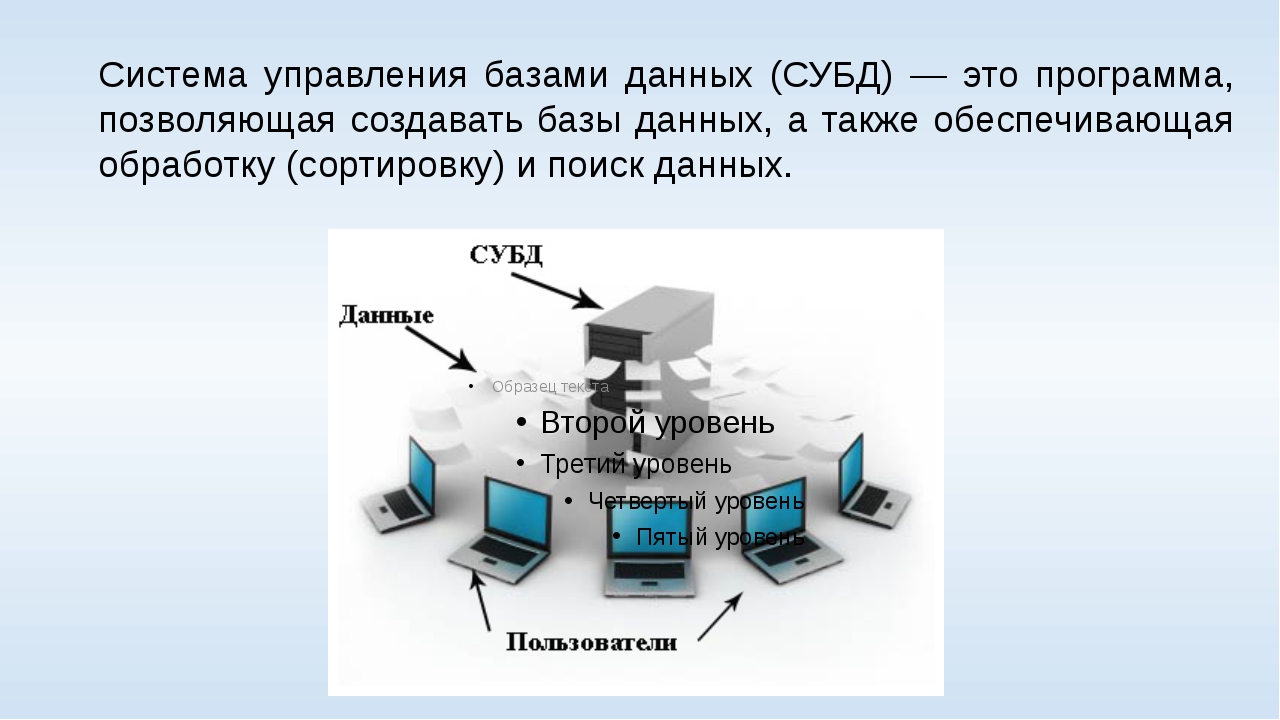
все от А до Я
К настоящему времени человечеством накоплено поистине гигантское количество информации об объектах и явлениях. Но эта информация не лежит мертвым грузом, она хранится в электронном виде и используется в базах данных. Базы данных – это часть информационных систем – программно-аппаратных комплексов, осуществляющих хранение и обработку огромных информационных массивов.
Малый бизнес и базы данных понятия неразделимые. Базы данных способны содержать любую возможную информацию на расстоянии буквально одного клика. Коммерческие базы данных помогают владельцам малого бизнеса систематизировать информацию о своих клиентах, сотрудниках и партнерах. Более подробную информацию можно получить по адресу: bazaemail.ru.
Точно так же БД являются интегральной составляющей электронного бизнеса. Они позволяют предпринимателям хранить и анализировать наиболее существенную информацию о товарах, услугах, продажах так, чтобы адекватно реагировать на быстро изменяющиеся условия рынка.
Зачем нужна база данных предприятий?
Базы данных предприятий предназначены для поиска новых клиентов, партнеров, проведения почтовых рассылок с целью продажи товаров и услуг, приглашения к участию в презентации, конференции, стимулирования сбыта и др.
В первую в базах данных представлена подробная информация по интересующим Вас отраслям деятельности той или иной частной организации. А информация, как известно, в наше время имеет очень большое значение. И тот, кто владеет этой информацией, может зарабатывать деньги, как для себя, так и для своего бизнеса.
Каждая база данных содержит:
- Название компании,
- Адреса,
- Телефоны,
- Факс,
- e-mail,
- Сайт организации,
- Имя и должность руководителя,
- Информацию об экспорте и импорте организации,
- Подробное описание видов деятельности предприятия.
Если база данных подобрана грамотно и верно, то процент откликов будет достаточно высок. Однако отклики содержатся не только от базы данных, но и содержания сообщений, которые осуществляет почтовая рассылка. Поэтому закономерность, которая существует в мире почтовых услуг, вполне верна – чем больше и шире база данных предприятий, тем меньший процент откликов получает отправитель.
Однако отклики содержатся не только от базы данных, но и содержания сообщений, которые осуществляет почтовая рассылка. Поэтому закономерность, которая существует в мире почтовых услуг, вполне верна – чем больше и шире база данных предприятий, тем меньший процент откликов получает отправитель.
Практическая цель точной информации, которую предоставляет база данных предприятий России, основана на получении достоверных сведений по ряду целевых признаков. Реестр предприятий РОССТАТ составлен с учетом наиболее полных данных по контактам юридических лиц, содержит данные по учредителям юридическим лицам.
Кроме того, содержится информация о количестве учредителей юридических лиц с указанием гражданства. Выборка сформирована в удобном табличном виде с разделением данных по отраслевому, региональному или адресному критериям.
При помощи базы данных, возможно, определить: географию хозяйствующего субъекта, систему организации и формы управления, что дает возможность включения полученной информации для аналитического обзора или в короткие сроки получить доступ ко всем имеющимся адресам и контактам.
Постоянное обновление базы позволяет своевременно вносить коррективы в собственные списки промышленных предприятий без риска использования устаревших данных.
Информация о клиентах
В базе данных обязательно должна присутствовать информация о клиентах, включая полные имена и достоверные контактные данные. Записи для бизнес-клиентов могут содержать информацию о типе и величине их бизнеса, а также о сфере деятельности. Что касается потребителей, то в этом случае ценна любая информация относительно покупательной способности и предпочтениях вашей целевой аудитории.
Анализ транзакций
Для успешного ведения электронного бизнеса необходимо обладать о своих клиентах определенным объемом сущностной информации. Тщательно отслеживая и фиксируя запросы пользователя, историю его покупок, просмотры тех или иных товаров, вы можете составить детальную картину личных предпочтений и покупательного потенциала своих клиентов.
Персонализация
Составление детальных личностных профилей позволит вам персонализировать предложения, основываясь на покупательских предпочтениях ваших клиентов. Если ваш сайт продает, например, спортивную одежду, вы можете провести рекламную компанию, рассчитанную на молодых женщин информация о которых содержится в вашей базе данных, предпочитающих спортивные костюмы определенного бренда.
Если ваш сайт продает, например, спортивную одежду, вы можете провести рекламную компанию, рассчитанную на молодых женщин информация о которых содержится в вашей базе данных, предпочитающих спортивные костюмы определенного бренда.
Для назначения цены также можно использовать информацию из базы данных – например, для определенной категории клиентов БД может возвращать цену со скидкой на некоторые виды товаров.
Где же могут применять базы данных?
Практически везде. Почтовая отправка сообщений всегда осуществляется по базе данных. Особенно важна здесь персонализация. Человеку приятно, когда рекламодатель обращается к нему по имени, знает, чем он увлекается и чем живет.
Особенно важна здесь персонализация. Человеку приятно, когда рекламодатель обращается к нему по имени, знает, чем он увлекается и чем живет.
Для того чтобы понять что же нужно конкретному человеку, очень часто организуются различные опросы, выдаются анкеты или осуществляется обзвон по телефону. Ведь конкретно из базы данных можно взять всю необходимую информацию, и даже графические элементы, контакты, какую-то уникальную и индивидуальную информацию о каждом человеке и многое другое.
Даже в Гражданском кодексе России указано, что база данных – это специально показанная в беспристрастной форме соединение нескольких самостоятельных материалов, классифицированные так, что все предоставленные материалы могут быть найдены и обработаны с помощью электронной почты и другой вычислительной техники.
База данных предприятий существует в некоторых вариантах. Это может быть созданная в одной структуре совокупность определенных данных, в которые можно добавлять информацию или менять ее, в связи с изменившимися данными. Это может быть уже построена логически цепочка, благодаря которой удобно и быстро можно отправить почтовое сообщение посредством сети Интернет.
Это может быть уже построена логически цепочка, благодаря которой удобно и быстро можно отправить почтовое сообщение посредством сети Интернет.
В наше время есть много программных обеспечений для работы с базами данных.
В таких случаях можно использовать более простые программные обеспечения. Например, Microsoft Excel. C появлением Excel 2013, в программе появились новые инструменты работы с таблицами. С их помощью можно связывать ячейки и диаграммы, создавать обновляемые отчеты и выполнять поиск. С этими возможностями процесс создания баз данных и таблиц становится более упрощенным. И можно получить доступ к отчетам и данным за короткое время.
Таким образом, можно сделать вывод, что базы данных облегчают работу с большим объемом информации и его хранением и являются неотъемлемой частью организации работы любого предприятия.
Для чего нужна база данных на сайте: простое и понятное объяснение
Здравствуйте, уважаемые читатели блога start-luck. Сегодня обойдемся без шуток. Я решил написать статью на достаточно серьезную и сложную тему. Постараюсь изложить ее так, чтобы каждому было понятно. Вопрос непростой, а потому вам придется настроиться на восприятие, а мне очень постараться, чтобы дать ответы на все вопросы.
Мы поговорим о том, для чего нужна база данных на сайте. Какие преимущества она дает и как работает. Постараюсь сделать публикацию простой и не слишком нудной, но ничего обещать не могу. Итак. Приступим.
Зачем она нужна
Прежде чем создать сайт, человек в идеале сначала изучает html, затем css, ну и потом JavaScript. Первое помогает справиться с текстом, второе определяет дизайн, третье дает возможность создавать скрипты. Кстати, такой подход – явная заявка на успех в интернет-сфере.
Но многие обходятся совсем без этого, выбирая свою сферу. Сейчас эти этапы не так важны. Существует множество готовых решений и любой человек, даже без особенных навыков может просто и быстро обрести свой проект. Но мы говорим об идеальном мире.
Существует множество готовых решений и любой человек, даже без особенных навыков может просто и быстро обрести свой проект. Но мы говорим об идеальном мире.
Даже если вы все это постигли и на данный момент создали портал по всем правилам, пока его нельзя назвать динамическим. Им он станет после того, как перестанет просто лежать на сервере, а начнет обновляться.
Делать это помогает система управления или движок. По правилам, вы сами должны его спрограммировать, но сейчас существует множество готовых CMS. К примеру, WordPress, о котором я неоднократно говорил. Он-то и помогает управлять контентом и сайтом. Добавлять новые статьи и менять что-то на сайте даже без знаний кода.
Давайте предположим, вы создаете не сайт, а библиотеку. Это поможет разобраться с БД (базами данных). Вполне реальную библиотеку с полками и всем прочим. Человек приходит и видит где стоят книги, это видимая часть контента, то есть сами статьи на портале.
Как посетителю найти конкретное издание? Если вы бывали в публичных библиотеках, то возможно видели картотеки. А если писали диплом самостоятельно, то наверняка знаете, что это такое и зачем они нужны.
А если писали диплом самостоятельно, то наверняка знаете, что это такое и зачем они нужны.
Картотека – это архив с небольшими записочками, в которые внесена вся основная информация о изданиях: где расположена книга, кто ее автор, в каком году он ее написал. Это и есть база данных. Только сейчас мы говорим о базе для сайта.
Когда книг не много, то можно обойтись и без архива, у вас все на виду. Вы найдете необходимый материал, но когда у вас огромный портал вы или ваш читатель потратит уйму времени, пока не отыщет нужное среди книг и полок.
Существуют движки, которые себе в преимущество ставят то, что они обходятся без Mysql. Но что это значит? По факту, где-то должен располагаться текстовый документ, в котором все равно находится информация о новых публикациях.
