Присоединяйтесь к широкому международному сообществу креативных людей, пользующихся Cliparto каждый день. чтобы покупать или продавать изображения.
| ◢ Мой Cliparto › ЛайтБокс (0)
Не помните пароль / логин? ◢ Впервые у нас? Зарегистрируйтесь ◢ Есть аккаунт на Vector-Images. Не нужно регистрироваться заново. Просто используйте свой логин и на Cliparto. › Недавно просмотрено
|
||||||||||||||||
 Изображения предоставлятся по Royalty-Free лицензиям. Наши Условия использования сервисов разрешают использование изображений для широкого спектра услуг, товаров и отраслей, где изображения, приобретенные через Cliparto будут работать на Вас.
Изображения предоставлятся по Royalty-Free лицензиям. Наши Условия использования сервисов разрешают использование изображений для широкого спектра услуг, товаров и отраслей, где изображения, приобретенные через Cliparto будут работать на Вас.
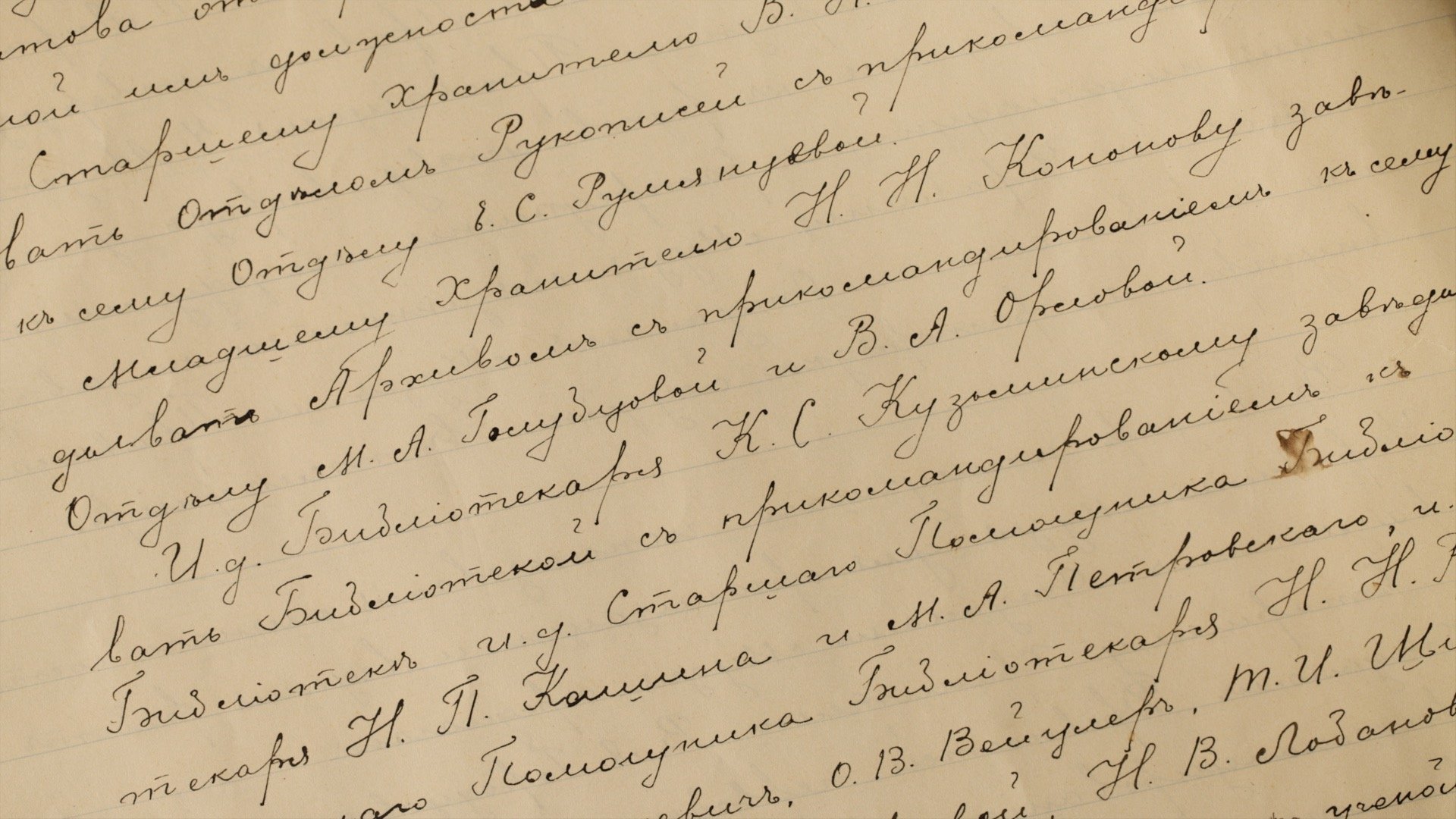

Как нейросети переводят рукописный текст в цифровой формат
Как программы распознавания документов разбираются в рукописных текстах
Существуют 2 способа распознавания рукописи. В онлайновом буквы выводятся при помощи стилуса и тут же появляются в печатном виде на экране девайса. В офлайновом подразумевается именно распознавание документов: текст уже существует на бумаге и его надо перевести в электронный вид. При этом распознавание текста можно проводить на базе отсканированной копии так и фотографии. Когда вы слышите о программе распознавания документов, всегда подразумевается именно офлайновый метод.
Как выглядит подготовка к процессу распознавания рукописи
Чтобы распознать рукописный текст, программа должна его предварительно обработать. Сначала искусственному интеллекту нужно отделить объект (текст) от фона. Это не всегда бывает просто. Если приходится иметь дело с фотографиями, особенно старыми, фон может быть затемненным. Бумага может содержать загрязнения, пожелтеть от времени и др. Все подобные артефакты осложняют процесс распознавания.
