c++ — Русская строка в C
Как получается что русские символы умещаются в C строке в кодировке UTF-8 когда каждый русский символ в этой кодировке занимает 2 байта, а ячейка в C строке вмещает только 1 байт? Почему если выводить эту строку, то она выведется без проблем, а если выводить её посимвольно, то она выводит ошибки? Ещё если можно, то посоветуйте материалов почитать по этой теме.
char a[] = "Строка"; std::cout << a << std::endl; for (int i = 0; i < 6; i++) std::cout << a[i] << std::endl;
1
Чудес не бывает — символы, занимающие больше одного байта в Си так же занимают больше одного байта. В случае со строкой char они лежат в нескольких ячейках (в случае с двухбайтными — первый символ лежит в первых двух, второй — во вторых двух).
Если говорить о C++, то для многобайтных символов есть специальный тип wchar_t
GNU/Linux и 2 байта для Windows APIАналогом std::string для этого типа является std::wstring.
http://en.cppreference.com/w/cpp/string/basic_string
// сперва считаем символ беззнаковым, потом переводим его в целое число char a[] = "Строка"; std::cout << (int)(unsigned char)a[0] << "; " << (int)(unsigned char)a[1] << std::endl;
Выведет 208; 161 (https://ideone.com/FyUdhj)
Согласно вот это (https://unicode-table.com/ru/0421/) таблице, символ С в UTF-8 представляется двумя байтами, как раз 208 161
7
Ячейка в С-строке вмещает, конечно, один байт, но каждый символ в таком случае будет занимать в ней два места. И длина всей строки — 12
char a[] = "Строка"; std::cout << a << ' ' << strlen(a) << std::endl; // Строка 12
Например, если вывести из этой строки по два символа, то выведутся правильные символы:
for (int i = 0; i < 6; i++)
std::cout << a[2*i] << a[2*i+1] << std::endl;
utf-8 — мультибайтовая кодировка (разные символы могут занимать разное количество байт).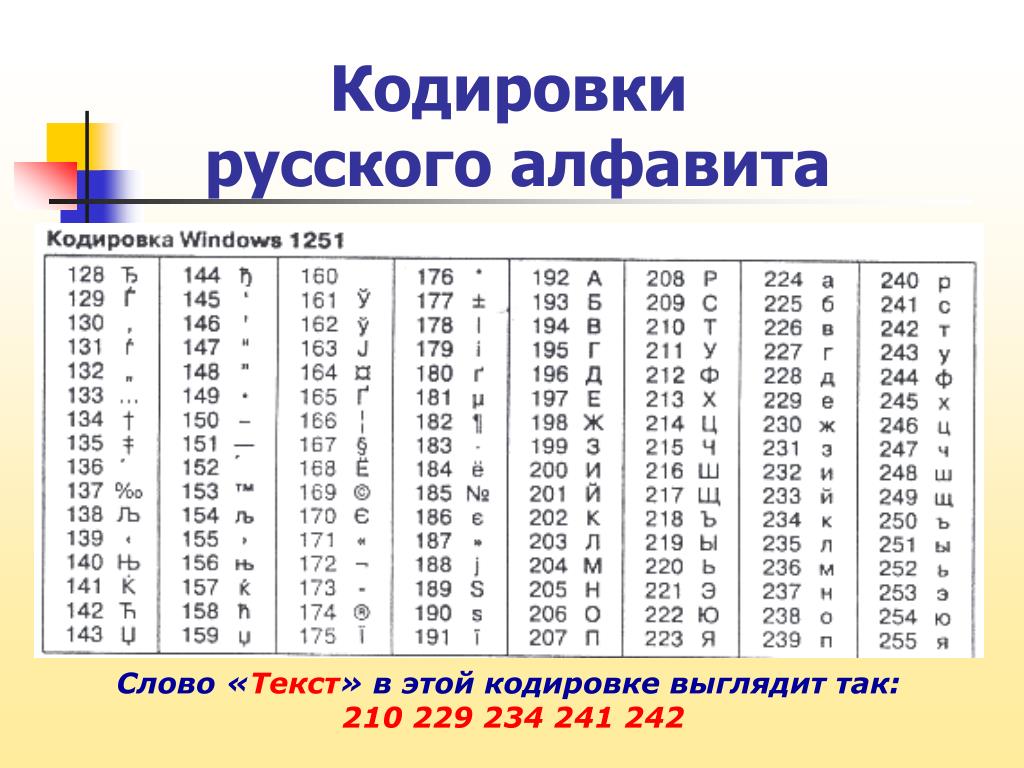 В том числе кириллические символы будут занимать два байта. При инициализации строки каждый по два байта и займёт.
В том числе кириллические символы будут занимать два байта. При инициализации строки каждый по два байта и займёт.
Следующие две конструкции с точки зрения языка эквивалентны:
char a[] = "\xd0\xa1\xd1\x82\xd1\x80\xd0\xbe\xd0\xba\xd0\xb0"; char a[] = "Строка";
3
Зарегистрируйтесь или войдите
Регистрация через Facebook
Регистрация через почту
Отправить без регистрации
Почта
Необходима, но никому не показывается
Отправить без регистрации
Почта
Необходима, но никому не показывается
Нажимая на кнопку «Отправить ответ», вы соглашаетесь с нашими пользовательским соглашением, политикой конфиденциальности и политикой о куки
Как научить Python русскому языку — Учимся с Python
Специфика работы в Python со строками на русском языке проистекает из того, что существует множество независимых кодировок для представления на компьютере букв, отличных от латинских.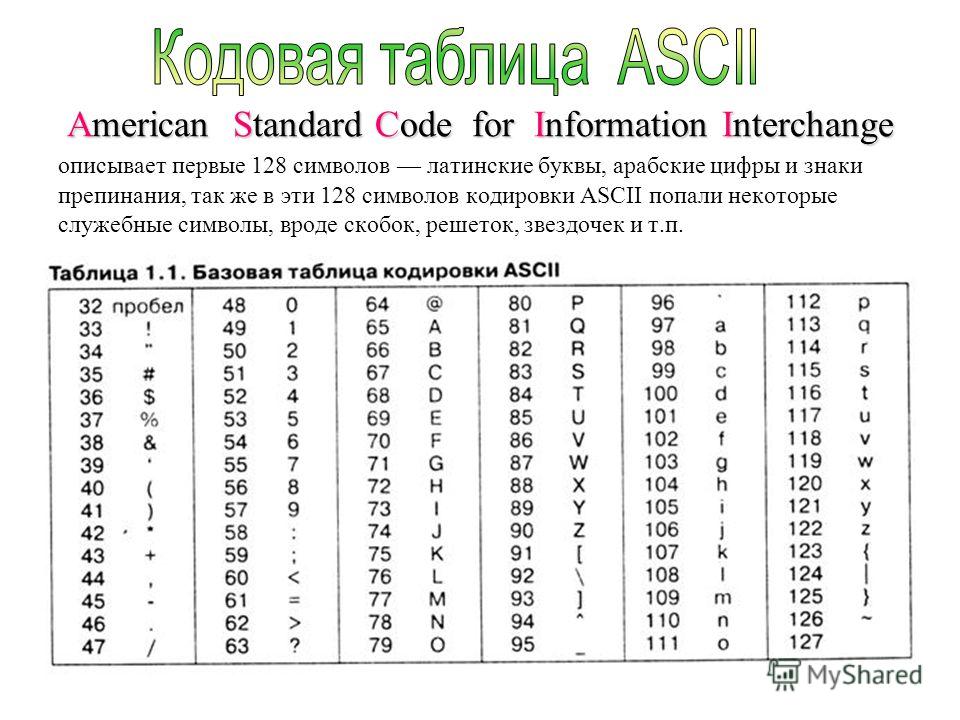
Поэтому каждый символ, отображаемый или принимаемый компьютером, кодируется некоторым числом. Ниже представлена таблица кодировки ASCII, которая использует числа от 0 до 127 для кодирования символов, включая латиницу (буквы латинского алфавита), цифры от 0 до 9, знаки пунктуации и специальные символы. Кроме того, коды от 0 до 31 кодируют специальные управляющие символы, такие как табуляция TAB, перевод строки LF и другие. Подробнее познакомиться с таблицей ASCII можно в Википедии.
