Файлы в Python OTUS
Статья расскажет о работе с файлами в Python: о вводе и выводе, открытии, чтении, записи, закрытии и выполнении других не менее важных операций.
Файл представляет собой набор данных, сохраненных на компьютере, причем каждый файл имеет название — filename (имя файла, name of file).
В языке программирования Python выделяют 2 вида файлов:
— текстовые;
— бинарные.
Поговорим о каждом из типов подробнее.
Текстовые файлы. Формат .txtСодержимое таких файлов вполне понятно человеку. То есть речь идет об обычных общепринятых символах, тексте, цифрах и т. п. Такие документы можно без проблем создавать, открывать, читать и редактировать Блокнотом и прочими простейшими редакторами.
Также важно отметить, что текст хранят не только в форме .txt, но и в формате.rtf (так называемом «формате обогащенного текста»).
Бинарные файлы. Формат .binВ бинарных файлах отображение данных осуществляется в кодированной форме (применяются лишь нули и единицы). То есть речь идет уже о последовательности битов. Как следует из подзаголовка, для хранения используется формат .bin.
То есть речь идет уже о последовательности битов. Как следует из подзаголовка, для хранения используется формат .bin.
Основные операции
По сути, практически любую операцию с файлом мы можем разделить на 3 главных этапа:
- Открытие.
- Непосредственно выполнение операции (чтение, запись).
- Закрытие.
В «Питоне» существует встроенная функция open. Используя ее, вы сможете открыть файл на персональном компьютере. Технически, речь идет о создании на основе файла объекта.
Синтаксис относительно прост:
f = open(file_name, access_mode)
Что здесь что:
- file_name — это имя файла, который надо открыть;
- access_mode — это режим открытия файла. Это может быть чтение, запись и так далее. Если ничего не указать, будут справедливы настройки по умолчанию, те есть станет использоваться режим чтения (r).
Полный список режимов открытия смотрите в таблице ниже:
В качестве примера давайте выполним создание текстового файла test.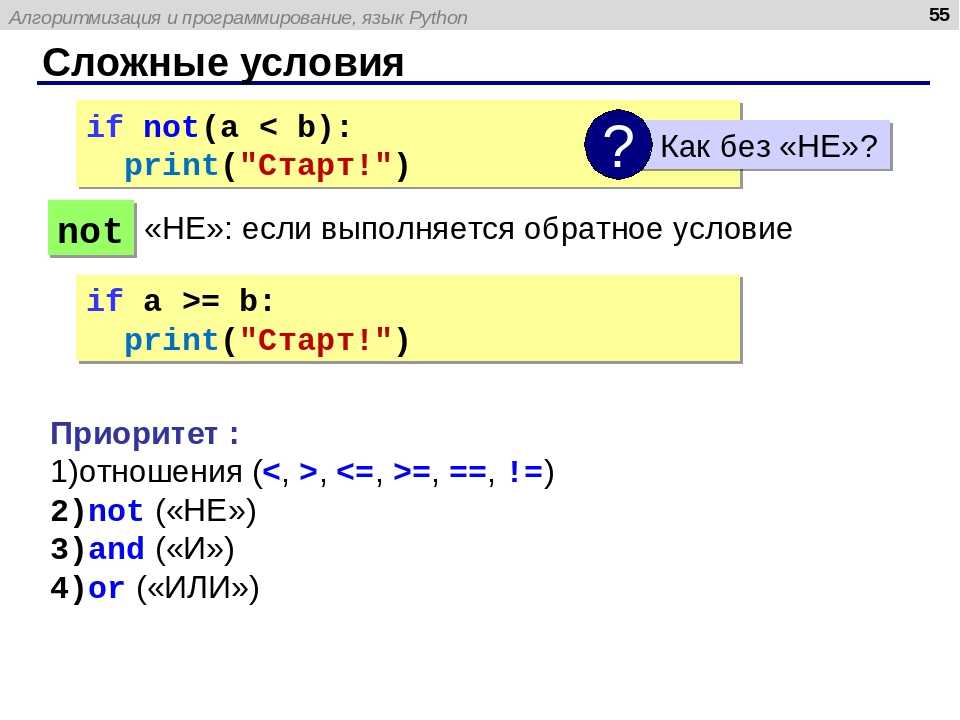 txt с последующим сохранением его в рабочей директории.
txt с последующим сохранением его в рабочей директории.
Открыть созданный документ можно в режиме чтения из рабочей директории:
f = open('test.txt','r')
Здесь f представляет собой переменную-указатель на файл test.txt.
Идем далее. Код ниже выведет содержимое файла и информацию об этом файле.
>>> print(*f) # вывод содержимого
Hello, Otus!
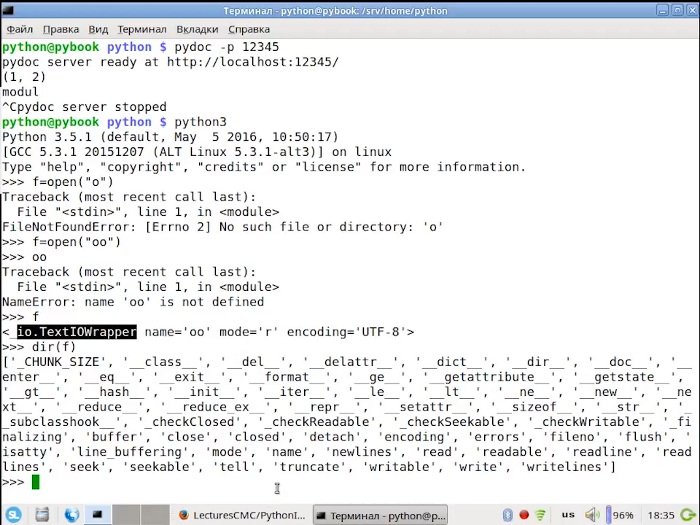
>>> print(f) # вывод объекта
<_io.TextIOWrapper name='test.txt' mode='r' encoding='cp1252'>
Учтите, что в операционной системе «Виндовс» стандартная кодировка — это cp1252, в то время как в Linux — utf-08.
