Windows-1251 – вопросы и ответы по программированию
У меня есть следующее: deviceName = String.init(bytes: temp.prefix(upTo: index), encoding: .windowsCP1251) где temp — [UInt8] . Мой вопрос: как я могу преобразовать эту строку обратно в Data ? Я пы…
Я пишу приложение WinPhone 8.1. Код очень прост и работает в большинстве случаев: string htmlContent; using (var client = new HttpClient()) { htmlContent = await client.GetStringAsync(GenerateUri()…
Я пытаюсь проанализировать (и избежать) строки CSV файла, который хранится в кодировке символов Windows-1251 .
Я пытаюсь создать XML файл из массива. Это мой код разработчика: def buildXML(formattedText) builder = Nokogiri::XML::Builder.new do |xml| xml.products { formattedText.each do |lineItem| xml.item {…
моя сложная жизнь заставляет меня использовать кодировку «windows-1251» на С# под Ubuntu 16.04. Я использую «mono» для запуска С#. обе команды Encoding.GetEncoding(1251) Encoding.GetEncoding(«windo…
У меня проблема с сборкой проекта: D:. ..\Main.java:112: error: unmappable character (0x98) для кодирования окон-1251 . Robot.getBrowserControl() findElement (By.xpath( «//DIV [= ‘НАПИСАТЬ.]»)) Нажм… 2 года, 11 месяцев назад
GRbI3yH
..\Main.java:112: error: unmappable character (0x98) для кодирования окон-1251 . Robot.getBrowserControl() findElement (By.xpath( «//DIV [= ‘НАПИСАТЬ.]»)) Нажм… 2 года, 11 месяцев назад
GRbI3yHЯ использую функцию iconv с опцией translit. Есть ли транслитерация от UTF-8 до CP1251, когда один символ заменяет несколько символов? Где я могу найти эту информацию? Я использую iconv.
4 года, 9 месяцев назад MayRiv Я знаю, что есть эти методы — decode… 4 года, 5 месяцев назад
Romanzhivo
Я знаю, что есть эти методы — decode… 4 года, 5 месяцев назад
RomanzhivoЯ мало знаю об этом, помогите мне, пожалуйста. Я устанавливал рубиновые окна-драйверы на шаге 9, возникла проблема
PostgreSQL : Документация: 10: 23.3. Поддержка кодировок : Компания Postgres Professional
23.3. Поддержка кодировок
Поддержка кодировок в PostgreSQL позволяет хранить текст в различных кодировках, включая однобайтовые кодировки, такие как входящие в семейство ISO 8859 и многобайтовые кодировки, такие как EUC (Extended Unix Code), UTF-8 и внутренний код Mule. Все поддерживаемые кодировки могут прозрачно использоваться клиентами, но некоторые не поддерживаются сервером (в качестве серверной кодировки). Кодировка по умолчанию выбирается при инициализации кластера базы данных PostgreSQL при помощи
Все поддерживаемые кодировки могут прозрачно использоваться клиентами, но некоторые не поддерживаются сервером (в качестве серверной кодировки). Кодировка по умолчанию выбирается при инициализации кластера базы данных PostgreSQL при помощи initdb. Она может быть переопределена при создании базы данных, что позволяет иметь несколько баз данных с разными кодировками.
Важным ограничением, однако, является то, что кодировка каждой базы данных должна быть совместима с параметрами локали базы данных LC_CTYPE (классификация символов) и LC_COLLATE (порядок сортировки строк). Для локали C или POSIX подойдёт любой набор символов, но для других локалей, предоставляемых библиотекой libc, есть только один набор символов, который будет работать правильно. (Однако в среде Windows кодировка UTF-8 может использоваться с любой локалью.) Если у вас включена поддержка ICU, локали, предоставляемые библиотекой ICU, можно использовать с большинством (но не всеми) кодировками на стороне сервера.
23.3.1. Поддерживаемые кодировки
Таблица 23.1 показывает кодировки, доступные для использования в PostgreSQL.
Таблица 23.1. Кодировки PostgreSQL
| Имя | Описание | Язык | Поддержка на сервере | ICU? | Байтов на символ | Псевдонимы |
|---|---|---|---|---|---|---|
BIG5 | Big Five | Традиционные китайские иероглифы | Нет | Нет | 1-2 | WIN950, Windows950 |
EUC_CN | Extended UNIX Code-CN | Упрощённые китайские иероглифы | Да | Да | 1-3 | |
EUC_JP | Extended UNIX Code-JP | Японский | Да | Да | 1-3 | |
EUC_JIS_2004 | Extended UNIX Code-JP, JIS X 0213 | Японский | Да | Нет | 1-3 | |
EUC_KR | Extended UNIX Code-KR | Корейский | Да | Да | 1-3 | |
EUC_TW | Extended UNIX Code-TW | Традиционные китайские иероглифы, тайваньский | Да | Да | 1-3 | |
GB18030 | Национальный стандарт | Китайский | Нет | Нет | 1-4 | |
GBK | Расширенный национальный стандарт | Упрощённые китайские иероглифы | Нет | Нет | 1-2 | WIN936, Windows936 |
ISO_8859_5 | ISO 8859-5, ECMA 113 | Латинский/Кириллица | Да | Да | 1 | |
ISO_8859_6 | ISO 8859-6, ECMA 114 | Латинский/Арабский | Да | Да | 1 | |
ISO_8859_7 | ISO 8859-7, ECMA 118 | Латинский/Греческий | Да | Да | 1 | |
ISO_8859_8 | ISO 8859-8, ECMA 121 | Латинский/Иврит | Да | Да | 1 | |
JOHAB | JOHAB | Корейский (Хангыль) | Нет | Нет | 1-3 | |
KOI8R | KOI8-R | Кириллица (Русский) | Да | Да | 1 | KOI8 |
KOI8U | KOI8-U | Кириллица (Украинский) | Да | Да | 1 | |
LATIN1 | ISO 8859-1, ECMA 94 | Западноевропейские | Да | Да | 1 | ISO88591 |
LATIN2 | ISO 8859-2, ECMA 94 | Центральноевропейские | Да | Да | 1 | ISO88592 |
LATIN3 | ISO 8859-3, ECMA 94 | Южноевропейские | Да | Да | 1 | ISO88593 |
LATIN4 | ISO 8859-4, ECMA 94 | Североевропейские | Да | Да | 1 | ISO88594 |
LATIN5 | ISO 8859-9, ECMA 128 | Турецкий | Да | Да | 1 | ISO88599 |
LATIN6 | ISO 8859-10, ECMA 144 | Скандинавские | Да | Да | 1 | ISO885910 |
LATIN7 | ISO 8859-13 | Балтийские | Да | Да | 1 | ISO885913 |
LATIN8 | ISO 8859-14 | Кельтские | Да | Да | 1 | ISO885914 |
LATIN9 | ISO 8859-15 | LATIN1 c европейскими языками и диалектами | Да | Да | 1 | ISO885915 |
LATIN10 | ISO 8859-16, ASRO SR 14111 | Румынский | Да | Нет | 1 | ISO885916 |
MULE_INTERNAL | Внутренний код Mule | Мультиязычный редактор Emacs | Да | Нет | 1-4 | |
SJIS | Shift JIS | Японский | Нет | Нет | 1-2 | Mskanji, ShiftJIS, WIN932, Windows932 |
SHIFT_JIS_2004 | Shift JIS, JIS X 0213 | Японский | Нет | Нет | 1-2 | |
SQL_ASCII | не указан (см. текст) текст) | any | Да | Нет | 1 | |
UHC | Унифицированный код Хангыль | Корейский | Нет | Нет | 1-2 | WIN949, Windows949 |
UTF8 | Unicode, 8-bit | все | Да | Да | 1-4 | Unicode |
WIN866 | Windows CP866 | Кириллица | Да | Да | 1 | ALT |
WIN874 | Windows CP874 | Тайский | Да | Нет | 1 | |
WIN1250 | Windows CP1250 | Центральноевропейские | Да | Да | 1 | |
WIN1251 | Windows CP1251 | Кириллица | Да | Да | 1 | WIN |
WIN1252 | Windows CP1252 | Западноевропейские | Да | Да | 1 | |
WIN1253 | Windows CP1253 | Греческий | Да | Да | 1 | |
WIN1254 | Windows CP1254 | Турецкий | Да | Да | 1 | |
WIN1255 | Windows CP1255 | Иврит | Да | Да | 1 | |
WIN1256 | Windows CP1256 | Арабский | Да | Да | 1 | |
WIN1257 | Windows CP1257 | Балтийские | Да | Да | 1 | |
WIN1258 | Windows CP1258 | Вьетнамский | Да | Да | 1 | ABC, TCVN, TCVN5712, VSCII |
Не все клиентские API поддерживают все перечисленные кодировки. Например, драйвер интерфейса JDBC PostgreSQL не поддерживает
Например, драйвер интерфейса JDBC PostgreSQL не поддерживает MULE_INTERNAL, LATIN6, LATIN8 и LATIN10.
Поведение кодировки SQL_ASCII существенно отличается от других. Когда набором символов сервера является SQL_ASCII, сервер интерпретирует значения от 0 до 127 байт согласно кодировке ASCII, тогда как значения от 128 до 255 воспринимаются как незначимые. Перекодировка не будет выполнена при выборе SQL_ASCII. Таким образом, этот вариант является не столько объявлением того, что используется определённая кодировка, сколько объявлением того, что кодировка игнорируется. В большинстве случаев, если вы работаете с любыми данными, отличными от ASCII, не стоит использовать SQL_ASCII, так как PostgreSQL не сможет преобразовать или проверить символы, отличные от ASCII.
23.3.2. Настройка кодировки
initdb определяет кодировку по умолчанию для кластера PostgreSQL. Например,
Например,
initdb -E EUC_JP
настраивает кодировку по умолчанию на EUC_JP (Расширенная система кодирования для японского языка). Можно использовать --encoding вместо -E в случае предпочтения более длинных имён параметров. Если параметр -E или --encoding не задан, initdb пытается определить подходящую кодировку в зависимости от указанной или заданной по умолчанию локали.
При создании базы данных можно указать кодировку, отличную от заданной по умолчанию, если эта кодировка совместима с выбранной локалью:
createdb -E EUC_KR -T template0 --lc-collate=ko_KR.euckr --lc-ctype=ko_KR.euckr korean
Это создаст базу данных с именем korean, которая использует кодировку EUC_KR и локаль ko_KR. Также, получить желаемый результат можно с помощью данной SQL-команды:
CREATE DATABASE korean WITH ENCODING 'EUC_KR' LC_COLLATE='ko_KR.euckr' LC_CTYPE='ko_KR.euckr' TEMPLATE=template0;
Заметьте, что приведённые выше команды задают копирование базы данных template0. При копировании любой другой базы данных, параметры локали и кодировку исходной базы изменить нельзя, так как это может привести к искажению данных. Более подробное описание приведено в Разделе 22.3.
Кодировка базы данных хранится в системном каталоге pg_database. Её можно увидеть при помощи параметра psql -l или команды \l.
$psql -lList of databases Name | Owner | Encoding | Collation | Ctype | Access Privileges -----------+----------+-----------+-------------+-------------+------------------------------------- clocaledb | hlinnaka | SQL_ASCII | C | C | englishdb | hlinnaka | UTF8 | en_GB.UTF8 | en_GB.UTF8 | japanese | hlinnaka | UTF8 | ja_JP.UTF8 | ja_JP.UTF8 | korean | hlinnaka | EUC_KR | ko_KR.euckr | ko_KR.euckr | postgres | hlinnaka | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | template0 | hlinnaka | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | {=c/hlinnaka,hlinnaka=CTc/hlinnaka} template1 | hlinnaka | UTF8 | fi_FI.UTF8 | fi_FI.UTF8 | {=c/hlinnaka,hlinnaka=CTc/hlinnaka} (7 rows)
Важно
На большинстве современных операционных систем PostgreSQL может определить, какая кодировка подразумевается параметром LC_CTYPE, что обеспечит использование только соответствующей кодировки базы данных. На более старых системах необходимо самостоятельно следить за тем, чтобы использовалась кодировка, соответствующая выбранной языковой среде. Ошибка в этой области, скорее всего, приведёт к странному поведению зависимых от локали операций, таких как сортировка.
PostgreSQL позволит суперпользователям создавать базы данных с кодировкой SQL_ASCII, даже когда значение LC_CTYPE не установлено в C или POSIX.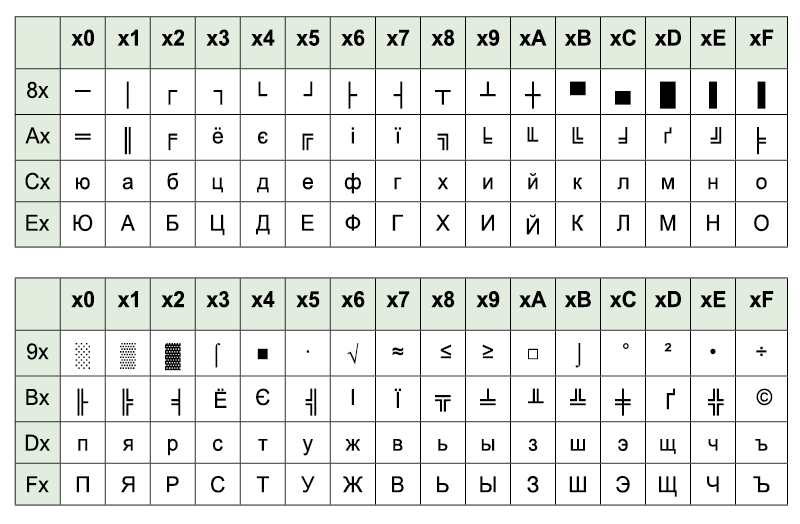 Как было сказано выше,
Как было сказано выше, SQL_ASCII не гарантирует, что данные, хранящиеся в базе, имеют определённую кодировку, и таким образом, этот выбор чреват сбоями, связанными с локалью. Использование данной комбинации устарело и, возможно, будет полностью запрещено.
23.3.3. Автоматическая перекодировка между сервером и клиентом
PostgreSQL поддерживает автоматическую перекодировку между сервером и клиентом для определённых комбинаций кодировок. Информация, касающаяся перекодировки, хранится в системном каталоге pg_conversion. PostgreSQL включает в себя некоторые предопределённые кодировки, как показано в Таблице 23.2. Есть возможность создать новую перекодировку при помощи SQL-команды CREATE CONVERSION.
Таблица 23.2. Клиент-серверные перекодировки наборов символов
| Серверная кодировка | Доступные клиентские кодировки |
|---|---|
BIG5 | не поддерживается как серверная кодировка |
EUC_CN | EUC_CN, MULE_INTERNAL, UTF8 |
EUC_JP | EUC_JP, MULE_INTERNAL, SJIS, UTF8 |
EUC_JIS_2004 | EUC_JIS_2004, SHIFT_JIS_2004, UTF8 |
EUC_KR | EUC_KR, MULE_INTERNAL, UTF8 |
EUC_TW | EUC_TW, BIG5, MULE_INTERNAL, UTF8 |
GB18030 | не поддерживается как серверная кодировка |
GBK | не поддерживается как серверная кодировка |
ISO_8859_5 | ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN866, WIN1251 |
ISO_8859_6 | ISO_8859_6, UTF8 |
ISO_8859_7 | ISO_8859_7, UTF8 |
ISO_8859_8 | ISO_8859_8, UTF8 |
JOHAB | не поддерживается как серверная кодировка |
KOI8R | KOI8R, ISO_8859_5, MULE_INTERNAL, UTF8, WIN866, WIN1251 |
KOI8U | KOI8U, UTF8 |
LATIN1 | LATIN1, MULE_INTERNAL, UTF8 |
LATIN2 | LATIN2, MULE_INTERNAL, UTF8, WIN1250 |
LATIN3 | LATIN3, MULE_INTERNAL, UTF8 |
LATIN4 | LATIN4, MULE_INTERNAL, UTF8 |
LATIN5 | LATIN5, UTF8 |
LATIN6 | LATIN6, UTF8 |
LATIN7 | LATIN7, UTF8 |
LATIN8 | LATIN8, UTF8 |
LATIN9 | LATIN9, UTF8 |
LATIN10 | LATIN10, UTF8 |
MULE_INTERNAL | MULE_INTERNAL, BIG5, EUC_CN, EUC_JP, EUC_KR, EUC_TW, ISO_8859_5, KOI8R, LATIN1 to LATIN4, SJIS, WIN866, WIN1250, WIN1251 |
SJIS | не поддерживается как серверная кодировка |
SHIFT_JIS_2004 | не поддерживается как серверная кодировка |
SQL_ASCII | любая (перекодировка не будет выполнена) |
UHC | не поддерживается как серверная кодировка |
UTF8 | все поддерживаемые кодировки |
WIN866 | WIN866, ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN1251 |
WIN874 | WIN874, UTF8 |
WIN1250 | WIN1250, LATIN2, MULE_INTERNAL, UTF8 |
WIN1251 | WIN1251, ISO_8859_5, KOI8R, MULE_INTERNAL, UTF8, WIN866 |
WIN1252 | WIN1252, UTF8 |
WIN1253 | WIN1253, UTF8 |
WIN1254 | WIN1254, UTF8 |
WIN1255 | WIN1255, UTF8 |
WIN1256 | WIN1256, UTF8 |
WIN1257 | WIN1257, UTF8 |
WIN1258 | WIN1258, UTF8 |
Чтобы включить автоматическую перекодировку символов, необходимо сообщить PostgreSQL кодировку, которую вы хотели бы использовать на стороне клиента. Это можно выполнить несколькими способами:
Это можно выполнить несколькими способами:
Использование команды
\encodingв psql.\encodingпозволяет оперативно изменять клиентскую кодировку. Например, чтобы изменить кодировку наSJIS, введите:\encoding SJIS
libpq (Раздел 33.10) имеет функции, для управления клиентской кодировкой.
Использование
SET client_encoding TO. Клиентская кодировка устанавливается следующей SQL-командой:SET CLIENT_ENCODING TO '
value';Также, для этой цели можно использовать стандартный синтаксис SQL
SET NAMES:SET NAMES '
value';Получить текущую клиентскую кодировку:
SHOW client_encoding;
Вернуть кодировку по умолчанию:
RESET client_encoding;
Использование
PGCLIENTENCODING. Если установлена переменная окруженияPGCLIENTENCODING, то эта клиентская кодировка выбирается автоматически при подключении к серверу. (В дальнейшем это может быть переопределено при помощи любого из методов, указанных выше.)
(В дальнейшем это может быть переопределено при помощи любого из методов, указанных выше.)Использование переменной конфигурации client_encoding. Если задана переменная
client_encoding, указанная клиентская кодировка выбирается автоматически при подключении к серверу. (В дальнейшем это может быть переопределено при помощи любого из методов, указанных выше.)
Если перекодировка определённого символа невозможна (предположим, выбраны EUC_JP для сервера и LATIN1 для клиента, и передаются некоторые японские иероглифы, не представленные в LATIN1), возникает ошибка.
Если клиентская кодировка определена как SQL_ASCII, перекодировка отключается вне зависимости от кодировки сервера. Что же касается сервера, не стоит использовать SQL_ASCII, если только вы не работаете с данными, которые полностью соответствуют ASCII.
23.3.4. Дополнительные источники информации
Рекомендуемые источники для начала изучения различных видов систем кодирования.
- Обработка информации на китайском, японском, корейском & вьетнамском языках.
Содержит подробные объяснения по
EUC_JP,EUC_CN,EUC_KR,EUC_TW.- http://www.unicode.org/
Сайт Unicode Consortium.
- RFC 3629
UTF-8 (формат преобразования 8-битного UCS/Unicode) определён здесь.
Модуль ngx_http_charset_module
Модуль ngx_http_charset_module
Модуль ngx_http_charset_module добавляет указанную
кодировку в поле “Content-Type” заголовка ответа.
Кроме того, модуль может перекодировать данные из одной кодировки в другую
с некоторыми ограничениями:
- перекодирование осуществляется только в одну сторону — от сервера к клиенту,
- перекодироваться могут только однобайтные кодировки
- или однобайтные кодировки в UTF-8 и обратно.
Пример конфигурации
include conf/koi-win; charset windows-1251; source_charset koi8-r;
Директивы
| Синтаксис: | charset |
|---|---|
| Умолчание: | charset off; |
| Контекст: | http, server, location, if в location |
Добавляет указанную кодировку в поле “Content-Type”
заголовка ответа.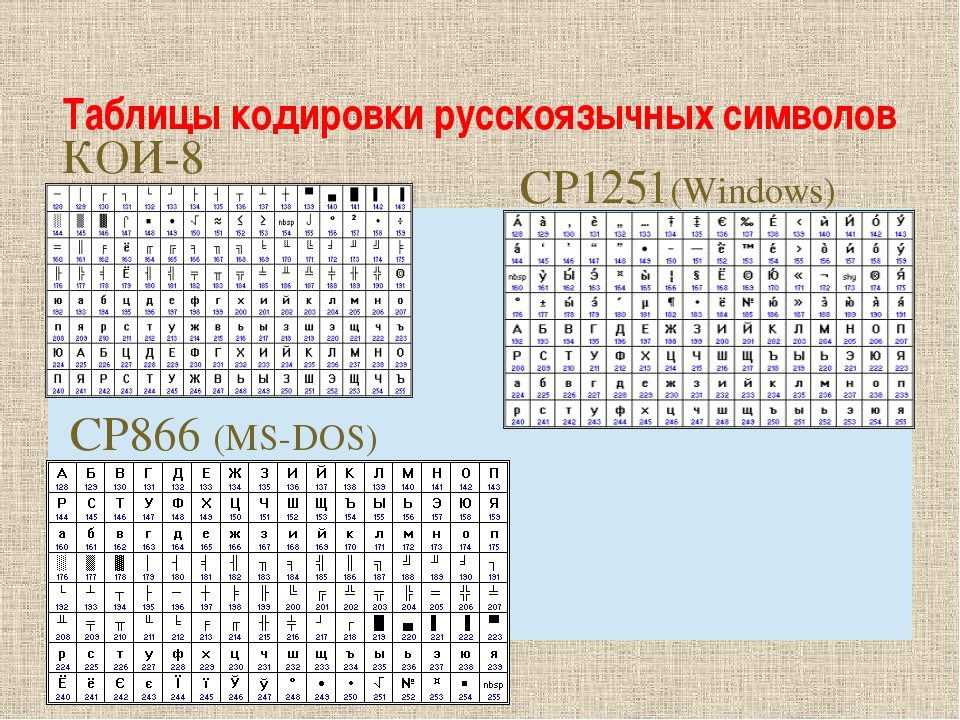 Если эта кодировка отличается от указанной в директиве
source_charset, то выполняется перекодирование.
