Генератор HTML таблиц | Создавайте HTML таблицы с настраиваемыми параметрами!
Powered by aspose.com and aspose.cloud
Попробуйте другие приложения
Настройте свою HTML таблицу!
Вы ищете быстрый и простой способ создания HTML таблицы? Генератор HTML таблиц — это онлайн-приложение для создания таблиц с настраиваемыми параметрами. Этот бесплатный инструмент удобен и понятен в использовании. Просто заполните все необходимые поля таблицы и получите результат!
Создавайте HTML таблицы для веб-сайтов за несколько простых шагов. Вы можете указать количество строк и столбцов и задать другие параметры по своему усмотрению, например, заголовок, рамку, выравнивание. Генератор HTML таблиц автоматически создает HTML код. Этот инструмент был разработан для того, чтобы вы могли получить необходимую таблицу HTML и как можно быстрее разместить ее в Интернете. Просто скопируйте и вставьте сгенерированный HTML код в исходный код вашего сайта.
Бесплатный онлайн Генератор HTML таблиц работает в любом современном браузере, таком как Chrome, Firefox, Edge или Safari. Наше приложение совместимо со всеми устройствами ПК, смартфонами и планшетами. Мы надеемся, что этот инструмент будет полезен для людей, которым нужна таблица для веб-сайта, HTML-документа или блога. Другими словами, для тех, кто просто хочет быстро создать таблицу HTML.
Хотите интегрировать Генератор таблиц HTML в свое приложение? Это очень быстро и просто! Пожалуйста, ознакомьтесь с нашей документацией.
- Быстрый и простой способ создать HTML-таблицу с необходимыми параметрами
- Высокая производительность и высокое качество
- Дружественный интерфейс и простые настройки
- Никаких ограничений, регистрации и установки дополнительного программного обеспечения
- Работает с вашего любимого устройства
Как создать таблицу HTML
- Настройте параметры для создания HTML таблицы. Выберите тип и ширину границы в пикселях, отметьте, нужны ли вам заголовки, установите выравнивание.
- Нажмите кнопку «Создать», чтобы сгенерировать HTML код.
- Вы увидите HTML код таблицы. Нажмите кнопку «Копировать в буфер обмена», получите сгенерированный код и используйте его где угодно.
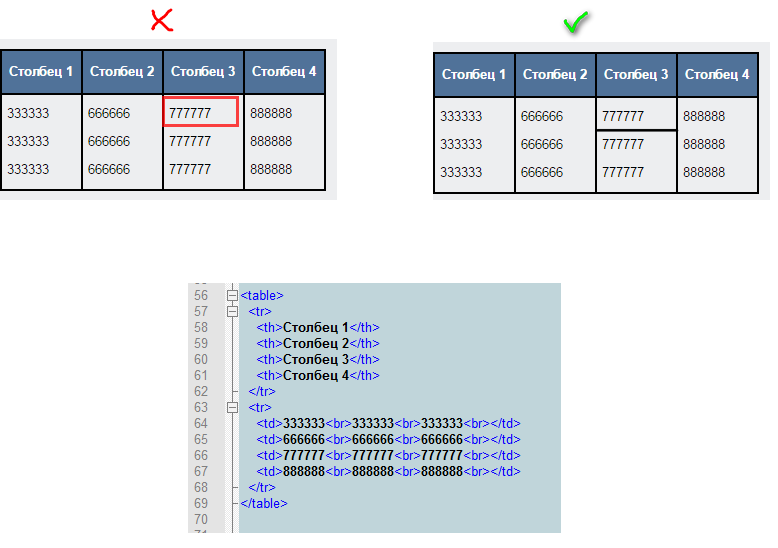 org/HowToStep»>Используя настройки, установите желаемые размеры HTML таблицы. Вы можете указать количество строк и столбцов.
org/HowToStep»>Используя настройки, установите желаемые размеры HTML таблицы. Вы можете указать количество строк и столбцов.ЧАСТО ЗАДАВАЕМЫЕ ВОПРОСЫ
- Как создать таблицу HTML?Чтобы создать таблицу, вам нужно выбрать количество строк и столбцов, установить другие параметры по своему усмотрению, например, ширину, заголовок, границу, выравнивание.
 Нажмите кнопку «Создать». Вы увидите HTML код в текстовой области. Нажмите кнопку «Копировать в буфер обмена» и получите сгенерированный HTML код.
Нажмите кнопку «Создать». Вы увидите HTML код в текстовой области. Нажмите кнопку «Копировать в буфер обмена» и получите сгенерированный HTML код. - Сколько времени нужно для создания HTML таблицы?Это приложение работает быстро. Вы можете создать HTML код для таблицы с необходимыми параметрами за несколько секунд.
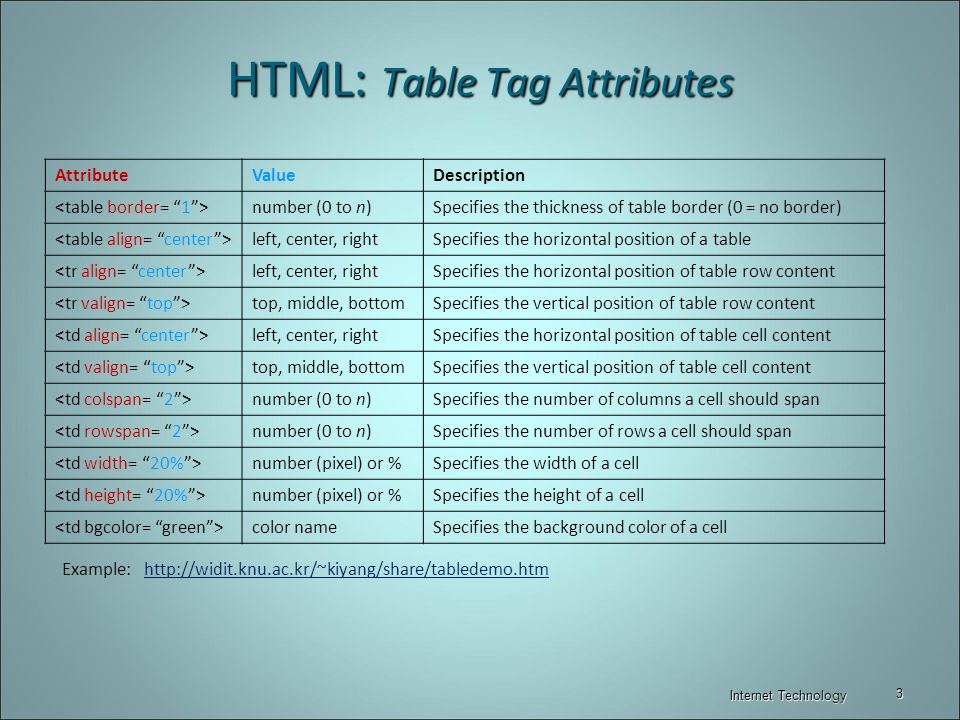
- Зачем использовать HTML таблицы?HTML таблицы часто используются на веб-сайтах и идеально подходят для отображения табличных данных, таких как текст, изображения, ссылки и т. д. Таблица — отличный способ разместить и показать финансовые данные, цены, сравнение функций, результаты спортивных игр и многое другое.