| 0 | 32 | Space | 64 | @ | 96 | ` | |
| 1 | SOH | 33 | ! | 65 | A | 97 | a |
| 2 | STX | 34 | “ | 66 | B | 98 | b |
| 3 | ETX | 35 | # | 67 | C | 99 | c |
| 4 | EOT | 36 | $ | 68 | D | 100 | d |
| 5 | ENQ | 37 | % | 69 | E | 101 | e |
| 6 | ACK | 38 | & | 70 | F | 102 | f |
| 7 | BEL | 39 | ‘ | 71 | G | 103 | g |
| 8 | BS | 40 | ( | 72 | H | 104 | h |
| 9 | TAB | 41 | ) | 73 | I | 105 | i |
| 10 | LF | 42 | * | 74 | J | 106 | j |
| 11 | VT | 43 | + | 75 | K | 107 | k |
| 12 | FF | 44 | , | 76 | L | 108 | l |
| 13 | CR | 45 | — | 77 | M | 109 | m |
| 14 | SO | 46 | . | 78 | N | 110 | n |
| 15 | SI | 47 | / | 79 | O | 111 | o |
| 16 | DLE | 48 | 0 | 80 | P | 112 | p |
| 17 | DC1 | 49 | 1 | 81 | Q | 113 | q |
| 18 | DC2 | 50 | 2 | R | 114 | r | |
| 19 | DC3 | 51 | 3 | 83 | S | 115 | s |
| 20 | DC4 | 52 | 4 | 84 | T | 116 | t |
| 21 | NAK | 53 | 5 | 85 | U | 117 | u |
| 22 | SYN | 54 | 6 | 86 | V | 118 | v |
| 23 | ETB | 55 | 7 | 87 | W | 119 | w |
| 24 | CAN | 56 | 8 | 88 | X | 120 | x |
| 25 | EM | 57 | 9 | 89 | Y | 121 | y |
| 26 | SUB | 58 | : | 90 | Z | 122 | z |
| 27 | ESC | 59 | ; | 91 | [ | 123 | { |
| 28 | FS | 60 | < | 92 | 124 | | | |
| 29 | GS | 61 | = | 93 | ] | 125 | } |
| 30 | RS | 62 | > | 94 | ^ | 126 | ~ |
| 31 | US | 63 | ? | 95 | _ | 127 | DEL |
Все современные компьютеры и программы понимают и широко используют кодировку ASCII. Вот почему латиница является самым распространенным алфавитом на компьютерах, а англоязычные пользователи компьютеров, по большей части, лишены необходимости задумываться о кодировках символов и переключать раскладку клавиатуры.
Вот почему латиница является самым распространенным алфавитом на компьютерах, а англоязычные пользователи компьютеров, по большей части, лишены необходимости задумываться о кодировках символов и переключать раскладку клавиатуры.
Закодируем, используя приведенную выше таблицу кодов ASCII, слово “Hello”. Мы получим следующую последовательностью числовых кодов: 72, 101, 108, 108, 111. Проверить (и узнать) соответствие букв и кодов можно при помощи встроенных функций Python chr и ord. Функция chr принимает в качестве аргумента целочисленный код и возвращает соответствующий ему символ. Функция ord, наоборот, принимает символ и возвращает кодирующее его целое число:
>>> ord('H')
72
>>> ord('e')
101
>>> chr(101)
'e'
>>> type(chr(101))
<type 'str'>
>>>
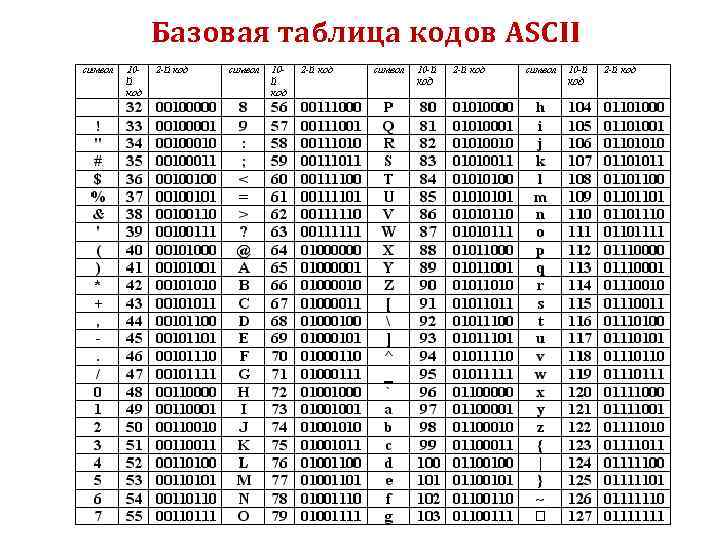
Посмотрите еще раз на таблицу ASCII. Как видите, в ней нет букв русского алфавита. А также в ней греческих, арабских, японских и других букв и иероглифов, использующихся в разных языках Земли.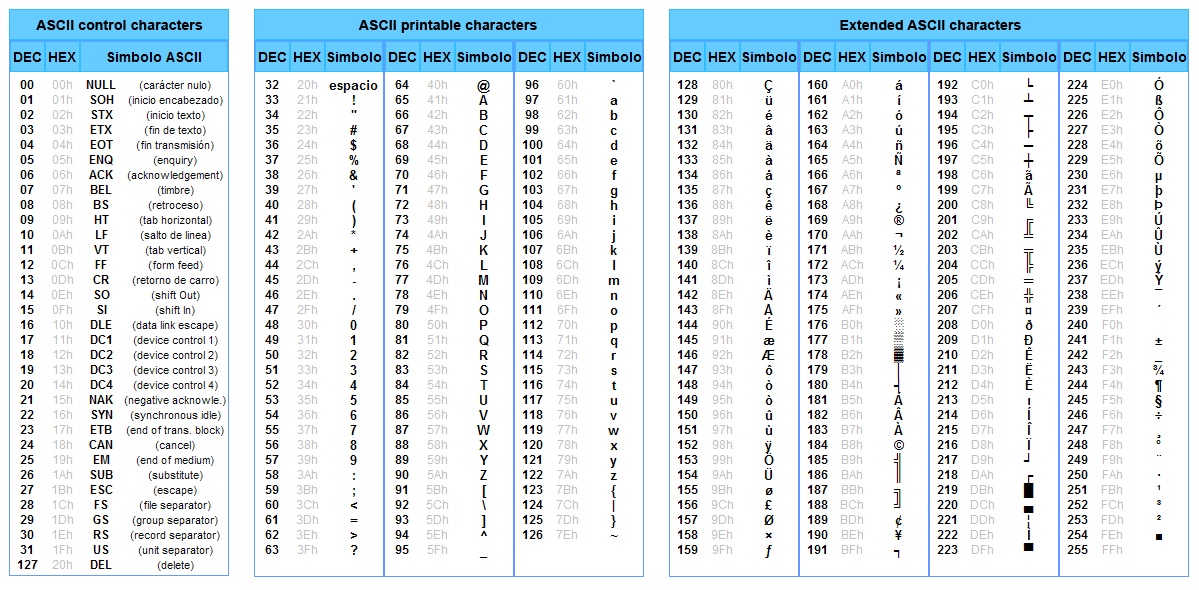 Для кодирования букв и других символов, отсутствующих в таблице ASCII, используются числа больше 128. На следующем рисунке представлена кодировка cp866, использующая числа от 128 до 255 для кодирования символов кириллицы (букв русского алфавита) и специальных графических символов.
