|
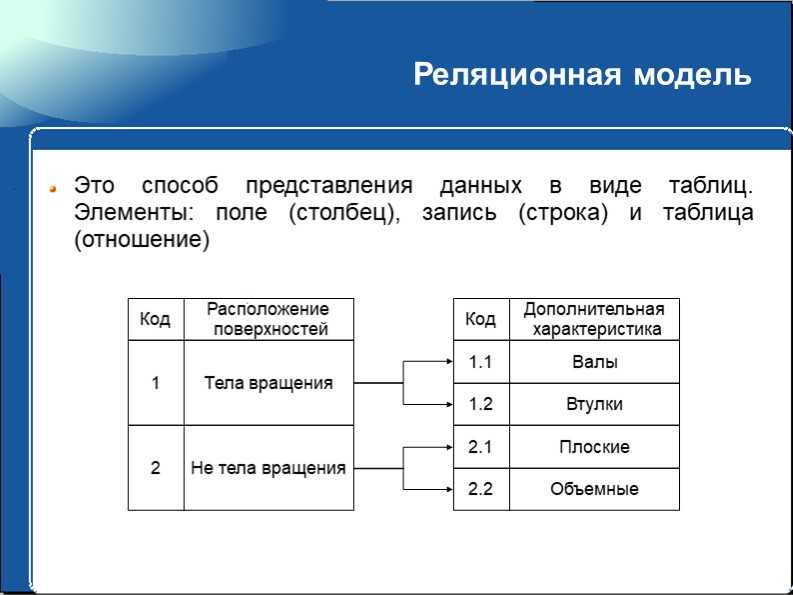
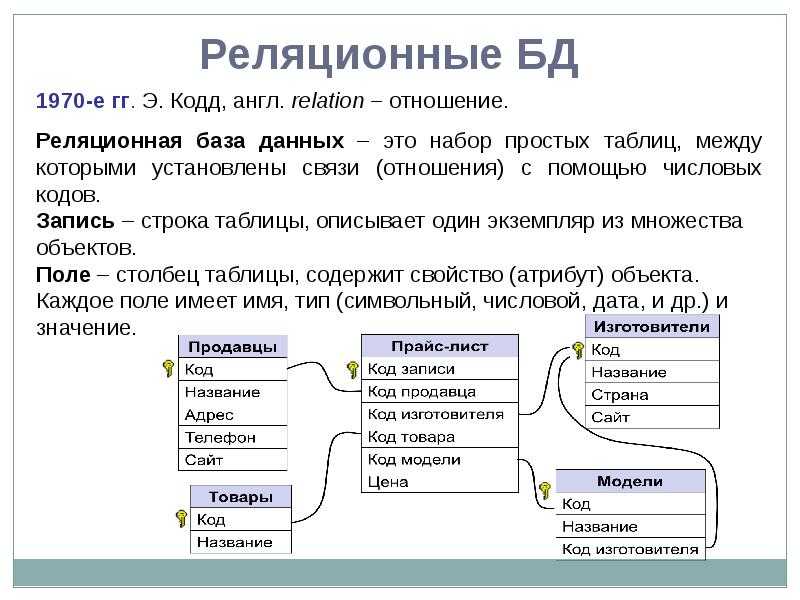
5.4.1. Реляционные базы данных Все реляционные базы данных используют в качестве модели хранения данных двумерные таблицы. Эта модель выбрана потому что она в основном знакома всем пользователям и рассматривается как «естественный» путь представления данных. Любая система данных, не имеет значения какой сложности, может быть сведена к набору таблиц (или «отношений» в терминологии СУРБД) с некоторой избыточностью. Избыточность контролируется путем приведения отношений к канонической «нормальной» форме, которая минимизирует ненужную избыточность без уменьшения связей между элементами данных.
Каждая строка олицетворяет уникальный элемент данных, который ею и описывается. Столбцы представляют собой отдельные куски информации (атрибуты данных), которые известны о данном элементе. Строки обычно называют записями, а столбцы — полями. Кроме того, для обработки отношений разрешены только следующие операции:
Другие операции с данными обычно не поддерживаются в базах с реляционной структурой. Добавление произвольных данных, которые, например, не соответствуют ни одному полю в описании данных, запрещено. Добавление поля для произвольных данных потребовало бы перестройки (реструктурирования) базы данных. А этот, зачастую очень длительный, процесс может выполняться только когда базой данных никто не пользуется. Вообще, лишь немногие реальные базы данных могут быть описаны при помощи единственной таблицы. Большинство приложений используют множество таблиц, которые содержат столбцы (поля) с одинаковым именем. Эти общие данные позволяют объединяя две (или несколько) таблицы, строить осмысленные ассоциации. Лучше всего это иллюстрируется примером. Рассмотрим два отношения «Служащий» и «Отдел», показанные на рис.5.14. Рис. 5.14. Отношения «Служащий» и «Отдел». В этом примере поля Номер Служащего и Номер Отдела выделены; это указывает на то, что эти поля — первичные ключи. Во многих случаях это объединение не такое простое. Предположим, нам требуется найти способ для определения, кто является Руководителем для любого Служащего. Мы могли бы создать следующую структуру данных (рис.5.15). Эта на вид интуитивная структура может вызвать проблемы из-за избыточности связи отношения «Руководитель», связанного с отношением «Служащий» как напрямую, так и через отношение «Отдел». Эта избыточность позволяет руководителю служащего отличаться от руководителя отдела служащего. Если это не разрешено, то приведенная структура таблиц не подходит. Рис. 5.15. Отношения «Служащий», «Отдел» и «Руководитель». Рис. 5.16. Вместо нее более подходящей была бы структура, представленная на рис.5.16. Эта структура удаляет избыточность, которая позволяет Служащему иметь Руководителя, отличного от Руководителя его Отдела. Но делая это, она удаляет прямую связь, которая