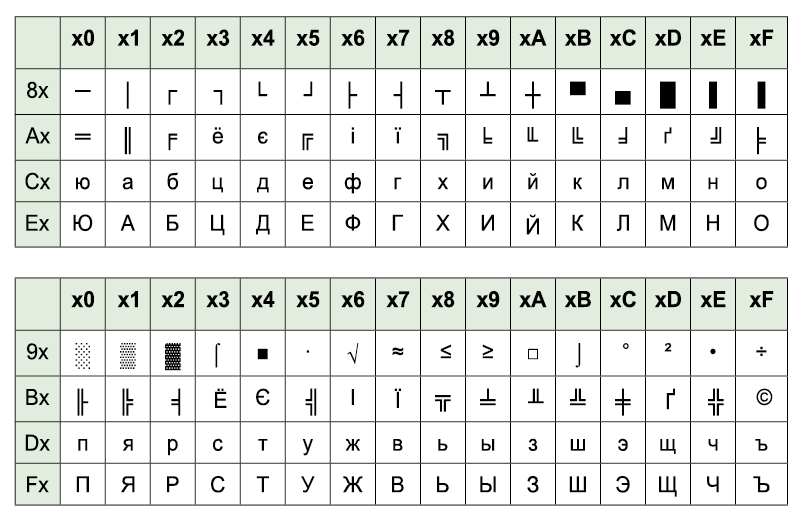
Universal online Cyrillic decoder — recover your texts
Universal online Cyrillic decoder — recover your texts Version: 20230216 By the same author: Virtour.fr — visites virtuelles Հայերեն —
Башҡорт — Беларуская — Български —
Иронау —
Қазақша —
Кыргызча — Македонски —
Монгол
Нохчийн — O’zbek — Русский — Slovensky — Српски — Татарча — Тоҷикӣ — Українська — Чaваш — Français — English
Output
The resulting text will be displayed here…
| Guestbook Please link to this site! | Custom Work For a small fee I can help you quickly recode/recover large pieces of data — texts, databases, websites… or write custom functions you can use (invoice available).  FAQ and contact information. |
About the program
Welcome! You may find this site useful, if you have recieved some texts that you believe are written in the Cyrillic alphabet, but instead are displayed in some strange combination of bizarre characters. This program will try to guess the encoding, and if it does not, it will show samples, examples of all encoding-combinations, so as you will be able to select the good one.
How to
- Paste the text to decode in the big text area. The first few words will be analyzed so they should be (scrambled) in supposed Cyrillic.
- The program will try to decode the text and will print the result below.
- If the translation is successful, you will see the text in Cyrillic characters and will be able to copy it and save it if it’s important.
- If the translation isn’t successful (still the text is not in Cyrillic but in the same or other unintelligible characters), you can choose from the newly created select-listbox the variant that is in Cyrillic (if there are more than one, select the longest).
 By pressing the button OK you will have the correct text converted.
By pressing the button OK you will have the correct text converted. - If the text is not totally converted, try all other variants in Cyrillic from the select-listbox.
Limits
- If your text contains question marks «???? ?? ??????», the problem is with the sender and no recovery will be possible. Ask them to resend the text, eventually as an ordinary text file or in LibreOffice/OpenOffice/MSOffice format.
- There is no claim that every text is recoverable, even if you are certain that the text is in Cyrillic.
- The analyzed and converted text is limited to 100 KiB.
- A 100% precision is not always achieved — in a conversion from a codepage to another code page, some characters may be lost, like the Bulgarian quotes or rarely some single letters. Some of this depends on your Windows Clipboard character handling.
- The program will try a maximum of 8280 variants in two or three levels: if there had been a multiple encoding like koi8(utf(cp1251(utf))), it will not be detected or tested.
 Usually the possible and displayed correct variants are between 32 and 255.
Usually the possible and displayed correct variants are between 32 and 255. - If a part of the text is encoded with one code page, and another part — with another code page, the program could recognize only one of the parts at a time.