Для кодирования букв и других символов, отсутствующих в таблице ASCII, используются числа больше 128. На следующем рисунке представлена кодировка cp866, использующая числа от 128 до 255 для кодирования символов кириллицы (букв русского алфавита) и специальных графических символов.
| 128 | А | 160 | а | 192 | └ | 224 | р |
| 129 | Б | 161 | б | 193 | ┴ | 225 | с |
| 130 | В | 162 | в | 194 | ┬ | 226 | т |
| 131 | Г | 163 | г | 195 | ├ | 227 | у |
| 132 | Д | 164 | д | 196 | ─ | 228 | ф |
| 133 | Е | 165 | е | 197 | ┼ | 229 | х |
| 134 | Ж | 166 | ж | 198 | ╞ | 230 | ц |
| 135 | З | 167 | з | 199 | ╟ | 231 | ч |
| 136 | И | 168 | и | 200 | ╚ | 232 | ш |
| 137 | Й | 169 | й | 201 | ╔ | 233 | щ |
| 138 | К | 170 | к | 202 | ╩ | 234 | ъ |
| 139 | Л | 171 | л | 203 | ╦ | 235 | ы |
| 140 | М | 172 | м | 204 | ╠ | 236 | ь |
| 141 | Н | 173 | н | 205 | ═ | 237 | э |
| 142 | О | 174 | о | 206 | ╬ | 238 | ю |
| 143 | П | 175 | п | 207 | ╧ | 239 | я |
| 144 | Р | 176 | ░ | 208 | ╨ | 240 | Ё |
| 145 | С | 177 | ▒ | 209 | ╤ | 241 | ё |
| 146 | Т | 178 | ▓ | 210 | ╥ | 242 | Є |
| 147 | У | 179 | │ | 211 | ╙ | 243 | є |
| 148 | Ф | 180 | ┤ | 212 | ╘ | 244 | Ї |
| 149 | Х | 181 | ╡ | 213 | ╒ | 245 | ї |
| 150 | Ц | 182 | ╢ | 214 | ╓ | 246 | Ў |
| 151 | Ч | 183 | ╖ | 215 | ╫ | 247 | ў |
| 152 | Ш | 184 | ╕ | 216 | ╪ | 248 | ° |
| 153 | Щ | 185 | ╣ | 217 | ┘ | 249 | ∙ |
| 154 | Ъ | 186 | ║ | 218 | ┌ | 250 | · |
| 155 | Ы | 187 | ╗ | 219 | █ | 251 | √ |
| 156 | Ь | 188 | ╝ | 220 | ▄ | 252 | № |
| 157 | Э | 189 | ╜ | 221 | ▌ | 253 | ¤ |
| 158 | Ю | 190 | ╛ | 222 | ▐ | 254 | ■ |
| 159 | Я | 191 | ┐ | 223 | ▀ | 255 |
Кодировка cp866 использовалась в операционной системе MS DOS и теперь по умолчанию используется в консоли MS Windows. Буквы cp в названии этой и других кодировок — сокращение от code page (англ.: кодовая страница).
Буквы cp в названии этой и других кодировок — сокращение от code page (англ.: кодовая страница).
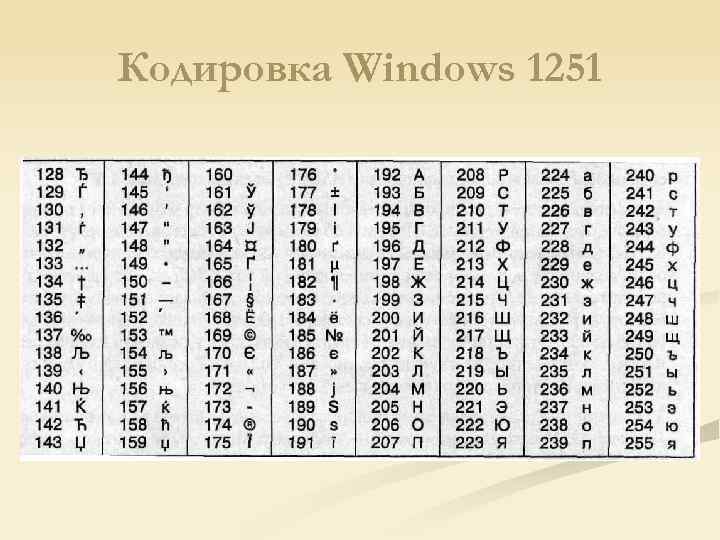
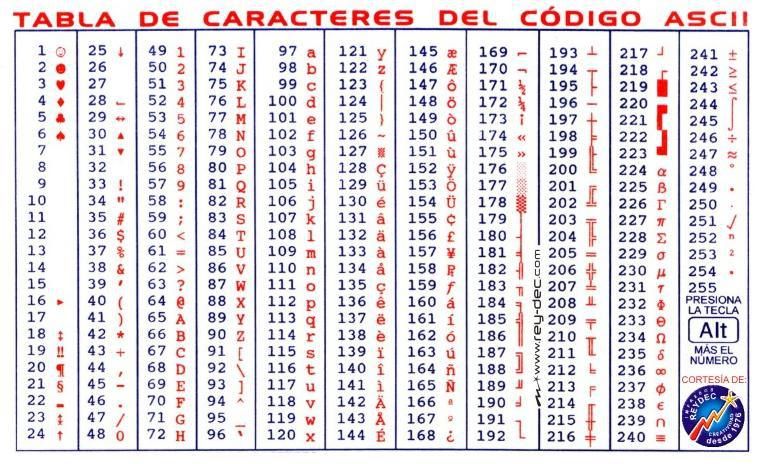
Случилось так, что числа от 128 до 255 стали использоваться в разных странах для кодирования букв алфавитов разных языков, а не только русского. Но даже если вести речь только о кириллице, то, кроме кодировки cp866, существуют несколько других кодировок, которые иначе сопоставляют буквы кириллицы кодам в диапазоне от 128 до 255. В качестве примера еще одной кириллической кодировки ниже приведена таблица кодов cp1251, используемая графическими приложениями в ОС MS Windows, такими как Блокнот, MS Office и другими.