Если эта кодировка отличается от указанной в директиве
source_charset, то выполняется перекодирование.
Параметр off отменяет добавление кодировки
в поле “Content-Type” заголовка ответа.
Кодировка может быть задана с помощью переменной:
charset $charset;
В этом случае необходимо, чтобы все возможные значения переменной
присутствовали хотя бы один раз в любом месте конфигурации в виде
директив charset_map, charset или
source_charset.
Для кодировок utf-8, windows-1251 и koi8-r для этого достаточно включить в конфигурацию
файлы conf/koi-win, conf/koi-utf и conf/win-utf.
Для других кодировок можно просто сделать фиктивную таблицу перекодировки,
например:
charset_map iso-8859-5 _ { }
Кроме того, кодировка может быть задана в поле “X-Accel-Charset”
заголовка ответа.
Эту возможность можно запретить с помощью директив
proxy_ignore_headers,
fastcgi_ignore_headers,
uwsgi_ignore_headers,
scgi_ignore_headers
и
grpc_ignore_headers.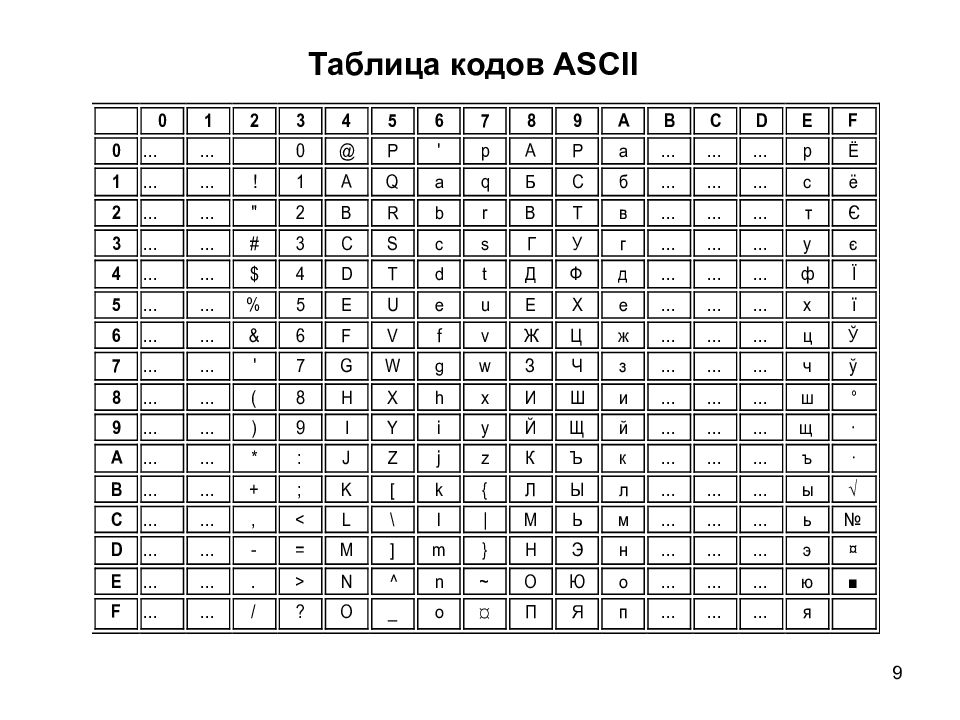
| Синтаксис: | charset_map |
|---|---|
| Умолчание: | — |
| Контекст: | http |
Описывает таблицу перекодирования из одной кодировки в другую.
Таблица для обратного перекодирования строится на основании тех же данных.
Коды символов задаются в шестнадцатеричном виде.
Неописанные символы в пределах 80-FF заменяются на “?”.
При перекодировании из UTF-8 символы, отсутствующие в однобайтной кодировке,
заменяются на “&#XXXX;”.
Пример:
charset_map koi8-r windows-1251 {
C0 FE ; # small yu
C1 E0 ; # small a
C2 E1 ; # small b
C3 F6 ; # small ts
. ..
}
..
}
При описании таблицы перекодирования в UTF-8, коды кодировки UTF-8 должны быть указаны во второй колонке, например:
charset_map koi8-r utf-8 {
C0 D18E ; # small yu
C1 D0B0 ; # small a
C2 D0B1 ; # small b
C3 D186 ; # small ts
...
}
Полные таблицы преобразования из windows-1251 и из koi8-r и windows-1251 в utf-8 входят в дистрибутив и находятся в файлах conf/koi-win, conf/koi-utf и conf/win-utf.
| Синтаксис: | charset_types |
|---|---|
| Умолчание: | charset_types text/html text/xml text/plain text/vnd.wap.wml application/javascript application/rss+xml; |
| Контекст: | http, server, location |
Эта директива появилась в версии 0. 7.9.
7.9.
Разрешает работу модуля в ответах с указанными MIME-типами
в дополнение к “text/html”.
Специальное значение “*” соответствует любому MIME-типу
(0.8.29).
До версии 1.5.4 по умолчанию вместо MIME-типа “application/javascript” использовался “application/x-javascript”.
| Синтаксис: | override_charset |
|---|---|
| Умолчание: | override_charset off; |
| Контекст: | http, server, location, if в location |
Определяет, выполнять ли перекодирование для ответов,
полученных от проксированного сервера или от FastCGI/uwsgi/SCGI/gRPC-сервера,
если в ответах уже указана кодировка в поле “Content-Type”
заголовка ответа. Если перекодирование разрешено, то в качестве исходной кодировки
используется кодировка, указанная в полученном ответе.
Если перекодирование разрешено, то в качестве исходной кодировки
используется кодировка, указанная в полученном ответе.
Необходимо отметить, что если ответ был получен в подзапросе,
то, независимо от значения директивы override_charset,
всегда выполняется перекодирование из кодировки ответа в кодировку
основного запроса.| Синтаксис: | source_charset |
|---|---|
| Умолчание: | — |
| Контекст: | http, server, location, if в location |
Задаёт исходную кодировку ответа.
Если эта кодировка отличается от указанной в директиве
charset, то выполняется перекодирование.
Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
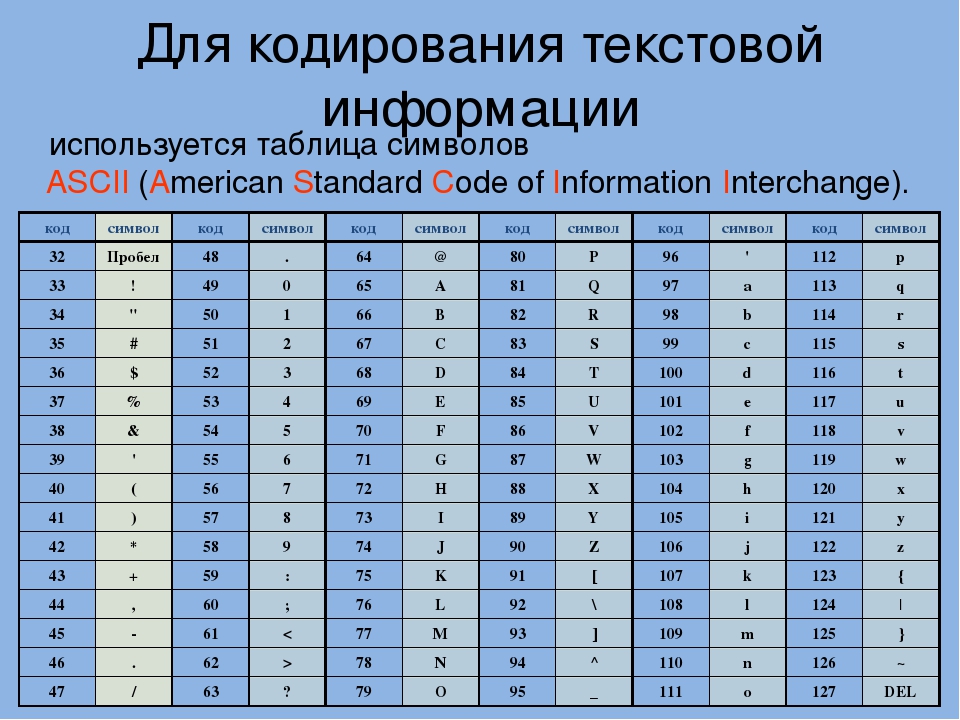
Сегодня мы поговорим о том, откуда берутся кракозябры на сайте и в программах, какие кодировки текста существуют и какие из них следует использовать. Подробно рассмотрим историю их развития, начиная с базовой ASCII, а также ее расширенных версий CP866, KOI8-R, Windows 1251 и заканчивая современными кодировками консорциума Юникод UTF 16 и 8. Оглавление: Кому-то эти сведения могут показаться излишними, но знали бы вы, сколько мне приходит вопросов именно касаемо вылезших кракозябров (нечитаемого набора символов). Теперь у меня будет возможность отсылать всех к тексту этой статьи и самостоятельно отыскивать свои косяки. Ну что же, приготовьтесь впитывать информацию и постарайтесь следить за ходом повествования.ASCII — базовая кодировка текста для латиницы
Развитие кодировок текстов происходило одновременно с формированием отрасли IT, и они за это время успели претерпеть достаточно много изменений. Исторически все начиналось с довольно-таки неблагозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами. Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания. Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы вроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
Именно эти 128 символов из первоначального варианта ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке. Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской).
Исторически все начиналось с довольно-таки неблагозвучной в русском произношении EBCDIC, которая позволяла кодировать буквы латинского алфавита, арабские цифры и знаки пунктуации с управляющими символами. Но все же отправной точкой для развития современных кодировок текстов стоит считать знаменитую ASCII (American Standard Code for Information Interchange, которая по-русски обычно произносится как «аски»). Она описывает первые 128 символов из наиболее часто используемых англоязычными пользователями — латинские буквы, арабские цифры и знаки препинания. Еще в эти 128 знаков, описанных в ASCII, попадали некоторые служебные символы вроде скобок, решеток, звездочек и т.п. Собственно, вы сами можете увидеть их:
Именно эти 128 символов из первоначального варианта ASCII стали стандартом, и в любой другой кодировке вы их обязательно встретите и стоять они будут именно в таком порядке. Но дело в том, что с помощью одного байта информации можно закодировать не 128, а целых 256 различных значений (двойка в степени восемь равняется 256), поэтому вслед за базовой версией Аски появился целый ряд расширенных кодировок ASCII, в которых можно было кроме 128 основных знаков закодировать еще и символы национальной кодировки (например, русской). Тут, наверное, стоит еще немного сказать о системах счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет собой двойку в степени, начиная с нулевой, и до двойки в седьмой: Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички. В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получается 233 в десятичной системе счисления. Как видите, все очень просто. Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке.
Тут, наверное, стоит еще немного сказать о системах счисления, которые используются при описании. Во-первых, как вы все знаете, компьютер работает только с числами в двоичной системе, а именно с нулями и единицами («булева алгебра», если кто проходил в институте или в школе). Один байт состоит из восьми бит, каждый из которых представляет собой двойку в степени, начиная с нулевой, и до двойки в седьмой: Не трудно понять, что всех возможных комбинаций нулей и единиц в такой конструкции может быть только 256. Переводить число из двоичной системы в десятичную довольно просто. Нужно просто сложить все степени двойки, над которыми стоят единички. В нашем примере это получается 1 (2 в степени ноль) плюс 8 (два в степени 3), плюс 32 (двойка в пятой степени), плюс 64 (в шестой), плюс 128 (в седьмой). Итого получается 233 в десятичной системе счисления. Как видите, все очень просто. Но если вы присмотритесь к таблице с символами ASCII, то увидите, что они представлены в шестнадцатеричной кодировке. Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать). Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому способу. Каждый байт информации разбивают на две части по четыре бита. Т.е. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом. Причем в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.
Например, «звездочка» соответствует в Аски шестнадцатеричному числу 2A. Наверное, вам известно, что в шестнадцатеричной системе счисления используются кроме арабских цифр еще и латинские буквы от A (означает десять) до F (означает пятнадцать). Ну так вот, для перевода двоичного числа в шестнадцатеричное прибегают к следующему простому способу. Каждый байт информации разбивают на две части по четыре бита. Т.е. в каждой половинке байта двоичным кодом можно закодировать только шестнадцать значений (два в четвертой степени), что можно легко представить шестнадцатеричным числом. Причем в левой половине байта считать степени нужно будет опять начиная с нулевой, а не так, как показано на скриншоте. В результате мы получим, что на скриншоте закодировано число E9. Надеюсь, что ход моих рассуждений и разгадка данного ребуса вам оказались понятны. Ну, а теперь продолжим, собственно, говорить про кодировки текста.Расширенные версии Аски — кодировки CP866 и KOI8-R с псевдографикой
Итак, мы с вами начали говорить про ASCII, которая являлась как бы отправной точкой для развития всех современных кодировок (Windows 1251, юникод, UTF 8). Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка. Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место. Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста.
Изначально в нее было заложено только 128 знаков латинского алфавита, арабских цифр и еще чего-то там, но в расширенной версии появилась возможность использовать все 256 значений, которые можно закодировать в одном байте информации. Т.е. появилась возможность добавить в Аски символы букв своего языка. Тут нужно будет еще раз отвлечься, чтобы пояснить — зачем вообще нужны кодировки текстов и почему это так важно. Символы на экране вашего компьютера формируются на основе двух вещей — наборов векторных форм (представлений) всевозможных знаков (они находятся в файлах со шрифтами, которые установлены на вашем компьютере) и кода, который позволяет выдернуть из этого набора векторных форм (файла шрифта) именно тот символ, который нужно будет вставить в нужное место. Понятно, что за сами векторные формы отвечают шрифты, а вот за кодирование отвечает операционная система и используемые в ней программы. Т.е. любой текст на вашем компьютере будет представлять собой набор байтов, в каждом из которых закодирован один единственный символ этого самого текста. Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально. Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), нужно выполнить два условия: векторная форма этого знака должна быть в используемом шрифте, и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски. Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита, и она являлась расширенной версией ASCII. То есть, ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика): Видите, в правом столбце цифры начинаются с 8, т.
Программа, отображающая этот текст на экране (текстовый редактор, браузер и т.п.), при разборе кода считывает кодировку очередного знака и ищет соответствующую ему векторную форму в нужном файле шрифта, который подключен для отображения данного текстового документа. Все просто и банально. Значит, чтобы закодировать любой нужный нам символ (например, из национального алфавита), нужно выполнить два условия: векторная форма этого знака должна быть в используемом шрифте, и этот символ можно было бы закодировать в расширенных кодировках ASCII в один байт. Поэтому таких вариантов существует целая куча. Только лишь для кодирования символов русского языка существует несколько разновидностей расширенной Аски. Например, изначально появилась CP866, в которой была возможность использовать символы русского алфавита, и она являлась расширенной версией ASCII. То есть, ее верхняя часть полностью совпадала с базовой версией Аски (128 символов латиницы, цифр и еще всякой лабуды), которая представлена на приведенном чуть выше скриншоте, а вот уже нижняя часть таблицы с кодировкой CP866 имела указанный на скриншоте чуть ниже вид и позволяла закодировать еще 128 знаков (русские буквы и всякая там псевдографика): Видите, в правом столбце цифры начинаются с 8, т. к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Таким образом, у кириллической буквы «М» в CP866 будет код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте. Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда графические операционные системы не были распространены как сейчас. А в Досе и подобных ей текстовых операционках псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски. CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом.
к. числа с 0 до 7 относятся к базовой части ASCII (см. первый скриншот). Таким образом, у кириллической буквы «М» в CP866 будет код 9С (она находится на пересечении соответствующих строки с 9 и столбца с цифрой С в шестнадцатеричной системе счисления), который можно записать в одном байте информации, и при наличии подходящего шрифта с русскими символами эта буква без проблем отобразится в тексте. Откуда взялось такое количество псевдографики в CP866? Тут все дело в том, что эта кодировка для русского текста разрабатывалась еще в те мохнатые года, когда графические операционные системы не были распространены как сейчас. А в Досе и подобных ей текстовых операционках псевдографика позволяла хоть как-то разнообразить оформление текстов и поэтому ею изобилует CP866 и все другие ее ровесницы из разряда расширенных версий Аски. CP866 распространяла компания IBM, но кроме этого для символов русского языка были разработаны еще ряд кодировок, например, к этому же типу (расширенных ASCII) можно отнести KOI8-R:
Принцип ее работы остался тот же самый, что и у описанной чуть ранее CP866 — каждый символ текста кодируется одним единственным байтом. На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье. Среди особенностей кодировки KOI8-R можно отметить то, что кириллические буквы в ее таблице идут не в алфавитном порядке, как это сделали в CP866. Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).
На скриншоте показана вторая половина таблицы KOI8-R, т.к. первая половина полностью соответствует базовой Аски, которая показана на первом скриншоте в этой статье. Среди особенностей кодировки KOI8-R можно отметить то, что кириллические буквы в ее таблице идут не в алфавитном порядке, как это сделали в CP866. Если посмотрите на самый первый скриншот (базовой части, которая входит во все расширенные кодировки), то заметите, что в KOI8-R русские буквы расположены в тех же ячейках таблицы, что и созвучные им буквы латинского алфавита из первой части таблицы. Это было сделано для удобства перехода с русских символов на латинские путем отбрасывания всего одного бита (два в седьмой степени или 128).Windows 1251 — современная версия ASCII и почему вылезают кракозябры
Дальнейшее развитие кодировок текста было связано с тем, что набирали популярность графические операционные системы и необходимость использования псевдографики в них со временем пропала. В результате возникла целая группа, которая по своей сути по-прежнему являлись расширенными версиями Аски (один символ текста кодируется всего одним байтом информации), но уже без использования символов псевдографики. Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251. Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией. Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251.
Они относились к так называемым ANSI кодировкам, которые были разработаны американским институтом стандартизации. В просторечии еще использовалось название кириллица для варианта с поддержкой русского языка. Примером такой может служить Windows 1251. Она выгодно отличалась от используемых ранее CP866 и KOI8-R тем, что место символов псевдографики в ней заняли недостающие символы русской типографики (окромя знака ударения), а также символы, используемые в близких к русскому славянских языках (украинскому, белорусскому и т.д.):
Из-за такого обилия кодировок русского языка, у производителей шрифтов и производителей программного обеспечения постоянно возникала головная боль, а у нас с вам, уважаемые читатели, зачастую вылезали те самые пресловутые кракозябры, когда происходила путаница с используемой в тексте версией. Очень часто они вылезали при отправке и получении сообщений по электронной почте, что повлекло за собой создание очень сложных перекодировочных таблиц, которые, собственно, решить эту проблему в корне не смогли, и зачастую пользователи для переписки использовали транслит латинских букв, чтобы избежать пресловутых кракозябров при использовании русских кодировок подобных CP866, KOI8-R или Windows 1251. По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально. Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом. В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы проблему с появлением не читаемых текстов.
По сути, кракозябры, вылазящие вместо русского текста, были результатом некорректного использования кодировки данного языка, которая не соответствовала той, в которой было закодировано текстовое сообщение изначально. Допустим, если символы, закодированные с помощью CP866, попробовать отобразить, используя кодовую таблицу Windows 1251, то эти самые кракозябры (бессмысленный набор знаков) и вылезут, полностью заменив собой текст сообщения.
Аналогичная ситуация очень часто возникает при создании и настройке сайтов, форумов или блогов, когда текст с русскими символами по ошибке сохраняется не в той кодировке, которая используется на сайте по умолчанию, или же не в том текстовом редакторе, который добавляет в код отсебятину не видимую невооруженным глазом. В конце концов такая ситуация с множеством кодировок и постоянно вылезающими кракозябрами многим надоела, появились предпосылки к созданию новой универсальной вариации, которая бы заменила собой все существующие и решила бы проблему с появлением не читаемых текстов. Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.
Кроме этого существовала проблема языков подобных китайскому, где символов языка было гораздо больше, чем 256.Юникод (Unicode) — универсальные кодировки UTF 8, 16 и 32
Эти тысячи знаков языковой группы юго-восточной Азии никак невозможно было описать в одном байте информации, который выделялся для кодирования символов в расширенных версиях ASCII. В результате был создан консорциум под названием Юникод (Unicode — Unicode Consortium) при сотрудничестве многих лидеров IT индустрии (те, кто производит софт, кто кодирует железо, кто создает шрифты), которые были заинтересованы в появлении универсальной кодировки текста. Первой вариацией, вышедшей под эгидой консорциума Юникод, была UTF 32. Цифра в названии кодировки означает количество бит, которое используется для кодирования одного символа. 32 бита составляют 4 байта информации, которые понадобятся для кодирования одного единственного знака в новой универсальной кодировке UTF. В результате чего один и тот же файл с текстом, закодированный в расширенной версии ASCII и в UTF-32, в последнем случае будет иметь размер (весить) в четыре раза больше. Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом). Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет-трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить. В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит. В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов».
Это плохо, но зато теперь у нас появилась возможность закодировать с помощью ЮТФ число знаков, равное двум в тридцать второй степени (миллиарды символов, которые покроют любое реально необходимое значение с колоссальным запасом). Но многим странам с языками европейской группы такое огромное количество знаков использовать в кодировке вовсе и не было необходимости, однако при задействовании UTF-32 они ни за что ни про что получали четырехкратное увеличение веса текстовых документов, а в результате и увеличение объема интернет-трафика и объема хранимых данных. Это много, и такое расточительство себе никто не мог позволить. В результате развития Юникода появилась UTF-16, которая получилась настолько удачной, что была принята по умолчанию как базовое пространство для всех символов, которые у нас используются. Она использует два байта для кодирования одного знака. Давайте посмотрим, как это дело выглядит. В операционной системе Windows вы можете пройти по пути «Пуск» — «Программы» — «Стандартные» — «Служебные» — «Таблица символов». В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста. Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16).
