Команда HAVING — условие для GROUP BY
Команда HAVING позволяет фильтровать результат группировки, сделанной с помощью команды GROUP BY.
См. также команду WHERE, которая задает условие на выборку записей.
Синтаксис
GROUP BY поле HAVING условиеПримеры
Все примеры будут по этой таблице workers, если не сказано иное:
| id айди | name имя | age возраст | salary зарплата |
|---|---|---|---|
| 1 | Дима | 23 | 100 |
| 2 | Петя | 23 | 200 |
| 3 | Вася | 23 | 300 |
| 4 | Коля | 24 | 1000 |
| 5 | Иван | 24 | 2000 |
| 6 | Кирилл | 25 | 1000 |
Пример
В данном примере демонстрируется работа GROUP BY без условия
SELECT age, SUM(salary) as sum FROM workers GROUP BY ageSQL запрос выберет следующие строки:
| age возраст | sum сумма |
|---|---|
| 23 | 600 |
| 24 | 3000 |
| 25 | 1000 |
А теперь с помощью условия HAVING оставим только те строки, в которых суммарная зарплата больше или равна 1000:
SELECT age, SUM(salary) as sum FROM workers GROUP BY age HAVING sum>=1000SQL запрос выберет следующие строки:
| age возраст | sum сумма |
|---|---|
| 24 | 3000 |
| 25 | 1000 |
Пример
Подсчитаем с помощью функции COUNT количество записей в группе (не используя HAVING):
SELECT age, COUNT(*) as count FROM workers GROUP BY age| age возраст | count количество |
|---|---|
| 23 | 3 |
| 24 | 2 |
| 25 | 1 |
А теперь с помощью условия HAVING оставим только те группы, в которых количество строк меньше или равно двум:
SELECT age, COUNT(*) as count FROM workers GROUP BY age HAVING countSQL запрос выберет следующие строки:
| age возраст | count количество |
|---|---|
| 24 | 2 |
| 25 | 1 |
Аналогичного эффекта можно достигнуть, если воспользоваться командой IN:
SELECT age, COUNT(*) as count FROM workers GROUP BY age HAVING count IN(1,2)Можно также использовать команду BETWEEN:
SELECT age, COUNT(*) as count FROM workers GROUP BY age HAVING count BETWEEN 1 AND 2
Как вы видите, в HAVING допустимы все команды,
используемые в условии WHERE.
Функция GROUP_CONCAT — сложение разных строк таблицы
Функция GROUP_CONCAT складывает (как строки) содержимое одного поля из разных строк, вставляя между ними разделитель (по умолчанию это запятая).
К примеру, можно получить список всех выбранных имен через запятую или другой разделитель.
Внимание: у этой функции есть ограничение на объем выводимых данных. По умолчанию 1024 символа для каждого объединения — для каждой выводимой строки. Если размер склеенных данных больше, то он будет урезаться.
Чтобы расширить размер нужно выполнить команду SET group_concat_max_len = 4096;
Если у вас есть привилегии, то вы расширите объем получаемых данных до 4096, можно и больше. Но чаще всего на обычных хостингах таких привилегий нет.
См. также команду GROUP BY, с помощью которой можно группировать строки для использования GROUP_CONCAT.
См. также функции
CONCAT и
CONCAT_WS
которые складывают колонки одной строки.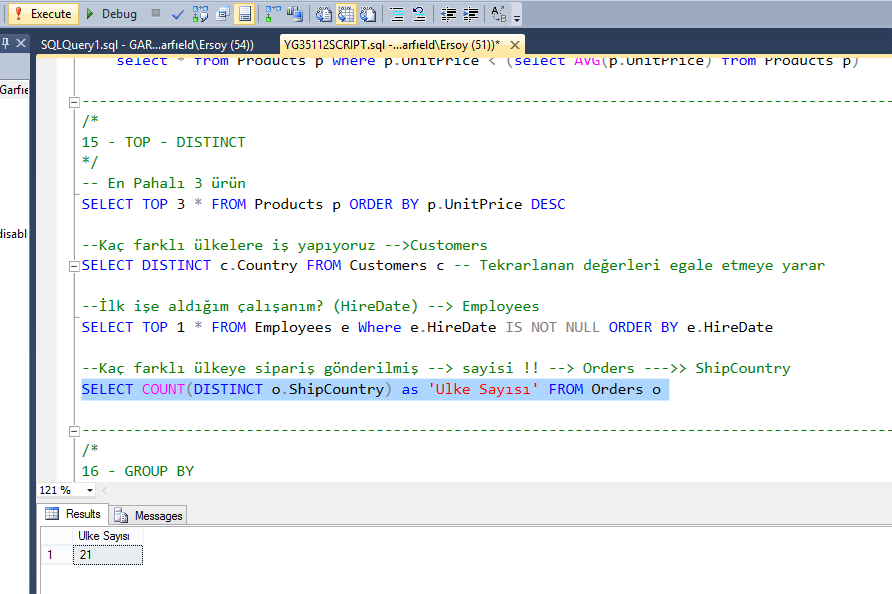
Синтаксис
Без указания разделителя (по умолчанию это будет запятая):
SELECT GROUP_CONCAT(поле) FROM имя_таблицы WHERE условиеС указанием разделителя:
SELECT GROUP_CONCAT(поле SEPARATOR разделитель) FROM имя_таблицы WHERE условиеПримеры
Все примеры будут по этой таблице workers, если не сказано иное:
| id айди | name имя | age возраст |
|---|---|---|
| 1 | Дима | 23 |
| 2 | Петя | 23 |
| 3 | Вася | 23 |
| 4 | Коля | 24 |
| 5 | Иван | 24 |
| 6 | Кирилл | 25 |
Пример
В данном примере запрос находит все имена в таблицы и выводит их через запятую:
SELECT GROUP_CONCAT(name) as name FROM workersSQL запрос выберет следующие строки:
| name имена |
|---|
| Дима,Петя,Вася,Коля,Иван,Кирилл |
Пример
В данном примере разделитель меняется на ‘+’ с помощью команды SEPARATOR:
SELECT GROUP_CONCAT(name SEPARATOR '+') as name FROM workersSQL запрос выберет следующие строки:
| name имена |
|---|
| Дима+Петя+Вася+Коля+Иван+Кирилл |