| 128 | Ђ | 160 | 192 | А | 224 | а | |
| 129 | Ѓ | 161 | Ў | 193 | Б | 225 | б |
| 130 | ‚ | 162 | ў | 194 | В | 226 | в |
| 131 | ѓ | 163 | Ј | 195 | Г | 227 | г |
| 132 | „ | 164 | ¤ | 196 | Д | 228 | д |
| 133 | … | 165 | Ґ | 197 | Е | 229 | е |
| 134 | † | 166 | ¦ | 198 | Ж | 230 | ж |
| 135 | ‡ | 167 | § | 199 | З | 231 | з |
| 136 | € | 168 | Ё | 200 | И | 232 | и |
| 137 | ‰ | 169 | © | 201 | Й | 233 | й |
| 138 | Љ | 170 | Є | 202 | К | 234 | к |
| 139 | ‹ | 171 | « | 203 | Л | 235 | л |
| 140 | Њ | 172 | ¬ | 204 | М | 236 | м |
| 141 | Ќ | 173 | | 205 | Н | 237 | н |
| 142 | Ћ | 174 | ® | 206 | О | 238 | о |
| 143 | Џ | 175 | Ї | 207 | П | 239 | п |
| 144 | ђ | 176 | ° | 208 | Р | 240 | р |
| 145 | ‘ | 177 | ± | 209 | С | 241 | с |
| 146 | ’ | 178 | І | 210 | Т | 242 | т |
| 147 | “ | 179 | і | 211 | У | 243 | у |
| 148 | ” | 180 | ґ | 212 | Ф | 244 | ф |
| 149 | • | 181 | µ | 213 | Х | 245 | х |
| 150 | – | 182 | ¶ | 214 | Ц | 246 | ц |
| 151 | — | 183 | · | 215 | Ч | 247 | ч |
| 152 | | 184 | ё | 216 | Ш | 248 | ш |
| 153 | ™ | 185 | № | 217 | Щ | 249 | щ |
| 154 | љ | 186 | є | 218 | Ъ | 250 | ъ |
| 155 | › | 187 | » | 219 | Ы | 251 | ы |
| 156 | њ | 188 | ј | 220 | Ь | 252 | ь |
| 157 | ќ | 189 | Ѕ | 221 | Э | 253 | э |
| 158 | ћ | 190 | ѕ | 222 | Ю | 254 | ю |
| 159 | џ | 191 | ї | 223 | Я | 255 | я |
Из сказанного можно сделать вывод о том, что для правильного отображения символов на экране компьютеру необходимо знать, в какой кодировке представлены данные, которые нужно отобразить. Например, пускай нам дана следующая последовательность кодов: 232, 227, 226. Если принять, что это символы, представленные в кодировке cp866, то мы получим слово “шут”. А если принять, что это символы, представленные в кодировке cp1251, то мы получим слово “игв”. А в греческой кодировке cp1253 эти же коды дадут нам “θγβ”! На сегодняшний день существуют десятки кодировок, сопоставляющих числовые коды от 128 до 255 различным символам!
Например, пускай нам дана следующая последовательность кодов: 232, 227, 226. Если принять, что это символы, представленные в кодировке cp866, то мы получим слово “шут”. А если принять, что это символы, представленные в кодировке cp1251, то мы получим слово “игв”. А в греческой кодировке cp1253 эти же коды дадут нам “θγβ”! На сегодняшний день существуют десятки кодировок, сопоставляющих числовые коды от 128 до 255 различным символам!
Если вы запускаете интерпретатор Python в консоли русскоязычной Windows, то Python ожидает, что строки используют кодировку cp866. Давайте проведем небольшое исследование для того, чтобы подтвердить или опровергнуть это утверждение. Воспользуемся функцией ord для получения числовых кодов нескольких русских букв, введенных с клавиатуры, и таблицей кодов cp866, приведенной выше, чтобы убедиться, что функция ord вернула нам коды букв в кодировке cp866:
>>> print ord('э'), ord('ю'), ord('я')
237 238 239
>>>
А функция chr выведет буквы русского алфавита, соответствующие кодам, взятым нами из таблицы cp866:
>>> print chr(128), chr(129), chr(130) А Б В >>>
Итак, русские буквы, которые мы вводим с клавиатуры при работе в интерактивном режиме Python, представлены в кодировке cp866. Работая в интерактивном режиме Python, мы можем смело использовать русские буквы в строковых значениях:
Работая в интерактивном режиме Python, мы можем смело использовать русские буквы в строковых значениях:
>>> name = 'мир' >>> print 'Привет', name Привет мир >>>
Таким образом, все примеры работы в интерактивном режиме, приведенные в книге, можно безболезненно русифицировать, заменяя английские слова и предложения на русские.
Однако, для русификации скриптов Python, сохраненных в файлах, нам осталось сделать еще один шаг. Нам нужно ответить на вопрос, в какой кодировке сохранен наш скрипт в файле? Это зависит от текстового редактора, в котором был написан и сохранен скрипт, и от того, была ли явно указана кодировка при сохранении файла.
Как было сказано выше, Блокнот, или Notepad, простой текстовый редактор, имеющийся в ОС Windows, использует кириллическую кодировку cp1251, а консоль Windows, или окно для работы с командной строкой, по умолчанию использует кириллическую кодировку cp866. Это очень неудобно для русскоязычных пользователей.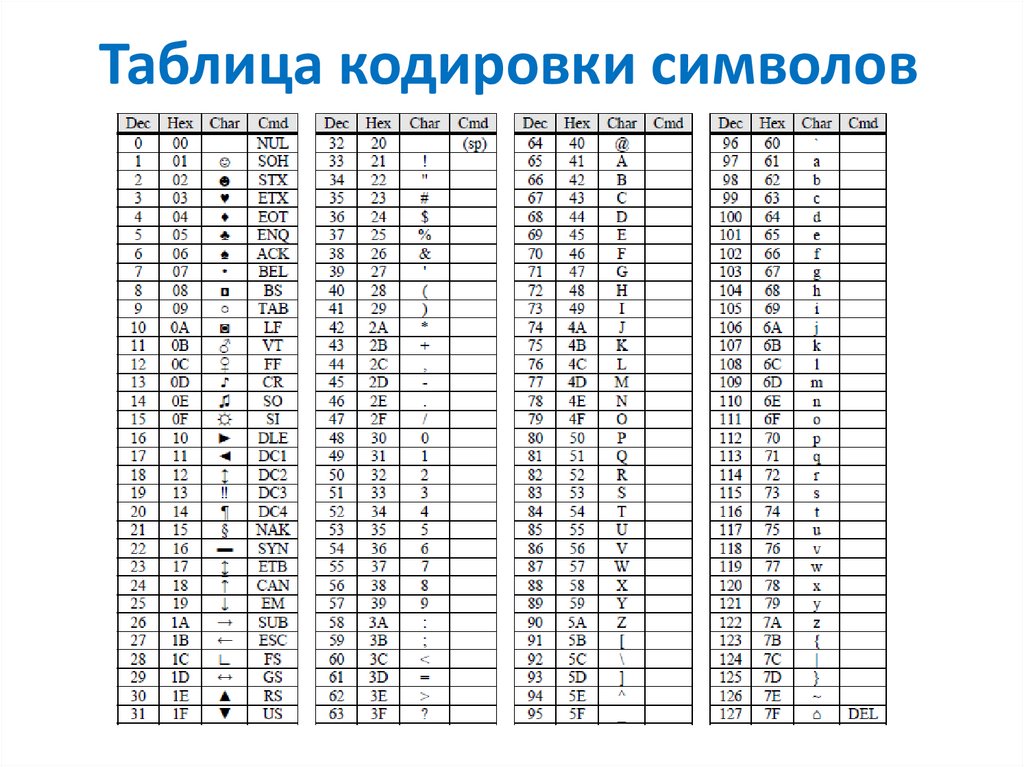
Например, создайте в Блокноте файл C:\russian.txt с единственной строкой:
Привет мир!