Закрытие. Метод closeРаз открыли, надо и закрыть — это высвободит ресурсы. Язык программирования Python автоматически закроет файл в том случае, если объект будет присвоен другому файлу.
Для закрытия есть несколько вариантов действий.
Вариант №1
Один из наиболее простых способов. Открытый файл закрываем с помощью метода close.
Открытый файл закрываем с помощью метода close.
f = open('test.txt','r')
# работаем с файлом
f.close()
Все, документ закрыт (closed). Закрыв его таким образом, вы не сможете его использовать, пока не откроете по новой.
Вариант №2
Можно прописать try/finally. В результате файл закроется автоматически, если операции с ним приведут к исключениям. Закрытие произойдет до того, как остановится программа.
Синтаксис создания исключения следующий:
f = open('test.txt','r')
try:
# работаем с файлом
finally:
f.close()
Важно отметить, что файл следует открыть до срабатывания инструкции try.
Вариант №3
В третьем случае пригодится инструкция with, упрощающая обработку исключений посредством инкапсуляции начальных операций, а также задач по очистке и закрытию.
Тут уже инструкция close нужна не будет, так как with закроет файл автоматически.
Реализация в коде относительно проста:
with open('test.txt') as f:
# работаем с документом
Используя соответствующие режимы, можно выполнять чтение информации и ее сохранение (save) в буфер памяти.
Функция readПрименяется для чтения содержимого после открытия документа в режиме чтения (r).
Вот, как это выглядит:
file.read(size)
Что здесь что:
- file — это объект файла;
- size — это число символов, которые необходимо прочесть. Если конкретное число не указывать, документ будет прочитан полностью.
>>> f = open('test.txt','r')
>>> f.read(7) # читаем семь символов из test.txt
Это функция обеспечивает построчное чтение (считывание) содержимого. Ее используют для работы с большими файлами, так как она позволяет получать доступ к конкретной строке, причем любой.
Для примера создадим test.txt со следующими строками:
This is Otus for developers 1.
This is Otus for developers 2.
This is Otus for developers 3.
И воспользуемся readline:
x = open('test.txt','r')
x.readline() # читаем первую строку
This is Otus for developers 1.
>>> x.readline(2) # читаем 2-ю строку
This is Otus for developers 2.
>>> x.readlines() # читаем все строки сразу
['This is Otus for developers 1.','This is Otus for developers 2.','This is Otus for developers 3.']
Чтобы выполнить сохранение, нужно использовать функцию write. Сохранение в буфер памяти возможно только в те документы, которые открыты для записи (их можно сохранять, когда они находятся в соответствующем режиме).
Синтаксис несложен:
file.write(string)
Если вы попытаетесь открыть в данном режиме файл, несуществующий в буфере, будет создан новый. Представим, что файла supertest.txt у нас нет. Однако при попытке его открыть в режиме чтения, он появится:
Представим, что файла supertest.txt у нас нет. Однако при попытке его открыть в режиме чтения, он появится:
f = open('supertest.txt','w') # открываем в режиме записи
f.write('Hello \n Otus') # пишем Hello Otus в документ
Hello
Otus
f.close() # закрываем документ
Может возникнуть необходимость в переименовании имен файлов (filenames). Вопрос можно решить посредством функции rename. Но чтобы это сделать, сначала надо импортировать модуль os.
Синтаксис:
import os
os.rename(src,dest)
Что здесь что:
- src — это файловый документ, которому надо изменить name;
- dest — это новое имя.
Вот, как это выглядит в коде:
import os
# переименовываем otus1.txt в otus2.txt
>>> os. rename("otus1.txt","otus2.txt")
rename("otus1.txt","otus2.txt")
В таблице ниже вы увидите основные методы, которые используются при работе с файлами (files) в «Пайтон»:
Источник
Файлы и исключения в Python
Разрабатывая приложения вам придется работать с файлами, анализировать большие объемы данных, сохранять пользовательские данные, чтобы они не терялись по завершению работы программы. Также при работе с файлами важно научиться обрабатывать ошибки, чтобы они не привели к аварийному завершению программы. Для этого в Python существуют специальные объекты — исключения, которые создаются для управления ошибок.
| Содержание страницы: |
|---|
| 1. Чтение файла |
| 1.2. Чтение больших файлов и работа с ними |
| 1.3. Анализ текста из файла |
| 2. Запись в файл |
2. 1. Запись в пустой файл 1. Запись в пустой файл |
| 2.2. Многострочная запись в файл |
| 2.3. Присоединение данных к файлу |
| 3. Исключения |
| 3.1. Блоки try-except |
| 3.2. Блоки try-except-else |
| 3.3. Блоки try-except с текстовыми файлами |
| 3.4. Ошибки без уведомления пользователя |
1. Чтение файла в Python
В файлах может содержаться любой объем данных, начиная от небольшого рассказа и до сохранения истории погоды за столетия. Чтение файлов особенно актуально для приложений, предназначенных для анализа данных. Приведем пример простой программы, которая открывает файл и выводит его содержимое на экран. В примере я буду использовать файл с числом «Пи» с точностью до 10 знаков после запятой. Скачать этот файл можно прямо здесь ( pi_10.
with open(‘pi_10.txt’) as file_pi:
digits = file_pi.read()
print(digits)
Код начинается с ключевого слова with. При использование ключевого слова with используемый файл открывается с помощью функции open(), а закрывается автоматически после завершения блока with и вам не придется в конце вызывать функцию close(). Файлы можно открывать и закрывать явными вызовами open() и close(). Функция open() получает один аргумент — имя открываемого файла, в нашем случае ‘pi_10.txt’. Python ищет указанный файл в каталоге, где хранится файл текущей программы. Функция open() возвращает объект, представляющий файл ‘pi_10.txt’. Python сохраняет этот объект в переменной file_pi .