Это не всегда бывает просто. Если приходится иметь дело с фотографиями, особенно старыми, фон может быть затемненным. Бумага может содержать загрязнения, пожелтеть от времени и др. Все подобные артефакты осложняют процесс распознавания.
Если фон сложный, то дополнительно производится так называемое удаление шумов: программа распознает не имеющие смысла элементы и убирает их.
Чем больше наклон букв, тем сложнее оцифровать текст, потому на подготовительном этапе наклон выравнивается.
Далее текст разделяется на строки, затем на слова и в конце концов на отдельные символы.
Документ просто подготовить к распознаванию, если строки прямые и расстояние между словами больше, чем между буквами. В этом случае достаточно элементарной нейросетки. В большинстве же случаев применяются гибридные модели распознавания документов.
Если документ слабо структурирован — строки не прямые, расстояние между словами и буквами варьируется, — применяют более сложные системы с элементами, например, скрытой марковской модели: на основе известных параметров угадываются неизвестные.
Осложнить этап подготовки могут также:
- нестандартный формат и текстура бумажного листа
- размазанные чернила или слабо пропечатанные на печатной машинке буквы
- устаревшие печатные шрифты
- наличие штампов, особенно, если их несколько и они нанесены один поверх другого и др.
Получить консультацию
Распознавание + верификация: что в процессе делают люди
Если рукописный текст содержит сложные символы или элементы, то нейросеть, как правило, справляется не очень хорошо.
На этом этапе к работе необходимо подключать верификаторов — людей, которые работают либо в штате компании/архива, либо нанимать внешних квалифицированных сотрудников, то есть отдать вопрос на аутсорс. Аутсорсинговую верификацию предлагают далеко не все игроки рынка, из-за чего в проектах оцифровки документов, которые содержат рукописные элементы, по факту возникают трудности.
