Запрос SQL на выборку определённого числа записей
Вы здесь: Главная — MySQL — SQL — Запрос SQL на выборку определённого числа записей
В одной из предыдущих статей, посвящённых SQL-запросу на выборку записей из таблицы, мы с Вами разобрали возможность считывания данных из таблиц. И, в принципе, этого вполне достаточно для успешного использования базы данных. Однако, иногда наиболее рационально ограничить число результирующих записей, и как раз о том, как это сделать, мы и поговорим ниже.
Давайте сразу рассмотрим запрос SQL на выборку определённого числа записей:
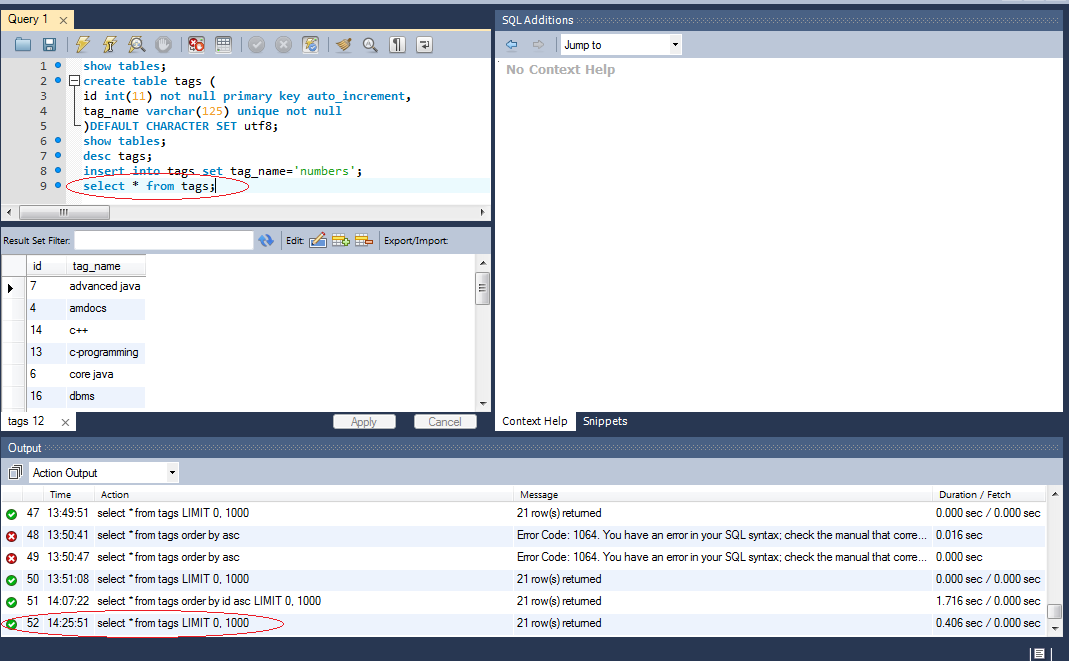
SELECT * FROM users WHERE id > 5 LIMIT 10
Данным запросом мы получим 10 первых записей. Все остальные отпадут. Изменение от обычного SQL-запроса на выборку данных состоит только в параметре «LIMIT«. Число, которое идёт за ним, сообщает, какое количество записей мы хотим получить, и в нашем случае — это 10

Также существует возможность задавать после «LIMIT» два числа:
SELECT * FROM users WHERE id > 5 LIMIT 10, 20
Данный SQL-запрос вернёт записи, начиная с 10-го номера включительно в количестве 20-ти штук. То есть первое число означает, с какой записи надо формировать результат выборки, а второе число означает, какое количество записей всего должно быть.
Собственно, это всё, что необходимо для выборки определённого числа записей. Используется это очень часто, например, при выводе последних 10-ти зарегистрированных пользователях. Или при выводе 5-ти свежих статей (как на главной странице моего сайта), или в других аналогичных ситуациях.
- Создано 18.01.2011 21:35:07
- Михаил Русаков
 ru)!
ru)!Добавляйтесь ко мне в друзья ВКонтакте: http://vk.com/myrusakov.
Если Вы хотите дать оценку мне и моей работе, то напишите её в моей группе: http://vk.com/rusakovmy.
Если Вы не хотите пропустить новые материалы на сайте,
то Вы можете подписаться на обновления: Подписаться на обновления
Если у Вас остались какие-либо вопросы, либо у Вас есть желание высказаться по поводу этой статьи, то Вы можете оставить свой комментарий внизу страницы.
Порекомендуйте эту статью друзьям:
Если Вам понравился сайт, то разместите ссылку на него (у себя на сайте, на форуме, в контакте):
-
Кнопка:
<a href=»https://myrusakov.ru» target=»_blank»><img src=»https://myrusakov.ru/images/button.gif» alt=»Как создать свой сайт» /></a> -
Текстовая ссылка:
<a href=»https://myrusakov.ru» target=»_blank»>Как создать свой сайт</a>Она выглядит вот так: Как создать свой сайт
- BB-код ссылки для форумов (например, можете поставить её в подписи):
[URL=»https://myrusakov. ru»]Как создать свой сайт[/URL]
ru»]Как создать свой сайт[/URL]
|
Дата: 15.09.2019 Автор: Василий Лукьянчиков , vl (at) sqlinfo (dot) ru Судя по сообщениям на форуме SQLinfo, выбор более одной строки из группы — часто встречающаяся задача (например, несколько популярных/новых товаров из каждой категории, последние новости для каждой рубрики, и т.д.), которая вызывает сложности при попытке решить её средствами SQL. В статье объясняется несколько способов как одним запросом получить N первых, последних или случайных строк из группы и дана оценка их эффективности с точки зрения производительности. Разберем решения на примере таблицы сообщений, имеющей поля (post_id, user_id, date_added, post_text), в которой хранится id сообщения, id пользователя, дата добавления и текст поста. Предполагается, что комбинация (user_id, date_added) уникальна, т.е. пользователь не может разместить 2 сообщения в один момент времени. `post_id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) NOT NULL, `date_added` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP, `post_text` text NOT NULL, PRIMARY KEY (`post_id`), UNIQUE KEY `user_id` (`user_id`,`date_added`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; INSERT INTO `posts` VALUES (1,1,’2018-04-17 05:37:15′,’Есть таблица товаров. Каждый товар относится к какой-то категории. Как вывести по 3 товара из каждой категории?’); INSERT INTO `posts` VALUES (3,2,’2018-04-17 11:13:22′,’Выборка по N последних товаров каждой категории. Просто не хочется делать запрос на каждую категорию.’); INSERT INTO `posts` VALUES (4,1,’2018-04-17 15:38:04′,’Как вывести по N строк из каждой группы? Например, последние новости для каждой рубрики или несколько популярных товаров из каждой категории’); INSERT INTO `posts` VALUES (5,1,’2018-04-17 15:52:18′,’Помогите написать запрос.  Выбор по несколько строк из каждой группы в запросе’); Выбор по несколько строк из каждой группы в запросе’);INSERT INTO `posts` VALUES (6,4,’2018-04-18 12:17:05′,’MySQL не поддерживает LIMIT внутри IN подзапросов. Как написать запрос с лимитом строк внутри каждой группы?’); INSERT INTO `posts` VALUES (7,4,’2018-04-18 14:55:36′,’К сожалению, в MySQL нет windows function. Используйте user variables для их эмуляции.’); INSERT INTO `posts` VALUES (8,1,’2018-04-23 02:17:14′,’Помогите ускорить выборку случайных строк из группы.’); INSERT INTO `posts` VALUES (9,4,’2018-04-25 17:22:02′,’TOP в подзапросе выдает ошибку.’); INSERT INTO `posts` VALUES (10,4,’2018-04-26 22:28:45′,’Нужно выбрать из каждой группы по 2 последних элемента и 2 случайных.’); Пусть нам требуется выбрать 3 последних сообщения каждого пользователя. Некоторые из предложенных ниже вариантов после незначительных изменений могут быть использованы для выборки 3 случайных сообщений каждого пользователя (о чем будут даны соответствующие пояснения). 1. зависимый подзапросselect t1.* from posts t1 Эффективность запроса ухудшается по мере роста числа сообщений у пользователя. Нельзя ограничится рассмотрением только нескольких записей каждого пользователя, необходимо проверить все сообщения и для каждого из них подсчитать точное кол-во более поздних. Кроме того метод неприменим для выборки нескольких случайных строк из группы. 2. join + group byТа же идея, что и в предыдущем случае, только реализована через самообъединение таблицы и группировку. Каждой строке сопоставляется набор строк с тем же user_id и большей или равной date_added, после группировки мы получаем для каждой строки (количество сообщений того же пользователя с большей датой добавления) + 1. select t1.* from Этот способ часто рекомендуют в интернете в качестве решения задачи (встречаются вариации с left join). Однако его производительность не самая оптимальная в сравнении с другими методами, рассмотренными в этой статье. Вероятно, причина популярности этого решения в том, что join многим интуитивно представляется более простым решением. Обратите внимание: в режиме ONLY_FULL_GROUP_BY придется усложнять запрос: сначала выбрать нужные post_id, затем по ним дополнительным join извлечь остальные поля (подробнее см статью Группировка в MySQL). Простое перечисление всех полей в части group by в разы увеличивает время выполнения запроса. Строго говоря, этот способ как и предыдущий (с помощью зависимого подзапроса) можно использовать для выборки случайных строк из группы, но только в новых версиях, где есть поддержка обобщенных табличных выражений.