Terms of use
Please notice that this freeware program is created with the hope that it would be useful, but has no warranty, not even an implied warranty for fitness for any particular use. Please use it at your own risk.
If you have very long texts to translate, please make sure you have a backup copy.
What’s new
- March 2021 : After a server upgrade, the program stopped working and some parts of it had to be rewritten.
- May 2020 : Added Тоҷикӣ/Tajik translation, thanks to Анвар/Anvar.
- October 2017 : Added «Select all / Copy» button.
- July 2016 : SSL Certificate installed, you can now access the Decoder on a secure connection.
- October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text.
 If you notice any problem, please notify me ASAP.
If you notice any problem, please notify me ASAP. - March 2013 : My hosting provider sent me a warning that the Decoder is using too much server CPU power and its processes were killed more than 100 times. I am making some changes so that the program will use less CPU, especially when reposting a previously sampled text, however, the decoded form may load somewhat slower. Please contact me if you have some difficulties using the program.
- 2012-08-09 : Added French translation, thanks to Arnaud D.
- 2011-03-06 : Added Belorussian translation, thanks to Зыль and Aliaksandr Hliakau.
- 31.07.10 : Added Serbian translation, thanks to Miodrag Danilovic (Boston — Beograd).
- 07.05.09 : Raised limit of MAX text size to 50 kiB.
- may 2009 : Added Ukrainian interface thanks to Barmalini.
- 2008-2009 : A number of small fixes and tweaks of the detection algorithm. Changed interface to default to automatic decoding.

- 12.08.07 : Fixed Russian language translation, thanks to Petr Vasilyev. This page will be significantly restructured in the near future.
- 10.11.06 : Three new postfilters added: «base64», «unix-to-unix» и «bin-to-hex», theoretically the tested combinations are 4725. Changes to the frequency analysis function (testing).
- 11.10.06 : The main site is on a new hardware server, should run faster.
- 11.09.06 : The program now uses PHP5 and should run times faster.
- 19.08.06 : Because of a broken DNS entry, this site was inaccessible from 06:00 on 15 august up to 15:00 on 18 august. That was the reason for me to set two «mirror» sites (5ko.free.fr/decode and www.accent.bg/decode) with the same program. If the original has a problem, you can find the copies in Google and recover your texts.
- 17.06.06 : Added two more antique Cyrillic encodings, MIK и KOI-7, but you better not need them.
- 03.03.
 06 : Added Slovak translation, thanks to Martin from KPR Slovakia.
06 : Added Slovak translation, thanks to Martin from KPR Slovakia. - 15.02.06 : More encodings added and tested.
- 20.10.05 : Small improvement to the frequency-analysis function: for texts, written in all-capital letters.
- 14.10.05 : Two more gmail-Cyrillic encodings were added. Theoretically the tested combinations are 2112.
- 15.06.05 : Russian language interface was added. Big thanks to chAlx!
- 16.02.05 : One more postfilter decoding is added, for strings like this: «%u043A%u0438%u0440%u0438%u043B%u0438%u0446%u0430».
- 05.02.05 : More encodings tests added, the number of tested encodings is doubled, but thus the program may work slightly slower.
- 03.02.05 : The frequency analysis function that detects the original encoding works much better now. Currently the program recognises most of the encodings if the first few words are not too weird. It although still needs some improvement.

- 15.01.05 : The input text limit is raised from 10 to 20 kB.
- 01.12.04 : First public release.
Back to the Latin to Cyrillic convertor.
С# — В чем разница между Encoding.GetEncoding(1255) и Encoding.GetEncoding(1252)?
Задавать вопрос
спросил
Изменено 2 года, 6 месяцев назад
Просмотрено 29 тысяч раз
У меня есть программа на основе формы C#, и я использую
System.Text.Encoding.GetEncoding(1252)
, но у меня возникли проблемы с чтением неанглийских символов, я обнаружил
System. Text.Encoding.GetEncoding(1255)
работает, однако я не знаю последствий изменения этого, поэтому я надеюсь, что кто-то может пролить свет на разницу и возможные последствия.