может быть желательна с точки зрения производительности больших баз данных. Эта взаимосвязь между производительностью и целостностью данных присутствует фактически во всех моделях баз данных. Простой реальный пример может потребовать еще более сложной структуры. Пусть Служащий является членом более чем одного Отдела. Правила соединения в реляционных базах данных не разрешают связей «многие-ко-многим» (которые можно обозначить при помощи стрелки с двойным указателем на каждом конце). Чтобы представить отношение с такими связями (например, каждый Отдел имеет многочисленных Служащих и каждый Служащий может быть членом Многочисленных Отделов), нам надо создать отдельное отношение, которое является гибридом двух столбцов (рис. Рис. 5.17. Отношения «Служащий», «Назначение», «Отдел» и «Руководитель». Здесь отношение «Назначение» содержит запись для каждого отдела, сотрудником которого является служащий. То есть, если Служащий работает в Отделе, то соответствующие Номер Служащего и Номер отдела обнаруживаются точно в одной записи отношения «Назначение». Поле Номер Назначения фактически не нужно, так как Номер Служащего и Номер Отдела могут вместе служить ключем. В большинстве (но не во всех) СУРБД разрешены отношения с составными ключами. Для тех из них, в которых ключ должен быть представлен обязательно одним полем, структура будет такой, как представлена выше. «Естественный подход» с использованием таблиц может оказаться еще более «притянутым за уши», когда данные — разреженные. Разреженные данные означают, что не каждое поле в каждой записи содержит данные. В некоторых приложениях данные очень разреженные — только несколько из большого числа столбцов, определенных для данного отношения, могут содержать данные в каком-либо заданном ряду. Реляционные базы данных были бы совсем непригодны, если бы эти разреженные данные действительно хранились внутри прямоугольного массива, так как для этих пустых элементов данных надо было бы выделять пространство. |

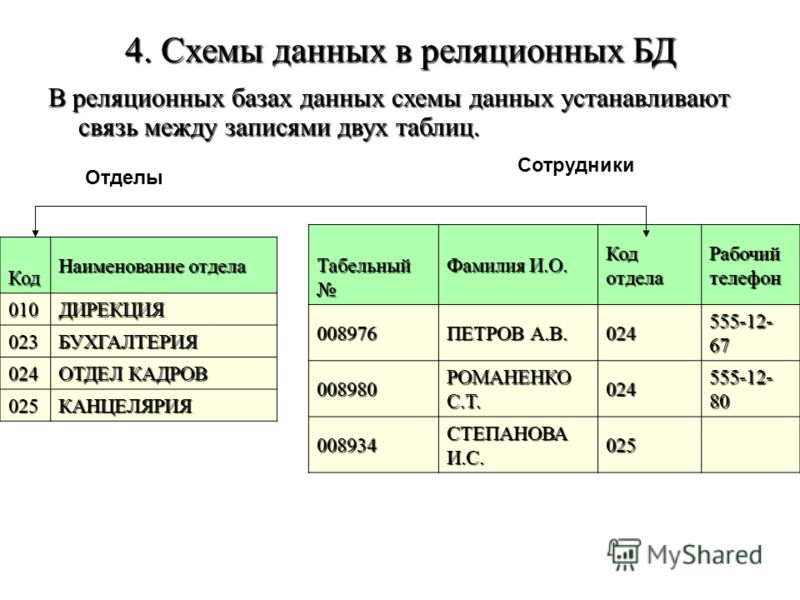
 Это означает, что элементы данных в этих полях единственным образом определяют запись (т.е. никакие две записи не имеют одинакового элемента данных в ключевом поле). Более того, поле N отдела обнаруживается в обеих таблицах. Это позволяет объединить две таблицы таким образом, чтобы, например, определять Название отдела для любого заданного Служащего.
Это означает, что элементы данных в этих полях единственным образом определяют запись (т.е. никакие две записи не имеют одинакового элемента данных в ключевом поле). Более того, поле N отдела обнаруживается в обеих таблицах. Это позволяет объединить две таблицы таким образом, чтобы, например, определять Название отдела для любого заданного Служащего.
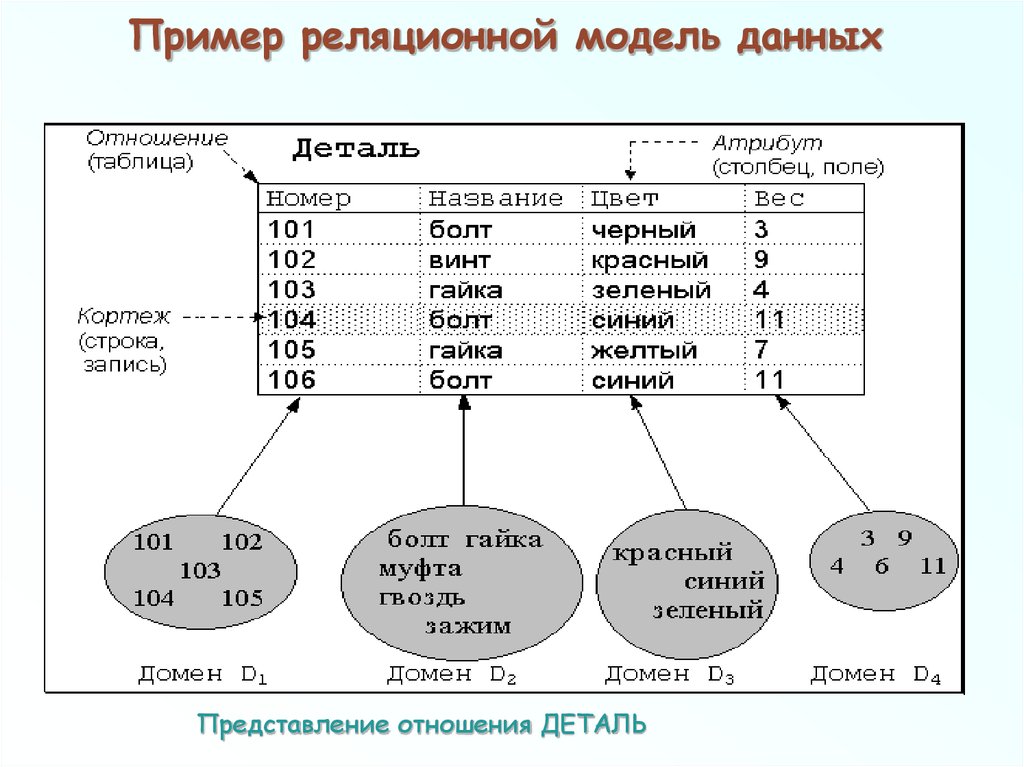 5.17):
5.17):
Реляционные базы данных | это… Что такое Реляционные базы данных?