3. group_concat()Для каждого пользователя с помощью group_concat() составляется список идентификаторов его сообщений, отсортированный по убыванию даты. Используя substring_index(), вырезаем первые 3 значения post_id, и по ним извлекается вся строка. select t1.* from posts t1 join К сожалению, MySQL не умеет решать уравнения, поэтому для поиска по условию с find_in_set будет просканирована вся таблица сообщений. with cte as ( Будет ли такой трюк эффективным зависит от:
Этот способ можно применять для выборки 3 случайных сообщений каждого пользователя. 4. оконные функцииНачиная с MariaDB 10.2 / MySQL 8 добавлена поддержка оконных функций. С помощью row_number() можно для каждого пользователя сделать отдельную нумерацию сообщений в порядке убывания даты. После чего выбрать те записи, у которых № меньше или равен 3. select post_id, user_id, date_added, post_text from Производительность — двойное сканирование таблицы: сначала для нумерации (нет возможности ограничиться нумерацией только нескольких строк из группы), потом отбросить не удовлетворяющие условию where i <= 3. Для случайных сообщений пользователя достаточно заменить сортировку по убыванию даты order by date_added desc на случайную — order by rand(). 5. пользовательские переменные Та же идея, что и в предыдущем варианте, только реализована с помощью пользовательских переменных (user variables). select post_id, user_id, date_added, post_text from Как и в примере с row_number(), мы нумеруем сообщения каждого пользователя в порядке убывания даты добавления (только делаем это с помощью пользовательских переменных), затем оставляем только те строки, у которых № меньше или равен 3. Способ можно применять и для выборки нескольких случайных сообщений юзера. Однако простая замена сортировки по убыванию даты на случайную не даст нужного эффекта. select post_id, user_id, date_added, post_text from Обратите внимание на добавление ещё одной переменной @z:=1, которая более нигде не применяется. В общем, пользовательские переменные — мощный инструмент написания и оптимизации запросов, но нужно быть очень внимательными при работе с ними, понимать на каком эффекте основан, используемый вами трюк, и проверять работоспособность в новых версиях. Подробнее см Оптимизация запросов MySQL с использованием пользовательских переменных 6. подзапросы lateralВ MySQL 8.0.14 добавлена поддержка зависимых подзапросов в части FROM, с помощью которых наша задача решается оптимальным образом. Сначала формируется список идентификаторов пользователей (производная таблица t1) и для каждого из выбираются нужные строки (коррелированный from-подзапрос t2). select t2.* from (select user_id from posts group by user_id) as t1, К удивлению, при выборе строк в подзапросе t2 сервер читает все строки группы и делает файловую сортировку вместо нахождения 3 нужных строк по уникальному индексу (user_id, date_added). Возможно в будущих версиях это поведение будет исправлено. На сегодняшний день можно применить следующий трюк, благодаря которому MySQL будет использовать индекс — расширить выражение сортировки следующим образом: .. order by user_id desc, date_added desc limit 3 Спасибо за совет Гильяму Бишоту.Для выборки случайных строк из группы достаточно в lateral подзапросе заменить сортировку на случайную — order by rand(). ЗаключениеСводная таблица, показывающая среднее время выполнения изложенных выше способов для нахождения трёх последних и трёх случайных сообщений каждого пользователя на тестовых данных в 16000 строк, равномерно распределенных среди count(distinct user_id) = 20.
Если ваша СУБД поддерживает подзапросы lateral, то используйте их. Вообще, каждый раз, когда есть необходимость «для каждого значения выбрать …» — возможно вы сможете эффективно решить задачу, используя LATERAL производные таблицы. Подробнее об этой функциональности можно прочитать в статье В MySQL 8.0.14 добавлена поддержка производных таблиц типа LATERAL. Неожиданно высокую эффективность показал третий способ, особенно для выборки случайных строк из группы. Также не забывайте про вариант реализации lateral во внешнем приложении: сначала выбираем список идентификаторов групп, потом в цикле отдельными запросами находим нужные строки для каждой группы. Порой встречается ошибочное мнение, что это ламерский подход и правильно решать задачу в один запрос к базе. По эффективности множество «простых» запросов, выбирающих по индексу нужные строки, лучше одного «сложного», который многократно сканирует всю таблицу. Разумеется это справедливо, когда в группах много элементов, и нужно вернуть лишь малую часть, иначе накладные расходы могут превысить выигрыш от снижения количества прочитанных строк. P.S.При выборе подходящего варианта проводите тестирование в своем окружении. Дата публикации: 15. © Все права на данную статью принадлежат порталу SQLInfo.ru. Перепечатка в интернет-изданиях разрешается только с указанием автора и прямой ссылки на оригинальную статью. Перепечатка в бумажных изданиях допускается только с разрешения редакции. |
||


 Есть обходной путь: используя строковые функции и union all, вырезать id сообщений из списка и объединить их в один столбец. Тогда оптимизатор сможет использовать их для поиска нужных строк в таблице сообщений, а не наоборот.
Есть обходной путь: используя строковые функции и union all, вырезать id сообщений из списка и объединить их в один столбец. Тогда оптимизатор сможет использовать их для поиска нужных строк в таблице сообщений, а не наоборот. Для этого достаточно указать иной вид сортировки внутри group_concat: order by rand() вместо order by date_added desc.
Для этого достаточно указать иной вид сортировки внутри group_concat: order by rand() вместо order by date_added desc. Актуально для версий, в которых нет оконных функций.
Актуально для версий, в которых нет оконных функций.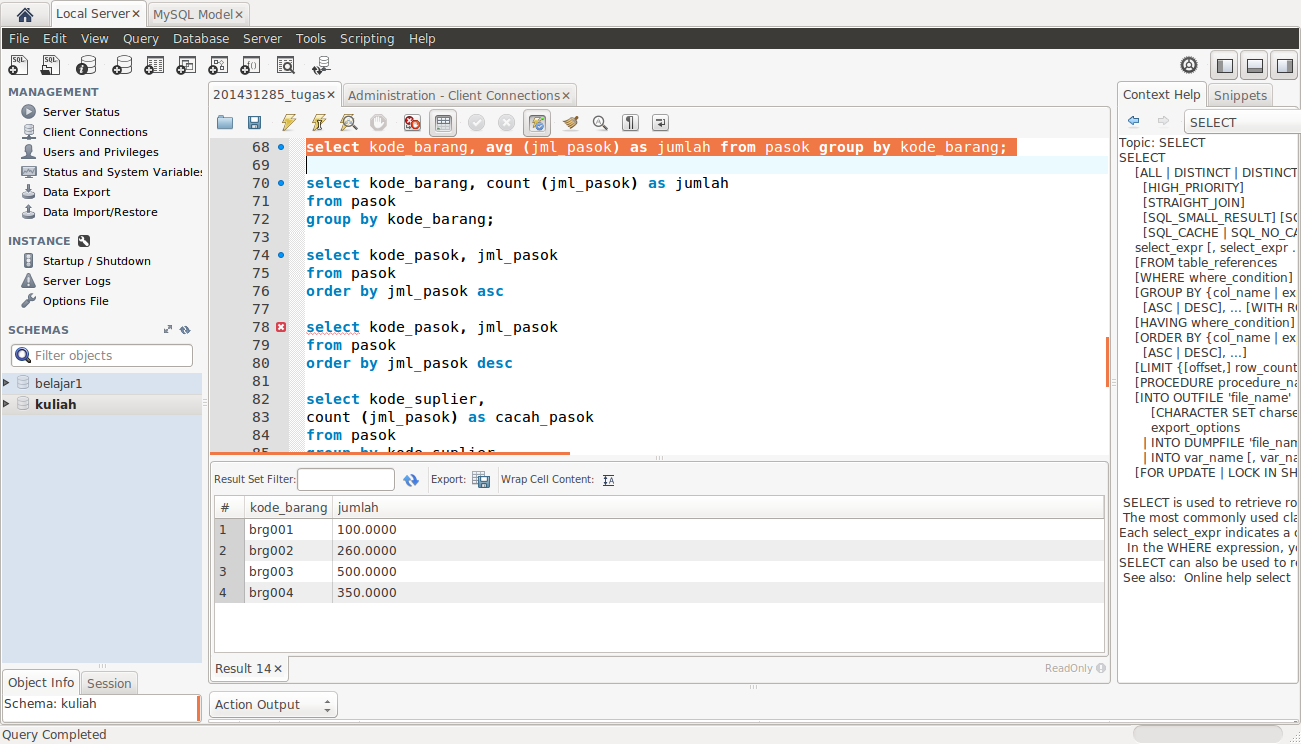 С некоторых пор оптимизатор научился упрощать тривиальные с его точки зрения from-подзапросы, перенося условия из них во внешний запрос. Однако, если в подзапросе используются переменные, то пока оптимизатор материализует такие подзапросы.