Пример
В данном примере с помощью команды WHERE выбираются не все строки, а заданные:
SELECT GROUP_CONCAT(name) as name FROM workers WHERE id>=3 AND id SQL запрос выберет следующие строки:
| name имена |
|---|
| Вася,Коля,Иван |
Пример
В данном примере с помощью команды GROUP BY строки группируются по возрасту и для каждой группы через запятую выводятся имена работников с таким возрастом:
SELECT age, GROUP_CONCAT(name) as name FROM workers GROUP BY ageSQL запрос выберет следующие строки:
| age возраст | name имена |
|---|---|
| 23 | Дима,Петя,Вася |
| 24 | Коля,Иван |
| 25 | Кирилл |
Пример
Поменяем разделитель на ‘-‘:
SELECT age, GROUP_CONCAT(name SEPARATOR '-') as name FROM workers GROUP BY ageSQL запрос выберет следующие строки:
| age возраст | name имена |
|---|---|
| 23 | Дима-Петя-Вася |
| 24 | Коля-Иван |
| 25 | Кирилл |
GROUP BY оператор — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
Этот SQL руководство объясняет, как использовать SQL GROUP BY с синтаксисом и примерами.
Описание
SQL оператор GROUP BY можно использовать в SELECT для сбора данных по нескольким записям и группировки результатов одного или нескольких столбцов.
Синтаксис
SELECT expression1, expression2, … expression_n,
aggregate_function (aggregate_expression)
FROM tables
[WHERE conditions]
GROUP BY expression1, expression2, … expression_n;
Параметры или аргументы
expression1, expression2, … expression_n — выражения, которые не входят в aggregate_function и должны быть включены в предложение GROUP BY в конце оператора SQL.
aggregate_function — это функция, такая как SUM, COUNT, функции MIN, MAX или AVG.
aggregate_expression – это столбец или выражение, которое используется в aggregate_function.
tables – таблицы из которых вы хотите выгрузить данные. После оператора FROM должна быть указана хотя бы одна таблица.
WHERE conditions. Необязательный. Условия, которые должны быть выполнены для записей, которые будут выбраны.
Пример – использования функции SUM
Давайте посмотрим на примере SQL запроса GROUP BY, который использует SQL функцию SUM.
В этом примере GROUP BY использует функцию SUM, чтобы получить total sales (общий объем продаж) по department (наименование отдела) таблицы order_details.
SELECT department, SUM(sales) AS «Total sales» FROM order_details GROUP BY department;
SELECT department, SUM(sales) AS «Total sales» FROM order_details GROUP BY department; |
В SQL SELECT предложении мы перечислили один столбец department, не входящий в функции SUM. Поле department должно быть указано в операторе GROUP BY.
Пример – использование функции COUNT
Давайте посмотрим, как можно использовать предложение GROUP BY с SQL функцией COUNT.
В этом примере GROUP BY использует функцию COUNT для возврата department (наименование отдела) и number of employees (количество сотрудников в отделе), которые делают более $ 5000 / год.
SELECT department, COUNT(*) AS «Number of employees» FROM employees WHERE salary > 25000 GROUP BY department;
SELECT department, COUNT(*) AS «Number of employees» FROM employees WHERE salary > 25000 GROUP BY department; |
Пример – использование функции MIN
Давайте рассмотрим следующий пример, как мы могли бы использовать GROUP BY с SQL функцией MIN.
Этот пример GROUP BY использует функцию MIN, для возврата department (наименование отдела) и минимальную salary (зарплату) в department.
SELECT department, MIN(salary) AS «Lowest salary» FROM employees GROUP BY department;
SELECT department, MIN(salary) AS «Lowest salary» FROM employees GROUP BY department; |
Пример — использование функции MAX
И, наконец, давайте посмотрим на то, как мы могли бы использовать GROUP BY с SQL функцией MAX.
В этом примере GROUP BY использует функцию MAX, чтобы вернуть department (наименование отдела) и максимальную salary (зарплату) в department.