Толкование
- Реляционные базы данных
Реляционные базы данных
Реляционная база данных — база данных, основанная на реляционной модели данных. Слово «реляционный» происходит от англ.
Использование реляционных баз данных было предложено доктором Коддом из компании IBM в 1970 году.
Содержание
- 1 Нормализация
- 2 Нормальные формы
- 3 См. также
- 4 Примечания
- 5 Литература
Нормализация
Основная статья: Нормализация баз данных
Целью нормализации является устранение недостатков структуры базы данных, приводящих к вредной избыточности в данных, которая в свою очередь потенциально приводит к различным аномалиям и нарушениям целостности данных.
Теоретики реляционных баз данных в процессе развития теории выявили и описали типичные примеры избыточности и способы их устранения.
Нормальные формы
Основная статья: Нормальные формы
Нормальная форма — формальное свойство отношения, которое характеризует степень избыточности хранимых данных и возможные проблемы. Каждая следующая нормальная форма в нижеприведенном списке (кроме ДКНФ) в некотором смысле является более совершенной, чем предыдущая, с точки зрения устранения избыточности.
- Первая нормальная форма (1НФ, 1NF)
- Вторая нормальная форма (2НФ, 2NF)
- Третья нормальная форма (3НФ, 3NF)
- Нормальная форма Бойса — Кодда (НФБК, BCNF)
- Четвёртая нормальная форма (4НФ, 4NF)
- Пятая нормальная форма (5НФ, 5NF)
- Доменно-ключевая нормальная форма (ДКНФ, DKNF).
См. также
- Реляционная СУБД
- Хранилище данных
- Первичный ключ
- Внешний ключ
- SQL
Примечания
- ↑ Строгое изложение предполагает использование строгих математических терминов
Литература
- К. Дж. Дейт Введение в системы баз данных = Introduction to Database Systems. — 8-е изд. — М.: «Вильямс», 2006. — С. 1328. — ISBN 0-321-19784-4
- ISBN 5-94157-805-9 Рудикова.
 Разработка баз приложений СУБД
Разработка баз приложений СУБД
СУБД Концепции (Эдгар Кодд, Кристофер Дейт, …)
База данных | Модель данных | Реляционные базы данных | Реляционная модель данных | Реляционная алгебра
Первичный ключ — Внешний ключ — Суррогатный ключ — Superkey — Возможный ключ
Нормальная форма | Ссылочная целостность | Реляционные СУБД | Распределённые СУБД | ACIDОбъекты
Триггер (Trigger) | Представление (View) | Таблица (Table) | Курсор (Cursor) | Журнал транзакций | Транзакция | Индекс | Хранимая процедура | PartitionSQL (DCL, DDL, DML)
SELECT | INSERT | UPDATE | MERGE | DELETE | JOIN | UNION | CREATE | ALTER | DROP
Сравнение синтаксисаРеализации систем управления базами данных Типы реализаций
Flat file | Deductive | Dimensional | Иерархическая | Объектно-ориентированная | TemporalСвободные системы
Firebird | Ingres | Kexi | PostgreSQL | MySQL | Sav Zigzag | SQLiteКомпоненты
Язык запросов | Оптимизатор запросов | План выполнения запроса | ODBC | JDBCWikimedia Foundation.
 2010.
2010.- Электрический двигатель
- Система управления базами данных
Игры ⚽ Нужно сделать НИР?
