Предложение GROUP BY — Служба поддержки Майкрософт
Access
Запросы
Синтаксис SQL
Синтаксис SQL
Предложение GROUP BY
Access для Microsoft 365 Access 2021 Access 2019 Access 2016 Access 2013 Access 2010 Access 2007 Еще…Меньше
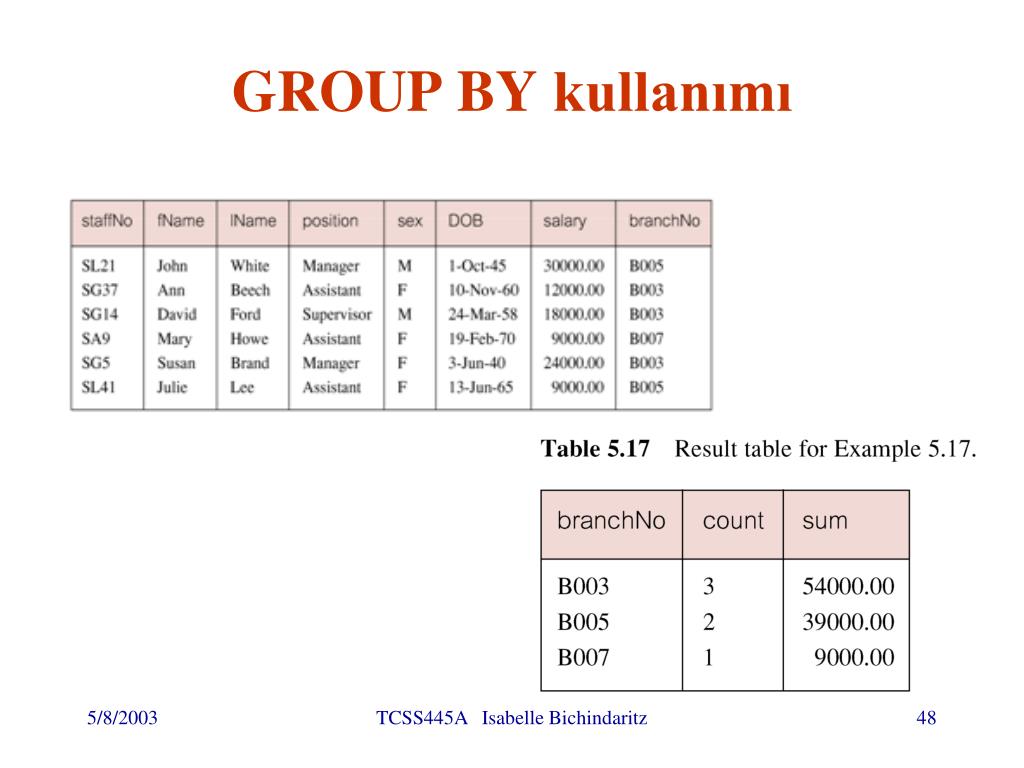
Предложение GROUP BY в Access объединяет записи с одинаковыми значениями в указанном списке полей в одну запись. Сводное значение создается для каждой записи, если в инструкцию SELECT включена агрегатная функция SQL, например Sum или Count.
Синтаксис
SELECT список_полей
FROM таблица
WHERE условия
[GROUP BY список_полей_группы]
Инструкция SELECT, содержащая предложение GROUP BY, включает в себя следующие элементы:
|
|
Описание |
|
список_полей |
Имена полей, извлекаемых вместе с любыми псевдонимами, статистическими функциями SQL, предикатами отбора (ALL, DISTINCT, DISTINCTROW или TOP) или с другими параметрами инструкции SELECT. |
|
Таблица |
Имя таблицы, из которой извлекаются записи. |
|
условия |
Условия отбора. Если инструкция содержит предложение WHERE, то после его применения к записям ядро базы данных Microsoft Access сгруппирует значения. |
|
список_полей_группы |
Имена полей (не более 10), используемых для группировки записей. Порядок следования имен в списке_полей_группы определяет уровень группировки — от самого высокого до самого низкого |

Замечания
Предложение GROUP BY не является обязательным.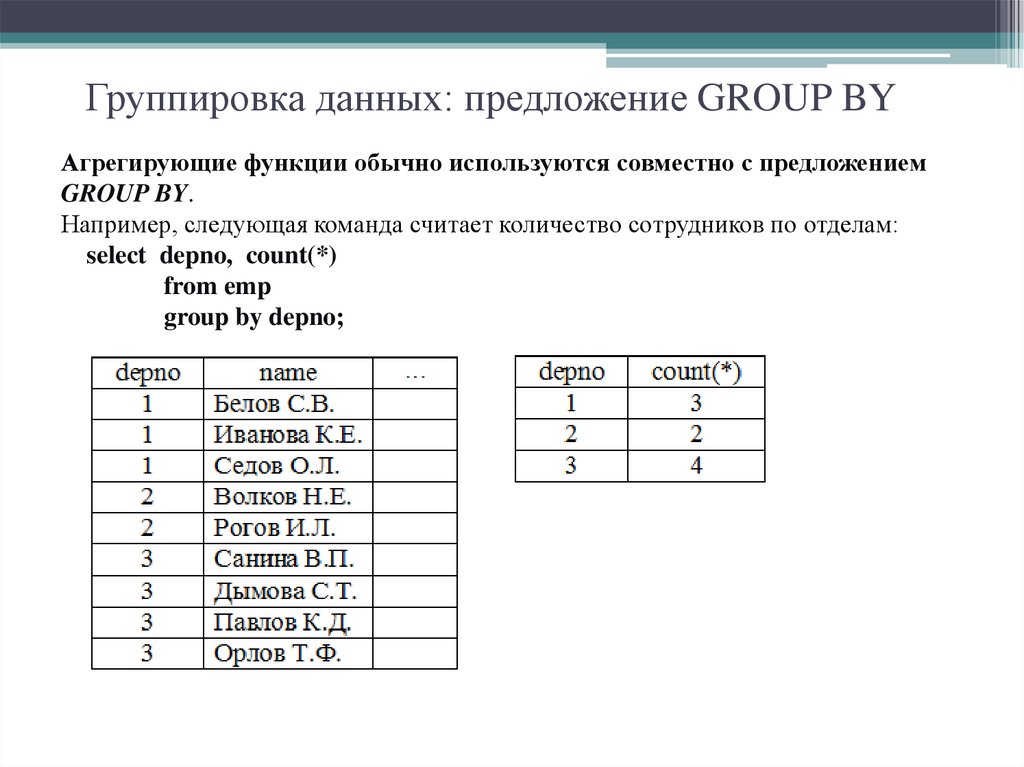
Если в инструкцию SELECT не включены статистические функции SQL, сводные значения не вычисляются.
Значения NULL в полях GROUP BY группются и не опускаются. Однако они не вычисляются ни одной из статистических функций SQL.
Предложение WHERE используется для исключения строк, которые не нужно группировать. Предложение HAVING позволяет фильтровать записи после группировки.
