользовательский интерфейс
Современные операционные системы обеспечивают диалог пользователя с компьютером на базе графического интерфейса.
Работа с файлами
За организацию хранения информации и обеспечения доступа к ней отвечает подсистема ОС, называемая файловой системой.
К сервисным программам (утилитам) относят различные программы, выполняющие дополнительные услуги системного характера:
— Обслуживание дисков и диагностика компьютера:
— проверка диска,
— восстановление диска,
— очистка диска.
— Архивирование файлов:
— сжатие программ и данных.
— Защита от вирусов:
— обнаружение компьютерных вирусов и средства «лечения».
Многие программы сжатия данных построены на основе алгоритма Хаффмана.
- Считать все входные данные и подсчитать частоты встречаемости всех символов.
- Частоты встречаемости символов выписать в ряд — это вершины будущего графа (дерева).
- Выбрать две вершины с наименьшими весами и объединить их — создать новую вершину, от которой провести рёбра к выбранным вершинам с наименьшими весами, а вес новой вершины задать равным сумме их весов. Расставить на рёбрах графа числа 0 и 1 (на верхнем ребре — 0, а на нижнем — 1). Чтобы выбранные вершины больше не просматривались, стереть их веса.
- Продолжить объединение вершин, каждый раз выбирая пару с наименьшими весами, до тех пор, пока не останется одна вершина — корень дерева. Вес этой вершины будет равен длине сжимаемого массива.
- Создать кодовую таблицу. Для определения двоичного кода каждой конкретной буквы необходимо пройти от корня до этой вершины, выписывая 0 и 1, встречающиеся на маршруте.
- Сгенерировать сжатый массив данных, для чего надо снова прочесть входные данные и каждый символ заменить соответствующим ему кодом.
Задание
Сжать с помощью алгоритма Хаффмана фразу:
VENI, VIDI, VICI
Решение:
Частота встречаемости символов
Частоты встречаемости символов выписать в ряд — это будут вершины будущего графа (дерева). В центре лучше расположить символ с наибольшим весом. Выбрать две вершины с наименьшими весами и объединить их — создать новую вершину, вес которой задать равным сумме весов двух предыдущих вершин. Расставить на рёбрах графа числа «0» и «1» (например, на верхнем ребре — «0», а на нижнем — «1»). Чтобы выбранные вершины больше не просматривались, стереть их веса. Продолжить объединение вершин, каждый раз выбирая пару с наименьшими весами, до тех пор, пока не останется одна вершина — корень дерева. Вес этой вершины будет равен длине сжимаемого массива.
Создать кодовую таблицу. Для определения двоичного кода каждой буквы надо пройти от корня до этой вершины, выписывая «0» и «1», встречающиеся на маршруте.
Вход:
VENI, VIDI, VICI
Выход:
01111011111000100001101
101100010000110110010
Исходный текст состоит из 16 символов, т. е. его длина в несжатом виде будет равна 16 байт или 128 бит. Код сжатого текста будет занимать 44 бита. Получаем коэффициент сжатия, равный 128/44 ≈ 2,9.
Комплекс программных средств, предназначенных для разработки новых программ, называют системой программирования или интегрированной средой разработки.
Рассмотрим основные компоненты, входящие в состав большинства систем программирования.
Специализированный текстовый редактор — позволяет программисту набрать и отредактировать текст программы на языке программирования высокого уровня. Трансляторы — специальные программы для перевода программы, написанной на языке высокого уровня, в машинные коды; существует два типа трансляторов: интерпретаторы и компиляторы. Интерпретаторы — обрабатывают и исполняют команды программы последовательно, от оператора к оператору, при каждом запуске программы она заново переводится в машинные коды. Компиляторы — обрабатывают весь текст программы, преобразовывая его в машинный код и строя исполняемый файл, готовый к запуску; после этого ни текст программы, ни компилятор не нужны.
Библиотеки стандартных подпрограмм — позволяют вызывать стандартные процедуры из вновь разрабатываемой программы. Компоновщик — собирает разные части (модули) создаваемой программы и используемые в ней стандартные подпрограммы в единый исполняемый файл.
Отладчик — позволяет управлять процессом исполнения программы, определять место и вид ошибок в программе, наблюдать за изменением значений переменных и выражений.
Программы, с помощью которых пользователь может работать с разными видами информации, не прибегая к программированию, принято называть прикладными программами или приложениями. Можно выделить приложения общего и специального назначения. Приложения общего назначения требуются практически каждому пользователю для работы с разными видами информации. К ним относятся: текстовые редакторы и процессоры; графические редакторы и пакеты компьютерной графики; табличные процессоры; редакторы презентаций, аудио и видеоредакторы; системы управления базами данных; браузеры; почтовые программы и др. Как правило, пользователь, приобретая компьютер, устанавливает на нём так называемый офисный пакет программ, включающий основные приложения общего назначения. Наибольшее распространение получили такие офисные пакеты, как Microsoft Office и Open Office. С любого компьютера, имеющего выход в Интернет, может быть доступен онлайн-офис, независимо от того, какую операционную систему этот компьютер использует. Онлайн-офис — это набор веб-сервисов, включающий в себя все основные компоненты традиционных офисных пакетов: текстовый редактор, электронные таблицы, редактор презентаций и др. Самый известный онлайн-офис — Google Docs.
Приложения специального назначения предназначены для профессионального применения квалифицированными пользователями в различных сферах деятельности. Это:
— настольные издательские системы,
— бухгалтерские программы,
— системы автоматизированного проектирования (САПР),
— программы компьютерного моделирования,
— математические пакеты,
— геоинформационные системы (ГИС), системы автоматического перевода и другие программы.
Когда мы рассматривали основные функции, выполняемые ОС современного компьютера, то сказали о файловой системе. Давайте разберем подробнее эту функцию.
Из курса основной школы вам известно, что файл — это поименованная совокупность данных определённого размера, размещаемая на внешних устройствах (носителях информации) и рассматриваемая в процессе обработки как единое целое. Файл характеризуется набором параметров (имя, размер, дата создания, дата последней модификации) и атрибутами, используемыми операционной системой для его обработки (архивный, системный, скрытый, только для чтения). Размер файла выражается в байтах. На каждом компьютерном носителе информации может храниться большое количество файлов. Для удобства поиска информации файлы по определённым признакам объединяют в группы, называемые каталогами или папками.
Каталог (папка) — это поименованная совокупность файлов и подкаталогов (вложенных каталогов).
Правила построения имён файлов и папок (каталогов) зависит от ОС. В операционной системе Windows:
- Допускается использование имён, длиной до 255 символов.
- Можно использовать прописные и строчные буквы латинского и национальных алфавитов, цифры, пробелы и некоторые символы.
- Нельзя использовать символы: \ / : * ? “ < > |.
- Не различаются прописные и строчные буквы в имени.