С некоторых пор оптимизатор научился упрощать тривиальные с его точки зрения from-подзапросы, перенося условия из них во внешний запрос. Однако, если в подзапросе используются переменные, то пока оптимизатор материализует такие подзапросы. user_id=posts.user_id order by date_added desc limit 3) as t2;
user_id=posts.user_id order by date_added desc limit 3) as t2; зависимый подзапрос
зависимый подзапрос Неожиданно, потому что как правило рекомендуют использовать второй и четвертый (для MySQL до недавнего времени его реализацию через переменные, т.е. пятый) способы.
Неожиданно, потому что как правило рекомендуют использовать второй и четвертый (для MySQL до недавнего времени его реализацию через переменные, т.е. пятый) способы. 09.2019
09.2019Как получить 10 лучших значений в postgresql?
Вопрос:
У меня простой вопрос:
У меня есть база данных postgresql: Scores(score integer).
Как бы я получил самые высокие 10 баллов быстрее?
ОБНОВИТЬ:
Я буду делать этот запрос несколько раз и стремлюсь к самому быстрому решению.
Ответ №1
Для этого вы можете использовать лимит
select *
from scores
order by score desc
limit 10
Если важна производительность (когда это не так ;-), ищите индекс на счет.
Начиная с версии 8.4, вы также можете использовать стандарт (SQL: 2008) fetch first
select *
from scores
order by score desc
fetch first 10 rows only
Как отметил @Raphvanns, это даст вам буквально first 10 rows. Чтобы удалить повторяющиеся значения, необходимо выбрать
Чтобы удалить повторяющиеся значения, необходимо выбрать distinct строк, например.
select distinct *
from scores
order by score desc
fetch first 10 rows only
SQL Fiddle
Ответ №2
Кажется, что вы ищете ORDER BY в DESC окончательном порядке с LIMIT:
SELECT
*
FROM
scores
ORDER BY score DESC
LIMIT 10
Конечно, SELECT * может серьезно повлиять на производительность, поэтому используйте его с осторожностью.
Ответ №3
Обратите внимание, что если есть связи в первых 10 значениях, вы получите только первые 10 строк, а не 10 лучших значений с предоставленными ответами. Пример: если верхние 5 значений 10, 11, 12, 13, 14, 15, но ваши данные содержат 10, 10, 11, 12, 13, 14, 15, вы получите только 10, 10, 11, 12, 13, 14 в качестве верхней 5 с LIMIT
Вот решение, которое будет возвращать более 10 строк, если есть связи, но вы получите все строки, где some_value_column технически находятся в топ-10.
select
*
from
(select
*,
rank() (order by some_value_column desc) as my_rank
from
mytable) subquery
where my_rank <= 10
Ответ №4
(SELECT <some columns>
FROM mytable
<maybe some joins here>
WHERE <various conditions>
ORDER BY date DESC
LIMIT 10)
UNION ALL
(SELECT <some columns>
FROM mytable
<maybe some joins here>
WHERE <various conditions>
ORDER BY date ASC
LIMIT 10)
PostgreSQL : Документация: 9.6: CREATE INDEX : Компания Postgres Professional
Описание
CREATE INDEX создаёт индексы по указанному столбцу(ам) заданного отношения, которым может быть таблица или материализованное представление. Индексы применяются в первую очередь для оптимизации производительности базы данных (хотя при неправильном использовании возможен и противоположный эффект).
Ключевое поле для индекса задаётся как имя столбца или выражение, заключённое в скобки. Если метод индекса поддерживает составные индексы, допускается указание нескольких полей.
Поле индекса может быть выражением, вычисляемым из значений одного или нескольких столбцов в строке таблицы. Это может быть полезно для получения быстрого доступа к данным по некоторому преобразованию исходных значений. Например, индекс, построенный по выражению upper(col), позволит использовать поиск по индексу в предложении WHERE upper(col) = 'JIM'.
PostgreSQL предоставляет следующие методы индексов: B-дерево, хеш, GiST, SP-GiST, GIN и BRIN. Пользователи могут определить и собственные методы индексов, но это довольно сложная задача.
Если в команде присутствует предложение WHERE, она создаёт частичный индекс. Такой индекс содержит записи только для части таблицы, обычно более полезной для индексации, чем остальная таблица. Например, если таблица содержит информацию об оплаченных и неоплаченных счетах, при этом последних сравнительно немного, но именно эта часть таблицы наиболее востребована, то увеличить быстродействие можно, создав индекс только по этой части. Ещё одно возможное применение
Ещё одно возможное применение WHERE — добавив UNIQUE, обеспечить уникальность в подмножестве таблицы. Подробнее это рассматривается в Разделе 11.8.
Выражение в предложении WHERE может ссылаться только на столбцы нижележащей таблицы, но не обязательно ограничиваться теми, по которым строится индекс. В настоящее время в WHERE также нельзя использовать подзапросы и агрегатные выражения. Это же ограничение распространяется и на выражения в полях индексов.
Все функции и операторы, используемые в определении индекса, должны быть «постоянными», то есть, их результаты должны зависеть только от аргументов, но не от внешних факторов (например, содержимого другой таблицы или текущего времени). Это ограничение обеспечивает определённость поведения индекса. Чтобы использовать в выражении индекса или в предложении WHERE собственную функцию, не забудьте пометить её при создании как постоянную (IMMUTABLE).