Если оно не содержит данных «Memo» или «Объект OLE», поле в списке полей GROUP BY может ссылаться на любое поле из любой таблицы, перечисленных в предложении FROM, даже если это поле не включено в предложение SELECT, если в предложении SELECT есть по крайней мере одна агрегатная функция SQL. Яд баз данных Microsoft Access не может группться по полям объектов Memo и OLE.
Все поля в списке полей SELECT должны либо содержаться в предложении GROUP BY, либо быть аргументами статистической функции SQL.
sql — Как работает GROUP BY в MySQL?
Привет.
Вопрос по sql по клаузуле GROUP BY.
Рассмотрим группировку по ОДНОМУ столбцу. Пример:
SELECT DEPARTMENT_ID, SUM(SALARY) FROM Employees GROUP BY DEPARTMENT_ID;
То есть, в столбце
DEPARTMENT_IDищется уникальное (похоже наDISTINCT) значение отдела, например, 30, затем ищутся все строки, где упоминается отдел 30 в данной таблице, из этих строк берутся значения из столбцаSALARYи суммируются (SUM). Потом ищется другой покупатель и все повторяется. В итоге я получаю сколько получил вообще денег каждый отдел.Не понимаю момент: у меня есть 6 строк, в которых есть столбец
SELECTи почему? То есть, в таблицеEmployeesбыло шесть строк сDEPARTMENT_ID30, а в таблице-SELECTтакая строка только одна. Как вообще эта группировка работает?
Как вообще эта группировка работает?Рассмотрим группировку по двум столбцам. Ее я вообще не понимаю. Даже картинки нормальной не нашел, из которой было бы понятно. Просмотрел кучу статей и книг по этому вопросу, но не понял ничего.
- mysql
- sql
- group-by
4
В выборку после group by не попадет ни одна из изначальных строк. На выходе агрегат — сумма данных в нужном разрезе. К колонкам, к которым вы явно не применили никаких групповых функций (таких как sum()), будет применена функция «первое попавшееся». Причем только в MySQL и только при выключенной опции ONLY_FULL_GROUP_BY. В остальных СУБД запрос, в котором хотя бы к одной колонке, не являющейся разрезом указанным в group by, «забыли» применить групповую функцию выдаст ошибку.