Вернемся к аналогии. Представьте, вы приходите в библиотеку, просите Бунина, а вам предлагают поискать его в трехметровом списке. Сначала букву нужную найди и не пропустить, затем произведение, потом нужный год выпуска.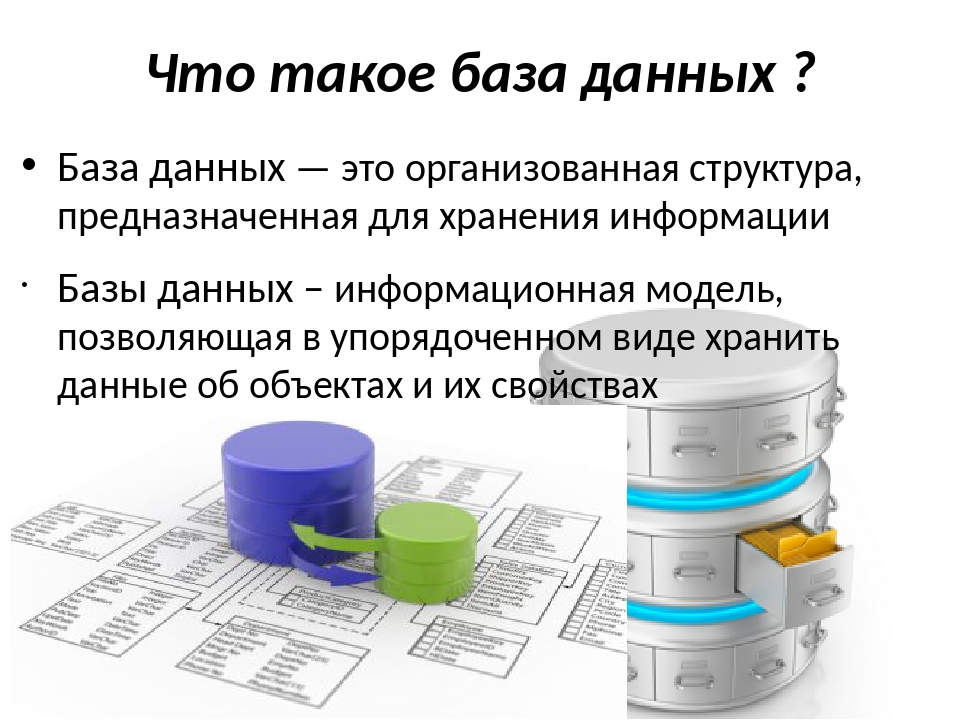 Приходится пробегать глазами от начала и до конца. Такое отношение мало кому понравится.
Приходится пробегать глазами от начала и до конца. Такое отношение мало кому понравится.
Реляционная база данных
Итак, с базами данных разобрались, думаю вы поняли что это такое. Но существуют разные виды хранения информации, ведь списки можно составлять по-разному. Давайте разбираться в этом.
Вообще SQL это язык программирования, свод правил, которым должна подчиняться база данных. MySQL, это программа для работы с базой данных, подчиняющаяся правилам SQL. Давайте теперь разбираться по пунктам.
Эдгар Кодд сформулировал 12 законов, на которых строится реляционная база данных SQL. Не хочу грузить вас этими правилами, они не так уж важны и я боюсь, что простым языком их никак не объяснить. В конце концов, важно лишь понять основные принципы.
Не в моих силах предоставить вам теорию в полной мере. Для этого нужны более внушительные труды. Я покажу лишь основную информацию и отличия реляционной базы на конкретном примере.
Предположим у вас есть таблица с несколькими графами: порядковый номер (код), название книги и ее расположение (слева, справа на полке).
Код является первичным ключом, а название книги и расположение – теми полезными сведениями, которые и нужно получить посредством запросов к базе. Реляционная база создана на основе взаимосвязи между несколькими таблицами.
Чтобы каждый раз не писать «слева» и «справа», ведь числа читать проще не только нам, но и машинам. Существует другая таблица, в которой обозначено лево – цифрой 1, а право – 2. В итоге, третья колонка у нас состоит только из этих обозначений: 1 и 2, но чтобы получить расшифровку, нужно обратиться к третьей таблицу, получить внешний ключ.
Именно на этом принципе и строятся реляционные таблицы. Все они взаимосвязаны. Без одной вам не получить информацию о другой.
SQL и MySQL
Из предыдущей главы, думаю, в общих чертах вы поняли, что такое SQL. Переводится эта аббревиатура как язык структурированных запросов. Создана она для того, чтобы работа с разными типами баз данных строилась по одному стандарту, а значит и управлять бы ей стало легче.
Что же можно делать при помощи этого языка? Создавать и менять структуру базы, сортировать, добавлять новые записи и так далее. Однако, не все так просто. Зная язык программирования его нужно еще и применять каким-то образом.
Зная html и css многие все равно обращаются к таким программам как Dreamweaver или Notepad++, чтобы было удобнее и быстрее работать. В конце концов они открывают хотя бы обычный блокнот, чтобы выполнять эти операции.
С SQL точно также. Для того чтобы его использовать, на хостинге устанавливается MySQL, через которую и ведется вся работа.
Поведем итоге. Существует множество типов баз данных, но самой популярной признана реляционная. Для работы с ней необходимо знать язык программирования SQL и хоть он не единственный язык, но, опять же, самый распространенный. И наконец вы можете обойтись без MySQL, в интернете достаточно и других программ, но работать с ней будет легче.
Стоит ли его изучать
Чем полезно знание этого языка? Скажу вам так, если вы знаете его и умеете пользоваться БД, то можете достичь невероятной скорости поиска нужной информации, избежать проблем с параллельным доступом, то есть вам будет совершенно все равно, когда несколько людей захочет поискать что-то одно.
Решать вам стоит ли срочно хвататься за книги. Если вы хотите научиться создавать мощные проекты с огромным бюджетом и потому по всем правилам, то да, тем более, что это не займет так уж много времени. Особенно если сравнивать с силами.
Могу предложить вам две книги для изучения языка. «SQL за 10 минут» Бена Форта. Учебник с краткой информацией и конкретными примерами. Напрягать мозг придется минимально, особенно если у вас уже есть какие-то знания, то это лучший вариант.
Второй учебник более основателен. Называется «SQL для чайник
Что такое база данных веб-сайта и зачем это нужно.
Любой человек, который занимается веб-разработкой рано или поздно сталкивается с таким понятием как база данных веб-сайта.
Давайте будем разбираться, что такое база данных и зачем это нужно.
Предположим, что мы решили создать какой-то свой веб-сайт. Мы создали одну страницу. Предположим, что это будет страница page.html. На этой странице находится какое-то содержимое.
С течением времени сайт начинает разрастаться. На нем начинают появляться все новые и новые материалы и страниц, на которых будут храниться эти материалы становиться все больше и больше.
Возникает вопрос, как хранить все данные, которые будут отображаться на этих веб-страницах. Какую структуру организации этих данных выбрать.
1 способ. Каждый материал (страница) — отдельный html-файл.
Как вариант, это будет работать. Но, при этом возникает ряд проблем.
Что если в этой структуре файлов, нам нужно будет добавить или изменить какой-то общий элемент? Например, нужно поменять изображение в шапке сайта.
Нужно будет открывать каждый из этих файлов и в каждом из них менять путь до картинки.
Конечно, если файлов всего 3 — это сделать довольно просто.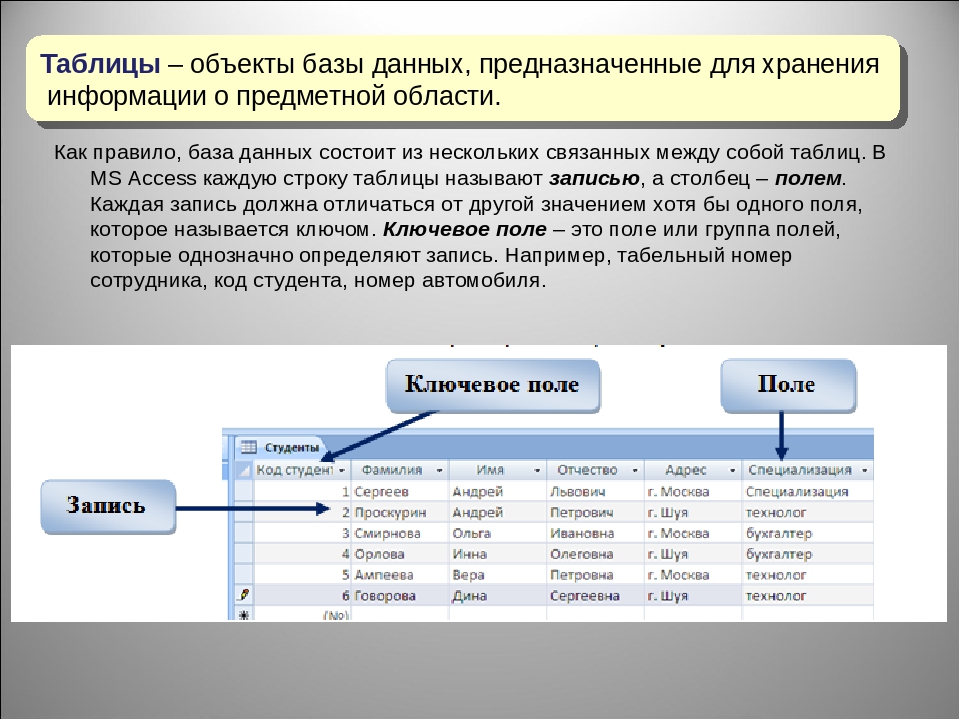 Но, если этих файлов сотни и тысячи, могут возникнуть трудности.
Но, если этих файлов сотни и тысячи, могут возникнуть трудности.
А что если у нас будет стоять задача получить какую-то статистику по этим страницам? Например, нам нужно узнать сколько всего у нас есть веб-страниц и вывести это в каком-то месте веб-сайта.
Если каждая страница у нас отдельный файл, сделать это может быть трудно.
Что если нам нужно будет организовать поиск по этим файлам?
С этим тоже могут быть трудности.
Наконец, как дать доступ на редактирование созданных html-страниц человеку, который в веб-разработке ничего не понимает. Для него это тоже будут некоторые трудности.
Из-за этих проблем, что трудно обслуживать такую структуру организации данных веб-сайта, есть другой подход как можно хранить информацию, которая будет отображаться на всех этих страницах.
В этом подходе мы исходим из того, что у нас есть только один файл. Предположим, это файл page.php.
Именно этот файл будет главным для всех страниц нашего сайта. А текст всех страниц, которые будут на этом сайте. Ссылки, даты и.т.д. мы выносим в отдельную сущность, которая называется база данных.
А текст всех страниц, которые будут на этом сайте. Ссылки, даты и.т.д. мы выносим в отдельную сущность, которая называется база данных.
По сути, база данных — это простые таблицы, которые содержат строки и столбцы. На пересечении этих строк и столбцов содержится какая-то информация. Каждый элемент, который будет на сайте, храниться в отдельном поле базы данных.
Каждая строка соответствует каждой странице.
При такой структуре мы можем настроить веб-сервер, чтобы при обращении по определенному url-адресу ему показывается каждый раз какая-то уникальная страница из базы данных.
Главное преимущество такой структуры в том, что нам теперь не нужно хранить на сервере огромное количество файлов.
Теперь у нас контент отдельно и разметка страницы тоже отдельно.
Какие мы теперь получаем преимущества:
1) Мы можем просто вносить изменения в содержимое страниц сайта за счет того, что контент размещается отдельно от структуры и логики.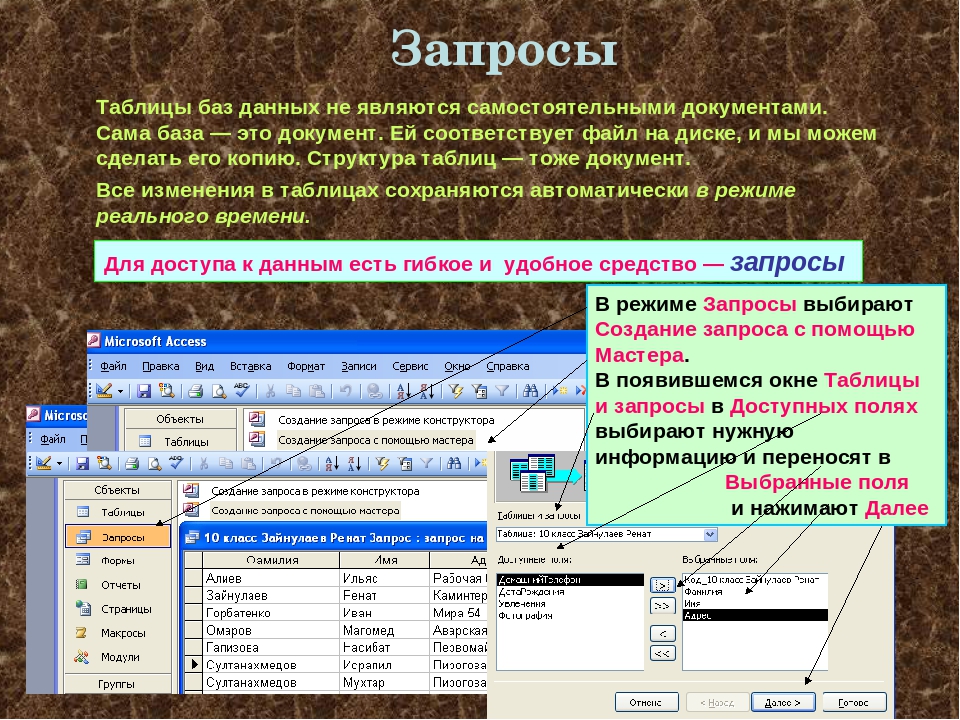
2) Скорость и простота обработки информации в базе данных. Статистика, поиск и.т.д.