После появления объекта, представляющего файл ‘pi_10.txt’, используется метод read(), который читает все содержимое файла и сохраняет его в одной строке в переменной contents.
3.1415926535
В случае, если файл расположен не в одном каталоге с файлом программы, необходимо указать путь, чтобы Python искал файлы в конкретном месте. Существует два пути как прописать расположение файла:
Относительный путь приказывает Python искать файлы в каталоге, который задается относительно каталога, в котором находится текущий файл программы
with open(‘files/имя_файла.txt’) as file:
- Абсолютный путь.
Местонахождение файла не зависит от того, где находится ваша программа. Абсолютные пути обычно длиннее относительных, поэтому их лучше сохранить в переменную и затем передать функции open().
file_path = ‘/Users/Desktop/files/имя_файла.txt’
with open(file_path) as file:
С абсолютными путями можно читать файлы из любого каталога вашей системы.
1.2. Чтение больших файлов на Python и работа с ними
В первом примере был файл с 10 знаками после запятой. Теперь давайте проанализируем файл с миллионом знаков числа «Пи» после запятой. Скачать число «Пи» с миллионом знаков после запятой можно отсюда( ‘pi_1000000.txt’ ). Изменять код из первого примера не придется, просто заменим файл, который должен читать Python.
with open(‘pi_1000000.txt’) as file_pi:
digits = file_pi.read()
print(digits[:102])
print(len(digits))
Выведем на экран первые 100 знаков после запятой. Добавим в конец функцию len, чтобы узнать длину файла
1000002
Из выходных данных видно, что строка содержит значение «Пи» с точностью до 1 000 000 знаков после запятой. В Python нет никаких ограничений на длину данных, с которыми можно работать, единственное ограничение это объем памяти вашей системы.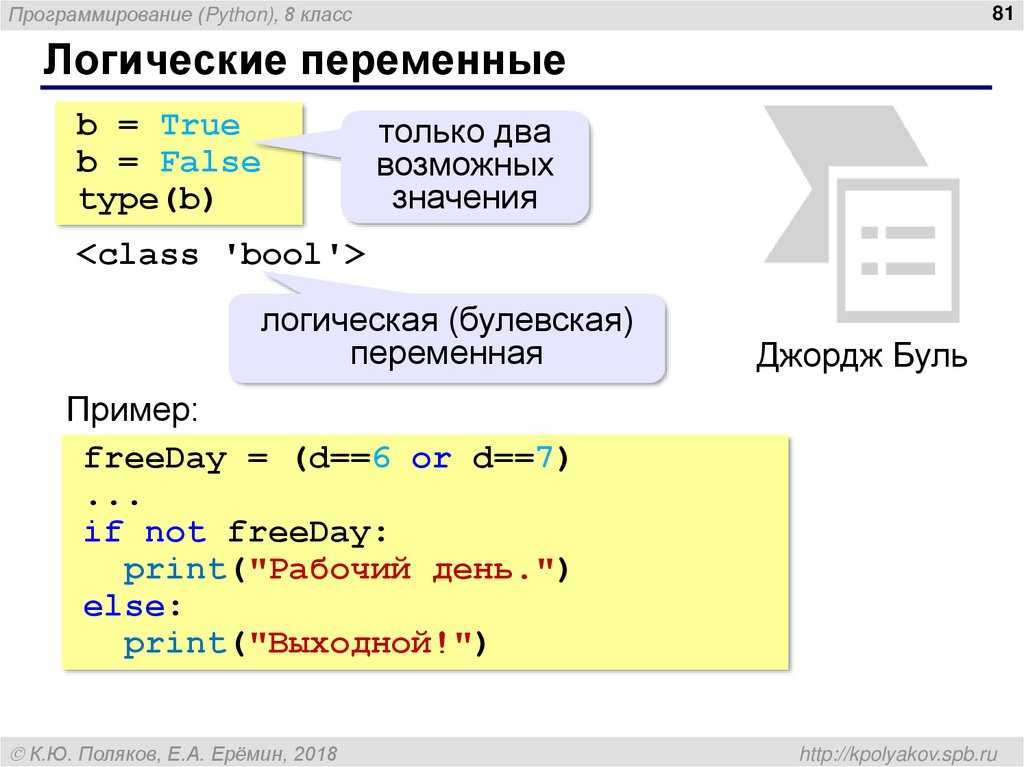
После сохранения данных в переменной можно делать с ними все что угодно. Давайте проверим, входит ли в число «Пи» дата вашего дня рождения. Напишем небольшую программу, которая будет читать файл и проверять входит ли дата день рождения в первый миллион числа «Пи»:
with open(‘pi_1000000.txt’) as file_pi:
digits = file_pi.read()
birthday = input(«Введите дату дня рождения: «)
if birthday in digits:
print(«Ваш день рождение входит в число ‘Пи'»)
print(«Ваш день рождение не входит в число ‘Пи'»)
Начало программы не изменилось, читаем файл и сохраняем данные в переменной digits. Далее запрашиваем данные от пользователя с помощью функции input и сохраняем в переменную birstday. Затем проверяем вхождение birstday в digits с помощью команды if-else. Запустив несколько раз программу, получим результат:
Введите дату дня рождения: 260786
Ваш день рождение не входит в число ‘Пи’
Введите дату дня рождения: 260884
Ваш день рождение входит в число ‘Пи’
В зависимости от введенных данных мы получили результат вхождения или не вхождения дня рождения в число «Пи»
Важно: Читая данные из текстового файла, Python интерпретирует весь текст как строку.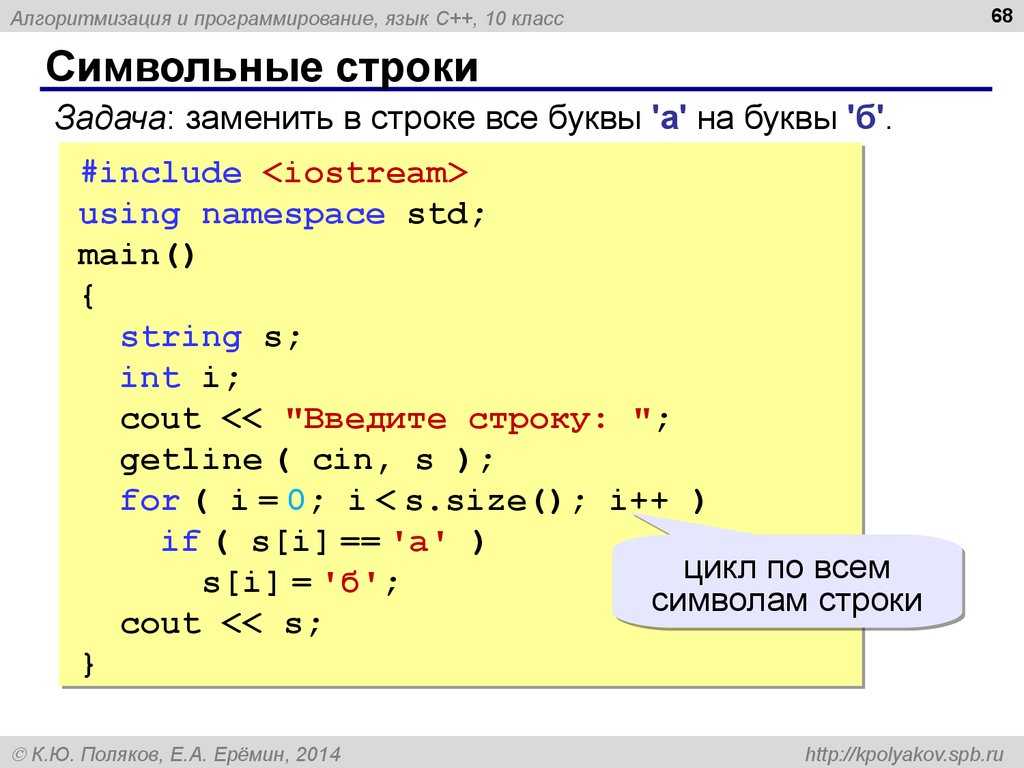
1.3. Анализ текста из файла на Python
Python может анализировать текстовые файлы, содержащие целые книги. Возьмем книгу «Алиса в стране чудес» и попробуем подсчитать количество слов в книге. Текстовый файл с книгой можете скачать здесь(‘ alice ‘) или загрузить любое другое произведение. Напишем простую программу, которая подсчитает количество слов в книге и сколько раз повторяется имя Алиса в книге.
filename = ‘alice.txt’
with open(filename, encoding=’utf-8′) as file:
contents = file.read()
n_alice = contents.lower().count(‘алиса’)