Как работает group by можно прикинуть в экселе.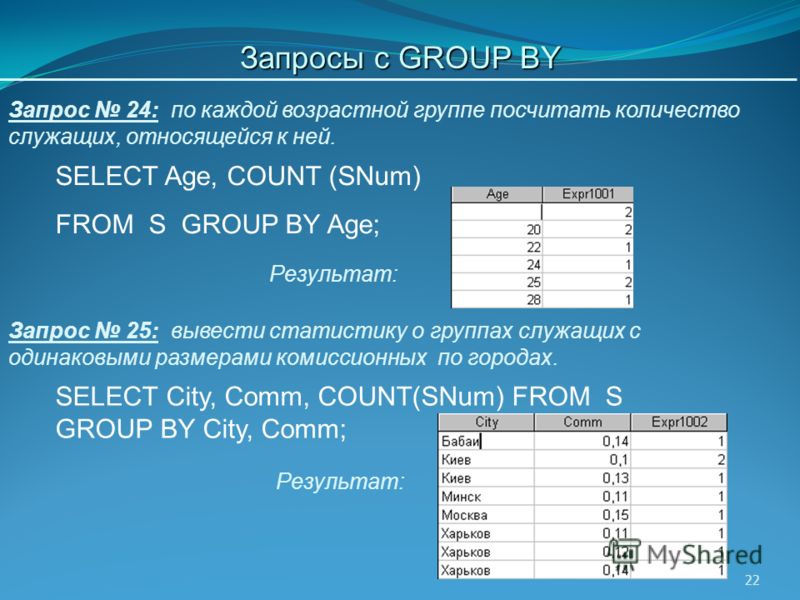 Запишите данные на лист, отсортируйте по тем полям, которые должны быть в
Запишите данные на лист, отсортируйте по тем полям, которые должны быть в group by. Читая отсортированные данные подряд в любом случае когда значение в очередной строке в колонках, указанных в group by отличается от значений в предыдущей — вставьте новую строку, скопируйте значения колонок group by, а в остальные поместите формулы вроде СУММ()
group by — это именно эти вставленные итоговые записи. СУБД работает примерно по такому же алгоритму — сначала сортирует, потом суммирует идущие подряд одинаковые записи.Добавлю про MySQL — он все таки слишком вольно к этому относится. Старайтесь всегда явно применять групповые функции ко всем колонкам, что бы самому понимать что именно в них окажется, ибо ‘первое попавшееся’ ни чем не стандартизировано и может меняться от версии к версии и в зависимости от физического расположения записей на диске и плана выполнения запроса.
0
Добавлю с примером запросов и вывода GROUP BY по двух полях. Смотреть можно по таблице в которую, например, сохраняеться какой пользователь (user_id) вносил деньги, на какой счет (account) и сколько (balance). Например, нужно узнать сколько каждый пользователь внес на каждый из своих счетов.
SELECT MIN(user_id), MIN(account), SUM(balance) FROM `t1` GROUP BY user_id, account;
Работает GROUP BY по двум полям так же как и по одному, сначала сортирует, а потом смотрит, если оба значения в строке такие же как и в предыдущей строке, тогда групирует эти строки. Если хотя бы одно значение не такое как в предыдущей строке, тогда групировки не будет. Для 3 и больше полей GROUP BY работает так же.
Результат:
0
Зарегистрируйтесь или войдите
Регистрация через Google
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Как использовать предложение GROUP BY в SQL
Data Science
Простые и сложные примеры использования SQL GROUP BY, менее чем за 10 минут
Фото Мэрайи Хьюайнс на Unsplash — Язык структурированных запросов — широко используемый инструмент для извлечения данных из реляционной базы данных и их преобразования.
Преобразование данных будет неполным без объединения данных, что является важной концепцией в SQL. А агрегация данных невозможна без GROUP BY! Поэтому важно освоить GROUP BY, чтобы легко выполнять все типы преобразования и агрегирования данных.
В SQL GROUP BY используется для агрегирования данных с использованием агрегатных функций. например СУММ() , МИН() , МАКС() , СРЕДН() и СЧЁТ() .
Но почему функция агрегации используется в сочетании с GROUP BY?
В SQL предложение GROUP BY используется для группировки строк. Поэтому, когда вы используете агрегатную функцию для столбца, результат описывает данные для этой конкретной группы строк.
В этой статье я объясню 5 примеров использования предложения GROUP BY в запросе SQL, которые помогут вам использовать GROUP BY без каких-либо проблем.
Я сделал эту статью довольно короткой, чтобы вы могли быстро закончить ее и освоить одну из важных концепций SQL.
С помощью этого указателя вы можете быстро перейти к своей любимой части.
· GROUP BY с функциями агрегирования
· Группа по без совокупных функций
· Группа с помощью
· Группа по заказу на
· Группа с тем, где, примечание и порядок
📍 77777777777777777777777 : Я использую браузер SQLite DB и самостоятельно созданные данные о продажах, созданные с использованием Faker . Вы можете получить его в моем репозитории Github бесплатно по лицензии MIT License !
Простой 9Набор данных 999 x 11, как показано ниже.