3) Возможность создания панели управления для людей, которые не знакомы с веб-разработкой.
В итоге, база данных — это то место, где храниться содержимое какой-то определенной сущности. Например, мы выбрали сущности «страница» и храним информацию в базе данных, которая к этой сущности относится.
Надеюсь, что стало понятнее что такое база данных и для чего они нужны.
Не во всех случаях оправдано их использование. Если вам приходится работать с большим объемом каких-то данных, тот первый вопрос, который вам нужно себе задать: не логичнее ли будет всю эту информацию хранить в базе данных.
На этом все, желаю вам удачно проектировать структуру своего веб-сайта и удачной работы.
Наборы данных, массивы данных, банки данных, базы данных – что это такое и как их различать?
Закон.Ру – официально зарегистрированное СМИ. Ссылка на настоящую статью будет выглядеть следующим образом: Рожкова М.А. Наборы данных, массивы данных, банки данных, базы данных – что это такое и как их различать? [Электронный ресурс] // Закон.ру. 2020. 6 июля. URL: https://zakon.ru/blog/2020/7/6/nabory_dannyh_massivy_dannyh_banki_dannyh_bazy_dannyh__chto_eto_takoe_i_kak_ih_razlichat
Ссылка на настоящую статью будет выглядеть следующим образом: Рожкова М.А. Наборы данных, массивы данных, банки данных, базы данных – что это такое и как их различать? [Электронный ресурс] // Закон.ру. 2020. 6 июля. URL: https://zakon.ru/blog/2020/7/6/nabory_dannyh_massivy_dannyh_banki_dannyh_bazy_dannyh__chto_eto_takoe_i_kak_ih_razlichat
(настоящая работа представляет собой часть статьи: Рожкова М.А. О правовых аспектах использования технологий: MadTech (проблемы правового режима данных) // Хозяйство и право. 2020. № 8).
Информационные технологии предполагают использование различных видов данных. Юридические проблемы здесь возникают вследствие неоднозначности в вопросе принадлежности прав на данные, что значительно усугубляется присутствием в составе данных персональных данных, легальность использования которых напрямую зависит от наличия правовых оснований на обработку.
Разбор некоторых сложных вопросов в обозначенной сфере следует предварить указанием на то, что право на информацию традиционно рассматривается юристами, прежде всего, в контексте конвенционных / конституционных прав, принадлежащих всем и каждому с рождения. Так, в ст. 10 Конвенции о защите прав человека и основных свобод закреплено, что каждый вправе свободно выражать свое мнение, что означает свободу не только в том, чтобы придерживаться своего мнения, но и получать и распространять информацию и идеи без какого-либо вмешательства со стороны публичных властей и независимо от государственных границ. В этом аспекте предметом дискуссий выступает обычно содержание конвенционного / конституционного права на информацию, а также возможность легальных ограничений его реализации.
Так, в ст. 10 Конвенции о защите прав человека и основных свобод закреплено, что каждый вправе свободно выражать свое мнение, что означает свободу не только в том, чтобы придерживаться своего мнения, но и получать и распространять информацию и идеи без какого-либо вмешательства со стороны публичных властей и независимо от государственных границ. В этом аспекте предметом дискуссий выступает обычно содержание конвенционного / конституционного права на информацию, а также возможность легальных ограничений его реализации.
Но на сегодняшний день актуальной стала другая – имущественная – ипостась информации, что стало следствием развития информационных технологий и становления информационного общества. Поэтому внимание цивилистов все чаще обращается к проблематике субъективных гражданских прав на информацию и введения этого имущества в гражданский оборот. При этом, как показывают проведенные исследования, определение правового режима информации оказалось довольно сложной задачей для большинства юрисдикций.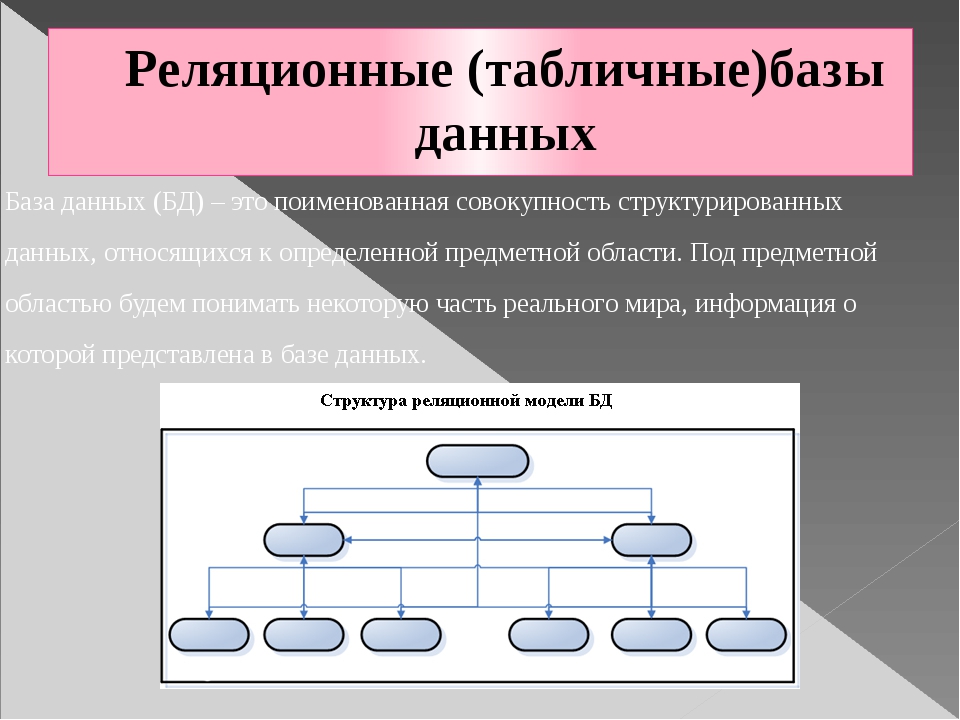
В отечественном праве разрешение вопроса принадлежности субъективных гражданских прав на информацию осложняется тем, что в 2008 г. информация была исключена из перечня объектов гражданских прав, закрепленного в ст. 128 ГК РФ. Поясняя такое законодательное решение, нужно напомнить, что при разработке Кодекса под информацией изначально понимались лишь служебная и коммерческая тайна, и когда впоследствии отношения по этому поводу были урегулированы Федеральным законом от 29.07.2004 № 98-ФЗ «О коммерческой тайне» и гл. 75 ГК РФ о секрете производства, специальное упоминание информации в ст. 128 ГК РФ, по мнению разработчиков Кодекса, стало излишним и было исключено[1]. Эта новация сослужила плохую службу, дав повод для суждений о чуть ли не легальном запрете рассматривать информацию в имущественном ключе, вследствие чего часть юристов продолжает придерживаться мнения, что информация сможет стать объектом гражданских прав только при условии ее прямого возвращения в текст ст. 128 ГК РФ.
Подобный вывод нельзя поддержать. Но его опровержение требует подробного обоснования, которое в дальнейшем может стать подспорьем при формировании правового режима данных.
1. Согласно ст. 2 Федерального закона от 27.07.2006 № 149-ФЗ «Об информации, информационных технологиях и о защите информации» (далее – Закон об информации) понятием «информация» охватываются: (1) сообщения; (2) сведения; (3) данные. Закон не делает различий между указанными понятиями рассматривая их, по сути, как равнозначные виды информации, но их сущностные отличия выявлялись мною ранее[2], поэтому здесь они будут изложены реферативно с некоторыми дополнениями.
На мой взгляд, решение большинства возникающих юридических вопросов требует учета того обстоятельства, что обработка информации может рассматриваться с двух сторон – технической (охватывая различные приемы и способы передачи, накопления, хранения и иной обработки информации, не имеющей цели использования ее содержательной составляющей) и содержательной (что связано именно со смысловой составляющей информации – аналитика данных, распространение информации и проч.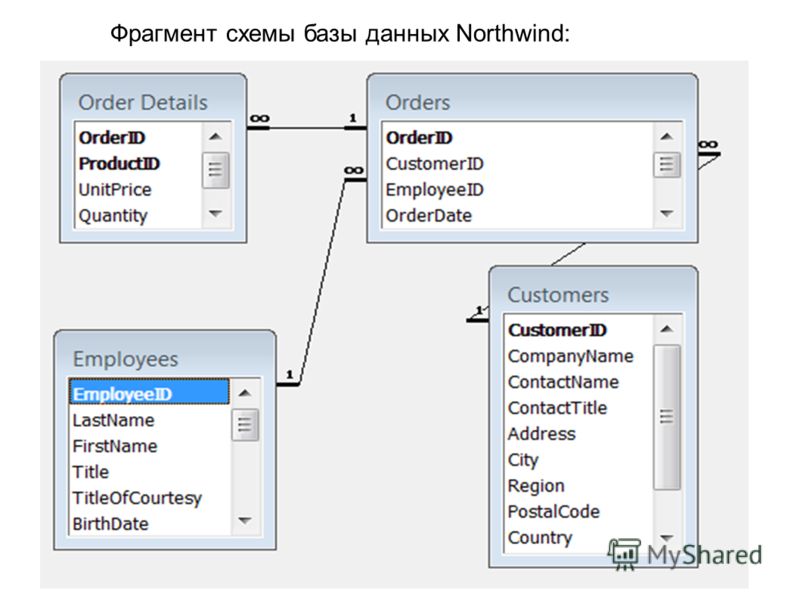 ). Следование этому разделению позволяет правильно употреблять перечисленные выше понятия.
). Следование этому разделению позволяет правильно употреблять перечисленные выше понятия.
Понятие «сообщение» приобретает значение применительно к технической стороне обработки информации и обозначает вовсе не разновидность информации, а, по сути, форму физической передачи определенных объемов информации. Это может быть, например, устное или письменное сообщение, переданное человеком. Либо речь может идти об автоматизированном процессе пространственного переноса информации: источник информации посылает сообщение, которое кодируется в одиночных или нескольких следующих друг за другом сигналах; этот сигнал (сигналы) передается по каналу связи; в приемнике информации появляется принимаемый сигнал (сигналы), который декодируется и становится принимаемым сообщением. Вследствие сказанного можно утверждать: сообщение – это лишь составляющая системы передачи информации, которая не может становится объектом гражданских прав.
Содержательная сторона обработки информации отражается в категориях «сведения» и «данные» – как раз они являются разновидностями информации. Не возводя непреодолимые границы между этими понятиями, правильно было бы их разграничивать, понимая под «сведениями» информацию, относящуюся к конкретному субъекту, объекту, факту, случаю, а под «данными» – совокупность информации, объединенную и упорядоченную по какому-либо признаку, нескольким признакам или критериям. Обе эти разновидности информации в соответствующих ситуациях способны становиться объектами гражданских прав – с момента приобретения ими имущественной ценности, на что уже обращалось внимание ранее[3].
Не возводя непреодолимые границы между этими понятиями, правильно было бы их разграничивать, понимая под «сведениями» информацию, относящуюся к конкретному субъекту, объекту, факту, случаю, а под «данными» – совокупность информации, объединенную и упорядоченную по какому-либо признаку, нескольким признакам или критериям. Обе эти разновидности информации в соответствующих ситуациях способны становиться объектами гражданских прав – с момента приобретения ими имущественной ценности, на что уже обращалось внимание ранее[3].
2. Для целей правильного разрешения цивилистических вопросов следует исходить из того, что информация имеет нематериальный (невещественный) характер, что принципиально отграничивает ее от материальных предметов, могущих стать объектами вещных прав.
Это замечание обусловлено тем, что в ряде современных теорий можно встретить заключения о сходстве информации с энергией, а то и обоснование материальности информации. Например, в теории квантовой энтропийной логики информация постулируется как физическая (материальная) категория – такая же как, например, энергия или масса. Однако при этом отмечается: «Объектом этой дисциплины является нечто, имеющее мало общего с тем, что называют информацией в обыденной жизни. Действительно, если «в быту» доминирует содержательная, смысловая сторона информации, то Квантовая энтропийная логика семантику информации вообще не рассматривает… использование постулатов теории Квантовой энтропийной логики способно исключить грубые логические противоречия, существовавшие в квантовой механике»[4]. Идея о сходстве информации с энергией находит отражение и в социологической теории: так, в аналитической концепции постиндустриального общества обращается внимание на повышение значимости информационной компоненты в производственных процессах, сопоставлемой с ролью сырья и энергии[5]. В то же время следует учитывать и то, что основоположник кибернетики Н. Винер стоял на следующей позиции: «Информация есть информация, а не материя и не энергия.