В результате откроется таблица с векторными формами всех установленных у вас в системе шрифтов. Если вы выберете в «Дополнительных параметрах» набор знаков Юникод, сможете увидеть для каждого шрифта в отдельности весь ассортимент входящих в него символов. Кстати, щелкнув по любому из них, вы сможете увидеть его двухбайтовый код в формате UTF-16, состоящий из четырех шестнадцатеричных цифр:
Сколько символов можно закодировать в UTF-16 с помощью 16 бит? 65 536 (два в степени шестнадцать), и именно это число было принято за базовое пространство в Юникоде. Помимо этого существуют способы закодировать с помощью нее и около двух миллионов знаков, но ограничились расширенным пространством в миллион символов текста. Но даже эта удачная версия кодировки Юникода не принесла особого удовлетворения тем, кто писал, допустим, программы только на английском языке, ибо у них после перехода от расширенной версии ASCII к UTF-16, вес документов увеличивался в два раза (один байт на один символ в Аски и два байта на тот же самый символ в ЮТФ-16). Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт. На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. То есть, базовая часть Аски просто перешла в это детище консорциума Unicode. Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство.
Вот именно для удовлетворения всех и вся в консорциуме Unicode было решено придумать кодировку переменной длины. Ее назвали UTF-8. Несмотря на восьмерку в названии, она действительно имеет переменную длину, т.е. каждый символ текста может быть закодирован в последовательность длиной от одного до шести байт. На практике же в UTF-8 используется только диапазон от одного до четырех байт, потому что за четырьмя байтами кода ничего уже даже теоретически не возможно представить. Все латинские знаки в ней кодируются в один байт, так же как и в старой доброй ASCII. Что примечательно, в случае кодирования только латиницы, даже те программы, которые не понимают Юникод, все равно прочитают то, что закодировано в ЮТФ-8. То есть, базовая часть Аски просто перешла в это детище консорциума Unicode. Кириллические же знаки в UTF-8 кодируются в два байта, а, например, грузинские — в три байта. Консорциум Юникод после создания UTF 16 и 8 решил основную проблему — теперь у нас в шрифтах существует единое кодовое пространство.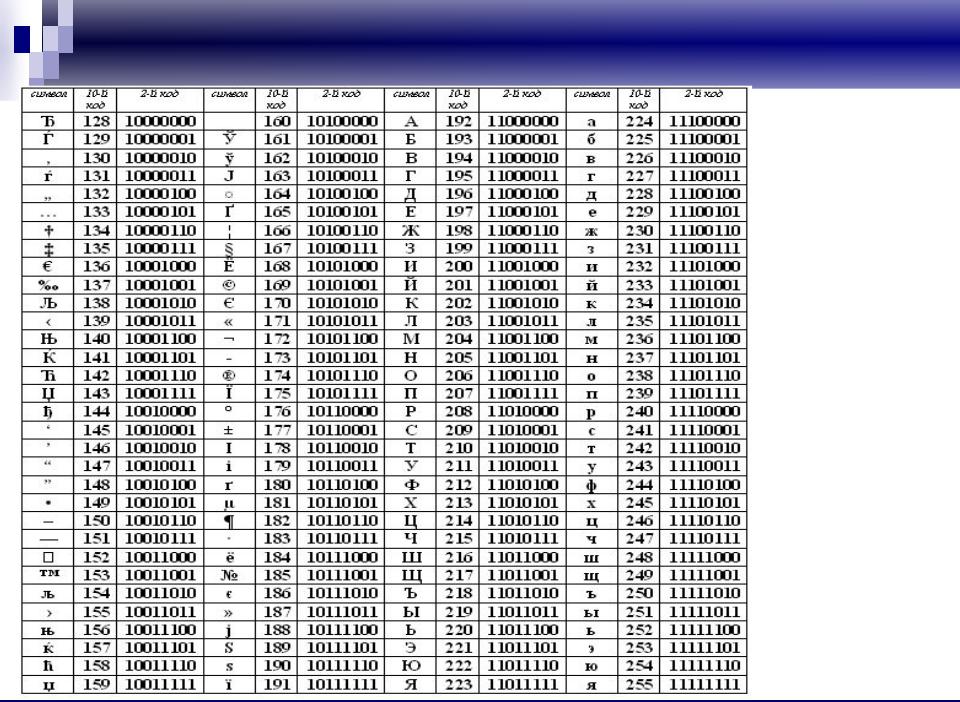 И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.
И теперь их производителям остается только исходя из своих сил и возможностей заполнять его векторными формами символов текста. В приведенной чуть выше «Таблице символов» видно, что разные шрифты поддерживают разное количество знаков. Некоторые насыщенные символами Юникода шрифты могут весить очень прилично. Но зато теперь они отличаются не тем, что они созданы для разных кодировок, а тем, что производитель шрифта заполнил или не заполнил единое кодовое пространство теми или иными векторными формами до конца.Кракозябры вместо русских букв — как исправить
Давайте теперь посмотрим, как появляются вместо текста кракозябры или, другими словами, как выбирается правильная кодировка для русского текста. Собственно, она задается в той программе, в которой вы создаете или редактируете этот самый текст, или же код с использованием текстовых фрагментов. Для редактирования и создания текстовых файлов лично я использую очень хороший, на мой взгляд, Html и PHP редактор Notepad++. Впрочем, он может подсвечивать синтаксис еще доброй сотни языков программирования и разметки, а также имеет возможность расширения с помощью плагинов. Читайте подробный обзор этой замечательной программы по приведенной ссылке. В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM? Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов. В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код.
Читайте подробный обзор этой замечательной программы по приведенной ссылке. В верхнем меню Notepad++ есть пункт «Кодировки», где у вас будет возможность преобразовать уже имеющийся вариант в тот, который используется на вашем сайте по умолчанию:
В случае сайта на Joomla 1.5 и выше, а также в случае блога на WordPress следует во избежании появления кракозябров выбирать вариант UTF 8 без BOM. А что такое приставка BOM? Дело в том, что когда разрабатывали кодировку ЮТФ-16, зачем-то решили прикрутить к ней такую вещь, как возможность записывать код символа, как в прямой последовательности (например, 0A15), так и в обратной (150A). А для того, чтобы программы понимали, в какой именно последовательности читать коды, и был придуман BOM (Byte Order Mark или, другими словами, сигнатура), которая выражалась в добавлении трех дополнительных байтов в самое начало документов. В кодировке UTF-8 никаких BOM предусмотрено в консорциуме Юникод не было и поэтому добавление сигнатуры (этих самых пресловутых дополнительных трех байтов в начало документа) некоторым программам просто-напросто мешает читать код.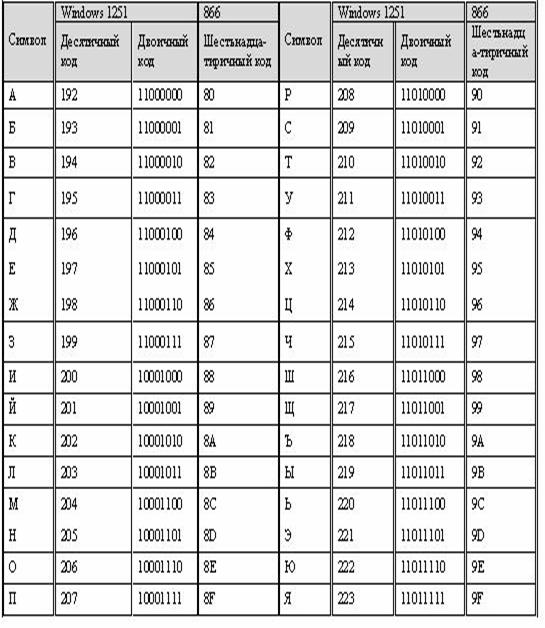 Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров. Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры. Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств. В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод.
Поэтому мы всегда при сохранении файлов в ЮТФ должны выбирать вариант без BOM (без сигнатуры). Таким образом, вы заранее обезопасите себя от вылезания кракозябров. Что примечательно, некоторые программы в Windows не умеют этого делать (не умеют сохранять текст в ЮТФ-8 без BOM), например, все тот же пресловутый Блокнот Windows. Он сохраняет документ в UTF-8, но все равно добавляет в его начало сигнатуру (три дополнительных байта). Причем эти байты будут всегда одни и те же — читать код в прямой последовательности. Но на серверах из-за этой мелочи может возникнуть проблема — вылезут кракозябры. Поэтому ни в коем случае не пользуйтесь обычным блокнотом Windows для редактирования документов вашего сайта, если не хотите появления кракозябров. Лучшим и наиболее простым вариантом я считаю уже упомянутый редактор Notepad++, который практически не имеет недостатков и состоит из одних лишь достоинств. В Notepad ++ при выборе кодировки у вас будет возможность преобразовать текст в кодировку UCS-2, которая по своей сути очень близка к стандарту Юникод. Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация? Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка. После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название: Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы. Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.
Также в Нотепаде можно будет закодировать текст в ANSI, т.е. применительно к русскому языку это будет уже описанная нами чуть выше Windows 1251. Откуда берется эта информация? Она прописана в реестре вашей операционной системы Windows — какую кодировку выбирать в случае ANSI, какую выбирать в случае OEM (для русского языка это будет CP866). Если вы установите на своем компьютере другой язык по умолчанию, то и эти кодировки будут заменены на аналогичные из разряда ANSI или OEM для того самого языка. После того, как вы в Notepad++ сохраните документ в нужной вам кодировке или же откроете документ с сайта для редактирования, то в правом нижнем углу редактора сможете увидеть ее название: Чтобы избежать кракозябров, кроме описанных выше действий, будет полезным прописать в его шапке исходного кода всех страниц сайта информацию об этой самой кодировке, чтобы на сервере или локальном хосте не возникло путаницы. Вообще, во всех языках гипертекстовой разметки кроме Html используется специальное объявление xml, в котором указывается кодировка текста.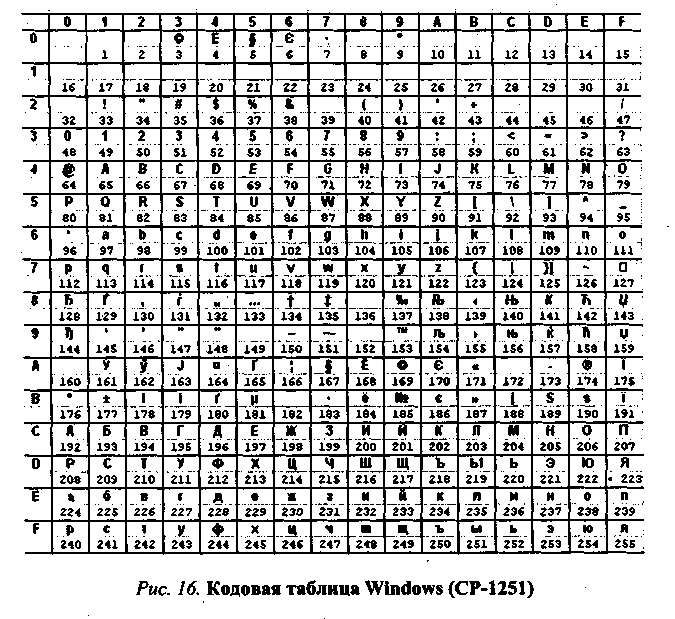
<?xml version="1.0" encoding="windows-1251"?>
<head>
...
<meta charset="utf-8">
...
</head>
 Ссылка на первоисточник: Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрами
Ссылка на первоисточник: Кодировка текста ASCII (Windows 1251, CP866, KOI8-R) и Юникод (UTF 8, 16, 32) — как исправить проблему с кракозябрамиpowershell — Преобразование исходников в UTF-8 без спецификации
Как указывает в комментарии Ансгар Вичерс, проблема в том, что Windows PowerShell при отсутствии спецификации по умолчанию файлы интерпретируются как «ANSI» -кодированные , т. е. кодировка, подразумеваемая региональным стандартом устаревшей системы (кодовая страница ANSI), как это отражено в .NET Framework (но не .NET Core ) в [System.Text.Encoding]::Default.
Учитывая, что, судя по вашим последующим комментариям, файлы без спецификации среди ваших входных файлов представляют собой смесь файлов в кодировке Windows-1251 и UTF-8 , вы необходимо изучить их content , чтобы определить их конкретную кодировку:
Прочтите каждый файл с помощью
-Encoding Utf8и проверьте, содержит ли полученная строка кодировку Unicode ЗАМЕНА ХАРАКТЕРА (U+FFFD). Если это так, то подразумевается, что файл не UTF-8, потому что этот специальный символ используется для обозначения того, что обнаружены последовательности байтов, недопустимые в UTF-8.
Если это так, то подразумевается, что файл не UTF-8, потому что этот специальный символ используется для обозначения того, что обнаружены последовательности байтов, недопустимые в UTF-8.Если файл недопустим в кодировке UTF-8, просто прочитайте файл еще раз без указания
-Encoding, что заставит Windows PowerShell интерпретировать файл как файл в кодировке Windows-1251, учитывая, что это кодировка (кодовая страница) подразумевается вашей системной локалью.
$MyPath = "D:\my projects\etc"
Get-ChildItem $MyPath\* -Include *.h, *.cpp, *.c | Foreach-Object {
# Note:
# * the use of -Encoding Utf8 to first try to read the file as UTF-8.
# * the use of -Raw to read the entire file as a *single string*.
$content = Get-Content -Raw -Encoding Utf8 $_.FullName
# If the replacement char. is found in the content, the implication
# is that the file is NOT UTF-8, so read it again *without -Encoding*,
# which interprets the files as "ANSI" encoded (Windows-1251, in your case).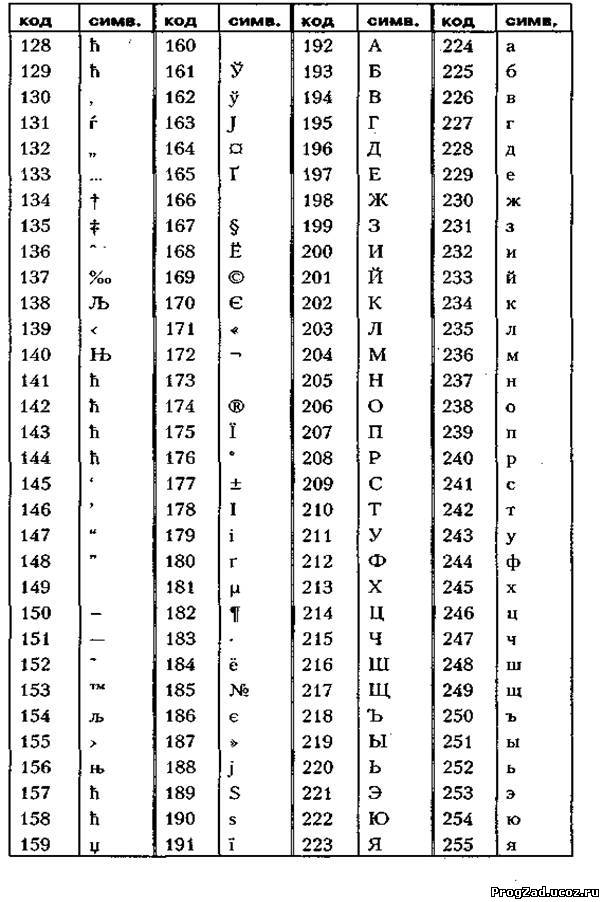 if ($content.Contains([char] 0xfffd)) {
$content = Get-Content -Raw $_.FullName
}
# Note the use of WriteAllText() in lieu of WriteAllLines()
# and that no explicit encoding object is passed, given that
# .NET *defaults* to BOM-less UTF-8.
# CAVEAT: There's a slight risk of data loss if writing back to the input
# file is interrupted.
[System.IO.File]::WriteAllText($_.FullName, $content)
}
if ($content.Contains([char] 0xfffd)) {
$content = Get-Content -Raw $_.FullName
}
# Note the use of WriteAllText() in lieu of WriteAllLines()
# and that no explicit encoding object is passed, given that
# .NET *defaults* to BOM-less UTF-8.
# CAVEAT: There's a slight risk of data loss if writing back to the input
# file is interrupted.
[System.IO.File]::WriteAllText($_.FullName, $content)
}
более быстрая альтернатива — использовать [IO.File]::ReadAllText() с объектом кодировки UTF-8, который выдает исключение при обнаружении байтов недопустимого как-UTF-8 (синтаксис PSv5 + ) :
$utf8EncodingThatThrows = [Text.UTF8Encoding]::new($false, $true)
# ...
try {
$content = [IO.File]::ReadAllText($_.FullName, $utf8EncodingThatThrows)
} catch [Text.DecoderFallbackException] {
$content = [IO.File]::ReadAllText($_.FullName, [Text.Encoding]::Default)
}
# . ..
..
Адаптация вышеуказанных решений к PowerShell Core / .NET Core:
PowerShell Core по умолчанию использует (без спецификации) UTF-8, поэтому простой пропуск
-Encodingне работает для чтения файлов в кодировке ANSI.Точно так же
[System.Text.Encoding]::Defaultнеизменно сообщает UTF-8 в .NET Core.
Следовательно, необходимо вручную определить кодовую страницу ANSI активного языкового стандарта системы и получить соответствующий объект кодировки :
$ansiEncoding = [Text.Encoding]::GetEncoding(
[int] (Get-ItemPropertyValue HKLM:\SYSTEM\CurrentControlSet\Control\Nls\CodePage ACP)
)
Затем вам нужно явно передать эту кодировку в Get-Content -Encoding (Get-Content -Raw -Encoding $ansiEncoding $_.FullName) или в методы .NET ([IO.File]::ReadAllText($_.FullName, $ansiEncoding)).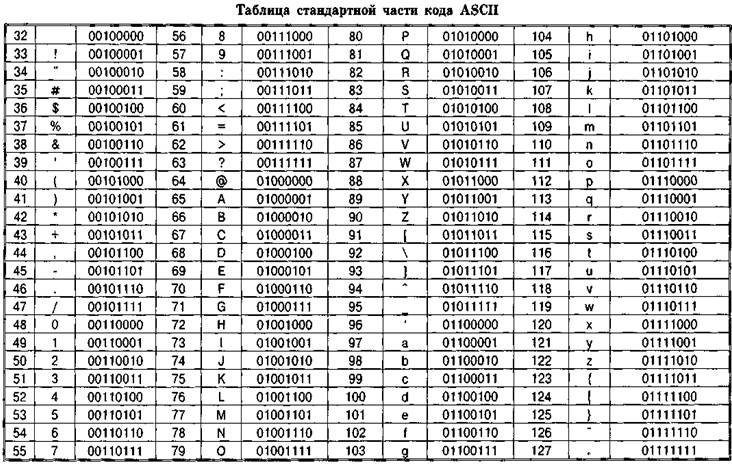
Исходная форма ответа: для входных файлов, которые уже все закодированы в UTF-8:
Следовательно, если некоторые из ваших файлов в кодировке UTF-8 (уже) не содержат спецификации, вы должны явно указать Get-Content рассматривать их как UTF-8 с использованием -Encoding Utf8 — в противном случае они будут неправильно интерпретированы, если содержат символы вне 7-битного диапазона ASCII:
$MyPath = "D:\my projects\etc"
Get-ChildItem $MyPath\* -Include *.h, *.cpp, *.c | Foreach-Object {
# Note:
# * the use of -Encoding Utf8 to ensure the correct interpretation of the input file
# * the use of -Raw to read the entire file as a *single string*.
$content = Get-Content -Raw -Encoding Utf8 $_.FullName
# Note the use of WriteAllText() in lieu of WriteAllLines()
# and that no explicit encoding object is passed, given that
# .NET *defaults* to BOM-less UTF-8.
# CAVEAT: There's a slight risk of data loss if writing back to the input
# file is interrupted.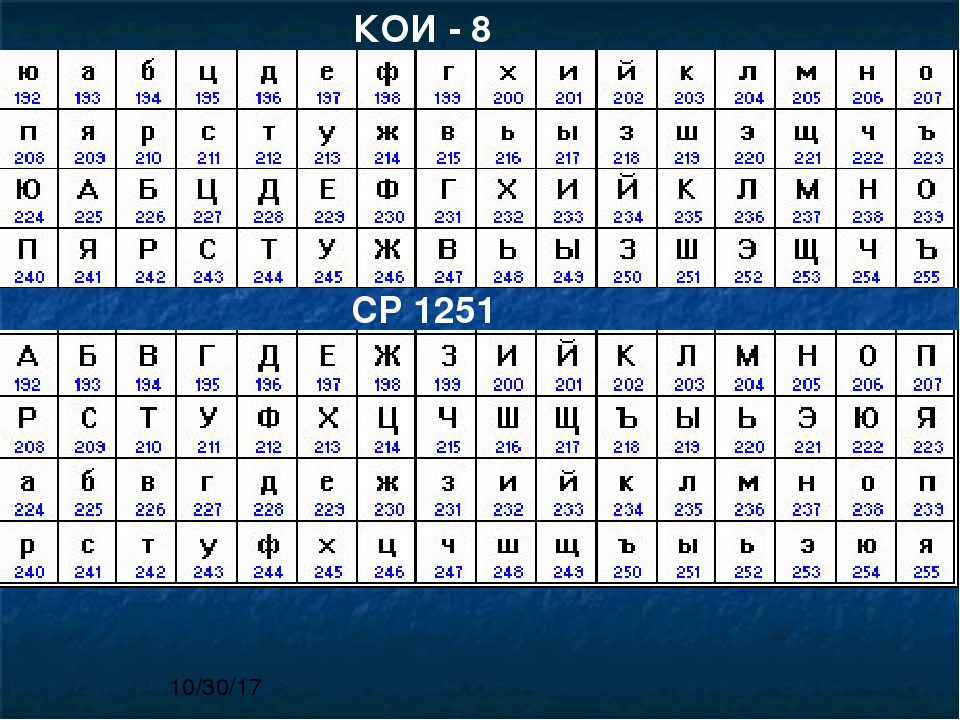 [System.IO.File]::WriteAllText($_.FullName, $content)
}
[System.IO.File]::WriteAllText($_.FullName, $content)
}
Примечание. Файлы UTF-8 без спецификаций не нуждаются в переписывании в вашем сценарии, но это неопасно и упрощает код; альтернативой будет проверить, являются ли первые 3 байта каждого файла спецификацией UTF-8 , и пропустить такой файл: $hasUtf8Bom = "$(Get-Content -Encoding Byte -First 3 $_.FullName)" -eq '239 187 191' (Windows PowerShell) или $hasUtf8Bom = "$(Get-Content -AsByteStream -First 3 $_.FullName)" -eq '239 187 191' (PowerShell Core).