SELECT department, MAX(salary) AS «Highest salary» FROM employees GROUP BY department;
SELECT department, MAX(salary) AS «Highest salary» FROM employees GROUP BY department; |
GROUP BY оператор MySQL — Oracle PL/SQL •MySQL •MariaDB •SQL Server •SQLite
В этом учебном пособии вы узнаете, как использовать MySQL оператор GROUP BY с синтаксисом и примерами.
Описание
MySQL оператор GROUP BY используется в SELECT предложении для сбора данных по нескольким записям и группировки результатов по одному или нескольким столбцам.
Синтаксис
Синтаксис оператора GROUP BY в MySQL:
SELECT expression1, expression2, … expression_n,
aggregate_function (expression)
FROM tables
[WHERE conditions]
GROUP BY expression1, expression2, … expression_n;
Параметры или аргументы
expression1, expression2, … expression_n — выражения, которые не заключены в агрегированную функцию и должны быть включены в предложение GROUP BY.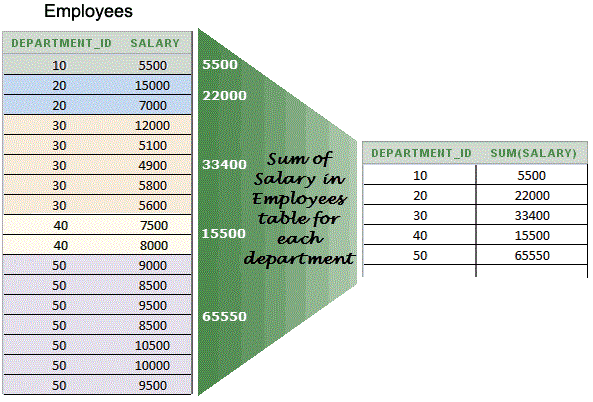
aggregate_function — функция, такая как функции SUM, COUNT, MIN, MAX или AVG.
tables — таблицы, из которых вы хотите получить записи. Должна быть хотя бы одна таблица, перечисленная в операторе FROM.
WHERE conditions — необязательный. Условия, которые должны быть выполнены для выбранных записей.
Пример использования функции SUM
Рассмотрим пример запроса MySQL GROUP BY, который использует функцию SUM.
В этом примере MySQL GROUP BY используется функция SUM, чтобы вернуть имя product и общее количество (для product).
SELECT product, SUM(quantity) AS «Total kol» FROM order_details GROUP BY product;
SELECT product, SUM(quantity) AS «Total kol» FROM order_details GROUP BY product; |
Запрос в примере вернет общее количество по полю quantity под алиасом «Total kol».
Поскольку вы указали один столбец (поле product) в операторе SELECT, который не инкапсулирован в функцию SUM, то вы должны использовать оператор GROUP BY. Поэтому поле product должно быть указано в операторе GROUP BY.
Поэтому поле product должно быть указано в операторе GROUP BY.
Пример использования функции COUNT
Рассмотрим, как мы можем использовать оператор GROUP BY с функцией COUNT в MySQL.
В этом примере GROUP BY используется функция COUNT для возврата product и количества заказов (для этого product), которые находятся в категории product.
SELECT product, COUNT(*) AS «Number of orders» FROM order_details WHERE category = ‘produce’ GROUP BY product;
SELECT product, COUNT(*) AS «Number of orders» FROM order_details WHERE category = ‘produce’ GROUP BY product; |
Пример использования функции MIN
Рассмотрим, как мы можем использовать оператор GROUP BY с функцией MIN в MySQL.
В этом примере GROUP BY используется функция MIN, чтобы вернуть department (имя каждого отдела) и lowest salary (минимальную зарплату в отделе).
SELECT department, MIN(salary) AS «Lowest salary» FROM employees GROUP BY department;
SELECT department, MIN(salary) AS «Lowest salary» FROM employees GROUP BY department; |
Пример использования функции MAX
Наконец, посмотрим, как мы можем использовать оператор GROUP BY с функцией MAX в MySQL.
В этом примере GROUP BY используется функция MAX для возврата имени каждого department и максимальной заработной платы в department.
SELECT department, MAX(salary) AS «Highest salary» FROM employees GROUP BY department;
SELECT department, MAX(salary) AS «Highest salary» FROM employees GROUP BY department; |
Предложение GROUP BY (Microsoft Access SQL)
- Чтение занимает 2 мин
В этой статье
Область применения: Access 2013 | Access 2016Applies to: Access 2013 | Access 2016
Объединяет записи с одинаковыми значениями из указанного списка полей в одну запись. Combines records with identical values in the specified field list into a single record. Сводное значение создается для каждой записи, если вы включили статистическую функцию SQL, например Sum или Count, в операторе SELECT .A summary value is created for each record if you include an SQL aggregate function, such as Sum or Count, in the SELECT statement.
Combines records with identical values in the specified field list into a single record. Сводное значение создается для каждой записи, если вы включили статистическую функцию SQL, например Sum или Count, в операторе SELECT .A summary value is created for each record if you include an SQL aggregate function, such as Sum or Count, in the SELECT statement.