А теперь откройте окно с командной строкой и выведите содержимое этого файла на экран:
C:\>type russian.txt ╧ЁштхЄ ьшЁ!
Что это за кракозябры?
Если вы отыщете эти символы, один за одним, в приведенной выше таблице кодов cp866, то получится последовательность кодов: 207, 240, 232, 226, 229, 242, 32, 252, 248, 240, 33. (Пробел и восклицательный знак имеют коды из диапазона 0 — 127 и кодируются таблицей ASCII.) Теперь переведите эти коды в символы, используя таблицу кодировки cp1251, и вы получите “Привет мир!” Кракозябры в консольном окне мы видим потому, что Блокнот сохранил файл в кодировке cp1251, а консольное окно считает, что коды от 128 до 255 представляют символы из кодировки cp866!
Преодолеть эту проблему можно с помощью консольной команды chcp. Команда chcp без параметров показывает, какая кодировка является текущей:
C:\>chcp Active code page: 866
А в качестве параметра команда chcp принимает номер кодировки, которую необходимо сделать текущей. Если с ее помощью изменить текущую кодировку консольного окна на cp1251, то мы, наконец, сможем увидеть содержимое файла russian.txt неискаженным:
Если с ее помощью изменить текущую кодировку консольного окна на cp1251, то мы, наконец, сможем увидеть содержимое файла russian.txt неискаженным:
C:\>chcp 1251 Active code page: 1251 C:\>type russian.txt Привет мир!
Скрипт на Python является текстовым файлом точно так же, как файл russian.txt, с которым мы экспериментировали. И если создать и сохранить скрипт, использующий русские буквы, в Блокноте, то скрипт будет сохранен в кодировке cp1251. Давайте откроем в Блокноте файл russian.txt и сохраним его как russian.py, слегка изменив его содержимое:
print 'Привет мир!'
Теперь это файл с очень простым скриптом на языке Python. Выполним его:
C:\>python russian.py File "russian.py", line 1 SyntaxError: Non-ASCII character '\xcf' in file russian.py on line 1, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details
Вместо ожидаемого приветствия на русском языке Python вывел сообщение об ошибке. Сообщение говорит о том, что в 1-ой строке файла встретился символ, не являющийся символом ASCII, а кодировка не объявлена. Очевидно, что символы, не являющиеся символами ASCII, в нашем файле — это русские буквы. Но что же в этом плохого?
Очевидно, что символы, не являющиеся символами ASCII, в нашем файле — это русские буквы. Но что же в этом плохого?
Дело в том, что Python по умолчанию ожидает, что скрипты, переданные ему для выполнения, имеют кодировку ASCII, то есть, содержат символы с кодами в диапазоне 0 — 127. Для всех, кто использует в своих скриптах только латиницу, цифры и другие символы ASCII, это работает прекрасно. Пользователи, использующие в своих программах строковые значения и комментарии на английском языке, чувствуют себя совершенно комфортно в этой ситуации и, по большей части, не подозревают о проблеме, с которой мы только что столкнулись.
Чтобы сообщить Python о том, что скрипт использует кодировку, отличную от ASCII, нужно в начале файла поместить комментарий специального вида, содержащий информацию о кодировке файла. Для скрипта russian.py, созданного в Блокноте, укажем кодировку cp1251, после чего скрипт будет выглядеть так:
# -*- coding: cp1251 -*- print 'Привет мир!'
После этого сможем успешно выполнить скрипт в консольном окне Windows (только не забудьте установить текущую кодировку командой chcp 1251):
C:\>chcp 1251 Active code page: 1251 C:\>python russian.py Привет мир!
Итак, для того, чтобы скрипт Python заговорил по-русски в консольном окне Windows, необходимо:
Указать в начале скрипта кодировку, которую использует файл. Например:
# -*- coding: cp1251 -*-
Установить в консольном окне Windows кодировку, которую использует выполняемый скрипт. Например:
C:\> chcp 1251 Active code page: 1251
В общем случае, скрипт с русскими строками и комментариями может использовать любую из кириллических кодировок, в частности, любую из рассмотренных выше, cp1251 или cp866. Важно, чтобы объявленная в начале файла кодировка была та самая, в которой сохранен файл.
Если скрипт использует кодировку cp866, то в консольном окне русскоязычной Windows не нужно предпринимать никаких специальных действий перед выполнением скрипта, ведь cp866 — кодировка, установленная в консоли по умолчанию. Но если скрипт использует кодировку cp1251, то перед его выполнением в консоли нужно установить текущую кодировку командой chcp 1251.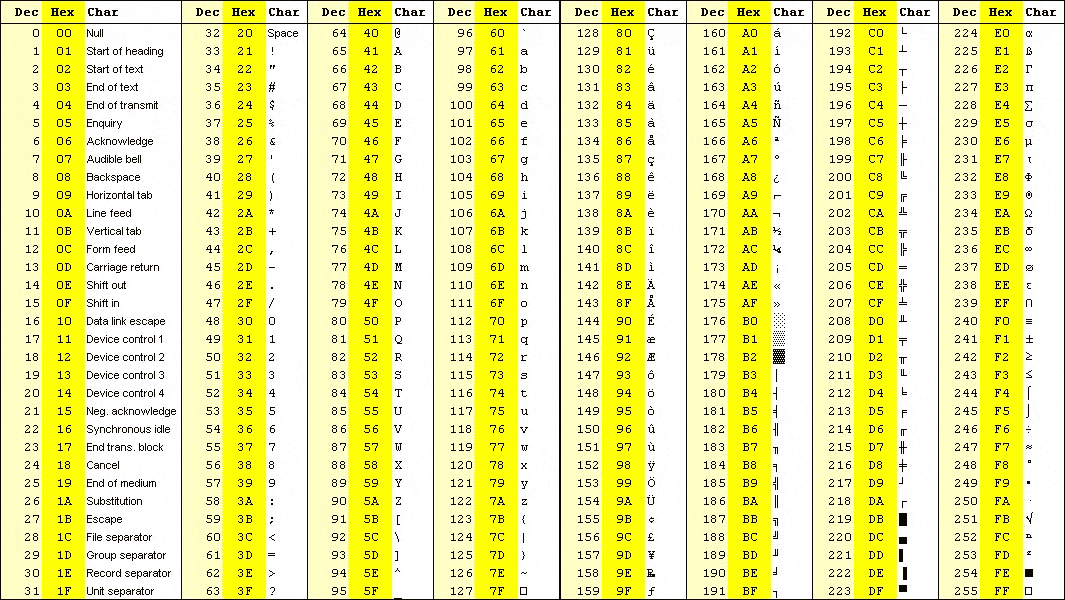
Ascii для кириллической кодировки (CP866)
Американский стандартный код для обмена информацией ( ASCII ) — широко используемая система кодировки символов , представленная в 1963 году. стандартный набор символов изначально состоял из 128 символов (7-битный код). Первые 32 символа — это управляющие символы (также называемые непечатаемыми символами), которые используются для управления потоками данных, а также такими устройствами, как принтеры. Позже он был расширен для поддержки 256 символов (8-битный код), чтобы предоставить символы, специфичные для языка, различные символы, а также символы для рисования блоков: элементы, используемые для презентационных целей, позволяющие рисовать различные виды фреймов и блоков. Символы в диапазоне 128-255 называются расширенным ASCII.