В стороне: если есть входные файлы с кодировкой, отличной от UTF8 (например, UTF-16), решение по-прежнему работает , пока эти файлы имеют спецификацию , потому что PowerShell (тихо ) дает приоритет спецификации над кодировкой, указанной через -Encoding .
Обратите внимание, что использование -Raw / WriteAllText() для чтения / записи файлов целиком (одна строка) не только немного ускоряет обработку, но и гарантирует, что следующие характеристики каждого входной файл сохранен :
- конкретный стиль новой строки (CRLF (Windows) против LF-only (Unix))
- есть ли в последней строке завершающий символ новой строки.

Напротив, отказ от использования -Raw (построчное чтение) и использование .WriteAllLines() не сохраняет эти характеристики: вы неизменно получаете соответствующие платформе символы новой строки (в Windows PowerShell , всегда CRLF), и вы всегда получаете завершающую новую строку.
Обратите внимание, что многоплатформенная версия Powershell Core разумно по умолчанию использует UTF-8 при чтении файла без спецификации. и также по умолчанию создает файлы UTF-8 без спецификации — создание файла UTF-8 с BOM требует явного согласия с {{ X0 } } .
Поэтому решение PowerShell Core намного проще :
# PowerShell Core only.
$MyPath = "D:\my projects\etc"
Get-ChildItem $MyPath\* -Include *.h, *.cpp, *.c | Foreach-Object {
# * Read the file at hand (UTF8 files both with and without BOM are
# read correctly). # * Simply rewrite it with the *default* encoding, which in
# PowerShell Core is BOM-less UTF-8.
# Note the (...) around the Get-Content call, which is necessary in order
# to write back to the *same* file in the same pipeline.
# CAVEAT: There's a slight risk of data loss if writing back to the input
# file is interrupted.
(Get-Content -Raw $_.FullName) | Set-Content -NoNewline $_.FullName
}
# * Simply rewrite it with the *default* encoding, which in
# PowerShell Core is BOM-less UTF-8.
# Note the (...) around the Get-Content call, which is necessary in order
# to write back to the *same* file in the same pipeline.
# CAVEAT: There's a slight risk of data loss if writing back to the input
# file is interrupted.
(Get-Content -Raw $_.FullName) | Set-Content -NoNewline $_.FullName
}
Более быстрое решение на основе .NET
Вышеупомянутые решения работают, но Get-Content и Set-Content относительно медленные , поэтому использование типов .NET для чтения и перезаписи файлов будет работать лучше.
Как и выше, в следующем решении явно не должна быть указана кодировка (даже в Windows PowerShell ), потому что сама .NET похвально по умолчанию использует UTF без спецификации. -8 с момента его создания (при этом все еще распознается спецификация UTF-8 если присутствует):
$MyPath = "D:\my projects\etc"
Get-ChildItem $MyPath\* -Include *.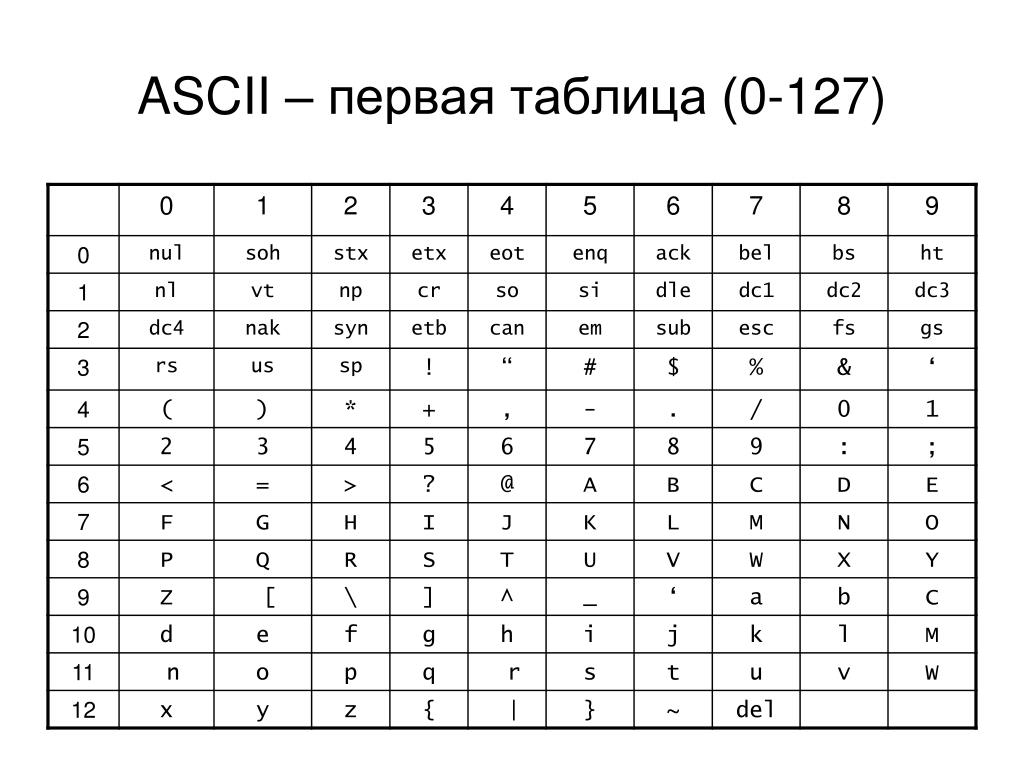 h, *.cpp, *.c | Foreach-Object {
# CAVEAT: There's a slight risk of data loss if writing back to the input
# file is interrupted.
[System.IO.File]::WriteAllText(
$_.FullName,
[System.IO.File]::ReadAllText($_.FullName)
)
}
h, *.cpp, *.c | Foreach-Object {
# CAVEAT: There's a slight risk of data loss if writing back to the input
# file is interrupted.
[System.IO.File]::WriteAllText(
$_.FullName,
[System.IO.File]::ReadAllText($_.FullName)
)
}
1
mklement0 6 Фев 2019 в 10:51
HowTo: Check and Change File Encoding In Linux
The Linux administrators that work with web hosting know how is it important to keep correct character encoding of the html documents.
From the following article you’ll learn how to check a file’s encoding from the command-line in Linux.
You will also find the best solution to convert text files between different charsets.
I’ll also show the most common examples of how to convert a file’s encoding between CP1251 (Windows-1251, Cyrillic), UTF-8, ISO-8859-1 and ASCII charsets.
Cool Tip: Want see your native language in the Linux terminal? Simply change locale! Read more →
Check a File’s Encoding
Use the following command to check what encoding is used in a file:
$ file -bi [filename]
| Option | Description |
|---|---|
-b, --brief | Don’t print filename (brief mode) |
-i, --mime | Print filetype and encoding |
Check the encoding of the file in.txt:
$ file -bi in.txt text/plain; charset=utf-8
Change a File’s Encoding
Use the following command to change the encoding of a file:
$ iconv -f [encoding] -t [encoding] -o [newfilename] [filename]
| Option | Description |
|---|---|
-f, --from-code | Convert a file’s encoding from charset |
-t, --to-code | Convert a file’s encoding to charset |
-o, --output | Specify output file (instead of stdout) |
Change a file’s encoding from CP1251 (Windows-1251, Cyrillic) charset to UTF-8:
$ iconv -f cp1251 -t utf-8 in.txt
Change a file’s encoding from ISO-8859-1 charset to and save it to out.txt:
$ iconv -f iso-8859-1 -t utf-8 -o out.txt in.txt
Change a file’s encoding from ASCII to UTF-8:
$ iconv -f utf-8 -t ascii -o out.txt in.txt
Change a file’s encoding from UTF-8 charset to ASCII:
Illegal input sequence at position: As UTF-8 can contain characters that can’t be encoded with ASCII, the iconv will generate the error message “illegal input sequence at position” unless you tell it to strip all non-ASCII characters using the -c option.
$ iconv -c -f utf-8 -t ascii -o out.txt in.txt
| Option | Description |
|---|---|
-c | Omit invalid characters from the output |
You can lose characters: Note that if you use the iconv with the -c option, nonconvertible characters will be lost.
This concerns in particular Windows machines with Cyrillic.
You have copied some file from Windows to Linux, but when you open it in Linux, you see “Êàêèå-òî êðàêîçÿáðû” – WTF!?
Don’t panic – such strings can be easily converted from CP1251 (Windows-1251, Cyrillic) charset to UTF-8 with:
$ echo "Êàêèå-òî êðàêîçÿáðû" | iconv -t latin1 | iconv -f cp1251 -t utf-8 Какие-то кракозябры
List All Charsets
List all the known charsets in your Linux system:
$ iconv -l
| Option | Description |
|---|---|
-l, --list | List known charsets |
Таблица кодов символов Windows-1251
Windows-1251 — набор символов и кодировка, являющаяся стандартной 8-битной кодировкой для всех русских версий Microsoft Windows. Данная кодировка пользуется довольно большой популярностью в восточно-европейских странах.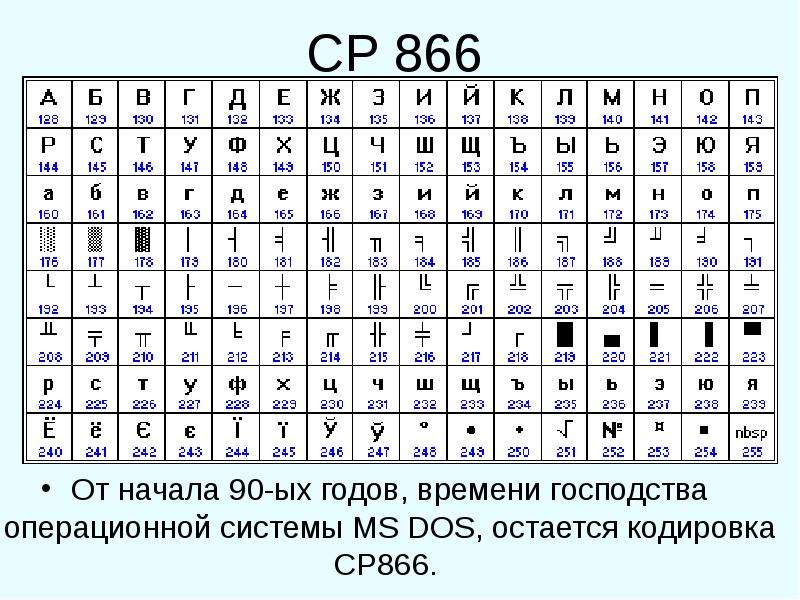 Windows-1251 выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в традиционной русской типографике для обычного текста (отсутствует только знак ударения). Кириллические символы идут в алфавитном порядке.
Windows-1251 выгодно отличается от других 8-битных кириллических кодировок (таких как CP866, KOI8-R и ISO 8859-5) наличием практически всех символов, использующихся в традиционной русской типографике для обычного текста (отсутствует только знак ударения). Кириллические символы идут в алфавитном порядке.
Windows-1251 также содержит все символы для близких к русскому языку языков: белорусского, украинского, сербского, македонского и болгарского.
На практике этого оказалось достаточно, чтобы кодировка Windows-1251 закрепилась в интернете вплоть до распространения UTF-8.
| Dec | Hex | Символ | Dec | Hex | Символ | |
|---|---|---|---|---|---|---|
| 000 | 00 | NOP | 128 | 80 | Ђ | |
| 001 | 01 | SOH | 129 | 81 | Ѓ | |
| 002 | 02 | STX | 130 | 82 | ‚ | |
| 003 | 03 | ETX | 131 | 83 | ѓ | |
| 004 | 04 | EOT | 132 | 84 | „ | |
| 005 | 05 | ENQ | 133 | 85 | … | |
| 006 | 06 | ACK | 134 | 86 | † | |
| 007 | 07 | BEL | 135 | 87 | ‡ | |
| 008 | 08 | BS | 136 | 88 | € | |
| 009 | 09 | TAB | 137 | 89 | ‰ | |
| 010 | 0A | LF | 138 | 8A | Љ | |
| 011 | 0B | VT | 139 | 8B | ‹ | |
| 012 | 0C | FF | 140 | 8C | Њ | |
| 013 | 0D | CR | 141 | 8D | Ќ | |
| 014 | 0E | SO | 142 | 8E | Ћ | |
| 015 | 0F | SI | 143 | 8F | Џ | |
| 016 | 10 | DLE | 144 | 90 | ђ | |
| 017 | 11 | DC1 | 145 | 91 | ‘ | |
| 018 | 12 | DC2 | 146 | 92 | ’ | |
| 019 | 13 | DC3 | 147 | 93 | “ | |
| 020 | 14 | DC4 | 148 | 94 | ” | |
| 021 | 15 | NAK | 149 | 95 | • | |
| 022 | 16 | SYN | 150 | 96 | – | |
| 023 | 17 | ETB | 151 | 97 | — | |
| 024 | 18 | CAN | 152 | 98 | ||
| 025 | 19 | EM | 153 | 99 | ™ | |
| 026 | 1A | SUB | 154 | 9A | љ | |
| 027 | 1B | ESC | 155 | 9B | › | |
| 028 | 1C | FS | 156 | 9C | њ | |
| 029 | 1D | GS | 157 | 9D | ќ | |
| 030 | 1E | RS | 158 | 9E | ћ | |
| 031 | 1F | US | 159 | 9F | џ | |
| 032 | 20 | SP | 160 | A0 | ||
| 033 | 21 | ! | 161 | A1 | Ў | |
| 034 | 22 | « | 162 | A2 | ў | |
| 035 | 23 | # | 163 | A3 | Ћ | |
| 036 | 24 | $ | 164 | A4 | ¤ | |
| 037 | 25 | % | 165 | A5 | Ґ | |
| 038 | 26 | & | 166 | A6 | ¦ | |
| 039 | 27 | ‘ | 167 | A7 | § | |
| 040 | 28 | ( | 168 | A8 | Ё | |
| 041 | 29 | ) | 169 | A9 | © | |
| 042 | 2A | * | 170 | AA | Є | |
| 043 | 2B | + | 171 | AB | « | |
| 044 | 2C | , | 172 | AC | ¬ | |
| 045 | 2D | — | 173 | AD | | |
| 046 | 2E | .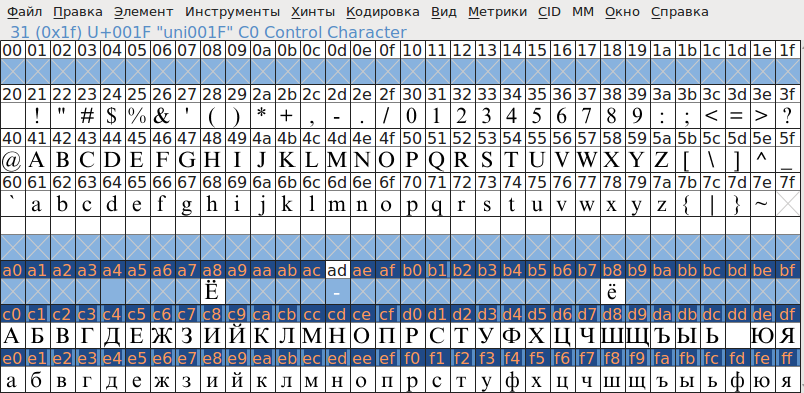 | 174 | AE | ® | |
| 047 | 2F | / | 175 | AF | Ї | |
| 048 | 30 | 0 | 176 | B0 | ° | |
| 049 | 31 | 1 | 177 | B1 | ± | |
| 050 | 32 | 2 | 178 | B2 | І | |
| 051 | 33 | 3 | 179 | B3 | і | |
| 052 | 34 | 4 | 180 | B4 | ґ | |
| 053 | 35 | 5 | 181 | B5 | µ | |
| 054 | 36 | 6 | 182 | B6 | ¶ | |
| 055 | 37 | 7 | 183 | B7 | · | |
| 056 | 38 | 8 | 184 | B8 | ё | |
| 057 | 39 | 9 | 185 | B9 | № | |
| 058 | 3A | : | 186 | BA | є | |
| 059 | 3B | ; | 187 | BB | » | |
| 060 | 3C | < | 188 | BC | ј | |
| 061 | 3D | = | 189 | BD | Ѕ | |
| 062 | 3E | > | 190 | BE | ѕ | |
| 063 | 3F | ? | 191 | BF | ї | |
| 064 | 40 | @ | 192 | C0 | А | |
| 065 | 41 | A | 193 | C1 | Б | |
| 066 | 42 | B | 194 | C2 | В | |
| 067 | 43 | C | 195 | C3 | Г | |
| 068 | 44 | D | 196 | C4 | Д | |
| 069 | 45 | E | 197 | C5 | Е | |
| 070 | 46 | F | 198 | C6 | Ж | |
| 071 | 47 | G | 199 | C7 | З | |
| 072 | 48 | H | 200 | C8 | И | |
| 073 | 49 | I | 201 | C9 | Й | |
| 074 | 4A | J | 202 | CA | К | |
| 075 | 4B | K | 203 | CB | Л | |
| 076 | 4C | L | 204 | CC | М | |
| 077 | 4D | M | 205 | CD | Н | |
| 078 | 4E | N | 206 | CE | О | |
| 079 | 4F | O | 207 | CF | П | |
| 080 | 50 | P | 208 | D0 | Р | |
| 081 | 51 | Q | 209 | D1 | С | |
| 082 | 52 | R | 210 | D2 | Т | |
| 083 | 53 | S | 211 | D3 | У | |
| 084 | 54 | T | 212 | D4 | Ф | |
| 085 | 55 | U | 213 | D5 | Х | |
| 086 | 56 | V | 214 | D6 | Ц | |
| 087 | 57 | W | 215 | D7 | Ч | |
| 088 | 58 | X | 216 | D8 | Ш | |
| 089 | 59 | Y | 217 | D9 | Щ | |
| 090 | 5A | Z | 218 | DA | Ъ | |
| 091 | 5B | [ | 219 | DB | Ы | |
| 092 | 5C | \ | 220 | DC | Ь | |
| 093 | 5D | ] | 221 | DD | Э | |
| 094 | 5E | ^ | 222 | DE | Ю | |
| 095 | 5F | _ | 223 | DF | Я | |
| 096 | 60 | ` | 224 | E0 | а | |
| 097 | 61 | a | 225 | E1 | б | |
| 098 | 62 | b | 226 | E2 | в | |
| 099 | 63 | c | 227 | E3 | г | |
| 100 | 64 | d | 228 | E4 | д | |
| 101 | 65 | e | 229 | E5 | е | |
| 102 | 66 | f | 230 | E6 | ж | |
| 103 | 67 | g | 231 | E7 | з | |
| 104 | 68 | h | 232 | E8 | и | |
| 105 | 69 | i | 233 | E9 | й | |
| 106 | 6A | j | 234 | EA | к | |
| 107 | 6B | k | 235 | EB | л | |
| 108 | 6C | l | 236 | EC | м | |
| 109 | 6D | m | 237 | ED | н | |
| 110 | 6E | n | 238 | EE | о | |
| 111 | 6F | o | 239 | EF | п | |
| 112 | 70 | p | 240 | F0 | р | |
| 113 | 71 | q | 241 | F1 | с | |
| 114 | 72 | r | 242 | F2 | т | |
| 115 | 73 | s | 243 | F3 | у | |
| 116 | 74 | t | 244 | F4 | ф | |
| 117 | 75 | u | 245 | F5 | х | |
| 118 | 76 | v | 246 | F6 | ц | |
| 119 | 77 | w | 247 | F7 | ч | |
| 120 | 78 | x | 248 | F8 | ш | |
| 121 | 79 | y | 249 | F9 | щ | |
| 122 | 7A | z | 250 | FA | ъ | |
| 123 | 7B | { | 251 | FB | ы | |
| 124 | 7C | | | 252 | FC | ь | |
| 125 | 7D | } | 253 | FD | э | |
| 126 | 7E | ~ | 254 | FE | ю | |
| 127 | 7F | DEL | 255 | FF | я |
Описание специальных (управляющих) символов
Первоначально управляющие символы таблицы ASCII (диапазон 00-31, плюс 127) были разработаны для того, чтобы управлять устройствами аппаратных средств, таких как телетайп, ввод данных на перфоленту и др.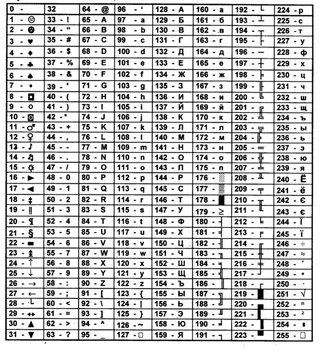
Управляющие символы (кроме горизонтальной табуляции, перевода строки и возврата каретки) не используются в HTML-документах.