ОС Linux отличается тем, что различаются прописные и строчные буквы в имени, нельзя использовать символ \, а символы / : * ? “ < > | следует использовать с осторожностью, так как некоторые из них могут иметь специальный смысл, а также из соображений совместимости с другими ОС. Имя файла состоит из собственного имени (даем его мы) и расширения. Расширения файлам, как правило, даются автоматически программами, в которых они создаются; существует ряд стандартных расширений, по которым можно узнать тип файла и программу, в которой их можно открыть. Файловая система — часть операционной системы, определяющая способ организации, хранения и именования данных на носителе информации.
Файловые системы решают следующие задачи:
— определяют правила построения имён файлов и каталогов,
— поддерживают программный интерфейс работы с файлами для приложений,
— определяют порядок размещения файлов на диске,
— обеспечивают защиту данных в случае сбоев и ошибок,
— обеспечивают установку прав доступа к данным для каждого конкретного пользователя,
— обеспечивают совместную работу с файлами.
В операционных системах Windows распространены две файловые системы: FAT32 и NTFS. В ОС Linux применяются ext2fs и ext3fs.
Файлы хранятся на дисках, которые именуются, начиная с латинской буквы С. Файл, представляемый нами как единое целое, на самом деле может быть разбросан «кусочками» по всему диску. Минимальный размер такого «кусочка» (кластера, блока) — от 512 байт до 64 Кбайт в зависимости от используемой файловой системы. При размещении на диске каждому файлу отводится целое число кластеров.
Защита данных во время сбоев, ошибок
Эта функция обеспечивается за счёт журналирования, суть которого состоит в следующем:
- Перед началом выполнения операций с файлами ОС записывает (сохраняет) список действий, которые она будет проводить с файловой системой; эти записи хранятся в отдельной части файловой системы, называемой журналом.
- Как только изменения файловой системы внесены в журнал, она применяет эти изменения к файлам, после чего удаляет эти записи из журнала.
- Если во время выполнения операций с файлами произошёл сбой, то по записям в журнале можно определить пострадавшие файлы и восстановить их.
Совокупность файлов на диске и взаимосвязей между ними называют файловой структурой диска. Первоначально файловые системы поддерживали только одноуровневые файловые структуры: все файлы хранились в одном каталоге. Для хранения большого количества файлов используются иерархические (многоуровневые) файловые структуры: файлы группируются в каталоги, каталоги могут группироваться в каталоги более высокого уровня. Графическое изображение иерархической файловой структуры называется деревом. Чтобы обратиться к нужному файлу, хранящемуся на некотором диске, можно указать путь (адрес каталога) — набор символов, показывающий расположение файла в файловой системе. Полное имя файла — запись пути к файлу, завершаемая именем файла. Сначала записывают диск, затем все папки, в которых он находится, разделяя их символом «\» и после записывают файл. Современные операционные системы имеют специальные инструменты, позволяющие достаточно быстро находить нужные файлы даже в том случае, когда точно не известно их расположение. Для поиска файла можно воспользоваться маской имени файла. Маска — это обозначение для группы файлов.
Используют два символа:
— Символ «?» (вопросительный знак) означает, что на его месте в имени файла должен быть ровно один произвольный (из допустимых) символ.
— Символ «*» (звёздочка) означает, что на его месте в имени файла может быть последовательность любых допустимых символов произвольной длины, в том числе и пустая последовательность.
Давайте рассмотрим пример: Какие файлы будут найдены по маске?
*.* — все файлы;
?????.doc — файлы имеют пять символов в собственном имени и с расширением .doc;
*.jpg — любое собственное имя с расширением jpg;
doc*.* — имя обязательно начинается на doc, но дальше могут стоять любое количество символов и расширение любое.
Давайте рассмотрим задачу
В каталоге находятся 6 файлов:
motors.dat
torsten.docx
motors.doc
victoria.docx
storch.doc
x_torero.doc
Определите, по какой из перечисленных масок из этих 6 файлов будет отобрана указанная группа файлов:
motors.doc
storch.doc
victoria.docx
x_torero.doc
- *tor?*.d* 2) ?tor*.doc 3) *?tor?*.do* 4) *tor?.doc*
Решение: Выясним, какие группы файлов позволит выбрать каждая из масок. Результаты анализа представим в таблице:
Если файл соответствует маске, то в ячейке, находящейся на пересечении строки с именем файла и столбца с именем маски, будем ставить «+», иначе — «–». В столбце искомой маски, знаки «+» должны соответствовать отобранным файлам, знаки «–» — всем прочим. Анализируя маску *tor?*.d*, ставим знак «+» в ячейку, соответствующую файлу motors.dat. Данная маска позволяет отобрать файл, который не входит в интересующую нас группу, следовательно, она не может обеспечить отбор нужных файлов. Дальнейшее рассмотрение этой маски можно прекратить. Маска ?tor*.doc не позволит отобрать файл motors.dat, но она же не позволит отобрать и подлежащий отбору файл motors.doc. Следовательно, дальнейшее рассмотрение этой маски можно прекратить. Маска *?tor?*.do* позволяет отобрать только те файлы, которые нам нужны. Её можно использовать для решения задачи. Но, возможно, задача имеет не одно решение. Проверяем маску *tor?.doc*. Она не позволит нам отобрать файл storch.doc. Итак, решением задачи может быть только третья маска *?tor?*.do*
Итак, сегодня вы узнали про программное обеспечение (ПО). Оно бывает: системное (работает системный администратор), системы программирования (работают программисты), прикладное (работают все пользователи). Узнали, что системное ПО разделяется на операционную систему и сервисные программы (утилиты). Основные компоненты операционной системы — это управление устройствами, управление процессами, пользовательский интерфейс и работа с файлами. Для работы с файлами есть файловые системы. Программы, с помощью которых пользователь может работать с разными видами информации, не прибегая к программированию, принято называть прикладными программами (приложениями). Приложения общего назначения требуются практически всем. Приложения специального назначения предназначены для профессионального применения квалифицированными пользователями.
Тренировочный модуль.
1 задание
Соедините стрелками. Укажите, в какой программе создан файл.
Проверь себя:
2 задание
Реши кроссворд «Программное обеспечение».
- Программы, с помощью которых пользователь может работать с разными видами информации, не прибегая к программированию.
- Специальная программа для подключения внешних устройств.
- Важный этап в разработке новой программы.
- Файл с расширением bmp — это …
- Прикладное ПО для просмотра веб-страниц.
- Поименованная совокупность данных определённого размера, размещаемая на внешних устройствах.
- Человек, создающий новые программы.
- ПО, которое обеспечивает согласованную работу всех узлов компьютера.
- Какая файловая структура применяется в современных компьютерах?
- Программа, которая преобразует исходные тексты программ в машинный код.
- Минимальный элемент информации на жестком диске.
Проверь себя:
3 задание
Определите, какое из указанных имен файлов удовлетворяет маске:
?ba*r.?xt
- bar.txt
- obar.txt
- obar.xt
- barr.txt
Решение: первый и четвёртый варианты ответа отпадают, поскольку в них нет ни одного символа перед слогом «ba». Третий вариант отпадает из-за того, что между точкой и «xt» нет ни одного символа. Остаётся второй вариант, он полностью соответствует маске: первому слева знаку вопроса сопоставляется «о», звёздочке — пустая последовательность, второму знаку вопроса — «t». Ответ: 2.