- Могу ли я создавать таблицы HTML в Linux, Mac OS или Android?Вы можете использовать наше бесплатное приложение в любой операционной системе с веб-браузером. Этот инструмент работает онлайн и не требует установки дополнительного программного обеспечения.
 Нажмите кнопку «Создать». Вы увидите HTML код в текстовой области. Нажмите кнопку «Копировать в буфер обмена» и получите сгенерированный HTML код.
Нажмите кнопку «Создать». Вы увидите HTML код в текстовой области. Нажмите кнопку «Копировать в буфер обмена» и получите сгенерированный HTML код. Этот инструмент работает онлайн и не требует установки дополнительного программного обеспечения.
Этот инструмент работает онлайн и не требует установки дополнительного программного обеспечения.Быстрый и простой Генератор HTML таблиц
Задайте желаемый размер таблицы и укажите дополнительные настройки в отведенных полях. Нажмите кнопку «Создать». Вы можете увидеть HTML-код в текстовой области. Нажмите кнопку «Копировать в буфер обмена» и получите HTML код.Создание HTML кода с любого устройства
Приложение работает на всех платформах, включая Windows, Linux, Mac Os, Android и iOS. Все файлы обрабатываются на наших серверах. Вам не требуется установка плагинов или программного обеспечения.Качество создания HTML таблиц
Все данные обрабатываются с использованием API Aspose, которые хорошо зарекомендовали себя в индустрии программного обеспечения и используются многими компаниями из списка Fortune 100 в 114 странах.
Как сделать таблицу html быстро и красиво
Иногда при размещении контента на сайт возникает потребность разместить в содержимом табличные данные.
Писать «вручную» html-код для таблицы — довольно хлопотное занятие, а использование «конвертации» из Excel или Word в html дает довольно избыточный код.
В статье приведены 2 способа как в WordPress сделать таблицу html и быстро, и просто.
1. Сервис Tables Generator
Для создания красивой html-таблицы можно использовать сервис Tables Generator
Чтобы получить html-код таблицы для публикации в статье я использую следующий порядок действий.
1. Сперва подготавливаю исходную таблицу в MS Excel и экспортирую ее окончательный вариант в файл с расширением .csv.
2. Далее загружаю файл с расширением .csv в Tables Generator
3. Потом, при необходимости, редактирую загруженную таблицу уже в самом Tables Generator. В сервисе есть достаточный набор инструментов плюс есть готовые шаблоны представления таблиц.
4. Заключительный момент — генерация html-кода таблицы. Нажав кнопку «Generate» ниже в окне получаю html-код таблицы, который можно скопировать и вставить в содержимое сайта.
Код может быть с встроенными стилями, без стилей, а также в компактном виде (одной строкой). Я использую код без CSS, если использую свои стили на сайте.
s
Недостаток сервиса — размер столбцов таблицы может генерироваться в абсолютных значениях. Это может приводить к некорректному отображению таблицы при изменении размеров окна браузера. И посему в таком случае уже на блоге нужно желать корректировку кода, заменяя абсолютные размеры относительными
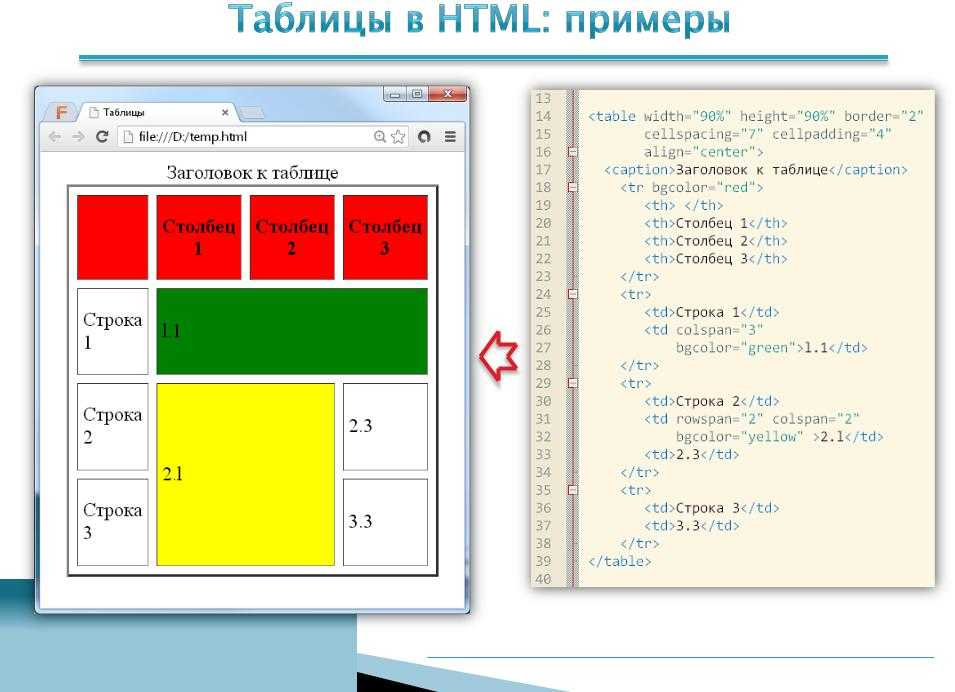
Примеры таблиц, сделанных по такой технологии:
Характеристики насосов ЭЦВ Размеры электродвигателей
Ссылка на Tables Generator
- Tables Generator: http://www.tablesgenerator.com/html_tables
к оглавлению ↑
2. Cоздание таблицы в редакторе Guttenberg
Редактор Гуттнберг стал частью WordPress с конца 2018 года.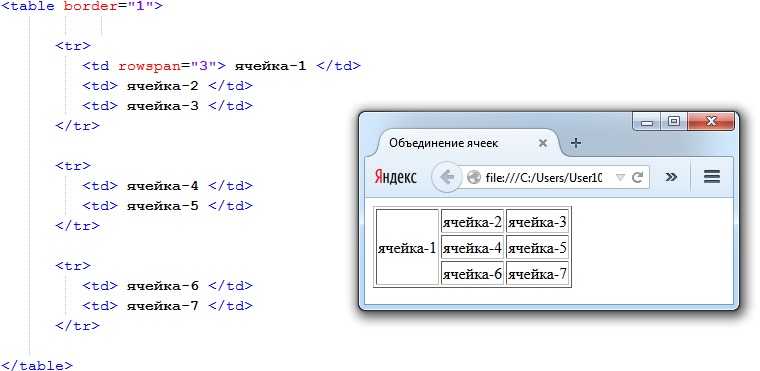
Гуттнберг — блочный редактор. Это значит что контент страницы представлен в виде отдельных блоков.
Среди большого количества блоков есть блок «Таблица». Блок позволяет быстро сделать таблицу html и разместить ее на страницу.