Набор данных фиктивных продаж | Изображение автораИтак, начнем…
Хорошо, прежде чем двигаться дальше, всегда помните одно правило GROUP BY. .
.
должен либо присутствовать в предложении GROUP BY , либо встречаться как параметр в агрегированной функции.
Теперь давайте начнем с самого простого варианта использования.
Это наиболее часто используемый сценарий, в котором функция агрегирования применяется к одному или нескольким столбцам. Как упоминалось выше, GROUP BY просто группирует вместе строки, которые имеют схожие значения в указанных столбцах.
Например, предположим, вы хотите получить статистическую сводку цены за единицу по каждой категории продуктов. В этом примере конкретно объясняется, как использовать все агрегатные функции.
Статистическую сводку можно получить с помощью запроса —
SELECT Product_Category,Агрегирование данных в SQL | Изображение автора
MIN(UnitPrice) AS Lowest_UnitPrice,
MAX(UnitPrice) AS Highest_UnitPrice,
SUM(UnitPrice) AS Total_UnitPrice,
AVG(UnitPrice) AS Average_UnitPrice
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category
Как вы видите в приведенном выше запросе, вы использовали два столбца — Product_Category и UnitPrice — и последний всегда используется в агрегатных функциях. Таким образом, предложение
Таким образом, предложение GROUP BY содержит только один оставшийся столбец.
Вы можете заметить, что первая запись в Product_Category равна NULL , что означает, что GROUP BY объединяет все значения NULL в Product_Category в одну группу. Это соответствует стандарту SQL, как указано в Microsoft —
«Если столбец группировки содержит значения NULL, все значения NULL считаются равными и собираются в одну группу».
Кроме того, по умолчанию таблица результатов упорядочена в порядке возрастания столбцов в GROUP BY с NULL (если есть) вверху. Если вы не хотите, чтобы NULL был частью вашей таблицы результатов, вы можете в любое время использовать функцию COALESCE и дать значимое имя для NULL , как показано ниже.
Выберите Coalesce (Product_category, 'Undefined_category') как Product_category ,Значения NULL в SQL GROUP BY | Image by Author
мин (UNITPRICE) в качестве самую низкую_unitprice,
MAX (UNITPRICE) в качестве наивысшего_NITPRICE,
SUM (UNITPRIE0054 FROM Dummy_Sales_Data_v1
GROUP BY Product_Category
🚩 Здесь важно отметить —
Хотя
COALESCEприменяется к столбцу Product_Category, на самом деле вы не агрегируете значения из этого столбца.Таким образом, это должно быть частью GROUP BY.
Таким образом, вы можете добавить столько столбцов, сколько вам нужно, в оператор SELECT , применить агрегатную функцию к некоторым или ко всем столбцам и упомянуть оставшиеся имена столбцов в GROUP BY , чтобы получить желаемые результаты.
Ну, речь шла об использовании GROUP BY вместе с функцией агрегации. Но вы также можете использовать это предложение без агрегатных функций, как объяснено далее.
Хотя в большинстве случаев GROUP BY используется вместе с агрегатными функциями, его можно использовать и без агрегатных функций — для поиска уникальных записей .
Например, предположим, что вы хотите получить все уникальные комбинации из Sales_Manager и Product_Category . Используя GROUP BY, это очень просто. Все, что вам нужно сделать, это указать все имена столбцов в GROUP BY , которые вы упомянули в SELECT , как показано ниже.
ВЫБЕРИТЕ Product_Category,SQL GROUP BY без агрегатных функций | Изображение автора
Sales_Manager
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager
На данный момент некоторые могут возразить, что те же результаты можно получить, используя DISTINCT ключевое слово перед именами столбцов.
Однако есть две основные причины, по которым вам следует выбрать GROUP BY вместо DISTINCT , чтобы получить уникальные записи.
- Результаты, полученные с помощью предложения GROUP BY, по умолчанию упорядочены в порядке возрастания. Таким образом, вам не нужно сортировать записи отдельно.
- DISTINCT может быть дорогостоящим, если вы работаете с набором данных с миллионами строк, а ваш SQL-запрос содержит JOIN
Таким образом, использование GROUP BY позволяет эффективно получать уникальные записи из базы данных, даже если в запросе используется несколько JOIN.
Вы можете прочитать о другом интересном примере использования предложения GROUP BY в одной из моих предыдущих статей —
3 лучших способа найти уникальные записи в SQL
Прекратите использовать DISTINCT! Начните использовать эти быстрые альтернативы, чтобы избежать путаницы!
в направлении datascience.com
Двигаясь дальше, давайте узнаем больше о том, как можно эффективно ограничить выходные данные, полученные с помощью предложения GROUP BY.
В SQL HAVING работает по той же логике, что и предложение WHERE , с той лишь разницей, что оно фильтрует группу записей, а не каждую другую запись.