Кодовая страница 866 является наиболее широко используемой кодовой страницей для написания языков на основе кириллицы: белорусского, боснийского, болгарского, македонского, русского, сербского, украинского (славянские языки), а также казахского, киргизского, молдавского, монгольского, таджикского, Узбекский (неславянский), кодовая страница 855 является альтернативной. Только расширенный набор символов отличается от исходной кодовой страницы, причем как управляющие символы, так и стандартный набор символов представляют собой простой ASCII.
Только расширенный набор символов отличается от исходной кодовой страницы, причем как управляющие символы, так и стандартный набор символов представляют собой простой ASCII.
В приведенной ниже таблице символов показано графическое представление каждого символа с точностью до пикселя, а также текстовое описание.
Control characters (0 — 31):
| Dec | Hex | Char | Description | Dec | Hex | Char | Description |
| 0 | 0 | NUL (Null ) | 16 | 10 | DLE (Data Link Escape) | ||
| 1 | 1 | SOH (Start of Header) | 17 | 11 | DC1 (Device Control 1) | ||
| 2 | 2 | STX (Start of Text) | 18 | 12 | DC2 (Device Control 2) | ||
| 3 | 3 | ETX (End of Text) | 19 | 13 | DC3 (Device Control 3) | ||
| 4 | 4 | EOT (End of Transmission) | 20 | 14 | DC4 (Device Control 4) | ||
| 5 | 5 | ENQ (Enquiry) | 21 | 15 | NAK (Negative Acknowledge) | ||
| 6 | 6 | ACK (Acknowledge) | 22 | 16 | SYN (Synchronous Idle) | ||
| 7 | 7 | BEL (Bell) | 23 | 17 | ETB (End of Transmission Block) | ||
| 8 | 8 | BS (BackSpace) | 24 | 18 | CAN (Cancel) | ||
| 9 | 9 | HT (Horizontal Tabulation) | 25 | 19 | EM (End of Medium) | ||
| 10 | A | LF (Line Feed) | 26 | 1A | SUB (Substitute) | ||
| 11 | B | VT (Vertical Tabulation) | 27 | 1B | ESC (Escape) | ||
| 12 | C | FF (Form Feed) | 28 | 1C | FS (File Separator) | ||
| 13 | D | CR (Carriage Return) | 29 | 1D | GS (Group Separator) | ||
| 14 | E | SO (Shift Out) | 30 | 1E | RS (Record Сепаратор) | ||
| 15 | F | SI (Shift in) | 31 | 1F | США (единица разделителя) |
Стандарт.
 Hex
Hex 0023
0023024 2F
 0025
0025025
 0024 Lower case t
0024 Lower case tExtended character set (128 — 255):
| Dec | Hex | Char | Description | Dec | Hex | Char | Описание | ||||||
| 128 | 80 | Cyrillic Верхний корпус A | 192 | C0 | Box Huls Up Up Up и справа | Box Bulting0024 129 | 81 | Cyrillic upper case BE | 193 | C1 | Box drawings light up and horizontal | ||
| 130 | 82 | Cyrillic upper case VE | 194 | C2 | Чертежи коробки светлая вниз и горизонтальная | ||||||||
| 131 | 83 | Кириллица прописная GHE | 195 | C3 | Чертеж вертикальная и правая25 | ||||||||
| 132 | 84 | Cyrillic upper case DE | 196 | C4 | Box drawings light horizontal | ||||||||
| 133 | 85 | Cyrillic upper case IE | 197 | C5 | Чертежи коробки светлая вертикальная и горизонтальная | ||||||||
| 134 | 86 | Кириллица заглавная ZHE | 198 | C6 | вертикальная и двойная Правая коробка | ||||||||
| 135 | 87 | Cyrillic upper case ZE | 199 | C7 | Box drawings vertical double and right single | ||||||||
| 136 | 88 | Cyrillic upper case I | 200 | C8 | Чертежи боксов двойные вверх и вправо | ||||||||
| 137 | 89 | Прописная кириллица короткая I | 205 | 9||||||||||
| 138 | 8A | Cyrillic upper case KA | 202 | CA | Box drawings double up and horizontal | ||||||||
| 139 | 8B | Cyrillic upper case EL | 203 | CB | Чертежи коробок двойные вниз и горизонтальные | ||||||||
| 140 | 8C | Кириллица заглавная | 204 | CC | Box drawings double vertical and right | ||||||||
| 141 | 8D | Cyrillic upper case EN | 205 | CD | Box drawings double horizontal | ||||||||
| 142 | 8E | Заглавная кириллица O | 206 | CE | Чертежи коробки двойные вертикальные и горизонтальные | ||||||||
| 143 | 8F | 60024 Cyrillic upper case PE | 207 | CF | Box drawings up single and horizontal double | ||||||||
| 144 | 90 | Cyrillic upper case ER | 208 | D0 | Box drawings up double and горизонтальный одинарный | ||||||||
| 145 | 91 | кириллица заглавная ES | 209 | D1 | двойная рамка 9 одинарная и горизонтальная0025 | ||||||||
| 146 | 92 | Cyrillic upper case TE | 210 | D2 | Box drawings down double and horizontal single | ||||||||
| 147 | 93 | Cyrillic upper case U | 211 | D3 | Чертежи коробки вверх двойная и правая одинарная | ||||||||
| 148 | 94 | Кириллица заглавная EF | 205 | D 6 | Box drawings up single and right double | ||||||||