Полезное
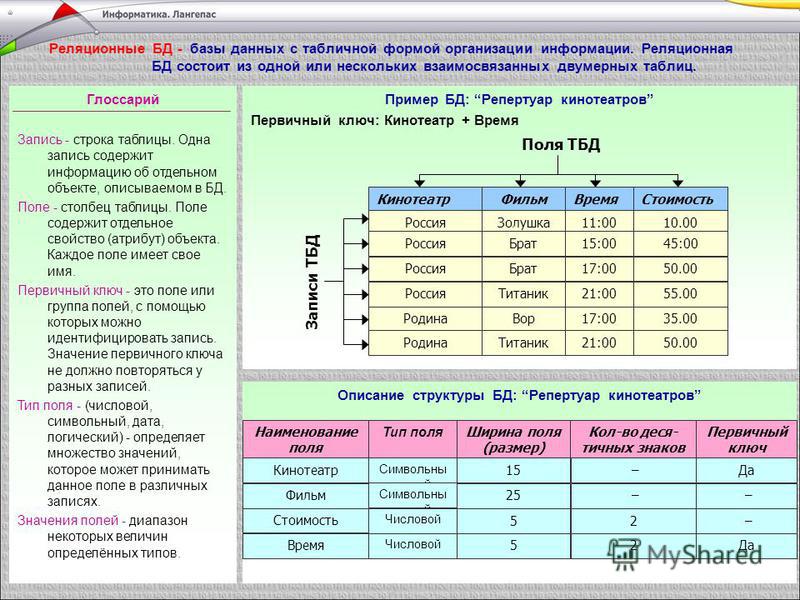
Что такое реляционная база данных? (Определение, варианты)
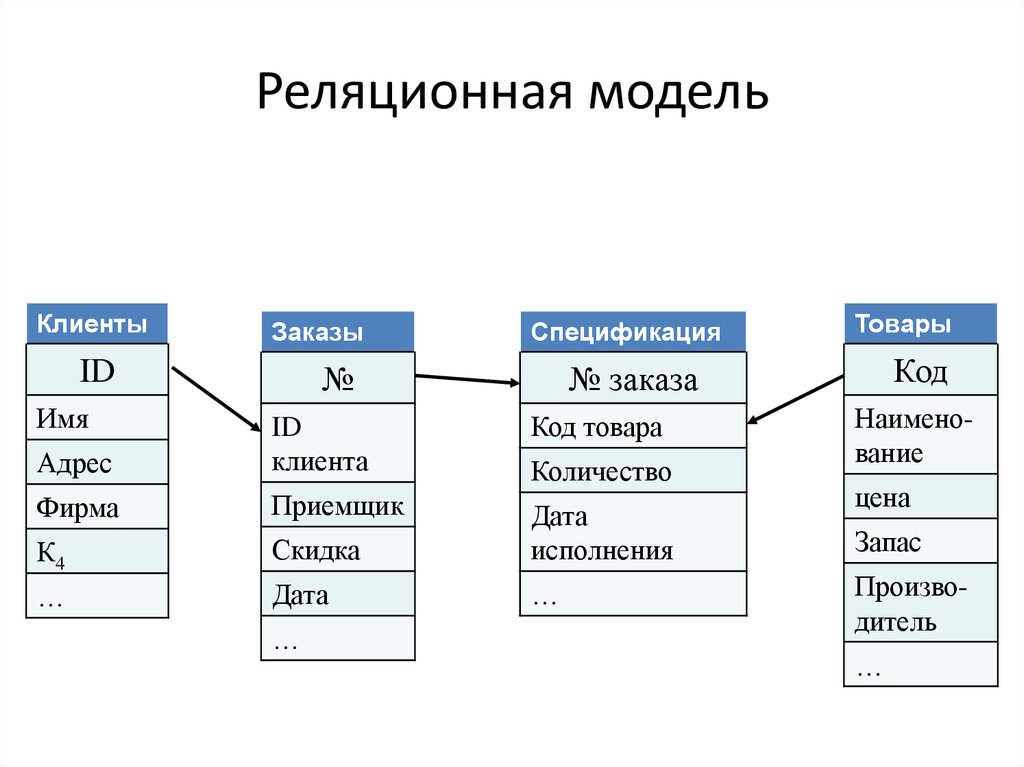
Реляционные базы данных состоят из таблиц, где каждая таблица содержит строки и столбцы, и каждая строка имеет уникальный идентификатор, известный как первичный ключ.
Давайте представим набор данных, содержащий 100 клиентов с их именами, адресами и любимым продуктом. При использовании реляционной модели одна таблица может содержать список продуктов с четырьмя столбцами для хранения первичного ключа, обзора продукта, названия продукта и идентификатора продукта. Наконец, в другой таблице может быть 100 строк для хранения всех 100 клиентов и четыре столбца для первичного ключа, имени клиента, адреса клиента и идентификатора продукта. Мы можем использовать значение идентификатора продукта, чтобы построить связь между этими двумя таблицами. Мы можем использовать язык структурированных запросов (SQL) для дальнейшего запроса наших таблиц и получения дополнительной информации о продуктах, такой как название продукта или обзор продукта.
Мы можем использовать язык структурированных запросов (SQL) для дальнейшего запроса наших таблиц и получения дополнительной информации о продуктах, такой как название продукта или обзор продукта.
Дополнительная информация из встроенного технического словаря Что такое база данных?
Как работает реляционная база данных?
Реляционные базы данных основаны на реляционной модели данных, которая позволяет специалистам по обработке данных эффективно запрашивать информацию из нескольких таблиц, связанных общими атрибутами.
Для запроса информации из реляционной базы данных обычно используется SQL, основная точка контакта с реляционной базой данных. Некоторые поставщики создают свои собственные реализации SQL, такие как MySQL, PostgreSQL и Oracle SQL. Эти реализации могут отличаться по своему синтаксису или другим функциям от SQL. Например, PostgreSQL предлагает безопасное для транзакций усечение, которое позволяет пользователям восстанавливать удаленные данные, если что-то пойдет не так с транзакцией, связанной с действием усечения; MySQL не поддерживает эту функцию.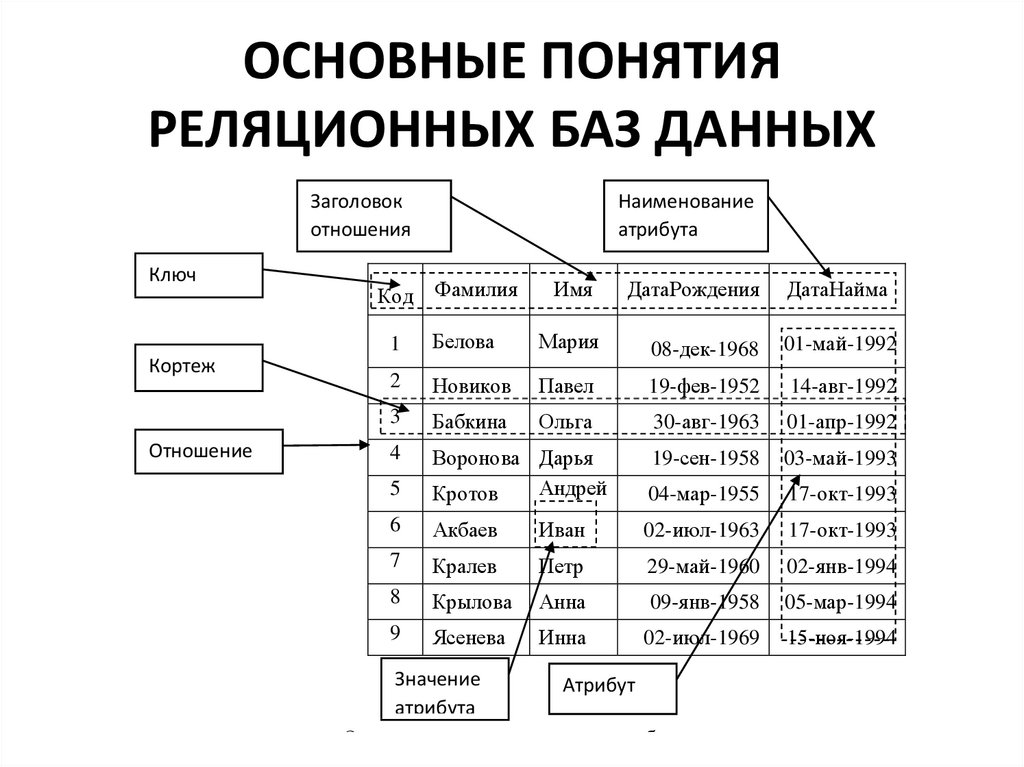
Учебные пособия от встроенных экспертовПочему SQLZoo — лучший способ попрактиковаться в SQL
Почему важны реляционные базы данных?