После выбора блока Таблица вам необходимо указать размерность таблицы. В последующем вы можете изменять количество строк и столбцов.
Далее вы заполняете поля таблицы нужными значениями.
После ввода сохраните страницу и таблица будет успешно размещена в содержимом.
Рекомендую курс «Cпособы ввода контента сайта на WordPress», в котором подробно разобрано как работать в блочным редакторе Гуттенберг.
Делитесь в комментариях способами, которые вы используете для быстрого создания html кода таблиц.
Удачи!
Александр Коваль
Рубрики: Сервисы и Хостинг и Полезности Метки: Дизайн сайта
Руководство по созданию HTML-таблицы
Содержание:
Когда вы создаете проект, в котором есть данные для представления, вам нужен хороший способ показать информацию легко и понятно. В зависимости от типа данных вы можете выбирать между различными элементами HTML.
В зависимости от типа данных вы можете выбирать между различными элементами HTML.
Во многих случаях таблица является наиболее удобным способом удобного отображения больших объемов структурированных данных. Вот почему в этой статье я хотел бы объяснить вам структуру таблицы, показать, как ее создать, и дать вам небольшой совет, когда лучше представлять данные в виде таблицы.
Если вы предпочитаете смотреть, а не читать, у меня есть видеоверсия для вас прямо здесь.
Давайте начнем и станем мастером таблиц HTML!
1. Структура таблицы HTML — что внутри?
HTML-таблицы состоят из нескольких элементов, и каждый из этих элементов имеет разные теги.
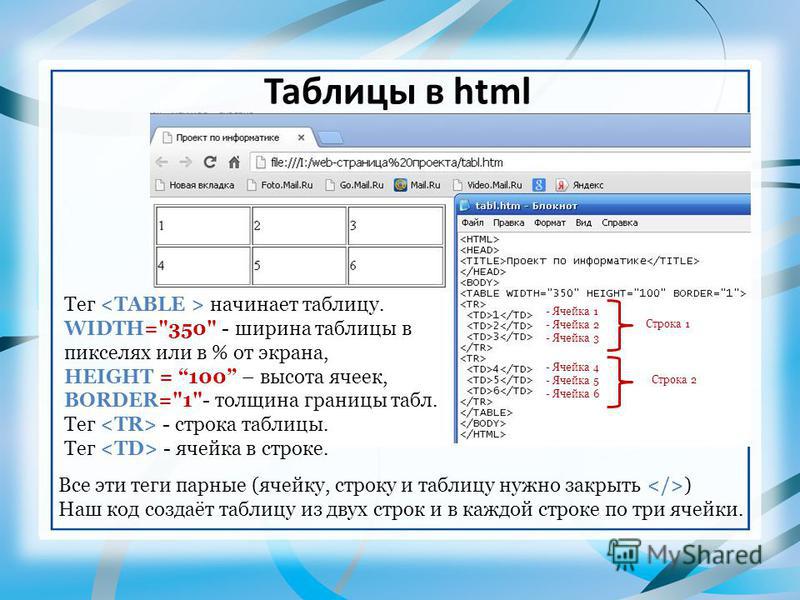
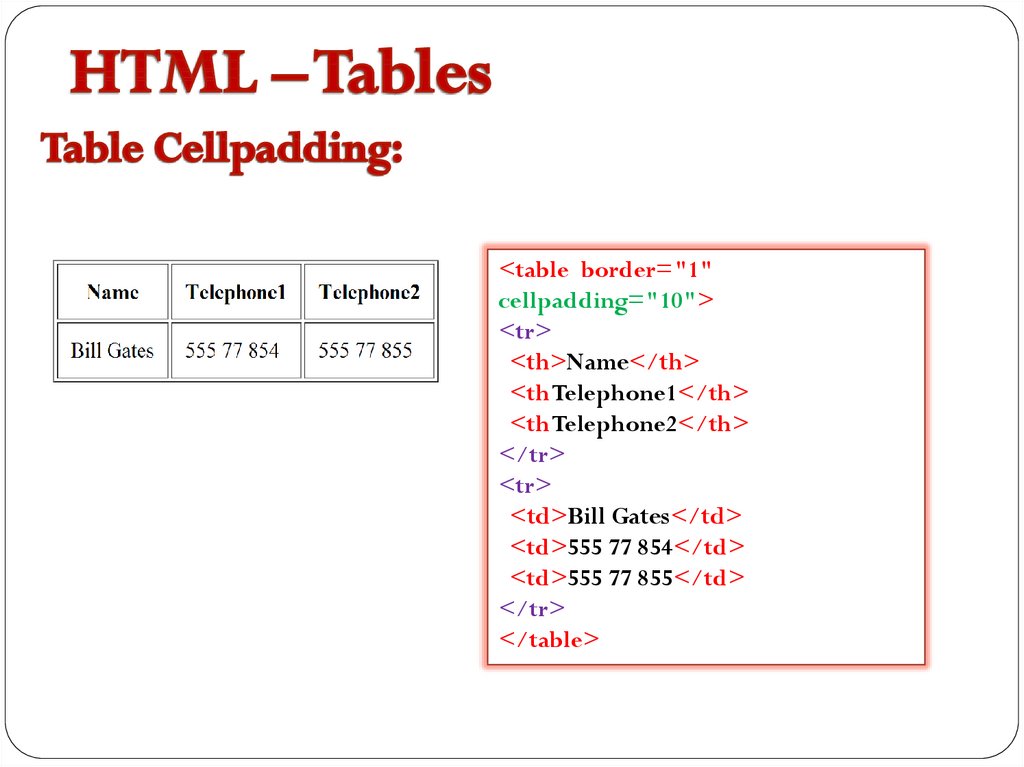
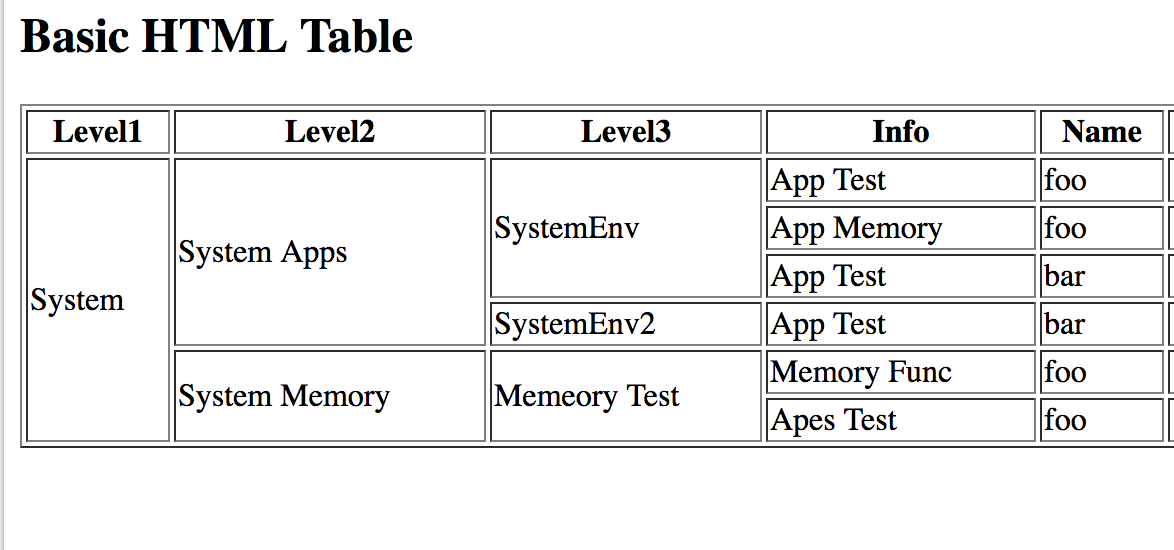
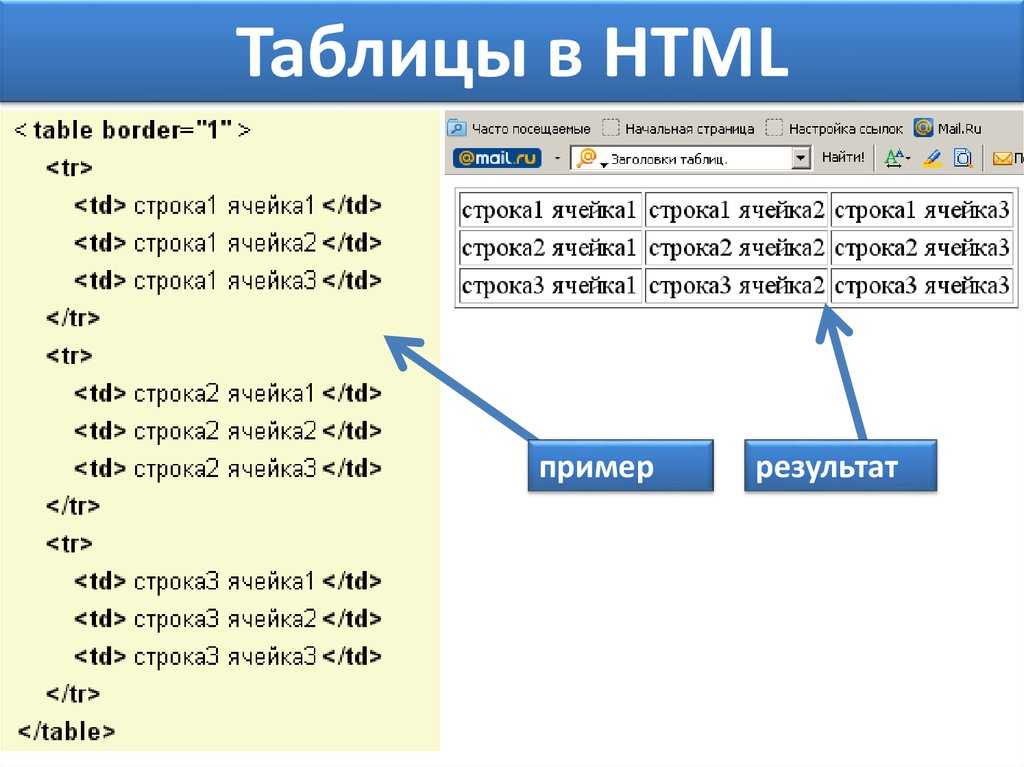
Первый элемент, который вы должны использовать, это На изображении ниже вы можете увидеть, какие элементы являются частью самой простой таблицы. Затем внутри строки нужно создать ячейки, что также можно рассматривать как создание столбцов. Вы можете сделать это, используя два разных тега, в зависимости от потребностей: Давайте рассмотрим короткий пример: Теги, описанные выше, являются лишь основными элементами, которые необходимо использовать для создания HTML-таблицы. Есть еще несколько тегов HTML, которые могут помочь вам создать более сложные таблицы с дополнительными элементами. ярлык; Есть также два специальных атрибута, которые позволяют нам манипулировать ячейкой, это colspan и rowspan. Эти атрибуты принимают числовое значение и позволяют расширить столбец или строку таблицы на другие строки или столбцы. После того, как вы ознакомились со всем, что вам нужно знать о HTML-таблицах, давайте создадим ее. Сначала откройте свой любимый редактор кода и создайте простой файл . Начните создавать простую файловую структуру HTML со структурой таблицы внутри, как в приведенном ниже коде: Теперь у нас есть структура, и пришло время поместить в нее некоторые данные. Давайте создадим заголовок нашей таблицы. Заголовок таблицы подготовлен, поэтому давайте добавим данные в тело нашей таблицы. У нас будет 10 рядов. Теперь тело нашей таблицы готово. Давайте просто добавим элемент Структура таблицы готова, но мы хотим, чтобы наша таблица выглядела красиво, поэтому добавим несколько стилей. Вернемся к И вуаля! Ваша таблица HTML готова. В приведенном выше коде мы создали простую таблицу, используя все структурные элементы. Мы также добавили некоторые стили, чтобы сделать нашу таблицу более удобной и привлекательной. Наша таблица также имеет фиксированный заголовок, поэтому вы можете прокручивать большое количество данных и по-прежнему видеть строку заголовка. Если вы не уверены, когда следует использовать таблицу, а когда нет, взгляните на дату, которую вы должны представить. Если это структуры и табличные данные, которые я использовал выше, то это один из лучших возможных вариантов отображения их в виде таблицы. Помимо чистого представления данных, легко применить удобную фильтрацию и сортировку с помощью таблиц. Но есть одна вещь, которой вам следует избегать, — это построение макета вашего сайта в виде таблицы. Некоторое время назад это был популярный подход, но сейчас у нас есть такие возможности, как flexbox и CSS grid, так что вы можете сделать это намного лучше, сохраняя отзывчивость вашей страницы. HTML-таблицы — отличный способ представить структурированные табличные данные в макете. Его можно создать, используя базовые элементы, такие как Если вам не очень нравится играть с CSS и HTML, вы можете попробовать одну из популярных фреймворков CSS, в которой есть готовые адаптивные таблицы с множеством готовых опций, которые вы можете легко использовать в своих проектах. Но я действительно призываю вас научиться строить его самостоятельно, чтобы знать, как это работает и что вы можете изменить. Спасибо за прочтение, Анна из Duomly Учебное