Весь комплекс печатных услуг в Перми. Общирная сеть печатных салонов в Перми. Цифровая печать, цветное и черно-белое копирование документов, сканирование документов, ризография в Перми
Html кодировка windows 1251: Атрибут charset | htmlbook.ru
Содержание
Meta теги. Учебник html
Глава 10
В первой главе этого учебника, об общем построении html документа, я говорил о том, что все html документы должны иметь вот такой шаблон кода:
<html> — начало документа <head> — начало головы </head> — закрытие головы <body> — начало тела </body> — закрытие тела </html> — конец документа
Где между тегами <body> </body> указывается информация предназначенная для вывода на экран в нужном нам виде, а между тегами <head> </head> исключительно служебная информация предназначенная для поисковых систем и браузеров тех или иных пользователей. Так что же это за информация такая и для чего она нужна? Отвечу, планомерно и порционально в этой главе.
С тегом <title> мы уже знакомы, с помощью него мы указываем имя документа в заголовке страницы.
Теперь новый тег <meta> (закрывающего тега не требует) с помощью него мы и будем указывать эту самую служебную информацию на нашей страничке.<meta> тег имеет следующие атрибуты:
http-equiv — указывает браузеру как следует обработать основное содержание документа, точнее на основе каких данных.
name — информационное имя. (применяется в паре с атрибутом content)
content — информационное содержание, связанное с мета именем (name)
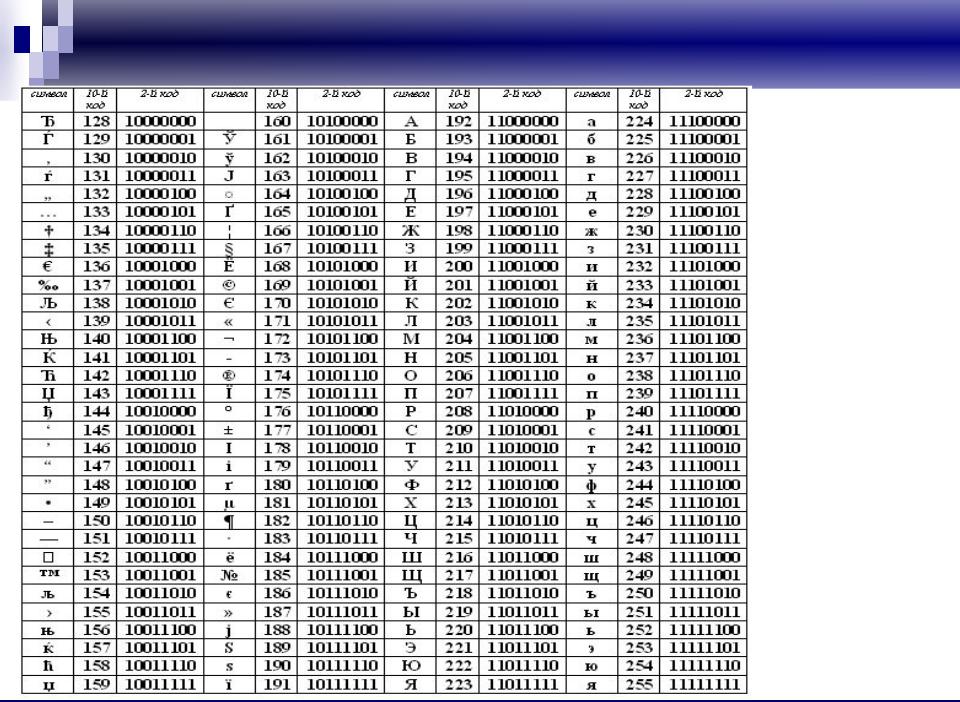
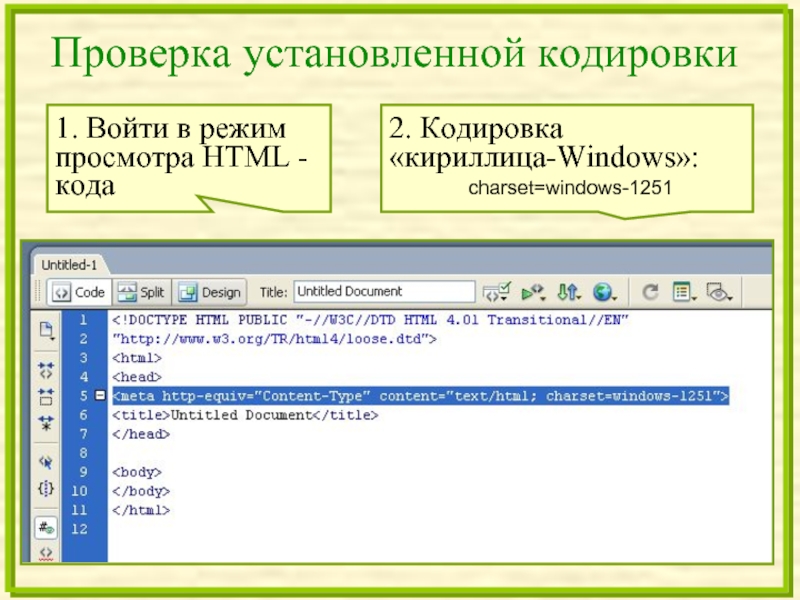
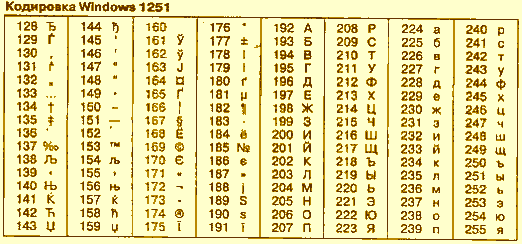
Сначала расскажу зачем необходима эта строка в заголовке html документа. Данная запись указывает браузеру кодировку в которой была написана данная страница — формат документа и раскладку клавиатуры, в данном случае это кириллица для Windows.
Если эту строку не писать в заголовке страницы, то есть большая вероятность что весь текст на Вашей странице отобразится в виде непонятных человеку «иероглифов» у разных пользователей тех или иных браузеров. Конечно, пользователь может применить к такому документу команду в браузере Вид->Кодировка->Кириллица, но он может не знать о данной функции, да и зачем утруждать человека данным действием.