Настройка каталогов классов :: классы и объекты (программирование)
Настройка каталогов классов :: классы и объекты (программирование)| Программирование |
Настройка каталогов классов
M-файлы, определяющие методы для класса, собираются вместе в каталоге, называемом каталогом классов. Имя каталога формируется из имени класса, которому предшествует символ @. Например, один из примеров, используемых в этой главе, — это класс, включающий многочлены от одной переменной.Имя класса и имя конструктора класса — полином . M-файлы, определяющие класс полинома, будут расположены в каталоге с именем @polynom .
Каталоги классов являются подкаталогами каталогов на пути поиска MATLAB, но сами не находятся на пути. Например, t новый каталог @polynom может быть подкаталогом рабочего каталога MATLAB или вашим личным каталогом, который был добавлен к пути поиска.
Добавление каталога классов к пути MATLAB
После создания каталога классов необходимо обновить путь MATLAB, чтобы MATLAB мог найти исходные файлы класса. Каталог классов не должен находиться непосредственно на пути MATLAB. Вместо этого вы должны добавить родительский каталог к пути MATLAB. Например, если каталог классов @polynom расположен по адресу
, вы добавляете каталог классов к пути MATLAB с помощью команды addpath
Использование нескольких каталогов классов
Класс MATLAB может обращаться к методам в нескольких каталогах @ classname , если все такие каталоги видимы для MATLAB (т.е.е., родительские каталоги находятся на пути MATLAB или в текущем каталоге). Когда вы пытаетесь использовать метод класса, MATLAB ищет соответствующий метод во всех видимых каталогах с именем @ имя класса .
Для получения дополнительной информации см. Как MATLAB определяет, какой метод вызывать.
Структура данных
Одним из первых шагов в разработке нового класса является выбор структуры данных, которая будет использоваться классом.Объекты хранятся в структурах MATLAB. Поля структуры и детали операций с полями видны только внутри методов класса. Дизайн соответствующей структуры данных может повлиять на производительность кода.
| Методы класса отладки | Советы для программистов на C ++ и Java |
© 1994-2005 The MathWorks, Inc.
Папки, содержащие определения классов — MATLAB & Simulink
Папки, содержащие определения классов
Определения классов на пути
Чтобы вызвать метод класса, определение класса должно быть на пути MATLAB ® , как описано в следующих разделах.
Папки классов и путей
Есть два типа папок, которые могут содержать файлы определения классов.
Папки пути — папка находится на пути MATLAB, и имя папки не начинается с
@персонаж. Используйте этот тип папки, если вам нужно несколько классов и функций в одна папка. Все определение класса должно содержаться в одном файле.Папки классов — имя папки начинается с символа @, за которым следует имя класса.Папка не находится на пути MATLAB, но ее родительская папка находится на пути. Используйте этот тип папки, если вы хотите использовать несколько файлов для одного определения класса.
См. Функцию path для информации о пути MATLAB.
Использование папок пути
Папки, которые содержат файлы определения класса, находятся на пути MATLAB. Следовательно, определения классов, помещенные в папки пути, ведут себя как любые обычная функция в отношении приоритета — первое вхождение имени в путь MATLAB имеет приоритет над всеми последующими вхождениями того же имени.
Имя каждого файла определения класса должно совпадать с именем класса, указанного с помощью ключевого слова classdef . Использование папки пути избавляет от необходимости создавать отдельную папку класса для каждого класса. Однако все определение класса, включая все методы, должно содержаться в одном файле.
Предположим, что у вас есть три класса, определенные в одной папке:
... / path_folder / MyClass1.m ... / папка_путь / MyClass2.m ... / папка_путь / MyClass3.м
Чтобы использовать эти классы, добавьте path_folder к вашему пути MATLAB:
Использование папок классов
Имя папки класса всегда начинается с символа @ за которым следует имя класса для имени папки. Папка класса должна содержаться в
папка пути, но папка класса не находится на пути MATLAB. Поместите файл определения класса в папку классов, которая также
может содержать отдельные файлы методов. Файл определения класса должен иметь то же имя, что и
папка класса (без символа @ ).
... / parent_folder/@MyClass/MyClass.m ... / parent_folder/@MyClass/myMethod1.m ... / parent_folder/@MyClass/myMethod2.m
Определите только один класс для каждой папки. Все файлы имеют .m или .p расширение. Для версий MATLAB R2018a и более поздних автономные методы могут быть живыми функциями с .mlx расширение.
Используйте папку класса, если вы хотите использовать более одного файла для определения вашего класса. MATLAB обрабатывает любой файл функции в папке класса как метод класса.Функциональные файлы могут быть кодом MATLAB ( .m ), форматом файла Live Code ( .mlx ), функциями MEX (расширениями, зависящими от платформы) и файлами P-кода ( .p ).
MATLAB явно идентифицирует любой файл в папке класса как метод этого класс. Это позволяет вам использовать более модульный подход к методам разработки ваших класс.
Базовое имя каждого файла должно быть действительным именем функции MATLAB. Допустимые имена функций начинаются с буквенного символа и могут содержать буквы, цифры или символы подчеркивания.Для получения дополнительной информации см. Методы в отдельных файлах.
Функции в личных папках в папках классов
Личные папки содержат функции, которые доступны только из функций, определенных в
папки непосредственно над частной папкой . Любые функции определены
в частной папке внутри папки класса можно вызвать только из
методы класса. Функции имеют доступ к закрытым членам класса, но
сами по себе не методы.Они не требуют передачи объекта в качестве входных данных и
может быть вызван только с использованием обозначения функций. Использование функций в частном папок, когда вам нужны вспомогательные функции, которые можно вызывать из нескольких методов вашего
класс.
Если папка класса содержит частную папку , только класс, определенный в этой папке, может получить доступ к функциям, определенным в частной папке . Подклассы не имеют доступа к закрытым функциям суперкласса.Дополнительные сведения о личных папках см. В разделе «Частные функции».
Если вы хотите, чтобы подкласс имел доступ к закрытым функциям суперкласса, определите функции как защищенные методы суперкласса. Укажите методы с атрибутом Access , для которого установлено значение protected .
Отправка методам в частных папках
Если класс определяет функции в частной папке , которая находится в
class, тогда MATLAB следует этим правилам приоритета при отправке в частный
функции по сравнению с методами файла classdef :
Использование точечной нотации (
obj.methodName), функция в частной папкеclassdef.Использование обозначения функции (
methodName (obj)), a метод, определенный в файлеclassdef, имеет приоритет над функция в частной папке
Нет определений классов в личных папках
Нельзя помещать определения классов (файл classdef ) в личные папки, потому что это не соответствует требованиям для папок классов или путей.
Приоритет класса и путь к MATLAB
Когда есть несколько определений классов с тем же именем, расположение файла на путь MATLAB определяет приоритет. Определение класса в папке, которая идет first на пути MATLAB всегда имеет приоритет над любыми классами, которые находятся позже на пути, независимо от того, содержатся ли определения в папке класса.