пособие по присоединению к SQL с примерами Как создать информационную панель с помощью учебного пособия Bootstrap Git шпаргалка Анна Данилек Анна Данилек получила высшее образование в области управления бизнесом. Подробнее об Анне Данилец Если вам понравилось, поделитесь и прокомментируйте! Табличные данные — один из лучших источников данных в Интернете. Они могут хранить огромное количество полезной информации, не теряя ее удобного для чтения формата, что делает их золотыми приисками для проектов, связанных с данными. Будь то парсинг футбольных данных или извлечение данных фондового рынка, мы можем использовать Python для быстрого доступа, анализа и извлечения данных из HTML-таблиц благодаря Requests и Beautiful Soup. Кроме того, в конце у нас есть для вас небольшой черно-белый сюрприз, так что продолжайте читать! Визуально таблица HTML представляет собой набор строк и столбцов, отображающих информацию в табличном формате. Для этого урока мы будем очищать приведенную выше таблицу: Чтобы иметь возможность очищать данные, содержащиеся в этой таблице, нам нужно немного углубиться в ее кодирование. Вообще говоря, таблицы HTML создаются с использованием следующих тегов HTML: Однако, как мы увидим в реальных сценариях, не все разработчики соблюдают эти соглашения при создании своих таблиц, что проекты сложнее, чем другие. Давайте введем URL-адрес таблицы (https://datatables.net/examples/styling/stripe.html) в наш браузер и проверим страницу, чтобы увидеть, что происходит внутри. Вот почему это отличная страница для практики очистки табличных данных с помощью Python. Есть четкая пара тегов Еще несколько вещей, которые нужно знать об этой таблице: в ней всего 57 записей, которые мы хотим очистить, и, кажется, есть два решения для доступа к данным. Первый — щелкнуть раскрывающееся меню и выбрать «100», чтобы отобразить все записи: Или нажать кнопку «Далее», чтобы перейти по нумерации страниц. Так кто же будет? Любое из этих решений усложнит наш сценарий, поэтому вместо этого давайте сначала проверим, откуда берутся данные. Конечно, поскольку это таблица HTML, все данные должны быть в самом файле HTML без необходимости внедрения AJAX. Чтобы убедиться в этом, Щелкните правой кнопкой мыши > Просмотр исходного кода страницы . Затем скопируйте несколько ячеек и найдите их в исходном коде. Мы сделали то же самое еще для пары записей из разных ячеек с разбивкой на страницы, и да, кажется, что все наши целевые данные находятся там, хотя внешний интерфейс их не отображает. И с этой информацией мы готовы перейти к коду! Поскольку все данные о сотрудниках, которые мы хотим очистить, находятся в файле HTML, мы можем использовать библиотеку Requests для отправки HTTP-запроса и анализа ответа с помощью Beautiful Soup. Примечание: Если вы новичок в парсинге веб-страниц, мы создали руководство по парсингу веб-страниц в Python для начинающих. Хотя вы сможете следовать без опыта, всегда полезно начинать с основ. Давайте создадим новый каталог для проекта с именем python-html-table , затем новую папку с именем bs4-table-scraper и, наконец, создадим новый файл python_table_scraper.py .54 Из терминала , давайте Чтобы отправить HTTP-запросы с запросами, все, что нам нужно сделать, это установить URL-адрес и передать это через request.get(), сохраните возвращенный HTML внутри переменной ответа и распечатайте response.status_code. Примечание. Если вы новичок в Python, вы можете запустить свой код из терминала с помощью команды python3 python_table_scraper.py. response = request.get(url) print(response.status_code) Если он работает, он вернет код состояния 200. ScraperAPI — это элегантное решение, позволяющее избежать применения практически любых методов защиты от очистки данных. Он использует машинное обучение и многолетний статистический анализ для определения лучших комбинаций заголовков и IP-адресов для доступа к данным, обработки CAPTCHA и ротации вашего IP-адреса между каждым запросом. Для начала давайте создадим новую бесплатную учетную запись ScraperAPI, чтобы активировать 5000 бесплатных API и наш ключ API. С панели управления нашей учетной записи мы можем скопировать значение нашего ключа, чтобы создать URL-адрес запроса. Следуя этой структуре, мы заменяем держатели нашими данными и снова отправляем наш запрос : url = 'http://api.scraperapi.com?api_key=51e43be283e4db2a5afbxxxxxxxxxxxx&url=https:/ /datatables.net/examples/styling/stripe.html' response = request.get(url) print(response.status_code) Отлично, все работает без сбоев! Прежде чем мы сможем извлечь данные, нам нужно преобразовать необработанный HTML в отформатированные или проанализированные данные. Мы сохраним этот проанализированный HTML-код в объекте супа следующим образом: Отсюда мы можем перемещаться по