Группировка (GROUP) | Основы реляционных баз данных
Зарегистрируйтесь для доступа к 15+ бесплатным курсам по программированию с тренажером
С агрегатными функциями связано множество разных задач. Например, они помогают вывести общее число топиков для каждого пользователя. Так это может выглядеть:
SELECT COUNT(*) FROM topics WHERE user_id = 3; SELECT COUNT(*) FROM topics WHERE user_id = 4; -- ...
При этом здесь мы сталкиваемся с одной сложностью — невозможно выполнить данную задачу за один запрос, используя только функции. Нам придется делать выборку для каждой категории индивидуально, а это долго и неудобно. Если пользователей тысячи, то такое решение вопроса неприемлемо в принципе.
Подобные задачи возникают настолько часто, что для них существует специальная форма GROUP BY. В этом уроке мы изучим, как работает эта функция.
GROUP BY
Эта функция группирует строки по определенному признаку и выполняет подсчеты внутри каждой группы независимо от других групп:
SELECT user_id, COUNT(*) FROM topics GROUP BY user_id;
user_id | count
---------+-------
71 | 1
80 | 1
84 | 3
92 | 1
60 | 1
97 | 2
98 | 1
44 | 1
40 | 1
43 | 1
В запросе выше мы создали группы записей по значению поля user_id. Эти данные можно представить себе как набор виртуальных таблиц, каждая из которых содержит все записи по одному пользователю. Подсчет количества идет по каждому пользователю независимо от других. К результатам такой выборки можно применять сортировку и лимитирование:
Эти данные можно представить себе как набор виртуальных таблиц, каждая из которых содержит все записи по одному пользователю. Подсчет количества идет по каждому пользователю независимо от других. К результатам такой выборки можно применять сортировку и лимитирование:
SELECT user_id, COUNT(*) FROM topics GROUP BY user_id ORDER BY count DESC LIMIT 3;
user_id | count
---------+-------
84 | 3
97 | 2
57 | 2
С помощью сортировки мы можем обращаться не только к полям самой таблицы, но и к вычисленному значению. По умолчанию имя этого виртуального поля совпадает с именем функции, но его можно изменить с помощью механизма псевдонимов:
SELECT user_id, COUNT(*) AS topics_count FROM topics GROUP BY user_id ORDER BY topics_count DESC LIMIT 3;
Псевдонимы создаются не только для агрегатных значений, но и для любых имен в запросе. Переименовываются даже существующие поля. Общая структура имени выглядит так: <expression> AS <name>.
У псевдонимов есть одно удобное свойство. Если определить их в одном месте, они становятся доступны в других частях SQL-запроса:
SELECT first_name AS name FROM users ORDER BY name;
Теперь попытаемся выполнить следующий запрос:
SELECT user_id, created_at, COUNT(*) AS topics_count FROM topics GROUP BY user_id;
Запрос завершится с ошибкой:
ERROR: column "topics.created_at" must appear in the GROUP BY clause or be used in an aggregate function LINE 1: SELECT user_id, created_at, COUNT(*) AS topics_count FROM topics G...
Чтобы лучше понять работу GROUP BY, разберемся, почему запрос выше не сработает.
Дело в том, что группировка обращается к записям в таблице и создает из них независимые группы записей, по которым проводится анализ.
Группа записей — не то же самое, что одна запись. Мы не можем просто взять и указать имя любого поля — база данных сама не выберет какое-то значение из этой группы. Такое поведение создает неоднозначность и не несет в себе смысла.