Функция с тем же именем, что и класс в папке пути, имеет приоритет над class, если функция находится в папке, которая находится раньше по пути.Однако класс определенный в папке класса (@ -folder) имеет приоритет над одноименной функцией, даже если функция определена в папке, которая находится раньше по пути.
Например, рассмотрим путь со следующими папками и файлами.
| Порядок в пути | Папка и файл | Определение файла |
|---|---|---|
1 | | Класс |
2 | | Функция |
3 87 | 12 @ Foo / Foo.m | Class |
4 | | Метод |
5 | | Class |
MATLAB применяет эту логику, чтобы определить, какая версия Foo будет
вызов:
Класс fldr1 / Foo.m имеет приоритет над классом fldr3 / @ Foo , потому что:
Класс fldr3 / @ Foo имеет приоритет над функцией fldr2 / Foo.m , потому что:
fldr3 / @ Foo— это класс в папке классов.fldr2 / Foo.мэто не класс.Классы в папках классов имеют приоритет над функциями.
Функция fldr2 / Foo.m имеет приоритет над классом fldr5 / Foo.m , потому что:
fldr2предшествует классуfldr5на дорожка.fldr5 / Foo.mотсутствует в папке класса.Классы, которые не определены в папках классов, подчиняются порядку путей по отношению к функциям.
Класс fldr3 / @ Foo имеет приоритет над fldr4 / @ Foo , потому что:
Если fldr3/@Foo/Foo.m содержит класс MATLAB, созданный до Версии 7.6 (то есть класс не использует classdef ключевое слово), затем fldr4/@Foo/bar.m становится методом класса Foo , определенного в fldr3 / @ Foo .
Предыдущее поведение классов, определенных в папках классов
В версиях MATLAB с 5 по 7 папки классов не затеняют другие папки классов, имеющие то же имя, но находящиеся в более поздних папках пути.Вместо этого класс использует комбинацию методов из всех папок классов с одинаковыми именами для определения класса. Такое поведение больше не поддерживается.
Для обратной совместимости классы, определенные в папках классов, всегда имеют приоритет над функциями и сценариями с тем же именем. Этот приоритет применяется к функциям и скриптам, которые идут перед этими классами на пути.
Изменение пути к обновлению определения класса
MATLAB может распознавать только одно определение класса как текущее определение.Изменение вашего пути MATLAB может изменить файл определения для класса (см. Путь ). Если экземпляров старого определения не существует (т. Е.
определение, которое больше не является первым на пути), MATLAB немедленно распознает новую папку как текущее определение. Если,
однако у вас есть существующий экземпляр класса до изменения пути, независимо от того,
MATLAB использует определение в новой папке, зависит от того, как новый класс
был определен.Если новое определение определено в папке класса, MATLAB немедленно распознает новую папку как определение текущего класса.
Однако для классов, определенных в папках пути (то есть не в классе @ папок), вы должны очистить класс до того, как MATLAB распознает новую папку как определение текущего класса.
Определения классов в папках классов
Предположим, вы определяете две версии класса с именем Foo в двух папках: fldA и fldB .
fldA/@Foo/Foo.m fldB/@Foo/Foo.m
Добавьте папку fldA в начало пути.
Создайте экземпляр класса Foo . MATLAB использует fldA/@Foo/Foo.m в качестве определения класса.
Измените текущую папку на fldB .
Текущая папка всегда первая в пути. Следовательно, MATLAB находит fldB/@Foo/Foo.m как определение для класса Фу .
MATLAB автоматически обновляет существующий экземпляр, a , чтобы использовать определение нового класса в fldB .
Определения классов в папках пути
Предположим, вы определяете две версии класса с именем Foo в двух папках, fldA и fldB , но не используете папку классов.
Добавьте папку fldA в начало пути.
Создайте экземпляр класса Foo . MATLAB использует fldA / Foo.m в качестве определения класса.
Измените текущую папку на fldB .
Текущая папка фактически является верхней частью пути.Однако MATLAB не идентифицирует fldB / Foo.m как определение для
класс Foo . MATLAB продолжает использовать определение исходного класса, пока вы не очистите
класс.
Чтобы использовать определение Foo в foldB , очистите Фу .
MATLAB автоматически обновляет существующие объекты, чтобы соответствовать определению класса в fldB . Обычно в очистке переменных экземпляра нет необходимости.
См. Также
Создание, копирование, переименование и удаление файлов и каталогов Unix
В этом документе перечислены команды для создания, копирования, переименования и удаления файлов и каталогов Unix. Предполагается, что вы используете Unix в ITS Login Service (login.itd.umich.edu). Приведенные здесь инструкции применимы ко многим другим машинам Unix; однако вы можете заметить другое поведение, если не используете ITS Login Service.
Что такое файлы и каталоги Unix?
Файл — это «контейнер» для данных.Unix не делает различий между типами файлов — файл может содержать текст документа, данные для программы или саму программу.
Каталогипозволяют организовать файлы, позволяя группировать связанные файлы вместе. Каталоги могут содержать файлы и / или другие каталоги. Каталоги аналогичны папкам Macintosh и Windows.
Именование файлов и каталогов Unix
У каждого файла и каталога есть имя. Внутри каталога каждый элемент (то есть каждый файл или каталог) должен иметь уникальное имя, но элементы с таким же именем могут существовать более чем в одном каталоге.Каталог может иметь то же имя, что и один из содержащихся в нем элементов.
Имена файлов и каталогов могут содержать до 256 символов. В именах можно использовать практически любые символы (кроме пробела). Вы можете разделить имя файла, состоящее из нескольких слов, с помощью подчеркивания или точки (например, chapter_one или chapter.two ).
Некоторые символы имеют особое значение для Unix. Лучше избегать использования этих символов в именах файлов:
/ \ «‘* |!? ~ $ <>
Unix чувствителен к регистру.Каждый из них представляет собой уникальный файл: myfile, Myfile, myFile, и MYFILE .
Создание файла
Многие люди создают файлы с помощью текстового редактора, но вы можете использовать команду cat для создания файлов без использования / обучения использованию текстового редактора. Чтобы создать файл практики (с именем firstfile ) и ввести в него одну строку текста, введите в командной строке % следующее:
cat> firstfile
(Нажмите клавишу Enter / Return .D
Чтобы проверить содержимое только что созданного файла, введите это в командной строке % :
cat firstfile
Копирование файла
Чтобы сделать дубликат файла, используйте команду cp . Например, чтобы создать точную копию файла с именем firstfile, вы должны ввести:
cp firstfile secondfile
В результате получается два файла с разными именами, каждый из которых содержит одинаковую информацию.Команда cp работает путем перезаписи информации. Если вы создаете другой файл с именем thirdfile , а затем набираете следующую команду:
cp третий файл первый файл
, вы обнаружите, что исходное содержимое firstfile исчезло, оно заменено содержимым третьего файла .
Переименование файла
Unix не имеет специальной команды для переименования файлов. Вместо этого команда mv используется как для изменения имени файла, так и для перемещения файла в другой каталог.