У компании «Биорг» для целей верификации есть собственная краудсорсинговая облачная платформа, где трудоустроены сотрудники, прошедшие специальное обучение. В случае необходимости они получают доступ к отдельным распознаваемым элементам (не целым документам), чтобы корректно ввести нераспознанное значение. На пиковых этапах, когда компания выпоняла большие проекты с колоссальными объёмами документов, на платформе было зарегистрировано более 50 тыс. операторов. Такая методика фирменного двухэтапного распознавания (ИИ+люди) позволяет оцифровать даже самый сложный документ с высокой степенью точности.
В случае необходимости они получают доступ к отдельным распознаваемым элементам (не целым документам), чтобы корректно ввести нераспознанное значение. На пиковых этапах, когда компания выпоняла большие проекты с колоссальными объёмами документов, на платформе было зарегистрировано более 50 тыс. операторов. Такая методика фирменного двухэтапного распознавания (ИИ+люди) позволяет оцифровать даже самый сложный документ с высокой степенью точности.
Верификаторы на платформе, распознавая сложные значения, одновременно дообучают ИИ. В дальнейшем даже сложные тексты можно распознавать намного быстрее, а людей-верификаторов требуется меньше.
Как происходит основной процесс распознавания рукописиВ зависимости от типа текста, применяют разные виды нейросетей. Например, если документ стандартный, его можно распознать при помощи языковой модели: она умеет предсказывать следующее слово по нескольким предшествующим. Особенно хорошо языковая модель работает при распознавании однотипных документов, где встречаются повторяющиеся слова, словосочетания и предложения. Так, если при оцифровке документов ИИ работает с приказами или заявлениями, которые, как правило, составлены по схожим шаблонам, значительную часть документа можно распознать довольно быстро.
Так, если при оцифровке документов ИИ работает с приказами или заявлениями, которые, как правило, составлены по схожим шаблонам, значительную часть документа можно распознать довольно быстро.
Классификатор ИИ может работать как с отдельными словами, так и с целыми строками. Сначала к работе приступают сверточные нейронные сети (СНС). Их главная задача — сформировать карту характерных признаков. Как только каждый элемент изображения проанализирован, СНС приступают к пуллингу: сформированные карты признаков становятся менее подробными, то есть их просто уменьшают в размере.
Дальше к работе приступают рекуррентные нейронные сети (РНС). Их применяют для работы с последовательностями – результат зависит не только от входного слова, но и от всех предыдущих. Эти свойства полезны, чтобы правильно классифицировать элементы текста.
Например, одна из популярных разновидностей РНС — это LSTM-сети: сегодня показывают одни из лучших результатов при работе с рукописями. Но есть также и другие разновидности: IDCN, mdlstm и др.
Перед распознаванием рабочего массива документов нейросеть нужно обязательно обучить на качественно размеченном тестовом наборе данных. Его создают из реальных документов, требующих распознавания. В процессе обучения результат распознавания сверяется с датасетом, в котором хранится множество изображений для каждой буквы, написанной разным почерком. Вычисляется разница межу предсказанным и реальным значением и на этом основании нейросеть обучается (меняются веса в слоях нейросети)
Что входит в постобработку оцифрованного рукописного документаПосле того как текст оцифрован, нейросеть проводит проверку орфографии. Даже если исходный текст содержал ошибки, конечный оцифрованный документ будет представлен в корректном виде.
Иногда в текстах есть специальные термины, которые отсутствуют в стандартных словарях (например, недавно появившиеся аббревиатуры или узкоспециализированные термины). В этом случае ИИ дополнительно обучается их распознавать. Очень часто именно на этапе постобработки выявляются разные буквы, которые человек написал одинаково (например, буквы «у» и «д» или цифру «3» и заглавную букву «З»).
Постобработка может значительно улучшить качество оцифрованного документа (на 10 % и более).
Если после автоматической постобработки точность распознавания все еще ниже изначально установленной, документ отправляется на верификацию через краудсорсинговую платформу. Люди уточняют распознанные ИИ данные. Таким образом, можно переводить в электронный вид даже очень важные документы, оцифровка которых связана с серьёзной степенью ответственности. Это могут быть чертежи, формулы, древние рукописи. Когда в процессе участвуют и искусственный интеллект, и люди, это дает надежность распознавания на уровне 100 %.