дереву анализа, используя теги HTML и их атрибуты. Если мы вернемся к таблице на странице, мы уже увидим, что таблица заключена между Примечание: После тестирования добавление второго класса (dataTable) не вернуло элемент. На самом деле в возвращаемых элементах классом таблицы является только страйп. Вы также можете использовать id = «пример». Вот что он возвращает: Теперь, когда мы захватили таблицу, мы можем пройтись по строкам и получить нужные данные. Возвращаясь к структуре таблицы, каждая строка представлена элементом Чтобы извлечь данные, мы создадим два для просмотра, один для захвата раздела В строках мы будем хранить все Для начала попробуем выбрать имя первого сотрудника в консоли нашего браузера с помощью метода .querySelectorAll(). Действительно полезная особенность этого метода заключается в том, что мы можем углубляться в иерархию, реализуя символ больше, чем (>), чтобы определить родительский элемент (слева) и дочерний элемент, которого мы хотим захватить (справа). Лучше и быть не может. Как видите, как только мы захватим все элементы Оттуда мы можем написать наш код следующим образом: Проще говоря, мы берем каждую строку, одну за другой, и находим все ячейки внутри, как только у нас есть список, мы берем только первую в индексе (позиция 0) и заканчиваем с помощью метода .text чтобы захватить только текст элемента, игнорируя данные HTML, которые нам не нужны. Вот они, список всех имен сотрудников! В остальном мы просто следуем той же логике: Однако печать всех этих данных на нашей консоли не очень полезна. Вместо этого давайте сохраним эти данные в новом, более удобном формате. Хотя мы могли бы легко создать файл CSV и отправить туда наши данные, это был бы не самый удобный формат, если бы мы могли создать что-то новое, используя очищенные данные. Тем не менее, вот проект, который мы сделали несколько месяцев назад, объясняя, как создать файл CSV для хранения очищенных данных. Хорошая новость заключается в том, что в Python есть собственный модуль JSON для работы с объектами JSON, поэтому нам не нужно ничего устанавливать, просто импортируйте его. Но прежде чем мы сможем продолжить и создать наш файл JSON, нам нужно превратить все эти очищенные данные в список. Для этого мы создадим пустой массив вне нашего цикла. А затем добавить к нему данные, при этом каждый цикл добавляет в массив новый объект. Если мы Все еще немного беспорядочно, но у нас есть набор объектов, готовых для преобразования в JSON. Примечание: В качестве теста мы напечатали длину Для импорта списка в JSON достаточно двух строк кода: Если вы следили за этим, ваша кодовая база должна выглядеть так: url = 'http://api. #пустой массив #запрос и анализ файла HTML #выбор таблицы Примечание: Мы добавили несколько комментариев для контекста. А вот первые три объекта из файла JSON: Хранение очищенных данных в формате JSON позволяет нам перепрофилировать информацию для новых приложений или Прежде чем покинуть страницу , мы хотим изучить второй подход к очистке HTML-таблиц. В нескольких строках кода мы можем извлечь все табличные данные из HTML-документа и сохранить их в фрейме данных с помощью Pandas. Создайте новую папку внутри каталога проекта (мы назвали ее pandas-html-table-scraper) и создайте новое имя файла pandas_table_scraper.py. Давайте откроем новый терминал и перейдем к только что созданной папке (cd pandas-html-table-scraper) и оттуда установим pandas: И мы импортируем его в начало файла. Pandas имеет функцию read_html(), которая в основном очищает целевой URL-адрес для нас и возвращает все таблицы HTML в виде списка объектов DataFrame. Однако для того, чтобы это работало, таблица HTML должна быть структурирована по крайней мере несколько прилично, так как функция будет искать такие элементы, как Чтобы использовать эту функцию, давайте создадим новую переменную и передадим ей URL-адрес, который мы использовали ранее: /datatables.net/examples/styling/stripe.html’) При печати он возвращает список таблиц HTML на странице. Если мы сравним первые три строки в DataFrame, они идеально совпадают с тем, что мы очистили с помощью Beautiful Soup. Для работы с JSON в Pandas есть встроенная функция .to_json(). Он преобразует список объектов DataFrame в строку JSON . Все, что нам нужно сделать, это вызвать метод в нашем DataFrame и передать путь, формат (разделение, данные, записи, индекс и т. д.) и добавить отступ, чтобы сделать его более читабельным: Если мы сейчас запустим наш код, вот результирующий файл: Обратите внимание, что нам нужно было выбрать нашу таблицу из индекса ([0]), потому что . тег, который является своего рода контейнером для элементов, формирующих таблицу. И внутри этого контейнера вы должны поместить другие элементы, такие как строки, столбцы или ячейки.