- c#
- .net
- кодировка
При использовании GetEncoding(1252) вы указываете кодировку Windows-1252, которая указывает латинский алфавит для Западной Европы. GetEncoding(1255) — это кодировка Windows-1255, которая используется для записи на иврите.
Кодировка символов 1255 включает символы иврита, тогда как 1252 ориентирована на западные языки. Это тот случай, когда неанглийские символы являются ивритскими?
11252 — Windows-1252 Западноевропейская (Windows)
1255 — это Windows-1255 Иврит (Windows)
источник: http://msdn.microsoft.com/en-us/library/system.text.encodinginfo.codepage.aspx
Ваша кодировка всегда должна совпадать с той, которая использовался для создания файла. Если нет доступных метаданных (или человека), которые могли бы помочь в этом выборе, то единственное, что можно было бы сделать, — это попробовать каждый из них и посмотреть, какой из них разборчив. Поскольку это, по-видимому, на языке, который вы не знаете, вам может потребоваться спросить кого-то, кто говорит на этом языке, можно ли это прочитать.
Вероятно, вы захотите использовать одну из «именованных» кодировок Unicode, например, Encoding.UTF8 . Но, чтобы ответить на ваш вопрос, страница 1252 — это «Западноевропейская (Windows)», а 1255 — «Иврит (Windows)».
Если вы не знаете, кодовые страницы в значительной степени являются пережитком ASCII, и вы должны стараться придерживаться Unicode, где это возможно.
2Зарегистрируйтесь или войдите в систему
Зарегистрируйтесь с помощью GoogleОпубликовать как гость
Электронная почтаОбязательно, но не отображается
Опубликовать как гость
Электронная почтаТребуется, но не отображается
Кодировка/кодовая страница: отсюда невозможно добраться автор: Кристофер Х. Лако |
последнее сообщение от: Лако |
последнее сообщение от:Долгая история длиннее. Мне нужно получить ввод веб-пользователя в серверную систему что а) работает только с однобайтовым кодированием, б) ожидает передачи данных быть… .NET Framework |
Нужна помощь в кодировании греческого языка автор: ПАН | последнее сообщение от:Мне нужно руководство здесь Я написал этот HTML-код с помощью ноутбука Windows: … HTML/CSS |
Преобразование кодировки из Shift-JIS в UTF-8 автор: DbNetLink | последнее сообщение от:Я пытаюсь преобразовать японский текст, закодированный как Shift-JIS/ISO-2022-JP. в UTF-8, чтобы я мог хранить все данные в моей базе данных с общей кодировкой. … C# / C Sharp |
ISO-Latin Encoding автор: Энди | последнее сообщение от: Я пытаюсь написать цикл for, который будет печатать все символы ISO-Latin. C# / C Sharp |
кодирование/декодирование строки запроса автор: Марк | последнее сообщение от:Я провел несколько простых тестов, чтобы посмотреть, как кодирование/декодирование строки запроса обрабатывается в asp.net, и кажется, что ситуация еще более запутанная… ASP.NET |
Кодировка темы и заголовка электронной почты, отличной от ASCII автор: Чуин | последнее сообщение от:Всем привет, Мне нужно отправлять электронные письма mail() с пользовательским вводом, который содержит не-ascii (умлауты, ударения) и нелатинские (кириллица) символы в… |
японская кодировка iso-2022-jp в python и perl автор: чайник | последнее сообщение от: Привет,
Я новичок в python, и в настоящее время борюсь с некоторыми
проблемы с кодировкой. Оставить комментарий
|
 в базу данных. Однако: я не уверен, как именно это сделать…
в базу данных. Однако: я не уверен, как именно это сделать…