words = contents.split()
n_words = len(words)
print(f»Книга ‘Алиса в стране чудес’ содержит {n_words} слов.»)
print(f»Имя Алиса повторяется {n_alice} раз.»)
При открытии файла добавился аргумент encoding=’utf-8′.
Для подсчета вхождения слова или выражений в строке можно воспользоваться методом count(), но прежде привести все слова к нижнему регистру функцией lower(). Количество вхождений сохраним в переменной n_alice.
Чтобы подсчитать количество слов в тексе, воспользуемся методом split(), предназначенный для построения списка слов на основе строки. Метод split() разделяет строку на части, где обнаружит пробел и сохраняет все части строки в элементах списка. Пример метода split():
title = ‘Алиса в стране чудес’
print(title.split())
[‘Алиса’, ‘в’, ‘стране’, ‘чудес’]
После использования метода split(), сохраним список в переменной
Книга ‘Алиса в стране чудес’ содержит 28389 слов.
Имя Алиса повторяется 419 раз.
2.1. Запись в пустой файл в Python
Самый простой способ сохранения данных, это записать их в файл. Чтобы записать текс в файл, требуется вызвать open() со вторым аргументом, который сообщит Python что требуется записать файл. Пример программы записи простого сообщения в файл на Python:
filename = ‘memory.txt’
with open(filename, ‘w’) as file:
file.write(«Язык программирования Python»)
Для начала определим название и тип будущего файла и сохраним в переменную filename. Затем при вызове функции open() передадим два аргумента. Первый аргумент содержит имя открываемого файла. Второй аргумент ‘ w ‘ сообщает Python, что файл должен быть открыт в режиме записи. Во второй строчке метод write() используется для записи строки в файл. Открыв файл ‘ memory.txt ‘ вы увидите в нем строку:
Язык программирования Python
Получившийся файл ничем не отличается от любых других текстовых файлах на компьютере, с ним можно делать все что угодно.
Важно: Открывая файл в режиме записи ‘ w ‘, если файл уже существует, то Python уничтожит его данные перед возвращением объекта файла.
Файлы можно открывать в режимах:
- чтение ‘ r ‘
- запись ‘ w ‘
- присоединение ‘ a ‘
- режим как чтения, так и записи ‘ r+ ‘
2.2. Многострочная запись в файл на Python
При использовании функции write() символы новой строки не добавляются в записываемый файл:
filename = ‘memory.txt’
with open(filename, ‘w’) as file:
file.write(«Язык программирования Python»)
file.write(«Язык программирования Java»)
file.write(«Язык программирования Perl»)
В результате открыв файл мы увидим что все строки склеились:
Язык программирования PythonЯзык программирования JavaЯзык программирования Perl
Для написания каждого сообщения с новой строки используйте символ новой строки \n
filename = ‘memory. txt’
txt’
with open(filename, ‘w’) as file:
file.write(«Язык программирования Python\n»)
file.write(«Язык программирования Java\n»)
file.write(«Язык программирования Perl\n»)
Результат будет выглядеть так:
Язык программирования Python
Язык программирования Java
Язык программирования Perl
2.3. Присоединение данных к файлу на Python
Для добавления новых данных в файл, вместо того чтобы постоянно перезаписывать файл, откройте файл в режиме присоединения ‘ a ‘. Все новые строки добавятся в конец файла. Возьмем созданный файл из раздела 2.2 ‘memory.txt’. Добавим в него еще пару строк.
filename = ‘memory.txt’
with open(filename, ‘a’) as file:
file.write(«Hello world\n»)
file.write(«Полет на луну\n»)
В результате к нашему файлу добавятся две строки:
Язык программирования Python
Язык программирования Java
Язык программирования Perl
Hello world
Полет на луну
3.