Производительность max () против ORDER BY DESC + LIMIT 1
Я искал несколько медленных SQL-запросов сегодня и не совсем понимаю разницу в производительности ниже:
При попытке извлечь max (timestamp) из таблицы данных на основе некоторого условия использование MAX() выполняется медленнее, чем ORDER BY timestamp LIMIT 1 если соответствующая строка существует, но значительно быстрее, если совпадающая строка не найдена.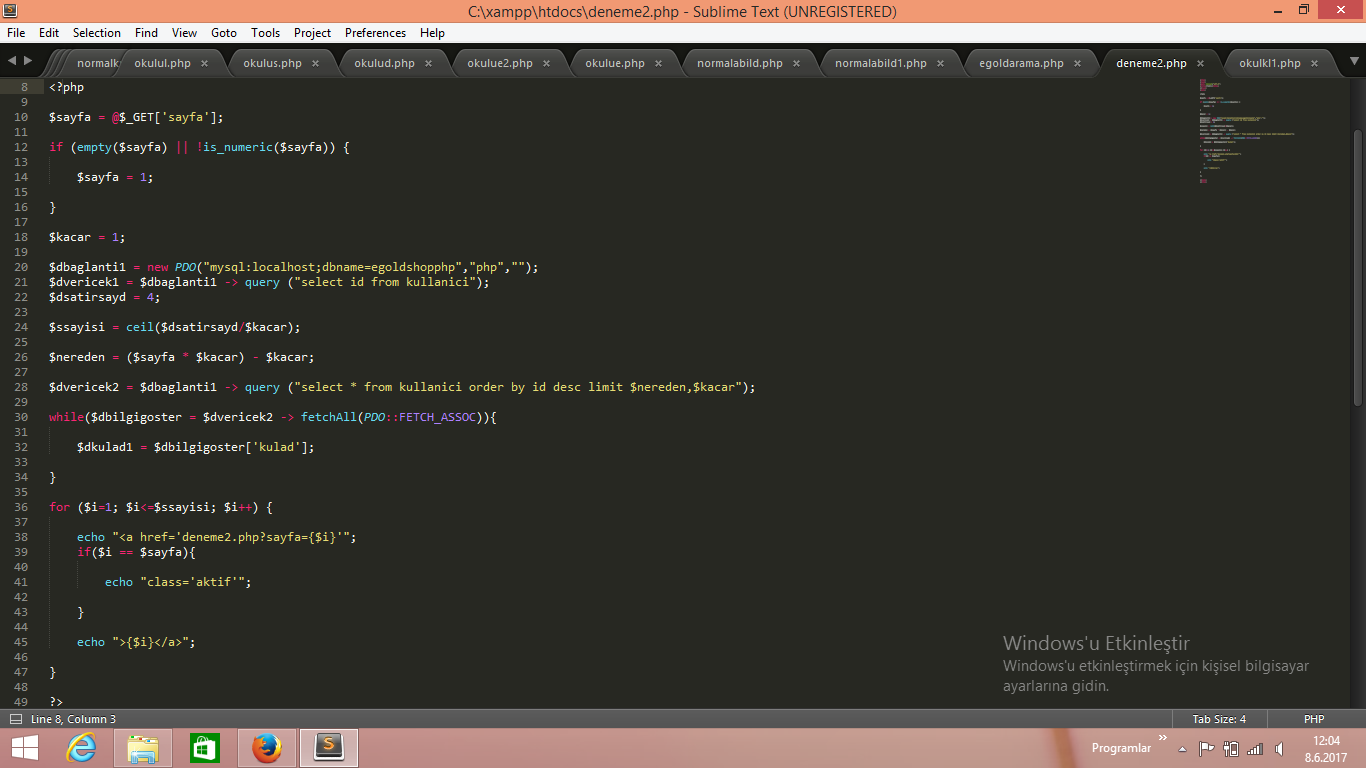
SELECT timestamp
FROM data JOIN sensors ON ( sensors.id = data.sensor_id )
WHERE sensor.station_id = 4
ORDER BY timestamp DESC
LIMIT 1;
(0 rows)
Time: 1314.544 ms
SELECT timestamp
FROM data JOIN sensors ON ( sensors.id = data.sensor_id )
WHERE sensor.station_id = 5
ORDER BY timestamp DESC
LIMIT 1;
(1 row)
Time: 10.890 ms
SELECT MAX(timestamp)
FROM data JOIN sensors ON ( sensors.id = data.sensor_id )
WHERE sensor.station_id = 4;
(0 rows)
Time: 0.869 ms
SELECT MAX(timestamp)
FROM data JOIN sensors ON ( sensors.id = data.sensor_id )
WHERE sensor.station_id = 5;
(1 row)
Time: 84.087 ms
Есть индексы на (timestamp) и (sensor_id, timestamp) , и я заметил, что Postgres использует очень разные планы и индексы запросов для обоих случаев:
QUERY PLAN (ORDER BY)
--------------------------------------------------------------------------------------------------------
Limit (cost=0. 43..9.47 rows=1 width=8)
-> Nested Loop (cost=0.43..396254.63 rows=43823 width=8)
Join Filter: (data.sensor_id = sensors.id)
-> Index Scan using timestamp_ind on data (cost=0.43..254918.66 rows=4710976 width=12)
-> Materialize (cost=0.00..6.70 rows=2 width=4)
-> Seq Scan on sensors (cost=0.00..6.69 rows=2 width=4)
Filter: (station_id = 4)
(7 rows)
QUERY PLAN (MAX)
----------------------------------------------------------------------------------------------------------
Aggregate (cost=3680.59..3680.60 rows=1 width=8)
-> Nested Loop (cost=0.43..3571.03 rows=43823 width=8)
-> Seq Scan on sensors (cost=0.00..6.69 rows=2 width=4)
Filter: (station_id = 4)
-> Index Only Scan using sensor_ind_timestamp on data (cost=0.43..1389.59 rows=39258 width=12)
Index Cond: (sensor_id = sensors.id)
(6 rows)
43..9.47 rows=1 width=8)
-> Nested Loop (cost=0.43..396254.63 rows=43823 width=8)
Join Filter: (data.sensor_id = sensors.id)
-> Index Scan using timestamp_ind on data (cost=0.43..254918.66 rows=4710976 width=12)
-> Materialize (cost=0.00..6.70 rows=2 width=4)
-> Seq Scan on sensors (cost=0.00..6.69 rows=2 width=4)
Filter: (station_id = 4)
(7 rows)
QUERY PLAN (MAX)
----------------------------------------------------------------------------------------------------------
Aggregate (cost=3680.59..3680.60 rows=1 width=8)
-> Nested Loop (cost=0.43..3571.03 rows=43823 width=8)
-> Seq Scan on sensors (cost=0.00..6.69 rows=2 width=4)
Filter: (station_id = 4)
-> Index Only Scan using sensor_ind_timestamp on data (cost=0.43..1389.59 rows=39258 width=12)
Index Cond: (sensor_id = sensors.id)
(6 rows)
Итак, мои два вопроса:
- Откуда возникает эта разница в производительности? Я видел принятый ответ здесь MIN/MAX vs.
ORDER BY и LIMIT , но это не совсем похоже на применение здесь. Любые хорошие ресурсы будут оценены.
- Есть ли более эффективные способы повышения производительности во всех случаях (совпадение строк с несоответствующей строкой), чем добавление проверки
EXISTS?
EDIT to address the questions in the comments below. I kept the initial query plans above for future reference:
Определения таблиц:
Table "public.sensors"
Column | Type | Modifiers
----------------------+------------------------+-----------------------------------------------------------------
id | integer | not null default nextval('sensors_id_seq'::regclass)
station_id | integer | not null
....
Indexes:
"sensor_primary" PRIMARY KEY, btree (id)
"ind_station_id" btree (station_id, id)
"ind_station" btree (station_id)
Table "public.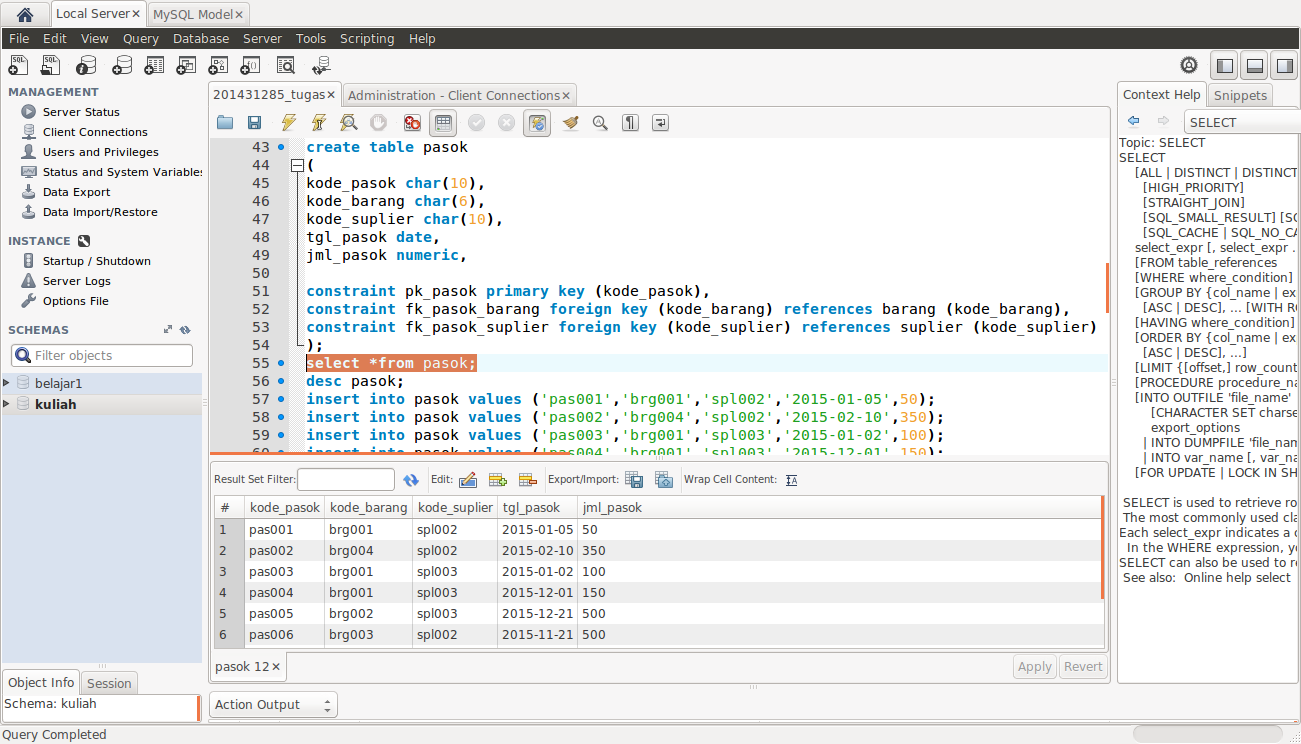 data"
Column | Type | Modifiers
-----------+--------------------------+------------------------------------------------------------------
id | integer | not null default nextval('data_id_seq'::regclass)
timestamp | timestamp with time zone | not null
sensor_id | integer | not null
avg | integer |
Indexes:
"timestamp_ind" btree ("timestamp" DESC)
"sensor_ind" btree (sensor_id)
"sensor_ind_timestamp" btree (sensor_id, "timestamp")
"sensor_ind_timestamp_desc" btree (sensor_id, "timestamp" DESC)
data"
Column | Type | Modifiers
-----------+--------------------------+------------------------------------------------------------------
id | integer | not null default nextval('data_id_seq'::regclass)
timestamp | timestamp with time zone | not null
sensor_id | integer | not null
avg | integer |
Indexes:
"timestamp_ind" btree ("timestamp" DESC)
"sensor_ind" btree (sensor_id)
"sensor_ind_timestamp" btree (sensor_id, "timestamp")
"sensor_ind_timestamp_desc" btree (sensor_id, "timestamp" DESC)
Note that I added ind_station_id on sensors just now after @Erwin’s suggestion below. Timings haven’t really changed drastically, still >1200ms in the ORDER BY DESC + LIMIT 1 case and ~0.9ms in the MAX case.
