основы архитектуры компьютеров / Хабр
Мы воспринимаем центральный процессор как «мозг» компьютера, но что это значит на самом деле? Что именно происходит внутри миллиардов транзисторов, благодаря которым работает компьютер? В нашей новой мини-серии из четырёх статей мы рассмотрим процесс создания архитектуры компьютерного оборудования и расскажем о принципах его работы.В этой серии мы расскажем о компьютерной архитектуре, проектировании процессорных плат, VLSI (very-large-scale integration), производстве чипов и тенденциях будущего в области вычислительной техники. Если вам было интересно разобраться в подробностях работы процессоров, то начинать изучение лучше с этой серии статей.
Мы начнём с очень высокоуровневого объяснения того, чем занимается процессор и как строительные блоки соединяются в функционирующую конструкцию. В том числе мы рассмотрим процессорные ядра, иерархию памяти, предсказание ветвлений и другое. Во-первых, нам нужно дать простое определение тому, что делает ЦП.
Программы, например, операционная система или игра, сами по себе являются последовательностями инструкций, которые должен выполнять ЦП. Эти инструкции загружаются из памяти и в простом процессоре выполняются одна за другой, пока программа не завершится. Разработчики программного обеспечения пишут программы на высокоуровневых языках, например, на C++ или на Python, но процессор не может их понимать. Он понимает только единицы и нули, поэтому нам нужно каким-то образом представить код в этом формате.
 Это набор команд, которые должен понимать и выполнять ЦП. Одними из наиболее распространённых ISA являются x86, MIPS, ARM, RISC-V и PowerPC. Точно так же, как синтаксис написания функции на C++ отличается от функции, выполняющей то же действие в Python, у каждой ISA есть свой отличающийся синтаксис.
Это набор команд, которые должен понимать и выполнять ЦП. Одними из наиболее распространённых ISA являются x86, MIPS, ARM, RISC-V и PowerPC. Точно так же, как синтаксис написания функции на C++ отличается от функции, выполняющей то же действие в Python, у каждой ISA есть свой отличающийся синтаксис.Эти ISA можно разбить на две основных категории: с фиксированной и с переменной длиной. ISA RISC-V использует инструкции с фиксированной длиной, и это означает, что определённое заранее заданное количество битов в каждой инструкции определяет, какой тип имеет эта инструкция. В x86 всё иначе, в нём используются инструкции с переменной длиной. В x86 инструкции могут кодироваться различным способом с разным количеством битов для разных частей. Из-за такой сложности декодер инструкций в процессоре x86 обычно является самой сложной частью всего устройства.
Инструкции с фиксированной длиной обеспечивают простое декодирование благодаря постоянной структуре, но ограничивают общее количество инструкций, которые могут поддерживаться ISA. В то время, как у популярных версий архитектуры RISC-V есть примерно 100 инструкций и все они имеют открытый исходный код, архитектура x86 проприетарна и никто не знает, сколько всего инструкций в ней есть. Обычно считается, что существует несколько тысяч инструкций x86, но точное число никто не публикует. Несмотря на различия между ISA, по сути все они имеют одинаковую базовую функциональность.
В то время, как у популярных версий архитектуры RISC-V есть примерно 100 инструкций и все они имеют открытый исходный код, архитектура x86 проприетарна и никто не знает, сколько всего инструкций в ней есть. Обычно считается, что существует несколько тысяч инструкций x86, но точное число никто не публикует. Несмотря на различия между ISA, по сути все они имеют одинаковую базовую функциональность.
Теперь мы готовы включить компьютер и начать выполнять программы. Выполнение инструкции имеет несколько базовых частей, которые разбиты на множество этапов процессора.
Первый этап — передача инструкции из памяти в процессор для начала выполнения. На втором этапе инструкция декодируется, чтобы ЦП мог понять, какого типа эта инструкция.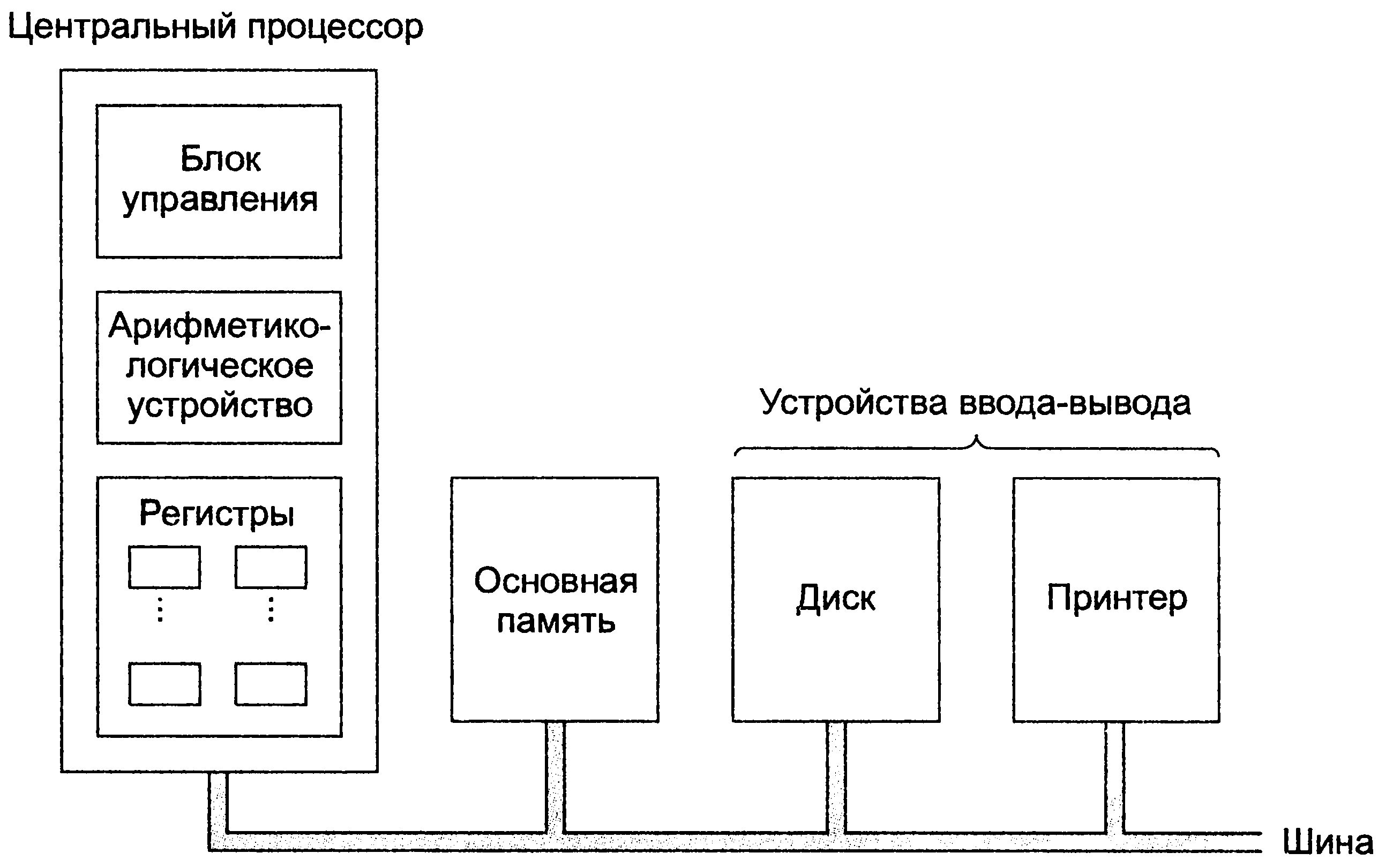 Существует множество типов, в том числе арифметические инструкции, инструкции ветвления и инструкции памяти. После того, как ЦП узнает, инструкцию какого типа он выполняет, операнды для инструкции берутся из памяти или внутренних регистров ЦП. Если вы хотите сложить число A и число B, то не можете выполнять сложение, пока не знаете значений A и B. Большинство современных процессоров являются 64-битными, то есть размер каждого значения данных составляет 64 бита.
Существует множество типов, в том числе арифметические инструкции, инструкции ветвления и инструкции памяти. После того, как ЦП узнает, инструкцию какого типа он выполняет, операнды для инструкции берутся из памяти или внутренних регистров ЦП. Если вы хотите сложить число A и число B, то не можете выполнять сложение, пока не знаете значений A и B. Большинство современных процессоров являются 64-битными, то есть размер каждого значения данных составляет 64 бита.
Получив операнды для инструкции, процессор переносит их на этап выполнения, где производится операция над входящими данными. Это может быть сложение чисел, выполнение логических манипуляций с числами или просто передача чисел без их изменения. После вычисления результата может потребоваться доступ к памяти для его сохранения, или процессор может просто хранить значение в одном из своих внутренних регистров. После сохранения результата ЦП обновляет состояние различных элементов и переходит к следующей инструкции.
После вычисления результата может потребоваться доступ к памяти для его сохранения, или процессор может просто хранить значение в одном из своих внутренних регистров. После сохранения результата ЦП обновляет состояние различных элементов и переходит к следующей инструкции.
Это объяснение, разумеется, сильно упрощено, и большинство современных процессоров для повышения эффективности разбивает эти несколько этапов на 20 или даже больше мелких этапов. Это означает, что хотя процессор начинает и завершает в каждом цикле несколько инструкций, может потребоваться 20 или больше циклов, чтобы выполнить одну инструкцию от начала до конца. Такая модель обычно называется pipeline («трубопровод», на русский обычно переводят как «конвейер»), потому что для заполнения трубопровода жидкостью и полного её прохождения требуется время, но после заполнения расход (вывод данных) будет постоянным.
