Национальный корпус русского языка
Подробнее о Корпусе
Состав и структура
Статистика корпуса
Руководство пользователя
Портрет слова
Частотный словарь
НКРЯ в школе
21.07.2023
Портрет слова в Основном корпусе пополнился данными об однокоренных словах. В новом виджете сейчас показаны гнезда однокоренных слов. Пока эта опция доступна только для слов с одним корнем (например, стол, но не пароход), которые размечены вручную в словаре морфемного анализа. Данные о других словах появятся в ближайшие месяцы, но и сейчас в Портрете можно увидеть интересные связи между словами.
По традиции рядом с новым виджетом вы увидите кнопку «Оценить» и сможете сообщить нам о замеченных ошибках. Благодаря вашей обратной связи мы регулярно улучшаем нейролингвистические модели, лежащие в основе Портрета слова. Нам очень интересно и важно, что вы думаете о первой версии модели однокоренных слов.
Появилась возможность точнее задавать условия лексико-грамматического поиска в основном, газетном и региональном корпусах. Как вы знаете, в форме поиска можно задавать условия на расстояние между словами. До сегодняшнего дня если заданный диапазон включал 0 (например, от -1 до 1), то в результатах поиска найденные слова могли совпадать. Теперь вверху формы поиска можно выбрать опцию «совпадения слов исключаются» чтобы убрать нулевое расстояние из диапазона. Например, можно выяснить, рядом с какими одушевленными существительными во множественном числе перечисляются крестьяне, причем с любым порядком сочинения (рабочие и крестьяне, крестьян и мещан…). Вот получившийся список. Раньше аналогичный запрос находил бы и слово крестьянин во множественном числе в одиночестве, без «соседей» (поскольку при расстоянии 0 оно само удовлетворяет всем условиям на сочиненное существительное).
Подпишитесь на наш телеграм канал, чтобы следить за обновлениями и получать иллюстрированные инструкции по работе с корпусом.
21.07.2023
В корпусе «Социальные сети» исправлены ошибочные датировки и устранены повторы текстов. Теперь корпус стал действенным инструментом по изучению диахронии языковых явлений: так, доступна хронология употребительности получающих популярность или выходящих из моды языковых единиц (ср. хайп, превед, уметь во что-л.).
В корпус включена коллекция текстов социальных сетей, подготовленная сотрудниками и студентами Воронежского государственного университета. В нее вошли материалы «Большого воронежского форума» и других локальных сетей Воронежа, записи известных воронежских блогеров, обсуждения в местных группах на популярных платформах VK, Telegram, Livejournal и др. — всего около 22,8 млн словоупотреблений. Тексты воронежской коллекции имеют более подробную метатекстовую разметку и охватывают период 2001—2023 годов. В дальнейшем планируется включить в корпус материалы социальных сетей других регионов России.
03.07.2023
В портрете слова появилось несколько улучшений:
- Добавлены новые скетчи — сочиненные существительные, прилагательные, глаголы и наречия.
- В основном корпусе для всех скетчей включена возможность по клику в ячейке таблицы перейти к примерам употребления сочетания слов в корпусе.
- Благодаря обратной связи от заинтересованных пользователей улучшены морфемные разборы. Пожалуйста, продолжайте информировать нас о замеченных ошибках с помощью кнопки “Оценить”.
Оптимизирована работа с информацией о говорящих в Устном корпусе. Теперь в результатах поиска выделены имя и роль, а подробную информацию о социологических параметрах можно получить во всплывающем окне, которое открывается по клику на имени.
При выгрузке результатов поиска в Excel на дополнительном листе Info теперь отображается информация о параметрах запроса, результаты которого скачаны в файл, а также есть ссылка на сам запрос.