Например, предположим, что вы хотите получить уникальные записи с Категория продукта, менеджер по продажам и стоимость доставки , где стоимость доставки превышает 34 .
Этого можно добиться с помощью WHERE , а также предложения HAVING , как указано ниже.
- Где пункт Select Product_category,Одинаковые выходные данные WHERE и HAVING in GROUP BY | Image by Author
Sales_Manager,
Shipping_cost
от Dummy_sales_Data_V1
, где Shiping_COST> = 34
GRAP . ВЫБЕРИТЕ Product_Category,
Sales_Manager,
Shipping_Cost
FROM Dummy_Sales_Data_v1
GROUP BY Product_Category,
Sales_Manager,
Shipping_Cost
HAVING Shipping_Cost >= 34
Хотя вышеприведенные оба запроса генерируют один и тот же вывод, логика совершенно разная. Предложение WHERE выполняется перед GROUP BY , поэтому, по сути, оно сканирует весь набор данных для заданного условия.
Однако HAVING выполняется после GROUP BY , поэтому сканируется сравнительно небольшое количество записей, поскольку строки уже сгруппированы. Так
Так НАЛИЧИЕ экономит время.
Ну, допустим, вас мало волнует эффективность. Но теперь вам нужны все категорий продуктов и менеджер по продажам , где общая стоимость доставки превышает 6000. И вот когда ИМЕЕТ , пригодится.
Здесь, чтобы отфильтровать записи, вам нужно использовать условие SUM(Shipping_Cost) > 6000 , и вы не можете использовать какую-либо агрегатную функцию в предложении WHERE .
Вы можете использовать , имея , как ниже в этой ситуации —
Select Product_category,SQL ГРУППА ПО НАЛИЧИИ | Изображение автора
Sales_Manager,
SUM (Shipping_COST) as total_cost
от Dummy_Sales_DATA_V1
Группа Product_Category,
44.
9009 9009 9009 9009 99.0009.
Поскольку вы использовали агрегацию Shipping_Cost , вам не нужно упоминать об этом в GROUP BY . Логически все строки сгруппированы вместе на основе категории продукта и менеджера по продажам, а затем HAVING сканирует данное условие во всех этих группах.
Таким образом, HAVING , используемый в сочетании с GROUP BY , представляет собой оптимизированный способ фильтрации строк на основе условия.
🚩 Примечание. Поскольку HAVING выполняется до SELECT, вы не можете использовать псевдонимы столбцов в условиях в предложении HAVING.
Кроме того, несмотря на то, что GROUP BY упорядочивает записи в возрастающем или алфавитном порядке, иногда может потребоваться упорядочить записи в соответствии с агрегированными столбцами. И вот когда ORDER BY .
В SQL ORDER BY используется для сортировки результатов и по умолчанию сортирует их в порядке возрастания. Однако, чтобы получить результат в порядке убывания, вам нужно просто добавить ключевое слово DESC после имен столбцов в предложении ORDER BY .
Продолжим рассмотренный выше пример. Вы можете видеть, что последний результат упорядочен в возрастающем (алфавитном) порядке, сначала по столбцу Product_Category , а затем по Sales_Manager . Однако значения в последнем столбце — Total_Cost — не упорядочены.
Однако значения в последнем столбце — Total_Cost — не упорядочены.
Этого можно добиться с помощью предложения ORDER BY , как указано ниже.
SELECT Product_Category,DESCENCER . Изображение автора
Sales_Manager,
SUM (Shipping_COST) AS Total_COST
от DUMMY_SALES_DATA_V1
Группа по продукту_категории,
Sales_manager
заказа на Total_COST DESC
Понятно, что последний столбец теперь расположен в порядке убывания. Кроме того, вы можете видеть, что теперь нет определенного порядка значений в первых двух столбцах. И это потому, что вы включили их только в GROUP BY , но не в пункте ORDER BY .
Эта проблема может быть решена, упомянув их в предложении «Заказ по », как ниже —
Select Product_category,ORDER BY несколько столбцов в SQL | Изображение автора
Sales_Manager,
SUM (Shipping_COST) AS Total_cost
от DUMMY_SALES_DATA_V1
Group By Product_Caterory,
Sales_sales_DATA_V1
By Product_caterory,
Sales_sales_DATA_V1
.Product_Category,
Sales_Manager,
Total_Cost DESC
Теперь первые два столбца расположены в порядке возрастания, и только последний столбец — Total_Cost — в порядке убывания. И это потому, что ключевое слово DESC используется только после имени этого столбца.
🚩 Это дает вам важный урок —
Вы можете упорядочить набор данных результатов SQL по нескольким столбцам в разном порядке, т.е. расположить некоторые столбцы в порядке возрастания, а остальные в порядке убывания. Но обратите внимание на порядок, в котором имена столбцов упоминаются в ORDER BY , так как это изменяет результирующий набор.