СУБД отслеживает такие ошибки и просит выполнить одно из двух действий:
Действие 1 — указать поле created_at в выражении GROUP BY. Тогда значение поля для каждой записи из группы будет одинаковым — в этом и суть группировки. Значит, СУБД однозначно определит, что нужно добавить в результат:
SELECT user_id, created_at, COUNT(*) AS topics_count
FROM topics
GROUP BY user_id, created_at;
user_id | created_at | topics_count
---------+-------------------------+--------------
40 | 2018-12-05 18:40:05.603 | 1
67 | 2018-12-06 05:23:40.65 | 1
Такой запрос выполнит группировку сначала по user_id, а затем по дате создания. Даты создания у всех топиков почти наверняка уникальны, поэтому вся таблица разобьется на группы по одному элементу. Смысла в таком запросе не очень много, гораздо полезнее сделать то же самое с разбивкой по дням или месяцам. Тогда можно будет увидеть, сколько топиков создает конкретный пользователь каждый день:
Тогда можно будет увидеть, сколько топиков создает конкретный пользователь каждый день:
-- В этом запросе используется функция EXTRACT,
-- которая извлекает значения из даты: например, номер дня или месяца
SELECT user_id, EXTRACT(day from created_at) AS day, COUNT(*) AS topics_count
FROM topics
GROUP BY user_id, day
ORDER BY user_id;
user_id | day | topics_count
--------+-----+--------------
1 | 5 | 1
1 | 6 | 1
4 | 6 | 1
6 | 5 | 1
7 | 6 | 2
8 | 5 | 1
9 | 6 | 1
Действие 2 — использовать created_at внутри агрегатной функции. В таком случае мы получим результат на основе анализа всех значений в рамках группы. Например, добавление вызова MAX(created_at) посчитает дату последнего добавленного топика для каждой группы:
SELECT user_id, MAX(created_at), COUNT(*) AS topics_count
FROM topics
GROUP BY user_id;
user_id | max | topics_count
--------+-------------------------+--------------
40 | 2018-12-05 18:40:05. 603 | 1
67 | 2018-12-06 05:23:40.65 | 1
49 | 2018-12-06 14:55:08.99 | 1
43 | 2018-12-06 00:20:11.835 | 1
603 | 1
67 | 2018-12-06 05:23:40.65 | 1
49 | 2018-12-06 14:55:08.99 | 1
43 | 2018-12-06 00:20:11.835 | 1
HAVING
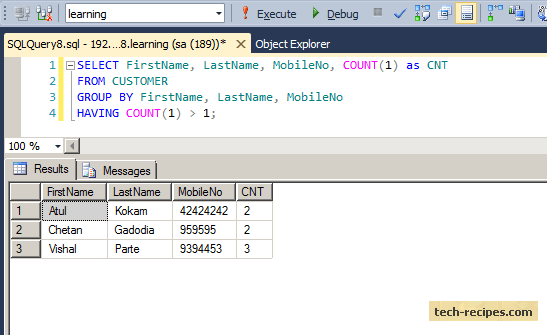
Иногда встречаются более сложные ситуации, в которых нужно проводить анализ только по некоторым группам. Предположим, что мы хотим выбрать всех пользователей, у которых количество топиков больше одного. Эта задача сводится к поиску групп, в которых более одной записи.
Подобный запрос невозможно сделать через WHERE, потому что эти условия применяются к записям исходной выборки, еще до создания самих групп.
В этой задаче понадобится дополнение к GROUP BY, которое называется HAVING:
SELECT user_id, COUNT(*) FROM topics
GROUP BY user_id
HAVING COUNT(*) > 1;
user_id | count
---------+-------
84 | 3
97 | 2
57 | 2
30 | 2
83 | 2
7 | 2
38 | 2
1 | 2
(8 rows)
Подчеркнем, что HAVING нужен для отбора групп по какому-то агрегатному признаку — например, количеству записей в группе. Если вам надо посмотреть значение конкретного поля, используйте именно
Если вам надо посмотреть значение конкретного поля, используйте именно WHERE.
Группировка — это мощный, но в то же время сложный инструмент, который помогает анализировать данные в таблицах. Не заморачивайтесь над тем, чтобы выучить группировку от и до прямо сейчас. Опытные разработчики пользуются ей не каждый день и сами постоянно подсматривают в документацию.
Важно понимать спектр задач, для которых группировка подходит, а остальное — дело техники и умения читать документацию. Это общее правило, характерное и для многих других аспектов баз данных.
Выводы
В этом уроке мы изучили форму GROUP BY и узнали, как работает эта функция. Теперь вы лучше понимаете агрегатные функции и можете выполнять даже сложные задачи за один запрос.
Дополнительные материалы
- Официальная документация
Остались вопросы? Задайте их в разделе «Обсуждение»
Вам ответят команда поддержки Хекслета или другие студенты.
Для полного доступа к курсу нужен базовый план
Базовый план откроет полный доступ ко всем курсам, упражнениям и урокам Хекслета, проектам и пожизненный доступ к теории пройденных уроков. Подписку можно отменить в любой момент.
Получить доступ130
курсов1000
упражнений
2000+
часов теории
3200
тестов
Расширения GROUP BY
Время прочтения: 3 мин.
Для начала вспомним что такое GROUP BY. Итак, GROUP BY – конструкция, которая используется в SQL для группировки данных по полю при использовании в запросе функций агрегации (например, SUM, MAX, MIN и д.р.) либо для исключения дублирования строк (как эквивалент ключевого слова DISTINCT).
Теперь же рассмотрим расширения GROUP BY, которые позволяют получать промежуточные итоги и итоги в целом — ROLLUP, CUBE и GROUPING SETS. Создадим тестовую таблицу и заполним ее данными.