 Исключения в Python
Исключения в PythonПри выполнении программ могут возникать ошибки, для управления ими Python использует специальные объекты, называемые исключениями. Когда в программу включен код обработки исключения, ваша программа продолжится, а если нет, то программа остановится и выведет трассировку с отчетом об исключении. Исключения обрабатываются в блоках try-except. С блоками try-except программы будут работать даже в том случае, если что-то пошло не так.
3.1. Блоки try-except на Python
Приведем пример простой ошибки деления на ноль:
print(7/0)
Traceback (most recent call last):
File «example.py», line 1, in <module>
print(7/0)
ZeroDivisionError: division by zero
Если в вашей программе возможно появление ошибки, то вы можете заранее написать блок try-except для обработки данного исключения. Приведем пример обработки ошибки ZeroDivisionError с помощью блока try-except:
try:
print(7/0)
except ZeroDivisionError:
print(«Деление на ноль запрещено»)
Команда print(7/0) помещена в блок try. Если код в блоке try выполняется успешно, то Python пропускает блок except. Если же код в блоке try создал ошибку, то Python ищет блок except и запускает код в этом блоке. В нашем случае в блоке except выводится сообщение «Деление на ноль запрещено». При выполнение этого кода пользователь увидит понятное сообщение:
Если код в блоке try выполняется успешно, то Python пропускает блок except. Если же код в блоке try создал ошибку, то Python ищет блок except и запускает код в этом блоке. В нашем случае в блоке except выводится сообщение «Деление на ноль запрещено». При выполнение этого кода пользователь увидит понятное сообщение:
Деление на ноль запрещено
Если за кодом try-except следует другой код, то Python продолжит выполнение программы.
3.2. Блок try-except-else на Python
Напишем простой калькулятор, который запрашивает данные у пользователя, а затем результат деления выводит на экран. Сразу заключим возможную ошибку деления на ноль ZeroDivisionError и добавим блок else при успешном выполнение блока try.
while True:
first_number = input(«Введите первое число: «)
if first_number == ‘q’:
break
second_number = input(«Введите второе число: «)
if second_number == ‘q’:
break
try:
a = int(first_number) / int(second_number)
except ZeroDivisionError:
print(«Деление на ноль запрещено»)
else:
print(f»Частное двух чисел равно {a}»)
Программа запрашивает у пользователя первое число (first_number), затем второе (second_number). Если пользователь не ввел » q « для завершения работы программа продолжается. В блок try помещаем код, в котором возможно появление ошибки. В случае отсутствия ошибки деления, выполняется код else и Python выводит результат на экран. В случае ошибки ZeroDivisionError выполняется блок except и выводится сообщение о запрете деления на ноль, а программа продолжит свое выполнение. Запустив код получим такие результаты:
Если пользователь не ввел » q « для завершения работы программа продолжается. В блок try помещаем код, в котором возможно появление ошибки. В случае отсутствия ошибки деления, выполняется код else и Python выводит результат на экран. В случае ошибки ZeroDivisionError выполняется блок except и выводится сообщение о запрете деления на ноль, а программа продолжит свое выполнение. Запустив код получим такие результаты:
Введите первое число: 30
Введите второе число: 5
Частное двух чисел равно 6.0
Введите первое число: 7
Введите второе число: 0
Деление на ноль запрещено
Введите первое число: q
В результате действие программы при появлении ошибки не прервалось.
3.3. Блок try-except с текстовыми файлами на Python
Одна из стандартных проблем при работе с файлами, это отсутствие необходимого файла, или файл находится в другом месте и Python не может его найти. Попробуем прочитать не существующий файл:
Попробуем прочитать не существующий файл:
filename = ‘alice_2.txt’
with open(filename, encoding=’utf-8′) as file:
contents = file.read()
Так как такого файла не существует, Python выдает исключение:
Traceback (most recent call last):
File «example.py», line 3, in <module>
with open(filename, encoding=’utf-8′) as file:
FileNotFoundError: [Errno 2] No such file or directory: ‘alice_2.txt’
FileNotFoundError — это ошибка отсутствия запрашиваемого файла. С помощью блока try-except обработаем ее:
filename = ‘alice_2.txt’
try:
with open(filename, encoding=’utf-8′) as file:
contents = file.read()
except FileNotFoundError:
print(f»Запрашиваемый файл {filename } не найден»)
В результате при отсутствии файла мы получим:
Запрашиваемый файл alice_2.txt не найден
3.4. Ошибки без уведомления пользователя
В предыдущих примерах мы сообщали пользователю об ошибках. В Python есть возможность обработать ошибку и не сообщать пользователю о ней и продолжить выполнение программы дальше. Для этого блок try пишется, как и обычно, а в блоке except вы прописываете Python не предпринимать никаких действий с помощью команды pass. Приведем пример ошибки без уведомления:
В Python есть возможность обработать ошибку и не сообщать пользователю о ней и продолжить выполнение программы дальше. Для этого блок try пишется, как и обычно, а в блоке except вы прописываете Python не предпринимать никаких действий с помощью команды pass. Приведем пример ошибки без уведомления:
ilename = ‘alice_2.txt’
try:
with open(filename, encoding=’utf-8′) as file:
contents = file.read()
except FileNotFoundError:
pass
В результате при запуске этой программы и отсутствия запрашиваемого файла ничего не произойдет.
Далее: Функции json. Сохранение данных Python
Назад: Классы в Python
Please enable JavaScript to view the comments powered by Disqus.