– тег, который нужно сначала создать внутри таблицы. Он используется для построения строки. Его легко запомнить, потому что вы можете думать о tr как о строке таблицы. <й> – возможность создавать ячейки заголовков. – используется для построения простых ячеек, и вы можете поместить столько элементов в строку, сколько пожелаете.
идентификатор
<тд>1

<заголовок> | | позволяет создать более структурированную таблицу, поместив заголовок таблицы в , все элементы тела в , а строки нижнего колонтитула или другую информацию в ; 2. Создание HTML-таблицы с примером кода
 html. Вы можете назвать это, как вы предпочитаете.
html. Вы можете назвать это, как вы предпочитаете.
<голова>
<заголовок>
Идентификатор
Имя
Электронная почта
Номер телефона
<тело>
001
Марк Смит
[email protected]
0034 238 212 123
0034 78 261 231
<тд>002
Марта Коллинз
martha.
 [email protected]
[email protected]0034 726 121 984
<тд>003
Сэм МакНил
[email protected]
0022 081 273 552
004
Сара Пауэлс
[email protected]
0044 019 937 133
005
Петр Ковальский
[email protected]
0022 836 657 342
Джон Доу
[email protected]
0021 384 482 173
007
Энн Флори
[email protected]
<тд>0044 239138 283
008
Мартин Эдвардс
[email protected]
0034 276 693 538
0034 40 5793 963
009
Джуди Малкольм
[email protected]
0021 845 304 287
010
Чарльз Ричардсон
richardsonch@outlook.
<тд>0044 856 248 329
 com
com tfoot :
Общее количество клиентов: 10
style в разделе head HTML-файла и поместим следующий код: тело {
маржа: 0;
набивка: 2рем;
}
.tablecontainer {
максимальная высота: 250 пикселей;
переполнение: авто;
}
стол {
выравнивание текста: по левому краю;
положение: родственник;
граница коллапса: коллапс;
цвет фона: #f6f6f6;
}
й, тд {
набивка: 0,5 см;
}
й {
фон: #ffc107;
белый цвет;
радиус границы: 0;
положение: липкое;
сверху: 0;
отступ: 10 пикселей;
}
тд {
граница: 1px сплошной белый;
box-sizing: граница-коробка;
}
tfoot > тр {
фон: черный;
белый цвет;
}
tbody > тр:наведите {
цвет фона: #ffc107;
}  Вы должны получить результат, как на изображении ниже:
Вы должны получить результат, как на изображении ниже: 3. Когда следует использовать HTML-таблицы в проекте
Заключение
,
и , но у вас также есть возможность поэкспериментировать с этим, добавить еще несколько функций и построить правильную структуру. 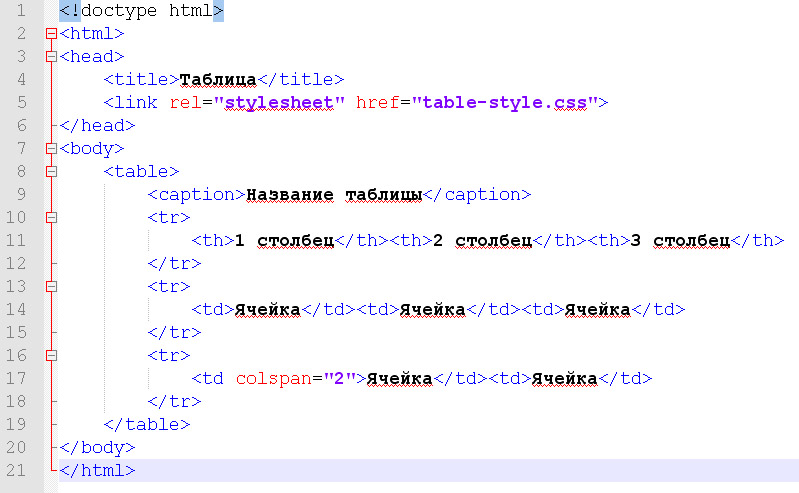 В течение многих лет она получала солидный опыт во фронтенд- и бэкенд-разработке, создавая программное обеспечение для известных ИТ-компаний.
Ее опыт в области ИТ — это React.JS, Angular, React Native, Flutter, Node.JS и Nest.JS.
В последние годы она вела бизнес для Duomly, уделяя особое внимание ИТ, а также онлайн-маркетингу, дизайну и созданию контента, например, ведению блогов и YouTube. В нерабочее время Анна ведет свой настоящий криминальный канал на YouTube, любит спорт, солнце и средиземноморскую кухню.
В течение многих лет она получала солидный опыт во фронтенд- и бэкенд-разработке, создавая программное обеспечение для известных ИТ-компаний.
Ее опыт в области ИТ — это React.JS, Angular, React Native, Flutter, Node.JS и Nest.JS.