Планы запросов:
QUERY PLAN (ORDER BY)
----------------------------------------------------------------------------------------------------------
Limit (cost=0.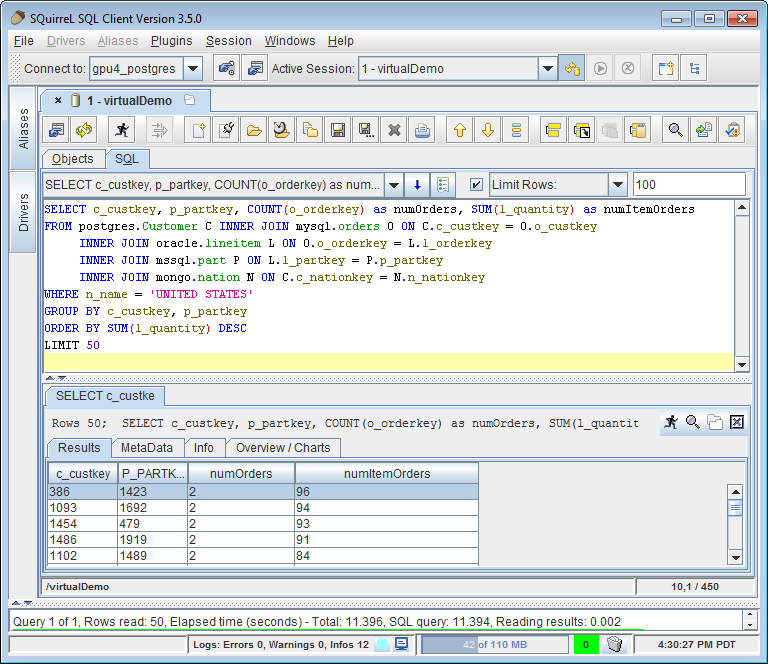 58..9.62 rows=1 width=8) (actual time=2161.054..2161.054 rows=0 loops=1)
Buffers: shared hit=3418066 read=47326
-> Nested Loop (cost=0.58..396382.45 rows=43823 width=8) (actual time=2161.053..2161.053 rows=0 loops=1)
Join Filter: (data.sensor_id = sensors.id)
Buffers: shared hit=3418066 read=47326
-> Index Scan using timestamp_ind on data (cost=0.43..255048.99 rows=4710976 width=12) (actual time=0.047..1410.715 rows=4710976 loops=1)
Buffers: shared hit=3418065 read=47326
-> Materialize (cost=0.14..4.19 rows=2 width=4) (actual time=0.000..0.000 rows=0 loops=4710976)
Buffers: shared hit=1
-> Index Only Scan using ind_station_id on sensors (cost=0.14..4.18 rows=2 width=4) (actual time=0.004..0.004 rows=0 loops=1)
Index Cond: (station_id = 4)
Heap Fetches: 0
Buffers: shared hit=1
Planning time: 0.478 ms
Execution time: 2161.090 ms
(15 rows)
QUERY (MAX)
----------------------------------------------------------------------------------------------------------
Aggregate (cost=3678.
58..9.62 rows=1 width=8) (actual time=2161.054..2161.054 rows=0 loops=1)
Buffers: shared hit=3418066 read=47326
-> Nested Loop (cost=0.58..396382.45 rows=43823 width=8) (actual time=2161.053..2161.053 rows=0 loops=1)
Join Filter: (data.sensor_id = sensors.id)
Buffers: shared hit=3418066 read=47326
-> Index Scan using timestamp_ind on data (cost=0.43..255048.99 rows=4710976 width=12) (actual time=0.047..1410.715 rows=4710976 loops=1)
Buffers: shared hit=3418065 read=47326
-> Materialize (cost=0.14..4.19 rows=2 width=4) (actual time=0.000..0.000 rows=0 loops=4710976)
Buffers: shared hit=1
-> Index Only Scan using ind_station_id on sensors (cost=0.14..4.18 rows=2 width=4) (actual time=0.004..0.004 rows=0 loops=1)
Index Cond: (station_id = 4)
Heap Fetches: 0
Buffers: shared hit=1
Planning time: 0.478 ms
Execution time: 2161.090 ms
(15 rows)
QUERY (MAX)
----------------------------------------------------------------------------------------------------------
Aggregate (cost=3678. 08..3678.09 rows=1 width=8) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=1
-> Nested Loop (cost=0.58..3568.52 rows=43823 width=8) (actual time=0.006..0.006 rows=0 loops=1)
Buffers: shared hit=1
-> Index Only Scan using ind_station_id on sensors (cost=0.14..4.18 rows=2 width=4) (actual time=0.005..0.005 rows=0 loops=1)
Index Cond: (station_id = 4)
Heap Fetches: 0
Buffers: shared hit=1
-> Index Only Scan using sensor_ind_timestamp on data (cost=0.43..1389.59 rows=39258 width=12) (never executed)
Index Cond: (sensor_id = sensors.id)
Heap Fetches: 0
Planning time: 0.435 ms
Execution time: 0.048 ms
(13 rows)
08..3678.09 rows=1 width=8) (actual time=0.009..0.009 rows=1 loops=1)
Buffers: shared hit=1
-> Nested Loop (cost=0.58..3568.52 rows=43823 width=8) (actual time=0.006..0.006 rows=0 loops=1)
Buffers: shared hit=1
-> Index Only Scan using ind_station_id on sensors (cost=0.14..4.18 rows=2 width=4) (actual time=0.005..0.005 rows=0 loops=1)
Index Cond: (station_id = 4)
Heap Fetches: 0
Buffers: shared hit=1
-> Index Only Scan using sensor_ind_timestamp on data (cost=0.43..1389.59 rows=39258 width=12) (never executed)
Index Cond: (sensor_id = sensors.id)
Heap Fetches: 0
Planning time: 0.435 ms
Execution time: 0.048 ms
(13 rows)
Так, как и в более ранних объяснениях, ORDER BY выполняет Scan, используя timestamp_in для данных , что не выполняется в случае MAX .
Postgres version:
Postgres from the Ubuntu repos: PostgreSQL 9. 4.5 on x86_64-unknown-linux-gnu, compiled by gcc (Ubuntu 5.2.1-21ubuntu2) 5.2.1 20151003, 64-bit
4.5 on x86_64-unknown-linux-gnu, compiled by gcc (Ubuntu 5.2.1-21ubuntu2) 5.2.1 20151003, 64-bit
Обратите внимание, что существуют ограничения NOT NULL , поэтому ORDER BY не нужно сортировать пустые строки.
Note also that I’m largely interested in where the difference comes from. While not ideal, I can retrieve data relatively quickly using EXISTS ( and then SELECT (~11ms).
Тесты Базы данных SQL с ответами
Тесты на знание SQL с ответами
Правильный вариант ответа отмечен знаком +
1. Для создания новой таблицы в существующей базе данных используют команду:
— NEW TABLE
+ CREATE TABLE
— MAKE TABLE
2. Имеются элементы запроса: 1. SELECT employees.name, departments.name; 2. ON employees.department_id=departments.id; 3. FROM employees; 4. LEFT JOIN departments. В каком порядке их нужно расположить, чтобы выполнить поиск имен всех работников со всех отделов?