Например, в теории квантовой энтропийной логики информация постулируется как физическая (материальная) категория – такая же как, например, энергия или масса. Однако при этом отмечается: «Объектом этой дисциплины является нечто, имеющее мало общего с тем, что называют информацией в обыденной жизни. Действительно, если «в быту» доминирует содержательная, смысловая сторона информации, то Квантовая энтропийная логика семантику информации вообще не рассматривает… использование постулатов теории Квантовой энтропийной логики способно исключить грубые логические противоречия, существовавшие в квантовой механике»[4]. Идея о сходстве информации с энергией находит отражение и в социологической теории: так, в аналитической концепции постиндустриального общества обращается внимание на повышение значимости информационной компоненты в производственных процессах, сопоставлемой с ролью сырья и энергии[5]. В то же время следует учитывать и то, что основоположник кибернетики Н. Винер стоял на следующей позиции: «Информация есть информация, а не материя и не энергия. Тот материализм, который не признает этого, не может быть жизнеспособным в настоящее время»[6].
Тот материализм, который не признает этого, не может быть жизнеспособным в настоящее время»[6].
Признание нематериальности информации позволяет утверждать, что информация является объектом, изъятым из гражданского оборота в силу естественных свойств. Подобно объектам интеллектуальных прав, не являющимся оборотоспособными по той же причине и допускающим лишь оборот исключительных прав на них и материальных носителей таких объектов (п. 4 ст. 129 ГК РФ), информация не отличается свойством оборотоспособности – это свойство можно признавать только за правами на информацию и носителями информации (вещами).
Заключение об отсутствии у информации свойства оборотоспособности вряд ли вызовет у юристов серьезные возражения, пока не встанет вопрос о допустимости передачи (перехода) информации. Дело в том, что отсутствие у объекта свойства оборотоспособности исключает возможность легального перехода (передачи) самого этого объекта – допускается лишь переход прав на такой объект. Такой подход прямо закреплен в ГК РФ в отношении имеющих нематериальную природу объектов интеллектуальных прав. Следовательно, в русле отечественной правовой доктрины недопустимым должен признаваться и переход (передача) информации от одного лица к другому – возможен лишь переход прав на информацию или материальных носителей информации (вещей).
Такой подход прямо закреплен в ГК РФ в отношении имеющих нематериальную природу объектов интеллектуальных прав. Следовательно, в русле отечественной правовой доктрины недопустимым должен признаваться и переход (передача) информации от одного лица к другому – возможен лишь переход прав на информацию или материальных носителей информации (вещей).
Предвосхищая критику предложенного подхода, следует вновь обратить внимание на необходимость различать техническую и содержательную стороны обработки информации. Без всяких сомнений можно говорить о передаче информации в техническом смысле, понимая ее как сообщение (форму физической передачи определенных объемов информации), – именно в этом контексте сформулированы, например, положения законодательства о связи. Однако, когда значимой становится содержательная составляющая информации, то речь может идти о сведениях или данных, которые вполне способны стать объектом гражданских прав, но сами не могут быть допущены в гражданский оборот – только права на них.
В развитие сказанного надо подчеркнуть, что допустимость возникновения в отношении информации субъективных гражданских прав находит прямое подтверждение в Федеральном законе от 27.07.2006 № 149-ФЗ «Об информации, информационных технологиях и о защите информации» (далее – Закон об информации), в котором предпринята попытка сформулировать основы правового режима информации.
К сожалению, данную попытку сложно назвать удачной – Закон об информации, по сути, пренебрегает градацией правоотношений на публичные и частные, игнорирует положения отечественной цивилистической доктрины, и, конечно, не учитывает разницу между техническими и содержательными аспектами обработки информации. В частности, с учетом изложенного ошибочным следует признать содержащееся в Законе об информации положение об обладании лицом самой информацией, а не правом на информацию – положение, которое породило термин «обладатель информации» вместо «правообладатель информации» (нельзя тут не вспомнить и пресловутого «владельца сайта» вместо юридически корректного «правообладателя сайта»). Отмеченные недостатки не позволили расценивать Закон об информации как содержащий адекватное и эффективное регулирование гражданско-правовых отношений по поводу информации.
Отмеченные недостатки не позволили расценивать Закон об информации как содержащий адекватное и эффективное регулирование гражданско-правовых отношений по поводу информации.
3. Сегодня в литературе можно обнаружить большое количество определений, даваемых понятию «данные». При этом разные авторы акцентируют внимание на различных нюансах наподобие источников данных, форматов и типов данных, способов их обработки и проч.
В этих условиях весьма неожиданным стало предложение провести в законодательстве четкий рубеж между понятиями «данные» и «информация», «поскольку их отождествление вступает в противоречие с существующей технологической реальностью»[7].
А.И. Савельев ранее рассматривал категории «сведения», «сообщения», «данные» как разновидности информации: «Так, сведения представляют собой информацию, рассматриваемую в содержательном аспекте, т.е. безотносительно к ее восприятию и использованию В то же время сообщение представляет собой информацию, рассматриваемую в коммуникативном аспекте, т. е. как обмен сведениями, часть процесса между пользователями. Понятие «данные» (data) обычно используется применительно к информации, сгенерированной техническими устройствами или введенной в память компьютера»[8]. Сегодня автор пишет о принципиальных различиях между понятиями «данные» и «информация», ссылаясь на дефиниции, содержащиеся в разных стандартах Международной организации по стандартизации: «…данные – это поддающееся многократной интерпретации представление информации в формализованном виде, пригодном для передачи, связи или обработки. При этом информация – это результат интерпретации (смысл) такого представления»[9]. И предлагает по-иному рассматривать соотношение понятий «данные» и «информация»: по его мнению, данные не являются разновидностью информации – информация является результатом интерпретации данных.
е. как обмен сведениями, часть процесса между пользователями. Понятие «данные» (data) обычно используется применительно к информации, сгенерированной техническими устройствами или введенной в память компьютера»[8]. Сегодня автор пишет о принципиальных различиях между понятиями «данные» и «информация», ссылаясь на дефиниции, содержащиеся в разных стандартах Международной организации по стандартизации: «…данные – это поддающееся многократной интерпретации представление информации в формализованном виде, пригодном для передачи, связи или обработки. При этом информация – это результат интерпретации (смысл) такого представления»[9]. И предлагает по-иному рассматривать соотношение понятий «данные» и «информация»: по его мнению, данные не являются разновидностью информации – информация является результатом интерпретации данных.
Последнее предложение является хорошей иллюстрацией к утверждению о необходимости четкого понимания, о каком аспекте обработки информации идет речь – техническом или содержательном. В изложенных А.И. Савельевым дефинициях речь идет о технической стороне обработки информации, в рамках которой под интерпретацией данных понимается «перевод» данных в понятный для машины (компьютера) формат, что позволяет осуществить машинную обработку необходимой информации. Сомнительно, что подобное правило нуждается в отражении его в действующем законодательстве. При этом является очевидным, что, поскольку ничто здесь не влияет на содержательную сторону обработки информации, отсутствуют сколь-нибудь серьезные основания отвергать аксиому, согласно которой «информация» является родовым понятием для понятия «данные».
В изложенных А.И. Савельевым дефинициях речь идет о технической стороне обработки информации, в рамках которой под интерпретацией данных понимается «перевод» данных в понятный для машины (компьютера) формат, что позволяет осуществить машинную обработку необходимой информации. Сомнительно, что подобное правило нуждается в отражении его в действующем законодательстве. При этом является очевидным, что, поскольку ничто здесь не влияет на содержательную сторону обработки информации, отсутствуют сколь-нибудь серьезные основания отвергать аксиому, согласно которой «информация» является родовым понятием для понятия «данные».
Применительно к аргументации разбираемого предложения хотелось заметить следующее. Общая дефиниция понятия «данные» сформулирована в упоминаемом А.И. Савельевым терминологическом словаре по информационным технологиям[10] для целей этого словаря максимально широко – чтобы охватить все аспекты обработки данных в рамках информационных технологий. Это связано также и с тем, что понятие «данные» (англ. – data) является составляющей большого количества других значимых в сфере информационных технологий понятий, которым дано определение в этом словаре: data acquisition, data administration, data analysis, data attribute, data authentication, data bank, data breakpoint, data circuit, data collection, data communication и т.д. При этом важно заметить, что упомянутом словаре нередко дается несколько дефиниций одного и того же термина, что обусловлено многоаспектностью значительного числа понятий, используемых в области информационных технологий. Это коснулось и основополагающей категории «информация»: так, в контексте обработки информации (англ. – information processing) информация понимается как «знание об объектах, таких как факты, события, вещи, процессы или идеи, включая понятия, которые в определенном контексте имеют особое значение», а в контексте теории информации (англ. – information theory) – как «знание, которое уменьшает или устраняет неопределенность в отношении наступления определенного события из данного набора возможных событий».
Это связано также и с тем, что понятие «данные» (англ. – data) является составляющей большого количества других значимых в сфере информационных технологий понятий, которым дано определение в этом словаре: data acquisition, data administration, data analysis, data attribute, data authentication, data bank, data breakpoint, data circuit, data collection, data communication и т.д. При этом важно заметить, что упомянутом словаре нередко дается несколько дефиниций одного и того же термина, что обусловлено многоаспектностью значительного числа понятий, используемых в области информационных технологий. Это коснулось и основополагающей категории «информация»: так, в контексте обработки информации (англ. – information processing) информация понимается как «знание об объектах, таких как факты, события, вещи, процессы или идеи, включая понятия, которые в определенном контексте имеют особое значение», а в контексте теории информации (англ. – information theory) – как «знание, которое уменьшает или устраняет неопределенность в отношении наступления определенного события из данного набора возможных событий». Процитированная А.И. Савельевым иная дефиниция понятия «информация» сформулирована для целей другого словаря – терминологического словаря по системам и программным разработкам[11], и попросту отражает другой аспект этого понятия.
Процитированная А.И. Савельевым иная дефиниция понятия «информация» сформулирована для целей другого словаря – терминологического словаря по системам и программным разработкам[11], и попросту отражает другой аспект этого понятия.
В развитие изложенного надо заметить, что в упомянутом словаре по информационным технологиям применительно к понятию «данные» сделана специальная оговорка о том, что данные могут обрабатываться как людьми, так и техническими средствами. Это позволяет не соглашаться с высказываемой иногда позицией о том, что данные – это информация, предназначенная для обработки исключительно с помощью компьютера: вне всяких сомнений, аналитика данных предполагает задействование технических средств, но нельзя отрицать существование данных, которые и сегодня проходят «ручную» обработку.
4. Все увеличивающееся многообразие данных и рост объемов информации, которую нужно хранить, обрабатывать и анализировать в различных отраслях, потребовали создания принципиально новых систем складирования и хранения данных. Современные технологии позволяют осуществлять хранение:
Современные технологии позволяют осуществлять хранение:
– структурированных данных – данных, относящихся к одной предметной области и упорядоченных определенным образом с целью применения к ним различных методов машинной обработки. Классической моделью хранения структурированных данных признается таблица, состоящая из столбцов и строк;
– неструктурированных данных – разнородных данных, требующих применения специальных приемов извлечения и структуризации с тем, чтобы в отношении них могли осуществляться различные методы машинной обработки. Это данные из соцсетей, видео- и аудиофайлы, книги и журналы, метаданные, данные GPS, медицинские записи, сообщения электронной почты, данные о перемещении мобильного абонента, веб-страницы, аналоговые записи, файлы PDF и проч. Как правило, неструктурированные данные представлены в виде текста, который содержит факты, даты, цифры, и хранятся обычно в форме электронных документов. Машинная обработка таких данных возможна только тогда, когда они извлечены из электронного документа и преобразованы в понятный для машины формат, то есть интерпретированы;
– слабоструктурированных (полуструктурированных) данных – данных, доступных для машинного распознавания, но требующих применения дополнительных приемов для получения конкретной информации (они определенным образом структурированы, но не имеют характерного для структурированных данных формата таблицы).
Традиционными хранилищами структурированных данных признаются банки данных (англ. – data bank) и базы данных (англ. – database). Примечательно, что отечественное законодательство регулирует связанные с ними отношения по-разному.