Чтобы изменить имя файла, используйте следующий формат команды (где thirdfile и file3 — это имена файлов примеров):
mv третий файл file3
Эта команда приводит к полному удалению третьего файла , но новый файл с именем файл3 содержит предыдущее содержимое третьего файла .
Как и cp, , команда mv также перезаписывает существующие файлы. Например, если у вас есть два файла, , четвертый файл, и , второй файл, , и вы набираете команду
mv 4thfile secondfile
mv удалит исходное содержимое второго файла и заменит его содержимым четвертого файла .В результате четвертый файл переименовывается в второй файл , но в процессе второй файл удаляется.
Удаление файла
Используйте команду rm для удаления файла. Например,
rm файл3
удаляет файл3 и его содержимое. Вы можете удалить более одного файла за раз, указав список файлов для удаления. Например,
rm firstfile secondfile
Вам будет предложено подтвердить, действительно ли вы хотите удалить файлы:
rm: удалить первый файл (да / нет)? y
rm: удалить второй файл (да / нет)? n
Введите y или да , чтобы удалить файл; введите № или № , чтобы оставить его нетронутым.
Создание каталога
Создание каталогов позволяет вам организовать свои файлы. Команда
мкдир проект1
создает каталог с именем project1, , где вы можете хранить файлы, относящиеся к конкретному проекту. Созданный вами каталог будет подкаталогом в вашем текущем каталоге. Для получения подробной информации о том, как перемещаться по каталогам и отображать файлы и каталоги, которые они содержат, см. Список содержимого и Навигация по каталогам Unix.
Перемещение и копирование файлов в каталог
Команды mv и cp могут использоваться для помещения файлов в каталог. Предположим, вы хотите поместить некоторые файлы из текущего каталога во вновь созданный каталог с именем project1. Команда
мв библиографический проект1
переместит файл bibliography в каталог project1 . Команда
cp chapter1 project1
поместит копию файла chapter1 в каталог project1 , но оставит chapter1 без изменений в текущем каталоге.Теперь будет две копии chapter1 , одна в текущем каталоге и одна в project1 .
Переименование каталога
Вы также можете использовать команду mv для переименования и перемещения каталогов. При вводе команды
мв проект1 проект2
каталогу с именем project1 будет присвоено новое имя project2 , если каталог с именем project2 ранее не существовал.Если каталог project2 уже существовал до того, как была введена команда mv,
мв проект1 проект2
переместит каталог project1 и его файлы в каталог project2.
Копирование каталога
Вы можете использовать команду cp для создания дублирующей копии каталога и его содержимого. Чтобы скопировать каталог project1 в каталог proj1copy, например, , вы должны ввести
cp -r project1 proj1copy
Если каталог proj1copy уже существует, эта команда поместит дубликат каталога project1 в каталог proj1copy \ .
Удаление каталога
Используйте команду rmdir , чтобы удалить пустой каталог. Несколько пустых каталогов можно удалить, указав их после команды:
rmdir testdir1 testdir2
Если вы попытаетесь удалить каталог, который не пуст, вы увидите
rmdir: testdir3: Каталог не пустой
Если вы уверены, что хотите удалить каталог и все файлы, которые в нем содержатся, используйте команду
rm -r testdir3
Сводка команд
Работа с файлами
mv file1 file2
Переименовывает file1 в file2 (если file2 существовало ранее, перезаписывает исходное содержимое file2 ).cp file1 file2
Копирует file1 как file2 (если ранее существовало file2 , перезаписывает исходное содержимое file2 ).rm file3 file4
Удаляет file3 и file4, запрашивает подтверждение для каждого удаления.
Работа с каталогами
mkdir dir1
Создает новый каталог с именем dir1.mv dir1 dir2
Если dir2 не существует, переименовывает dir1 в dir2.
Если существует dir2 , перемещает dir1 внутрь dir2.cp -r dir1 dir2
Если dir2 не существует, копирует dir1 как dir2.
Если dir2 действительно существует, копирует dir1 внутри dir2.rmdir dir1
Удаляет dir1, , если dir1 не содержит файлов.rm -r dir1
Удаляет dir1 и все файлы, которые он содержит. Используйте с осторожностью.
Работа с файлами и каталогами
java — Что означает «Не удалось найти или загрузить основной класс»?
Синтаксис команды
java <имя-класса> Прежде всего, вам необходимо понять, как правильно запускать программу с помощью команды java (или javaw ).
Нормальный синтаксис 1 таков:
java [<параметры>] <имя-класса> [<аргумент>...]
, где <опция> — это параметр командной строки (начинающийся с символа «-»), <имя-класса> — полное имя класса Java, а — произвольный аргумент командной строки, который передается в ваше приложение.
1 — Есть некоторые другие синтаксисы, которые описаны в конце этого ответа.
Полное имя (FQN) класса обычно записывается так же, как в исходном коде Java; е.грамм.
packagename.packagename2.packagename3.ClassName
Однако некоторые версии команды java позволяют использовать косую черту вместо точек; например
packagename / packagename2 / packagename3 / ClassName
, который (сбивает с толку) выглядит как путь к файлу, но не является таковым. Обратите внимание, что термин полностью определенное имя является стандартной терминологией Java … не то, что я придумал, чтобы вас запутать 🙂
Вот пример того, как должна выглядеть команда java :
java -Xmx100m com.acme.example.ListUsers Фред Джо Берт
Вышеупомянутое приведет к тому, что команда java выполнит следующее:
- Найдите скомпилированную версию класса
com.acme.example.ListUsers. - Загрузите класс.
- Убедитесь, что класс имеет метод
mainс сигнатурой , тип возврата и модификаторы , заданные общедоступным статическим void main (String []) . (Обратите внимание, что имя аргумента метода — НЕ часть подписи.) - Вызовите этот метод, передав ему аргументы командной строки («fred», «joe», «bert») в виде строки
String [].
Причины, по которым Java не может найти класс
Когда вы получаете сообщение «Не удалось найти или загрузить основной класс …», это означает, что первый шаг завершился неудачно. Команде java не удалось найти класс. И действительно, «…» в сообщении будет полностью определенным именем класса , который ищет java .
Так почему же он не может найти класс?
Причина № 1 — вы ошиблись с аргументом имени класса
Первая вероятная причина в том, что вы указали неправильное имя класса. (Или … правильное имя класса, но в неправильной форме.) Рассматривая приведенный выше пример, вот несколько неправильных способов указать имя класса:
Пример # 1 — простое имя класса:
Java ListUserКогда класс объявлен в пакете, например
com.acme.example, тогда вы должны использовать полное имя класса , включая имя пакета в командеjava; напримерjava com.acme.example.ListUserПример # 2 — имя файла или путь, а не имя класса:
java ListUser.class java com / acme / example / ListUser.classПример №3 — неверное имя класса с регистром:
java com.acme.example.listuserПример №4 — опечатка
java com.acme.example.mistuserПример # 5 — имя исходного файла (кроме Java 11 или новее; см. Ниже)
java ListUser.javaПример # 6 — вы полностью забыли имя класса
java много аргументов
Причина №2 — неверно указан путь к классам приложения
Вторая вероятная причина заключается в том, что имя класса правильное, но команда java не может найти класс.Чтобы понять это, вам нужно понять концепцию «пути к классам». Это объясняется скважиной в документации Oracle:
Итак … если вы правильно указали имя класса, следующее, что нужно проверить, это правильно ли вы указали путь к классам:
- Прочтите три документа, ссылки на которые приведены выше. (Да … ПРОЧИТАЙТЕ их! Важно, чтобы Java-программист понимал , по крайней мере, основы работы механизмов пути к классам Java.)