Теперь разберём по «слогам» нашу запись: <meta http-equiv=»Content-Type» — указываем что в этом мета теге мы будем заниматься Content-Type — типом содержания Content=»text/html; — а именно его текстом Charset=Windows-1251″>
— документ для Windows — Кириллица где 1251 кодировка раскладки клавиатуры, так например Английская клавиатура будет задаваться Charset=Windows-1252
В настоящее время продвинутые веб-мастера рекомендуют использовать кодировку UTF 8
Данные метаописатели предназначены для заявления об авторских правах непосредственно в заголовке html кода, так name=»author» указывает имя автора страницы, а name=»copyright» авторское право (копирайт) в котором может указываться фамилия, имя, отчество автора сайта, название фирмы, бренда.. и т. д. Кроме того включив в заголовок документа такое описание Вы значительно упростите задачу поисковой машине при поиске Вашего сайта по имени автора, названию фирмы, бренду…
Пример:
<meta name =»Generator» Content=»Microsoft Notepad»>
Если хотите можете указать с помощью какого html редактора была написана данная страница.
Пример:
<meta name=»description» Content=»Производим закупку по выгодным ценам рогов и копыт!»>
Description — краткое описание страницы.
Данное описание частенько используется поисковыми системами для вывода в результатах поиска, по какому либо запросу, информации о сайте и его назначении.
Keywords — ключевые слова веб-страницы, опять таки предназначены для поисковых машин.
Представьте что Вы ищете в какой либо поисковой системе сайт с информацией о том где можно продать те же рога и копыта 🙂 Какие слова и фразы Вы будите вводить в строке «Поиск»? ну наверно что то типа: «Где продать коровьи рога?» или «Реализовать копыта по выгодной цене» Так вот если определить ключевые слова и так сказать предугадать мысли потенциального посетителя можно надеяться на то, что та или иная поисковая система выдаст ссылку на Ваш сайт в первых строчках результата поиска.
Конечно ввод данного метоописателя не есть гарант того что именно Ваш сайт займет первые места в поиске по данным словам, но всё же не стоит им пренебрегать. Впрочем, оптимизация и раскрутка сайта это отдельная тема для разговора.
Помните что описание description не должно превышать по длине более 200 символов, а ключевые слова keywords 1000 символов, иначе это может пагубно отразится при продвижении Вашего сайта в ТОП поисковых систем.