Получить презентацию
25.04.2023
Текстура фона рукописного текста роялти бесплатно вектор
Текстура фона рукописного текста роялти бесплатно векторы- лицензионные векторы
 org/ListItem»> текстуры векторов
org/ListItem»> текстуры векторов
ЛицензияПодробнее
Стандарт Вы можете использовать вектор в личных и коммерческих целях. Расширенный Вы можете использовать вектор на предметах для перепродажи и печати по требованию.Тип лицензии определяет, как вы можете использовать этот образ.
| Станд. | ||
|---|---|---|
| Печатный/редакционный | ||
| Графический дизайн | ||
| Веб-дизайн | ||
| Социальные сети | ||
| Редактировать и изменить | ||
| Многопользовательский | ||
| Предметы перепродажи | ||
| Печать по запросу |
Владение Узнать больше
Эксклюзивный Если вы хотите купить исключительно этот вектор, отправьте художнику запрос ниже: Хотите, чтобы это векторное изображение было только у вас? Эксклюзивный выкуп обеспечивает все права этого вектора.
Мы удалим этот вектор из нашей библиотеки, а художник прекратит продажу работ.
Способы покупкиСравнить
Плата за изображение $ 14,99 Кредиты $ 1,00 Подписка 9 долларов0082 0,69Оплатить стандартные лицензии можно тремя способами. Цены составляют $ $.
| Оплата с помощью | Цена изображения |
|---|---|
| Плата за изображение $ 14,99 Одноразовый платеж | |
| Предоплаченные кредиты $ 1 Загружайте изображения по запросу (1 кредит = 1 доллар США). Минимальная покупка 30р. | |
| План подписки От 69 центов Выберите месячный план. Неиспользованные загрузки автоматически переносятся на следующий месяц. | |
Способы покупкиСравнить
Плата за изображение $ 39,99 Кредиты $ 30,00 Существует два способа оплаты расширенных лицензий. Цены составляют $ $.
Цены составляют $ $.
| Оплата с помощью | Цена за изображение |
|---|---|
| Плата за изображение $ 39,99 Оплата разовая, регистрация не требуется. | |
| Предоплаченные кредиты $ 30 Загружайте изображения по запросу (1 кредит = 1 доллар США). | |
Оплата
Плата за изображение $ 399Дополнительные услугиПодробнее
Настроить изображение Доступно только с оплатой за изображение 9 долларов0082 85,00Нравится изображение, но нужно всего лишь несколько модификаций? Пусть наши талантливые художники сделают всю работу за вас!
Мы свяжем вас с дизайнером, который сможет внести изменения и отправить вам изображение в выбранном вами формате.
Примеры
- Изменить текст
- Изменить цвета
- Изменить размер до новых размеров
- Включить логотип или символ
- Добавьте название своей компании или компании
Включенные файлы
Подробности загрузки. ..
..
- Идентификатор изображения
- 13504509
- Цветовой режим
- CMYK
- Художник
- пасевен
Рукописный текст. Текстура фона. Цифровая бумага для вырезок — стоковое изображение
Рукописный текст. Текстура фона. Цифровая бумага для вырезок — Стоковая фотография — EverypixelКлючевые слова:
- нет людей
- текст
- книга
- антиквариат
- окрашенный
- почерк
- фоны
- старый
- бумага
- образец
- старомодный
- каллиграфия
- чернила
- документ
- стр.
- фоновая текстура
- цифровое искусство
- фон цифровой
- новостной фон
- фон текста
- текстура фона
- текстура винтажная бумага
- газета
- газетчики
- старая винтажная рамка
- штамп цифровой
- старый английский
- винтаж старый
- старая газета
- текстуры бумаги
- форма отчета
- текстовых сообщения
- винтажное событие
- написать бумагу
- книжный фон
- бумажные человечки
- бумажное зерно
- человек винтаж
Выберите.