Управление каталогами и файлами Python (с примерами)
В этом руководстве мы узнаем об управлении файлами и каталогами в Python с помощью примеров.
Каталог — это набор файлов и подкаталогов. Каталог внутри каталога называется подкаталогом.
Python имеет модуль os , который предоставляет нам множество полезных методов для работы с каталогами (а также с файлами).
Получить текущий каталог в Python
Мы можем получить текущий рабочий каталог, используя метод getcwd() модуля os .
Этот метод возвращает текущий рабочий каталог в виде строки. Например,
импорт ОС печать (os.getcwd()) # Вывод: C:\Program Files\PyScripter
Здесь getcwd() возвращает текущий каталог в виде строки.
Изменение каталога в Python
В Python мы можем изменить текущий рабочий каталог, используя метод chdir() .
Новый путь, который мы хотим изменить, должен быть предоставлен этому методу в виде строки. И мы можем использовать как прямую косую черту /, так и обратную косую черту \ для разделения элементов пути.
Давайте посмотрим пример,
import os
# изменить каталог
os.chdir('C:\\Python33')
печать (os.getcwd())
Вывод: C:\Python33 Здесь мы использовали метод chdir() для изменения текущего рабочего каталога и передали новый путь в виде строки на чдир() .
Список каталогов и файлов в Python
Все файлы и подкаталоги внутри каталога можно получить с помощью метода listdir() .
Этот метод принимает путь и возвращает список подкаталогов и файлов по этому пути.
Если путь не указан, возвращает список подкаталогов и файлов из текущего рабочего каталога.
импорт ОС
печать (os.getcwd())
C:\Питон33
# список всех подкаталогов
os.listdir()
['DLL',
'Док',
'включать',
'Либ',
'библиотеки',
'ЛИЦЕНЗИЯ.txt',
'НОВОСТИ.txt',
'python.exe',
'pythonw.exe',
'README.txt',
'Скрипты',
'ткл',
'Инструменты']
os.listdir('G:\\')
['$RECYCLE.BIN',
'Кино',
'Музыка',
'Фото',
'Ряд',
«Информация о системном томе»] Создание нового каталога в Python
В Python мы можем создать новый каталог, используя метод mkdir() .
Этот метод принимает путь к новому каталогу. Если полный путь не указан, новый каталог создается в текущем рабочем каталоге.
os.mkdir('тест')
os.listdir()
['test'] Переименование каталога или файла
Метод rename() может переименовать каталог или файл.
Для переименования любого каталога или файла, rename() принимает два основных аргумента:
- старое имя в качестве первого аргумента
- новое имя в качестве второго аргумента.
Давайте посмотрим пример,
import os
os.listdir()
['контрольная работа']
# переименовать каталог
os.rename('тест','new_one')
os.listdir()
['new_one'] Здесь каталог 'test ‘ переименовывается в 'new_one' с использованием метода rename() .
Удаление каталога или файла в Python
В Python мы можем использовать метод remove() или метод rmdir() для удаления файла или каталога.
Сначала воспользуемся remove() для удаления файла,
import os
# удалить файл "myfile.txt"
os.remove("myfile.txt") Здесь мы использовали метод remove() для удаления файла "myfile.txt" .
Теперь воспользуемся rmdir() для удаления пустого каталога,
import os
# удалить пустой каталог "mydir"
os.rmdir("mydir") Чтобы удалить непустой каталог, мы можем использовать метод rmtree() внутри модуля Shutil . Например,
импортный шатил
# удалить каталог "mydir" и все его содержимое
Shutil.rmtree("mydir") Важно отметить, что эти функции безвозвратно удаляют файлы или каталоги, поэтому мы должны быть осторожны при их использовании.
Чтение и запись файлов CSV
В этом руководстве мы научимся читать и записывать файлы CSV в Python с помощью примеров.
Формат CSV (значения, разделенные запятыми) — один из самых простых и распространенных способов хранения табличных данных. Чтобы представить файл CSV, он должен быть сохранен с расширением .csv .
Чтобы представить файл CSV, он должен быть сохранен с расширением .csv .
Возьмем пример:
Если вы откроете указанный выше файл CSV с помощью текстового редактора, такого как возвышенный текст, вы увидите:
Серийный номер, Имя, Город 1, Майкл, Нью-Джерси 2, Джек, Калифорния
Как видите, элементы файла CSV разделены запятыми. Здесь, , — это разделитель.
Вы можете использовать любой символ в качестве разделителя в соответствии с вашими потребностями.
Примечание: Модуль csv также можно использовать для файлов с другими расширениями (например: .txt ), если их содержимое имеет правильную структуру.
Работа с файлами CSV в Python
Хотя мы могли бы использовать встроенную функцию open() для работы с файлами CSV в Python, существует специальный модуль csv , который значительно упрощает работу с файлами CSV.
Прежде чем мы сможем использовать методы модуля csv , нам нужно сначала импортировать модуль, используя:
import csv
Чтение CSV-файлов с помощью csv.
 reader()
reader() Чтобы прочитать CSV-файл в Python, мы можем использовать функцию csv.reader() . Предположим, у нас есть файл csv с именем people.csv в текущем каталоге со следующими записями.