— 1, 4, 2, 3
— 1, 2, 4, 3
+ 1, 3, 4, 2
3. Как расшифровывается SQL?
Как расшифровывается SQL?
+ structured query language
— strict question line
— strong question language
4. Запрос для выборки всех значений из таблицы «Persons» имеет вид:
— SELECT ALL Persons
+ SELECT * FROM Persons
— SELECT .[Persons]
5. Какое выражение используется для возврата только разных значений?
+ SELECT DISCINCT
— SELECT DIFFERENT
— SELECT UNIQUE
6. Для подсчета количества записей в таблице «Persons» используется команда:
— COUNT ROW IN Persons
+ SELECT COUNT(*) FROM Persons
— SELECT ROWS FROM Persons
7. Наиболее распространенным является тип объединения:
+ INNER JOIN
— FULL JOIN
— LEFT JOIN
8. Что возвращает запрос SELECT * FROM Students?
+ Все записи из таблицы «Students»
— Рассчитанное суммарное количество записей в таблице «Students»
— Внутреннюю структуру таблицы «Students»
9. Запрос «SELECT name ___ Employees WHERE age ___ 35 AND 50» возвращает имена работников, возраст которых от 35 до 50 лет. Заполните пропущенные места в запросе.
Запрос «SELECT name ___ Employees WHERE age ___ 35 AND 50» возвращает имена работников, возраст которых от 35 до 50 лет. Заполните пропущенные места в запросе.
— INTO, IN
— FROM, IN
+ FROM, BETWEEN
тест 10. Какая агрегатная функция используется для расчета суммы?
+ SUM
— AVG
— COUNT
11. Запрос для выборки первых 14 записей из таблицы «Users» имеет вид:
+ SELECT * FROM Users LIMIT 14
— SELECT * LIMIT 14 FROM Users
— SELECT * FROM USERS
12. Выберите верное утверждение:
— SQL чувствителен к регистру при написании запросов
— SQL чувствителен к регистру в названиях таблиц при написании запросов
— SQL нечувствителен к регистру
13. Заполните пробелы в запросе «SELECT ___, Сountry FROM ___ », который возвращает имена заказчиков и страны, где они находятся, из таблицы «Customers».
— *, Customers
— NULL, Customers
+ Name, Customers
14. Запрос, возвращающий все значения из таблицы «Countries», за исключением страны с ID=8, имеет вид:
— SELECT * FROM Countries EXP ID=8
+ SELECT * FROM Countries WHERE ID !=8
— SELECT ALL FROM Countries LIMIT 8
15. Напишите запрос для выборки данных из таблицы «Customers», где условием является проживание заказчика в городе Москва
+ SELECT * FROM Customers WHERE City=”Moscow”
— SELECT City=”Moscow” FROM Customers
— SELECT Customers WHERE City=”Moscow”
16. Напишите запрос, возвращающий имена, фамилии и даты рождения сотрудников (таблица «Employees»). Условие – в фамилии содержится сочетание «se».
— SELECT FirstName, LastName, BirthDate from Employees WHERE LastName=“se”
— SELECT * from Employees WHERE LastName like “_se_”
+ SELECT FirstName, LastName, BirthDate from Employees WHERE LastName like “%se%”
17.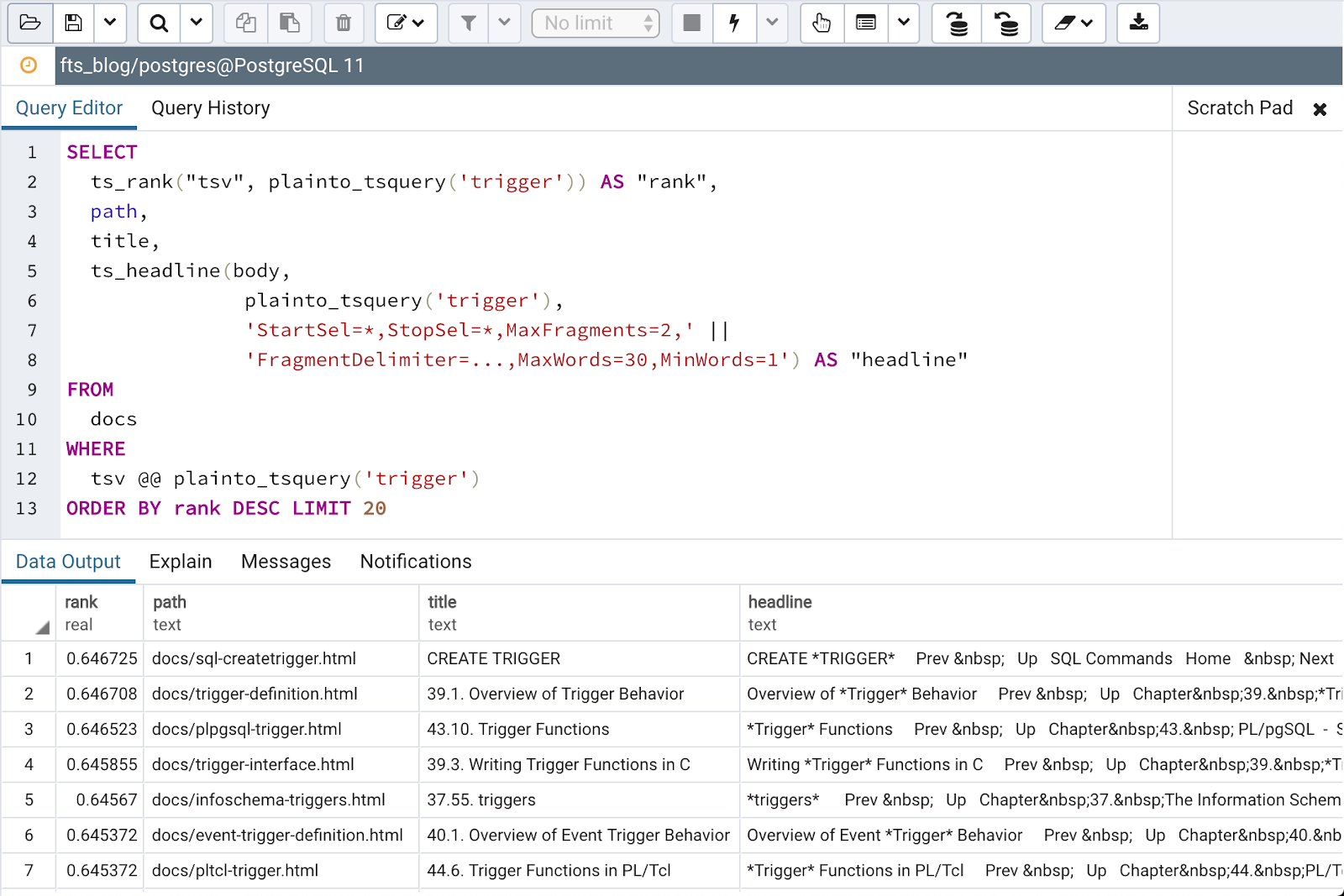 Какая функция позволяет преобразовать все буквы в выбранном столбце в верхний регистр?
Какая функция позволяет преобразовать все буквы в выбранном столбце в верхний регистр?
— TOP
+ UPPER
— UP
18. Напишите запрос, позволяющий переименовать столбец LastName в Surname в таблице «Employees».
— RENAME LastName into Surname FROM Employees
+ ALTER TABLE Employees CHANGE LastName Surname varchar(50)
— ALTER TABLE Surname(LastName) FROM Employees
19. Для создания новой виртуальной таблицы, которая базируется на результатах сделанного ранее SQL запроса, используется команда:
— CREATE VIRTUAL TABLE
+ CREATE VIEW
— ALTER VIEW
тест-20. В таблице «Emlpoyees» содержатся данные об именах, фамилиях и зарплате сотрудников. Напишите запрос, который изменит значение зарплаты с 2000 на 2500 для сотрудника с ID=7.
— SET Salary=2500 FROM Salary=2000 FOR ID=7 FROM Employees
— ALTER TABLE Employees Salary=2500 FOR ID=7
+ UPDATE Employees SET Salary=2500 WHERE ID=7
21. К какому результату приведет выполнение запроса DROP DATABASE Users?
К какому результату приведет выполнение запроса DROP DATABASE Users?