Под банком данных принято понимать систему специальным образом организованных данных, которые предназначены для централизованного хранения и коллективного многоцелевого использования. Отечественное законодательство не устанавливает общий правовой режим банков данных, однако в отдельных законах закрепляются организационно-правовые основы для формирования и ведения таких банков в публичных целях. Примером тому является недавно принятый Федеральный закон от 8 июня 2020 г. № 168-ФЗ «О едином федеральном информационном регистре, содержащем сведения о населении Российской Федерации».
Под базой данных принято понимать совокупность данных, предназначенную для длительного хранения в особом, организованном виде, который определяется структурой (схемой) этой базы данных и правилами ее управления. В отечественном законодательстве для целей установления правовой охраны базу данных предложено понимать как совокупность самостоятельных материалов, систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью компьютера (абз. 2 п. 2 ст. 1260 ГК РФ).
В отечественном законодательстве для целей установления правовой охраны базу данных предложено понимать как совокупность самостоятельных материалов, систематизированных таким образом, чтобы эти материалы могли быть найдены и обработаны с помощью компьютера (абз. 2 п. 2 ст. 1260 ГК РФ).
Часть четвертая ГК РФ закрепляет положение, согласно которому не всякая база данных способна получить правовую охрану в качестве объекта интеллектуальных прав – лишь в определенных законом случаях база данных может стать объектом авторских и (или) смежных прав. Для этого база данных должна отвечать критериям, установленным в гл. 70 ГК РФ «Авторское право» или § 5 гл. 71 ГК РФ «Право изготовителя базы данных». Причем следует специально подчеркнуть: объектом охраны здесь выступают вовсе не составляющие базу «материалы».
По смыслу п. 2 ст. 1260 ГК РФ база данных становится объектом авторских прав, если при подборе и компоновке ее составляющих (то есть при определении структуры (схемы) базы данных) был реализован новаторский подход, использовались оригинальные творческие идеи, креативность. Иначе говоря, охраняется именно порядок подбора и компоновки составляющих базы данных, но не ее содержание, и не имеет абсолютно никакого значения, какие объекты входят в ее состав – фотографии, персональные данные или литературные опусы – речь идет только о подборе или компоновке при структурировании базы данных. Вследствие сказанного и передача авторских прав на базу данных предусматривает передачу прав на порядок подбора и компоновки, но никак не прав на содержащиеся в базе данные.
Иначе говоря, охраняется именно порядок подбора и компоновки составляющих базы данных, но не ее содержание, и не имеет абсолютно никакого значения, какие объекты входят в ее состав – фотографии, персональные данные или литературные опусы – речь идет только о подборе или компоновке при структурировании базы данных. Вследствие сказанного и передача авторских прав на базу данных предусматривает передачу прав на порядок подбора и компоновки, но никак не прав на содержащиеся в базе данные.
По смыслу п. 1 ст. 1334 ГК РФ база данных становится объектом смежных прав, если она является результатом существенных финансовых, материальных, организационных или иных вложений (инвестиций) изготовителя базы в ее создание. Очевидно, что для такой базы данных главенствующее значение имеет накопление и обработка значительных объемов информации, но правовая охрана предоставляется опять-таки не содержанию, а, по сути, целостности базы данных: в силу подп. 4 п. 1 ст. 1304 ГК РФ база данных охраняется от несанкционированного извлечения и повторного использования составляющих ее содержание материалов. В то же время положение, согласно которому исключительное право изготовителя базы признается и действует независимо от наличия прав иных лиц на составляющие базу данных материалы (п. 2 ст. 1334 ГК РФ), позволяет говорить о том, что изготовитель базы может вовсе не являться обладателем прав на данные, включенные в состав этой базы: так, множество лиц могут одновременно собирать и хранить данные, полученные из одних и тех же открытых источников. В этих условиях передача изготовителем прав на базу данных, являющуюся объектом смежных прав, не предполагает автоматической передачи прав и на содержащиеся в этой базе данные.
4 п. 1 ст. 1304 ГК РФ база данных охраняется от несанкционированного извлечения и повторного использования составляющих ее содержание материалов. В то же время положение, согласно которому исключительное право изготовителя базы признается и действует независимо от наличия прав иных лиц на составляющие базу данных материалы (п. 2 ст. 1334 ГК РФ), позволяет говорить о том, что изготовитель базы может вовсе не являться обладателем прав на данные, включенные в состав этой базы: так, множество лиц могут одновременно собирать и хранить данные, полученные из одних и тех же открытых источников. В этих условиях передача изготовителем прав на базу данных, являющуюся объектом смежных прав, не предполагает автоматической передачи прав и на содержащиеся в этой базе данные.
Резюмируя, следует признать, что законодательство, регулирующее отношения по поводу банков данных и баз данных, не создает прочных правовых основ для перехода (передачи) прав на сами данные.
5. В развитие вышеизложенного следует подчеркнуть, что наибольшая потенциальная полезность сегодня усматривается за неструктурированными данными, в том числе «сырыми» данными (англ. – raw data), под которыми понимаются необработанные или обработанные в минимальной степени данные. В новейших системах хранения данных, в частности, в объектных хранилищах (англ. – object storage), накапливаются и сохраняются огромные объемы информации, которые используются разными организациями в различных целях. При этом применительно к этой сфере отмечается следующее: «…организации вынуждены обмениваться массивами данных, продавая их, использовать в качестве вклада по договорам о совместной деятельности и, разумеется, защищать от неправомерных посягательств третьих лиц. Появляются специализированные биржи (маркетплейсы) данных и другие посредники на рассматриваемом рынке, предоставляющие соответствующие сервисы (Data-as-a-Service)»[12]. То есть можно говорить о том, что в условиях отсутствия адекватного гражданско-правового регулирования отношений по поводу информации формируется «рынок оборота данных».
Для целей разрешения возникающих на практике правовых проблем А.И. Савельев предлагает задействовать понятие «массив данных», которое, согласно его идее, должно обозначить самостоятельный оборотоспособный объект прав, нуждающийся в особом правовом режиме.
Сожалея о том, что отечественное «законодательство не содержит дефиниции понятия «массив данных» (dataset в английской терминологии)»[13], автор оставляет без внимания, что английское data set обычно переводится на русский язык как «набор данных» (set – набор, комплект), и предлагает провести четкую границу между понятиями «массив данных» и «набор данных». В обоснование своего предложения А.И. Савельев ссылается на отличия между этими категориями, подчеркивая, что понятие «набор данных», которое определено в Национальной стратегии развития искусственного интеллекта на период до 2030 года как «совокупность данных, прошедших предварительную подготовку (обработку) в соответствии с требованиями законодательства Российской Федерации об информации, информационных технологиях и о защите информации и необходимых для разработки программного обеспечения на основе искусственного интеллекта»[14] является гораздо более узким, нежели «массив данных», поскольку не включает в себя «сырые» данные.
Позиционируя «массив данных» как ценный оборотоспособный актив, требующий особого правового режима, А.И. Савельев в качестве его особенностей называет лишь общеизвестные характеристики информации и больших данных (упоминаются подразделение источников информации на технические и социальные, цифровая форма информации, потенциальная коммерческая ценность информации и проч.) и выводит следующее определение: «массив данных – это существующая в машиночитаемой форме совокупность данных об окружающем мире и (или) о процессах, происходящих в нем, формируемая на основе источников технического или социального происхождения и обладающая действительной или потенциальной коммерческой ценностью»[15]. При этом автор оставляет за рамками своего исследования всякие критерии, которые позволили бы говорить о возникновении «массива данных» в качестве самостоятельного объекта прав, отмечая в том числе: «Сколько таких единиц данных должно присутствовать для того, чтобы сформировать массив данных, – вопрос философский»[16].
Проведенные исследования не позволяют поддержать позицию А.И. Савельева как в части заключения о допустимости оборота самих данных (что обосновывалось выше), так и в части предложения признать «массив данных» самостоятельным объектом гражданских прав. Несмотря на то, что авторские предложения нацелены, казалось бы, на разрешение актуальных, поставленных практикой проблем, вряд ли эти проблемы правильно разрешать посредством игнорирования доктринальных основ и подмены понятий.
Поясняя свою позицию в отношении предложения о создании для «массива данных» особого правового режима, должна указать следующее. Предлагаемым А.И. Савельевым понятием «массив данных» обозначаются те же самые данные, однако слово «массив» создает впечатление, что речь идет о каком-то ином, отличающемся явлении. Между тем в выражении «массив данных» слово «массив» имеет лишь вспомогательное значение, обозначая, по сути, факт обособления определенного объема информации из общей массы информации – подобное происходит, когда мы говорим о фактическом выделении вещей из общей массы таких же вещей: пакет молока, цистерна бензина, вагон зерна. С учетом этого представляется абсолютно безосновательным вводить в законодательство специальное понятие «массив данных», подменяя тем самым понятие «данные», и тем более рассматривать такой «массив» как самостоятельный оборотоспособный объект и устанавливать для него самостоятельный правовой режим.
С учетом этого представляется абсолютно безосновательным вводить в законодательство специальное понятие «массив данных», подменяя тем самым понятие «данные», и тем более рассматривать такой «массив» как самостоятельный оборотоспособный объект и устанавливать для него самостоятельный правовой режим.
Несмотря на изложенные критические замечания, вне всяких сомнений, поддержки заслуживает общий посыл статьи А.И. Савельева: для целей нормального функционирования цифровой экономики первоочередной задачей является создание гражданско-правового режима информации и данных, что позволит эффективно развиваться рынку использования данных (в том числе и больших данных), который имеет огромное значение абсолютно для всех сфер.
Другие работы автора в открытом доступе – http://rozhkova.com/all.html
P.S. лента новостей IP CLUB в сфере права интеллектуальной собственности и цифрового права (IP & Digital Law) в:
facebook – https://www.facebook.com/ipclubin
Вконтакте – https://vk.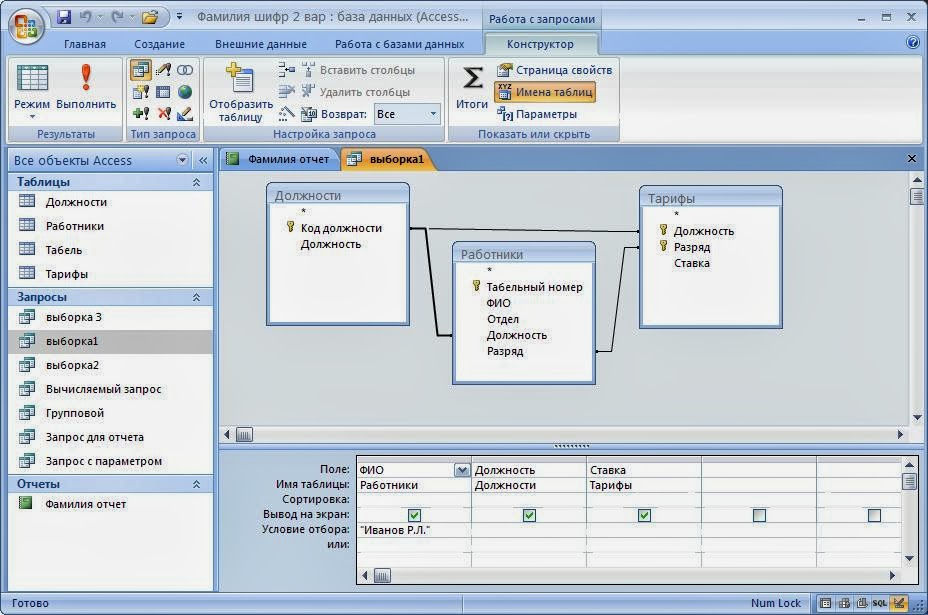 com/ipclubin
com/ipclubin
telegram – https://t.me/ipclubin
[1] Рожкова М.А. Персональные и неперсональные данные как объекты гражданских прав // Хозяйство и право. 2019. № 5.
[2] Рожкова М.А. Об имущественных правах на нематериальные объекты в системе абсолютных прав (часть третья – права на сведения и данные как разновидности информации) [Электронный ресурс] // Закон.ру. 2019. 14 января. (0,7 п.л.) URL: https://zakon.ru/blog/2019/01/14/ob_imuschestvennyh_pravah_na_nematerialnye_obekty_v_sisteme_absolyutnyh_prav_chast_tretya__prava_na_
[3] Рожкова М.А. Информация как объект гражданских прав, или Что надо менять в гражданском праве [Электронный ресурс] // Закон.ру. 2018. 6 ноября. (0,4 п.л.) URL: https://zakon.ru/blog/2018/11/06/informaciya_kak_obekt_grazhdanskih_prav_ili_chto_nado_menyat_v_grazhdanskom_prave
[4] Нестеров В.И. Информация в структуре мироздания // URL: https://metatron-nls.ru/wp-content/uploads/2017/12/fiz_osnovy1-1. pdf
pdf
[5] Bell D. Die nachindustrielle Gesellschaft. Frankfurt a. M.; N.Y.: Campus, 1989. (цит. по Бехманн Г. Общество знания – трансформация современных обществ / пер. Д.В. Ефременко // Концепция «общества знания» в современной социальной теории: Сб. науч. тр. / Отв. ред. Д.В. Ефременко. М., 2010. С. 42.