СинтаксисSyntax
Выберите фиелдлист из таблицы , где критерии [группировать по граупфиелдлист ]SELECT fieldlist FROM table WHERE criteria [GROUP BY groupfieldlist ]
Инструкция SELECT, содержащая предложение GROUP BY, состоит из следующих частей:A SELECT statement containing a GROUP BY clause has these parts:
| ЧастьPart | ОписаниеDescription |
|---|---|
| fieldlistfieldlist | Имя поля или полей, которые необходимо получить вместе с псевдонимами полей, статистическими функциями SQL, предикатами выбора (ALL, DISTINCT, DISTINCTROW или Top) или другими параметрами инструкции SELECT. The name of the field or fields to be retrieved along with any field-name aliases, SQL aggregate functions, selection predicates (ALL, DISTINCT, DISTINCTROW, or TOP), or other SELECT statement options. The name of the field or fields to be retrieved along with any field-name aliases, SQL aggregate functions, selection predicates (ALL, DISTINCT, DISTINCTROW, or TOP), or other SELECT statement options. |
| таблицаtable | Имя таблицы, из которой извлекаются записи.The name of the table from which records are retrieved. Более подробную информацию можно узнать в предложении from .For more information, see the FROM clause. |
| criteriacriteria | Критерии выбора.Selection criteria. Если оператор содержит предложение WHERE , то значения групп ядра СУБД Microsoft Access после применения условий WHERE к записям.If the statement includes a WHERE clause, the Microsoft Access database engine groups values after applying the WHERE conditions to the records. |
| граупфиелдлистgroupfieldlist | Имена, имеющие до 10 полей, используемых для группировки записей.The names of up to 10 fields used to group records. Порядок имен полей в граупфиелдлист определяет уровни группировки от самого высокого до самого низкого уровня группировки.The order of the field names in groupfieldlist determines the grouping levels from the highest to the lowest level of grouping. Порядок имен полей в граупфиелдлист определяет уровни группировки от самого высокого до самого низкого уровня группировки.The order of the field names in groupfieldlist determines the grouping levels from the highest to the lowest level of grouping. |
ПримечанияRemarks
GROUP BY является необязательным.GROUP BY is optional.
Итоговые значения опущены, если в операторе SELECT нет статистической функции SQL.Summary values are omitted if there is no SQL aggregate function in the SELECT statement.
Значения null в ПОЛЯХ Group By группируются и не пропускаются.Null values in GROUP BY fields are grouped and are not omitted. Однако значения null не оцениваются в статистических функциях SQL.However, Null values are not evaluated in any SQL aggregate function.
Используйте предложение WHERE, чтобы исключить строки, которые не должны быть сгруппированы, и используйте предложение HAVING для фильтрации записей после их группирования. Use the WHERE clause to exclude rows you do not want grouped, and use the HAVING clause to filter records after they have been grouped.
Use the WHERE clause to exclude rows you do not want grouped, and use the HAVING clause to filter records after they have been grouped.
Если он не содержит данные MEMO или объекта OLE, поле в списке полей GROUP BY может ссылаться на любое поле в любой таблице, указанной в предложении FROM, даже если поле не включено в инструкцию SELECT, при условии, что инструкция SELECT включает по крайней мере одну статистическую функцию SQL.Unless it contains Memo or OLE Object data, a field in the GROUP BY field list can refer to any field in any table listed in the FROM clause, even if the field is not included in the SELECT statement, provided the SELECT statement includes at least one SQL aggregate function. Ядро базы данных Microsoft® Jet не может группировать по полям MEMO или объектов OLE.The Microsoft® Jet database engine cannot group on Memo or OLE Object fields.
Все поля в списке Выбор поля должны быть включены в предложение GROUP BY или включаться в качестве аргументов статистической функции SQL. All fields in the SELECT field list must either be included in the GROUP BY clause or be included as arguments to an SQL aggregate function.
All fields in the SELECT field list must either be included in the GROUP BY clause or be included as arguments to an SQL aggregate function.
ПримерExample
В этом примере создается список уникальных названий заданий и число сотрудников с каждым названием.This example creates a list of unique job titles and the number of employees with each title. В этом примере выполняется вызов процедуры EnumFields, которую можно найти в примере для оператора SELECT.It calls the EnumFields procedure, which you can find in the SELECT statement example.
Sub GroupByX1()
Dim dbs As Database, rst As Recordset
' Modify this line to include the path to Northwind
' on your computer.
Set dbs = OpenDatabase("Northwind.mdb")
' For each title, count the number of employees
' with that title.
Set rst = dbs.OpenRecordset("SELECT Title, " _
& "Count([Title]) AS Tally " _
& "FROM Employees GROUP BY Title;")
' Populate the Recordset. rst.MoveLast
' Call EnumFields to print the contents of the
' Recordset. Pass the Recordset object and desired
' field width.
EnumFields rst, 25
dbs.Close
End Sub
rst.MoveLast
' Call EnumFields to print the contents of the
' Recordset. Pass the Recordset object and desired
' field width.
EnumFields rst, 25
dbs.Close
End Sub
В этом примере для каждого уникального названия задания вычисляется количество сотрудников в Вашингтоне, у которых есть название.For each unique job title, this example calculates the number of employees in Washington who have that title.
Sub GroupByX2()
Dim dbs As Database, rst As Recordset
' Modify this line to include the path to Northwind
' on your computer.