| Имя | Возраст | Профессия |
| Домкрат | 23 | Доктор |
| Миллер | 22 | Инженер |
Давайте прочитаем этот файл, используя csv.reader() :
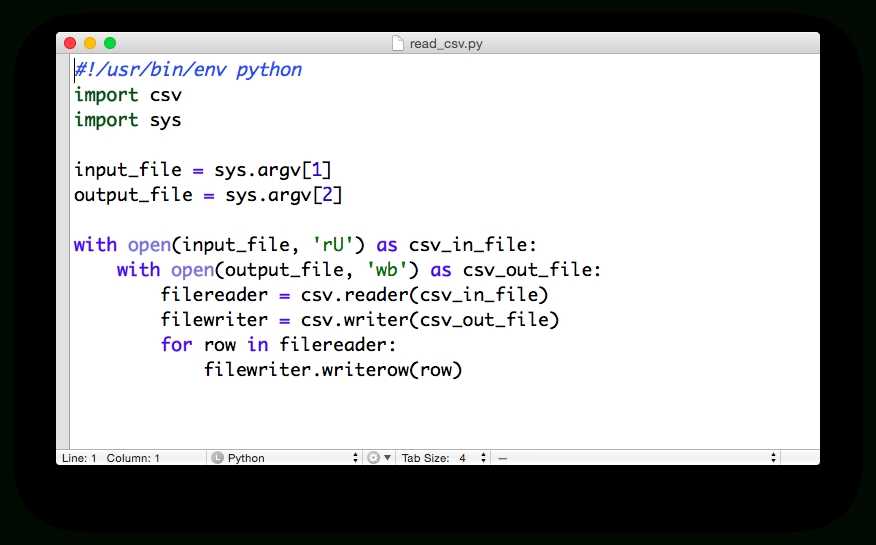
Пример 1: Чтение CSV с разделителем-запятой
import csv
с open('people.csv', 'r') в виде файла:
читатель = csv.reader (файл)
для строки в читателе:
печать (строка)
Выход
['Имя', 'Возраст', 'Профессия'] ['Джек', '23', 'Доктор'] ['Миллер', '22', 'Инженер']
Здесь мы открыли файл people.csv в режиме чтения, используя:
с open('people. csv', 'r') в качестве файла:
.. .. ...
csv', 'r') в качестве файла:
.. .. ...
Чтобы узнать больше об открытии файлов в Python, посетите: Python File Input/Output
Затем csv.reader() используется для чтения файла, который возвращает повторяемый объект reader .
9Затем объект 0007 reader повторяется с использованием цикла for для печати содержимого каждой строки.
В приведенном выше примере мы используем функцию csv.reader() в режиме по умолчанию для файлов CSV с разделителем-запятой.
Однако эта функция гораздо более настраиваема.
Предположим, что наш CSV-файл использует в качестве разделителя вкладку . Чтобы прочитать такие файлы, мы можем передать необязательные параметры функции csv.reader() . Возьмем пример.
Пример 2. Чтение CSV-файла с разделителем табуляции
Импорт csv
с open('people.csv', 'r',) в виде файла:
читатель = csv.reader (файл, разделитель = '\ t')
для строки в читателе:
печать (строка)
Обратите внимание на необязательный параметр delimiter = '\t' в приведенном выше примере.
Полный синтаксис функции csv.reader() :
Как видно из синтаксиса, мы также можем передать параметр диалекта в функция csv.reader() . Параметр диалект позволяет сделать функцию более гибкой. Чтобы узнать больше, посетите: Чтение файлов CSV в Python.
Запись CSV-файлов с помощью csv.writer()
Для записи в CSV-файл в Python мы можем использовать функцию csv.writer() .
Функция csv.writer() возвращает объект Writer , который преобразует данные пользователя в строку с разделителями. Позже эту строку можно будет использовать для записи в CSV-файлы с помощью функция writerow() . Возьмем пример.
Пример 3: запись в файл CSV
импорт csv
с open('protagonist.csv', 'w', newline='') в виде файла:
писатель = csv.writer (файл)
Writer.writerow(["SN", "Фильм", "Главный герой"])
author.writerow([1, "Властелин колец", "Фродо Бэггинс"])
author.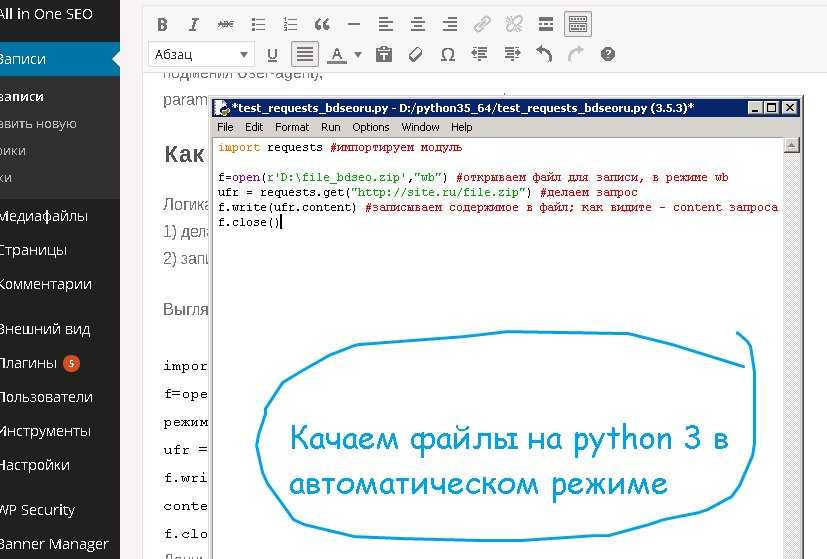 writerow([2, "Гарри Поттер", "Гарри Поттер"])
writerow([2, "Гарри Поттер", "Гарри Поттер"])
Когда мы запускаем указанную выше программу, создается файл protagonist.csv со следующим содержимым:
SN, фильм, главный герой 1, Властелин колец, Фродо Бэггинс 2, Гарри Поттер, Гарри Поттер
В приведенной выше программе мы открыли файл в режиме записи.
Затем мы передали каждую строку как список. Эти списки преобразуются в строку с разделителями и записываются в файл CSV.
Пример 4: Запись нескольких строк с помощью writerows()
Если нам нужно записать содержимое двумерного списка в файл CSV, вот как мы можем это сделать.