| Код | Описание |
|---|---|
| NUL, 00 | Null, пустой |
| SOH, 01 | Start Of Heading, начало заголовка |
| STX, 02 | Start of TeXt, начало текста |
| ETX, 03 | End of TeXt, конец текста |
| EOT, 04 | End of Transmission, конец передачи |
| ENQ, 05 | Enquire. Прошу подтверждения |
| ACK, 06 | Acknowledgement. Подтверждаю |
| BEL, 07 | Bell, звонок |
| BS, 08 | Backspace, возврат на один символ назад |
| TAB, 09 | Tab, горизонтальная табуляция |
| LF, 0A | Line Feed, перевод строки Сейчас в большинстве языков программирования обозначается как \n |
| VT, 0B | Vertical Tab, вертикальная табуляция |
| FF, 0C | Form Feed, прогон страницы, новая страница |
| CR, 0D | Carriage Return, возврат каретки Сейчас в большинстве языков программирования обозначается как \r |
| SO, 0E | Shift Out, изменить цвет красящей ленты в печатающем устройстве |
| SI, 0F | Shift In, вернуть цвет красящей ленты в печатающем устройстве обратно |
| DLE, 10 | Data Link Escape, переключение канала на передачу данных |
| DC1, 11 DC2, 12 DC3, 13 DC4, 14 | Device Control, символы управления устройствами |
| NAK, 15 | Negative Acknowledgment, не подтверждаю |
| SYN, 16 | Synchronization. Символ синхронизации Символ синхронизации |
| ETB, 17 | End of Text Block, конец текстового блока |
| CAN, 18 | Cancel, отмена переданного ранее |
| EM, 19 | End of Medium, конец носителя данных |
| SUB, 1A | Substitute, подставить. Ставится на месте символа, значение которого было потеряно или испорчено при передаче |
| ESC, 1B | Escape Управляющая последовательность |
| FS, 1C | File Separator, разделитель файлов |
| GS, 1D | Group Separator, разделитель групп |
| RS, 1E | Record Separator, разделитель записей |
| US, 1F | Unit Separator, разделитель юнитов |
| DEL, 7F | Delete, стереть последний символ. |
Смотрите также:
URL коды символов ACSII
URL коды символов UTF-8 диапазон от U+0400 до U+04FF
HTML Кодирование URL
Таблица кодов символов кирилицы UTF-8
| Каноническое имя для java.nio API | Каноническое имя для API java.io и API java.lang | Псевдоним или псевдоним | Описание |
|---|---|---|---|
| ЦЭСУ-8 | CESU8 | CESU8 CSCESU-8 | Юникод CESU-8 |
| IBM00858 | Cp858 | cp858 858 PC-Multilingual-850 + евро cp00858 ccsid00858 | Вариант CP850 с символом евро |
| IBM437 | Cp437 | ibm437 437 ibm-437 cspc8codepage437 cp437 windows-437 | MS-DOS США, Австралия, Новая Зеландия, Южная Африка |
| IBM775 | Cp775 | ibm-775 ibm775 775 cp775 | PC Baltic |
| IBM850 | Cp850 | cp850 cspc850 многоязычный ibm850 850 ibm-850 | MS-DOS Latin-1 |
| IBM852 | Cp852 | csPCp852 ibm-852 ibm852 852 cp852 | MS-DOS Latin-2 |
| IBM855 | Cp855 | ibm855 855 IBM-855 cp855 cspcp855 | IBM Кириллица |
| IBM857 | Cp857 | ibm857 857 cp857 csIBM857 ibm-857 | IBM Турецкий |
| IBM862 | Cp862 | csIBM862 cp862 ibm862 862 cspc862latinhebrew ibm-862 | PC Еврейский |
| IBM866 | Cp866 | ibm866 866 ibm-866 csIBM866 cp866 | MS-DOS Русский |
| ISO-8859-1 | ISO8859_1 | 819 ISO8859-1 l1 ISO_8859-1: 1987 ISO_8859-1 8859_1 iso-ir-100 latin1 cp819 ISO8859_1 IBM819 ISO_8859_1 IBM-819 csISOLatin1 | ISO-8859-1, латинский алфавит No. 1 1 |
| ISO-8859-2 | ISO8859_2 | ISO8859-2 ibm912 l2 ISO_8859-2 8859_2 cp912 ISO_8859-2: 1987 iso8859_2 iso-ir-101 latin2 912 csISOLatin2 ibm-912 | Латинский алфавит № 2 |
| ISO-8859-4 | ISO8859_4 | 8859_4 латинский4 l4 cp914 ISO_8859-4: 1988 ibm914 ISO_8859-4 iso-ir-110 iso8859_4 csISOLatin4 iso8859-4 914 ibm-914 | Латинский алфавит № 4 |
| ISO-8859-5 | ISO8859_5 | ISO_8859-5: 1988 csISOLatinCyrillic iso-ir-144 iso8859_5 cp915 8859_5 ibm-915 ISO_8859-5 ibm915 915 кириллица ISO8859-5 | Латинский / кириллица |
| ISO-8859-7 | ISO8859_7 | греческий 8859_7 греческий8 ibm813 ISO_8859-7 iso8859_7 ELOT_928 cp813 ISO_8859-7: 1987 sun_eu_greek csISOLatinGreek iso-ir-126813 iso8859-7 ECMA-118 ibm-813 | Латинский / греческий алфавит (ISO-8859-7: 2003) |
| ISO-8859-9 | ISO8859_9 | ibm-920 ISO_8859-9 8859_9 ISO_8859-9: 1989 ibm920 latin5 l5 iso8859_9 cp920 920 iso-ir-148 ISO8859-9 csISOLatin5 | Латинский алфавит No.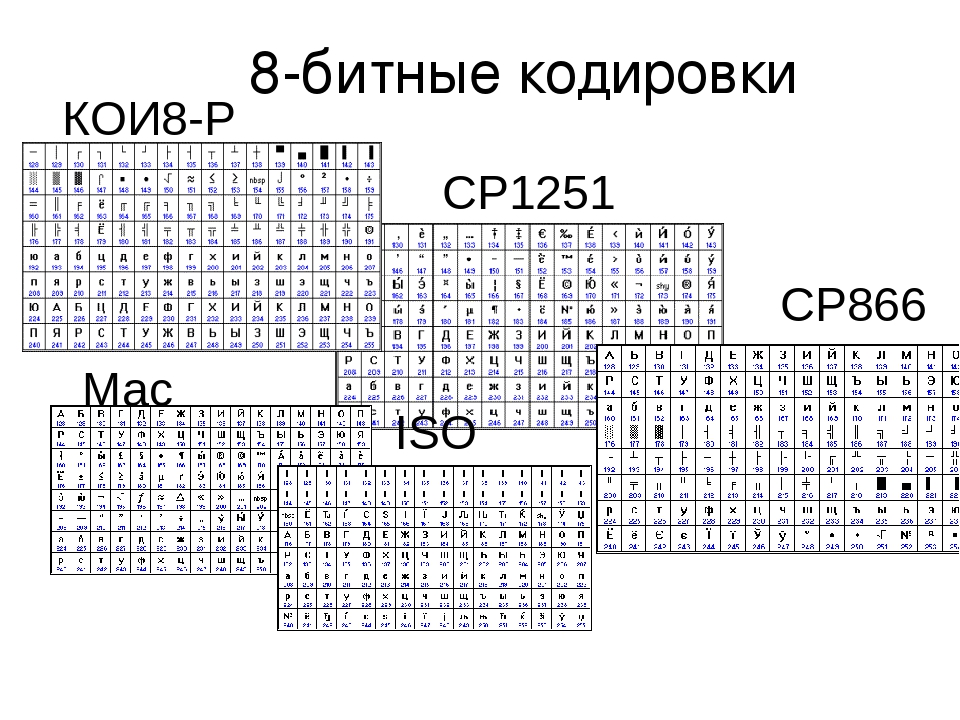 5 5 |
| ISO-8859-13 | ISO8859_13 | iso_8859-13 ISO8859-13 iso8859_13 8859_13 | Латинский алфавит № 7 |
| ISO-8859-15 | ISO8859_15 | ISO8859-15 LATIN0 ISO8859_15_FDIS ISO8859_15 cp923 8859_15 L9 ISO-8859-15 IBM923 csISOlatin9 ISO_8859-15 IBM-923 csISOlatin0 923 LATIN9 | Латинский алфавит № 9 |
| КОИ8-Р | KOI8_R | koi8_r koi8 cskoi8r | КОИ8-Р, Россия |
| КОИ8-У | КОИ8_У | koi8_u | КОИ8-У, Украинский |
| US-ASCII | ASCII | ANSI_X3.4-1968 cp367 csASCII iso-ir-6 ASCII iso_646.irv: 1983
ANSI_X3. 4-1986 ascii7 по умолчанию ISO_646.irv: 1991 ISO646-US IBM367 646 us 4-1986 ascii7 по умолчанию ISO_646.irv: 1991 ISO646-US IBM367 646 us | Американский стандартный код для обмена информацией |
| UTF-8 | UTF8 | юникод-1-1-utf-8 UTF8 | Восьмибитный формат преобразования Unicode (или UCS) |
| UTF-16 | UTF-16 | UTF_16 юникод utf16 UnicodeBig | Шестнадцатиразрядный формат преобразования Unicode (или UCS), порядок байтов идентифицируется необязательной меткой порядка байтов |
| UTF-16BE | UnicodeBig Без маркировки | X-UTF-16BE UTF_16BE ISO-10646-UCS-2 UnicodeBigUnmarked | Шестнадцатиразрядный формат преобразования Unicode (или UCS), прямой порядок байтов порядок байтов |
| UTF-16LE | UnicodeLittleUnmarked | UnicodeLittleUnmarked UTF_16LE X-UTF-16LE | Шестнадцатибитный формат преобразования Unicode (или UCS), порядок байтов с прямым порядком байтов |
| UTF-32 | UTF_32 | UTF_32 UTF32 | 32-битный формат преобразования Unicode (или UCS), порядок байтов идентифицируется необязательной меткой порядка байтов |
| UTF-32BE | UTF_32BE | X-UTF-32BE UTF_32BE | 32-битный формат преобразования Unicode (или UCS), с прямым порядком байтов заказ |
| UTF-32LE | UTF_32LE | X-UTF-32LE UTF_32LE | 32-битный формат преобразования Unicode (или UCS), прямой порядок байтов порядок байтов |
| x-UTF-32BE-BOM | UTF_32BE_BOM | UTF_32BE_BOM UTF-32BE-BOM | 32-битный формат преобразования Unicode (или UCS), с прямым порядком байтов порядок, с пометкой порядка байтов |
| x-UTF-32LE-BOM | UTF_32LE_BOM | UTF_32LE_BOM UTF-32LE-BOM | 32-битный формат преобразования Unicode (или UCS), прямой порядок байтов порядок байтов с отметкой порядка байтов |
| окна-1250 | Cp1250 | cp1250 cp5346 | Окна Восточноевропейская |
| окна-1251 | Cp1251 | cp5347 ansi-1251 cp1251 | Окна Кириллица |
| окна-1252 | Cp1252 | cp5348 cp1252 | Окна Latin-1 |
| окна-1253 | Cp1253 | cp1253 cp5349 | Окна Греческая |
| окна-1254 | Cp1254 | cp1254 cp5350 | Окна Турецкая |
| окна-1257 | Cp1257 | cp1257 cp5353 | Окна Балтика |
| Не доступен | UnicodeBig | Не доступен | Шестнадцатиразрядный формат преобразования Unicode (или UCS), прямой порядок байтов порядок байтов с отметкой порядка байтов |
| x-IBM737 | Cp737 | cp737 ibm737 737 ibm-737 | PC Греческий |
| x-IBM874 | Cp874 | ibm-874 ibm874 874 cp874 | IBM Тайский |
| x-UTF-16LE-BOM | Юникод, Литтл | Юникод, Литтл | Шестнадцатибитный формат преобразования Unicode (или UCS), порядок байтов с прямым порядком байтов, с меткой порядка байтов |
Каноническое имя для java. nio API nio API | Каноническое имя для API java.io и API java.lang | Псевдоним или псевдоним | Описание |
| Большой5 | Большой5 | csBig5 | Big5, традиционный китайский |
| Big5-HKSCS | Big5_HKSCS | big5-hkscs big5hk Big5_HKSCS big5hkscs | Big5 с расширениями Гонконга, традиционный китайский (включая редакцию 2001 г.) |
| EUC-JP | EUC_JP | csEUCPkdFmtjapanese x-euc-jp eucjis Extended_UNIX_Code_Packed_Format_for_Японский euc_jp eucjp x-eucjp | JISX 0201, 0208 и 0212, кодировка EUC, японская |
| EUC-KR | EUC_KR | ksc5601-1987 csEUCKR ksc5601_1987 ksc5601 5601 euc_kr ksc_5601 ks_c_5601-1987 euckr | KS C 5601, кодировка EUC, корейский язык |
| ГБ18030 | ГБ18030 | гб18030-2000 | Упрощенный китайский, стандарт КНР |
| ГБ 2312 | EUC_CN | GB2312 EUC-CN X-EUC-CN EUCCN EUC_CN GB2312-80 GB2312-1980 | GB2312, кодировка EUC, упрощенный китайский |
| ГБК | ГБК | CP936 окна-936 | GBK, упрощенный китайский |
| IBM-Thai | Cp838 | ibm-838 ibm838 838 cp838 | IBM Thailand расширенный SBCS |
| IBM01140 | Cp1140 | cp1140 1140 cp01140 ebcdic-us-037 + евро ccsid01140 | Вариант Cp037 с символом евро |
| IBM01141 | Cp1141 | 1141 cp1141 cp01141 ccsid01141 ebcdic-de-273 + евро | Вариант Cp273 с символом евро |
| IBM01142 | Cp1142 | 1142 cp1142 cp01142 ccsid01142 ebcdic-no-277 + евро ebcdic-dk-277 + евро | Вариант Cp277 с символом евро |
| IBM01143 | Cp1143 | 1143 cp01143 ccsid01143 cp1143 ebcdic-fi-278 + евро ebcdic-se-278 + евро | Вариант Cp278 с символом евро |
| IBM01144 | Cp1144 | cp01144 ccsid01144 ebcdic-it-280 + евро cp1144 1144 | Вариант Cp280 с символом евро |
| IBM01145 | Cp1145 | ccsid01145 ebcdic-es-284 + евро 1145 cp1145 cp01145 | Вариант CP284 с символом евро |
| IBM01146 | Cp1146 | ebcdic-gb-285 + евро 1146 cp1146 cp01146 ccsid01146 | Вариант CP285 с символом евро |
| IBM01147 | Cp1147 | cp1147 1147 cp01147 ccsid01147 ebcdic-fr-277 + евро | Вариант Cp297 с символом евро |
| IBM01148 | Cp1148 | cp1148 ebcdic-international-500 + евро 1148 cp01148 ccsid01148 | Вариант CP500 с символом евро |
| IBM01149 | Cp1149 | ebcdic-s-871 + евро 1149 cp1149 cp01149 ccsid01149 | Вариант Cp871 с символом евро |
| IBM037 | Cp037 | cp037 ibm037 ibm-037 csIBM037 ebcdic-cp-us ebcdic-cp-ca ebcdic-cp-nl ebcdic-cp-wt 037 cpibm37 cs-ebcdic-cp-wt ibm-37 cs-ebcdic-cp-us cs-ebcdic-cp-ca cs-ebcdic-cp-nl | США, Канада (двуязычный, французский), Нидерланды, Португалия, Бразилия, Австралия |
| IBM1026 | Cp1026 | cp1026 ibm-1026 1026 ibm1026 | IBM Latin-5, Турция |
| IBM1047 | Cp1047 | ibm-1047 1047 cp1047 | Набор символов Latin-1 для хостов EBCDIC |
| IBM273 | Cp273 | ibm-273 ibm273 273 cp273 | IBM Австрия, Германия |
| IBM277 | Cp277 | ibm277 277 cp277 ibm-277 | IBM Дания, Норвегия |
| IBM278 | Cp278 | cp278 278 ibm-278 ebcdic-cp-se csIBM278 ibm278 ebcdic-sv | IBM Финляндия, Швеция |
| IBM280 | Cp280 | ibm280 280 cp280 ibm-280 | IBM Италия |
| IBM284 | Cp284 | csIBM284 ibm-284 cpibm284 ibm284 284 cp284 | IBM Каталонский / Испания, испанский Латинская Америка |
| IBM285 | Cp285 | csIBM285 cp285 ebcdic-gb ibm-285 cpibm285 ibm285 285 ebcdic-cp-gb | IBM Великобритания, Ирландия |
| IBM290 | Cp290 | ibm290 290 cp290 EBCDIC-JP-кана csIBM290 ibm-290 | IBM Japanese Katakana Host Extended SBCS |
| IBM297 | Cp297 | 297 csIBM297 cp297 ibm297 ibm-297 cpibm297 ebcdic-cp-fr | IBM Франция |
| IBM420 | Cp420 | ibm420 420 cp420 csIBM420 ibm-420 ebcdic-cp-ar1 | IBM арабский |
| IBM424 | Cp424 | ebcdic-cp-he csIBM424 ibm-424 ibm424 424 cp424 | IBM Еврейский |
| IBM500 | Cp500 | ibm-500 ibm500 500 ebcdic-cp-bh ebcdic-cp-ch csIBM500 cp500 | EBCDIC 500V1 |
| IBM860 | Cp860 | ibm860 860 cp860 csIBM860 ibm-860 | MS-DOS Португальский |
| IBM861 | Cp861 | cp861 ibm861 861 ibm-861 cp-is csIBM861 | MS-DOS Исландский |
| IBM863 | Cp863 | csIBM863 ibm-863 ibm863 863 cp863 | MS-DOS Канадский французский |
| IBM864 | Cp864 | csIBM864 ibm-864 ibm864 864 cp864 | PC Арабский |
| IBM865 | Cp865 | ibm-865 csIBM865 cp865 ibm865 865 | MS-DOS Nordic |
| IBM868 | Cp868 | ibm868 868 cp868 csIBM868 ibm-868 cp-ar | MS-DOS Пакистан |
| IBM869 | Cp869 | cp869 ibm869 869 ibm-869 cp-gr csIBM869 | IBM Современный греческий |
| IBM870 | Cp870 | 870 cp870 csIBM870 ibm-870 ibm870 ebcdic-cp-roece ebcdic-cp-yu | IBM Multilingual Latin-2 |
| IBM871 | Cp871 | ibm871 871 cp871 ebcdic-cp-is csIBM871 ibm-871 | IBM Исландия |
| IBM918 | Cp918 | 918 ibm-918 ebcdic-cp-ar2 cp918 | IBM, Пакистан (урду) |
| ISO-2022-CN | ISO2022CN | csISO2022CN ISO2022CN | GB2312 и CNS11643 в форме ISO 2022 CN, упрощенной и Традиционный китайский (только преобразование в Unicode) |
| ISO-2022-JP | ISO2022JP | csjisencoding iso2022jp jis_encoding jis csISO2022JP | JIS X 0201, 0208, в форме ISO 2022, японский |
| ISO-2022-JP-2 | ISO2022JP2 | csISO2022JP2 iso2022jp2 | JIS X 0201, 0208, 0212 в форме ISO 2022, японский |
| ISO-2022-KR | ISO2022KR | csISO2022KR ISO2022KR | ISO 2022 KR, корейский |
| ISO-8859-3 | ISO8859_3 | ISO8859-3 ibm913 8859_3 l3 cp913 ISO_8859-3 iso8859_3 latin3 csISOLatin3 913 ISO_8859-3: 1988 ibm-913 iso-ir-109 | Латинский алфавит No. 3 3 |
| ISO-8859-6 | ISO8859_6 | ASMO-708 8859_6 iso8859_6 ISO_8859-6 csISOLatinArabic ibm1089 арабский ibm-1089 1089 ECMA-114 iso-ir-127 ISO_8859-6: 1987 ISO8859-6 cp1089 | Латинский / арабский алфавит |
| ISO-8859-8 | ISO8859_8 | 8859_8 ISO_8859-8 ISO_8859-8: 1988 cp916 iso-ir-138 ISO8859-8 иврит iso8859_8 ibm-916 csISOLatinHebrew 916 ibm916 | Латинский / еврейский алфавит |
| JIS_X0201 | JIS_X0201 | JIS0201 csHalfWidthKatakana X0201 JIS_X0201 | JIS X 0201 |
| JIS_X0212-1990 | JIS_X0212-1990 | JIS0212 iso-ir-159 x0212 jis_x0212-1990 csISO159JISX02121990 | JIS X 0212 |
| Shift_JIS | SJIS | shift_jis x-sjis sjis shift-jis ms_kanji csShiftJIS | Shift-JIS, японский |
| ТИС-620 | TIS620 | тис620 тис620. 2533 2533 | TIS620, тайский |
| окна-1255 | Cp1255 | cp1255 | Windows Иврит |
| окна-1256 | Cp1256 | cp1256 | Windows Арабский |
| окна-1258 | Cp1258 | cp1258 | Windows Вьетнамский |
| окна-31j | MS932 | MS932 Windows-932 CSWindows31J | Окна японские |
| x-Big5-Solaris | Big5_Solaris | Big5_Solaris | Big5 с семью дополнительными отображениями идеограммы Ханзи для Solaris zh_TW.BIG5 язык |
| x-euc-jp-linux | EUC_JP_LINUX | euc_jp_linux euc-jp-linux | JISX 0201, 0208, кодировка EUC, японская |
| x-EUC-TW | EUC_TW | euctw cns11643 EUC-TW euc_tw | CNS11643 (плоскость 1-7,15), кодировка EUC, традиционный китайский |
| x-eucJP-Open | EUC_JP_Solaris | eucJP-open EUC_JP_Solaris | JISX 0201, 0208, 0212, кодировка EUC, японская |
| х-IBM1006 | Cp1006 | ibm1006 ibm-1006 1006 cp1006 | IBM AIX Пакистан (урду) |
| x-IBM1025 | Cp1025 | ibm-1025 1025 cp1025 ibm1025 | IBM Multilingual Cyrillic: Болгария, Босния, Герцеговина, Македония (FYR) |
| x-IBM1046 | Cp1046 | ibm1046 ibm-1046 1046 cp1046 | IBM Arabic — Windows |
| х-IBM1097 | Cp1097 | ibm1097 ibm-1097 1097 cp1097 | IBM Иран (фарси) / персидский |
| x-IBM1098 | Cp1098 | ibm-1098 1098 cp1098 ibm1098 | IBM Иран (фарси) / персидский (ПК) |
| х-IBM1112 | Cp1112 | ibm1112 ibm-1112 1112 cp1112 | IBM Латвия, Литва |
| х-IBM1122 | Cp1122 | cp1122 ibm1122 ibm-1122 1122 | IBM Эстония |
| x-IBM1123 | Cp1123 | ibm1123 ibm-1123 1123 cp1123 | IBM Украина |
| x-IBM1124 | Cp1124 | ibm-1124 1124 cp1124 ibm1124 | IBM AIX Украина |
| x-IBM1166 | Cp1166 | cp1166 ibm1166 ibm-1166 1166 | IBM Cyrillic Multilingual с евро для Казахстана |
| х-IBM1364 | Cp1364 | cp1364 ibm1364 ibm-1364 1364 | IBM EBCDIC KS X 1005-1 |