CREATE TABLE #tmp ( [eployee] nvarchar(10), --сотрудник [department] nvarchar(10), --подразделение [work_year] int, --год [annual_income] money –доход )
Начнем с ROLLUP, который вернет нам общую суммирующую строку. Например, мы хотим посмотреть сколько сотрудников в каждом подразделении и их доход за все время работы. Для этого напишем простой запрос:
SELECT [department] ,COUNT(DISTINCT [eployee]) as employess_count ,SUM([annual_income]) as common_income FROM #tmp GROUP BY [department]
А если нам необходимы общее количество сотрудников и их совокупный доход? Тут на помощь и придет ROLLUP.
SELECT [department] ,COUNT(DISTINCT [eployee]) as employess_count ,SUM([annual_income]) as common_income FROM #tmp GROUP BY ROLLUP([department])
Также ROLLUP нам пригодится, если мы хотим увидеть промежуточный итог с доходом каждого сотрудника за все время работы.
SELECT [eployee] ,[work_year] ,SUM([annual_income]) as common_income FROM #tmp GROUP BY ROLLUP([eployee],[work_year])
Строки, отмеченные красными стрелками, будут промежуточным итогом по сотруднику за все его время работы, а фиолетовыми – общая суммирующая строка.
Следующий на очереди — CUBE. Он похож на ROLLUP по двум столбцам из предыдущего примера за тем исключением, что CUBE добавляет суммирующие строки для каждой комбинации групп.
SELECT [eployee] ,[work_year] ,SUM([annual_income]) as common_income FROM #tmp GROUP BY CUBE([eployee],[work_year])
В нашем случае красными стрелками показаны итоги по каждому году для всех сотрудников, которые работали в этом году, синими – общие итоги по каждому сотруднику за все время работы, а фиолетовыми – общая суммирующая строка, как при использовании ROLLUP.
Но что делать, если мы хотим видеть только суммирующие строки для групп? Ответ на этот вопрос – использовать GROUPING SETS. Он, как и ROLLUP и CUBE, добавляет суммирующую строку для групп, но при этом не включает сами группы.
SELECT [eployee] ,[work_year] ,SUM([annual_income]) as common_income FROM #tmp GROUP BY GROUPING SETS([eployee],[work_year])
То есть на примере видим результат выполнения CUBE, из которого исключены промежуточные итоги и общий суммирующий итог.
Описанные расширения конструкции GROUP BY позволяют легко сформировать необходимые итоги, не прибегая к использованию подзапросов и облегчая код.
Как использовать предложение GROUP BY в PostgreSQL
Предложение GROUP BY в PostgreSQL используется совместно с оператором SELECT для группировки нескольких элементов. Он используется для группировки нескольких строк, имеющих идентичные/соответствующие данные, возвращаемые оператором SELECT. В большинстве случаев предложение GROUP BY используется для устранения избыточности и вычисления агрегатов. Предложение GROUP BY можно использовать с различными функциями, такими как SUM() и COUNT() и т. д., для выполнения различных функций над элементами группы.
Как использовать предложение GROUP BY в Postgres?
Мы можем определить отдельный или несколько столбцов в предложении Postgres GROUP BY. Следуйте синтаксису с разделителями-запятыми, чтобы указать несколько столбцов в предложении GROUP BY:
SELECT list_of_columns ОТ tab_name GROUP BY col_1, col_2....col_N
Давайте пошагово проиллюстрируем приведенный выше синтаксис:
● В операторе SELECT укажите список столбцов, которые вы хотите сгруппировать.
● tab_name — это таблица, которой принадлежат выбранные столбцы.
● col_1, col_2, …, col_N представляют столбцы, которые необходимо сгруппировать.
Вы можете следовать следующей иерархии, чтобы указать различные предложения оператора SELECT, такие как WHERE, ORDER BY и т. д.
— Предложение FROM и предложение WHERE будут стоять перед предложением GROUP BY.
— Предложения HAVING, DISTINCT, ORDER BY и LIMIT будут следовать после предложения GROUP BY.
Давайте приступим к практической реализации предложения Postgres GROUP BY:
Пример 1: базовый пример предложения GROUP BY
Уже создана таблица с именем «bike_details», которая содержит следующие записи:
Выберите * из bike_details;
Приведенный ниже запрос получит запись выбранной таблицы и сгруппирует результат на основе bike_model:
SELECT bike_model FROM bike_details СГРУППИРОВАТЬ ПО bike_model;
Выходные данные показывают, что предложение GROUP BY устранило повторяющиеся/избыточные записи.
Пример 2. Как использовать предложение Postgres GROUP BY вместе с SUM()?
Давайте запустим приведенный ниже запрос, чтобы найти сумму элементов группы, используя функцию SUM():
SELECT bike_model, SUM (bike_price) ОТ bike_details СГРУППИРОВАТЬ ПО bike_model;
В этом примере мы использовали предложение GROUP BY для группировки велосипедов по их модели. Затем мы использовали агрегатную функцию с именем SUM(), которая вычисляла сумму элементов группы.