Set dbs = OpenDatabase("Northwind.mdb")
' For each title, count the number of employees
' with that title. Only include employees in the
' Washington region.
Set rst = dbs.OpenRecordset("SELECT Title, " _
& "Count(Title) AS Tally " _
& "FROM Employees WHERE Region = 'WA' " _
& "GROUP BY Title;")
' Populate the Recordset. rst.MoveLast
' Call EnumFields to print the contents of the
' Recordset. Pass the Recordset object and desired
' field width.
EnumFields rst, 25
dbs.Close
End Sub
rst.MoveLast
' Call EnumFields to print the contents of the
' Recordset. Pass the Recordset object and desired
' field width.
EnumFields rst, 25
dbs.Close
End Sub
См. такжеSee also
Поддержка и обратная связьSupport and feedback
Есть вопросы или отзывы, касающиеся Office VBA или этой статьи?Have questions or feedback about Office VBA or this documentation? Руководство по другим способам получения поддержки и отправки отзывов см. в статье Поддержка Office VBA и обратная связь.Please see Office VBA support and feedback for guidance about the ways you can receive support and provide feedback.
Агрегатные функции SQL — SUM, MIN, MAX, AVG, COUNT
Будем учиться подводить итоги. Нет, это ещё не итоги изучения SQL, а итоги значений столбцов таблиц
базы данных. Агрегатные функции SQL действуют в отношении значений столбца с целью получения
единого результирующего значения. Наиболее часто применяются агрегатные функции SQL SUM, MIN, MAX,
AVG и COUNT. Следует различать
два случая применения агрегатных функций. Первый: агрегатные функции используются сами по себе и возвращают
одно результирующее значение. Второй: агрегатные функции используются с оператором SQL GROUP BY, то есть
с группировкой по полям (столбцам) для получения результирующих значений в каждой группе. Рассмотрим сначала случаи использования агрегатных
функций без группировки.
Наиболее часто применяются агрегатные функции SQL SUM, MIN, MAX,
AVG и COUNT. Следует различать
два случая применения агрегатных функций. Первый: агрегатные функции используются сами по себе и возвращают
одно результирующее значение. Второй: агрегатные функции используются с оператором SQL GROUP BY, то есть
с группировкой по полям (столбцам) для получения результирующих значений в каждой группе. Рассмотрим сначала случаи использования агрегатных
функций без группировки.
Функция SQL SUM возвращает сумму значений столбца таблицы базы данных. Она может применяться только к столбцам, значениями которых являются числа. Запросы SQL для получения результирующей суммы начинаются так:
SELECT SUM(ИМЯ_СТОЛБЦА) …
После этого выражения следует FROM (ИМЯ_ТАБЛИЦЫ), а далее с помощью конструкции WHERE может быть
задано условие. Кроме того, перед именем столбца может быть указано DISTINCT, и это означает, что
учитываться будут только уникальные значения. По умолчанию же учитываются все значения (для этого
можно особо указать не DISTINCT, а ALL, но слово ALL не является обязательным).
По умолчанию же учитываются все значения (для этого
можно особо указать не DISTINCT, а ALL, но слово ALL не является обязательным).
Если вы хотите выполнить запросы к базе данных из этого урока на MS SQL Server, но эта СУБД не установлена на вашем компьютере, то ее можно установить, пользуясь инструкцией по этой ссылке.
Сначала работать будем с базой данных фирмы — Company1. Скрипт для создания этой базы данных, её таблиц и заполения таблиц данными — в файле по этой ссылке.
Пример 1. Есть база данных фирмы с данными о её подразделениях и сотрудниках. Таблица Staff помимо всего имеет столбец с данными о заработной плате сотрудников. Выборка из таблицы имеет следующий вид (для увеличения картинки щёлкнуть по ней левой кнопкой мыши):
Для получения суммы размеров всех заработных плат используем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT SUM(Salary) FROM Staff
Этот запрос вернёт значение 287664,63.
А теперь упражнение для самостоятельного решения. В упражнениях уже начинаем усложнять задания, приближая их к тем, что встречаются на практике.
Функция SQL MIN также действует в отношении столбцов, значениями которых являются числа и возвращает минимальное среди всех значений столбца. Эта функция имеет синтаксис аналогичный синтаксису функции SUM.
Пример 3. База данных и таблица — те же, что и в примере 1.
Требуется узнать минимальную заработную плату сотрудников отдела с номером 42. Для этого пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT MIN(Salary) FROM Staff WHERE Dept=42
Запрос вернёт значение 10505,90.
И вновь упражнение для самостоятельного решения. В этом и некоторых других упражнениях потребуется уже не только таблица Staff, но и таблица Org, содержащая данные о подразделениях фирмы:
Пример 4. К таблице Staff добавляется таблица Org, содержащая данные о подразделениях фирмы. Вывести минимальное количество лет, проработанных одним сотрудником в отделе, расположенном в Бостоне.
Правильное решение и ответ.
Аналогично работает и имеет аналогичный синтаксис функция SQL MAX, которая применяется, когда требуется определить максимальное значение среди всех значений столбца.
Пример 5. База данных и таблица — те же, что и в предыдущих примерах.