Думаю понятно.. здесь указывается адрес Вашего почтового ящика
Publisher-Email и адрес сайта Publisher-URL
Пример:
<meta name =»revisit-after» Content=»15 days»>
Если некая страница на Вашем сайте подразумевает постоянное обновление и/или дополнение информационным содержанием, то хорошо было бы включить данное описание в заголовок данной страницы. Такое введение позволит программе роботу своевременно посещать Ваш сайт и индексировать его содержание. В нашем примере мы заявили о том, что собираемся обновлять содержание на странице не менее одного раза в 15 дней, можете не сомневаться программа робот возьмет Ваши планы себе на заметку и будет приходить «к Вам в гости» раз в пятнадцать дней, для того чтобы проверить ничего ли у Вас не изменилось..
Пример:
<meta http-equiv=»expires» content=»Sun, 24 jan 2010 12:28:36 GMT+03:00″>
Для того чтобы ускорить загрузку страницы, а так же сэкономить трафик современные браузеры сохраняют посещаемые пользователем страницы в кэш (на жёсткий диск), и при повторном посещении загружают их не с сервера, а непосредственно с кэша. На самом деле такая функция хороша собой.. но есть одно «но», дело в том что в браузере может отображаться уже устаревшая информация, какой либо страницы. Представьте, к примеру, Ваш сайт представляет собой некое периодическое новостное интернет издание, а пользователь получит, вместо самых свежих новостей, уже устаревшую информацию, ту которая хранится у него в кэше!! и не разобравшись в чем «беда» примет Ваш сайт за «мертвый» заброшенный и никем не обновляемый.
Для того чтобы принудительно заставить браузер загружать ту или иную страницу не с жёсткого диска, а с сервера необходим мета тег с данным синтаксисом, где указывается день недели, число месяц год время (чч:мм:сс) и часовой пояс(
GMT+03:00 — время Московское + три часа). День недели и время дня можно не указывать. Теперь при чтении страницы браузером страница будет грузится с сервера, если указанная дата и время настало или просрочено, и напротив из кэша если указанное время еще не наступило.
Ниже на всякий случай приведены таблицы сокращений от Английских слов на месяцы и дни недели
Месяцы:
От Английского:
Сокращения:
Январь
January
Jan
Февраль
February
Feb
Март
March
Mar
Апрель
April
Apr
Май
May
May
Июнь
June
Jun
Июль
July
Jul
Август
August
Aug
Сентябрь
September
Sep
Октябрь
October
Oct
Ноябрь
November
Nov
Декабрь
December
Dec
Дни недели:
От Английского:
Сокращения:
Понедельник
Monday
Mon
Вторник
Tuesday
Tue
Среда
Wednesday
Wed
Четверг
Thursday
Thu
Пятница
Friday
Fri
Суббота
Saturday
Sat
Воскресенье
Sunday
Sun
Атрибуту content можно присвоить значение
«0» <meta http-equiv=»Expires» content=»0″> в этом случае страница всегда будет загружаться с сервера.
И еще.. некоторые поисковые роботы могут отказаться индексировать документ с заведомо устаревшей датой. — не искушайте судьбу..
Пример:
<meta http-equiv=»pragma» content=»no-cache»>
А такая запись вовсе запретит браузеру кэшировать данную страницу.
Пример:
<meta name=»robots» content=»Index,follow»>
Данный мета тег предназначен для подачи поисковому роботу той или иной команды.
Список возможных команд роботу:
Index — индексировать страницу
Noindex — не индексировать страницу
Follow — прослеживать гиперссылки на странице
Nofollow — не прослеживать гиперссылки на странице
All — индексировать страницу и прослеживать гиперссылки на странице (по умолчанию)
None — не индексировать страницу и не прослеживать гиперссылки на странице
Если вдруг по каким либо причинам Вы задумаете поменять URL адрес Вашего сайта то хорошо было бы на старом месте оставить страницу вроде этой:
<html> <head> <meta http-equiv=»Content-Type» Content=»text/html; Charset=Windows-1251″> <meta http-equiv=»Refresh» content=»10; URL=http://www.mysite/index.html»> <title>Переадресация</title> </head> <body> <font size=»+1″> Адрес сайта был изменен, через 10 секунд Ваш браузер будет автоматически перенаправлен по новому адресу:<br> <a href=»http://www.mysite.ru/index.html»><b>http://www.mysite.ru/</b></a><br> Нажмите <a href=»http://www.mysite.ru/index.html»>здесь</a> для того чтобы выполнить переход немедленно.<br> Приносим извинения за доставленные неудобства. </font> </body> </html>
meta http-equiv=»Refresh» — Refresh (восстановление) указывает браузеру что данную страницу необходимо обновить content=»10; — обновить через заданное количество секунд (в нашем случае десять) URL=http://www.mysite/index.html»— адрес новой/другой страницы на которую следует перейти.