Пример 4-этапного конвейера. Разноцветные прямоугольники обозначают независящие друг от друга инструкции.
Весь проходимый инструкцией цикл — это очень тщательно скоординированный процесс, но не все инструкции могут завершаться одновременно. Например, сложение выполняется очень быстро, а деление или загрузка из памяти может занимать тысячи циклов. Вместо останова всего процессора до момента завершения одной медленной инструкции большинство современных процессоров выполняют их с изменением очерёдности. То есть они определяют, какую из инструкций выгоднее всего выполнить в текущий момент и буферизируют другие инструкции, которые пока не готовы. Если текущая инструкция ещё не готова, то процессор может перепрыгнуть вперёд по коду, чтобы посмотреть, готово ли что-то ещё.
Кроме выполнения с изменением очерёдности современные процессоры применяют технологию под названием суперскалярная архитектура. Это означает, что в любой момент времени процессор одновременно выполняет на каждом этапе конвейера множество инструкций. Он может также ожидать ещё сотни других, чтобы начать их выполнение, и для того, чтобы иметь возможность одновременного выполнения нескольких инструкций внутри процессоров есть несколько копий каждого этапа конвейера.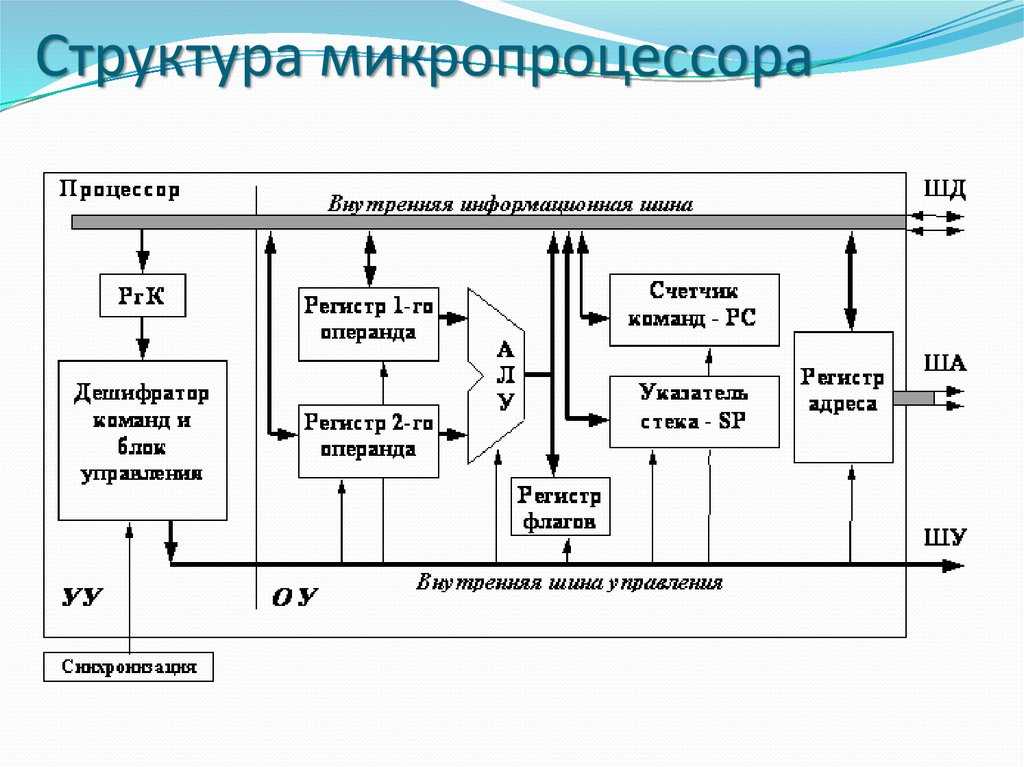
Необходимость кэшей иногда может сбивать с толку, ведь они хранят данные, как и ОЗУ или SSD. Но кэши отличаются задержкой и скоростью доступа. Даже несмотря на то, что память ОЗУ чрезвычайно быстра, она на порядки величин медленнее, чем нужно для ЦП. Для ответа с передачей данных ОЗУ может потребоваться сотни циклов, и процессору в это время будет нечем заняться. А если данных нет в ОЗУ, то могут потребоваться десятки тысяч циклов для получения доступа к ним с SSD. Без кэшей процессоры бы постоянно стопорились.
Но кэши отличаются задержкой и скоростью доступа. Даже несмотря на то, что память ОЗУ чрезвычайно быстра, она на порядки величин медленнее, чем нужно для ЦП. Для ответа с передачей данных ОЗУ может потребоваться сотни циклов, и процессору в это время будет нечем заняться. А если данных нет в ОЗУ, то могут потребоваться десятки тысяч циклов для получения доступа к ним с SSD. Без кэшей процессоры бы постоянно стопорились.
Обычно процессоры имеют три уровня кэша, образующих так называемую иерархию памяти. Кэш L1 — самый маленький и быстрый, L2 находится посередине, а L3 — самый крупный и медленный из всех кэшей. Выше кэшей в иерархии находятся мелкие регистры, хранящие во время вычислений единственное значение данных. По порядку величин эти регистры являются самыми быстрыми устройствами хранения в системе. Когда компилятор преобразует высокоуровневую программу в язык ассемблера, он определяет наилучший способ использования этих регистров.
Когда ЦП запрашивает данные из памяти, то сначала проверяет, хранятся ли эти данные уже в кэше L1. Если да, то можно всего за пару циклов получить к ним доступ. Если их там нет, то процессор проверяет L2, а затем и кэш L3. Кэши реализованы таким образом, что в общем случае они прозрачны для ядра. Ядро просто запрашивает данные по указанному адресу памяти, и тот уровень в иерархии, на котором они есть, отвечает ему. При переходе к последующим уровням в иерархии памяти размер и задержки обычно растут на порядки величин. В конце концов, если ЦП не находит данные ни в одном из кэшей, то обращается в основную память (ОЗУ).
Если да, то можно всего за пару циклов получить к ним доступ. Если их там нет, то процессор проверяет L2, а затем и кэш L3. Кэши реализованы таким образом, что в общем случае они прозрачны для ядра. Ядро просто запрашивает данные по указанному адресу памяти, и тот уровень в иерархии, на котором они есть, отвечает ему. При переходе к последующим уровням в иерархии памяти размер и задержки обычно растут на порядки величин. В конце концов, если ЦП не находит данные ни в одном из кэшей, то обращается в основную память (ОЗУ).
Когда процессор выполняет код, самые часто используемые инструкции и значения данных кэшируются. Это значительно ускоряет выполнение, потому что процессору не нужно постоянно обращаться за нужными данными в основную память. Во второй и третьей частях серии мы подробнее поговорим о том, как реализованы эти системы памяти.
Кроме кэшей одним из самых важных строительных блоков современного процессора является точный предсказатель переходов. Инструкции переходов (ветвлений) схожи с конструкциями «if» для процессора. Один набор инструкций выполняется, если условие истинно, а другой — если оно ложно. Например, нам нужно сравнить два числа, и если они равны, выполнить одну функцию, а если не равны, то выполнить другую. Эти инструкции ветвления применяются чрезвычайно часто и могут составлять примерно 20% всех инструкций в программе.
На первый взгляд кажется, что эти инструкции ветвления не должны вызывать проблем, но их правильное выполнение может оказаться очень сложным для процессора. В любой момент времени процессор может находиться в процессе одновременного выполнения десяти или двадцати инструкций, поэтому очень важно знать, какие инструкции выполнять. Может потребоваться 5 циклов, чтобы определить, что текущая инструкция — это переход и ещё 10 циклов, чтобы определить истинность условия. В это время процессор уже может начать выполнение десятков дополнительных инструкций, даже не зная, действительно ли это подходящие для выполнения инструкции.
В любой момент времени процессор может находиться в процессе одновременного выполнения десяти или двадцати инструкций, поэтому очень важно знать, какие инструкции выполнять. Может потребоваться 5 циклов, чтобы определить, что текущая инструкция — это переход и ещё 10 циклов, чтобы определить истинность условия. В это время процессор уже может начать выполнение десятков дополнительных инструкций, даже не зная, действительно ли это подходящие для выполнения инструкции.
Чтобы обойти эту проблему, все современные высокопроизводительные процессоры используют методику под названием «упреждение» (speculation). Это означает, что процессор отслеживает инструкции ветвления и гадает, будет ли выполнен условный переход, или нет. Если предсказание верно, то процессор уже начал выполнять последующие инструкции, и это обеспечивает рост производительности. Если предсказание неверно, то процессор останавливает выполнение, удаляет все неверные инструкции, которые он начал выполнять, и начинает заново с правильной точки.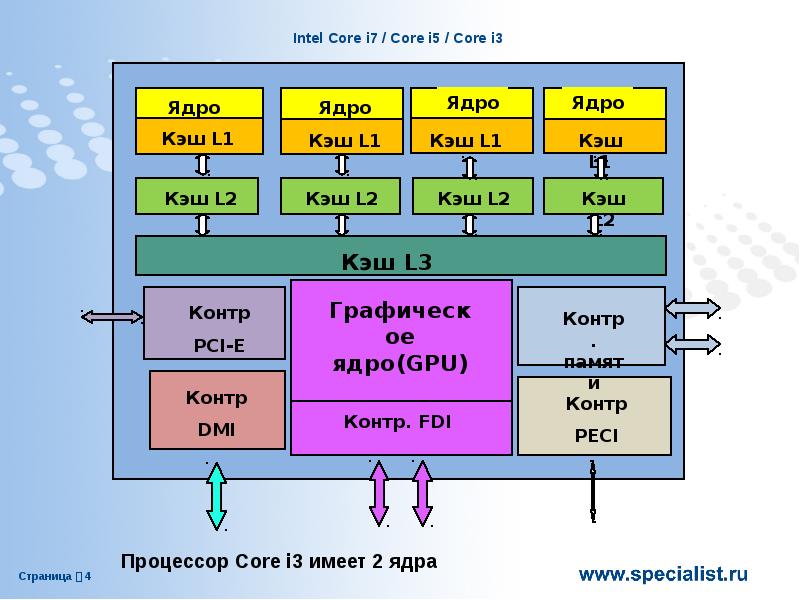
Такие предсказатели перехода — одни из самых простейших разновидностей машинного обучения, потому что предсказатель изучает поведение ветвей в процессе выполнения. Если он предсказывает неверно слишком часто, то начинает обучаться правильному поведению. Десятилетия исследований методик предсказания переходов привели к тому, что в современных процессорах точность предсказаний превышает 90%.