- Посмотрите на командную строку и / или переменную среды CLASSPATH, которая действует при запуске команды
java.Убедитесь, что имена каталогов и файлов JAR верны. - Если в пути к классам есть относительных путей , убедитесь, что они разрешаются правильно … из текущего каталога, который действует при запуске команды
java. - Убедитесь, что класс (упомянутый в сообщении об ошибке) может быть расположен на эффективном пути к классам .
- Обратите внимание, что синтаксис пути к классам отличается от для Windows и Linux и Mac OS.(Разделитель пути к классам —
;в Windows и:в остальных. Если вы используете неправильный разделитель для своей платформы, вы не получите явного сообщения об ошибке. Вместо этого вы получите несуществующий файл или каталог на путь, который будет автоматически проигнорирован.)
Причина № 2а — неправильный каталог находится в пути к классам
Когда вы помещаете каталог в путь к классам, он условно соответствует корню квалифицированного пространства имен. Классы расположены в структуре каталогов под этим корнем, , путем сопоставления полного имени с именем пути .Так, например, если «/ usr / local / acme / classes» находится на пути к классу, тогда, когда JVM ищет класс с именем com.acme.example.Foon , она будет искать файл «.class» с этим путем:
/usr/local/acme/classes/com/acme/example/Foon.class
Если бы вы поместили «/ usr / local / acme / classes / com / acme / example» в путь к классам, JVM не смогла бы найти класс.
Причина № 2b — путь к подкаталогу не соответствует FQN
Если FQN вашего класса ком.acme.example.Foon , тогда JVM будет искать «Foon.class» в каталоге «com / acme / example»:
Если ваша структура каталогов не соответствует названию пакета согласно приведенному выше шаблону, JVM не найдет ваш класс.
Если вы попытаетесь переименовать класс в , переместив его, это тоже не удастся … но трассировка стека исключений будет другой. Можно сказать что-то вроде этого:
Вызвано: java.lang.NoClassDefFoundError: <путь> (неправильное имя: <имя>), потому что FQN в файле класса не соответствует тому, что загрузчик классов ожидает найти.
Чтобы дать конкретный пример, предположим, что:
- вы хотите запустить
com.acme.example.Foonclass, - полный путь к файлу:
/usr/local/acme/classes/com/acme/example/Foon.class, - ваш текущий рабочий каталог —
/ usr / local / acme / classes / com / acme / example /,
, затем:
# неверно, необходим FQN
Java Foon
# неверно, в текущем рабочем каталоге нет папки com / acme / example
java com.acme.example.Foon
# неверно, похоже на выше
java -classpath. com.acme.example.Foon
# отлично; относительный путь к классам установлен
java -classpath ../../ .. com.acme.example.Foon
# отлично; абсолютный путь к классам установлен
java -classpath / usr / local / acme / classes com.acme.example.Foon
Примечания:
- Параметр
-classpathможет быть сокращен до-cpв большинстве выпусков Java. Проверьте соответствующие ручные записи дляjava,javacи так далее. - Тщательно подумайте, выбирая между абсолютными и относительными путями в путях к классам.Помните, что относительный путь может «сломаться» при изменении текущего каталога.
Причина № 2c — в пути к классам отсутствуют зависимости
Путь к классам должен включать все других (несистемных) классов, от которых зависит ваше приложение. (Системные классы располагаются автоматически, и вам редко нужно этим заниматься.) Для правильной загрузки основного класса JVM должна найти:
(Примечание: спецификации JLS и JVM позволяют JVM в некоторой степени загружать классы «лениво», и это может повлиять на возникновение исключения загрузчика классов.)
Причина №3 — класс был объявлен в неправильном пакете
Иногда случается, что кто-то помещает файл с исходным кодом в
неправильная папка в дереве исходного кода, или они не учитывают декларацию пакета . Если вы сделаете это в IDE, компилятор IDE немедленно сообщит вам об этом. Точно так же, если вы используете достойный инструмент сборки Java, инструмент будет запускать javac таким образом, чтобы обнаружить проблему. Однако, если вы создадите свой Java-код вручную, вы можете сделать это таким образом, чтобы компилятор не заметил проблему и ее результат ».class «находится не в том месте, где вы ожидали.
Все еще не можете найти проблему?
Тут есть что проверить, и легко что-то упустить. Попробуйте добавить параметр -Xdiag в командную строку java (в первую очередь после java ). Он выведет различные сведения о загрузке классов, и это может предложить вам ключ к пониманию реальной проблемы.
Также рассмотрите возможные проблемы, вызванные копированием и вставкой невидимых или не-ASCII символов с веб-сайтов, документов и т. Д.И рассмотрим «гомоглифы», где две буквы или символы выглядят одинаково … но не являются.
Наконец, вы, по-видимому, можете столкнуться с этой проблемой, если попытаетесь запустить из файла JAR с неправильными подписями в (META-INF / *. SF) или если есть синтаксическая ошибка в файле MANIFEST.MF ( см. https://stackoverflow.com/a/67145190/139985).
Альтернативный синтаксис для
java Существует три альтернативных синтаксиса для запуска программ Java с помощью команды java .
Для запуска «исполняемого» файла JAR используется следующий синтаксис:
java [<параметры>] -jar <имя-файла-jar> [<аргумент> ...]например
java -Xmx100m -jar /usr/local/acme-example/listuser.jar ФредИмя класса точки входа (например,
com.acme.example.ListUser) и путь к классам указаны в МАНИФЕСТЕ файла JAR.Синтаксис для запуска приложения из модуля (Java 9 и новее) следующий:
java [<параметры>] --module <модуль> [/ <основной класс>] [<аргумент>...]Имя класса точки входа либо определяется самим
Начиная с Java 11, вы можете скомпилировать и запустить один файл исходного кода и запустить его со следующим синтаксисом:
java [<параметры>] <исходный файл> [<аргумент> ...], где
Для получения дополнительных сведений см. Официальную документацию по команде java для используемой версии Java.
IDE
Типичная Java IDE поддерживает запуск приложений Java в самой JVM IDE или в дочерней JVM. Это , как правило, невосприимчивы к этому конкретному исключению, потому что IDE использует свои собственные механизмы для создания пути к классам среды выполнения, идентификации основного класса и создания командной строки java .
Однако это исключение все еще возможно, если вы делаете что-то за спиной IDE. Например, если вы ранее настроили средство запуска приложений для своего Java-приложения в Eclipse, а затем переместили файл JAR, содержащий «основной» класс, в другое место в файловой системе , не сообщая Eclipse , Eclipse непреднамеренно запустит JVM с неправильным путем к классам.