Главной особенностью реляционной базы данных является способность объединять данные из разных таблиц для создания новых и содержательных выводов. Допустим, компания электронной коммерции имеет реляционную базу данных с тремя таблицами, содержащими данные о продуктах, клиентах и продажах. В таблице продуктов есть список продуктов, содержащий столбцы для идентификатора продукта и количества запасов. В таблице клиентов есть список всех клиентов с контактной информацией и идентификатором клиента. Таблица продаж сообщает нам, какие идентификаторы клиентов и какие идентификаторы продуктов были проданы и по какой цене. С помощью SQL аналитик данных может легко запрашивать эти таблицы и находить полезную информацию, такую как самые продаваемые продукты, самые покупающие клиенты или день недели, когда наблюдается наибольшее количество продаж.
Каковы преимущества реляционных баз данных?
Реляционные базы данных используют первичные и внешние ключи для взаимосвязи таблиц. Это означает, что у нас может быть единственный источник достоверной информации для наших данных. Другими словами, мы можем избежать дублирования данных и быть уверенными в точности наших результатов. Без повторных записей изменить или удалить данные просто, поскольку все связанные записи в других таблицах будут отображать изменение. Вернемся к нашей компании электронной коммерции: клиенту нужно изменить свой адрес электронной почты или имя. Если мы обновим таблицу клиентов, все остальные сведения, такие как клиент, совершающий самые крупные покупки, или имя клиента в таблицах продаж, будут автоматически отражать новые данные о клиентах.
Произошла ошибка.
Невозможно выполнить JavaScript. Попробуйте посмотреть это видео на сайте www.youtube.com или включите JavaScript, если он отключен в вашем браузере.
Каковы недостатки реляционных баз данных?
Стоимость может быть серьезным недостатком, поскольку некоторые реляционные базы данных могут быть довольно дорогими. Например, корпоративный сервер Microsoft SQL может быть во много раз дороже стандартной версии.
Более того, поскольку реляционные базы данных могут объединять данные из многих таблиц с помощью одного запроса, низкая производительность может поставить реляционные базы данных в невыгодное положение. Производительность зависит от многих различных факторов, таких как количество используемых операторов JOIN, правильно ли мы индексируем нашу базу данных или используем ли мы звездочки для выбора столбцов, а не только те поля, которые нам нужны. Существует множество советов по улучшению производительности вашей реляционной базы данных в зависимости от варианта использования. В конце концов, повышение производительности ваших SQL-запросов становится проще с опытом.
Давайте рассмотрим пример. Ниже вы найдете «медленный» запрос, который мы сделаем более эффективным. Представим, что нам нужны три поля из таблицы за первые 15 дней августа 2022 года:
Исходный запрос:
SELECT * FROM SAMPLE_TABLE ГДЕ DATE_TIMESTAMP > "2022-08-01" ЗАКАЗАТЬ ПО DATE_TIMESTAMP ASC
Улучшенный запрос:
ВЫБРАТЬ FIELD_01, FIELD_02, DATE_TIMESTAMP FROM SAMPLE_TABLE ГДЕ DATE_TIMESTAMP МЕЖДУ "2022-08-01" И "2022-08-15" ЗАКАЗАТЬ ПО DATE_TIMESTAMP ASC
Исходный запрос использует SELECT * , который выбирает все поля в таблице, а улучшенный запрос выбирает три определенных поля из таблицы. Кроме того, в исходном запросе есть предложение WHERE , которое отделяет дату от первого августа 2022 года, но не ограничивает поиск до 15 августа. Это означает, что исходный запрос будет выполняться дольше, поскольку мы добавляем больше данных в стол.
Каковы альтернативы реляционным базам данных?