Пример 3: Как использовать предложение Postgres GROUP BY вместе с COUNT()?
В этом примере мы будем использовать функцию COUNT() для подсчета количества велосипедов, доступных для каждой модели:
SELECT bike_model, COUNT (bike_model) ОТ bike_details СГРУППИРОВАТЬ ПО bike_model;
Выходные данные показывают, что в результирующем наборе есть два велосипеда для моделей 2022 и 2021 годов.
Пример 4. Как работает предложение ORDER BY вместе с предложением GROUP BY?
В Postgres различные предложения оператора SELECT могут использоваться с предложением GROUP BY, например ORDER BY, WHERE и т. д. В этом примере мы будем использовать предложение ORDER BY с предложением GROUP BY для сортировки и группировки bike_model. столбец в порядке убывания:
ВЫБЕРИТЕ модель_байка ОТ bike_details СГРУППИРОВАТЬ ПО bike_model ЗАКАЗАТЬ ПО bike_model DESC;
Вывод подтвердил, что на этот раз GROUP CLAUSE удалил избыточные данные и отсортировал набор результатов в порядке убывания.
Это была вся основная информация о предложении Postgres GROUP BY .
Заключение
Предложение GROUP BY в PostgreSQL используется совместно с оператором SELECT для группировки нескольких элементов. Предложение GROUP BY в большинстве случаев используется для группировки идентичных строк, удаления избыточности и вычисления агрегатов. Для выполнения различных функций над элементами группы предложение GROUP BY можно комбинировать с такими функциями, как SUM() и COUNT(). Кроме того, различные предложения, такие как предложение WHERE, предложение ORDER BY и т. д. В этой статье объясняется работа GROUP BY , рассмотрев несколько примеров.
Предложение GROUP BY в большинстве случаев используется для группировки идентичных строк, удаления избыточности и вычисления агрегатов. Для выполнения различных функций над элементами группы предложение GROUP BY можно комбинировать с такими функциями, как SUM() и COUNT(). Кроме того, различные предложения, такие как предложение WHERE, предложение ORDER BY и т. д. В этой статье объясняется работа GROUP BY , рассмотрев несколько примеров.
Как использовать SQL-предложение «Группировать по» в Google Таблицах
Google Таблицы Группировать по
Группировать по — это мощное предложение в функции ЗАПРОС, которое фактически позволяет дополнительно суммировать большие объемы данных в Google Таблицах. Он использует формат =ЗАПРОС(диапазон,»запрос SQL»)
) и рассчитать их по группам с помощью SQL-подобного языка запросов в Google Таблицах.
Группировка по дате
Наиболее распространенным способом группировки строк записей является их группировка по дате. Для этого добавьте агрегатную функцию, примененную к строке, за которой следует группа с предложением , за которым следует столбец, содержащий дату. Например, у нас есть следующий лист, который включает дату транзакции, купленный товар, цену за товар, количество купленных товаров, результирующий общий объем продаж, стоимость за товар, общую стоимость и прибыль.
Для этого добавьте агрегатную функцию, примененную к строке, за которой следует группа с предложением , за которым следует столбец, содержащий дату. Например, у нас есть следующий лист, который включает дату транзакции, купленный товар, цену за товар, количество купленных товаров, результирующий общий объем продаж, стоимость за товар, общую стоимость и прибыль.
Мы можем рассчитать общую прибыль за день. Для этого мы можем использовать следующий запрос (без кавычек):
«выбрать A, сумма (H) группа по A»
При этом нам нужно будет поместить его в функцию ЗАПРОС Google Таблиц. в формате:
=запрос([диапазон],»[SQL-запрос]'»)
И результат будет выглядеть так:
Довольно аккуратно, правда? Все пять агрегатных функций будут работать в заданном формате. Например, вы также можете рассчитать среднюю прибыль в день, используя следующий запрос (без кавычек):
Например, вы также можете рассчитать среднюю прибыль в день, используя следующий запрос (без кавычек):
«выберите A, avg(H) group by A»
При этом мы должны разместить его в функции QUERY Google Sheets в формате:
=query([range],»[SQL query]'»)
И результат будет выглядеть так:
К сожалению, предложение группировки по не позволяет дополнительно группировать данные по определенному месяцу или году, если данные изначально не содержат определенные строки для месяца или года. Чтобы выполнить эту задачу, вам сначала нужно будет сделать это на исходном листе. Вы можете ознакомиться с последней частью этого руководства , чтобы узнать, как это сделать на исходном листе.
Группировка по номенклатуре
Предложение группировки по также прекрасно работает, если вы хотите сгруппировать заказы по номенклатуре.