Пример:
<meta http-equiv=»Refresh» content=»30″>
А вот если в заголовке Refresh URL адрес упустить, как показано в примере, то тогда браузер будет постоянно через каждые 30 секунд (ну или не 30.. сколько пропишите через столько и будет..) обновлять содержимое данной страницы.
Такой метод широко используется в новостных лентах, где информация идет так сказать потоком и требует постоянного обновления.
Данные заголовки создают визуальные эффекты при переходе с одной страницы на другую.
Page-Enter — Эффект появления страницы
Page- Exit — Эффект исчезновения страницы
В которых:
Duration — время действия эффекта в секундах
Transition — Один из номеров предлагаемых эффектов (от 0 до 23) перечисленных в таблице:
Номер
Описание эффекта
Номер
Описание эффекта
0
Прямоугольники внутрь
12
Растворение
1
Прямоугольники наружу
13
Вертикальная панорама внутрь
2
Круг внутрь
14
Вертикальная панорама наружу
3
Круг наружу
15
Горизонтальная панорама внутрь
4
Наплыв наверх
16
Горизонтальная панорама наружу
5
Наплыв вниз
17
Уголки влево — вниз
6
Наплыв вправо
18
Уголки влево — вверх
7
Наплыв влево
19
Уголки вправо – вниз
8
Вертикальные жалюзи
20
Уголки вправо – вверх
9
Горизонтальные жалюзи
21
Случайные горизонтальные полосы
10
Шажки горизонтальные
22
Случайные вертикальные полосы
11
Шажки вертикальные
23
Случайный выбор эффекта
Пример:
Файл page1. html
<html> <head> <meta http-equiv=»Content-Type» Content=»text/html; Charset=Windows-1251″> <meta http-equiv =»Page-Enter» Content=»RevealTrans(Duration=1.0, Transition=12)»> <title>Эффекты перехода страниц</title> </head> <body bgcolor=»#c5ffa0″> <center> <h3>На заметку:</h3> <font size=»+1″>Эффекты перехода с одной страницы на другую работают не во всех браузерах.</font><hr><br> <font size=»+1″>Нажмите на «Перейти» чтобы перейти к следующей странице<br> и оценить эффект перехода от одной странице к другой.</font><br><br> <a href=»page2.html»><font size=»+2″>»Перейти»</font></a> </center> </body> </html>
Файл page2. html
<html> <head> <meta http-equiv=»Content-Type» Content=»text/html; Charset=Windows-1251″> <meta http-equiv =»Page-Enter» Content=»RevealTrans(Duration=2.0, Transition=23)»> <title>Эффекты перехода страниц</title> </head> <body bgcolor=»#c0e4ff»> <center> <h3>На заметку:</h3> <font size=»+1″>Эффекты открытия и закрытия веб-страниц будут видны только при переходе <br> от одной страницы к другой или же при помощи кнопок «назад» «вперёд». <br> При первом открыти страницы, а также во время перезагрузки<br> эффекты перехода видны не будут.</font><hr><br> <font size=»+1″>Нажмите на «Перейти» чтобы перейти к следующей странице<br> и оценить эффект перехода от одной странице к другой. </font><br><br> <a href=»page1.html»><font size=»+2″>»Перейти»</font></a> </center> </body> </html>
смотреть пример
Ещё раз напомню о том что мета теги стоит применять умело и грамотно особенно это касается команд для робота и кодировки символов, иначе весь Ваш труд может пойти насмарку..
Заголовок Refresh (автоматический переход на другую страницу) можно использовать не совсем стандартно.. Некоторые авторы используют его для создания своего рода «презентации» слайд шоу, где сменяющиеся страницы и есть кадры презентации. Представьте заходит человек на такой сайт а тут ему «Откинетесь на спинку кресла и расслабьтесь..»:) а далее сами по себе пошли картинки, графики, тексты.. а последняя страница тупиковая где пользователь берёт сайт «в свои руки» или же может замыкаться на первую. Только всегда помните о золотом правиле веб-мастера: Главное не переборщить!