Существует больше альтернатив для хранения наших данных, которые предлагают определенные преимущества в зависимости от варианта использования.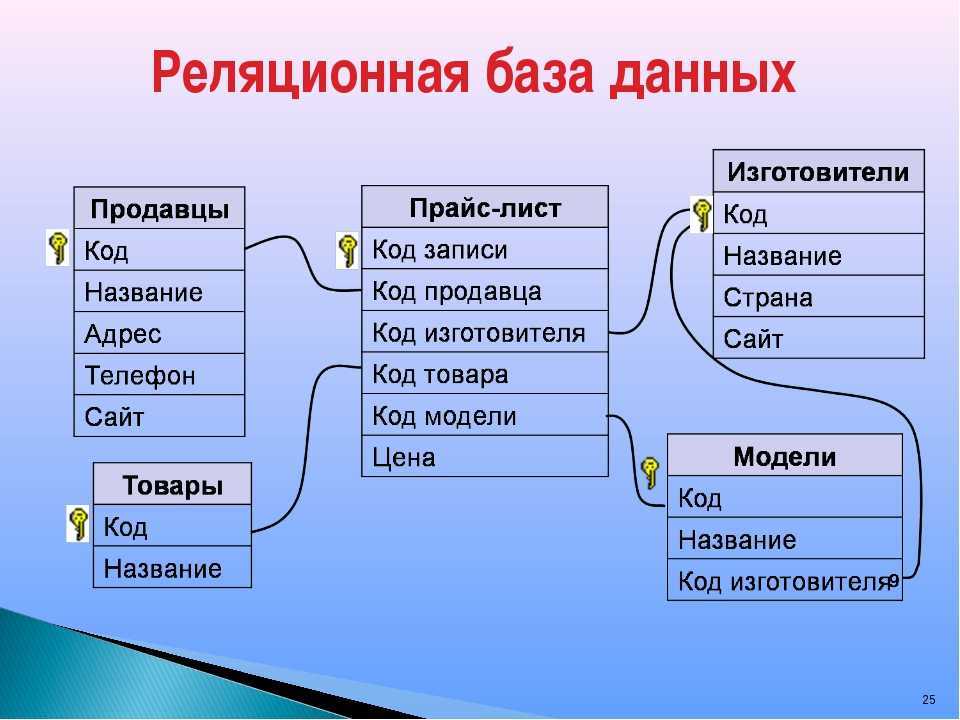 Для неструктурированных данных нереляционная (или NoSQL) база данных может обрабатывать большие объемы данных на высоких скоростях. Другой альтернативой реляционным базам данных является озеро данных (если представляется правильный вариант использования). Мы можем использовать озеро данных для хранения данных в любом масштабе, даже если мы еще не определили назначение данных. В озере данных данные могут быть структурированными, неструктурированными или даже в необработанных файлах.
Для неструктурированных данных нереляционная (или NoSQL) база данных может обрабатывать большие объемы данных на высоких скоростях. Другой альтернативой реляционным базам данных является озеро данных (если представляется правильный вариант использования). Мы можем использовать озеро данных для хранения данных в любом масштабе, даже если мы еще не определили назначение данных. В озере данных данные могут быть структурированными, неструктурированными или даже в необработанных файлах.
Если вам нужны реляционные данные и вам нужно выполнить анализ данных, хранилище данных может быть лучшим вариантом. Хранилища данных, как правило, основаны на облаке. Хотя хранилище данных использует реляционную модель, оно предназначено для использования в аналитике данных и поэтому имеет определенные отличия от реляционных баз данных. Например, в хранилище данных чаще собирают исторические данные, а не текущие. Более того, обновления данных планируются, а не создаются всякий раз, когда происходит транзакция.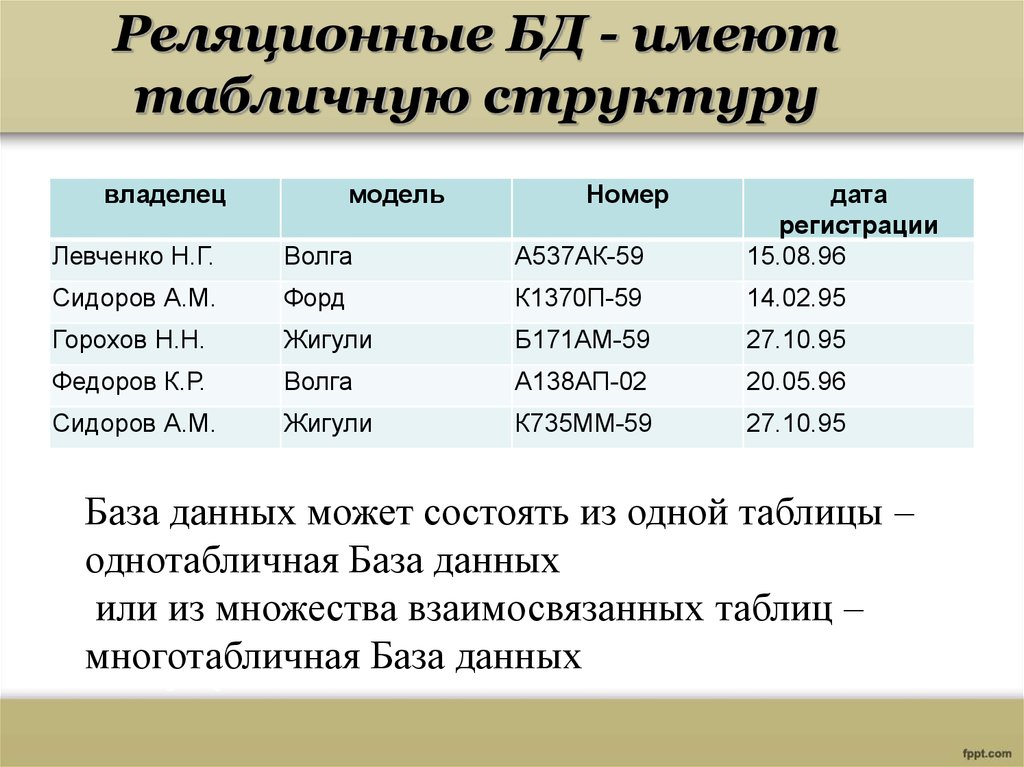 Наконец, хранилища данных создаются путем сбора и преобразования данных из нескольких источников данных для аналитических целей.
Наконец, хранилища данных создаются путем сбора и преобразования данных из нескольких источников данных для аналитических целей.
Связанные материалы от встроенных экспертовSQL и NoSQL: какой из них выбрать?