+ Полное удаление базы данных «Users»
— Блокировка на внесение изменений в базу данных «Users»
— Удаление таблицы «Users» из текущей базы данных
22. В таблице «Animals» базы данных зоопарка содержится информация обо всех обитающих там животных, в том числе о лисах: red fox, grey fox, little fox. Напишите запрос, возвращающий информацию о возрасте лис.
— SELECT %fox age FROM Animals
+ SELECT age FROM Animals WHERE Animal LIKE «%fox»
— SELECT age FROM %Fox.Animals
23. Что возвращает запрос SELECT FirstName, LastName, Salary FROM Employees Where Salary<(Select AVG(Salary) FROM Employees) ORDER BY Salary DESC?
— Имена, фамилии и зарплаты сотрудников, значения которых соответствуют среднему значению среди всех сотрудников
— Имена, фамилии сотрудников и их среднюю зарплату за весь период работы, с выполнением сортировки по убыванию
+ Имена, фамилии и зарплаты сотрудников, для которых справедливо условие, что их зарплата ниже средней, с выполнением сортировки зарплаты по убыванию
24. Напишите запрос, возвращающий значения из колонки «FirstName» таблицы «Users».
Напишите запрос, возвращающий значения из колонки «FirstName» таблицы «Users».
+ SELECT FirstName FROM Users
— SELECT FirstName.Users
— SELECT * FROM Users.FirstName
25. Напишите запрос, возвращающий информацию о заказчиках, проживающих в одном из городов: Москва, Тбилиси, Львов.
— SELECT Moscow, Tbilisi, Lvov FROM Customers
+ SELECT * FROM Customers WHERE City IN (‘Moscow’, ‘Tbilisi’, ‘Lvov’)
— SELECT City IN (‘Moscow’, ‘Tbilisi’, ‘Lvov’) FROM Customers
26. Какая команда используется для объединения результатов запроса без удаления дубликатов?
UNION
+ UNION ALL
— FULL JOIN
27. Оператор REVOKE предназначен для:
— Предоставления пользователю или группе пользователей прав на осуществление определенных операций;
— Задавания пользователю или группе пользователей запрета, который является приоритетным по сравнению с разрешением;
+ Отзыва у пользователя или группы пользователей выданных ранее разрешений
28. Для чего в SQL используются aliases?
Для чего в SQL используются aliases?
+ Для назначения имени источнику данных в запросе при использовании выражения в качестве источника данных или для упрощения структуры запросов
— Для переименования полей
— Для более точного указания источника данных, если в базе данных содержатся таблицы с одинаковыми названиями полей
29. Напишите запрос, который будет возвращать значения городов из таблицы «Countries».
— SELECT * FROM Countries WHERE ID=”City”
+ SELECT City FROM Countries
— SELECT City.Countries
тест_30. Имеются элементы запроса: 1. ORDER BY Name; 2. WHERE Age<19; 3. FROM Students; 4. SELECT FirstName, LastName. В каком порядке их нужно расположить, чтобы выполнить поиск имен и фамилий студентов в возрасте до 19 лет с сортировкой по имени?
— 1, 4, 2, 3
— 4, 2, 3, 1
+ 4, 3, 2, 1
31. Для чего в SQL используется оператор PRIVILEGUE?
— Для наделения суперпользователя правами администратора
— Для выбора пользователей с последующим наделением их набором определенных прав
+ Такого оператора не существует
32. Напишите запрос, который будет возвращать текущую дату.
+ SELECT GetDate()
— SELECT TodayDate()
— SELECT Date(Today)
33. Какой оператор используется для выборки значений в пределах заданного диапазона?
— WITHIN
— IN
+ BETWEEN
MySQL LIMIT
Сводка : В этом руководстве вы узнаете, как использовать предложение MySQL LIMIT для ограничения количества строк, возвращаемых запросом.
Введение в MySQL LIMIT Предложение
Предложение LIMIT используется в операторе SELECT для ограничения количества возвращаемых строк. Предложение LIMIT принимает один или два аргумента. Значения обоих аргументов должны быть нулевыми или положительными целыми числами.
Ниже показан синтаксис предложения LIMIT с двумя аргументами:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT select_list ИЗ table_name LIMIT [смещение,] row_count;
В этом синтаксисе:
- Смещение
-
row_countопределяет максимальное количество возвращаемых строк.
На следующем рисунке показано предложение LIMIT :
Когда вы используете предложение LIMIT с одним аргументом, MySQL будет использовать этот аргумент для определения максимального числа строк, возвращаемых из первой строки набора результатов.
Следовательно, эти два предложения эквивалентны:
Язык кода: SQL (язык структурированных запросов) (sql)
LIMIT row_count;
и
LIMIT 0, row_count;
В дополнение к приведенному выше синтаксису MySQL предоставляет следующее альтернативное предложение LIMIT для совместимости с PostgreSQL.
Язык кода: SQL (язык структурированных запросов) (sql)
LIMIT row_count OFFSET offset
LIMIT и Предложения ORDER BY
Оператор SELECT без предложения ORDER BY возвращает строки в неопределенном порядке. Это означает, что строки могут располагаться в любом порядке. Когда вы примените предложение LIMIT к этому неупорядоченному набору результатов, вы не будете знать, какие строки вернет запрос.
Например, вы можете захотеть получить строки с пятой по десятую, но с пятой по десятую в каком порядке? Порядок строк неизвестен, если вы не укажете условие ORDER BY .
Следовательно, рекомендуется всегда использовать предложение LIMIT с предложением ORDER BY , чтобы ограничить строки результатов в уникальном порядке.
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ select_list FROM table_name ORDER BY order_expression LIMIT смещение, row_count;
На следующем рисунке показан порядок оценки предложения LIMIT в операторе SELECT :
MySQL LIMIT примеров
Мы будем используйте для демонстрации таблицу customers из образца базы данных.
1) Использование MySQL LIMIT для получения самых высоких или самых низких строк
Этот оператор использует предложение LIMIT для получения пяти лучших клиентов с наивысшим кредитным рейтингом:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT номер клиента, Имя Клиента, кредитный лимит ИЗ клиенты ЗАКАЗАТЬ ПО кредитному лимиту УДАЛЕНИЕ LIMIT 5;
Попробовать
В этом примере:
- Во-первых, предложение
ORDER BYсортирует клиентов по кредитам в порядке убывания. - Затем предложение
LIMITвозвращает первые 5 строк.
Аналогичным образом в этом примере используется предложение LIMIT для поиска 5 клиентов с наименьшими кредитами:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT номер клиента, Имя Клиента, кредитный лимит ИЗ клиенты ЗАКАЗАТЬ ПО кредитному лимиту LIMIT 5;
Попробовать
В этом примере:
- Во-первых, предложение
ORDER BYсортирует клиентов по кредитам в порядке убывания. - Затем предложение
LIMITвозвращает первые 5 строк.
Поскольку более 5 клиентов имеют нулевые кредиты, результат вышеприведенного запроса может привести к противоречивому результату.
Чтобы решить эту проблему, вам нужно добавить дополнительный столбец в предложение ORDER BY , чтобы ограничить строку в уникальном порядке:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT номер клиента, Имя Клиента, кредитный лимит ИЗ клиенты СОРТИРОВАТЬ ПО кредитный лимит, номер клиента LIMIT 5;
Попробовать
2) Использование MySQL LIMIT для разбивки на страницы
Когда вы отображаете данные в приложениях, вы часто хотите разделить строки на страницы, где каждая страница содержит определенное количество строк, например 5, 10 или 20.
Чтобы рассчитать количество страниц, вы получаете общее количество строк, разделенное на количество строк на странице. Для получения строк определенной страницы вы можете использовать предложение LIMIT .
В этом запросе используется агрегатная функция COUNT (*) для получения итоговых строк из таблицы customers :
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT COUNT (*) FROM customers;
Язык кода: JavaScript (javascript)
+ ---------- + | СЧЁТ (*) | + ---------- + | 122 | + ---------- + 1 ряд в комплекте (0.00 сек)
Предположим, что каждая страница имеет 10 строк, для отображения 122 клиентов у вас есть 13 страниц. Последняя 13-я страница содержит только две строки.
Этот запрос использует предложение LIMIT для получения строк страницы 1, которая содержит первые 10 клиентов, отсортированных по имени клиента:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT номер клиента, Имя Клиента ИЗ клиенты ЗАКАЗАТЬ ПО customerName LIMIT 10;
Попробовать
В этом запросе используется предложение LIMIT для получения строк второй страницы, которые включают строку 11-20:
Язык кода: SQL (язык структурированных запросов) (sql)
ВЫБРАТЬ номер клиента, Имя Клиента ИЗ клиенты ЗАКАЗАТЬ ПО customerName ПРЕДЕЛ 10, 10;
Попробовать
В этом примере предложение LIMIT 10, 10 возвращает 10 строк для строки 11-20.