Короче говоря, если у вас возникла эта проблема в среде IDE, проверьте такие вещи, как устаревшее состояние IDE, неработающие ссылки на проекты или неверные конфигурации средства запуска.
IDE также может просто запутаться. IDE — это чрезвычайно сложные программные продукты, состоящие из множества взаимодействующих частей. Многие из этих частей используют различные стратегии кэширования, чтобы сделать среду IDE отзывчивой. Иногда они могут пойти не так, и одним из возможных симптомов являются проблемы при запуске приложений. Если вы подозреваете, что это могло произойти, стоит попробовать другие вещи, такие как перезапуск IDE, пересборка проекта и т. Д.
Прочие ссылки
Управление каталогами и файлами Python
Справочник Python
Если в нашей программе Python требуется обрабатывать большое количество файлов, мы можем расположить наш код в разных каталогах, чтобы упростить управление.
Каталог или папка — это набор файлов и подкаталогов. В Python есть модуль os , который предоставляет нам множество полезных методов для работы с каталогами (а также с файлами).
Получить текущий каталог
Мы можем получить текущий рабочий каталог, используя метод getcwd () модуля os .
Этот метод возвращает текущий рабочий каталог в виде строки. Мы также можем использовать метод getcwdb () , чтобы получить его как байтовый объект.
>>> импорт ОС
>>> os.getcwd ()
'C: \ Program Files \ PyScripter'
>>> os.getcwdb ()
b'C: \ Program Files \ PyScripter ' Дополнительная обратная косая черта подразумевает escape-последовательность. Функция print () отрендерит это правильно.
>>> печать (os.getcwd ())
C: \ Program Files \ PyScripter Смена каталога
Мы можем изменить текущий рабочий каталог с помощью метода chdir () .
Новый путь, который мы хотим изменить, должен быть передан этому методу в виде строки. Мы можем использовать как прямую косую черту /, так и обратную косую черту \ для разделения элементов пути.
Безопаснее использовать escape-последовательность при использовании обратной косой черты.
>>> os.chdir ('C: \\ Python33')
>>> печать (os.getcwd ())
C: \ Python33 Список каталогов и файлов
Все файлы и подкаталоги внутри каталога можно получить с помощью метода listdir () .
Этот метод принимает путь и возвращает список подкаталогов и файлов по этому пути. Если путь не указан, возвращается список подкаталогов и файлов из текущего рабочего каталога.
>>> печать (os.getcwd ())
C: \ Python33
>>> os.listdir ()
['DLL',
"Док",
'включать',
'Lib',
'библиотеки',
"LICENSE.txt",
"NEWS.txt",
'python.exe',
'pythonw.exe',
'README.txt',
'Скрипты',
'tcl',
'Инструменты']
>>> os.listdir ('G: \\')
['$ RECYCLE.BIN',
'Кино',
'Музыка',
'Фотографии',
'Ряд',
«Информация о системном объеме»] Создание нового каталога
Мы можем создать новый каталог, используя метод mkdir () .
Этот метод принимает путь к новому каталогу. Если полный путь не указан, новый каталог создается в текущем рабочем каталоге.
>>> os.mkdir ('тест')
>>> os.listdir ()
['test'] Переименование каталога или файла
Метод rename () может переименовать каталог или файл.
Для переименования любого каталога или файла метод rename () принимает два основных аргумента: старое имя в качестве первого аргумента и новое имя в качестве второго аргумента.
>>> os.listdir ()
['контрольная работа']
>>> os.rename ('test', 'new_one')
>>> os.listdir ()
['new_one'] Удаление каталога или файла
Файл можно удалить (удалить) с помощью метода remove () .
Аналогично, метод rmdir () удаляет пустой каталог.
>>> os.listdir ()
['new_one', 'old.txt']
>>> os.remove ('old.txt')
>>> os.listdir ()
['новый']
>>> os.rmdir ('новый_он')
>>> os.listdir ()
[] Примечание : Метод rmdir () может удалять только пустые каталоги.
Чтобы удалить непустой каталог, мы можем использовать метод rmtree () внутри модуля shutil .
>>> os.listdir ()
['контрольная работа']
>>> os.rmdir ('тест')
Отслеживание (последний вызов последний):
...
OSError: [WinError 145] Каталог не пуст: 'test'
>>> импортный шутиль
>>> шутил.rmtree ('тест')
>>> os.listdir ()
[] Изучение оболочки — Урок 2: Навигация
В этом уроке мы познакомимся с нашими первыми тремя командами: pwd (печать работает
справочник), cd (сменить каталог) и ls (список файлов и каталогов).
Новичкам в командной строке следует обратить на это пристальное внимание. урок, так как концепции потребуют некоторого привыкания.
Организация файловой системы
Как и Windows, файлы в системе Linux организованы в так называемом иерархическая структура каталогов .Это означает, что они организованы в древовидный образец каталогов (называемых папками в других системах), который может содержать файлы и подкаталоги . Первый каталог в файловая система называется корневым каталогом . Корневой каталог содержит файлы и подкаталоги, которые содержат больше файлов и подкаталогов и т. д. и так далее.
Большинство графических сред включают программу файлового менеджера, используемую для просмотра и манипулировать содержимым файловой системы.Часто мы будем видеть файловую систему представлен так:
Одно важное различие между Windows и Unix-подобными операционными системами Например, Linux заключается в том, что Linux не использует концепцию букв дисков. Пока Буквы дисков Windows разбивают файловую систему на несколько разных деревьев. (по одному на каждое устройство), в Linux всегда одно дерево. Различное хранилище устройства могут быть разными ветвями дерева, но всегда есть одиночное дерево.
pwd
Поскольку интерфейс командной строки не может предоставить графические изображения файла структура системы, мы должны иметь другой способ ее представления.Сделать это, Думайте о дереве файловой системы как о лабиринте и о том, что мы находимся в нем. В любом в данный момент мы находимся в едином каталоге. Внутри этого каталога мы может видеть его файлы и путь к его родительскому каталогу и пути к подкаталогам каталога, в котором мы находимся.
Каталог, в котором мы находимся, называется рабочим каталогом . К
смотрим название рабочего каталога, используем pwd команда.
[me @ linuxbox me] долларов в день / главная / я
Когда мы впервые входим в нашу систему Linux, рабочий каталог устанавливается на наш домашний каталог .Сюда мы помещаем наши файлы. В большинстве систем домашний каталог будет называться / home / user_name, но это может быть что угодно по прихоти сисадмина.
Чтобы вывести список файлов в рабочем каталоге, мы используем команду ls .
[me @ linuxbox me] $ ls Загрузки для рабочего стола foo.txt Шаблоны изображений
Документы examples.desktop Музыка Видео в открытом доступе
В следующем уроке мы вернемся к ls .Там
вы можете сделать с ним много забавных вещей, но мы должны поговорить о путях
и каталоги немного вначале.
компакт-диск
Для смены рабочего каталога (где мы стоим в лабиринте) используем
команда cd . Для этого мы набираем cd , а затем путь желаемого рабочего.