Хотя упреждение обеспечивает огромный рост производительности, потому что процессор может выполнять инструкции, которые уже готовы, вместо того, чтобы ожидать в очереди завершения выполняемых, оно в то же время создаёт уязвимости в защите. Знаменитая атака Spectre эксплуатирует баги в предсказании и упреждении переходов. Атакующий использует специально подобранный код, чтобы заставить процессор упреждающе выполнить код, благодаря чему происходит утечка значений из памяти. Для предотвращения утечки данных необходимо было переделать конструкцию отдельных аспектов упреждения, что привело к небольшому падению производительности.
За последние десятилетия используемая в современных процессорах архитектура прошла долгий путь. Инновации и разработка продуманной структуры привели к повышению производительности и более оптимальному использованию аппаратных средств. Однако разработчики центральных процессоров тщательно хранят секреты их технологий, поэтому мы не можем точно узнать, что происходит у них внутри. Тем не менее, фундаментальные принципы работы процессоров стандартированы для всех архитектур и моделей. Intel может добавлять свои секретные ингредиенты, чтобы повысить долю попаданий кэша, а AMD может добавить улучшенный предсказатель переходов, но процессоры обеих компаний выполняют одинаковую задачу.
В этом первом взгляде и обзоре мы рассмотрели основы работы процессоров. В следующей части мы расскажем, как разрабатываются компоненты, входящие в состав процессоров, поговорим о логических элементах, тактовых частотах, управлении питанием, принципиальных электросхемах и другом.
Рекомендуемое чтение
- The History of the Microprocessor and the Personal Computer
- Display Tech Compared: TN vs.
 VA vs. IPS
VA vs. IPS - 4GHz CPU Battle: AMD 2nd-Gen Ryzen vs. Intel 8th-Gen Core
- What’s Thermal Throttling and How to Prevent It
Процессоры, ядра и потоки. Топология систем / Хабр
В этой статье я попытаюсь описать терминологию, используемую для описания систем, способных исполнять несколько программ параллельно, то есть многоядерных, многопроцессорных, многопоточных. Разные виды параллелизма в ЦПУ IA-32 появлялись в разное время и в несколько непоследовательном порядке. Во всём этом довольно легко запутаться, особенно учитывая, что операционные системы заботливо прячут детали от не слишком искушённых прикладных программ.Используемая далее терминология используется в документации процессорам Intel. Другие архитектуры могут иметь другие названия для похожих понятий. Там, где они мне известны, я буду их упоминать.
Цель статьи — показать, что при всём многообразии возможных конфигураций многопроцессорных, многоядерных и многопоточных систем для программ, исполняющихся на них, создаются возможности как для абстракции (игнорирования различий), так и для учёта специфики (возможность программно узнать конфигурацию).
Мой комментарий объясняет, почему сотрудники компаний должны в публичных коммуникациях использовать знаки авторского права. В этой статье их пришлось использовать довольно часто.
Процессор
Конечно же, самый древний, чаще всего используемый и неоднозначный термин — это «процессор».В современном мире процессор — это то (package), что мы покупаем в красивой Retail коробке или не очень красивом OEM-пакетике. Неделимая сущность, вставляемая в разъём (socket) на материнской плате. Даже если никакого разъёма нет и снять его нельзя, то есть если он намертво припаян, это один чип.
Мобильные системы (телефоны, планшеты, ноутбуки) и большинство десктопов имеют один процессор. Рабочие станции и сервера иногда могут похвастаться двумя или больше процессорами на одной материнской плате.
Поддержка нескольких центральных процессоров в одной системе требует многочисленных изменений в её дизайне. Как минимум, необходимо обеспечить их физическое подключение (предусмотреть несколько сокетов на материнской плате), решить вопросы идентификации процессоров (см. далее в этой статье, а также мою предыдущую заметку), согласования доступов к памяти и доставки прерываний (контроллер прерываний должен уметь маршрутизировать прерывания на несколько процессоров) и, конечно же, поддержки со стороны операционной системы. Я, к сожалению, не смог найти документального упоминания момента создания первой многопроцессорной системы на процессорах Intel, однако Википедия утверждает, что Sequent Computer Systems поставляла их уже в 1987 году, используя процессоры Intel 80386. Широко распространённой поддержка же нескольких чипов в одной системе становится доступной, начиная с Intel® Pentium.
далее в этой статье, а также мою предыдущую заметку), согласования доступов к памяти и доставки прерываний (контроллер прерываний должен уметь маршрутизировать прерывания на несколько процессоров) и, конечно же, поддержки со стороны операционной системы. Я, к сожалению, не смог найти документального упоминания момента создания первой многопроцессорной системы на процессорах Intel, однако Википедия утверждает, что Sequent Computer Systems поставляла их уже в 1987 году, используя процессоры Intel 80386. Широко распространённой поддержка же нескольких чипов в одной системе становится доступной, начиная с Intel® Pentium.
Если процессоров несколько, то каждый из них имеет собственный разъём на плате. У каждого из них при этом имеются полные независимые копии всех ресурсов, таких как регистры, исполняющие устройства, кэши. Делят они общую память — RAM. Память может подключаться к ним различными и довольно нетривиальными способами, но это отдельная история, выходящая за рамки этой статьи. Важно то, что при любом раскладе для исполняемых программ должна создаваться иллюзия однородной общей памяти, доступной со всех входящих в систему процессоров.
Важно то, что при любом раскладе для исполняемых программ должна создаваться иллюзия однородной общей памяти, доступной со всех входящих в систему процессоров.
Ядро
Исторически многоядерность в Intel IA-32 появилась позже Intel® HyperThreading, однако в логической иерархии она идёт следующей.Казалось бы, если в системе больше процессоров, то выше её производительность (на задачах, способных задействовать все ресурсы). Однако, если стоимость коммуникаций между ними слишком велика, то весь выигрыш от параллелизма убивается длительными задержками на передачу общих данных. Именно это наблюдается в многопроцессорных системах — как физически, так и логически они находятся очень далеко друг от друга. Для эффективной коммуникации в таких условиях приходится придумывать специализированные шины, такие как Intel® QuickPath Interconnect. Энергопотребление, размеры и цена конечного решения, конечно, от всего этого не понижаются. На помощь должна прийти высокая интеграция компонент — схемы, исполняющие части параллельной программы, надо подтащить поближе друг к другу, желательно на один кристалл. Другими словами, в одном процессоре следует организовать несколько ядер, во всём идентичных друг другу, но работающих независимо.
На помощь должна прийти высокая интеграция компонент — схемы, исполняющие части параллельной программы, надо подтащить поближе друг к другу, желательно на один кристалл. Другими словами, в одном процессоре следует организовать несколько ядер, во всём идентичных друг другу, но работающих независимо.
Первые многоядерные процессоры IA-32 от Intel были представлены в 2005 году. С тех пор среднее число ядер в серверных, десктопных, а ныне и мобильных платформах неуклонно растёт.
В отличие от двух одноядерных процессоров в одной системе, разделяющих только память, два ядра могут иметь также общие кэши и другие ресурсы, отвечающие за взаимодействие с памятью. Чаще всего кэши первого уровня остаются приватными (у каждого ядра свой), тогда как второй и третий уровень может быть как общим, так и раздельным. Такая организация системы позволяет сократить задержки доставки данных между соседними ядрами, особенно если они работают над общей задачей.
Микроснимок четырёхядерного процессора Intel с кодовым именем Nehalem.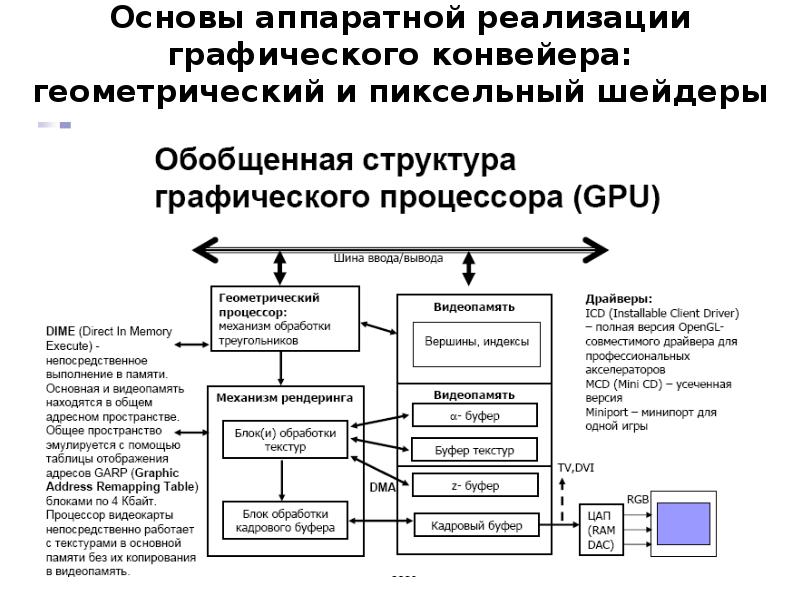 Выделены отдельные ядра, общий кэш третьего уровня, а также линки QPI к другим процессорам и общий контроллер памяти.