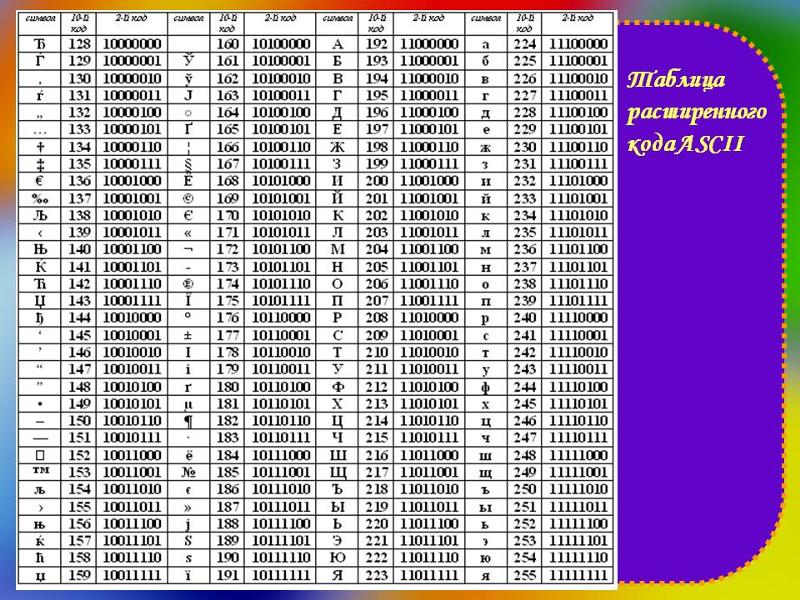
Кодировка в html
Кодировка документа HTML задается в
текстовом редакторе. Например,
Блокнот в ОС Windows по умолчанию сохраняет
текстовые файлы в кодировке Windows-1251.
Для того чтобы браузер правильно
отобразил HTML-страницу, необходимо
задать правильную кодировку в специальном
теге <meta>.
Если кодировка не будет указана, браузер
попытается «угадать» ее, но не
всегда это заканчивается успехом.
Пользователь может выбрать кодировку
самостоятельно в меню браузера (в
Internet Explorer и Mozilla Firefox: Вид → Кодировка).
При разработке сайта проблем с кодировкой
следует избегать, т.к. большинство
пользователей сразу же покинет страницу,
увидев нечитаемый набор букв на экране.
Специальные символы в html
В HTML предусмотрен механизм вставки в
документ любых символов Юникод –
подстановки или сущности (англ. entities).
Подстановки позволяют
CSS (Cascading Style Sheets – каскадные
таблицы стилей, произносится «си-эс-эс»)
– технология управления внешним видом
элементов (тегов) веб-страницы. CSS
предоставляет гораздо больше возможностей
по оформлению страницы, чем HTML. Например,
с помощью стилей CSS можно убрать у ссылок
подчеркивание, сделать у таблицы
пунктирные границы или даже поменять
курсор «мыши». Сейчас CSS используется
практически на всех сайтах Всемирной
паутины.
Синтаксис CSS
Рассмотрим синтаксис CSS. В
стилях задается набор правил отображения
в парах «свойство – значение», и то, к
каким элементам их применять (селектор):
Селектор
{
свойство1: значение1;
свойство2: значение2;
свойство3: значение3 значение4;
}
Правила записываются внутри
фигурных скобок и отделяются друг от
друга точкой с запятой. Между свойствами
и их значениями ставится двоеточие.
CSS, как и HTML, игнорирует
пробелы. Можно добавлять комментарии,
заключая их между /* и */.
Селекторы
Селектор определяет, к каким элементам
(тегам) страницы будут применяться
правила, заданные парами «свойство –
значение».
В качестве селектора можно
использовать:
Название
тега – тогда стиль
применится ко всем таким тегам.
Пример:
A {font-size: 12pt; text-decoration: none}
TABLE {border: black solid 1px}
Первая строчка этого CSS-кода
задает всем ссылкам 12-й размер шрифта
и убирает подчеркивание. На второй
строчке указывается, что у всех таблиц
граница будет черного цвета, сплошной
(solid) и шириной 1 пиксель.
Несколько
тегов через запятую – тогда стиль применится для всех
перечисленных тегов.
Правило относится ко всем тегам A,
вложенным в тег TABLE. Размер шрифта
увеличится на 20% от базового.
ID элемента. В стилях уникальный идентификатор
указывается после знака # – правила
применятся к тегу с атрибутом
id=»идентификатор».