каталог. Путь — это путь, который мы идем по ветвям дерева к
попадаем в нужный каталог. Пути можно указать двумя разными способами; абсолютных путей или относительных путей .Посмотрим с
сначала абсолютные пути.
Абсолютный путь начинается с корневого каталога и следует по дереву
переходить за веткой, пока не будет заполнен путь к желаемому каталогу или файлу.
Например, в вашей системе есть каталог, в котором хранится большинство программ.
установлены. Путь к каталогу — / usr / bin . Это означает
из корневого каталога (представлен ведущей косой чертой в имени пути)
есть каталог с именем «usr», который содержит каталог с именем «bin».
Давайте попробуем:
me @ linuxbox me] $ cd / usr / bin me @ linuxbox bin] долларов в день / usr / bin
я @ linuxbox bin] $ ls ‘[‘ mкороткое имя
2to3-2,7 мшоуфат
411toppm mtools
a2ps mtoolstest
a2ps-lpr-обертка mtr
mtrace с поддержкой aa
mtr-пакет aa-exec
aclocal mtvtoppm
aclocal-1.15 метров
связное бормотание
acpi_listen mxtar
add-apt-репозиторий mzip
addpart namei и многое другое …
Теперь мы видим, что мы изменили текущий рабочий каталог на / usr / bin и что он полон файлов. Обратите внимание, как приглашение оболочки
изменилось? Для удобства он обычно настраивается для отображения имени
рабочий каталог.
Где абсолютный путь начинается с корневого каталога и ведет к его destination, относительный путь начинается с рабочего каталога.Сделать это, он использует несколько специальных обозначений для представления относительных позиций в дерево файловой системы. Эти специальные обозначения — «.» (точка) и «..» (точка).
Символ «.» обозначение относится к самому рабочему каталогу и «..» обозначение относится к родительскому каталогу рабочего каталога. Вот как это работает. Давайте снова изменим рабочий каталог на / usr / bin:
me @ linuxbox me] $ cd / usr / bin me @ linuxbox bin] долларов в день / usr / bin
О.К., теперь допустим, что мы хотели изменить рабочий каталог на
родитель / usr / bin , который равен / usr . Мы могли бы сделать это
двумя разными способами. Во-первых, с абсолютным путем:
me @ linuxbox bin] $ cd / usr me @ linuxbox usr] долл. США / usr
Или с относительным путем:
me @ linuxbox bin] $ компакт-диск .. me @ linuxbox usr] долл. США / usr
Два разных метода с одинаковыми результатами. Какой из них мы должны использовать? В тот, который требует меньше всего набора текста!
Аналогичным образом мы можем изменить рабочий каталог с / usr на / usr / bin двумя разными способами.Сначала используя абсолютный
путь:
me @ linuxbox usr] $ cd / usr / bin me @ linuxbox bin] долларов в день / usr / bin
Или с относительным путем:
me @ linuxbox usr] $ cd. / Bin me @ linuxbox bin] долларов в день / usr / bin
Итак, есть кое-что важное, на что мы должны здесь указать. В большинстве случаях мы можем опустить «./». Это подразумевается. Набор:
me @ linuxbox usr] $ корзина для компакт-дисков
сделает то же самое.В общем, если мы не укажем путь к что-то предполагается, что рабочий каталог. Есть одно важное исключение из этого, но мы не будем до этого доходить.
Несколько ярлыков
Если мы введем cd , а затем ничего, cd изменит рабочий каталог на наш домашний
каталог.
Соответствующий ярлык — набрать cd
~ имя_пользователя . В этом случае cd будет
измените рабочий каталог на домашний каталог указанного пользователя.
Набрав cd - меняет рабочий
каталог к предыдущему.
Работа с файлами
Вы можете очень легко распространить предыдущие примеры на несколько файлов, указав несколько аргументов для из () :
Пример 4. Использование нескольких аргументов с from ()
build.gradle
tasks.register ('copyReportsForArchiving', Копировать) {
из layout.buildDirectory.file ("reports / my-report.pdf"), layout.projectDirectory.file ("src / docs / manual.pdf")
в layout.buildDirectory.dir ("toArchive")
} build.gradle.kts
tasks.register ("copyReportsForArchiving") {
из (layout.buildDirectory.file ("reports / my-report.pdf"), layout.projectDirectory.file ("src / docs / manual.pdf"))
в (layout.buildDirectory.dir ("toArchive"))
} Два файла теперь скопированы в каталог архива. Вы также можете использовать несколько операторов from () , чтобы сделать то же самое, как показано в первом примере раздела Углубленное копирование файлов.
Теперь рассмотрим другой пример: что, если вы хотите скопировать все файлы PDF в каталоге, не указывая каждый из них? Для этого прикрепите шаблоны включения и / или исключения к спецификации копии. Здесь мы используем строковый шаблон для включения только PDF-файлов:
Пример 5. Использование плоского фильтра
build.gradle
tasks.register ('copyPdfReportsForArchiving', Копировать) {
из layout.buildDirectory.dir ("отчеты")
включить "* .pdf"
в макет.buildDirectory.dir ("toArchive")
} build.gradle.kts
tasks.register ("copyPdfReportsForArchiving") {
из (layout.buildDirectory.dir ("отчеты"))
включить ("*. pdf")
в (layout.buildDirectory.dir ("toArchive"))
} Следует отметить, что, как показано на следующей диаграмме, копируются только файлы PDF, которые находятся непосредственно в каталоге отчетов :
Рис. 1. Влияние плоского фильтра на копирование.
Вы можете включать файлы в подкаталоги с помощью шаблона глобуса в стиле Ant ( ** / * ), как это сделано в этом обновленном примере:
Пример 6.Использование глубокого фильтра
build.gradle
tasks.register ('copyAllPdfReportsForArchiving', Копировать) {
из layout.buildDirectory.dir ("отчеты")
включить "** / *. pdf"
в layout.buildDirectory.dir ("toArchive")
} build.gradle.kts
tasks.register ("copyAllPdfReportsForArchiving") {
из (layout.buildDirectory.dir ("отчеты"))
включить ("** / *. pdf")
в (layout.buildDirectory.dir ("toArchive"))
} Эта задача имеет следующий эффект:
Рисунок 2.Влияние глубокого фильтра на копирование
Следует иметь в виду, что такой глубокий фильтр имеет побочный эффект, заключающийся в копировании структуры каталогов ниже , сообщает , а также файлы. Если вы просто хотите скопировать файлы без структуры каталогов, вам необходимо использовать явное fileTree ( dir ) { включает } .files выражение. Подробнее о разнице между деревьями файлов и коллекциями файлов мы поговорим в разделе Деревья файлов.
Это лишь один из вариантов поведения, с которым вы, вероятно, столкнетесь при работе с файловыми операциями в сборках Gradle. К счастью, Gradle предоставляет элегантные решения почти для всех этих случаев использования. Прочтите подробные разделы , посвященные , далее в этой главе, чтобы получить более подробную информацию о том, как файловые операции работают в Gradle и какие параметры у вас есть для их настройки.
.