В этом случае важно понять, как работает GROUP BY. Вы задавали себе вопрос —
Почему вы не видите все значения в столбце
Total_Costв порядке убывания❓
Это потому, что в упоминаются только первые два столбца GROUP BY . Все записи упорядочены по группам на основе значений только в этих двух столбцах, а общая стоимость рассчитывается путем агрегирования значений в 9 столбцах.0076 Столбец Shipping_Cost .
Все записи упорядочены по группам на основе значений только в этих двух столбцах, а общая стоимость рассчитывается путем агрегирования значений в 9 столбцах.0076 Столбец Shipping_Cost .
Таким образом, итоговые значения затрат в результате располагаются по этим группам, а не по всей таблице.
Вперед, давайте рассмотрим пример, который поможет вам понять разницу между фильтрацией записей и когда использовать WHERE и HAVING в сочетании с GROUP BY .
Поскольку вы уже ознакомились со всеми понятиями в статье, давайте начнем непосредственно с примера.
Предположим, вы хотите получить список менеджеров по продажам и категорий продуктов для всех заказов, которые не доставлены клиенту. При этом вы хотите отобразить только тех менеджеров по продажам, которые потратили более 1600 долларов США на доставку товаров в определенной товарной категории.
Теперь вы можете решить эту проблему, выполнив следующие 3 шага —
- Отфильтровать все записи, используя условие
Статус = «Не доставлено». Поскольку это не агрегированный столбец, вы можете использовать для этого WHERE.
Поскольку это не агрегированный столбец, вы можете использовать для этого WHERE. - Фильтрация записей на основе общей стоимости доставки с использованием условия
SUM(Shipping_Cost) > 1600. Поскольку это агрегированный столбец, для этого следует использовать HAVING. - Чтобы рассчитать общую стоимость доставки, вам необходимо сгруппировать записи по менеджерам по продажам и категориям продуктов, используя
GROUP BY
Если вы следуете инструкциям, ваш запрос должен выглядеть так —
SELECT Sales_Manager,SQL GROUP BY с ГДЕ и ИМЕЕТ Image by Author
Product_Category,
SUM(Стоимость_доставки) AS Total_Cost
FROM Dummy_Sales_Data_v1
ГДЕ Статус = 'Не доставлено'
ГРУППА ПО Sales_Manager,
Product_Category
ИМЕЕТ СУММУ (Стоимость_доставки) > 1600
Выдает все уникальные комбинации менеджера по продажам и категорий продуктов, удовлетворяющие условиям, указанным в примере.
Как видите, первые два столбца расположены в порядке возрастания. Кроме того, две строки, обведенные красным, показывают возрастание категорий продуктов для одного и того же менеджера по продажам. Это свидетельство того, что GROUP BY по умолчанию упорядочивает записи в порядке возрастания.
Это все о GROUP BY!
Надеюсь, вы быстро прочитали эту статью и нашли ее полезной и полезной.
Я использую SQL в течение последних 3 лет, и я обнаружил, что эти альтернативы довольно экономят время и являются мощными, особенно при работе с большими наборами данных. Четкое понимание этих концепций очень важно при работе над реальными проектами.
Хотите прочитать больше историй на Medium??
💡 Рассмотрим Стать участником Medium От до доступ к неограниченным историям на Medium и ежедневным интересным дайджестам Medium. Я получу небольшую часть вашего гонорара и никаких дополнительных затрат для вас.
💡 Не забудьте Подпишитесь на мою рассылку , чтобы получать первые экземпляры моих статей.
Спасибо за внимание!
SQLite Group By
Резюме : в этом руководстве вы узнаете, как использовать SQLite Предложение GROUP BY для создания набора итоговых строк из набора строк.
Введение в SQLite
Предложение GROUP BY Предложение GROUP BY является необязательным предложением оператора SELECT . Предложение GROUP BY
Предложение GROUP BY возвращает одну строку для каждой группы. Для каждой группы можно применить агрегатную функцию, например MIN , MAX , SUM , COUNT или AVG для предоставления дополнительной информации о каждой группе.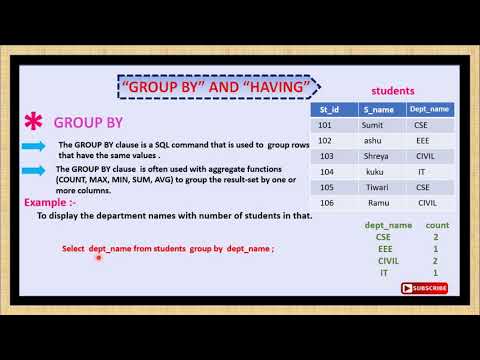
Следующий оператор иллюстрирует синтаксис предложения SQLite GROUP BY .