Требуется узнать максимальную заработную плату сотрудников отдела с номером 42. Для этого пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT MAX(Salary) FROM Staff WHERE Dept=42
Запрос вернёт значение 18352,80
Пришло время упражнения для самостоятельного решения.
Пример 6. Вновь работаем с двумя таблицами — Staff и Org. Вывести название отдела и максимальное значение комиссионных, получаемых одним сотрудником в отделе, относящемуся к группе отделов (Division) Eastern. Использовать JOIN (соединение таблиц).
Правильное решение и ответ.
Указанное в отношении синтаксиса для предыдущих описанных функций верно и в отношении функции SQL AVG. Эта функция возвращает среднее значение среди всех значений столбца.
Пример 7. База данных и таблица — те же, что и в предыдущих примерах.
Пусть требуется узнать средний трудовой стаж сотрудников отдела с номером 42. Для этого пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT AVG(Years) FROM Staff WHERE Dept=42
Результатом будет значение 6,33
В следующем упражнении для самостоятельного решения помимо агрегатной функции требуется использовать также предикат BETWEEN.
Функция SQL COUNT возвращает количество записей таблицы базы данных. Если в запросе указать SELECT COUNT(ИМЯ_СТОЛБЦА) …, то результатом будет количество записей без учёта тех записей, в которых значением столбца является NULL (неопределённое). Если использовать в качестве аргумента звёздочку и начать запрос SELECT COUNT(*) …, то результатом будет количество всех записей (строк) таблицы.
Пример 9. База данных и таблица — те же, что и в предыдущих примерах.
Требуется узнать число всех сотрудников, которые получают комиссионные. Число сотрудников, у которых значения столбца Comm — не NULL, вернёт следующий запрос (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT COUNT(Comm) FROM Staff
Результатом будет значение 11.
Пример 10. База данных и таблица — те же, что и в предыдущих примерах.
Если требуется узнать общее количество записей в таблице, то применяем запрос со звёздочкой в качестве аргумента функции COUNT (на MS SQL Server — с предваряющей конструкцией USE company1;):
SELECT COUNT(*) FROM Staff
Результатом будет значение 17.
В следующем упражнении для самостоятельного решения потребуется использовать подзапрос.
Теперь рассмотрим применение агрегатных функций вместе с оператором SQL GROUP BY. Оператор SQL GROUP BY служит для группировки результирующих значений по столбцам таблицы базы данных. На сайте есть урок, посвящённый отдельно этому оператору.
Работать будем с базой данных «Портал объявлений 1». Скрипт для создания этой базы данных, её таблицы и заполения таблицы данных — в файле по этой ссылке.
Пример 12. Итак, есть база данных портала объявлений. В ней есть таблица Ads, содержащая данные об объявлениях, поданных за неделю. Столбец Category содержит данные о больших категориях объявлений (например, Недвижимость), а столбец Parts — о более мелких частях, входящих в категории (например, части Квартиры и Дачи являются частями категории Недвижимость). Столбец Units содержит данные о количестве поданных объявлений, а столбец Money — о денежных суммах, вырученных за подачу объявлений.
| Category | Part | Units | Money |
| Транспорт | Автомашины | 110 | 17600 |
| Недвижимость | Квартиры | 89 | 18690 |
| Недвижимость | Дачи | 57 | 11970 |
| Транспорт | Мотоциклы | 131 | 20960 |
| Стройматериалы | Доски | 68 | 7140 |
| Электротехника | Телевизоры | 127 | 8255 |
| Электротехника | Холодильники | 137 | 8905 |
| Стройматериалы | Регипс | 112 | 11760 |
| Досуг | Книги | 96 | 6240 |
| Недвижимость | Дома | 47 | 9870 |
| Досуг | Музыка | 117 | 7605 |
| Досуг | Игры | 41 | 2665 |
Используя оператор SQL GROUP BY, найти суммы денег, вырученных за подачу объявлений в каждой категории. Пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
SELECT Category, SUM(Money) AS Money FROM ADS GROUP BY Category
Результатом будет следующая таблица:
| Category | Money |
| Досуг | 16510 |
| Недвижимость | 40530 |
| Стройматериалы | 18900 |
| Транспорт | 38560 |
| Электротехника | 17160 |
Пример 13. База данных и таблица — та же, что в предыдущем примере.
Используя оператор SQL GROUP BY, выяснить, в какой части каждой категории было подано наибольшее число объявлений. Пишем следующий запрос (на MS SQL Server — с предваряющей конструкцией USE adportal1;):
SELECT Category, Part, MAX(Units) AS Maximum FROM ADS GROUP BY Category
Результатом будет следующая таблица:
| Category | Part | Maximum |
| Досуг | Музыка | 117 |
| Недвижимость | Квартиры | 89 |
| Стройматериалы | Регипс | 112 |
| Транспорт | Мотоциклы | 131 |
| Электротехника | Холодильники | 137 |
Итоговые и индивидуальные значения в одной таблице можно получить объединением результатов запросов с помощью оператора UNION.