В последние годы она вела бизнес для Duomly, уделяя особое внимание ИТ, а также онлайн-маркетингу, дизайну и созданию контента, например, ведению блогов и YouTube. В нерабочее время Анна ведет свой настоящий криминальный канал на YouTube, любит спорт, солнце и средиземноморскую кухню. Полное руководство по извлечению HTML-таблиц с использованием Python
Понимание структуры таблицы HTML
: отмечает начало таблицы HTML
или: определяет строку как заголовок таблицы : определяет ячейку в таблице 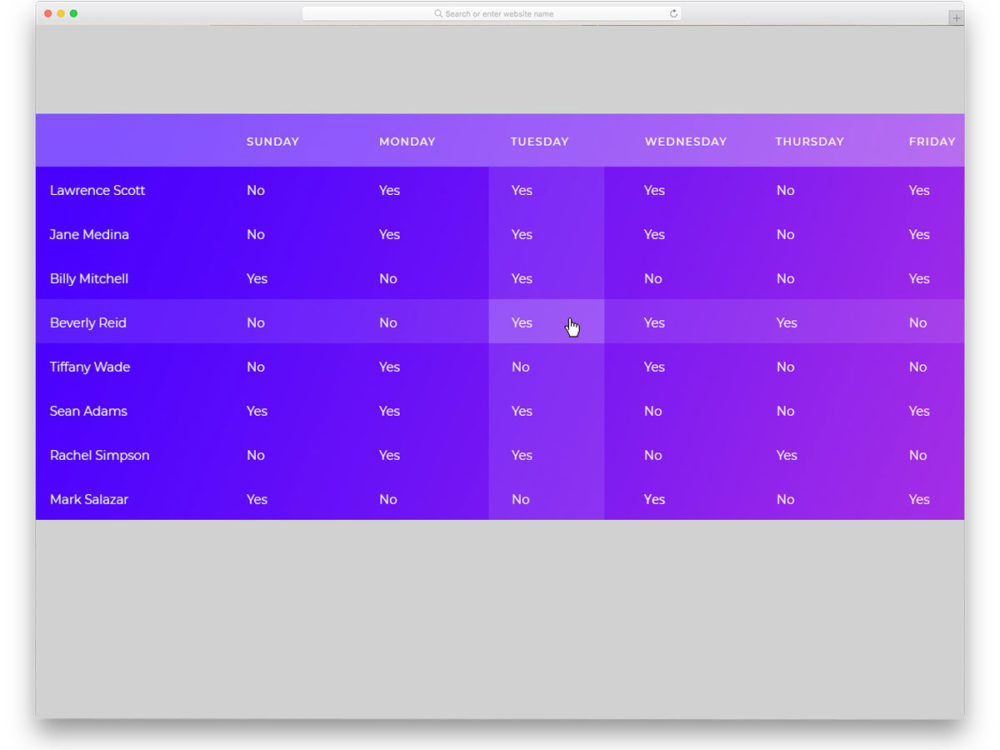 Тем не менее, понимание того, как они работают, имеет решающее значение для поиска правильного подхода.
Тем не менее, понимание того, как они работают, имеет решающее значение для поиска правильного подхода., открывающая и закрывающая таблицу, и все соответствующие данные находятся внутри тега. Он показывает только десять строк, что соответствует количеству записей, выбранных во внешнем интерфейсе.

Очистка таблиц HTML с помощью Beautiful Soup Python
1. Отправка основного запроса
pip3 установим запросы beautifulsoup4 и импортируем их в наш проект следующим образом: импортировать запросы
из bs4 import BeautifulSoup url = 'https://datatables.net/examples/styling/stripe.html'
 Все остальное означает, что ваш IP-адрес отклоняется системами защиты от парсинга, установленными на веб-сайте. Потенциальным решением является добавление пользовательских заголовков в ваш сценарий, чтобы он выглядел более человечно, но этого может быть недостаточно. Другим решением является использование API парсинга веб-страниц, чтобы справиться со всеми этими сложностями за вас.
Все остальное означает, что ваш IP-адрес отклоняется системами защиты от парсинга, установленными на веб-сайте. Потенциальным решением является добавление пользовательских заголовков в ваш сценарий, чтобы он выглядел более человечно, но этого может быть недостаточно. Другим решением является использование API парсинга веб-страниц, чтобы справиться со всеми этими сложностями за вас. 2. Интеграция ScraperAPI для предотвращения использования систем защиты от очистки данных
http://api.scraperapi.com?api_key={Your_API_KEY}&amp;amp;url={TARGET_URL} запросов на импорт
от bs4 import BeautifulSoup 3. Создание синтаксического анализатора с помощью Beautiful Soup
суп = BeautifulSoup(response.text, 'html.parser')

тегов с полосой класса
dataTable , которую мы можем использовать для выбора таблицы. table = sup.find('table', class_ = 'stripe')
print(table) 4. Циклический просмотр HTML-таблицы
, а внутри них есть элемент , содержащий данные, все это заключено между пара тегов . таблицы (где находятся все строки), а другой для хранения всех строк в переменной, которую мы можем использовать: для employee_data в table.
 find_all('tbody'):
find_all('tbody'):
rows = employee_data.find_all('tr')