[6] Винер Н. Кибернетика, или управление и связь в животном и машине. 1948-1961. 2-е издание. М.: Наука, 1983. С. 208.
[7] Савельев А.И. Гражданско-правовые аспекты регулирования оборота данных в условиях попыток формирования цифровой экономики // Вестник гражданского права. № 1. 2020. С. 68.
[8] Савельев А.И. Комментарий к Федеральному закону от 27 июля 2006 г. № 149-ФЗ «Об информации, информационных технологиях и защите информации» (постатейный). М.: Статут, 2015. С. 17.
[9] Савельев А.И. Гражданско-правовые аспекты регулирования оборота данных в условиях попыток формирования цифровой экономики. С. 68.
[10] ISO/IEC 2382:2015(en) Information technology — Vocabulary // URL: https://www. iso.org/obp/ui/#iso:std:iso-iec:2382:ed-1:v1:en
iso.org/obp/ui/#iso:std:iso-iec:2382:ed-1:v1:en
[11] ISO/IEC/IEEE 24765:2010 Systems and software engineering — Vocabulary. К слову, этот словарь был отменен и заменен ISO/IEC/IEEE 24765: 2017 (URL: https://www.iso.org/standard/50518.html).
[12] Савельев А.И. Гражданско-правовые аспекты регулирования оборота данных в условиях попыток формирования цифровой экономики. С. 63.
[13] Там же. С. 65.
[14] Утв. указом Президента РФ от 10 октября 2019 г. № 490 «О развитии искусственного интеллекта в Российской Федерации».
[15] Савельев А.И. Гражданско-правовые аспекты регулирования оборота данных в условиях попыток формирования цифровой экономики. С. 67.
[16] Там же. С. 65 (примечание).
Парсинг базы данных: зачем нужен сбор информации | Синапс
Парсинг резюме
- личные контакты. К этому направлению мы рекомендуем относиться очень деликатно, так как парсить данные с сайта с личными номерами и почтовыми адресами не совсем законно.
 Не получится взять почту потенциального покупателя, а после отправить на нее рассылку с рекламным буклетом. Тем не менее, технически это возможно;
Не получится взять почту потенциального покупателя, а после отправить на нее рассылку с рекламным буклетом. Тем не менее, технически это возможно; - объем продаж. Важное направление, если вам необходимо знать, сколько товара в этом месяце закупили и продали конкуренты, что это были за товары и так далее. Как правило, у больших торговых агрегаторов эта информация представлена в открытом доступе. Программе нужно всего лишь проанализировать их и выстроить логистику.
Для чего это нужно?
Перед тем, как парсить данные с какого-либо сайта, вы должны обозначить цель и ответить на три вопроса:
- Какую информацию собирать? Для того, что программа приступила к поиску, нужно детально проработать критерии. Каждый парсер-сервис содержит достаточно широкий спектр фильтров, каждый из которых нужно использовать.
- Какие программы для парсинга сайтов существуют?
- В данном случае все зависит от ресурсов, которыми вы располагаете.
 Есть множество достаточно простых и недорогих программ, с которыми вы можете поработать. Произвести парсинг сайтов бесплатно можно при помощи их пробных версий, однако результат будет соответствующим. Профессиональные парсинг-программы стоят дорого, но если сбор информации не требуется постоянно, то можно работать с более дешевыми площадками, но обязательно попробовать в деле какой-нибудь серьезный продукт. Вы увидите, разница будет колоссальной.
Есть множество достаточно простых и недорогих программ, с которыми вы можете поработать. Произвести парсинг сайтов бесплатно можно при помощи их пробных версий, однако результат будет соответствующим. Профессиональные парсинг-программы стоят дорого, но если сбор информации не требуется постоянно, то можно работать с более дешевыми площадками, но обязательно попробовать в деле какой-нибудь серьезный продукт. Вы увидите, разница будет колоссальной. - Как запустить парсинг базы данных? Каждая программа имеет специальную строчку, где вам нужно будет указать “донора”. То есть место, откуда сервис будет брать информацию. Если источник не один, указывайте их все. Некоторые программы автоматически собирают данные в таблицу. Вы можете настроить парсинг данных в Excel, либо в специальный каталог на сайте или любое другое удобное место.
Как выбрать подходящую программу
В первую очередь вам нужно определиться с поставленными целями и задачами. Как правило, большинство программ являются специализированными и заранее настроены на парсинг определенной базы данных. Если вам нужно собрать данные с разных площадок, скорее всего, что сервисов тоже будет несколько.
Как правило, большинство программ являются специализированными и заранее настроены на парсинг определенной базы данных. Если вам нужно собрать данные с разных площадок, скорее всего, что сервисов тоже будет несколько.
Каким бюджетом располагает ваша компания? Напоминаем, что все представленные на рынке программы – разной ценовой категории. Простые сервисы обойдутся вам дешево, а вот профессиональный сбор данных выйдет уже намного дороже. Парсинг сайтов можно запустить бесплатно при помощи пробной версии как дешевой программы, так и крутого продукта.
Не забывайте о том, что программа должна соответствовать специфике ваших запросов. Обязательно ознакомьтесь с отзывами о работе сервисов, правда, изучать нужно мнения реальных людей, проводивших парсинг. При выборе программы смотрите, чтобы техническая поддержка работала круглосуточно, без выходных и перерывов, вне зависимости от дня года. Попробуйте найти информацию о компаниях, которые уже пользовались услугами поставщика. Если среди них окажутся крупные фирмы, значит сервису можно доверять.
Если среди них окажутся крупные фирмы, значит сервису можно доверять.
Приведем в пример несколько таких сервисов:
Targethunter
Работа с базой данных: для чего предназначены запросы
Что такое «запрос»? Что вообще подразумевают под запросом в базу данных? Для чего предназначены запросы, которые посылаются в БД?
Под запросом подразумевается подача определённых условий, в соответствии с которым БД даст ответ и предоставит интересующую информацию. Т.е. в нём посылаются определённые условия/данные, по которым отбирается необходимая информация и передаётся на сторону клиента/или заносится в БД. Ответ на вопрос «для чего предназначен объект, запрос», вы обязательно узнаете из этой статьи.Зачем нужны запросы в БД?
Необходимо дать ответ не только на вопрос, что такое запрос, но и на вопрос, для чего предназначены запросы. Они необходимы, чтобы получить информацию, которая хранится в БД. Проще говоря, запросы в БД предназначены для получения информации, нужной в отдельных случаях. Их предназначение может быть самым разным: может быть нужным для идентификации как клиента банка на стороннем сайте, или для идентификации как работника внутрикорпоративной сети, или для получения информации о состоянии профиля на сайте игры.
Их предназначение может быть самым разным: может быть нужным для идентификации как клиента банка на стороннем сайте, или для идентификации как работника внутрикорпоративной сети, или для получения информации о состоянии профиля на сайте игры.
Какие составляющие запроса есть?
Продолжаем отвечать на вопрос: для чего предназначены запросы. Для написания запросов используется SQL. Обязательно должно быть только две составляющие: SELECT и FROM. Но кроме них может использоваться и используется целый ряд других команд, которые добавляют новые требования к отбору данных и их сортированию с отображением. Эти запросы в БД предназначены для получения самой необходимой информации компьютером: что нужно найти и где это что-то нужно искать. Самая популярная составляющая после обязательных частей является Where. Where применяется для того, чтобы задать конкретные условия для отбора данных. Так, здесь можно указать идентифицирующий номер, дату рождения или другую информацию, которая является уникальной и по которой можно идентифицировать человека.
Построение запроса
Любой запрос имеет строгую иерархию построения, нарушать которую нельзя. Ибо может возникнуть ошибка. Построение будет рассказано на основе простого запроса с тремя составляющими. Сначала идут SELECT, FROM и Where. Операторы могут быть набраны как большими, так и маленькими буквами, на исполнение это не влияет. Но по правилам хорошего тона все операторы пишутся с большой буквы, а искомые условия, названия таблиц и прочее с маленькой. И так более легко ориентироваться во время просмотра кода. Возвращаясь к коду, следует отдельно рассказать, что за что отвечает.Построение запроса, как правило, не отличается при работе в различных средах разработки. Так, стоит перед вами вопрос: «для чего предназначены запросы в access» или в другой среде разработки, и можно быть уверенным, что ответы, данные в этой статье, подойдут к им всем.
Основные данные запроса
Основных составляющих частей, как уже упоминалось ранее, всего две:
- SELECT [что нужно 1, что нужно 2, что нужно 3] – используется для того, чтобы указать, какая информация нужна.
 Именно она будет передана из БД в программу, с которой работает пользователь.
Именно она будет передана из БД в программу, с которой работает пользователь. - FROM [таблица, из которой берутся данные] – указать необходимые данные мало, нужно ещё и указать, откуда они должны быть взятые. В непосредственно БД хранятся не данные, а таблицы, в которых уже сами данные. В разных таблицах могут быть одинаковые столбцы данных, чтобы такого избежать, и используют указание, откуда что берётся.
Дополнительные данные запроса и групповые операции
Для улучшения результата поиска и предоставления информации по уже полученной информации используют дополнительные команды:- Where [условия поиска] – используется, чтобы отсортировать необходимую информацию относительно определённых условий отбора.
- LIMIT [число] – используется, чтобы ограничить количество строк, которые будут взятые из таблицы.
- GROUP BY [параметр запроса] – используется для того, чтобы сгруппировать полученную информацию от БД. Но группировке может быть подана не любая информация, а только соразмерна и имеющая один и тот же тип.
 Более подробно вы можете узнать, найдя отдельную статью по GROUP BY. Групповые операции в запросах предназначены для улучшения внешнего вида предоставляемой информации и её большей читабельности.
Более подробно вы можете узнать, найдя отдельную статью по GROUP BY. Групповые операции в запросах предназначены для улучшения внешнего вида предоставляемой информации и её большей читабельности. - UNION [запрос] используется для того, чтобы поместить в запрос отдельный подзапрос. При получении довольно значительного объема информации может понадобиться и такой вариант.
- LIKE “” используют, чтобы проверить, отвечает ли маска в запросе по размерам определённым данным. Так, с её помощью может искаться человек, зарплата которого вымеряется шестизначными числами.
Пример
Само по себе понимание написанного является проблематическим, без указания соответствующего примера. Но даже один пример не может всё пояснить, и вам придётся искать довольно много информации, пока вы сможете постичь все возможности, которые предоставляет разработчикам SQL:SELECT Name, ProductNumber, ListPrice AS Price
FROM Production.Product
WHERE ProductLine = ‘R’
Разбираем предложенный мной выше код. Сначала идёт выборка необходимых данных: имени, номера продукта и страница листка цен. Причем листок цен выводится под немного другим именем – просто «цена». Данные берутся из базы данных «Продукция» из таблицы «Продукт». В целом указывать базу данных необязательно, если вы работаете только с одной, которой собственно и шлете запрос. Но если баз несколько, то обязательно указывайте, учитывая то, что компьютер просто не будет понимать, к кому вы обращаетесь или вообще проигнорирует ваш запрос и выдаст ошибку. Третья строка указывает, что выводится не вся информация, а лишь та, которая идёт в линейке продукции «Р». Вот и закончилась небольшая статья, прочитав которую вы теперь понимаете, для чего предназначены запросы.
Сначала идёт выборка необходимых данных: имени, номера продукта и страница листка цен. Причем листок цен выводится под немного другим именем – просто «цена». Данные берутся из базы данных «Продукция» из таблицы «Продукт». В целом указывать базу данных необязательно, если вы работаете только с одной, которой собственно и шлете запрос. Но если баз несколько, то обязательно указывайте, учитывая то, что компьютер просто не будет понимать, к кому вы обращаетесь или вообще проигнорирует ваш запрос и выдаст ошибку. Третья строка указывает, что выводится не вся информация, а лишь та, которая идёт в линейке продукции «Р». Вот и закончилась небольшая статья, прочитав которую вы теперь понимаете, для чего предназначены запросы.
Какая база данных подходит для вашего случая использования?