Выделены отдельные ядра, общий кэш третьего уровня, а также линки QPI к другим процессорам и общий контроллер памяти.Гиперпоток
До примерно 2002 года единственный способ получить систему IA-32, способную параллельно исполнять две или более программы, состоял в использовании именно многопроцессорных систем. В Intel® Pentium® 4, а также линейке Xeon с кодовым именем Foster (Netburst) была представлена новая технология — гипертреды или гиперпотоки, — Intel® HyperThreading (далее HT).Ничто не ново под луной. HT — это частный случай того, что в литературе именуется одновременной многопоточностью (simultaneous multithreading, SMT). В отличие от «настоящих» ядер, являющихся полными и независимыми копиями, в случае HT в одном процессоре дублируется лишь часть внутренних узлов, в первую очередь отвечающих за хранение архитектурного состояния — регистры. Исполнительные же узлы, ответственные за организацию и обработку данных, остаются в единственном числе, и в любой момент времени используются максимум одним из потоков.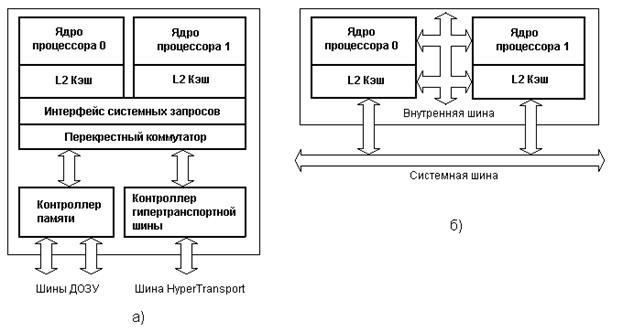 Как и ядра, гиперпотоки делят между собой кэши, однако начиная с какого уровня — это зависит от конкретной системы.
Как и ядра, гиперпотоки делят между собой кэши, однако начиная с какого уровня — это зависит от конкретной системы.
Я не буду пытаться объяснить все плюсы и минусы дизайнов с SMT вообще и с HT в частности. Интересующийся читатель может найти довольно подробное обсуждение технологии во многих источниках, и, конечно же, в Википедии. Однако отмечу следующий важный момент, объясняющий текущие ограничения на число гиперпотоков в реальной продукции.
Ограничения потоков
В каких случаях наличие «нечестной» многоядерности в виде HT оправдано? Если один поток приложения не в состоянии загрузить все исполняющие узлы внутри ядра, то их можно «одолжить» другому потоку. Это типично для приложений, имеющих «узкое место» не в вычислениях, а при доступе к данным, то есть часто генерирующих промахи кэша и вынужденных ожидать доставку данных из памяти. В это время ядро без HT будет вынуждено простаивать. Наличие же HT позволяет быстро переключить свободные исполняющие узлы к другому архитектурному состоянию (т. к. оно как раз дублируется) и исполнять его инструкции. Это — частный случай приёма под названием latency hiding, когда одна длительная операция, в течение которой полезные ресурсы простаивают, маскируется параллельным выполнением других задач. Если приложение уже имеет высокую степень утилизации ресурсов ядра, наличие гиперпотоков не позволит получить ускорение — здесь нужны «честные» ядра.
к. оно как раз дублируется) и исполнять его инструкции. Это — частный случай приёма под названием latency hiding, когда одна длительная операция, в течение которой полезные ресурсы простаивают, маскируется параллельным выполнением других задач. Если приложение уже имеет высокую степень утилизации ресурсов ядра, наличие гиперпотоков не позволит получить ускорение — здесь нужны «честные» ядра.Типичные сценарии работы десктопных и серверных приложений, рассчитанных на машинные архитектуры общего назначения, имеют потенциал к параллелизму, реализуемому с помощью HT. Однако этот потенциал быстро «расходуется». Возможно, по этой причине почти на всех процессорах IA-32 число аппаратных гиперпотоков не превышает двух. На типичных сценариях выигрыш от использования трёх и более гиперпотоков был бы невелик, а вот проигрыш в размере кристалла, его энергопотреблении и стоимости значителен.
Другая ситуация наблюдается на типичных задачах, выполняемых на видеоускорителях. Поэтому для этих архитектур характерно использование техники SMT с бóльшим числом потоков. Так как сопроцессоры Intel® Xeon Phi (представленные в 2010 году) идеологически и генеалогически довольно близки к видеокартам, на них может быть четыре гиперпотока на каждом ядре — уникальная для IA-32 конфигурация.
Так как сопроцессоры Intel® Xeon Phi (представленные в 2010 году) идеологически и генеалогически довольно близки к видеокартам, на них может быть четыре гиперпотока на каждом ядре — уникальная для IA-32 конфигурация.
Логический процессор
Из трёх описанных «уровней» параллелизма (процессоры, ядра, гиперпотоки) в конкретной системе могут отсутствовать некоторые или даже все. На это влияют настройки BIOS (многоядерность и многопоточность отключаются независимо), особенности микроархитектуры (например, HT отсутствовал в Intel® Core™ Duo, но был возвращён с выпуском Nehalem) и события при работе системы (многопроцессорные сервера могут выключать отказавшие процессоры в случае обнаружения неисправностей и продолжать «лететь» на оставшихся). Каким образом этот многоуровневый зоопарк параллелизма виден операционной системе и, в конечном счёте, прикладным приложениям?Далее для удобства обозначим количества процессоров, ядер и потоков в некоторой системе тройкой (x, y, z), где x — это число процессоров, y — число ядер в каждом процессоре, а z — число гиперпотоков в каждом ядре. Далее я буду называть эту тройку топологией — устоявшийся термин, мало что имеющий с разделом математики. Произведение p = xyz определяет число сущностей, именуемых логическими процессорами системы. Оно определяет полное число независимых контекстов прикладных процессов в системе с общей памятью, исполняющихся параллельно, которые операционная система вынуждена учитывать. Я говорю «вынуждена», потому что она не может управлять порядком исполнения двух процессов, находящихся на различных логических процессорах. Это относится в том числе к гиперпотокам: хотя они и работают «последовательно» на одном ядре, конкретный порядок диктуется аппаратурой и недоступен для наблюдения или управления программам.
Далее я буду называть эту тройку топологией — устоявшийся термин, мало что имеющий с разделом математики. Произведение p = xyz определяет число сущностей, именуемых логическими процессорами системы. Оно определяет полное число независимых контекстов прикладных процессов в системе с общей памятью, исполняющихся параллельно, которые операционная система вынуждена учитывать. Я говорю «вынуждена», потому что она не может управлять порядком исполнения двух процессов, находящихся на различных логических процессорах. Это относится в том числе к гиперпотокам: хотя они и работают «последовательно» на одном ядре, конкретный порядок диктуется аппаратурой и недоступен для наблюдения или управления программам.
Чаще всего операционная система прячет от конечных приложений особенности физической топологии системы, на которой она запущена. Например, три следующие топологии: (2, 1, 1), (1, 2, 1) и (1, 1, 2) — ОС будет представлять в виде двух логических процессоров, хотя первая из них имеет два процессора, вторая — два ядра, а третья — всего лишь два потока.
Windows Task Manager показывает 8 логических процессоров; но сколько это в процессорах, ядрах и гиперпотоках?
Linux top показывает 4 логических процессора.
Это довольно удобно для создателей прикладных приложений — им не приходится иметь дело с зачастую несущественными для них особенностями аппаратуры.
Программное определение топологии
Конечно, абстрагирование топологии в единственное число логических процессоров в ряде случаев создаёт достаточно оснований для путаницы и недоразумений (в жарких Интернет-спорах). Вычислительные приложения, желающие выжать из железа максимум производительности, требуют детального контроля над тем, где будут размещены их потоки: поближе друг к другу на соседних гиперпотоках или же наоборот, подальше на разных процессорах. Скорость коммуникаций между логическими процессорами в составе одного ядра или процессора значительно выше, чем скорость передачи данных между процессорами. Возможность неоднородности в организации оперативной памяти также усложняет картину.
Информация о топологии системы в целом, а также положении каждого логического процессора в IA-32 доступна с помощью инструкции CPUID. С момента появления первых многопроцессорных систем схема идентификации логических процессоров несколько раз расширялась. К настоящему моменту её части содержатся в листах 1, 4 и 11 CPUID. Какой из листов следует смотреть, можно определить из следующей блок-схемы, взятой из статьи [2]:
Я не буду здесь утомлять всеми подробностями отдельных частей этого алгоритма. Если возникнет интерес, то этому можно посвятить следующую часть этой статьи. Отошлю интересующегося читателя к [2], в которой этот вопрос разбирается максимально подробно. Здесь же я сначала кратко опишу, что такое APIC и как он связан с топологией. Затем рассмотрим работу с листом 0xB (одиннадцать в десятичном счислении), который на настоящий момент является последним словом в «апикостроении».