| х-IBM1381 | Cp1381 | cp1381 ibm-1381 1381 ibm1381 | IBM OS / 2, DOS Китайская Народная Республика (КНР) |
| x-IBM1383 | Cp 1383 | ibm1383 ibm-1383 1383 cp1383 | IBM AIX Китайская Народная Республика (КНР) |
| х-IBM300 | CP300 | cp300 ibm300 300 ibm-300 | IBM Японский двухбайтовый латинский хост |
| x-IBM33722 | Cp33722 | 33722 ibm-33722 cp33722 ibm33722 ibm-5050 ibm-33722_vascii_vpua | IBM-eucJP — японский (расширенный набор 5050) |
| x-IBM833 | Cp833 | ibm833 cp833 ibm-833 | IBM Korean Host Extended SBCS |
| x-IBM834 | Cp834 | ibm834 834 cp834 ibm-834 | IBM EBCDIC DBCS-only Korean |
| x-IBM856 | Cp856 | ibm856 856 cp856 ibm-856 | IBM Еврейский |
| x-IBM875 | Cp875 | ibm-875 ibm875 875 cp875 | IBM Греческий |
| х-IBM921 | Cp921 | ibm921 921 ibm-921 cp921 | IBM Латвия, Литва (AIX, DOS) |
| x-IBM922 | Cp922 | ibm922 922 cp922 ibm-922 | IBM Эстония (AIX, DOS) |
| x-IBM930 | Cp930 | ibm-930 ibm930 930 cp930 | Японские катакана и кандзи смешанные с 4370 УДК, расширенный набор из 5026 |
| x-IBM933 | Cp933 | ibm933 933 cp933 ibm-933 | Корейский смешанный с 1880 УДК, расширенный набор 5029 |
| х-IBM935 | Cp935 | cp935 ibm935 935 ibm-935 | Узел на упрощенном китайском, смешанный с 1880 UDC, расширенный набор 5031 |
| x-IBM937 | Cp937 | ibm-937 ibm937 937 cp937 | Традиционный китайский хост, соединенный с 6204 UDC, расширенный набор 5033 |
| x-IBM939 | Cp939 | ibm-939 cp939 ibm939 939 | (Японские латинские кандзи), смешанные с 4370 УДК, расширенный набор 5035 |
| х-IBM942 | Cp942 | ibm-942 cp942 ibm942 942 | IBM OS / 2 Japanese, расширенный набор Cp932 |
| x-IBM942C | Cp942C | ibm942C cp942C ibm-942C 942C | Вариант Cp942 |
| x-IBM943 | Cp943 | ibm943 943 ibm-943 cp943 | IBM OS / 2 Japanese, расширенный набор Cp932 и Shift-JIS |
| x-IBM943C | Cp943C | 943C cp943C ibm943C ibm-943C | Вариант Cp943 |
| x-IBM948 | Cp948 | ibm-948 ibm948 948 cp948 | OS / 2 Китайский (Тайвань) расширенный набор 938 |
| x-IBM949 | Cp949 | ibm-949 ibm949 949 cp949 | ПК Корейский |
| x-IBM949C | Cp949C | ibm949C ibm-949C cp949C 949C | Вариант Cp949 |
| x-IBM950 | CP950 | cp950 ibm950 950 ibm-950 | ПК Китайский (Гонконг, Тайвань) |
| x-IBM964 | Cp964 | ibm-964 cp964 ibm964 964 | AIX китайский (Тайвань) |
| х-IBM970 | CP970 | ibm970 ibm-eucKR 970 cp970 ibm-970 | AIX корейский |
| x-ISCII91 | ISCII91 | ISCII91 iso-ir-153 iscii ST_SEV_358-88 csISO153GOST1976874 | ISCII91 кодировка индийских скриптов |
| х-ISO2022-CN-CNS | ISO2022_CN_CNS | Не доступен | CNS11643 в форме ISO 2022 CN, традиционный китайский (преобразование только из Unicode) |
| x-ISO2022-CN-GB | ISO2022_CN_GB | Не доступен | GB2312 в форме ISO 2022 CN, упрощенный китайский (преобразование из Только Unicode) |
| x-iso-8859-11 | х-iso-8859-11 | iso-8859-11 iso8859_11 | Латинский / тайский алфавит |
| x-JIS0208 | х-JIS0208 | JIS0208 JIS_C6226-1983 iso-ir-87 x0208 JIS_X0208-1983 csISO87JISX0208 | JIS X 0208 |
| x-JISAutoDetect | JISAutoDetect | JISAutoDetect | Обнаруживает и преобразует Shift-JIS, EUC-JP, ISO 2022 JP (преобразование только в Unicode) |
| x-Johab | x-Johab | ms1361 ksc5601_1992 johab ksc5601-1992 | Корейский, набор символов Джохаб |
| x-Mac Арабский | Макарабский | Макарабский | Macintosh Арабский |
| x-MacCentralEurope | MacCentralEurope | MacCentralEurope | Macintosh Latin-2 |
| x-MacCroatian | МакКроат | МакКроат | Macintosh Хорватский |
| х-MacCyrillic | MacCyrillic | MacCyrillic | Macintosh Кириллица |
| х-MacDingbat | MacDingbat | MacDingbat | Macintosh Dingbat |
| x-MacGreek | MacGreek | MacGreek | Macintosh Греческий |
| x-Mac Иврит | MacHebrew | MacHebrew | Macintosh Иврит |
| x-MacIceland | MacIceland | MacIceland | Macintosh Исландия |
| x-MacRoman | MacRoman | MacRoman | Macintosh Roman |
| x-Mac Румыния | MacRomania | MacRomania | Macintosh Румыния |
| x-MacSymbol | MacSymbol | MacSymbol | Символ Macintosh |
| x-MacThai | MacThai | MacThai | Тайский Macintosh |
| x-Mac Турецкий | MacTurkish | MacTurkish | Macintosh Турецкий |
| x-Mac Украина | Mac Украина | Mac Украина | Macintosh Украина |
| x-MS932_0213 | x-MS950-HKSCS MS950_HKSCS | Не доступен | Shift_JISX0213 Windows MS932 вариант |
| x-MS950-HKSCS | MS950_HKSCS | MS950_HKSCS | Windows Традиционный китайский с расширениями для Гонконга |
| х-MS950-HKSCS-XP | x-mswin-936 MS936 | MS950_HKSCS_XP | HKSCS Windows XP вариант |
| x-mswin-936 | MS936 | мс936 мс_936 | Windows (упрощенный китайский) |
| x-PCK | PCK | уп | Версия Shift_JIS для Solaris |
| x-SJIS_0213 | x-SJIS_0213 | Не доступен | Shift_JISX0213 |
| x-windows-50220 | Cp50220 | cp50220 ms50220 | Кодовая страница Windows 50220 (7-битная реализация) |
| x-windows-50221 | Cp50221 | cp50221 ms50221 | Кодовая страница Windows 50221 (7-разрядная реализация) |
| x-окна-874 | MS874 | мс-874 мс874 окна-874 | Windows тайский |
| x-окна-949 | MS949 | windows949 ms949 windows-949 ms_949 | Windows корейский |
| x-окна-950 | MS950 | ms950 windows-950 | Windows Традиционный китайский |
| x-windows-iso2022jp | x-windows-iso2022jp | окна-iso2022jp | Вариант ISO-2022-JP (на основе MS932) |
 io.InputStreamReader
io.InputStreamReader 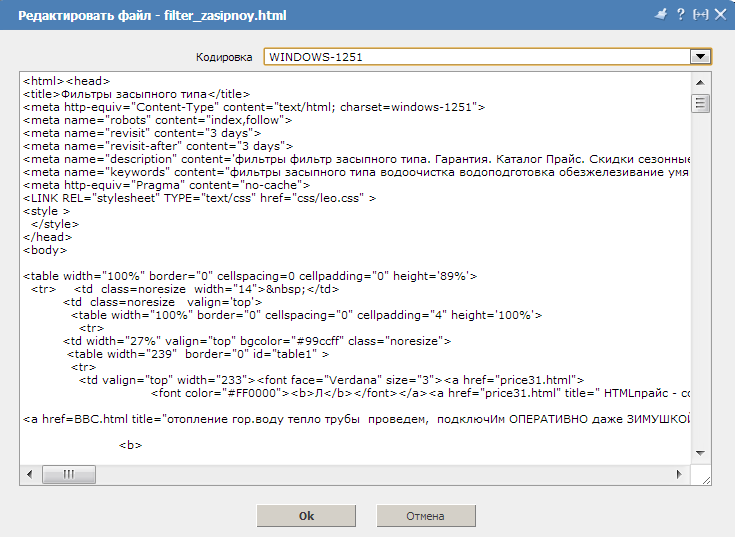 В
Версия для европейских языков поддерживает только кодировки, указанные в
следующую таблицу базового набора кодировок. Международная версия
(который включает файл lib / charsets.jar) поддерживает все
кодировки, показанные на этой странице.
В
Версия для европейских языков поддерживает только кодировки, указанные в
следующую таблицу базового набора кодировок. Международная версия
(который включает файл lib / charsets.jar) поддерживает все
кодировки, показанные на этой странице.Некоторые основные
- charset = big5
- Традиционный китайский (Big5)
- charset = euc-kr
- корейский (EUC)
- кодировка = iso-8859-1
- Западный алфавит
- charset = iso-8859-2
- Центральноевропейский алфавит (ISO)
- кодировка = iso-8859-3
- Латинский алфавит 3 (ISO)
- charset = iso-8859-4
- Балтийский алфавит (ISO)
- charset = iso-8859-5
- Кириллица (ISO)
- charset = iso-8859-6
- Арабский алфавит (ISO)
- charset = iso-8859-7
- Греческий алфавит (ISO)
- charset = iso-8859-8
- Еврейский алфавит (ISO)
- кодировка = koi8-r
- Кириллица (KOI8-R)
- charset = shift-jis
- японский (Shift-JIS)
- кодировка = x-euc
- японский (EUC)
- charset = utf-8
- Универсальный алфавит (UTF-8)
- charset = windows-1250
- Центральноевропейский алфавит (Windows)
- charset = windows-1251
- Кириллица (Windows)
- кодировка = windows-1252
- западный алфавит (Windows)
- charset = windows-1253
- Греческий алфавит (Windows)
- кодировка = windows-1254
- турецкий алфавит
- charset = windows-1255
- Еврейский алфавит (Windows)
- charset = windows-1256
- Арабский алфавит (Windows)
- charset = windows-1257
- Балтийский алфавит (Windows)
- charset = windows-1258
- Вьетнамский алфавит (Windows)
- charset = windows-874
- тайский (Windows)
Более длинный список
- Арабский (ASMO 708)
- ## charset = ASMO-708
- Арабский (DOS)
- ## charset = DOS-720
- арабский (ISO)
- ## charset = iso-8859-6
- Арабский (Mac)
- ## charset = x-mac-arabic
- Арабский (Windows)
- ## charset = windows-1256
- Балтика (DOS)
- ## charset = ibm775
- Балтика (ISO)
- ## charset = iso-8859-4
- Baltic (Windows)
- ## charset = windows-1257
- Центральноевропейская (DOS)
- ## charset = ibm852
- Центральноевропейская (ISO)
- ## charset = iso-8859-2
- Центральноевропейская (Mac)
- ## charset = x-mac-ce
- Центральноевропейская (Windows)
- ## charset = windows-1250
- Китайский упрощенный (EUC)
- ## charset = EUC-CN
- Китайский упрощенный (GB2312)
- ## charset = gb2312
- Китайский упрощенный (HZ)
- ## charset = hz-gb-2312
- Китайский упрощенный (Mac)
- ## charset = x-mac-chinesesimp
- Китайский традиционный (Big5)
- ## charset = big5
- Китайский традиционный (CNS)
- ## charset = x-Chinese-CNS
- Китайский традиционный (Eten)
- ## charset = x-Chinese-Eten
- Китайский традиционный (Mac)
- ## charset = x-mac-chinesetrad
- ## charset = 950
- Кириллица (DOS)
- ## charset = cp866
- Кириллица (ISO)
- ## charset = iso-8859-5
- Кириллица (KOI8-R)
- ## charset = koi8-r
- Кириллица (КОИ8-У)
- ## charset = koi8-u
- Кириллица (Mac)
- ## charset = x-mac-cyrillic
- Кириллица (Windows)
- ## charset = windows-1251
- Европа
- ## charset = x-Europa
- немецкий (IA5)
- ## charset = x-IA5-German
- Греческий (DOS)
- ## charset = ibm737
- Греческий (ISO)
- ## charset = iso-8859-7
- Греческий (Mac)
- ## charset = x-mac-greek
- Греческий (Windows)
- ## charset = windows-1253
- ## charset =
- Греческий, современный (DOS)
- ## charset = ibm869
- Еврейский (DOS)
- ## charset = DOS-862
- Еврейский (ISO-Logical)
- ## charset = iso-8859-8-i
- Еврейский (ISO-Visual)
- ## charset = iso-8859-8
- Еврейский (Mac)
- ## charset = x-mac-hebrew
- Еврейский (Windows)
- ## charset = windows-1255
- IBM EBCDIC (арабский)
- ## charset = x-EBCDIC-Arabic
- IBM EBCDIC (русская кириллица)
- ## charset = x-EBCDIC-CyrillicRussian
- IBM EBCDIC (кириллица сербско-болгарский)
- ## charset = x-EBCDIC-CyrillicSerbianBulgarian
- IBM EBCDIC (Дания-Норвегия)
- ## charset = x-EBCDIC-DenmarkNorway
- IBM EBCDIC (Дания-Норвегия-евро)
- ## charset = x-ebcdic-denmarknorway-euro
- IBM EBCDIC (Финляндия-Швеция)
- ## charset = x-EBCDIC-FinlandSweden
- IBM EBCDIC (Финляндия-Швеция-евро)
- ## charset = x-ebcdic-finlandsweden-euro
- IBM EBCDIC (Финляндия-Швеция-евро)
- ## charset = x-ebcdic-finlandsweden-euro
- IBM EBCDIC (Франция-евро)
- ## charset = x-ebcdic-france-euro
- IBM EBCDIC (Германия)
- ## charset = x-EBCDIC-Germany
- IBM EBCDIC (Германия-евро)
- ## charset = x-ebcdic-germany-euro
- IBM EBCDIC (современный греческий)
- ## charset = x-EBCDIC-GreekModern
- IBM EBCDIC (греческий)
- ## charset = x-EBCDIC-Greek
- IBM EBCDIC (иврит)
- ## charset = x-EBCDIC-Hebrew
- IBM EBCDIC (исландский)
- ## charset = x-EBCDIC-исландский
- IBM EBCDIC (исландские евро)
- ## charset = x-ebcdic-icelandic-euro
- IBM EBCDIC (международный — евро)
- ## charset = x-ebcdic-international-euro
- IBM EBCDIC (Италия)
- ## charset = x-EBCDIC-Italy
- IBM EBCDIC (Италия, евро)
- ## charset = x-ebcdic-italy-euro
- IBM EBCDIC (японский и японский катакана)
- ## charset = x-EBCDIC-JapaneseAndKana
- IBM EBCDIC (японский и японско-латинский)
- ## charset = x-EBCDIC-JapaneseAndJapaneseLatin
- IBM EBCDIC (Япония и США-Канада)
- ## charset = x-EBCDIC-JapaneseAndUSCanada
- IBM EBCDIC (японская катакана)
- ## charset = x-EBCDIC-JapaneseKatakana
- IBM EBCDIC (корейский и расширенный корейский)
- ## charset = x-EBCDIC-KoreanAndKoreanExtended
- IBM EBCDIC (расширенный корейский)
- ## charset = x-EBCDIC-KoreanExtended
- IBM EBCDIC (многоязычная латиница-2)
- ## charset = CP870
- IBM EBCDIC (упрощенный китайский)
- ## charset = x-EBCDIC-SimplifiedChinese
- IBM EBCDIC (Испания)
- ## charset = X-EBCDIC-Spain
- IBM EBCDIC (Испания-евро)
- ## charset = x-ebcdic-spain-euro
- IBM EBCDIC (тайский)
- ## charset = x-EBCDIC-Thai
- IBM EBCDIC (традиционный китайский)
- ## charset = x-EBCDIC-TraditionalChinese
- IBM EBCDIC (турецкая Latin-5)
- ## charset = CP1026
- IBM EBCDIC (турецкий)
- ## charset = x-EBCDIC-Turkish
- IBM EBCDIC (Великобритания)
- ## charset = x-EBCDIC-UK
- IBM EBCDIC (Великобритания-евро)
- ## charset = x-ebcdic-uk-euro
- IBM EBCDIC (США-Канада)
- ## charset = ebcdic-cp-us
- IBM EBCDIC (США-Канада-евро)
- ## charset = x-ebcdic-cp-us-euro
- Исландский (DOS)
- ## charset = ibm861
- Исландский (Mac)
- ## charset = x-mac-icelandic
- ISCII Ассамский
- ## charset = x-iscii-as
- ISCII Бенгальский
- ## charset = x-iscii-be
- ISCII Деванагари
- ## charset = x-iscii-de
- ISCII Гуджаратхи
- ## charset = x-iscii-gu
- ISCII каннада
- ## charset = x-iscii-ka
- ISCII Малаялам
- ## charset = x-iscii-ma
- ISCII Ория
- ## charset = x-iscii-or
- ISCII Panjabi
- ## charset = x-iscii-pa
- ISCII Тамил
- ## charset = x-iscii-ta
- ISCII телугу
- ## charset = x-iscii-te
- японский (EUC)
- ## charset = euc-jp
- ## charset = x-euc-jp
- японский (JIS)
- ## charset = iso-2022-jp
- японский (JIS-Allow 1 байт Кана — SO / SI)
- ## charset = iso-2022-jp
- Японский (JIS-Allow 1 байт Кана)
- ## charset = csISO2022JP
- Японский (Mac)
- ## charset = x-mac-japanese
- Японский (Shift-JIS)
- ## charset = shift_jis
- Корейский
- ## charset = ks_c_5601-1987
- Корейский (EUC)
- ## charset = euc-kr
- Корейский (ISO)
- ## charset = iso-2022-kr
- Корейский (Джохаб)
- ## charset = Johab
- Корейский (Mac)
- ## charset = x-mac-korean
- Latin 3 (ISO)
- ## charset = iso-8859-3
- Latin 9 (ISO)
- ## charset = iso-8859-15
- Норвежский (IA5)
- ## charset = x-IA5-норвежский
- OEM США
- ## charset = IBM437
- Шведский (IA5)
- ## charset = x-IA5-Swedish
- Тайский (Windows)
- ## charset = windows-874
- Турецкий (DOS)
- ## charset = ibm857
- Турецкий (ISO)
- ## charset = iso-8859-9
- Турецкий (Mac)
- ## charset = x-mac-turkish
- Турецкий (Windows)
- ## charset = windows-1254
- Юникод
- ## charset = юникод
- Юникод (с прямым порядком байтов)
- ## charset = unicodeFFFE
- Юникод (UTF-7)
- ## charset = utf-7
- Юникод (UTF-8)
- ## charset = utf-8
- US-ASCII
- ## charset = us-ascii
- Вьетнамский (Windows)
- ## charset = windows-1258
- Западноевропейский (DOS)
- ## charset = ibm850
- Западноевропейский (IA5)
- ## charset = x-IA5
- Западноевропейский (ISO)
- ## charset = iso-8859-1
- Западноевропейский (Mac)
- ## charset = macintosh
- Западноевропейская (Windows)
- ## charset = Windows-1252
Проблемы с кодировкой (кириллица) при импорте данных с помощью импорта CSV — проблемы
Exploratory Interaface не показывает русский язык (кириллические символы):
- как в заголовках, так и в столбцах
- в виде сводки, в виде таблицы, в редакторе команд
Исследовательский скрипт отлично работает в RStudio, R с теми же настройками локали
Программа просмотра данных R studio отлично показывает имена столбцов
Dataframe был загружен из файла Excel;
Но та же проблема остается, когда фрейм данных был загружен из csv через скрипт с правильной кодировкой («WINDOWS-1251»).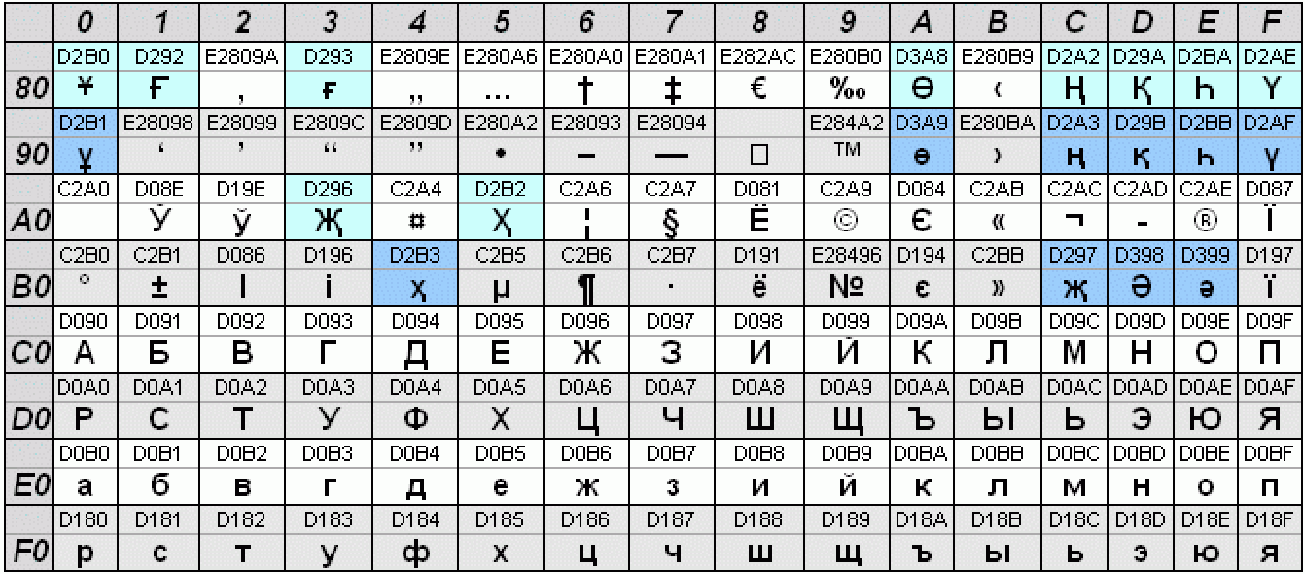
read_delim ("E: \\ _ other \\ Playground \\ Data Samples \\ abon.txt "," \ t ", quote =" \ "", skip = 0, col_names = TRUE, na = c ("", "NA"), n_max = -1, locale = locale (encoding = "WINDOWS-1251 ", decimal_mark =". "), progress = FALSE)
Когда вы экспортируете данные через «сохранить как csv», файл сохраняется в кодировке UTF-8 с правильными заголовками и содержимым.
После реимпорта csv в кодировке «UTF-8» — та же проблема во внутреннем интерфейсе.