16.06.2023
Сервис «Портрет слова» продолжает развиваться: у существительных в основном корпусе появился новый виджет, в котором показаны формы слова, которые встречаются в корпусе более 5 раз. Для одной и той же формы существительного (падеж + число) могут отображаться разные морфологические, фонетические и орфографические варианты, если такие встречаются в корпусе. Поскольку в основном корпусе внедрена автоматическая разметка, среди форм могут встречаться ошибочно отнесенные к искомому слову. Если вы заметите такие несоответствия, сообщайте нам о найденных ошибках с помощью кнопки «Оценить».
Для одной и той же формы существительного (падеж + число) могут отображаться разные морфологические, фонетические и орфографические варианты, если такие встречаются в корпусе. Поскольку в основном корпусе внедрена автоматическая разметка, среди форм могут встречаться ошибочно отнесенные к искомому слову. Если вы заметите такие несоответствия, сообщайте нам о найденных ошибках с помощью кнопки «Оценить».
Во всех корпусах в новом интерфейсе появилась возможность перейти из всплывающего окошка с информацией о разборе слова в портрет слова и посмотреть подробную информацию о нём.
Устный корпус переведен на новый интерфейс. Теперь в новом дизайне отображается поиск по корпусу, доступны «Портреты слов» устного корпуса, корпус подключен к «Обзору возможностей».
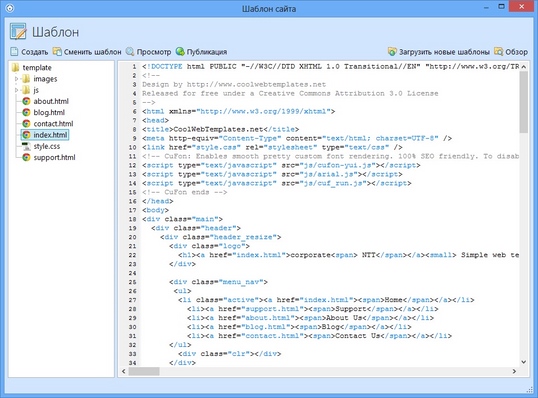
Что такое index.html и для чего он нужен?
В каждой файловой системе сайта существует основной файл, который содержит в себе всю структуру сайта – все файлы сайта. Данный основной файл и будет отображать главную страницу сайта. Все содержимое, размещенное в этом файле, будет выводиться на основную страницу сайта. Имя этого файла — index.html.
Все содержимое, размещенное в этом файле, будет выводиться на основную страницу сайта. Имя этого файла — index.html.
Чтобы подробно разобраться в этой теме, пройдите по ссылке https://webshake.ru/kurs-html-dlya-nachinayushih и запишитесь на курс HTML для начинающих. Там Вам объяснят, как и из чего создаются веб-страницы.
То есть любой сайт состоит из главной папки (главной страницы сайта) и вложенных в эту папку других папок нижнего уровня (остальных страниц сайта). Если пользователь хочет попасть на какую-либо страницу сайта, то путь к данному файлу серверу понятен, так как задан точный адрес страницы, например http:// example.org/products/ , данная страница единственная и неповторимая, другой такой страницы, с таким адресом не существует. А вот когда пользователь вводит адрес главной страницы — http:// example.org/ , которая является главной папкой – корневой директорией, а в этой папке размещено еще множество папок (остальные страницы сайта), то серверу непонятно, какую именно страницу (папку) из этого перечня папок (включая и главную папку) выдавать браузеру по требованию пользователя. Ведь главная папка подобно матрешке напичкана папками нижнего уровня, и сервер не в состоянии понять открывать ли главную страницу сайта или какую-либо еще страницу (файл) вложенную в эту самую главную страницу, или открывать сразу одним махом все страницы вместе с главным документом сайта. И чтобы не вводить сервер в заблуждение, было введено такое понятие как индексный файл. Работает это так: при вводе пользователем адреса главной страницы, сервер выдает браузеру исключительно ту страницу, в которой прописано имя index.html и не какую больше, т.е. выдает файл –index.html. Данный файл с таким именем и будет являться главной страницей.