APIC ID
Local APIC (advanced programmable interrupt controller) — это устройство (ныне входящее в состав процессора), отвечающее за работу с прерываниями, приходящими к конкретному логическому процессору.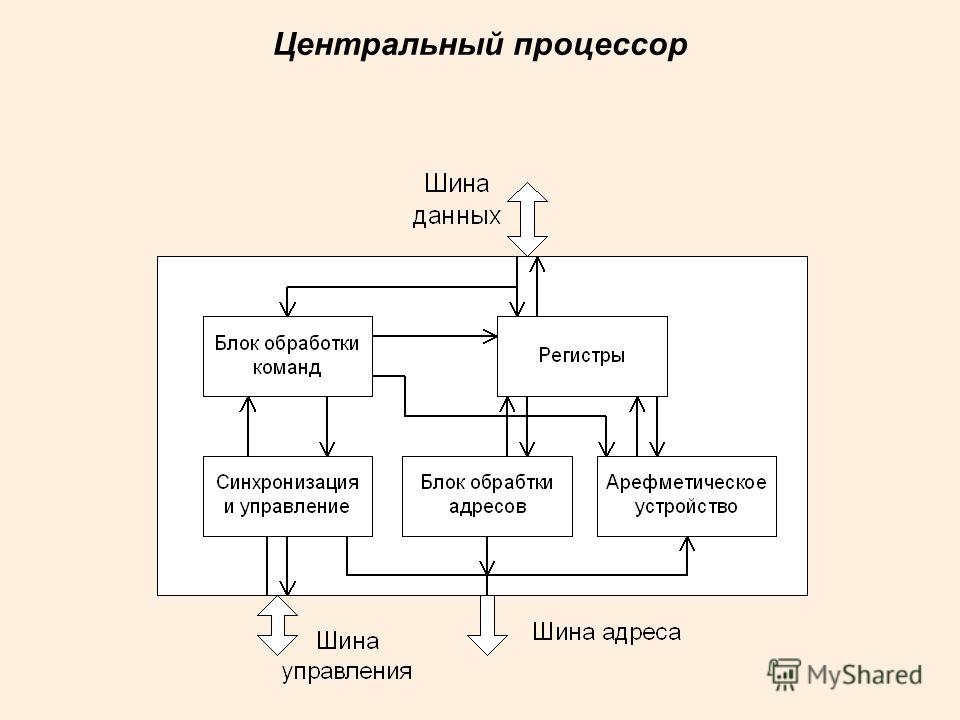 Свой собственный APIC есть у каждого логического процессора. И каждый из них в системе должен иметь уникальное значение APIC ID. Это число используется контроллерами прерываний для адресации при доставке сообщений, а всеми остальными (например, операционной системой) — для идентификации логических процессоров. Спецификация на этот контроллер прерываний эволюционировала, пройдя от микросхемы Intel 8259 PIC через Dual PIC, APIC иxAPIC кx2APIC.
Свой собственный APIC есть у каждого логического процессора. И каждый из них в системе должен иметь уникальное значение APIC ID. Это число используется контроллерами прерываний для адресации при доставке сообщений, а всеми остальными (например, операционной системой) — для идентификации логических процессоров. Спецификация на этот контроллер прерываний эволюционировала, пройдя от микросхемы Intel 8259 PIC через Dual PIC, APIC иxAPIC кx2APIC.В настоящий момент ширина числа, хранящегося в APIC ID, достигла полных 32 бит, хотя в прошлом оно было ограничено 16, а ещё раньше — только 8 битами. Нынче остатки старых дней раскиданы по всему CPUID, однако в CPUID.0xB.EDX[31:0] возвращаются все 32 бита APIC ID. На каждом логическом процессоре, независимо исполняющем инструкцию CPUID, возвращаться будет своё значение.
Выяснение родственных связей
Значение APIC ID само по себе ничего не говорит о топологии. Чтобы узнать, какие два логических процессора находятся внутри одного физического (т. е. являются «братьями» гипертредами), какие два — внутри одного процессора, а какие оказались и вовсе в разных процессорах, надо сравнить их значения APIC ID. В зависимости от степени родства некоторые их биты будут совпадать. Эта информация содержится в подлистьях CPUID.0xB, которые кодируются с помощью операнда в ECX. Каждый из них описывает положение битового поля одного из уровней топологии в EAX[5:0] (точнее, число бит, которые нужно сдвинуть в APIC ID вправо, чтобы убрать нижние уровни топологии), а также тип этого уровня — гиперпоток, ядро или процессор, — в ECX[15:8].
е. являются «братьями» гипертредами), какие два — внутри одного процессора, а какие оказались и вовсе в разных процессорах, надо сравнить их значения APIC ID. В зависимости от степени родства некоторые их биты будут совпадать. Эта информация содержится в подлистьях CPUID.0xB, которые кодируются с помощью операнда в ECX. Каждый из них описывает положение битового поля одного из уровней топологии в EAX[5:0] (точнее, число бит, которые нужно сдвинуть в APIC ID вправо, чтобы убрать нижние уровни топологии), а также тип этого уровня — гиперпоток, ядро или процессор, — в ECX[15:8].У логических процессоров, находящихся внутри одного ядра, будут совпадать все биты APIC ID, кроме принадлежащих полю SMT. Для логических процессоров, находящихся в одном процессоре, — все биты, кроме полей Core и SMT. Поскольку число подлистов у CPUID.0xB может расти, данная схема позволит поддержать описание топологий и с бóльшим числом уровней, если в будущем возникнет необходимость. Более того, можно будет ввести промежуточные уровни между уже существующими.
Важное следствие из организации данной схемы заключается в том, что в наборе всех APIC ID всех логических процессоров системы могут быть «дыры», т.е. они не будут идти последовательно. Например, во многоядерном процессоре с выключенным HT все APIC ID могут оказаться чётными, так как младший бит, отвечающий за кодирование номера гиперпотока, будет всегда нулевым.
Отмечу, что CPUID.0xB — не единственный источник информации о логических процессорах, доступный операционной системе. Список всех процессоров, доступный ей, вместе с их значениями APIC ID, кодируется в таблице MADT ACPI [3, 4].
Операционные системы и топология
Операционные системы предоставляют информацию о топологии логических процессоров приложениям с помощью своих собственных интерфейсов.В Linux информация о топологии содержится в псевдофайле /proc/cpuinfo, а также выводе команды dmidecode. В примере ниже я фильтрую содержимое cpuinfo на некоторой четырёхядерной системе без HT, оставляя только записи, относящиеся к топологии:
ggg@shadowbox:~$ cat /proc/cpuinfo |grep 'processor\|physical\ id\|siblings\|core\|cores\|apicid' processor : 0 physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 0 initial apicid : 0 processor : 1 physical id : 0 siblings : 4 core id : 0 cpu cores : 2 apicid : 1 initial apicid : 1 processor : 2 physical id : 0 siblings : 4 core id : 1 cpu cores : 2 apicid : 2 initial apicid : 2 processor : 3 physical id : 0 siblings : 4 core id : 1 cpu cores : 2 apicid : 3 initial apicid : 3
В FreeBSD топология сообщается через механизм sysctl в переменной kern. sched.topology_spec в виде XML:
sched.topology_spec в виде XML:
user@host:~$ sysctl kern.sched.topology_spec
kern.sched.topology_spec: <groups>
<group level="1" cache-level="0">
<cpu count="8" mask="0xff">0, 1, 2, 3, 4, 5, 6, 7</cpu>
<children>
<group level="2" cache-level="2">
<cpu count="8" mask="0xff">0, 1, 2, 3, 4, 5, 6, 7</cpu>
<children>
<group level="3" cache-level="1">
<cpu count="2" mask="0x3">0, 1</cpu>
<flags><flag name="THREAD">THREAD group</flag><flag name="SMT">SMT group</flag></flags>
</group>
<group level="3" cache-level="1">
<cpu count="2" mask="0xc">2, 3</cpu>
<flags><flag name="THREAD">THREAD group</flag><flag name="SMT">SMT group</flag></flags>
</group>
<group level="3" cache-level="1">
<cpu count="2" mask="0x30">4, 5</cpu>
<flags><flag name="THREAD">THREAD group</flag><flag name="SMT">SMT group</flag></flags>
</group>
<group level="3" cache-level="1">
<cpu count="2" mask="0xc0">6, 7</cpu>
<flags><flag name="THREAD">THREAD group</flag><flag name="SMT">SMT group</flag></flags>
</group>
</children>
</group>
</children>
</group>
</groups>
В MS Windows 8 сведения о топологии можно увидеть в диспетчере задач Task Manager.
Также их предоставляет консольная утилита Sysinternals Coreinfo и API вызов GetLogicalProcessorInformation.
Полная картина
Проиллюстрирую ещё раз отношения между понятиями «процессор», «ядро», «гиперпоток» и «логический процессор» на нескольких примерах.Система (2, 2, 2)
Система (2, 4, 1)
Система (4, 1, 1)
Прочие вопросы
В этот раздел я вынес некоторые курьёзы, возникающие из-за многоуровневой организации логических процессоров.Кэши
Как я уже упоминал, кэши в процессоре тоже образуют иерархию, и она довольно сильно связано с топологией ядер, однако не определяется ей однозначно. Для определения того, какие кэши для каких логических процессоров общие, а какие нет, используется вывод CPUID.4 и её подлистов.Лицензирование
Некоторые программные продукты поставляются числом лицензий, определяемых количеством процессоров в системе, на которой они будут использоваться. Другие — числом ядер в системе. Наконец, для определения числа лицензий число процессоров может умножаться на дробный «core factor», зависящий от типа процессора!