База данных позволяет нескольким пользователям быстро, безопасно и эффективно поддерживать, обновлять и редактировать сохраненную информацию. Это делает базу данных полезной для множества реальных случаев, таких как отслеживание корпоративных учетных записей, хранение огромных объемов данных из сети IoT-устройств, отслеживание систем инвентаризации вашей компании или создание веб-приложения.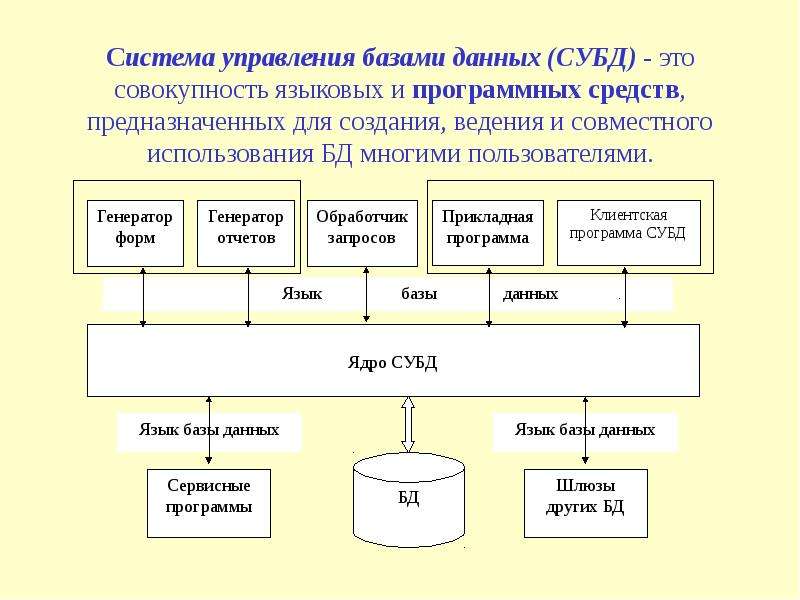 Существуют различные типы современных баз данных, каждая из которых имеет свой набор преимуществ и недостатков.Эта статья дает вам представление о наиболее популярных типах современных баз данных с высоты птичьего полета.
Существуют различные типы современных баз данных, каждая из которых имеет свой набор преимуществ и недостатков.Эта статья дает вам представление о наиболее популярных типах современных баз данных с высоты птичьего полета.
Попробуйте Xplenty, платформу конвейера данных для объединения всех ваших данных и получите полный доступ к более чем 100 нашим источникам и адресатам.
Содержание
на основе SQL против
на основе NoSQLОбзор самых популярных современных систем баз данных
Кейт подключил несколько источников данных к Amazon Redshift для преобразования, систематизации и анализа данных о клиентах.Amazon RedshiftКейт Слейтер
Старший разработчик Creative Anvil
Перед тем, как мы начали с Xplenty, мы пытались перенести данные из множества разных источников в Redshift. Xplenty помог нам сделать это быстро и легко.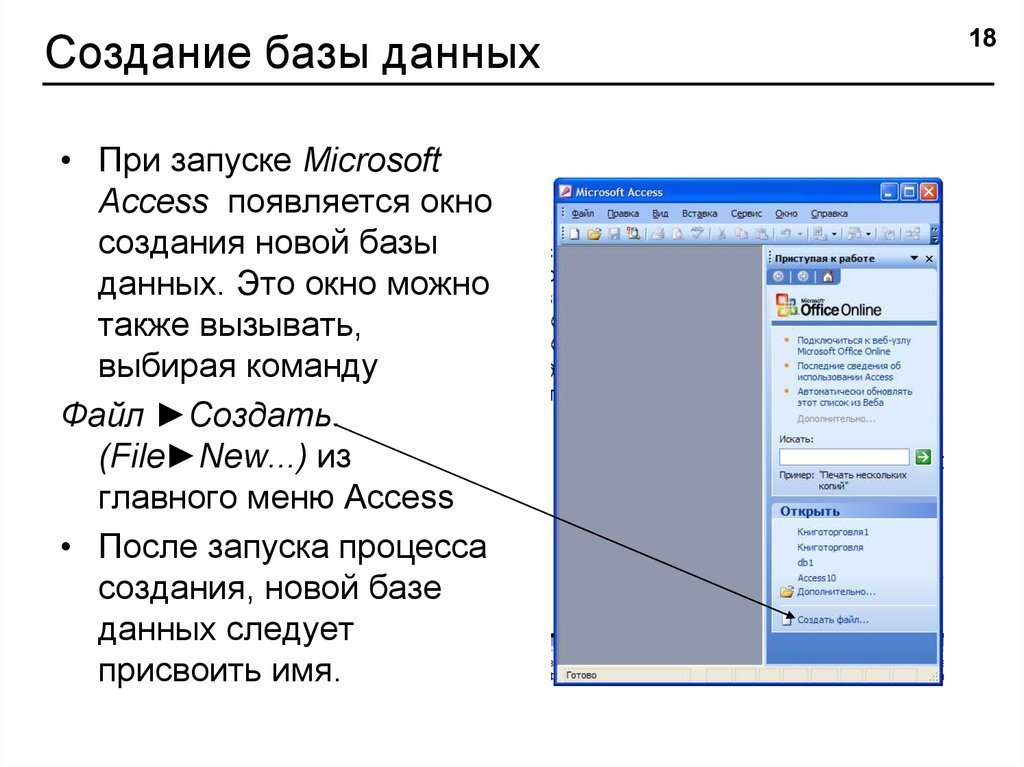 Лучшая особенность платформы — возможность манипулировать данными по мере необходимости, при этом процесс не становится чрезмерно сложным.Кроме того, поддержка отличная — они всегда отзывчивы и готовы помочь.
Лучшая особенность платформы — возможность манипулировать данными по мере необходимости, при этом процесс не становится чрезмерно сложным.Кроме того, поддержка отличная — они всегда отзывчивы и готовы помочь.
КОМПАНИИ ПО ВСЕМУ МИРУ ДОВЕРЯЮТ
Вам нравится эта статья?
Получайте отличный контент еженедельно с новостной рассылкой Xplenty!
на основе SQL и на основе NoSQL
Прежде чем углубляться в самые популярные современные варианты баз данных, важно понять разницу между системой управления реляционными базами данных (RDBMS, т.е. Базы данных SQL) и система управления нереляционными базами данных (базы данных NoSQL).
Дополнительная литература : SQL и NoSQL — чем они отличаются?
На протяжении большей части последних 40 лет предприятия полагались на системы управления реляционными базами данных (СУБД), в которых использовался язык программирования SQL.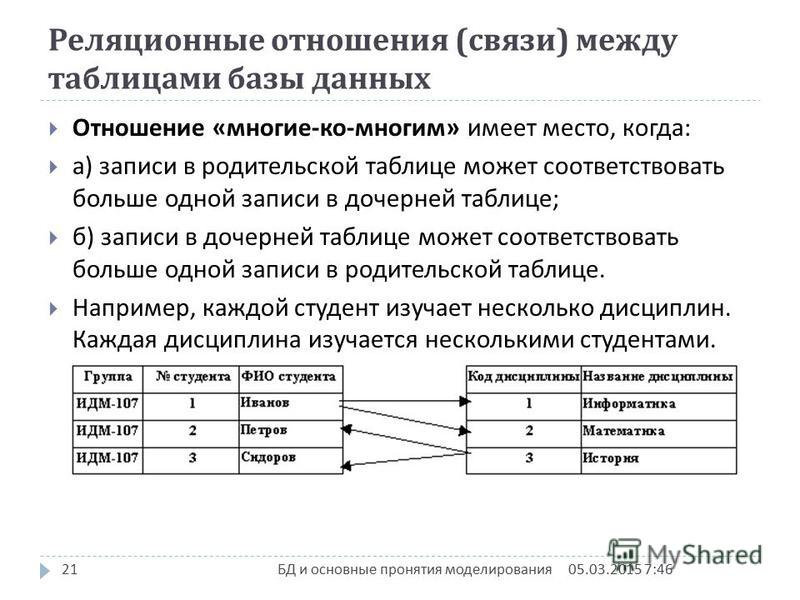 И модель на основе SQL продолжает доминировать. По состоянию на 2019 год 60,5% баз данных составляли системы управления реляционными базами данных на основе SQL.
И модель на основе SQL продолжает доминировать. По состоянию на 2019 год 60,5% баз данных составляли системы управления реляционными базами данных на основе SQL.
* Источник изображения scalegrid.io .
Тем не менее, с каждым годом системы управления нереляционными базами данных на основе NoSQL становятся все более популярными, особенно потому, что специалисты по данным хотят предоставить свои инструменты бизнес-аналитики машинного обучения большему количеству неструктурированных данных. Давайте посмотрим, чем отличаются эти стили базы данных.
Системы управления реляционными базами данных (на базе SQL)
Системы управления реляционными базами данных (СУБД) используют SQL, язык управления базами данных, который предлагает высокоорганизованный и структурированный подход к управлению информацией.Подобно тому, как телефонная книга содержит разные категории информации (имя, номер, адрес и т. Д. ) Для каждой строки данных, реляционные базы данных применяют строгие категориальные параметры, которые позволяют пользователям базы данных легко организовывать, получать доступ и поддерживать информацию в этих строках. параметры.
) Для каждой строки данных, реляционные базы данных применяют строгие категориальные параметры, которые позволяют пользователям базы данных легко организовывать, получать доступ и поддерживать информацию в этих строках. параметры.
Основными причинами, по которым СУБД на основе SQL продолжает доминировать, являются: (1) они очень стабильны и надежны; (2) они придерживаются стандарта, который легко интегрируется с популярными программными пакетами, такими как LAMP; и (3) мы используем их более 40 лет.
Преимущества СУБД :
- Соответствие ACID: Если система баз данных «ACID-совместима», она удовлетворяет набору приоритетов, которые измеряют атомарность, согласованность, изоляцию и надежность систем баз данных. Чем больше ACID-совместима база данных, тем больше она служит для гарантии достоверности транзакций базы данных, уменьшения количества аномалий, защиты целостности данных и создания стабильных систем баз данных. Как правило, СУБД на основе SQL достигают высокого уровня соответствия ACID, но базы данных NoSQL отказываются от этого различия, чтобы получить скорость и гибкость при работе с неструктурированными данными.

- Идеально подходит для согласованных систем данных: С СУБД на основе SQL ваша информация останется в структуре, которую вы изначально создали. Если вам не нужна динамическая информационная система для огромных объемов данных — и вы не имеете дело с множеством типов данных — СУБД предлагает большую скорость и стабильность.
- Лучшие варианты поддержки: Поскольку СУБД существуют уже более 40 лет, легче получить поддержку, дополнительные продукты и интегрировать данные из других систем.
Недостатки РСУБД :
- Проблемы масштабируемости и трудности с сегментированием: РСУБД труднее масштабировать в ответ на массовый рост по сравнению с базами данных NoSQL. Эти базы данных также создают проблемы, когда дело доходит до сегментирования. Шардинг — это процесс разделения большой базы данных на более мелкие части для упрощения управления. Если вы имеете дело с консервативной базой данных, которая, как вы не ожидаете, сильно изменится в ближайшие годы, проблемы сегментирования и масштабирования, связанные с решениями РСУБД, могут никогда не относиться к вам.
 С другой стороны, если вы планируете масштабироваться и развиваться в ближайшие годы, нереляционная система баз данных (на основе NoSQL) может лучше соответствовать вашим потребностям.
С другой стороны, если вы планируете масштабироваться и развиваться в ближайшие годы, нереляционная система баз данных (на основе NoSQL) может лучше соответствовать вашим потребностям. - Менее эффективны с форматами NoSQL: Большинство СУБД теперь совместимы с форматами данных NoSQL, но не работают с ними так же эффективно, как нереляционные базы данных.
Три самых популярных механизма СУБД / SQL (о которых мы поговорим более подробно ниже):
Что такое база данных?
Одним из технологических терминов, который большинство людей привыкло слышать на работе или во время работы в Интернете, является база данных.База данных раньше была чрезвычайно техническим термином, однако с развитием компьютерных систем и информационных технологий во всей нашей культуре, база данных стала нарицательным.
База данных — это структурированный набор записей или данных, которые хранятся в компьютерной системе. Чтобы база данных была действительно функциональной, она должна не только хорошо хранить большие объемы записей, но и быть легко доступной. Кроме того, новую информацию и изменения также должно быть довольно легко вводить. Чтобы иметь высокоэффективную систему базы данных, необходимо включить программу, которая управляет запросами и информацией, хранящейся в системе.Обычно это называется СУБД или системой управления базами данных. Помимо этих функций, все создаваемые базы данных должны быть построены с высокой целостностью данных и возможностью восстановления данных в случае отказа оборудования.
Кроме того, новую информацию и изменения также должно быть довольно легко вводить. Чтобы иметь высокоэффективную систему базы данных, необходимо включить программу, которая управляет запросами и информацией, хранящейся в системе.Обычно это называется СУБД или системой управления базами данных. Помимо этих функций, все создаваемые базы данных должны быть построены с высокой целостностью данных и возможностью восстановления данных в случае отказа оборудования.