Поделиться с друзьями
Реляционные базы данных и язык SQL
Как использовать GROUP BY в SQL Server
Автор Джефф Смит 30 июля 2007 г. | Теги: Запросы , ВЫБРАТЬ
Суммирование данных в операторе SELECT с использованием GROUP Предложение BY — очень распространенная область трудностей для начинающих программистов SQL.В первой части этой серии из двух частей мы будем использовать простую схему и типичный запрос отчета, чтобы охватить влияние JOINS на группировку и агрегированные вычисления, а также способы использования COUNT (Distinct) для преодоления этого. В части II мы завершим наш отчет, исследуя проблему с SUM (Distinct) и обсуждая, насколько полезными могут быть производные таблицы при группировании сложных данных. ( Эта статья была обновлена до SQL Server 2005. )
Вот схема, которую мы будем использовать вместе с некоторыми примерами данных:
создать таблицу заказов
(
Первичный ключ OrderID int,
Клиент varchar (10),
OrderDate datetime,
Стоимость доставки
)
создать таблицу OrderDetails
(
Первичный ключ DetailID int,
OrderID int ссылается на заказы (OrderID),
Элемент varchar (10),
Сумма денег
)
идти
вставить в заказы
выберите 1, 'ABC', '2007-01-01', 40 объединить все
выберите 2, 'ABC', '2007-01-02', 30 объединить все
выберите 3, 'ABC', '2007-01-03', 25 объединить все
выберите 4, 'DEF', '2007-01-02', 10
вставить в OrderDetails
выберите 1, 1, 'Item A', 100 объедините все
выберите 2, 1, 'Item B', 150 объединить все
выберите 3, 2, 'Item C', 125 объединить все
выберите 4, 2, 'Item B', 50 объединить все
выберите 5, 2, 'Item H', 200 объедините все
выберите 6, 3, 'Item X', 100 объедините все
выберите 7, 4, 'Item Y', 50 объединить все
выберите 8, 4, 'Item Z', 300
Определение виртуального первичного ключа набора результатов
Давайте исследуем наши образцы данных, объединив эти таблицы вместе, чтобы получить заказы вместе с OrderDetails:
выбрать о.orderID, o.customer, o.orderdate, o.shippingCost, od.DetailID, od.Item, od.Amount из приказы о внутреннее соединение OrderDetails od on o.OrderID = od.OrderID orderID заказчик дата заказа shippingCost DetailID Item Amount ----------- ---------- -------------- ------------- - ------- ---------- ---------- 1 ABC 2007-01-01 40.0000 1 Поз. A 100.0000 1 ABC 2007-01-01 40.0000 2 Поз. B 150.0000 2 ABC 2007-01-02 30.0000 3 Поз. C 125.0000 2 ABC 2007-01-02 30.0000 4 Поз. B 50.0000 2 ABC 2007-01-02 30.0000 5 Поз. H 200.0000 3 ABC 2007-01-03 25.0000 6 Поз. X 100.0000 4 DEF 2007-01-02 10.0000 7 Поз. Y 50.0000 4 DEF 2007-01-02 10.0000 8 Поз. Z 300.0000 (Затронуты 8 рядов)
Помните, что Orders имеет отношение один ко многим или родитель / потомок с OrderDetails: таким образом, один заказ может иметь многих деталей. Когда мы объединяем их вместе, столбцы Order повторяются снова и снова для каждого OrderDetail. Это нормальное, стандартное поведение SQL и то, что происходит, когда вы объединяете таблицы в отношении «один ко многим». Наш результат содержит по одной строке на OrderDetail, и эти строки OrderDetail никогда не повторяются, так как они не присоединяются ни к каким другим таблицам, которые будут создавать повторяющиеся строки.
Таким образом, мы могли бы сказать, что наш результирующий набор имеет виртуальный первичный ключ DetailID; в данных никогда не будет повторяющейся строки OrderDetail. Мы можем подсчитывать и складывать все столбцы OrderDetail и никогда не беспокоиться о двойном подсчете значений. Однако мы не можем сделать то же самое для таблицы Orders, поскольку ее строки дублируются в результатах. Помните об этом по мере продвижения вперед.
Пример типичного сводного отчета
Вот хороший пример использования Orders и OrderDetails, который демонстрирует различные агрегатные функции и типичные вещи, которые нужно искать:
Для каждого покупателя мы хотим вернуть общее количество заказов, количество заказанных товаров, общую сумму заказа и общую стоимость доставки.
Вся эта информация хранится в таблицах Orders и OrderDetails, и мы знаем, как объединить их вместе, нам просто нужно подвести итоги сейчас. Мы не хотим возвращать все 8 строк и видеть все детали; мы просто хотим вернуть 2 строки: по одной для каждого покупателя, с соответствующими итоговыми вычислениями.
Группирование и суммирование первичных строк
Так как мы хотим вернуть 1 строку для каждого клиента, мы можем просто добавить GROUP BY Customer в конец SELECT.Мы можем вернуть столбец «Клиент», поскольку мы группируем по нему, и мы можем добавить любые другие столбцы, если они суммированы в агрегатной функции. Мы также можем использовать CO
SQL GROUP BY — SQL Tutorial
Оператор SQL GROUP BY используется вместе с агрегатными функциями SQL, такими как SUM для предоставления средств группировки набора данных результатов по определенной таблице базы данных столбец (и).