Другие — числом ядер в системе. Наконец, для определения числа лицензий число процессоров может умножаться на дробный «core factor», зависящий от типа процессора!Виртуализация
Системы виртуализации, способные моделировать многоядерные системы, могут назначить виртуальным процессорам внутри машины произвольную топологию, не совпадающую с конфигурацией реальной аппаратуры. Так, внутри хозяйской системы (1, 2, 2) некоторые известные системы виртуализации по умолчанию выносят все логические процессоры на верхний уровень, т.е. создают конфигурацию (4, 1, 1). В сочетании с особенностями лицензирования, зависящими от топологии, это может порождать забавные эффекты.Спасибо за внимание!
Литература
- Intel Corporation. Intel® 64 and IA-32 Architectures Software Developer’s Manual. Volumes 1–3, 2014. www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
- Shih Kuo. Intel® 64 Architecture Processor Topology Enumeration, 2012 — software.
 intel.com/en-us/articles/intel-64-architecture-processor-topology-enumeration
intel.com/en-us/articles/intel-64-architecture-processor-topology-enumeration - OSDevWiki. MADT. wiki.osdev.org/MADT
- OSDevWiki. Detecting CPU Topology. wiki.osdev.org/Detecting_CPU_Topology_%2880×86%29
[Рейтинг тестов и сравнение производительности]
Выбор правильного ЦП среди миллиардов SKU разных поколений — это не что иное, как поиск иглы в пустыне.
Что ж, я и моя команда из 10scopes протестировали сотни процессоров трех последовательных поколений как Intel, так и AMD и ранжировали их на основе одноядерных , многоядерных , игровых и других оценок производительности. параметры.
Итак, не теряя ни секунды, давайте подробно изучим процессоры.
Параметры для сортировки ЦП Ранжирование ЦП выполняется на основе производительности. Не забывайте, кстати, и о ценах. Но для определения самого мощного процессора всегда преобладает фактор производительности.
Теперь, как мы можем получить свежий взгляд? Что ж, многочисленные приложения легко доступны для измерения производительности процессора.
Одно предостережение — при таком большом количестве номеров ЦП невозможно измерить производительность отдельных частей в каждой отдельной программе. К счастью, у нас есть программные решения для синтетических тестов, которые воспроизводят реальную производительность этих процессоров в приложениях, которые мы постоянно используем.
Тем не менее, мы оценили поведение каждого процессора Одноядерный , Многоядерный , Производительность , Игровой и Эффективность . Тем не менее, это те аспекты, на которые вам нужно обратить внимание, прежде чем брать процессор.
Тестовый стенд Intel 11th, 12th, 13th и Процессоры AMD Ryzen 3000, 5000, 7000 серий — наш выбор для создания пирамиды производительности, поскольку эти части являются новейшими и широко доступны в рынок.
Только ЦП не вырежет, да?
Итак, мы установили совершенно разные испытательные стенды для проведения тестов. У каждой платформы есть свой SSD; ни один из них не используется совместно двумя тестовыми стендами, такими как AMD или Intel, чтобы избежать любого конфликта драйверов.
На всякий случай мы установили отдельные диски ОС для AM4 , AM5 , LGA 1200 и LGA 1700 . Так что даже драйверы чипсета могут вызвать проблемы со стабильностью или производительностью.
Ниже представлена спецификация для тестовых стендов платформ Intel и AMD :
| Intel | |||
|---|---|---|---|
| Компоненты | Intel 13-го поколения (Raptor Lake) ASUS R OG Strix Z690E | Aorus Ultra Durable Z590 | |
| ОЗУ | G. SKILL Trident Z5 RGB Series 32 ГБ (2 x 16 ГБ) 6000 МГц DDR5 SKILL Trident Z5 RGB Series 32 ГБ (2 x 16 ГБ) 6000 МГц DDR5 | Crucial Ballistix 3200 МГц DDR4 32 ГБ (16 ГБ x 2) ) CL16 | |
| SSD | SABRENT 1 ТБ Rocket 4 Plus NVMe 4.0 Gen4 PCIe M.2 | ||
| ОС | Windows 11 | ||
| GPU | ASUS TUF GeForce RTX 4090 OC | ||
| Блок питания | Тише! Dark Power 13 1000 Вт, 80 Plus Titanium Efficiency, ATX 3.0, PCIe 5 | ||
| AMD | |||
|---|---|---|---|
| Компоненты 9000 6 | AMD Ryzen 7000 (Zen4, Raphael) | AMD Ryzen 5000 (Zen3, Vermeer) | AMD Ryzen 3000 (Zen2, Matisse) |
| Материнская плата | ASUS ROG Strix X670E-A Gaming WiFi 6E Socket AM5 | MSI MPG X570 Gaming Pro Carbon 9 0079 | |
| ОЗУ | Corsair Vengeance RGB DDR5 32 ГБ (2×16 ГБ), 5600 МГц C36 | CORSAIR Dominator Platinum RGB 32 ГБ (2×16 ГБ) DDR4 3600 | |
| SSD | Samsung 980 Pro 1 ТБ PCIe 4. 0 0 | ||
| ОС | Windows 11 | ||
| GPU | ASUS TUF GeForce RTX 4090 OC | ||
| блок питания 9007 9 | Молчи! Dark Power 13 1000 Вт, 80 Plus Titanium Efficiency, ATX 3.0, PCIe 5 | ||
Повседневные задачи, такие как игры, фотошоп, просмотр страниц и подобные рабочие нагрузки, сильно зависят от однопоточной производительности ЦП. Не говоря уже об общей плавности и быстроте работы. Все это вытекает из IPC (Instruction Per Cycle) и повышения тактовой частоты в каждом поколении.
Cinebench R23 , Geekbench 6 и PassMark являются нашими предпочтительными приложениями для регулирования рейтинга.
После запуска тестов мы сделали среднее из 3 результатов для каждого отдельного процессора.
Давайте посмотрим, как ЦП соотносятся друг с другом с точки зрения одноядерного рейтинга:
Core i9 13900KS пользуется преимуществом рекордного 6. 0 ГГц повышает тактовую частоту и лидирует одноядерный график, за ним следует vanilla i9 13900K, который отстает от лидера графика всего на 3,2% в нашем тестировании.
i7 13700K и Ryzen 9 7950X идут сразу после SKU i9, который на 8-9% медленнее.
Интересно отметить, что 3D V-кэш на самом деле не помог AMD с точки зрения общей одноядерной производительности. Но любой ЦП, который не соответствует 3-5% , на самом деле не делает его плохой частью. Можете считать это погрешностью. В действительности мы практически не почувствовали разницы между процессорами с таким несоответствием.
Сравнительный рейтинг многоядерных процессоров Производительность многоядерных процессоров интерпретирует, насколько сильно вы можете использовать производительные приложения. Это особенно важно для крупных студий или индустрии создания контента. Кроме того, медицинские исследования и инженерные области могут сэкономить огромное количество времени, что, я считаю, экономически выгодно.
Это особенно важно для крупных студий или индустрии создания контента. Кроме того, медицинские исследования и инженерные области могут сэкономить огромное количество времени, что, я считаю, экономически выгодно.
Просто чтобы вы знали, архитектура ЦП, IPC, количество ядер и частота — все это имеет значение, когда речь идет об улучшении многоядерности по сравнению с продуктом предыдущего поколения.
Теперь взгляните на рейтинг многоядерных процессоров.
Как видите, здесь все довольно увлекательно. Ядро i9 13900KS и Ryzen 9 7950X почти идентичны, с минимальным дефицитом производительности 0,5% для последнего флагманского SKU AMD. Итак, это в основном галстук.
То же самое можно сказать и о i9 13900K и R9 7950X3D . Если быть до конца честным, любой ЦП между этими 4 SKU — зверь, когда дело доходит до производительности. В обоих процессорах нет ничего плохого. 13-е поколение 9Однако 0005 i7 13700K и Ryzen 9 7900X на один шаг ниже.
В обоих процессорах нет ничего плохого. 13-е поколение 9Однако 0005 i7 13700K и Ryzen 9 7900X на один шаг ниже.
Теперь для измерения производительности мы запустили тесты Cinebench R23 и VRay 5 . Оба доводят процессор до его абсолютного предела. Мы оценили процессоры, получив 100 баллов за лучший. Другие оцениваются относительно лидеров чарта в процентном соотношении.
Учитывая все вышесказанное, рейтинг может немного измениться, если к результатам теста будет добавлено больше приложений. Но это не означает, что наши данные потеряют ценность, скорее вы обнаружите, что они больше соответствуют другим, имеющим небольшие различия. Это происходит из-за вариаций от запуска к запуску.
Иерархия игровых ЦП Игры были одним из самых разрекламированных и престижных решающих факторов для производителя, чтобы заявить о своем превосходстве над конкурентами. Как бы забавно это ни звучало, даже если они могут хоть немного продвинуться вперед, маркетинг и хвастовство в порядке вещей. Таким образом, мы видим чипы с большим количеством бинов, такие как KS и X3D от Intel и AMD соответственно.
Как бы забавно это ни звучало, даже если они могут хоть немного продвинуться вперед, маркетинг и хвастовство в порядке вещей. Таким образом, мы видим чипы с большим количеством бинов, такие как KS и X3D от Intel и AMD соответственно.
Если говорить об игровой производительности, то в основном она выигрывает от прироста IPC, повышения тактовой частоты, малой задержки памяти и кэша L3.