Итак, похоже, проблема в основном связана с интерфейсом, а не с R или его настройками.
В версии для Mac существует такая же проблема.
Еще одна проблема — кириллические имена не работают в диалоге импорта в версии Windows:
, а также для импорта пользовательского скрипта:
# Шаги анализа данных
xx <- read_delim ("E: \\ _ other \\ Playground \\ Data Samples \\ Абоненты.txt", "\ t", quote = "\" ", skip = 0, col_names = TRUE, na = c ("", "NA"), n_max = -1, locale = locale (encoding = "WINDOWS-1251", decimal_mark = ". 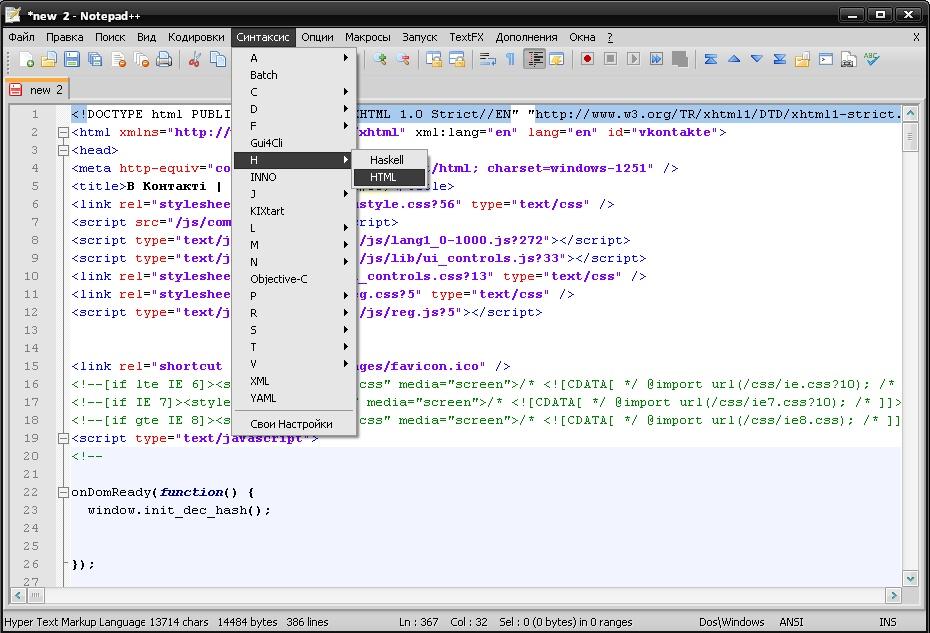 "), progress = FALSE)%>%
"), progress = FALSE)%>%
исследовательский :: clean_data_frame ()
, в то время как тот же сценарий отлично работает для Rstudio.
Для Mac версии импорт из файлов с кириллицей работает нормально.
«R версия 3.3.1 (2016-06-21)»,
«Платформа: x86_64-w64-mingw32 / x64 (64-разрядная)»,
«Работает под: Windows 7 x64 (сборка 7601) с пакетом обновления 1 «,
» «,
» locale: «,
» [1] LC_COLLATE = Russian_Russia.1251 LC_CTYPE = Russian_Russia.1251 «,
» [3] LC_MONETARY = Russian_Russia.1251 LC_NUMERIC = C «,
» [5] LC_TIME = Russian_Russia.1251 «,
| Символ | Число | Имя объекта | Описание | |||
|---|---|---|---|---|---|---|
| 0-31 | Управляющие символы (см. Ниже) | |||||
| 32 | пробел | |||||
| ! | 33 | восклицательный знак | ||||
| « | 34 | & quot; | кавычка | |||
| # | 35 | знак номер | ||||
| $ | 36 | знак доллара | ||||
| % | 37 | знак процента | ||||
| и | 38 | и | амперсанд | |||
| ‘ | 39 | апостроф 900 | 40 | левая скобка | ||
| ) | 41 | правая скобка | ||||
| * | 42 | звездочка | ||||
| + | 43 | + | 43 | знак плюс | ||
| , | 44 | запятая | ||||
| — | 45 | дефис минус | ||||
.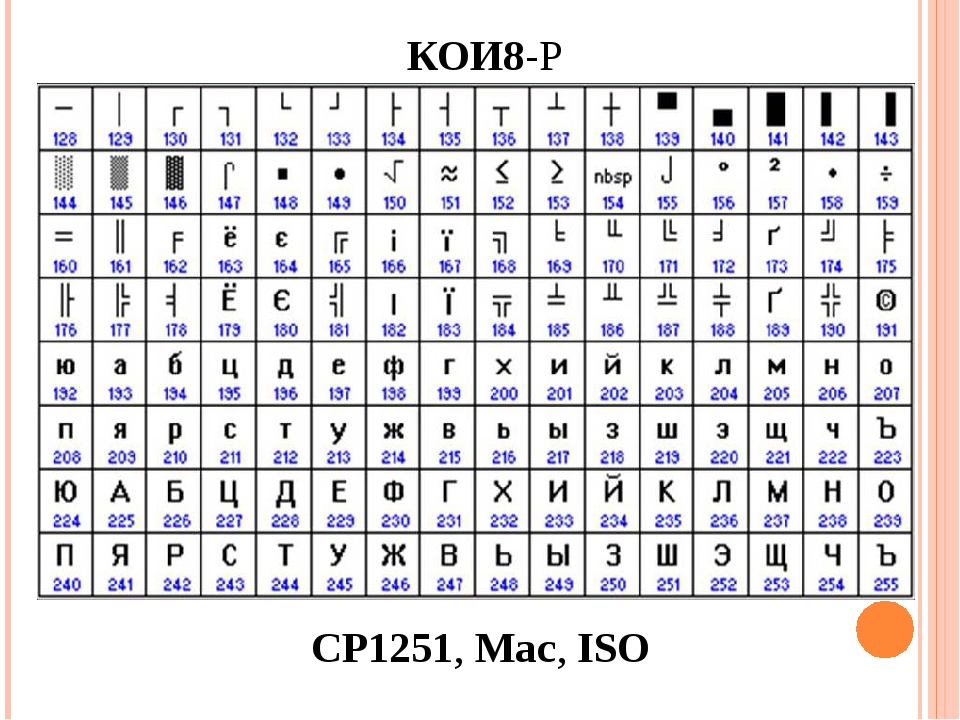 | 46 | полная остановка | ||||
| / | 47 | солидус | ||||
| 0 | 48 | цифра ноль | ||||
| 1 | 49 | цифра 900 | ||||
| 2 | 50 | цифра два | ||||
| 3 | 51 | цифра три | ||||
| 4 | 52 | цифра четыре | ||||
| 53 900 | цифра пять | |||||
| 6 | 54 | цифра шесть | ||||
| 7 | 55 | цифра семь | ||||
| 8 | 56 | цифра | цифра | |||
| 9 | 57 | цифра девять | ||||
| 58 | двоеточие | |||||
| ; | 59 | точка с запятой | ||||
| < | 60 | & lt; | знак меньше | |||
| = | 61 | знак равно | ||||
| > | 62 | & gt; | знак больше | |||
| ? | 63 | вопросительный знак | ||||
| @ | 64 | коммерческий в | ||||
| A | 65 | Заглавная латинская буква A | ||||
| B | 66 | B | 66 | 924Заглавная латинская буква B | ||
| C | 67 | Заглавная латинская буква C | ||||
| D | 68 | Заглавная латинская буква D | ||||
| E | 69 | Латинская заглавная буква E | ||||
| F | 70 | Заглавная латинская буква F | ||||
| G | 71 | Заглавная латинская буква G | ||||
| H | 72 | Заглавная латинская буква H | ||||
| I | 73 | Латинская заглавная буква I | ||||
| J | 74 | Заглавная латинская буква J | ||||
| K | 75 | Заглавная латинская буква K | ||||
| L | 76 | Заглавная латинская буква L | ||||
| M | 77 | Заглавная латинская буква M | ||||
| N | 78 | Заглавная латинская буква N | ||||
| O | 79 | Заглавная латинская буква O | ||||
| P | 80 | Заглавная латинская буква P | ||||
| Q | 81 | Заглавная латинская буква Q | ||||
| R | 82 | Заглавная латинская буква R | ||||
| S | 83 | Заглавная латинская буква S | ||||
| T 90 037 | 84 | Заглавная латинская буква T | ||||
| U | 85 | Заглавная латинская буква U | ||||
| V | 86 | Заглавная латинская буква V | ||||
| W | 87 | Заглавная латинская буква W | ||||
| X | 88 | Заглавная латинская буква X | ||||
| Y | 89 | Заглавная латинская буква Y | ||||
| Z | 90 | Заглавная латинская буква Z | ||||
| [ | 91 | левая квадратная скобка | ||||
| \ | 92 | обратный солидус | ||||
| ] | 93 | правый квадрат кронштейн | ||||
| ^ | 94 | циркумфлекс акцент | ||||
| _ | 95 | нижняя линия | ||||
| ` | 96 | могильный акцент | ||||
| a | 97 | латинская строчная буква а | 900 b34||||
| 98 | Строчная латинская буква b | |||||
| c | 99 | Строчная латинская буква c | ||||
| d | 100 | Строчная латинская буква d | ||||
| e | 101 | Строчная латинская буква e | ||||
| f | 102 | Строчная латинская буква f | ||||
| g | 103 | Строчная латинская буква g | ||||
| h | 104 | Строчная латинская буква h | ||||
| i | 105 | Строчная латинская буква i | ||||
| j | 106 | Строчная латинская буква j | ||||
| k | 107 | Строчная латинская буква k | ||||
| l | 108 | Латинская строчная буква l | ||||
| м | 109 | строчная латинская буква m | ||||
| n | 110 | строчная латинская буква n | ||||
| o | 111 | строчная латинская буква o | ||||
| p | 112 | Строчная латинская буква p | ||||
| q | 113 | Строчная латинская буква q | ||||
| r | 114 | Строчная латинская буква r | ||||
| s | 115 | Строчная латинская буква s | ||||
| 116 | Строчная латинская буква t | |||||
| u | 117 | Строчная латинская буква u | ||||
| v | 118 | Строчная латинская буква v | ||||
| w | 119 | Строчная латинская буква w | ||||
| x | 120 | Строчная латинская буква x | ||||
| y | 121 | Строчная латинская буква y | ||||
| z | 122 | Строчная латинская буква z | ||||
| { | 123 | левая фигурная скобка | ||||
| | | 124 | вертикальная линия | ||||
| } | 125 | правая фигурная скобка | ||||
| ~ | 126 | тильда | ||||
| 127 | 920 Управляющий символ (см.||||||
| € | 128 | и евро; | знак евро | |||
| 129 | НЕ ИСПОЛЬЗУЕТСЯ | |||||
| ‚ | 130 | & sbquo; | одинарная кавычка с малым числом 9 | |||
| ƒ | 131 | & fnof; | Строчная латинская буква f с крючком | |||
| „ | 132 | & bdquo; | двойная кавычка с малым числом 9 | |||
| … | 133 | & hellip; | эллипс по горизонтали | |||
| † | 134 | и крестик; | кинжал | |||
| ‡ | 135 | и кинжал; | двойной кинжал | |||
| ˆ | 136 | & circ; | модификатор буквы с циркумфлексом ударение | |||
| ‰ | 137 | & permil; | знак промилле | |||
| Š | 138 | & Scaron; | Заглавная латинская буква S с кароном | |||
| ‹ | 139 | & lsaquo; | одинарная кавычка, указывающая влево | |||
| Œ | 140 | & OElig; | Латинская заглавная лигатура OE | |||
| 141 | НЕ ИСПОЛЬЗУЕТСЯ | |||||
| & Zcaron; | 142 | и Zcaron; | Латинская заглавная буква Z с кароном | |||
| 143 | НЕ ИСПОЛЬЗУЕТСЯ | |||||
| 144 | НЕ ИСПОЛЬЗУЕТСЯ | |||||
| ‘ | 145 | & lsquo; | левая одинарная кавычка | |||
| ’ | 146 | & rsquo; | правая одинарная кавычка | |||
| “ | 147 | & ldquo; | левая двойная кавычка | |||
| ” | 148 | & rdquo; | правая двойная кавычка | |||
| • | 149 | & bull; | пуля | |||
| — | 150 | & ndash; | в тире | |||
| — | 151 | & mdash; | длинное тире | |||
| ~ | 152 | & тильда; | маленькая тильда | |||
| ™ | 153 | & trade; | знак товарного знака | |||
| š | 154 | & scaron; | Строчная латинская буква s с кароном | |||
| › | 155 | & rsaquo; | одинарная кавычка с прямым углом | |||
| œ | 156 | & oelig; | Строчная латинская лигатура oe | |||
| 157 | НЕ ИСПОЛЬЗУЕТСЯ | |||||
| & zcaron; | 158 | & zcaron; | Строчная латинская буква z с кароном | |||
| Ÿ | 159 | & Yuml; | Заглавная латинская буква Y с тремой | |||
| 160 | & nbsp; | непрерывное пространство | ||||
| ¡ | 161 | & iexcl; | перевернутый восклицательный знак | |||
| ¢ | 162 | & cent; | центов знак | |||
| £ | 163 | & фунт; | знак фунта | |||
| ¤ | 164 | & curren; | знак валюты | |||
| ¥ | 165 | и иен; | йен знак | |||
| ¦ | 166 | & brvbar; | сломанный стержень | |||
| § | 167 | & sect; | знак раздела | |||
| ¨ | 168 | & uml; | диэрезис | |||
| © | 169 | и копия; | знак авторского права | |||
| ª | 170 | & ordf; | женский порядковый указатель | |||
| « | 171 | & laquo; | двойные угловые кавычки, указывающие влево | |||
| ¬ | 172 | & not; | не подписывать | |||
| 173 | & shy; | мягкий перенос | ||||
| ® | 174 | & reg; | зарегистрированный знак | |||
| ¯ | 175 | & macr; | макрон | |||
| ° | 176 | & deg; | знак градуса | |||
| ± | 177 | & plusmn; | знак плюс-минус | |||
| ² | 178 | & sup2; | верхний индекс два | |||
| ³ | 179 | & sup3; | тройной верхний индекс | |||
| ´ | 180 | и острый; | острый акцент | |||
| µ | 181 | & микро; | микроподпись | |||
| ¶ | 182 | & para; | знак Pilcrow | |||
| · | 183 | & middot; | средняя точка | |||
| ¸ | 184 | & cedil; | седилла | |||
| ¹ | 185 | & sup1; | верхний индекс один | |||
| º | 186 | & ordm; | мужской порядковый номер | |||
| » | 187 | & raquo; | двойные угловые кавычки, указывающие вправо | |||
| ¼ | 188 | & frac14; | вульгарная фракция одна четверть | |||
| ½ | 189 | & frac12; | вульгарная фракция половина | |||
| ¾ | 190 | & frac34; | вульгарная фракция три четверти | |||
| ¿ | 191 | & iquest; | перевернутый вопросительный знак | |||
| À | 192 | & Agrave; | Латинская заглавная буква A с могилой | |||
| Á | 193 | & Aacute; | Заглавная латинская буква A с острым ударением | |||
| Â | 194 | & Acirc; | Заглавная латинская буква A с циркумфлексом | |||
| Ã | 195 | & Atilde; | Заглавная латинская буква A с тильдой | |||
| Ä | 196 | & Auml; | Заглавная латинская буква A с тремой | |||
| Å | 197 | & Aring; | Заглавная латинская буква A с кольцом сверху | |||
| Æ | 198 | & AElig; | Заглавная латинская буква AE | |||
| Ç | 199 | & Ccedil; | Заглавная латинская буква C с седилем | |||
| È | 200 | & Egrave; | Латинская заглавная буква E с тупым шрифтом | |||
| É | 201 | & Eacute; | Заглавная латинская буква E с острым ударением | |||
| Ê | 202 | & Ecirc; | Заглавная латинская буква E с циркумфлексом | |||
| Ë | 203 | & Euml; | Заглавная латинская буква E с тремой | |||
| Ì | 204 | & Igrave; | Латинская заглавная буква I с могилой | |||
| Í | 205 | & Iacute; | Заглавная латинская буква I с острым ударением | |||
| Î | 206 | & Icirc; | Заглавная латинская буква I с циркумфлексом | |||
| Ï | 207 | & Iuml; | Заглавная латинская буква I с тремой | |||
| ì | 208 | & ETH; | Заглавная латинская буква Eth | |||
| Ñ | 209 | & Ntilde; | Заглавная латинская буква N с тильдой | |||
| Ò | 210 | & Ograve; | Латинская заглавная буква O с могилой | |||
| Ó | 211 | & Oacute; | Заглавная латинская буква O с острым ударением | |||
| Ô | 212 | & Ocirc; | Заглавная латинская буква O с циркумфлексом | |||
| Õ | 213 | & Otilde; | Заглавная латинская буква O с тильдой | |||
| Ö | 214 | & Ouml; | Заглавная латинская буква O с тремой | |||
| × | 215 | & раз; | знак умножения | |||
| Ø | 216 | & Oslash; | Заглавная латинская буква O со штрихом | |||
| Ù | 217 | & Ugrave; | Латинская заглавная буква U с могилой | |||
| Ú | 218 | & Uacute; | Заглавная латинская буква U с острым ударением | |||
| Û | 219 | & Ucirc; | Латинская заглавная буква U с циркумфлексом | |||
| Ü | 220 | & Uuml; | Заглавная латинская буква U с тремой | |||
| Ý | 221 | & Yacute; | Заглавная латинская буква Y с острым ударением | |||
| Þ | 222 | & THORN; | Заглавная латинская буква Шип | |||
| ß | 223 | & szlig; | Строчная латинская буква, резкая s | |||
| à | 224 | & agrave; | Строчная латинская буква а с тупым ударением | |||
| á | 225 | & aacute; | Строчная латинская буква А с острым ударением | |||
| â | 226 | & acirc; | Строчная латинская буква а с циркумфлексом | |||
| ã | 227 | & atilde; | Строчная латинская буква а с тильдой | |||
| ä | 228 | & auml; | Строчная латинская буква а с тремой | |||
| å | 229 | & aring; | Строчная латинская буква а с кружком сверху | |||
| æ | 230 | & aelig; | Строчная латинская буква ae | |||
| ç | 231 | & ccedil; | Строчная латинская буква c с седилем | |||
| è | 232 | & egrave; | Строчная латинская буква е с тупым ударением | |||
| é | 233 | & eacute; | Строчная латинская буква e с острым ударением | |||
| ê | 234 | & ecirc; | Строчная латинская буква e с циркумфлексом | |||
| ë | 235 | & euml; | Строчная латинская буква e с тремой | |||
| ì | 236 | & igrave; | Строчная латинская буква i с надписями | |||
| í | 237 | & iacute; | Строчная латинская буква i с острым ударением | |||
| î | 238 | & icirc; | Строчная латинская буква i с циркумфлексом | |||
| ï | 239 | & iuml; | Строчная латинская буква i с тремой | |||
| ð | 240 | & eth; | Строчная латинская буква eth | |||
| — | 241 | & ntilde; | Строчная латинская буква n с тильдой | |||
| ò | 242 | & ograve; | Строчная латинская буква o с могилой | |||
| ó | 243 | & oacute; | Строчная латинская буква o с острым ударением | |||
| ô | 244 | & ocirc; | Строчная латинская буква o с циркумфлексом | |||
| х | 245 | & otilde; | Строчная латинская буква o с тильдой | |||
| ö | 246 | & ouml; | Строчная латинская буква o с тремой | |||
| ÷ | 247 | & div; | разделительный знак | |||
| ø | 248 | & oslash; | Строчная латинская буква o со штрихом | |||
| ù | 249 | & ugrave; | Латинская строчная буква u с тупым ударением | |||
| ú | 250 | & uacute; | Строчная латинская буква u с острым ударением | |||
| û | 251 | & ucirc; | Строчная латинская буква u с циркумфлексом | |||
| ü | 252 | & uuml; | Строчная латинская буква u с тремой | |||
| ý | 253 | & yacute; | Строчная латинская буква y с острым ударением | |||
| þ | 254 | & thorn; | Строчная латинская буква шип | |||
| ÿ | 255 | & yuml; | Строчная латинская буква y с диэрезисом |
 ниже)
ниже)Файлы ANSI и Unicode и строки C ++
Файлы ANSI и Unicode и строки C ++ Как вы обрабатываете текстовые файлы XML и HTML, будь то строки в памяти: UNICODE / wchar_t , MBCS или простой C? Загрузка и сохранение текста в файле Unicode или ANSI может включать преобразование в текстовую кодировку ваших строк C ++ и обратно.
Эй, если вы просто пытаетесь использовать текстовый редактор для сохранения файла ANSI в кодировке Unicode, см. Преобразование файла ANSI в Unicode.
UTF-8 — рекомендуемая кодировка для файлов XML и HTML. Если весь ваш текст состоит из ASCII, то он также действителен в кодировке UTF-8. Но если ваш XML-файл не является ASCII и не Unicode (то есть не UTF-8 или UTF-16 / UCS-2), вам действительно следует использовать XML-объявление для объявления вашей кодировки. Например, если это кодировка ANSI США по умолчанию, используйте это объявление:
Обзор кодовых страниц ANSI
В программировании под Windows термин ANSI используется для обозначения всех однобайтовых и многобайтовых символов, отличных от Unicode, которые могут быть выбраны в качестве кодовой страницы языкового стандарта системы. К ним относятся однобайтовые системы для Европы и «двухбайтовые» для китайского, японского и корейского языков, которые фактически используют один или два байта на символ.