Примеры реляционных баз данных
Некоторые примеры популярных реляционных баз данных включают Microsoft SQL Server, Oracle Database, MySQL, Amazon Relational Database Service (RDS), PostgreSQL, базу данных Azure SQL и многие другие. RDS и база данных SQL Azure являются облачными, тогда как сервер Microsoft SQL, MySQL и PostsgreSQL предназначены для локальной установки. PostgreSQL и MySQL имеют открытый исходный код, а сервер Microsoft SQL — нет. Кроме того, облачные среды, такие как Google Cloud Platform, Amazon Web Services или Microsoft Azure, также могут поддерживать локальные базы данных.
Что такое СУБД — javatpoint
следующий → ← предыдущая РСУБД означает Система управления реляционными базами данных. Все современные системы управления базами данных, такие как SQL, MS SQL Server, IBM DB2, ORACLE, My-SQL и Microsoft Access, основаны на СУБД. Она называется системой управления реляционными базами данных (RDBMS), поскольку основана на реляционной модели, представленной Э. Ф. Коддом. Как это работаетДанные представлены в виде кортежей (строк) в СУБД. Реляционная база данных является наиболее часто используемой базой данных. Он содержит несколько таблиц, и каждая таблица имеет свой первичный ключ. Благодаря набору организованного набора таблиц к данным можно легко получить доступ в РСУБД. Краткая история СУБДС 1970 по 1972 год Э. Ф. Кодд опубликовал статью, в которой предлагалось использовать модель реляционной базы данных. СУРБДизначально основана на изобретении Э. Ф. Кодда реляционной модели. Ниже приведены различные термины СУБД: Что такое таблица/связь? Все в реляционной базе данных хранится в виде отношений. Свойства отношения:
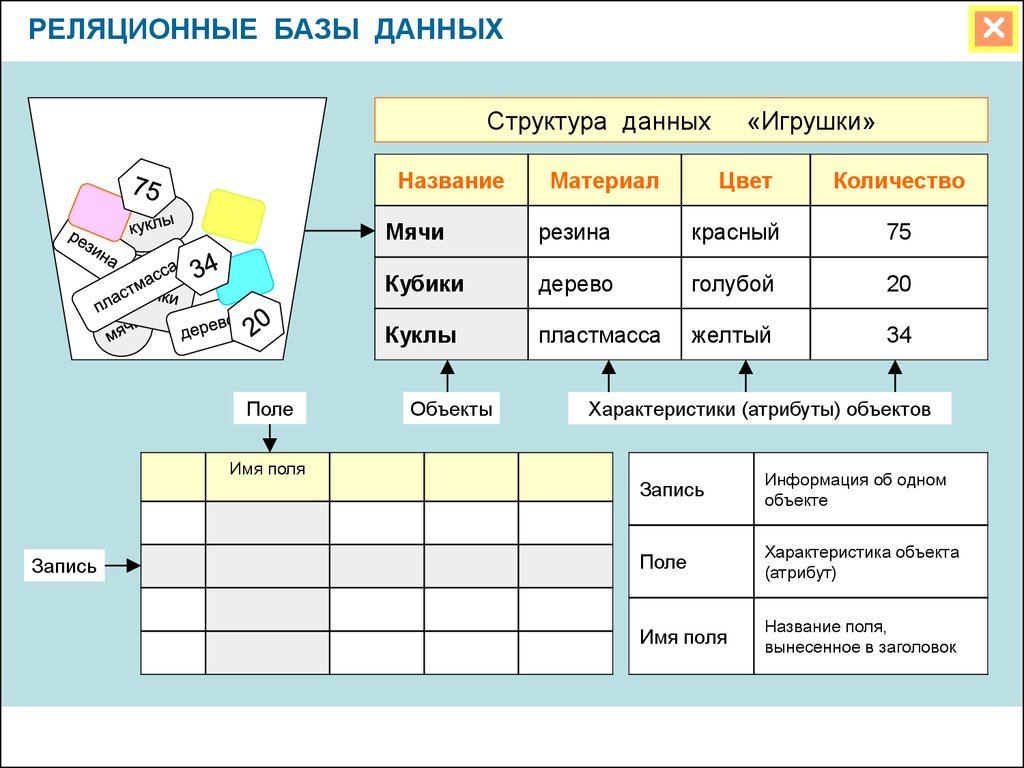
Таблица — это простейший пример данных, хранящихся в СУБД. Давайте посмотрим на примере стола ученика.
Что такое строка или запись?Строка таблицы также называется записью или кортежем. Он содержит конкретную информацию о каждой записи в таблице. Это горизонтальная сущность в таблице. Например, приведенная выше таблица содержит 5 записей. Свойства ряда:
Посмотрим одну запись/строку в таблице.
Что такое столбец/атрибут?Столбец — это вертикальный объект в таблице, который содержит всю информацию, связанную с определенным полем в таблице. Например, «имя» — это столбец в приведенной выше таблице, который содержит всю информацию об имени учащегося. Свойства атрибута:
Что такое элемент данных/ячейки? Наименьшая единица данных в таблице — это отдельный элемент данных. Свойства элементов данных:
В приведенном ниже примере элемент данных в таблице учащихся состоит из Ajeet, 24 и Btech и т. д.
Степень:Общее количество атрибутов, составляющих отношение, называется степенью таблицы. Например, таблица учеников имеет 4 атрибута, а ее степень равна 4.
Мощность: Общее количество кортежей в любой момент времени в отношении называется кардинальностью таблицы. Например, таблица student имеет 5 строк и имеет мощность 5.
Домен:Домен относится к возможным значениям, которые может содержать каждый атрибут. Его можно указать, используя стандартные типы данных, такие как целые числа, числа с плавающей запятой и т. д. Например, , Атрибут Marital_Status может быть ограничен значениями, состоящими или не состоящими в браке. НУЛЕВЫЕ значения Значение таблицы NULL указывает, что поле было оставлено пустым во время создания записи. Оставить комментарий
|

 База данных RDBMS использует таблицы для хранения данных. Таблица представляет собой набор связанных записей данных и содержит строки и столбцы для хранения данных. Каждая таблица представляет некоторые объекты реального мира, такие как человек, место или событие, о которых собирается информация. Организованный сбор данных в реляционную таблицу известен как логическое представление базы данных.