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ столбец_1, агрегатная_функция (столбец_2) ОТ стол ГРУППА ПО столбец_1, столбец_2;
Попробуйте
9Предложение 0017 GROUP BY следует за предложением FROM оператора SELECT . Если оператор содержит предложение WHERE , предложение GROUP BY должно стоять после предложения WHERE .
За предложением GROUP BY следует столбец или список столбцов, разделенных запятыми, которые используются для указания группы.
SQLite
GROUP BY examples Для демонстрации мы используем таблицу track из примера базы данных.
SQLite
Предложение GROUP BY с функцией COUNT Следующая инструкция возвращает идентификатор альбома и количество дорожек в альбоме. Он использует предложение GROUP BY для группировки дорожек по альбомам и применяет функцию COUNT() к каждой группе.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБЕРИТЕ альбумид, COUNT(идентификатор отслеживания) ОТ треки ГРУППА ПО альбумид;
Попробуйте
Вы можете использовать предложение ORDER BY для сортировки групп следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT альбумид, COUNT(идентификатор отслеживания) ОТ треки ГРУППА ПО альбумид ЗАКАЗАТЬ ПО СЧЕТУ (trackid) DESC;
Попробуйте
SQLite
GROUP BY и INNER JOIN предложение INNER JOIN , используя предложение INNER JOIN . затем используйте
затем используйте GROUP BY 9Предложение 0018 для группировки строк в набор сводных строк. Например, следующий оператор объединяет таблицу треков с таблицей альбомов для получения названий альбомов и использует предложение GROUP BY с функцией COUNT для получения количества треков в альбоме.
ВЫБЕРИТЕ
треки.альбом,
заголовок,
COUNT(идентификатор отслеживания)
ОТ
треки
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ альбомов ON Albums.albumid = tracks.albumid
ГРУППА ПО
треки.альбумид;
Язык кода: SQL (язык структурированных запросов) (sql)
Попробуйте
SQLite
GROUP BY с предложением HAVING Например, чтобы получить альбомы, содержащие более 15 треков, используйте следующий оператор:
SELECT.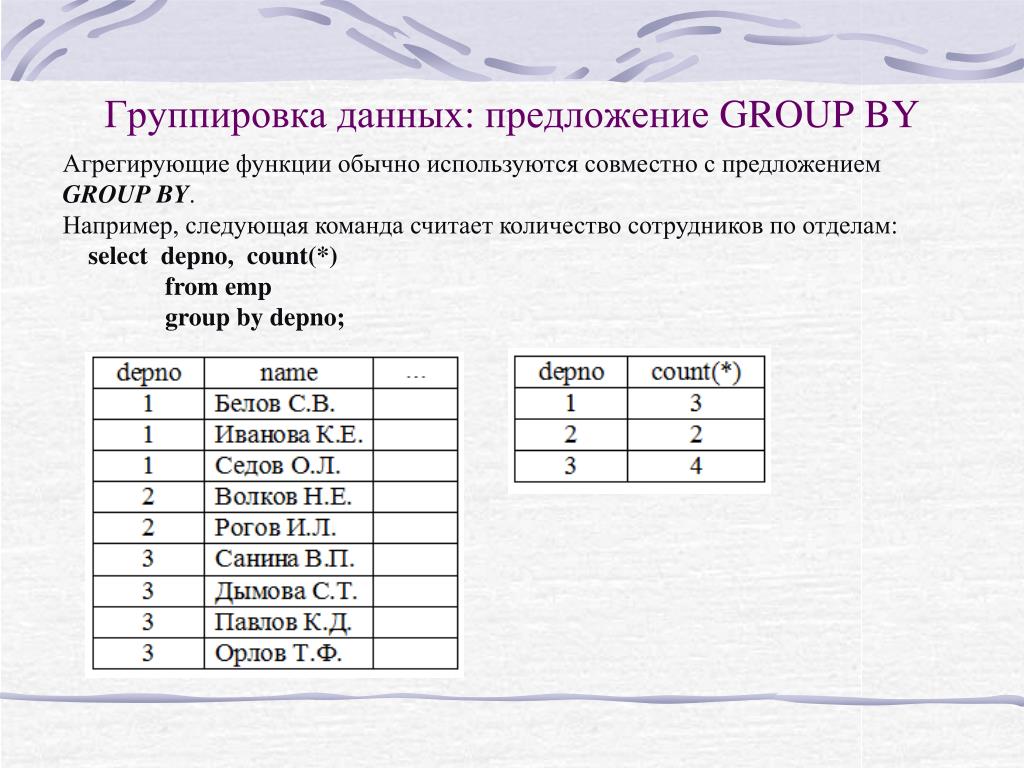 треки.альбом,
заголовок,
COUNT(идентификатор отслеживания)
ОТ
треки
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ альбомов ON Albums.albumid = tracks.albumid
ГРУППА ПО
треки.альбом
СЧЕТЧИК(trackid) > 15;
треки.альбом,
заголовок,
COUNT(идентификатор отслеживания)
ОТ
треки
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ альбомов ON Albums.albumid = tracks.albumid
ГРУППА ПО
треки.альбом
СЧЕТЧИК(trackid) > 15;
Язык кода: SQL (язык структурированных запросов) (sql)
Попробуйте
SQLite
Предложение GROUP BY с примером функции SUM Например, чтобы получить общую длину и количество байтов для каждого альбома, вы используете функцию SUM для расчета общего количества миллисекунд и байтов. ВЫБЕРИТЕ
альбумид,
SUM(миллисекунды) длина,
СУММА(байт) размер
ОТ
треки
ГРУППА ПО
альбумид;
Code language: SQL (Structured Query Language) (sql)
Try It
SQLite
GROUP BY with MAX , MIN , and AVG functions The following statement returns the album id , название альбома, максимальная длина, минимальная длина и средняя длина дорожек в таблице дорожек .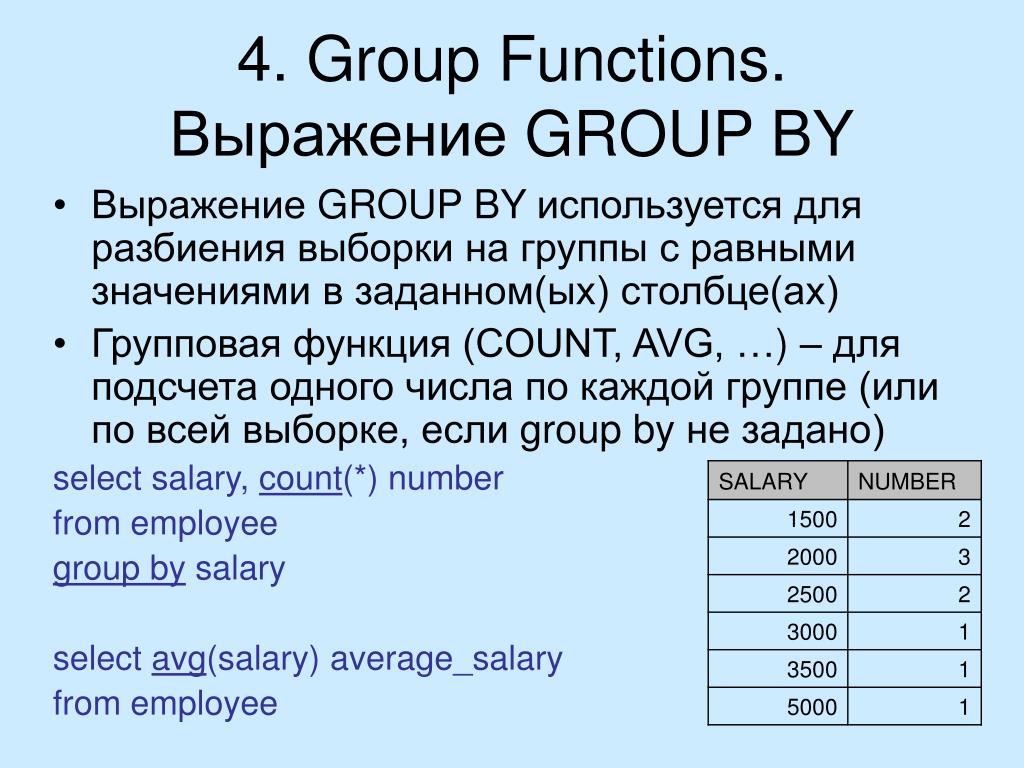
ВЫБЕРИТЕ
треки.альбом,
заголовок,
мин (миллисекунды),
макс (миллисекунды),
раунд (среднее (миллисекунды), 2)
ОТ
треки
ВНУТРЕННЕЕ ОБЪЕДИНЕНИЕ альбомов ON Albums.albumid = tracks.albumid
ГРУППА ПО
треки.альбумид;
Язык кода: SQL (язык структурированных запросов) (sql)
Попробуйте
SQLite
GROUP BY пример нескольких столбцов В предыдущем примере мы использовали один столбец в предложении GROUP BY . SQLite позволяет группировать строки по нескольким столбцам.
Например, чтобы сгруппировать дорожки по типу носителя и жанру, используйте следующий оператор:
SELECT
идентификатор типа медиа,
жанр,
COUNT(идентификатор_отслеживания)
ОТ
треки
ГРУППА ПО
идентификатор типа медиа,
ЖанрId;
Язык кода: SQL (язык структурированных запросов) (sql)
Попробуйте
SQLite использует комбинацию значений столбцов MediaTypeId и GenreId в виде группы, например, (1,1) и (1) ,2).