Пример:
CSS
#supersize {font-size: 200%}
HTML
<a
href=»http://htmlbook.ru»>Справочник
HTML и CSS</a>
Нельзя вносить в документ несколько
элементов с одинаковым id!
Символ
* – правила применятся
ко всем элементам документа.
Классы
Классы
Часто нужно, чтобы стиль
применялся не ко всем тегам на странице,
а только к некоторым элементам (например,
не ко всем ссылкам на странице, а только
к тем, которые расположены в меню сайта).
Для этого используются классы: ТЕГ.имя_класса { … }
Правила, указанные после
такого селектора, будут действовать
только на теги с атрибутом: <ТЕГ>
… </ТЕГ>
Можно не указывать имя тега,
тогда правила будут применятся ко всем
тегам с подходящим значением атрибута
class.
Рассмотрим пример:
Для всех тегов с атрибутом
добавим подчеркивание текста
и уменьшим размер шрифта, а для тега <B>
уберем подчеркивание.
apache — Браузер отображает страницу в UTF-8 вместо windows-1251
Задавать вопрос
спросил
Изменено
9 лет, 2 месяца назад
Просмотрено
5к раз
У меня есть сайт, он содержит только html и много кириллицы. Браузер устанавливает кодировку UTF-8 вместо windows-1251, как и должно быть. Итак, английские буквы отображаются нормально, но все символы кириллицы похожи на ����
Вот моя установка: RHEL 6.3 (2.6.32-279.el6.x86_64) Apache/2.2.15 (Unix)
Пример страницы на pastebin или phpfiddle для тех, у кого нет доступа к pastebin
Итак, charset везде установлен, и если я вручную меняю кодировку в браузере на windows-1251 — отображается нормально, но автоопределение ставит utf-8, и я не знаю, почему. Если поможет — сайт раньше размещался на Sun OS 5.10.
Спасибо за любую помощь.
apache
кодировка
кодировка символов
cp1251
11
I закомментировал следующую строку в httpd. conf , перезапустил httpd и теперь все отображается правильно:
AddDefaultCharset utf-8
3
Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью Google Зарегистрироваться через Facebook Зарегистрируйтесь, используя электронную почту и пароль
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Опубликовать как гость
Электронная почта
Требуется, но не отображается
Нажимая «Опубликовать свой ответ», вы соглашаетесь с нашими условиями обслуживания и подтверждаете, что прочитали и поняли нашу политику конфиденциальности и кодекс поведения.
Ограничения тега для указания кодировки символов — Seeblog
На Reddit возник вопрос: почему моя веб-страница интерпретируется с неправильной кодировкой символов? Вопрос (который с тех пор был удален, иначе я бы дал ссылку на него) включал некоторые особенности того, как страница обслуживалась, и, перефразируя, ответ заключался в том, что страницы, сгенерированные PHP, обслуживались с HTTP Content-Type. , который включал информацию о кодировке, а статические HTML-страницы — нет.





 Такое введение позволит программе роботу своевременно посещать Ваш сайт и индексировать его содержание. В нашем примере мы заявили о том, что собираемся обновлять содержание на странице не менее одного раза в 15 дней, можете не сомневаться программа робот возьмет Ваши планы себе на заметку и будет приходить «к Вам в гости» раз в пятнадцать дней, для того чтобы проверить ничего ли у Вас не изменилось..
Такое введение позволит программе роботу своевременно посещать Ваш сайт и индексировать его содержание. В нашем примере мы заявили о том, что собираемся обновлять содержание на странице не менее одного раза в 15 дней, можете не сомневаться программа робот возьмет Ваши планы себе на заметку и будет приходить «к Вам в гости» раз в пятнадцать дней, для того чтобы проверить ничего ли у Вас не изменилось..