| 149 | 95 | Cyrillic upper case HA | 213 | D5 | Box drawings down single and right double | ||||||||
| 150 | 96 | Кириллица заглавная TSE | 214 | D6 | Чертежи внизу двойные и правые одинарные | ||||||||
| 151 | 97 | 6 5 | 215 | D7 | Box drawings vertical double and horizontal single | ||||||||
| 152 | 98 | Cyrillic upper case SHA | 216 | D8 | Box drawings vertical single and horizontal double | ||||||||
| 153 | 99 | Кириллица прописная ЩА | 217 | D9 | Рисунки коробки светятся вверх и влево | 25 | 9A | Cyrillic upper case hard sign | 218 | DA | Box drawings light down and right | ||
| 155 | 9B | Cyrillic upper case YERU | 219 | DB | Полный блок | ||||||||
| 156 | 9C | Цириллический верхний чехол | 220 | DC | Нижняя половина блока | ||||||||
| 157 | 0025 | 9D | Cyrillic upper case E | 221 | DD | Left half block | |||||||
| 158 | 9E | Cyrillic upper case YU | 222 | DE | Right half block | ||||||||
| 159 | 9F | Cyrillic upper case YA | 223 | DF | Upper half block | ||||||||
| 160 | A0 | Cyrillic lower case a | 224 | E0 | Cyrillic lower case er | ||||||||
| 161 | A1 | Cyrillic lower case be | 225 | E1 | Cyrillic lower case es | ||||||||
| 162 | A2 | Cyrillic lower case ve | 226 | E2 | Cyrillic lower case te | ||||||||
| 163 | A3 | Cyrillic lower case ghe | 227 | E3 | Cyrillic lower case u | ||||||||
| 164 | A4 | Cyrillic lower case de | 228 | E4 | Cyrillic lower case ef | ||||||||
| 165 | A5 | Cyrillic Lower Case, т.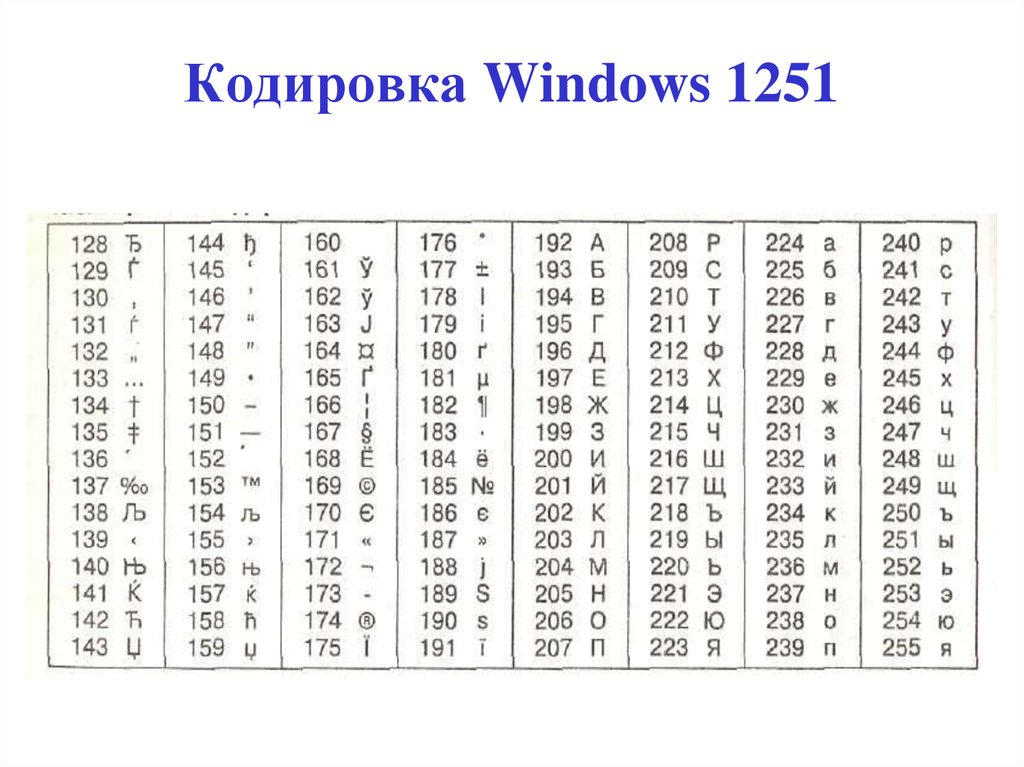 Е. Е. | 229 | E5 | Cyrillic Lower Case HA | ||||||||
| 166 | A6 | 230 | E6 | Cyrillic lower case tse | |||||||||
| 167 | A7 | Cyrillic lower case ze | 231 | E7 | Cyrillic lower case che | ||||||||
| 168 | A8 | Нижняя кириллица i | 232 | E8 | Нижняя кириллица sha | ||||||||
| 169 | A9 | Нижняя кириллица i | 60025 | 233 | E9 | Cyrillic lower case shcha | |||||||
| 170 | AA | Cyrillic lower case ka | 234 | EA | Cyrillic lower case hard sign | ||||||||
| 171 | AB | Cyrillic Lower Case EL | 235 | EB | Cyrillic Lower Case Yeru | ||||||||
| 172 | AC | Cyrillic Low Case Em | AC | Cyrillic EM | . 0025 0025 | 236 | EC | Cyrillic lower case soft sign | |||||
| 173 | AD | Cyrillic lower case en | 237 | ED | Cyrillic lower case e | ||||||||
| 174 | AE | Cyrillic Lower Case O | 238 | EE | Cyrillic Lower Case Yu | ||||||||
| 175 | AF | Cyrill Нижний Case PE | 0025 | 239 | EF | Cyrillic lower case ya | |||||||
| 176 | B0 | Light shade | 240 | F0 | Cyrillic upper case IO | ||||||||
| 177 | B1 | Medium shade | 241 | F1 | Cyrillic lower case io | ||||||||
| 178 | B2 | Dark shade | 242 | F2 | Cyrillic upper case ukrainian IE | ||||||||
| 179 | B3 | Box drawings light vertical | 243 | F3 | Cyrillic lower case ukrainian ie | ||||||||
| 180 | B4 | Box drawings light вертикальный и левый | 244 | F4 | Кириллица заглавная YI | ||||||||
| 181 | B5 | Двойной вертикальный одинарный и левый0025 | 245 | F5 | Cyrillic lower case yi | ||||||||
| 182 | B6 | Box drawings vertical double and left single | 246 | F6 | Cyrillic upper case short U | ||||||||
| 183 | B7 | Чертежи коробки вниз двойные и левые одинарные | 247 | F7 | Строчная кириллица короткая u | ||||||||
| 248 909 90 | рисунки коробки вниз по одному и левому двойному | 248 | F8 | Знак | |||||||||
| 186 | BA | Box Drawings Double Vertical | 250 | FA | Средняя точка | ||||||||
| 187 | BB | ||||||||||||
| 187 | BB | ||||||||||||
| 187 | BB | ||||||||||||
| 187 | BB | ||||||||||||
| 187 | BB | ||||||||||||
| Box drawings double down and left | 251 | FB | Square root | ||||||||||
| 188 | BC | Box drawings double up and left | 252 | FC | Numero sign | ||||||||
| 189 | BD | рисунки коробки с двойным и левым одиночным | 253 | FD | Валютный знак | ||||||||
| 190 | BE | ||||||||||||
| 190 | 4 BE | ||||||||||||
| 190 | 4 BE | ||||||||||||
| 190 | 4 BE | ||||||||||||
| 190 | BE | ||||||||||||
| рисунки коробки вверх и слева двойной | 254 | Fe | Черный квадрат | ||||||||||
| 5 | Box Blaining пробел |
Как сделать, чтобы символы кириллицы отображались корректно?
Tekla Structures
Не зависит от версии
Текла Структурс
Символы кириллицы
Символы русского языка
языковые настройки
Среда
Не зависит от среды
Вопрос:
Как заставить символы кириллицы работать правильно, если у вас не установлен русский язык системы ?