Мы выбрали игры с интенсивным использованием ЦП, чтобы привлечь лучшее к наименее производительным процессорам в играх. Cyberpunk 2077 , FarCry 6 , Microsoft Flight Simulator: 2021 , Cities Skyline , Total War: Warhammer III и Red Dead Redemption 2 — наш выбор игр.
Наши результаты включают данные 1080p и 1440p . Мы рассчитали среднее значение для каждого процессора. Так же, как одноядерный и многоядерный ранжирование, эта иерархия также рассчитывается в процентах.
Так же, как одноядерный и многоядерный ранжирование, эта иерархия также рассчитывается в процентах.
Ниже приведен наш рейтинг игровых процессоров:
Удивительно, но одноядерный чемпион i9 13900KS теперь стал третьим заполнителем, когда дело доходит до игр. Ryzen 9 7950X3D и 7900X3D занимают первые два места соответственно.
Само собой разумеется, что когда в апреле 2023 года выйдет Ryzen 7 7800X3D , он в конечном итоге будет работать наравне с двумя другими братьями из серии 7000X3D.
Остальная часть дерева иерархии выглядит как процессоры 13-го поколения в середине, за которыми следуют процессоры Ryzen 7000. Ryzen 7 5800X3D , однако, застает нас врасплох и входит в пятерку лучших процессоров для игр. Излишне говорить, что это один из лучших игровых процессоров по соотношению цена-качество.
Возвращаясь к списку, из-за огромного количества SKU нам пришлось выбрать для учета процессоры последнего поколения. Но наша команда усердно работает над тем, чтобы добавить больше процессоров в список игровой иерархии.
Но наша команда усердно работает над тем, чтобы добавить больше процессоров в список игровой иерархии.
В этом контексте ожидайте, что Intel 12-го поколения и Ryzen серии 5000 сходятся во взглядах. Но в основном чипы Intel вырываются вперед в играх.
Рейтинг производительности ЦП с iGPUВ последние годы APU привлекли большое внимание, особенно из-за впечатляющей производительности iGPU. Эти детали почти убивают необходимость в графическом процессоре начального уровня для игр или другой работы.
Однако из-за разделения мощности между iGPU и ядром ЦП они в основном находятся в нижней половине списка иерархии с точки зрения чистой производительности. Однако более новые архитектуры ядра в значительной степени сокращают этот разрыв.
Итак, мы оценили APU отдельно. Но наш тест не включает любые мобильные APU, такие как 6800U, 6600H и т. д.
Ниже приведены показатели производительности доступных APU для настольных ПК: 8 Дзен 3 ядер и Vega 8 iGPU. Ryzen 5 5600G и Ryzen 7 4750G последнего поколения занимают прочные позиции в иерархической лестнице соответственно.
Ryzen 5 5600G и Ryzen 7 4750G последнего поколения занимают прочные позиции в иерархической лестнице соответственно.
Как и ожидалось, превосходная графическая архитектура AMD доминирует в диаграмме производительности APU, несмотря на то, что ей уже 9 лет.0005 Вега iGPU. Это позволяет Intel UHD оказаться в нижней части рейтинга.
Рейтинг ЦП на основе эффективностиПо мере развития микроархитектуры производители позволяют чипам потреблять как можно больше энергии для достижения максимальной производительности. Это эффективно для вытеснения конкурентов, даже если поле уже, чем игольная петля.
Такая практика не всегда хороша, скорее на бумаге указывается большее число с такими оговорками, как тепло и дросселирование процессора . Итак, мы взяли на себя смелость и ранжировали процессоры по их производительности на каждый потребляемый ватт.
В нашем тестировании мы протестировали чипы в Cinebench R23 с полной загрузкой ядра и наблюдали среднее энергопотребление в сочетании с производительностью.
Во-первых, давайте посмотрим на энергопотребление протестированных нами чипов:
0005 295 Вт мощности. Однако аналоги AMD обладают сопоставимой производительностью при значительно меньшем энергопотреблении.
Теперь самое интересное, и вот как выглядит производительность на ватт для этих процессоров.
Ниже приведена иерархия ЦП, основанная на производительности на ватт:
Не-X Ryzen 9 7900 превосходит всех. Производительность, которую он дает при таком уровне мощности, феноменальна. Предыдущий чемпион по эффективности Ryzen 9 5950X занимает 3-е место, отставая от лидера по эффективности почти на 100 баллов по производительности на ватт.
Совершенно новый Ryzen 9 7950X3D работает исключительно хорошо и может похвастаться позицией 2. Это на 180 градусов отличается от разочаровывающего профиля мощности ванильного 7950X, несмотря на то, что он построен на сверхэффективном 5-нм техпроцессе TSMC FinFET .
Лучшие процессоры Intel i9 13900K/KS и i7 13700K занимают свое место на другом конце спектра. Но вы всегда можете настроить эти процессоры, понизив их напряжение.
Список уровней: иерархия ЦП с другой точки зрения
Иерархия на основе уровней помогает сгруппировать любой компонент. И процессоры не исключение. Различные SKU имеют разную цену и ориентированы на определенный сегмент клиентов. Мы уже рассмотрели аспект производительности 3-х поколений процессоров Intel и AMD.
Важно отметить, что наша многоуровневая иерархия поддерживается двумя последними поколениями процессоров Intel. Благодаря этому Intel представила большие маленькие ядра со своими процессорами 12-го поколения. Это совершенно неожиданно изменило набор продуктов.
Мы больше не можем сопоставлять i7 с SKU R7 из-за различий в количестве ядер. То же самое касается SKU продуктов i5 и R5. Например, и i7, и R7 раньше были частью 8C, 16T. Но Intel добавила еще 4 эффективных или маленьких ядра вместе с обычными 8 производительными ядрами на процессоре i7 12700K.
Всего за одно поколение они добавили еще 4 эффективных ядра к процессорам i7 13-го поколения. Это не соответствует аналогам Ryzen 7, поскольку они все еще 8C и 16T против 9.0005 16 ядер (8P + 8E) и 24 потока конкурентов.
Итак, учитывая цену, характеристики и производительность, мы выбрали эти процессоры.
В этом разделе я расскажу о ранжировании ЦП по сегментам.
Следуйте таблице ниже:
| Сегмент | Intel | 9000 5 AMD |
|---|---|---|
| Уровень S — Ultra High-End | i9 13900KS/K/KF | R9 7950X/3D |
| Уровень A — High-End | i7 13700K/KF | R9 7900X 3D |
| i9 12900K/KS/KF | R9 7900X | |
| R9 7900 | ||
| R9 5950X | ||
| Уровень B — High-Mid-End | i5 13600K | R7 7700X |
| i7 12700K | R7 7700 | |
| R9 5900X | ||
| R9 3950X | ||
| 5800X3D | ||
| Уровень C — средний уровень | i5 13500 | R5 7600X 9007 9 |
| i5 12600K | R5 7600 | |
| i5 13400/F | R7 5800X | |
| R7 5700X | ||
| R7 5700G | ||
| Уровень D — Низко-средний уровень | i5 12500 | R5 5600X |
| i5 12400/F | R5 5600 | |
| R5 5600G | ||
| Уровень F — начальный уровень | i3 13100 | R5 5500 |
| i3 12100 9007 9 |
Конец Примечания
Список иерархии ЦП не является постоянным. С каждым новым поколением продуктов этот список будет меняться. Поэтому мы будем добавлять больше данных и продолжать обновлять графики производительности.
С каждым новым поколением продуктов этот список будет меняться. Поэтому мы будем добавлять больше данных и продолжать обновлять графики производительности.
А пока воспользуйтесь нашими таблицами иерархии и выберите лучший ЦП в соответствии с вашими потребностями и предпочтениями.
Удачной сборки ПК!
ЦП AMD (процессор) Список в порядке производительности
СОДЕРЖАНИЕ
1Как процессоры AMD ранжированы в порядке производительности – есть ли простой список, который можно проверить?
Отслеживание производительности современных процессоров AMD может быть затруднено. AMD выпускает новые SKU процессора каждые несколько месяцев и совершенно новые поколения ЦП примерно каждые полтора года.
Какой процессор AMD лучше всего подходит для вас зависит от типичных рабочих нагрузок . Если вы профессионал, занимающийся активной работой, такой как редактирование фотографий или 3D-моделирование, или запускаете игры AAA, процессор с высокой производительностью одного ядра важнее, чем процессор с большим количеством ядер.
Однако, если вы выполняете рабочие нагрузки, которые можно легко распараллелить, такие как 3D-рендеринг, редактирование видео, пакетная обработка и машинное обучение, ЦП AMD с большим количеством ядер это правильный выбор для вас.