Лучший способ объяснить, как и когда использовать оператор SQL GROUP BY , — это пример, и это то, что мы собираемся делать.
Рассмотрим следующую таблицу базы данных под названием EmployeeHours, в которой хранятся ежедневные часы. для каждого сотрудника фракционной компании:
| Сотрудник | Дата | Часы |
| Джон Смит | 06.05.2004 | 8 |
| Аллан Бабель | 06.05.2004 | 8 |
| Тина Корона | 06.05.2004 | 8 |
| Джон Смит | 07.05.2004 | 9 |
| Аллан Бабель | 07.05.2004 | 8 |
| Тина Корона | 07.05.2004 | 10 |
| Джон Смит | 08.05.2004 | 8 |
| Аллан Бабель | 08.05.2004 | 8 |
| Тина Корона | 08.05.2004 | 9 |
Если менеджер компании хочет получить простую сумму всех отработанных часов для всех сотрудников ему необходимо выполнить следующий оператор SQL:
| ВЫБЕРИТЕ СУММУ (часы) ОТ EmployeeHours |
Но что, если менеджер хочет получить сумму всех часов для каждого своего
сотрудники?
Для этого ему нужно изменить свой SQL-запрос и использовать оператор SQL GROUP BY :
| ВЫБЕРИТЕ сотрудника, СУММА (часы) ОТ СотрудникаЧасов ГРУППА ПО сотруднику |
Результатом приведенного выше выражения SQL будет следующий:
| Сотрудник | Часы |
| Джон Смит | 25 |
| Аллан Бабель | 24 |
| Тина Корона | 27 |
Как видите, у нас есть только одна запись для каждого сотрудника, потому что мы группировка по столбцу Сотрудник.
Предложение SQL GROUP BY можно использовать с другими агрегатными функциями SQL для пример SQL AVG:
| ВЫБРАТЬ Сотрудника, СРЕДНЕЕ (часы) ОТ СотрудникаЧасов ГРУППА ПО сотруднику |
Результатом приведенного выше оператора SQL будет:
| Сотрудник | Часы |
| Джон Смит | 8.33 |
| Аллан Бабель | 8 |
| Тина Корона | 9 |
В нашей таблице сотрудников мы также можем сгруппировать по столбцу даты, чтобы узнать, что общее количество часов, отработанных на каждую дату в таблице:
| ВЫБЕРИТЕ дату, СУММУ (часы) ОТ СотрудникаЧасов ГРУППА ПО ДАТЕ |
Вот результат приведенного выше выражения SQL:
| Дата | Часы |
| 06.05.2004 | 24 |
| 07.05.2004 | 27 |
| 08.05.2004 | 25 |
SQLBolt — Изучение SQL — Урок SQL 10: Запросы с агрегатами (Pt.1)
Урок SQL 10: Запросы с агрегатами (часть 1)
В дополнение к простым выражениям, которые мы представили на прошлом уроке, SQL также поддерживает использование агрегированные выражения (или функции), которые позволяют суммировать информацию о группе строк данных. С помощью базы данных Pixar, которую вы использовали, агрегатные функции можно использовать для ответа такие вопросы, как «Сколько фильмов выпустила Pixar?» или «Какой самый кассовый фильм Pixar каждый год?».
Выбрать запрос с агрегатными функциями по всем строкам
SELECT AGG_FUNC ( column_or_expression ) AS aggregate_description ,…
ИЗ mytable
ГДЕ выражение_ограничения ; Без указанной группировки каждая агрегатная функция будет выполняться для всего набора результатов. строк и верните одно значение. И, как и обычные выражения, присваивая вашим агрегатным функциям псевдоним гарантирует, что результаты будет легче читать и обрабатывать.
Вот несколько общих агрегатных функций, которые мы собираемся использовать в наших примерах:
| Функция | Описание |
| COUNT ( * ) , COUNT ( столбец ) | Общая функция, используемая для подсчета количества строк в группе, если имя столбца не указано. В противном случае подсчитайте количество строк в группе со значениями, отличными от NULL, в указанном столбце. |
| МИН ( столбец ) | Находит наименьшее числовое значение в указанном столбце для всех строк в группе. |
| MAX ( столбец ) | Находит наибольшее числовое значение в указанном столбце для всех строк в группе. |
| AVG ( столбец) | Находит среднее числовое значение в указанном столбце для всех строк в группе. |
| СУММ ( столбец ) | Находит сумму всех числовых значений в указанном столбце для строк в группе. |
| Документы: MySQL, Постгрес, SQLite, Microsoft SQL Server | |
В дополнение к агрегированию по всем строкам вы можете вместо этого применить агрегатные функции к
отдельные группы данных внутри этой группы (т. е.кассовые сборы комедий против боевиков).
Тогда будет создано столько результатов, сколько уникальных групп определены в предложении GROUP BY .
Выбрать запрос с агрегатными функциями по группам
SELECT AGG_FUNC ( column_or_expression ) AS aggregate_description,…
ИЗ mytable
ГДЕ constraint_expression ГРУППА ПО столбцу ; Предложение GROUP BY работает, группируя строки, которые имеют одинаковое значение в указанном столбце.