Типы баз данных
Есть несколько распространенных типов баз данных. Каждый тип базы данных имеет свою собственную модель данных (то, как данные структурированы). К ним относятся плоская модель, иерархическая модель, реляционная модель и сетевая модель.
База данных плоских моделей
В базе данных плоской модели существует двумерный (плоская структура) массив данных.Например, есть один столбец информации, и в этом столбце предполагается, что каждый элемент данных связан с другим. Например, база данных плоских моделей включает только почтовые индексы. В базе данных есть только один столбец, и каждая новая строка в этом столбце будет иметь новый почтовый индекс.
В базе данных есть только один столбец, и каждая новая строка в этом столбце будет иметь новый почтовый индекс.
База данных иерархических моделей
База данных иерархической модели напоминает древовидную структуру, например, как Microsoft Windows организует папки и файлы. В базе данных с иерархической моделью каждая восходящая ссылка вложена, чтобы данные были организованы в определенном порядке на одном уровне списка.Например, иерархическая база данных продаж может перечислять продажи за каждый день в виде отдельного файла. В этом вложенном файле содержатся все продажи (одинаковые типы данных) за день.
Сетевая модель
В сетевой модели определяющей особенностью является то, что запись хранится со ссылкой на другие записи — фактически в сети. Эти сети (или иногда их называют указателями) могут содержать информацию любого типа, например номера узлов или даже адрес диска.
Реляционная модель
Реляционная модель — самый популярный тип базы данных и чрезвычайно мощный инструмент не только для хранения информации, но и для доступа к ней.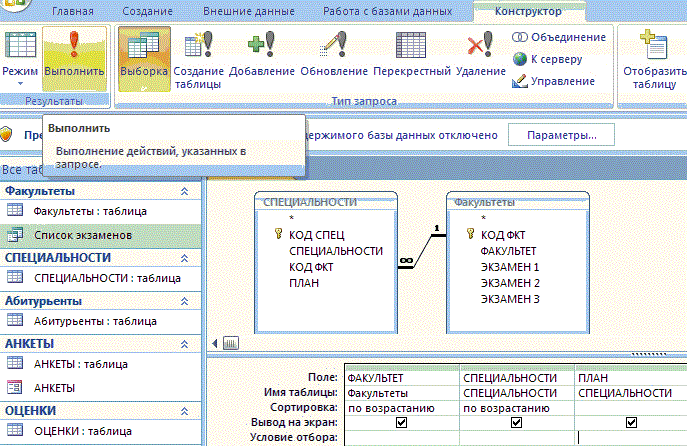 Реляционные базы данных организованы в виде таблиц. Прелесть таблицы в том, что к информации можно получить доступ или добавить ее без реорганизации таблиц. В таблице может быть много записей, и каждая запись может иметь много полей.
Реляционные базы данных организованы в виде таблиц. Прелесть таблицы в том, что к информации можно получить доступ или добавить ее без реорганизации таблиц. В таблице может быть много записей, и каждая запись может иметь много полей.
Таблицы иногда называют отношением. Например, у компании может быть база данных под названием заказы клиентов. В этой базе данных есть несколько различных таблиц или отношений, относящихся к заказам клиентов. Таблицы могут включать информацию о клиенте (имя, адрес, контакт, информацию, номер клиента и т. Д.).) и другие таблицы (отношения), такие как заказы, которые клиент ранее купил (это может включать номер позиции, описание позиции, сумму платежа, способ оплаты и т. д.). Следует отметить, что каждая запись (группа полей) в реляционной базе данных имеет собственный первичный ключ. Первичный ключ — это уникальное поле, которое упрощает идентификацию записи.
Реляционные базы данных используют программный интерфейс, называемый SQL (стандартный язык запросов). В настоящее время SQL используется практически во всех реляционных базах данных.Реляционные базы данных очень легко настроить, чтобы они подходили практически для любого типа хранилища данных. Можно легко создать отношения для товаров на продажу, сотрудников компании и т. Д.
В настоящее время SQL используется практически во всех реляционных базах данных.Реляционные базы данных очень легко настроить, чтобы они подходили практически для любого типа хранилища данных. Можно легко создать отношения для товаров на продажу, сотрудников компании и т. Д.
Доступ к информации с помощью базы данных
Хотя хранение данных — отличная функция базы данных, многие пользователи баз данных считают быстрый и простой поиск информации самым важным. Получить информацию о сотруднике в реляционной базе данных очень просто. Реляционные базы данных также добавляют возможности выполнения запросов.Запросы — это запросы на извлечение определенных типов информации и либо их отображение в естественном состоянии, либо создание отчета с использованием данных. Например, если у кого-то была база данных сотрудников, которая включала в себя такие таблицы, как зарплата и описание должности, он / она мог бы легко запустить запрос, чтобы узнать, какие рабочие места оплачивают больше определенной суммы. Независимо от того, какая информация хранится в базе данных, с помощью SQL можно создавать запросы, которые помогут ответить на важные вопросы.
Независимо от того, какая информация хранится в базе данных, с помощью SQL можно создавать запросы, которые помогут ответить на важные вопросы.
Хранение базы данных
Базы данных могут быть очень маленькими (менее 1 МБ) или очень большими и сложными (терабайты, как во многих государственных базах данных).Однако все базы данных обычно хранятся и располагаются на жестких дисках или других типах устройств хранения, и доступ к ним осуществляется через компьютер. Для больших баз данных могут потребоваться отдельные серверы и местоположения, однако многие небольшие базы данных могут легко поместиться в файлы, расположенные на жестком диске компьютера.
Защита базы данных
Очевидно, что во многих базах данных хранится конфиденциальная и важная информация, к которой не любой может легко получить доступ. Многие базы данных требуют паролей и других функций безопасности для доступа к информации.В то время как к некоторым базам данных можно получить доступ через Интернет через сеть, другие базы данных являются закрытыми системами и доступны только на месте.
Дополнительная литература
Кто такой администратор базы данных (DBA)?
Мы живем в эпоху больших данных, онлайн-бизнеса и постоянных требований к надежной кибербезопасности. Вот здесь и пригодится ваш администратор базы данных (или администратор базы данных). Но что такое администратор базы данных?
Администраторы баз данных играют важную роль в больших и малых компаниях.Но рост и возможности программного обеспечения для автоматизации заставили некоторых людей беспокоиться о том, что администраторы баз данных уходят. Они опасаются, что автоматизация вытеснит традиционную роль администратора баз данных.
Это , а не так.
На самом деле администраторы баз данных могут получить большую выгоду от автоматизации бизнес-процессов. Итак, мы разобрали, чем занимается администратор баз данных, зачем они нужны и как программное обеспечение для автоматизации вписывается в общую картину.
Кто такой администратор базы данных?
Хороший способ ответить на вопрос «кто такой администратор базы данных?» — взглянуть на три типа администраторов баз данных, задачи, которые они выполняют, и обязанности, которые они выполняют.
- Системные администраторы баз данных (также известные как операционные администраторы баз данных)
Системные администраторы баз данных занимаются физическими аспектами управления базами данных. Например, установка и обслуживание систем управления базами данных, резервное копирование баз данных, оптимизация производительности и аварийное восстановление.
Администраторы баз данных разработки занимаются аспектами разработки администрирования баз данных. Например, создание языка определения данных (DDL) и написание языка структурированных запросов (SQL).
Администраторы баз данных приложений управляют любыми сторонними приложениями и программным обеспечением, которые взаимодействуют с вашей базой данных. (Например, программное обеспечение для автоматизации.) В их задачи могут входить установка новых программных приложений, обеспечение системной интеграции и управление обновлениями.
(Например, программное обеспечение для автоматизации.) В их задачи могут входить установка новых программных приложений, обеспечение системной интеграции и управление обновлениями.
Нередко один человек выполняет обязанности всех трех типов администраторов баз данных.
Для чего нужен администратор базы данных?
Администраторы баз данных — важные члены ИТ-команды. Они контролируют ваши компьютерные системы. И, конечно же, они специализируются на управлении и обслуживании баз данных организации.
Администраторы баз данных особенно важны для любого бизнеса, который сильно полагается на свои информационные системы. Например, банки, страховые компании и больницы.
Другими словами, администраторы баз данных следят за созданием, обслуживанием и безопасностью ваших баз данных. Они делают это, обладая практическими знаниями (и опытом) в продуктах и программном обеспечении для управления базами данных.
Итак, кто такой администратор базы данных? Они обеспечивают целостность, безопасность и доступность данных компании.
Типичные задачи администратора баз данных
Администрирование баз данных — это умелая, разнообразная и напряженная работа. Итак, в качестве примера, повседневные задачи включают:
- Обеспечение безопасности данных компании
- Резервное копирование и восстановление данных
- Определение потребностей пользователей базы данных
- Создание и управление базами данных компании
- Обеспечение правильной и эффективной работы баз данных
- Внесение и тестирование изменений в структурах базы данных
- Обновление старых или унаследованных баз данных в новые
- Управление объединением межсистемных данных
- Текущее обслуживание базы данных
Лучший друг администратора данных
устаревший аргумент, что автоматизация уничтожит роли администраторов баз данных.На самом деле, наоборот. Программное обеспечение автоматизации не исключает поля, а дополняет администрирование баз данных.
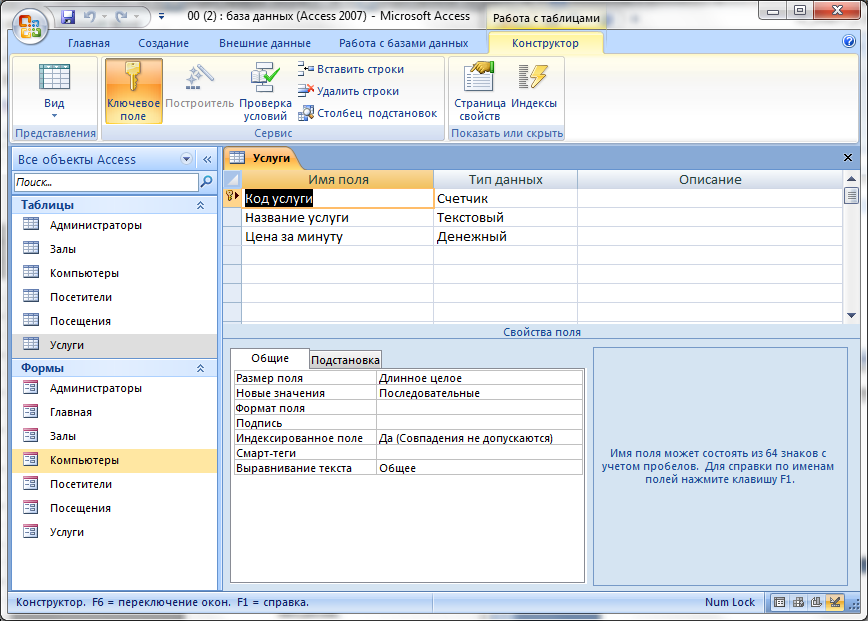
Например, запущенное программное обеспечение для автоматизации помогает администраторам баз данных выполнять текущее обслуживание баз данных компании. Это помогает поддерживать базу данных в актуальном состоянии, пока над ней работает ваш администратор баз данных. (Скорее, чем в нем.)
Программное обеспечение для автоматизации (например, ThinkAutomation) может помочь с множеством повторяющихся задач. Например, он может автоматически создавать резервные копии новых записей и удалять старые записи по истечении заданного времени.Это время будет определять ваш администратор базы данных.
Администратор баз данных может также использовать автоматизацию для обеспечения согласованности данных во всех базах данных. Или запускать автоматические отчеты. Или для запросов и поиска, для отслеживания и измерения, для извлечения, преобразования и загрузки.
И это только верхушка. Есть еще много рутинных задач, отягощающих ваших администраторов баз данных, с которыми может справиться программное обеспечение автоматизации.
Но если все это делает программа автоматизации, зачем нужен администратор базы данных?
Рука помощи, а не замена
Итак, что такое администратор базы данных с автоматизацией? Это тот, кто может сосредоточиться на оптимизации баз данных и информационных систем вашей компании на всех уровнях.
Ваш администратор баз данных также необходим для управления автоматизацией. Они управляют правилами, которым он следует, и процессами, которые он выполняет.
Администратор баз данных также важен для более крупных и сложных задач и решений, которые автоматизация не может принять.
Предполагается, что занятость администраторов баз данных вырастет на 10% с 2019 по 2029 год, что намного быстрее, чем в среднем по всем профессиям. Рост этой профессии будет обусловлен увеличением потребностей компаний в данных по всей экономике.
БЮРО ТРУДОВОЙ СТАТИСТИКИ США
Позвольте автоматизации помочь вашему администратору баз данных
Администраторы баз данных и автоматизация лучше вместе.