База данных RDBMS использует таблицы для хранения данных. Таблица представляет собой набор связанных записей данных и содержит строки и столбцы для хранения данных. Каждая таблица представляет некоторые объекты реального мира, такие как человек, место или событие, о которых собирается информация. Организованный сбор данных в реляционную таблицу известен как логическое представление базы данных. Тех
Тех Тех
Тех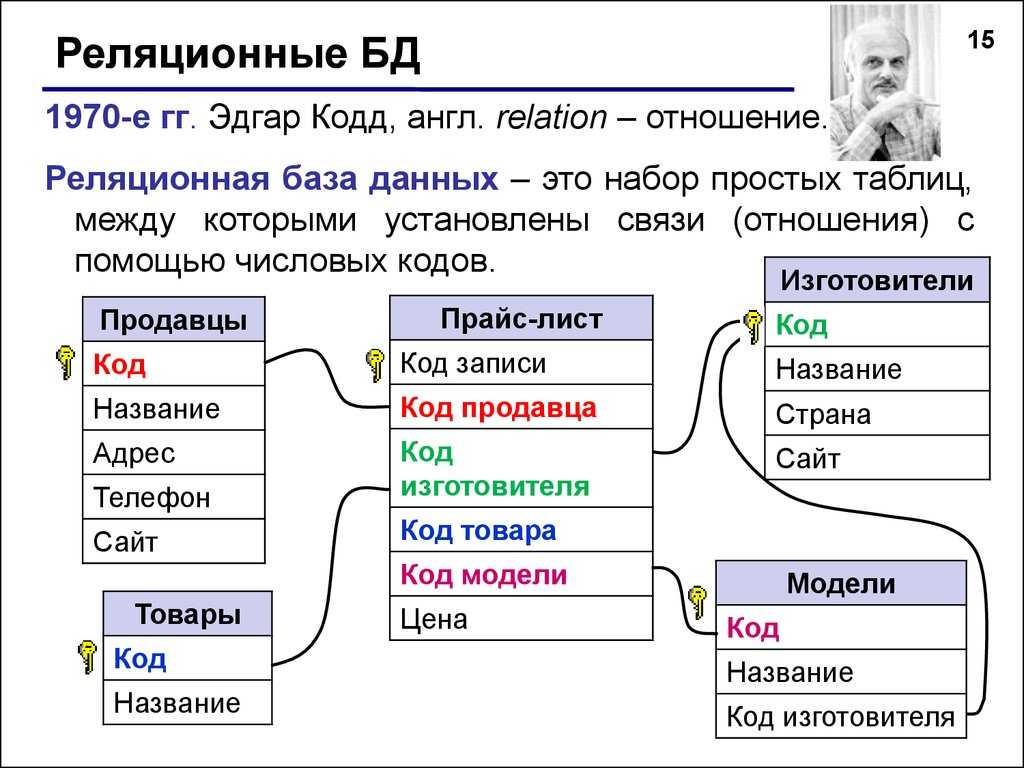 Он хранится на пересечении кортежей и атрибутов.
Он хранится на пересечении кортежей и атрибутов.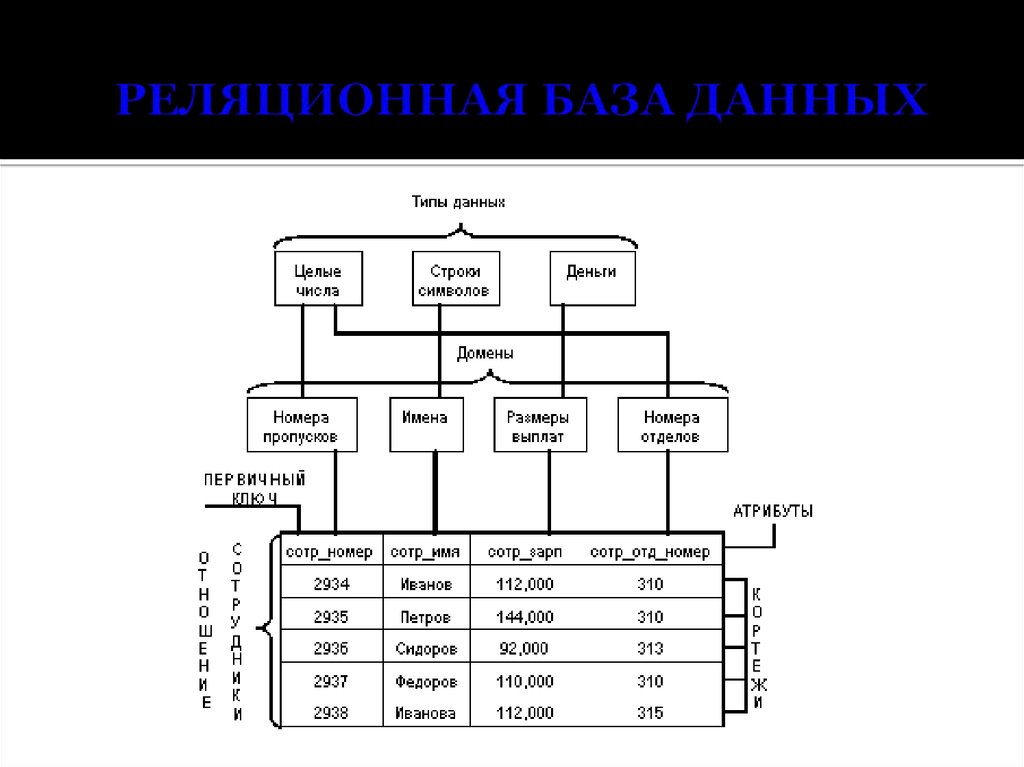 Отношение, мощность которого равна 0, называется пустой таблицей.
Отношение, мощность которого равна 0, называется пустой таблицей.