Ведь главная папка подобно матрешке напичкана папками нижнего уровня, и сервер не в состоянии понять открывать ли главную страницу сайта или какую-либо еще страницу (файл) вложенную в эту самую главную страницу, или открывать сразу одним махом все страницы вместе с главным документом сайта. И чтобы не вводить сервер в заблуждение, было введено такое понятие как индексный файл. Работает это так: при вводе пользователем адреса главной страницы, сервер выдает браузеру исключительно ту страницу, в которой прописано имя index.html и не какую больше, т.е. выдает файл –index.html. Данный файл с таким именем и будет являться главной страницей.
Если же на сайте данный файл будет отсутствовать, то сервер, при запросе главной страницы пользователем, будет выгружать ему все имеющиеся файлы, расположенные в главной папке сайта, и вместо главной страницы, пользователю отобразится некорректная страница, с перечнем всех файлов сайта, похожая на соединение с ftp-сервером. Поэтому при создании сайта, в обязательном порядке необходимо также создать файл index. html, без этого файла сайт полноценно работать не будет.
html, без этого файла сайт полноценно работать не будет.
Если у нас имеется сайт http:// example.org, то в нем должна быть главная страница с адресом — http:// example.org/index.html.Данная страница и будет являться индексным файлом.
Самому же пользователю, чтобы попасть на главную страницу сайта, достаточно ввести доменное имя сайта- http:// example.org, а имя файла – index.html прописывать в адресной строке совсем не обязательно. Да и создателю сайта, к ссылке на главную страницу не обязательно дописывать имя index.html, главное чтобы был в наличии файл index.html в файловой системе. К тому же ссылка с окончанием index.html будет выглядеть слишком громоздко, и это не совсем будет удобно для пользователей.
Автор: Пётр Кочков
Похожие статьи:
Веб-сервер. Как создать простой файл index.html, в котором перечислены все файлы/каталоги?
Существует достаточно веских причин для явного отключения автоматических индексов каталогов в Apache или других веб-серверах.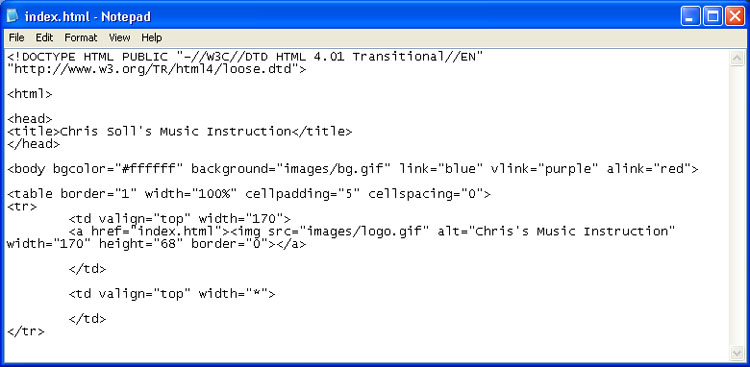 Или, например, вы можете захотеть включить в индекс только определенные типы файлов. В этих случаях вам может понадобиться статически сгенерированный файл index.html в определенных папках.
Или, например, вы можете захотеть включить в индекс только определенные типы файлов. В этих случаях вам может понадобиться статически сгенерированный файл index.html в определенных папках.
tree tree — минималистичная утилита, доступная в большинстве unix-подобных систем (ubuntu/debian: sudo apt install tree , mac: brew install tree , windows: zip). tree может генерировать обычный текст, XML ( -X ), JSON ( -J ) и HTML ( -H ).
Создать индекс каталога HTML на один уровень в глубину (опустить сам сгенерированный файл index.html ), включить размеры ( -s ) и метки времени ( -D ):
tree -H '.' -L 1 --noreport --dirsfirst -T 'Загрузки' -s -D --charset utf-8 -I "index.html" -o index.html
Включать только определенные типы файлов, которые соответствуют шаблону глобуса, например.