Ответ:
В этом руководстве приведены инструкции по правильному отображению символов кириллицы, если в качестве языка операционной системы не установлен русский язык.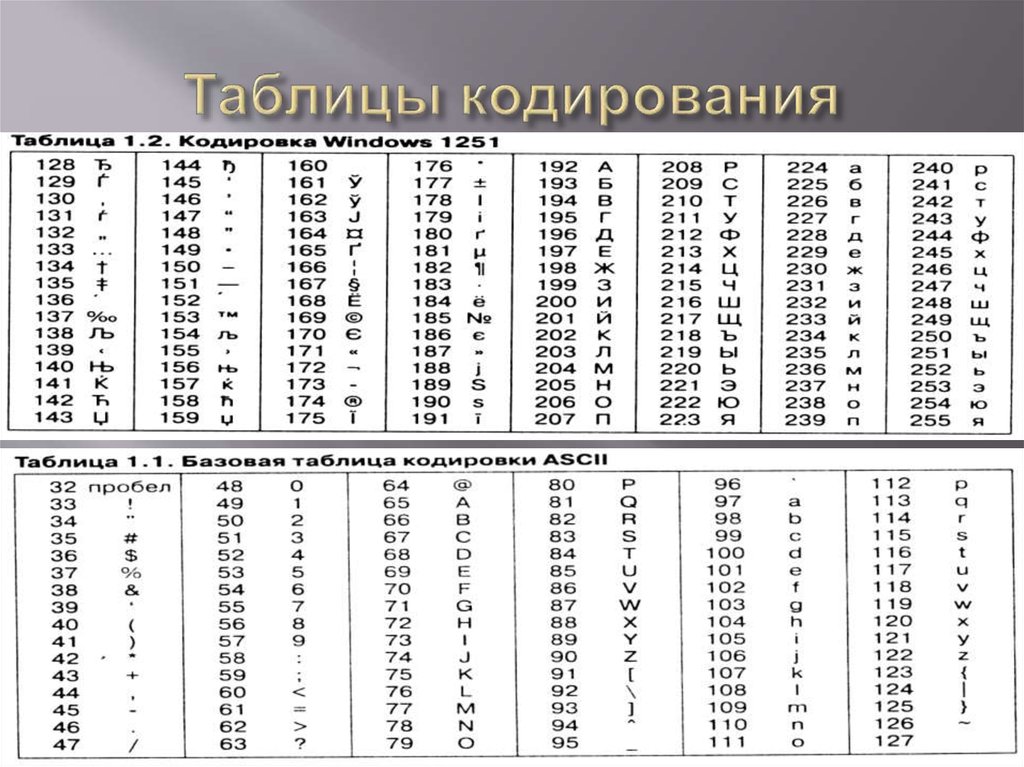 Это руководство предназначено для операционной системы Windows 7. Для применения этих настроек у вас должны быть права администратора на вашем компьютере, поэтому, если у вас их нет, обратитесь к системному администратору.
Это руководство предназначено для операционной системы Windows 7. Для применения этих настроек у вас должны быть права администратора на вашем компьютере, поэтому, если у вас их нет, обратитесь к системному администратору.
Вот так выглядит ваш интерфейс Tekla Structures (Свойства балки и Каталог профилей), если вы используете русскую среду с операционной системой Windows, например на английском (или любом другом языке, не содержащем кириллицы).
Изображение
Изображение
Для корректной работы:
1. Вы должны изменить системную локаль на русский язык. Это не повлияет на язык интерфейса вашей системы. Как поясняется в справке Windows, «локаль системы определяет набор символов по умолчанию (буквы, символы и цифры) и шрифт, используемый для ввода и отображения информации в программах, не использующих Unicode».
а. Чтобы изменить, перейдите в Панель управления -> Регион и язык и щелкните вкладку Административная .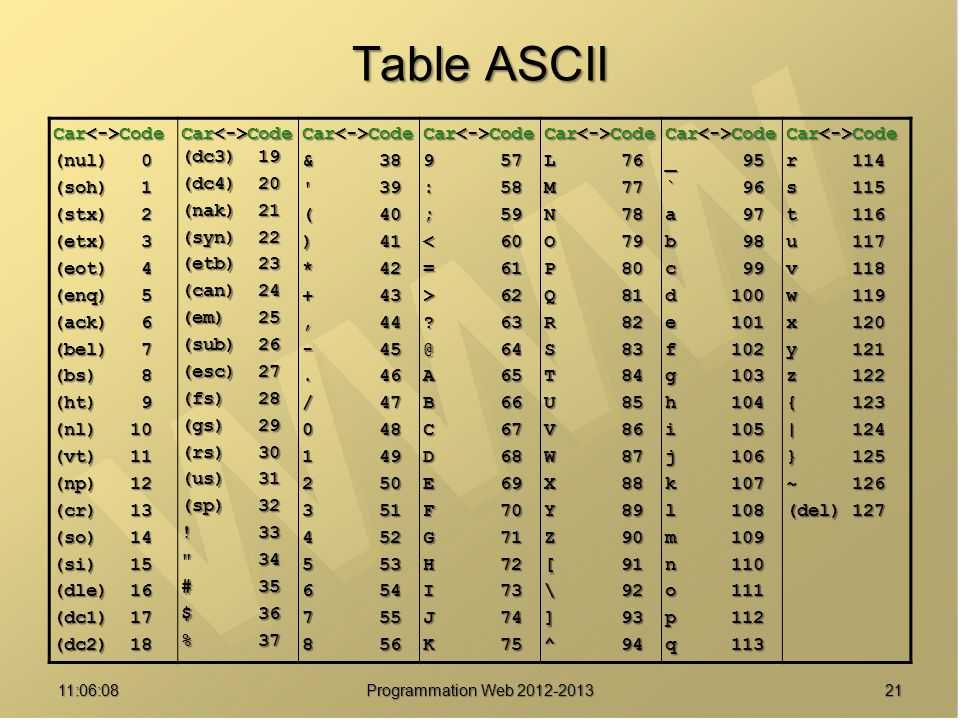
Изображение
б. Там нажмите Изменить язык системы… и из выпадающего списка выберите Русский (Россия) .
Изображение
c. После применения настроек вам придется перезагрузить компьютер.
д. После перезагрузки компьютера символы кириллицы должны правильно отображаться в интерфейсе Tekla Structures, например Свойства балок и каталог профилей.
Изображение
Изображение
e. Но в некоторых местах, напр. метки сетки в виде модели или шаблонах компоновки, символы все еще могли отображаться неправильно.
Изображение
Изображение
2. В этом случае необходимо установить расширенный параметр XS_STD_LOCALE в файле инициализации lang_rus.ini
Перейдите в папку установки Tekla Structures, например C:\Program Files\Tekla Structures\<версия>\nt\binb.
 Откройте lang_rus.ini с помощью любого текстового редактора и добавьте set XS_STD_LOCALE=russian_us.1251 (или другую строку кодовой страницы символов локали). Дополнительные сведения см. в разделе XS_STD_LOCALE.
Откройте lang_rus.ini с помощью любого текстового редактора и добавьте set XS_STD_LOCALE=russian_us.1251 (или другую строку кодовой страницы символов локали). Дополнительные сведения см. в разделе XS_STD_LOCALE.
Изображение
c. Вы не сможете сохранить файл непосредственно в папку установки. Вы должны сохранить измененный файл lang_rus.ini в другом месте, а затем скопировать его в папку установки.
ум. После применения этого расширенного параметра все символы кириллицы в Tekla Structures будут отображаться правильно.
Изображение
Изображение
Изображение | Начиная с Tekla Structures 21.0 в русской среде есть возможность выбора роли при запуске программы пользователем. Оставить комментарий
|