3) Использование MySQL LIMIT для получения n th наивысшего или наименьшего значения
Чтобы получить n-е наибольшее или наименьшее значение, вы используете следующее предложение LIMIT :
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT select_list FROM table_name ЗАКАЗАТЬ ПО sort_expression ПРЕДЕЛ n-1, 1;
Предложение LIMIT n-1, 1 возвращает строку 1 , начиная со строки n .
Например, следующий код находит клиента, у которого второй по величине кредит:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT Имя Клиента, кредитный лимит ИЗ клиенты СОРТИРОВАТЬ ПО creditLimit DESC LIMIT 1,1;
Попробовать
Давайте еще раз проверим результат. Этот запрос возвращает всех клиентов, отсортированных по кредитам от большего к меньшему:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT Имя Клиента, кредитный лимит ИЗ клиенты СОРТИРОВАТЬ ПО creditLimit DESC;
Попробовать
Как ясно видно из выходных данных, результат оказался правильным, как и ожидалось.
Обратите внимание, что этот метод работает, когда нет двух клиентов с одинаковыми кредитными лимитами. Для получения более точного результата следует использовать оконную функцию DENSE_RANK () .
В этом руководстве вы узнали, как использовать предложение MySQL LIMIT для ограничения количества строк, возвращаемых оператором SELECT .
- Было ли это руководство полезным?
- Да Нет
SQL: SELECT LIMIT Statement
В этом руководстве по SQL объясняется, как использовать оператор SELECT LIMIT в SQL с синтаксисом и примерами.
Описание
Оператор SQL SELECT LIMIT используется для извлечения записей из одной или нескольких таблиц в базе данных и ограничения количества возвращаемых записей на основе предельного значения.
СОВЕТ: SELECT LIMIT поддерживается не во всех базах данных SQL.
Для таких баз данных, как SQL Server или MSAccess, используйте оператор SELECT TOP, чтобы ограничить результаты. Оператор SELECT TOP является проприетарным эквивалентом оператора SELECT LIMIT от Microsoft.
Синтаксис
Синтаксис оператора SELECT LIMIT в SQL:
Выражения SELECT ИЗ столов [ГДЕ условия] [ORDER BY выражение [ASC | DESC]] LIMIT number_rows [OFFSET offset_value];
Параметры или аргументы
- выражений
- Столбцы или вычисления, которые вы хотите получить.
- столов
- Таблицы, из которых вы хотите получить записи. В предложении FROM должна быть хотя бы одна таблица.
- ГДЕ условия
- Необязательно. Условия, которые должны быть выполнены для выбора записей.
- ORDER BY выражение
- Необязательно. Он используется в операторе SELECT LIMIT, чтобы вы могли упорядочить результаты и выбрать те записи, которые хотите вернуть. ASC — это возрастающий порядок, а DESC — убывающий.
- LIMIT number_rows
- Указывает ограниченное количество строк в результирующем наборе, которое должно быть возвращено, на основе number_rows .Например, LIMIT 10 вернет первые 10 строк, соответствующих критериям SELECT. Здесь порядок сортировки имеет значение, поэтому не забудьте правильно использовать предложение ORDER BY.
- OFFSET значение_смещения
- Необязательно. Первая строка, возвращаемая LIMIT, будет определяться значением offset_value .
Пример — использование ключевого слова LIMIT
Давайте посмотрим, как использовать оператор SELECT с предложением LIMIT в SQL.
Например:
ВЫБЕРИТЕ contact_id, last_name, first_name ИЗ контактов ГДЕ веб-сайт = 'TechOnTheNet.com ' ЗАКАЗАТЬ ПО contact_id DESC LIMIT 5;
В этом примере SQL SELECT LIMIT будут выбраны первые 5 записей из таблицы контактов , где веб-сайт — «TechOnTheNet.com». Обратите внимание, что результаты отсортированы по contact_id в порядке убывания, поэтому это означает, что оператором SELECT LIMIT будет возвращено 5 самых больших значений contact_id .
Если есть другие записи в таблице контактов , у которых есть веб-сайт , значение равно ‘TechOnTheNet.com ‘, они не будут возвращены оператором SELECT LIMIT в SQL.
Если бы мы хотели выбрать 5 наименьших значений contact_id вместо наибольших, мы могли бы изменить порядок сортировки следующим образом:
ВЫБЕРИТЕ contact_id, last_name, first_name ИЗ контактов ГДЕ сайт = 'TechOnTheNet.com' ЗАКАЗАТЬ ПО contact_id ASC LIMIT 5;
Теперь результаты будут отсортированы по contact_id в порядке возрастания, так что первые 5 наименьших записей contact_id , имеющих веб-сайт TechOnTheNet.com ‘будет возвращено этим оператором SELECT LIMIT. Никакие другие записи не будут возвращены этим запросом.
Пример — использование ключевого слова OFFSET
Ключевое слово offset позволяет смещать первую запись, возвращаемую предложением LIMIT. Например:
ПРЕДЕЛ 3 СМЕЩЕНИЕ 1
Это предложение LIMIT вернет 3 записи в результирующем наборе со смещением 1. Это означает, что оператор SELECT пропустит первую запись, которая обычно будет возвращена, и вместо этого вернет вторую, третью и четвертую записи.
Давайте посмотрим, как использовать оператор SELECT LIMIT с предложением OFFSET в SQL.
Например:
ВЫБЕРИТЕ contact_id, last_name, first_name ИЗ контактов ГДЕ сайт = 'TechOnTheNet.com' ЗАКАЗАТЬ ПО contact_id DESC LIMIT 5 OFFSET 2;
В этом примере SQL SELECT LIMIT используется OFFSET 2, что означает, что первая и вторая записи в наборе результатов будут пропущены … и затем будут возвращены следующие 5 строк.
Получить подмножество строк, созданных запросом
Резюме : в этом руководстве вы узнаете, как использовать предложение PostgreSQL LIMIT для получения подмножества строк, созданных запросом.
Введение в PostgreSQL Предложение LIMIT
PostgreSQL LIMIT — это необязательный пункт оператора SELECT , который ограничивает количество строк, возвращаемых запросом.
Ниже показан синтаксис предложения LIMIT :
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT select_list FROM table_name ЗАКАЗАТЬ ПО sort_expression LIMIT row_count
Оператор возвращает row_count строк, сгенерированных запросом.Если row_count равно нулю, запрос возвращает пустой набор. В случае, если row_count равно NULL , запрос возвращает тот же набор результатов, так как он не имеет предложения LIMIT .
Если вы хотите пропустить несколько строк перед возвратом row_count строк, используйте предложение OFFSET , помещенное после предложения LIMIT , как следующий оператор:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT select_list FROM table_name LIMIT row_count OFFSET row_to_skip;
Оператор сначала пропускает row_to_skip строк, а затем возвращает row_count строк, сгенерированных запросом.Если row_to_skip равно нулю, инструкция будет работать так, как будто в ней нет предложения OFFSET .
Поскольку таблица может хранить строки в неопределенном порядке, при использовании предложения LIMIT всегда следует использовать предложение ORDER BY для управления порядком строк. Если вы не используете предложение ORDER BY , вы можете получить набор результатов с неопределенным порядком строк.
Примеры PostgreSQL LIMIT
Давайте рассмотрим несколько примеров использования предложения PostgreSQL LIMIT .Для демонстрации мы будем использовать таблицу film в базе данных примеров.
1) Использование PostgreSQL LIMIT для ограничения количества возвращаемых строк. Пример
В этом примере используется предложение LIMIT для сортировки первых пяти фильмов по film_id :
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT film_id, заглавие, release_year ИЗ фильм СОРТИРОВАТЬ ПО film_id LIMIT 5;
2) Использование PostgreSQL LIMIT с примером OFFSET
Чтобы получить 4 фильма, начиная с четвертого, заказанного с помощью film_id , вы используете как LIMIT , так и OFFSET пункты следующим образом:
Язык кода: SQL (язык структурированных запросов) (sql)
SELECT film_id, заглавие, release_year ИЗ фильм СОРТИРОВАТЬ ПО film_id LIMIT 4 OFFSET 3;
3) Использование PostgreSQL LIMIT OFFSSET для получения N строк сверху / снизу
Как правило, вы часто используете предложение LIMIT для выбора строк с наибольшим или нижним числом строк.