*.zip и *.gz файлы, сначала каталоги, включают размер и метки времени с пользовательским форматом даты:
дерево -H '.' \
-Л 1 \
--noreport \
--dirsfirst \
--кодировка utf-8 \
--игнорировать регистр \
--timefmt '%d-%b-%Y %H:%M' \
-I "index.html" \
-T 'Загрузки' \
-с -Д \
-P "*.zip|*.gz" \
-о index.html
-Ч '.'включить режим HTML и установить базовый href, может быть относительным, например..или абсолютный, например./ файлы.
-L 1ограничить только текущий каталог
--noreportне включать сводку в конце
--dirsfirstсначала поставить каталоги
--charset utf-8обеспечить кодировку UTF-8 9005 3--ignore-caseсделать параметры-Iи-Pнечувствительными к регистру
--timefmt '%d-%b-%Y %H:%M'установить формат даты (подробности см.
-I "index.html"I игнорировать сгенерированныйфайл index.html
-Tустановить пользовательский T itle
-sвключить файл 900 03 S izes
-Dвключает модифицированный d ates
-P "*.zip|*.gz"фильтр по шаблону P шаблон, например. zip/gz files
-o index.htmlзапись в файл (по умолчанию стандартный вывод)
дерево не имеет флага для отключения кредитов в нижнем колонтитуле HTML, но вы можете удалить их, пропустив через sed :
# удалить 7 строк, начиная со строки, соответствующей
дерево -Ч'.' -L 1 --noreport --charset utf-8 | sed -e '/
/,+7d' > index.html
Все поддерживаемые параметры см. в tree --help или man tree
Рекурсивно создавать файлы index.
 html в подкаталогах
html в подкаталогах В сочетании с gnu find вы можете рекурсивно создавать индексные файлы в поддереве, например. с:
найти . -type d -print -exec sh -c 'дерево "$0" \
-Х "." \
-Л 1 \
--noreport \
--dirsfirst \
--кодировка utf-8 \
-I "index.html" \
-T "Пользовательский заголовок" \
--игнорировать регистр \
--timefmt "%d-%b-%Y %H:%M" \
-с \
-Д \
-o "$0/index.html"' {} \;
Сценарий генератора с рекурсивным обходом
Мне нужен был генератор индексов, который я мог бы стилизовать так, как я хочу, поэтому в итоге я написал этот скрипт (python 3), который в дополнение к настраиваемому стилю может также рекурсивно генерировать файл index.html во всех вложенных подкаталогах (с --recursive 9000 8 или флаг file-server caddyserver. Он включает время последнего изменения и отображается в мобильных окнах просмотра. -r ). Стиль во многом заимствован из модуля 
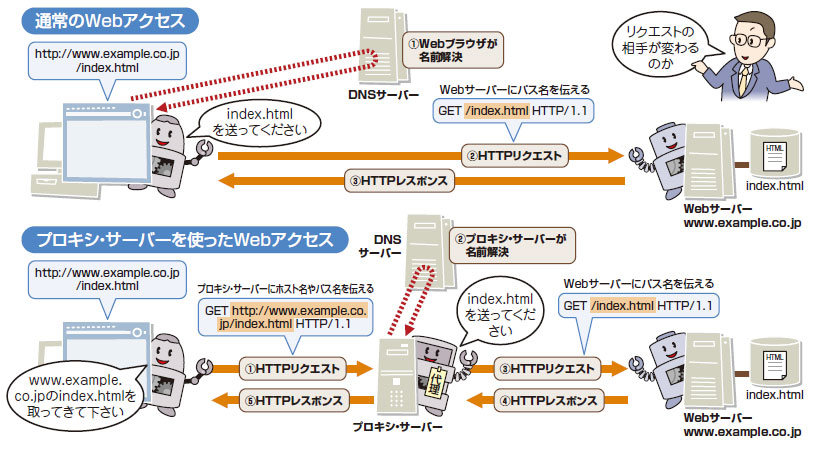
ftp — Как заставить веб-сайт запускать файл index.html?