print(rows) В основной части таблицы найдено элементов. Если вы следуете нашей логике, следующим шагом будет сохранение каждой отдельной строки в одном объекте и циклический просмотр их для поиска нужных данных. document.querySelectorAll('table.stripe &amp;gt; tbody &amp;gt; tr &amp;gt; td')[0] , они станут нодлистом. Поскольку мы не можем полагаться на то, что класс будет захватывать каждую ячейку, все, что нам нужно знать, это их положение в индексе, а первое, имя, равно 0. 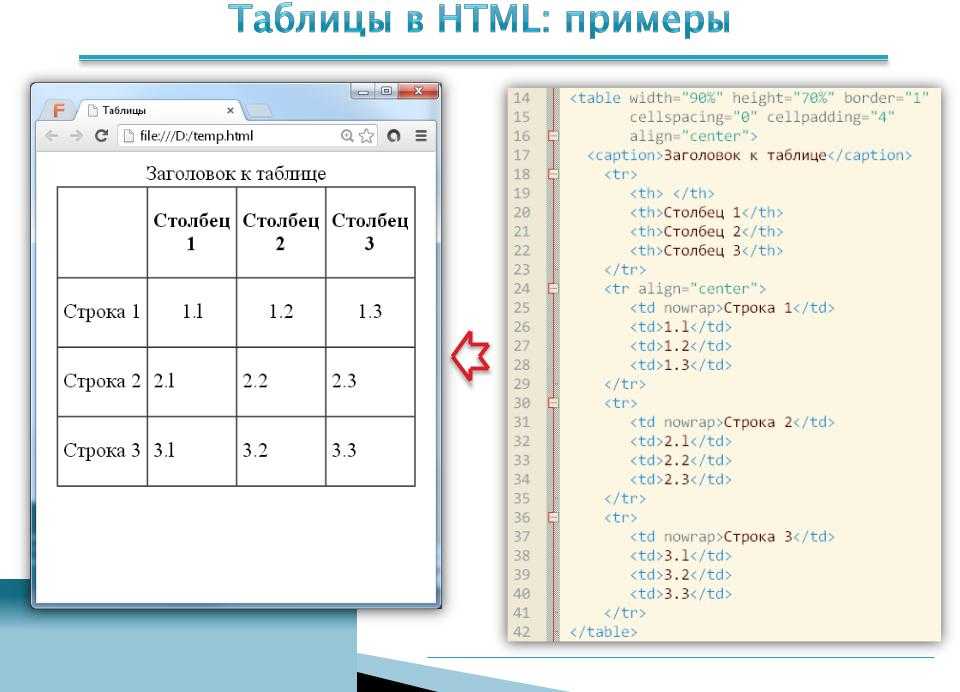
для строки в строках:
name = row.find_all('td')[0].text
print(name) position = row.find_all('td')[1].text
office = row.find_all('td')[2].text
age = row.find_all('td')[3].text
start_date = row.find_all('td')[4].text
salary = row.find_all('td')[ 5].текст 5. Хранение табличных данных в файле JSON
import json
employee_list = []
employee_list.append({
'Имя': имя,
'Должность': должность,
'Офис': должность,
'Возраст': возраст,
>'Дата начала': start_date,
'зарплата': зарплата
})
print(employee_list) , вот результат:
employee_list и вернули 57, что является правильным количеством строк, которые мы очистили (строки теперь являются объектами в массиве). с open('json_data', 'w') as json_file:
json.dump(employee_list, json_file, indent=2) (json_data) , и «w», поскольку мы хотим записать в него данные. .dump() для вывода данных из массива ( employee_list ) и indent=2 поэтому каждый объект имеет свою собственную строку, а не все в одну нечитаемую строку. 6. Запуск скрипта и полный код
#dependencies
запросы на импорт
от bs4 import BeautifulSoup
import json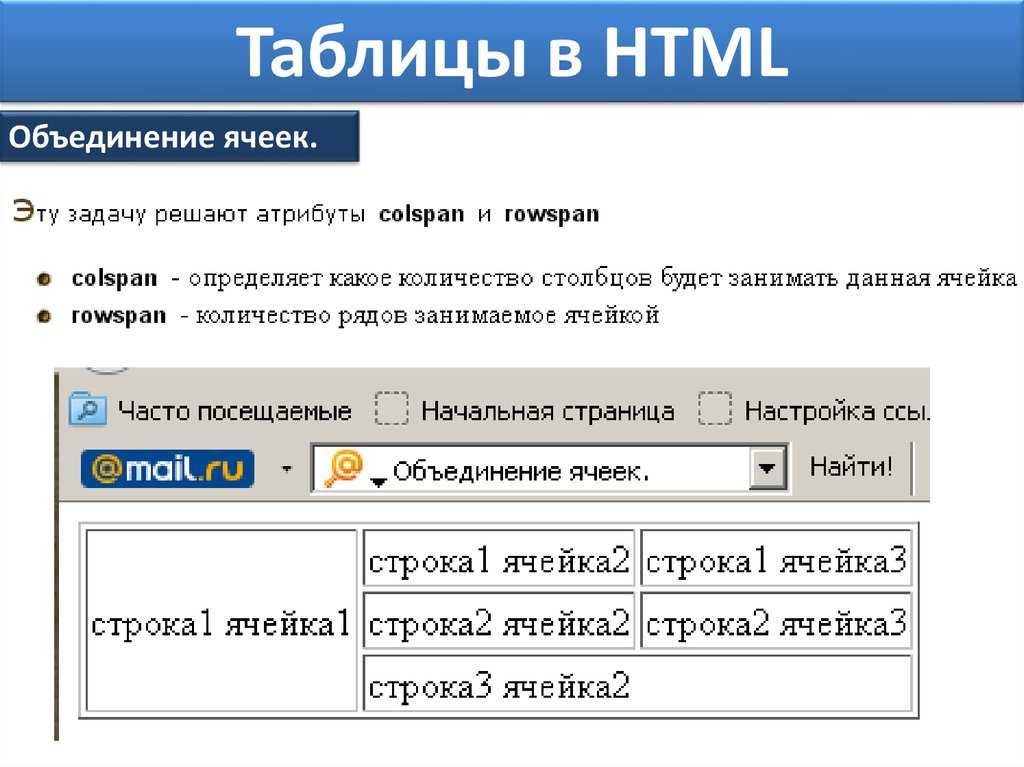 scraperapi .com?api_key=51e43be283e4db2a5afbxxxxxxxxxxx&url=https://datatables.net/examples/styling/stripe.html'
scraperapi .com?api_key=51e43be283e4db2a5afbxxxxxxxxxxx&url=https://datatables.net/examples/styling/stripe.html'
employee_list = []
response = request.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
table = sup.find('table', class_ = 'stripe')
#сохранение всех строк в одну переменную
для employee_data в table.find_all('tbody'):
rows = employee_data.find_all('tr')
#перебор HTML-таблицы для извлечения данных
для строк в строках:
name = row.find_all('td')[0]. text
position = row.find_all('td')[1].text
office = row.find_all('td')[2].text
age = row.find_all(' td')[3].text
start_date = row.find_all('td')[4].text
salary = row.find_all('td')[5].tex t
#отправка очищенных данных в пустой массив
employee_list.append({
'Имя': имя,
'Должность': должность,
'Офис': office,
'Возраст': age,
'Дата начала': start_date,
'salary': зарплата
})
#импорт массива в файл JSON
с open('employee_data', 'w') as json_file:
json.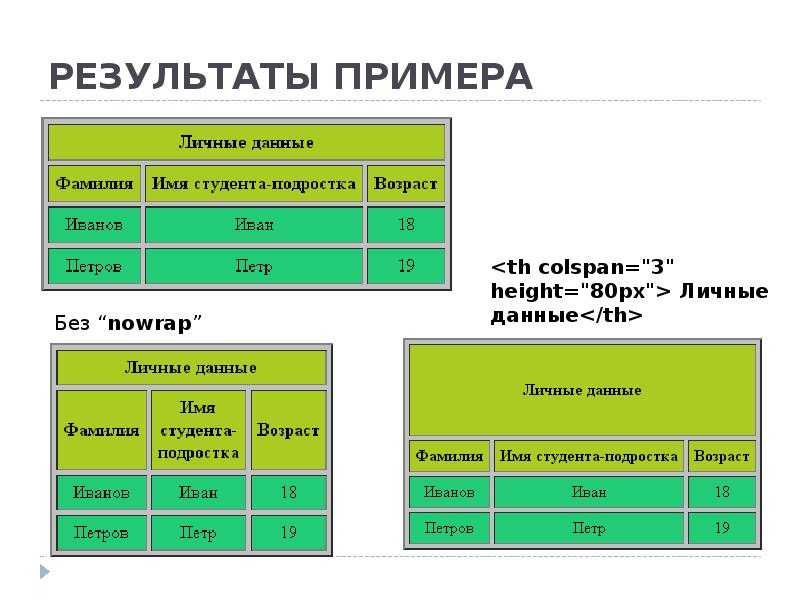 dump(employee_list, json_file, indent=2)
dump(employee_list, json_file, indent=2) Очистка HTML-таблиц с помощью Pandas
pip install pandas
import pandas as pd
, чтобы идентифицировать таблицы в файле.
employee_data[0].to_json('./employee_list.json', orient='index', indent=2) 