Большинство рабочих нагрузок, тем не менее, могут использовать как высокую одноядерную производительность и высокая многоядерная производительность, по крайней мере, в определенной степени, и именно поэтому я создал этот удобный небольшой список процессоров AMD в порядке производительности (одноядерные И многоядерные) , которые вы можете
ЦП AMD (процессор) Список в порядке производительности
| Название ЦП | Одноядерная производительность | Многоядерная производительность | Общая производительность* | 9 0522 Производительность / доллар*$ Цена (MSRP) | |
|---|---|---|---|---|---|
| AMD Threadripper 3990X | 1262 | 75671 | 3990 | ||
| AMD Threadripper Pro 3995WX | 1231 | 73220 | 5489 | ||
| AMD Epyc 7702P | 993 | 48959 | 4425 | ||
| AMD Threadripper 3970X | 13 08 | 46874 | 1999 | ||
| AMD Threadripper Pro 3975WX | 1244 | 43450 | 2749 | ||
| AMD Threadripper 3960X | 1307 | 34932 | 1399 | ||
| AMD Threadripper 2990WX 9 0079 | 1005 | 29651 | 1799 | ||
| AMD Ryzen 9 5950X | 1684 | 28782 | 907 28600 | ||
| AMD Threadripper Pro 3955WX | 1401 | 27175 | 1149 | ||
| AMD Ryzen 9 3950 AMD Ryzen 9 5900X | 1670 | 22046 | 450 | ||
| AMD Threadripper 1950X | 1027 | 19635 | 999 | ||
| AMD Threadripper 2950X | 1135 | 18797 | 899 | ||
| AMD Ryzen 9 3900X | 1312 | 18682 | 434 | ||
| AMD Ryzen 9 3900XT | 1354 | 18511 | 499 | ||
| AMD Threadripper 1920X | 1054 | 15038 | 799 | ||
| AMD Ryzen 7 5800X | 1596 | 14812 | 300 | ||
| AMD Ryzen 7 5700G | 1535 | 14350 | 359 9 0079 | ||
| AMD Ryzen 7 3800X | 1346 | 13848 | 339 | ||
| AMD R айзен 7 3800XT AMD Ryzen 7 3700X | 1345 | 12195 | 329 | ||
| AMD Райзен 5 5600X | 1593 | 11201 | 230 | ||
| AMD Ryzen 7 2700X | 1102 | 10140 | 329 | ||
| AMD Ryzen 5 3600XT | 1330 | 9945 | 249 | ||
| AMD Ryzen 5 3600X | 1323 | 9526 | 236 | ||
| AMD Ryzen 5 3600 | 1245 | 9073 | 199 | ||
| AMD Threadripper 1900X | 1005 | 8979 | 299 | 1299 | 6787 | 120 |
| AMD Ryzen 3 3100 | 1105 | 5423 | 9 072899 | ||
| AMD Райзен 5 5600 | 1472 | 11429 | 199 | ||
| AMD Райзен 5 5500 | 1372 | 9 0076 10710159 | |||
| AMD Ryzen 9 7950X | 2062 | 40795 | 9 0728 | 699 | |
| AMD Ryzen 9 7900X | 2044 | 30020 | 549 | ||
| AMD Ryzen 7 7700X | 2010 | 20144 | 399 | ||
| AMD Ryzen 5 7600X | 1981 | 14780 | 299 | 9 0072||
| AMD Ryzen 7 5800X3D | 1491 | 15003 | 449 | ||
| AMD Ryzen 7 5700X | 1523 | 14214 | 299 | ||
| AMD Ryzen 5 5600G | 1506 | 11285 | 259 | ||
| AMD Райзен 7 1700X | 987 | 8869 | 230 | ||
| AMD Threadripper PRO 5995WX | 1437 | 90 076 664036499 | |||
| AMD Threadripper PRO 5975WX | 1475 | 53977 | 9 0728 | 3299 | |
| AMD Threadripper PRO 5965WX | 1498 | 40535 | 2399 | Имя процессора | Производительность одного ядра | Многоядерная производительность | Общая производительность* | Производительность в долларах* | Цена (рекомендованная производителем розничная цена) |
*Взвешенно. Общая производительность (столбец) относится к AMD Ryzen 7 5800X с одинаковым весом при 50% одноядерной и 50% многоядерной производительности. Это взвешивание будет указывать на хорошую всестороннюю производительность для большинства рабочих нагрузок, не выходя за рамки слишком низкой одноядерной производительности или слишком большого количества ядер.
Общая производительность (столбец) относится к AMD Ryzen 7 5800X с одинаковым весом при 50% одноядерной и 50% многоядерной производительности. Это взвешивание будет указывать на хорошую всестороннюю производительность для большинства рабочих нагрузок, не выходя за рамки слишком низкой одноядерной производительности или слишком большого количества ядер.
Примечание. Если у вас очень конкретные задачи , которые, как вы знаете, могут эффективно использовать, например, много ядер, отсортировать таблицу по многоядерной производительности . Или, если вы уверены, что для ваших рабочих нагрузок требуется только высокая производительность с одним ядром , отсортируйте по этому столбцу.
Контрольный показатель, использованный для этого списка, — одиночные и множественные оценки Cinebench R23.
Лучший процессор AMD по соотношению цена-качество
Процессоры AMD начального уровня имеют чрезвычайно высокую ценность, учитывая их производительность на доллар. И AMD Ryzen 3 3100, и 3300X лидируют в диаграмме «производительность/доллар», учитывая их очень разумную цену.
И AMD Ryzen 3 3100, и 3300X лидируют в диаграмме «производительность/доллар», учитывая их очень разумную цену.
Это не означает, что все должны покупать Ryzen 3. Их общая производительность несколько ограничена, и у них меньше ядер, чем может потребоваться для ваших рабочих нагрузок, но они отлично подходят для решения многих низкоуровневых задач общей производительности.
Если ваш бюджет ограничен, но вам по-прежнему требуется более высокая производительность, чем предлагает Ryzen 3, Ryzen 5 7600X и Ryzen 5 5600X — два лучших универсальных процессора для большинства рабочих нагрузок и игр. Если вы готовы потратить больше, 12-ядерный процессор 5900X и 7900X обеспечивает серьезную производительность, если ваши рабочие нагрузки могут использовать больше ядер.
В конечном счете, лучший процессор AMD за свои деньги зависит от ваших рабочих нагрузок, требований и, конечно же, доступного бюджета.
Давайте взглянем на лучший процессор в определенных ценовых диапазонах:
Лучший процессор AMD до 500 долларов
После недавнего значительного снижения цен самым производительным процессором AMD до 500 долларов является AMD Ryzen 9 5900X (за ним следует Райзен 7 7700Х).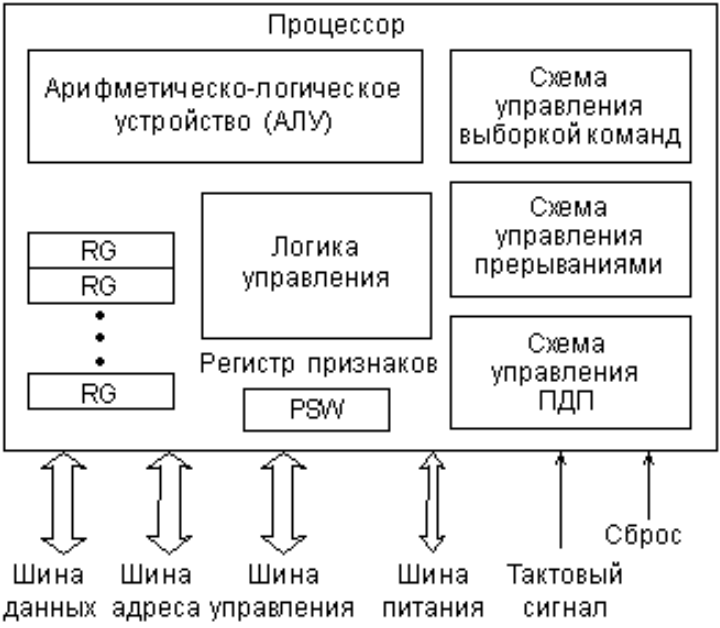 Всего за 450 долларов 12-ядерный процессор представляет собой мощный процессор, который без проблем справляется с любыми высокопроизводительными рабочими нагрузками.
Всего за 450 долларов 12-ядерный процессор представляет собой мощный процессор, который без проблем справляется с любыми высокопроизводительными рабочими нагрузками.
С базовой тактовой частотой 3,7 ГГц и ускорением до 4,8 ГГц процессор Ryzen 9 поддерживает 24 потока при потребляемой мощности (TDP) 105 Вт.
Лучший процессор AMD до 400 долларов
AMD Ryzen 7 7700X — лучший процессор, который можно купить менее чем за 400 долларов.
8 ядер и 16 потоков работают на базовой частоте 4,5 ГГц и форсированной 5,4 ГГц (здесь мы написали статью, объясняющую базовые и форсированные частоты). AMD Ryzen 7 7700X производится на узле TSMC 5NM, что делает его чрезвычайно энергоэффективным при TDP 105 Вт.
Лучший процессор AMD до 200 долларов
AMD Ryzen 5 3600 и 3600X — лучшие процессоры AMD до 200 долларов. Если вы можете найти его ниже 200 долларов, 5600X является преемником этих процессоров нового поколения со значительно более высокой одноядерной производительностью и энергоэффективностью.
Все процессоры Ryzen 5 являются 6-ядерными процессорами. 12 потоков процессора 5600X работают на базовой частоте 3,7 ГГц и могут повышаться до 4,6 ГГц.
Какой процессор AMD имеет наибольшее количество ядер?
В настоящее время AMD Threadripper 3990X (обзор) и PRO 39Оба 95WX имеют в своем распоряжении 64 ядра / 128 потоков.
На стороне сервера модели Epyc 7713P, 7h22, 7702P и 7742 также имеют 64 ядра, которые работают на разных частотах и имеют разные значения TDP.
Какой самый быстрый процессор AMD?
Это зависит от определения «быстро». Самая высокая многоядерная производительность обеспечивается процессорами AMD с самой высокой тактовой частотой и количеством ядер, такими как Threadripper 3990X.
Самая высокая одноядерная производительность у Ryzen 97950X.
Ryzen 7 лучше, чем Ryzen 5?
Да. Сегментация процессоров AMD выглядит следующим образом:
- Ryzen 9
- Райзен 7
- Райзен 5
- Ryzen 3
Чем выше число, тем выше число ядер, выше производительность одного ядра и выше энергопотребление.