Если вы хотите отображать содержимое файла index.html при запросе к домену вашего веб-сайта, скажем, domain.com, то все, что вам нужно сделать, это загрузить файл index.html в правильный корневой каталог документов на вашем сервере.
Корень документа — это папка, в которой хранятся файлы веб-сайта для доменного имени.
Корневые каталоги документов могут называться по-разному в зависимости от конфигурации вашего сервера, однако обычно они называются так:
/www/ /public_html/
Они также могут находиться в другом каталоге, таком как
/home/myusername/public_html/
Ваш основной домен обычно находится в папке www или public_html .
Когда кто-то пытается загрузить ваш веб-сайт и не вводит вручную имя файла (например, index.php или index.html), сервер пытается загрузить «индекс каталога». Индекс каталога — это список файлов, которые он должен загрузить.
Индекс каталога — это список файлов, которые он должен загрузить.
Например, если вы введете domain.com (т. е. не domain.com/index.php), сервер попытается загрузить файлы в следующем порядке. Если файл не найден, то пытается загрузить следующий файл в списке:
http://domain.com/index.html http://домен.com/index.htm http://домен.com/index.php
…и, наконец, если ваш сервер не находит ни один из этих файлов, он просто возвращает список всех файлов в каталоге. См. Изображение
Чтобы этого не произошло, необходимо создать index.html и загрузите его в корневой каталог документов сервера, как мы упоминали ранее.
Попробуйте создать свой первый файл .html с помощью простого текстового редактора, скопировав HTML-разметку ниже в новый файл, а затем сохраните его как index.html или загрузите файл здесь
<голова>Первая HTML5-страница моего веб-сайта <тело>Добро пожаловать!
Извините, но наш сайт находится в разработке.

Продолжайте и загрузите файл index.html в корневой каталог документов вашего сервера, а затем попытайтесь получить доступ к домену вашего веб-сайта. Вероятно, он загрузит ваш index.html , и теперь ваш сервер будет отображать содержимое файла index.html вместо «списка файлов DirectoryIndex».
КОГДА ЭТО НЕ РАБОТАЕТ:
Если вы только что поместили файл index.html или index.php в корневую папку документов вашего сервера, например: /public_html/, и вы по-прежнему не загружаете эти файлы по запросу к вашему домену, скорее всего, на вашем сервере отсутствует определенная конфигурация для «DirectoryIndex Directive».
Если этого не произошло, вы можете использовать директиву DirectoryIndex в файле .htaccess, чтобы указать пользовательский файл или файлы, которые веб-сервер ищет, когда посетитель запрашивает каталог. Чтобы включить директиву DirectoryIndex, используйте текстовый редактор для создания/изменения файла . htaccess следующим образом. Замените имя файла на файл, который вы хотите отображать всякий раз, когда пользователь запрашивает корневой каталог документов сервера:
htaccess следующим образом. Замените имя файла на файл, который вы хотите отображать всякий раз, когда пользователь запрашивает корневой каталог документов сервера:
DirectoryIndex имя файла
Вы также можете указать несколько имен файлов, и веб-сервер будет искать каждый файл, пока не найдет совпадение.
Откройте текстовый редактор и скопируйте следующий пример директивы, затем вставьте ее в новый файл:
DirectoryIndex index.php index.html index.htm
Сохраните файл как .htaccess
Без расширения файла, просто назовите его как .htaccess, поставив перед ним точку (.), чтобы убедиться, что это скрытый файл.
В этой директиве, когда посетитель запрашивает имя каталога, веб-сервер сначала ищет файл index.php. Если он не находит файл index.php, он ищет файл index.html и так далее, пока не найдет совпадение или пока не закончатся файлы для поиска.
Теперь загрузите файл .