импорт CSV
csv_rowlist = [["SN", "Фильм", "Главный герой"], [1, "Властелин колец", "Фродо Бэггинс"],
[2, «Гарри Поттер», «Гарри Поттер»]]
с open('protagonist.csv', 'w') в виде файла:
писатель = csv.writer (файл)
писатель.writerows (csv_rowlist)
Вывод программы такой же, как и в Пример 3 .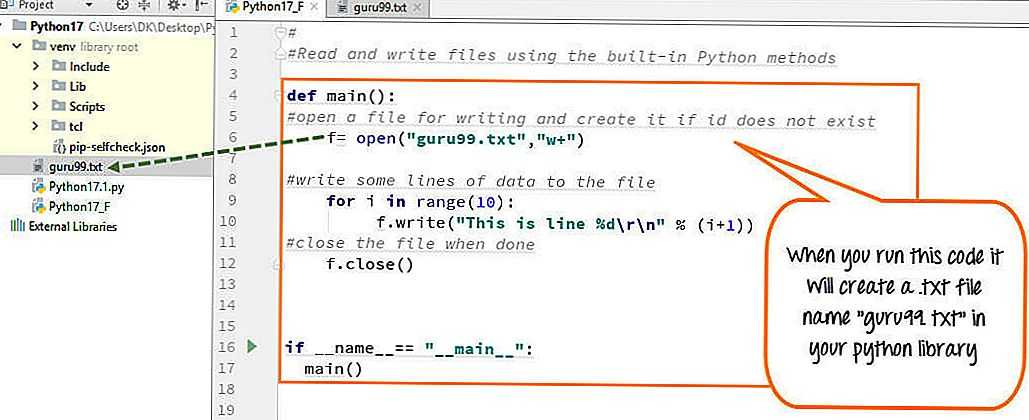
Здесь наш двумерный список передается методу write.writerows() для записи содержимого списка в файл CSV.
Пример 5: Запись в файл CSV с разделителем табуляции
import csv
с open('protagonist.csv', 'w') в виде файла:
писатель = csv.writer (файл, разделитель = '\ t')
Writer.writerow(["SN", "Фильм", "Главный герой"])
author.writerow([1, "Властелин колец", "Фродо Бэггинс"])
author.writerow([2, "Гарри Поттер", "Гарри Поттер"])
Обратите внимание на необязательный параметр delimiter = '\t' в функции csv.writer() .
Полный синтаксис csv.writer () функция:
csv.writer (csvfile, диалект = 'excel', ** необязательные_параметры)
Подобно csv.reader() , вы также можете передать диалектный параметр функции csv.writer() , чтобы сделать функцию более настраиваемой. Чтобы узнать больше, посетите: Написание CSV-файлов в Python
Python csv.
 DictReader() Class
DictReader() Class Объекты класса csv.DictReader() можно использовать для чтения CSV-файла в качестве словаря.
Пример 6: Python csv.DictReader()
Предположим, у нас есть тот же файл people.csv , что и в Пример 1 .
| Имя | Возраст | Профессия |
| Домкрат | 23 | Доктор |
| Миллер | 22 | Инженер |
Давайте посмотрим, как можно использовать csv.DictReader() .
импорт CSV
с open("people.csv", 'r') в виде файла:
csv_file = csv.DictReader(файл)
для строки в csv_file:
печать (дикт (строка))
Выход
{'Имя': 'Джек', 'Возраст': '23', 'Профессия': 'Доктор'}
{'Имя': 'Миллер', 'Возраст': '22', 'Профессия': 'Инженер'}
Как мы видим, записи первой строки являются ключами словаря. И записи в других строках являются значениями словаря.
И записи в других строках являются значениями словаря.
Здесь csv_file — это объект csv.DictReader() . Объект можно перебирать с помощью цикла for . csv.DictReader() вернул тип OrderedDict для каждой строки. Вот почему мы использовали dict() для преобразования каждой строки в словарь.
Обратите внимание, что мы явно использовали метод dict() для создания словарей внутри цикла for .
печать (дикт (строка))
Примечание . Начиная с Python 3.8, csv.DictReader() возвращает словарь для каждой строки, и нам не нужно явно использовать dict() .
Полный синтаксис csv.DictReader() класс:
csv.DictReader(файл, имена полей=Нет, restkey=Нет, restval=Нет, диалект='excel', *args, **kwds)
Чтобы узнать больше об этом, посетите: Python csv.DictReader() class
Python csv.DictWriter() Class
Объекты класса csv. можно использовать для записи в CSV файл из словаря Python. DictWriter()
DictWriter()
Минимальный синтаксис класса csv.DictWriter() :
csv.DictWriter(file, fieldnames)
Здесь,
-
файл— CSV файл куда мы хотим записать -
имена полей— объект списка
Пример 7: Python csv.DictWriter()
импорт csv
с open('players.csv', 'w', newline='') в виде файла:
fieldnames = ['player_name', 'fide_rating']
писатель = csv.DictWriter (файл, имена полей = имена полей)
писатель.writeheader()
Writer.writerow({'player_name': 'Магнус Карлсен', 'fide_rating': 2870})
Writer.writerow({'player_name': 'Фабиано Каруана', 'fide_rating': 2822})
Writer.writerow({'player_name': 'Дин Лижэнь', 'fide_rating': 2801})
Программа создает файл player. csv со следующими записями:
csv со следующими записями:
player_name,fide_rating Магнус Карлсен, 2870 Фабиано Каруана, 2822 г. Дин Лижэнь, 2801
Полный синтаксис класса csv.DictWriter() :
csv.DictWriter(f, имена полей, restval='', extrasaction='raise', диалект='excel', *args, * *kwds)
Чтобы узнать больше об этом, посетите: Python csv.DictWriter() class
Использование библиотеки Pandas для обработки файлов CSV
Pandas — это популярная библиотека данных на Python для обработки и анализа данных. Если мы работаем с огромными объемами данных, для простоты и эффективности лучше использовать pandas для обработки CSV-файлов.
Прежде чем мы сможем использовать pandas, нам нужно установить его. Чтобы узнать больше, посетите: Как установить Pandas?
После установки мы можем импортировать Pandas как:
импортировать pandas как pd
Чтобы прочитать файл CSV с помощью pandas, мы можем использовать read_csv() 9Функция 0008.