 mysite/index.html»>
mysite/index.html»>

 html
html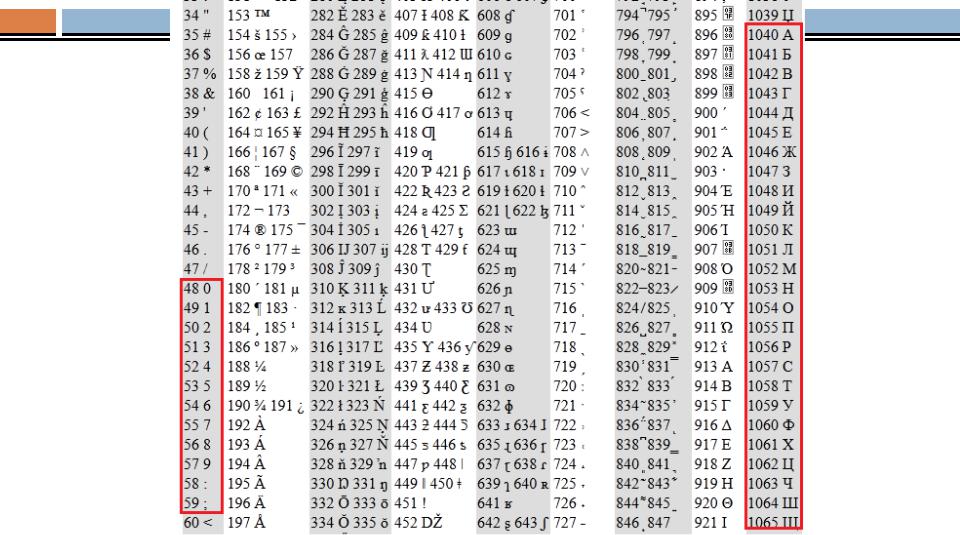 html
html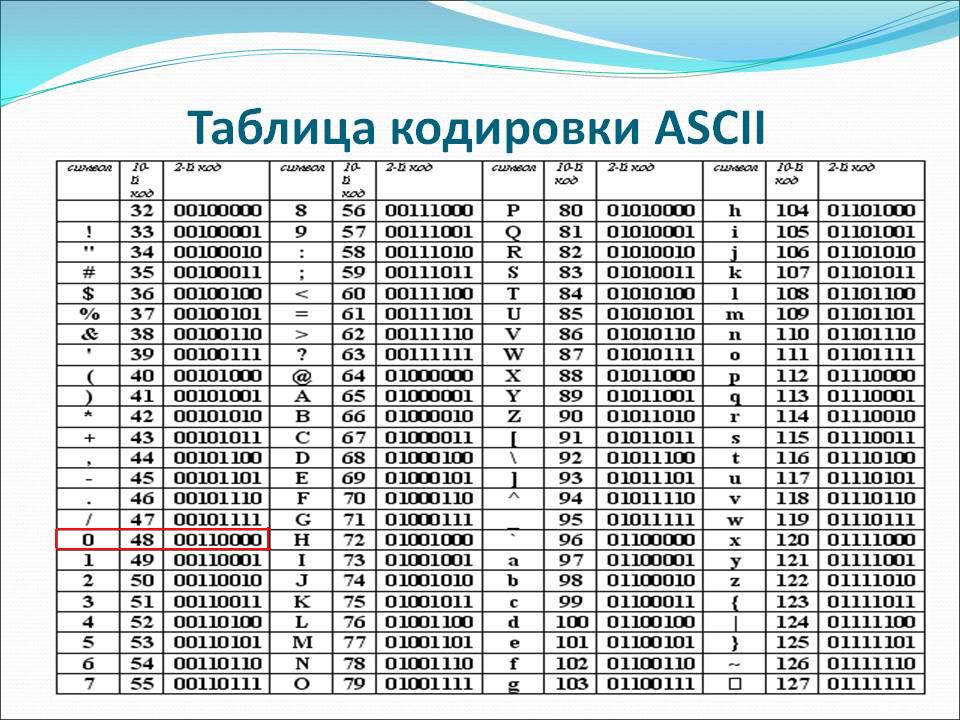 </font><br><br>
</font><br><br>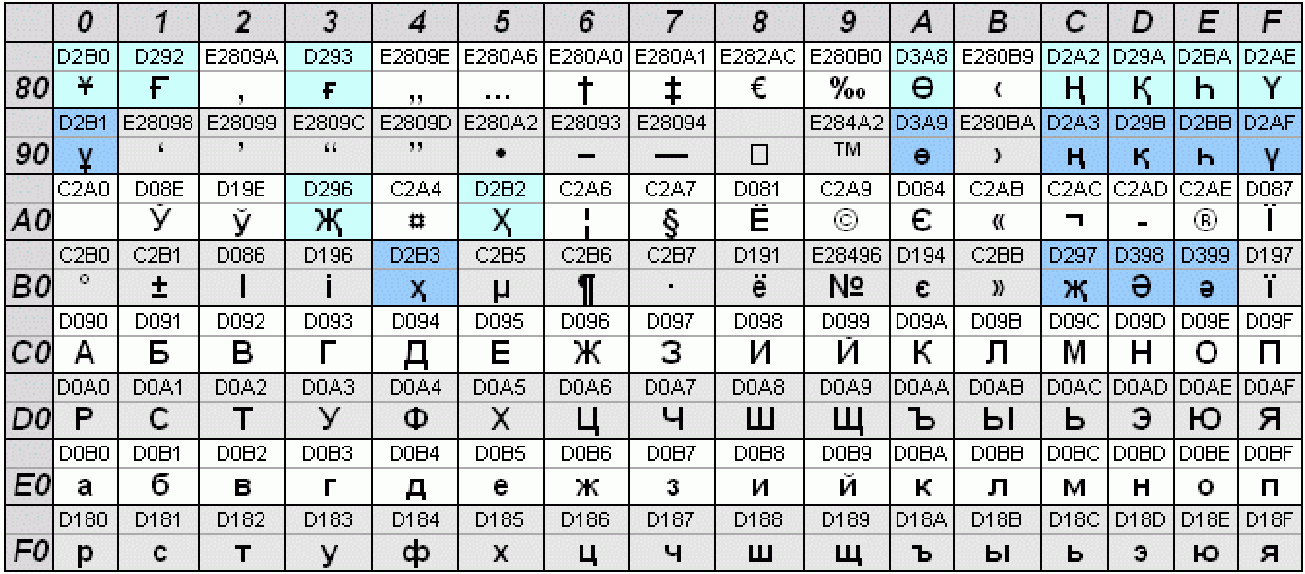 Например,
Например,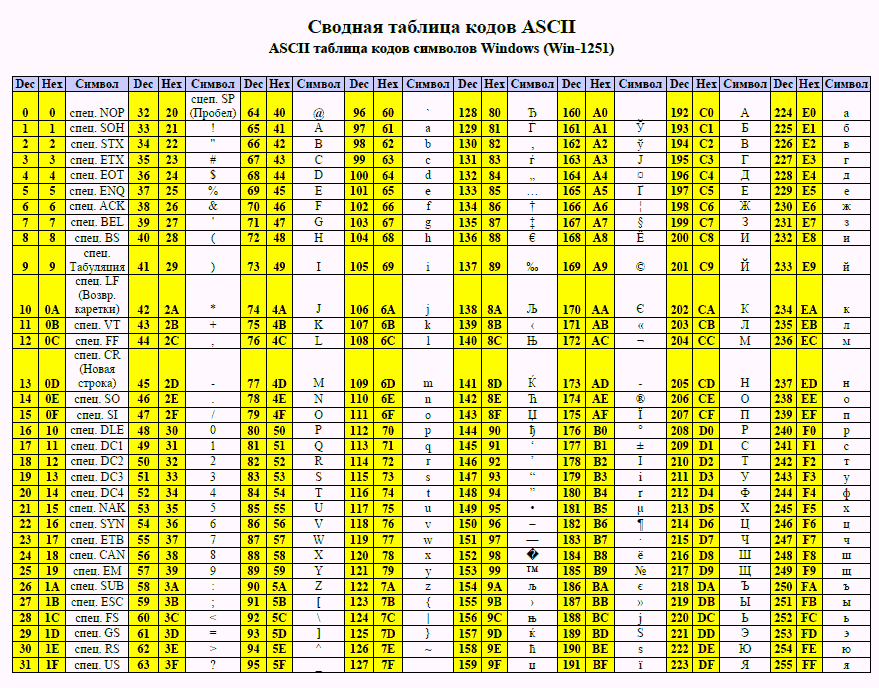 entities).
Подстановки позволяют
entities).
Подстановки позволяют Сейчас CSS используется
практически на всех сайтах Всемирной
паутины.
Сейчас CSS используется
практически на всех сайтах Всемирной
паутины.
 В стилях уникальный идентификатор
указывается после знака # – правила
применятся к тегу с атрибутом
id=»идентификатор».
Пример:
В стилях уникальный идентификатор
указывается после знака # – правила
применятся к тегу с атрибутом
id=»идентификатор».
Пример:
 Браузер устанавливает кодировку UTF-8 вместо windows-1251, как и должно быть. Итак, английские буквы отображаются нормально, но все символы кириллицы похожи на ����
Браузер устанавливает кодировку UTF-8 вместо windows-1251, как и должно быть. Итак, английские буквы отображаются нормально, но все символы кириллицы похожи на ���� conf
conf