В наборах символов, таких как Windows-1252 и кириллица Windows-1251, символ всегда представляет собой один байт со значением до 255.Проблема в том, что значения от 128 до 255 (шестнадцатеричные от 80 от до ff ) назначаются определенным символам, которые могут различаться в разных наборах символов. Например, символ евро (€) — это шестнадцатеричный 80 (десятичный 128) в Windows-1252, но в Windows-1251 шестнадцатеричное значение 80 представляет собой заглавную букву DJE (Ђ), а шестнадцатеричное 88 — евро. . Итак, когда компьютер видит значение 80 , это зависит от текущей настройки языкового стандарта системы, как он будет отображать этот символ.
| символ | Окна-1252 Латиница-1 | Windows-1251 Кириллица | UTF-8 | UTF-16 |
|---|---|---|---|---|
| € (евро) | 80 (128) | 88 (136) | E2 82 переменного тока | 20AC |
| ® (Зарегистрировано) | AE (174) | AE (174) | C2 AE | 00AE |
В наборах двухбайтовых символов, таких как GB2312 (китайский упрощенный), символ — это один байт, когда он находится в диапазоне ASCII, но в противном случае он может быть одним или двумя байтами (некоторые кодовые точки более 80 являются старшими байтами. которые интерпретируются вместе с завершающим байтом).Например, значение символа ASCII z не изменяется (сильно) между различными кодировками, но образец китайского символа полностью отличается:
которые интерпретируются вместе с завершающим байтом).Например, значение символа ASCII z не изменяется (сильно) между различными кодировками, но образец китайского символа полностью отличается:
| символ | ГБ 2312 | UTF-8 | UTF-16 |
|---|---|---|---|
| z | 7A | 7A | 007A |
| 中 (средний) | D6 D0 | E4 B8 AD | 4E2D |
Системы Windows позволяют программам, не использующим UNICODE, работать с одним набором символов ANSI за раз.Чтобы изменить кодировку, вы должны изменить настройку локали системы компьютера (поэтому Unicode отлично подходит, потому что вам не нужно этого делать).
Параметры сборки вашей кодировки в Windows
С точки зрения кодировки текста в памяти, существует 3 способа создания программы Windows C ++:
UNICODE означает использование широкого символа UTF-16 (или его предшественника UCS-2) MBCS означает использование кодировки локали системы Windows, однобайтовой или многобайтовой (DBCS) Для CMarkup это Unicode UTF-8 .
Для CMarkup это Unicode UTF-8 .Параметры сборки вашей кодировки в Linux, OS X и других платформах
Программы OS X и Linux C ++ не имеют режимов ANSI и UNICODE, которые есть в программах Windows. Но вы можете использовать строки на основе char , которые обычно являются строками UTF-8, или строк на основе wchar_t UTF-32. Соответствующие строковые классы STL: std :: string и std :: wstring . Хотя я рекомендую UTF-8, который требует меньше места и меньше преобразований, CMarkup поддерживает широкие строки на этих платформах с определением MARKUP_WCHAR .
Загрузка и сохранение текстовых файлов
Обновление от 17 декабря 2008 г .: В выпуске CMarkup 10.1 методы Save и Load и базовые функции WriteTextFile и ReadTextFile значительно расширили возможности преобразования символов для обработки наиболее распространенных кодировок ANSI и двухбайтовых кодировок, указанных в объявлении XML или HTML.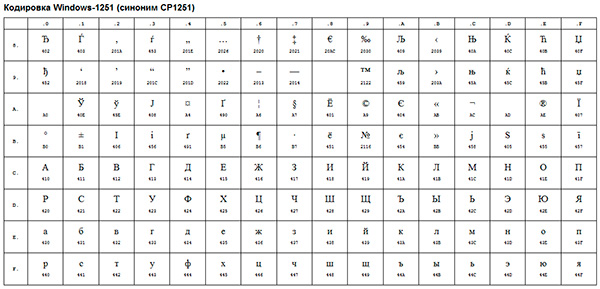 Метатег Content-Type (см. GetDeclaredEncoding) документа.
Метатег Content-Type (см. GetDeclaredEncoding) документа.
Какую бы кодировку вы ни использовали в памяти, CMarkup преобразует ее в кодировку вашего файла при чтении или записи файла.
В Windows функция преобразования текста CMarkup использует API-интерфейсы Windows MultiByteToWideChar и WideCharToMultiByte , см. Определение препроцессора MARKUP_WINCONV . В Visual C ++ MARKUP_WINCONV выбирается автоматически. В g ++ для cygwin и других компиляторах для Windows добавьте MARKUP_WINCONV в определения вашего препроцессора или укажите -DMARKUP_WINCONV в командной строке.
Если не в Windows, CMarkup использует API iconv , доступный в OS X, Linux и некоторых других платформах, см. Определение препроцессора MARKUP_ICONV .Компилятор g ++ GNU автоматически выберет MARKUP_ICONV . При необходимости поместите MARKUP_ICONV в определения препроцессора. В OS X вам может потребоваться указать библиотеку iconv компоновщику. Следующая команда используется для компиляции тестовой программы CMarkup в OS X:
В OS X вам может потребоваться указать библиотеку iconv компоновщику. Следующая команда используется для компиляции тестовой программы CMarkup в OS X:
g ++ main.cpp Markup.cpp MarkupTest.cpp -liconv
Без преобразования API
Определите MARKUP_STDCONV , чтобы не использовать ни API преобразования Windows, ни iconv .См. Обработку текста без поддержки Юникода в CMarkup.
Если вы не используете MARKUP_WINCONV или MARKUP_ICONV , CMarkup по-прежнему поддерживает преобразование между кодировками Unicode (UTF-8 и UTF-16 и wchar_t , который является UTF-32 в OS X и Linux), а также кодировка языкового стандарта системы, если вы вызываете setlocale . Кодировка, отличная от Unicode, поддерживается функциями ANSI C mbtowc и wctomb для преобразования в / из Unicode.
, сборка MBCS
Это режим сборки по умолчанию в старых проектах Windows Visual C ++ с использованием кодовой страницы ANSI языкового стандарта системы в строках и API Windows. Это означает, что ваши строки в памяти не являются Unicode.
CMarkup работает немного медленнее в сборке MBCS , чем в сборке без MBCS, потому что она должна вычислять длину символа (1 или 2 байта) при обработке строк. Это не относится к UTF-8, потому что, хотя UTF-8 является многобайтовым, это вычисление длины символа не требуется во время обработки большинства строк UTF-8 из-за того, как разработан UTF-8.См. Следующий раздел о внутреннем использовании UTF-8.
Если файл Unicode загружен в сборку MBCS , вы потеряете все символы, не поддерживаемые кодировкой, используемой в памяти. Или, если файл имеет другой набор символов, чем тот, который находится в памяти, вы можете потерять символы. Процесс преобразования обычно заменяет эти потерянные символы вопросительным знаком и сообщает в строке результата (GetResult), что символы были потеряны во время преобразования.
Отлично.К вашему сведению, автоматическое преобразование из UTF-8 в ANSI в памяти в сборке MBCS было реализовано в CMarkup Developer версии 7.3 и стало частью оценочной версии в версии 9.0. CMarkup версии 10.1 дополнительно добавляет возможность автоматического преобразования из файла ANSI, даже если он не соответствует кодировке ANSI языкового стандарта системы.
Сборка UTF-8 (без MBCS)
Если у вас нет MBCS (ни UNICODE , ни MARKUP_WCHAR ) в определениях вашего компилятора, CMarkup предназначен для внутреннего использования UTF-8.Это позволяет сохранить документ в Юникоде в памяти и избежать потери многоязычного текста, описанной выше в сборке MBCS . Вы должны преобразовывать строки в ANSI только по мере необходимости для отображения или передачи в Windows API с AToUTF8 и UTF8ToA.
Если ваш файл имеет формат UTF-8 (как рекомендовано для XML), это позволяет вам сохранить документ как UTF-8 в памяти без преобразования при загрузке и сохранении.
UTF-16 файлов
UTF-8 — рекомендуемая кодировка Unicode для XML, но иногда используется UTF-16.CMarkup обнаружит файлы UTF-16 (включая UCS-2), содержащие метку порядка байтов (BOM). См. Файлы UTF-16 и метку порядка байтов (BOM).
См. Также:
Файлы UTF-8 и преамбула
Установка декларации XML с помощью строки CMarkup
wchar_t в Linux, OS X и Windows
черновик-winitzki-koi8c-encoding-00
Internet Draft Serge Winitzki
проект-winitzki-koi8c-кодировка-00.текст
Истекает: Апрель 2002
Расширенный набор символов кириллицы
KOI8-C
Статус этого меморандума
Эта памятка является Интернет-проектом и регулируется всеми положениями.
раздела 10 RFC2026.
Интернет-проекты - это рабочие документы Интернета.
Инженерная рабочая группа (IETF), ее области и работа
группы. Обратите внимание, что другие группы также могут распространять рабочие
документы как Интернет-проекты.
Интернет-проекты - это черновики документов, действительные не более шести лет.
месяцев и может быть обновлен, заменен или исключен другими
документы в любое время.Нецелесообразно использовать
Интернет-проекты в качестве справочного материала или для их цитирования, кроме
как «незавершенное производство».
Со списком текущих Интернет-проектов можно ознакомиться по адресу
http://www.ietf.org/ietf/1id-abstracts.txt Список
Интернет-черновики теневых каталогов доступны по адресу
http://www.ietf.org/shadow.html.
Автор
Серж Виницки
Абстрактный
В этом документе содержится информация о кодировке символов.
KOI8-C (KOI8 Cyrillic) предлагается для использования с русским языком (в том числе
старая орфография), украинский, белорусский, сербский, македонский
языки со специальными знаками препинания.KOI8-C совместим
с КОИ8-Р [1] и КОИ8-У [2] в зоне русского, украинского
и белорусскими буквами, и дополняет их буквами для старых
Русская орфография, югославские буквы кириллицы и
типографские символы в позициях, совместимых с CP1251 для использования
в устаревших приложениях.
Предлагаемое имя набора символов MIME: koi8-c
Вступление
В этом документе содержится информация о предлагаемом новом персонаже.
кодирование KOI8-C, расширение стандартов KOI8-R и KOI8-U.
Это расширение поддерживает все русские буквы.
(в том числе необходимые для древнерусской орфографии), а также
Кириллица в белорусском, македонском, сербском и белорусском языках.
Украинские языки и некоторые часто используемые типографские
символы заимствованы из кодировки CP1251.Кодировка KOI8-C
совместим с существующими кодировками KOI8-RU и CP1251 в
соответствующие персонажи.
Мотивация
Семейство кодировок KOI8 издавна используется для электронных
обмен кириллическими текстами [1,2]. Следующие соображения
заставили автора предложить расширение KOI8.
1) Большая область таблицы кодирования KOI8 (большая часть 0x80-0xBF
диапазон) по историческим причинам занят символами
псевдографика, которая не используется в современном ПО. Эти символы
отсутствуют в большинстве реализаций шрифтов KOI8 без какого-либо влияния
по производительности пользователей.Эти места в таблице кодирования могут быть
используется для представления наиболее часто используемых символов.
2) Недавнее доминирование операционной среды "MS Windows".
привело к широкому распространению текстовых процессоров, использующих код
страница 1251 "для отображения кириллицы. Многие Интернет-документы
таким образом преобразуются в KOI8 из CP1251 и часто включают
определенные типографские знаки, такие как апострофы, цитаты или
тире, не представленные в кодировках KOI8, но оставленные без
изменение автоматическими преобразователями.Эти типографские символы падают
в неиспользуемой области псевдографики KOI8.
3) Тексты в древнерусской орфографии (до 1918 г.) содержат четыре
Кириллические буквы не представлены ни одним из широко используемых
Кириллические кодировки. Хотя инструменты на основе Unicode будут в
быть адекватным для рендеринга этих символов, текущий
программное обеспечение в основном не имеет необходимой поддержки. Это было бы
удобно иметь 8-битную кодировку, представляющую старый русский язык
символы и иметь возможность помещать их прямо в шрифт
карта кодирования и раскладка клавиатуры, совместимая с широким диапазоном
текущего программного обеспечения.Выполнение
Автор реализовал кодировку KOI8-C в соответствии с этими
рекомендации: (1) совместимость с символом KOI8-R и KOI8-U
наборов, (2) совместимость с набором символов CP1251 в области
типографские символы и югославская кириллица; (3) должно быть
умеет конвертировать шрифты в другие кодировки кириллицы.
Нижняя часть набора символов KOI8-C является полной копией
ASCII в диапазоне печатаемых символов (0x20 - 0x7F). В
диапазон (0x00 - 0x1F) занят псевдографикой и прочими
редко используются специальные символы.Верхняя часть набора символов KOI8-C содержит весь русский язык,
Белорусские и украинские буквы в позициях, определенных в KOI8-R
и КОИ8-У; часто используемые типографские символы (кавычки,
тире и символы валют) и югославской кириллицы как
определяется кодировкой CP1251; и старинные русские буквы. Большая коробка
рисование персонажей из KOI8-R, а также некоторые математические
символы, были удалены.
Результирующий набор символов содержит все символы ISO 8859-5.
кроме SOFT HYPHEN и охватывает CP1251 за исключением 5 знаков препинания
символы (все также в CP1252).Веб-страница
содержит авторские разработки, связанные с KOI8-C
кодировка и тексты в древнерусской орфографии. Бесплатное растровое изображение
шрифты семейства Cronyx для оконной системы X были адаптированы
в кодировку KOI8-C, реализующую полную карту KOI8-C (256
символов) во всех шрифтах (проект "xcyr"). Расширение
раскладка клавиатуры, содержащая старые русские буквы, была
предложил. Словарь для проверки орфографии для древнерусского языка
орфография с использованием кодировки KOI8-C.Отношение к другим усилиям
Эта кодировка была разработана как модификация [1,2]. An
независимый проект разработки шрифтов "CYR-RFX" использует
альтернативное кодирование «КОИ8-О» с аналогичными целями
совместимость с KOI8-R и CP1251, но не содержит
Югославские символы кириллицы.
Спецификация кодовой страницы KOI8-C
Описание всех персонажей верхней половины KOI8-C
кодовая страница задается в соответствии с набором символов Unicode ISO 10646
(ПСК).
# <описание>
0x01 U25C6 # ЧЕРНЫЙ АЛМАЗ
0x02 U2592 # СРЕДНИЙ ОТТЕНК
0x03 U00D7 # ЗНАК УМНОЖЕНИЯ
0x04 U00F7 # ЗНАК РАЗДЕЛЕНИЯ
0x05 U2030 # ЗНАК НА МЕЛЬНИЦУ
0x06 U2248 # ПОЧТИ РАВНО
0x07 U00B5 # МИКРОЗНАК
0x08 U00B1 # ЗНАК ПЛЮС-МИНУС
0x09 U00B6 # ЗНАК ПИЛКРОУ
0x0A U2021 # ДВОЙНОЙ КИНЖАЛ
0x0B U2518 # ЧЕРТЕЖИ КОРОБКИ СВЕТИЛЬНИКИ Вверх и Влево
0x0C U2510 # ЧЕРТЕЖИ КОРОБКИ СВЕТЛЫЕ ВНИЗ И ВЛЕВО
0x0D U250C # ЧЕРТЕЖИ НА КОРОБКЕ СВЕТЛЫЙ ВНИЗ И ВПРАВО
0x0E U2514 # ЧЕРТЕЖИ КОРОБКИ СВЕТИЛЬНИКИ ВПРАВО
0x0F U253C # КОРОБКА ЧЕРТЕЖЕЙ СВЕТЛАЯ ВЕРТИКАЛЬНАЯ И ГОРИЗОНТАЛЬНАЯ
0x10 UFFFD # ХАРАКТЕР ЗАМЕНЫ
0x11 UFFFD # ХАРАКТЕР ЗАМЕНЫ
0x12 U2500 # КОРОБКА ЧЕРТЕЖЕЙ СВЕТЛАЯ ГОРИЗОНТАЛЬНАЯ
0x13 UFFFD # ХАРАКТЕР ЗАМЕНЫ
0x14 UFFFD # ХАРАКТЕР ЗАМЕНЫ
0x15 U251C # ЧЕРТЕЖИ КОРОБКИ СВЕТЛЫЕ ВЕРТИКАЛЬНО И ПРАВО
0x16 U2524 # ЧЕРТЕЖИ КОРОБКИ СВЕТЛЫЕ ВЕРТИКАЛЬНО И СЛЕВА
0x17 U2534 # ЧЕРТЕЖИ КОРОБКИ СВЕТИЛЬНО И ГОРИЗОНТАЛЬНО
0x18 U252C # ЧЕРТЕЖИ НА КОРОБКЕ СВЕТЛЫЙ ВНИЗ И ГОРИЗОНТАЛЬНО
0x19 U2502 # КОРОБКА ЧЕРТЕЖЕЙ СВЕТЛАЯ ВЕРТИКАЛЬНАЯ
0x1A U2264 # МЕНЬШЕ ИЛИ РАВНО
0x1B U2265 # БОЛЬШЕ ИЛИ РАВНО
0x1C U03C0 # ГРЕЧЕСКАЯ СТРОЧНАЯ БУКВА PI
0x1D U2260 # НЕ РАВНО
0x1E U00A4 # ЗНАК ВАЛЮТЫ
0x1F U00B2 # СУПЕРСКРИПТ ДВА
0x20 U0020 # ПРОБЕЛ
0x21 U0021 # Восклицательный знак
0x22 U0022 # ЦИТАТНЫЙ ЗНАК
0x23 U0023 # НОМЕРНЫЙ ЗНАК
0x24 U0024 # ЗНАК ДОЛЛАРА
0x25 U0025 # ЗНАК ПРОЦЕНТА
0x26 U0026 # АМПЕРСАНД
0x27 U0027 # АПОСТРОФ
0x28 U0028 # ЛЕВЫЙ ПАРЕНТЕЗ
0x29 U0029 # ПРАВЫЙ ПАРЕНТЕЗ
0x2A U002A # ASTERISK
0x2B U002B # ПЛЮС ЗНАК
0x2C U002C # ЗАПЯТАЯ
0x2D U002D # ДЕФИС-МИНУС
0x2E U002E # ПОЛНАЯ ОСТАНОВКА
0x2F U002F # SOLIDUS
0x30 U0030 # ЦИФРОВОЙ НУЛЬ
0x31 U0031 # ЦИФРА ОДИН
0x32 U0032 # ЦИФРА ДВА
0x33 U0033 # ЦИФРА ТРИ
0x34 U0034 # ЦИФРА ЧЕТЫРЕ
0x35 U0035 # ЦИФРА ПЯТЬ
0x36 U0036 # ШЕСТЬ ЦИФРОВ
0x37 U0037 # ЦИФРА СЕМЬ
0x38 U0038 # ЦИФРА ВОСЬМАЯ
0x39 U0039 # ЦИФРА ДЕВЯТЬ
0x3A U003A # COLON
0x3B U003B # СЕМИКОЛОН
0x3C U003C # МЕНЬШЕ ЗНАКА
0x3D U003D # ЗНАК РАВНО
0x3E U003E # БОЛЬШЕ, ЧЕМ ЗНАК
0x3F U003F # ВОПРОСНЫЙ ЗНАК
0x40 U0040 # КОММЕРЧЕСКИЙ АТ
0x41 U0041 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА A
0x42 U0042 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА B
0x43 U0043 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА C
0x44 U0044 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА D
0x45 U0045 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА E
0x46 U0046 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА F
0x47 U0047 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА G
0x48 U0048 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА H
0x49 U0049 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА I
0x4A U004A # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА J
0x4B U004B # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА K
0x4C U004C # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА L
0x4D U004D # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА M
0x4E U004E # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА N
0x4F U004F # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА O
0x50 U0050 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА P
0x51 U0051 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Q
0x52 U0052 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА R
0x53 U0053 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА S
0x54 U0054 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА T
0x55 U0055 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА U
0x56 U0056 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА V
0x57 U0057 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА W
0x58 U0058 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА X
0x59 U0059 # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Y
0x5A U005A # ЗАГЛАВНАЯ ЛАТИНСКАЯ БУКВА Z
0x5B U005B # КВАДРАТНЫЙ КРОНШТЕЙН ЛЕВЫЙ
0x5C U005C # ОБРАТНЫЙ SOLIDUS
0x5D U005D # КРОНШТЕЙН ПРАВЫЙ КВАДРАТНЫЙ
0x5E U005E # CIRCUMFLEX ACCENT
0x5F U005F # НИЗКАЯ СТРОКА
0x60 U0060 # GRAVE ACCENT
0x61 U0061 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА A
0x62 U0062 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА B
0x63 U0063 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА C
0x64 U0064 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА D
0x65 U0065 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА E
0x66 U0066 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА F
0x67 U0067 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА G
0x68 U0068 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА H
0x69 U0069 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА I
0x6A U006A # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА J
0x6B U006B # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА K
0x6C U006C # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА L
0x6D U006D # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА M
0x6E U006E # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА N
0x6F U006F # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА O
0x70 U0070 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА P
0x71 U0071 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Q
0x72 U0072 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА R
0x73 U0073 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА S
0x74 U0074 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА T
0x75 U0075 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА U
0x76 U0076 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА V
0x77 U0077 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА W
0x78 U0078 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА X
0x79 U0079 # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Y
0x7A U007A # СТРОЧНАЯ ЛАТИНСКАЯ БУКВА Z
0x7B U007B # КРОНШТЕЙН ЛЕВЫЙ ИЗОЛИРУЮЩИЙ
0x7C U007C # ВЕРТИКАЛЬНАЯ ЛИНИЯ
0x7D U007D # ПРАВЫЙ КРОНШТЕЙН
0x7E U007E # ТИЛЬДА
0x7F U00AC # НЕ ПОДПИСАТЬ
0x80 U0402 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА DJE
0x81 U0403 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА GJE
0x82 U00B8 # CEDILLA
0x83 U0453 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА GJE
0x84 U201E # ДВОЙНОЙ ЦИТАТНЫЙ ЗНАК НИЗКОГО-9
0x85 U2026 # ГОРИЗОНТАЛЬНЫЙ ЭЛЛИПСИС
0x86 U2020 # КИНЖАЛ
0x87 U00A7 # ЗНАК РАЗДЕЛА
0x88 U20AC # ЗНАК ЕВРО
0x89 U00A8 # ДИАРЕЗИС
0x8A U0409 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА LJE
0x8B U2039 # ОДИН ЛЕВЫЙ УГОЛ ЦИТАТЫ
0x8C U040A # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА NJE
0x8D U040C # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА KJE
0x8E U040B # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА TSHE
0x8F U040F # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ДЖЕ
0x90 U0452 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА DJE
0x91 U2018 # ОДИН ЦИТАТНЫЙ МАРК ЛЕВЫЙ
0x92 U2019 # ОДИНОЧНЫЙ ЦИТАТНЫЙ ЗНАК ПРАВЫЙ
0x93 U201C # ЛЕВЫЙ ДВОЙНОЙ ЦИТАТНЫЙ МАРК
0x94 U201D # ПРАВЫЙ ДВОЙНОЙ ЗНАК
0x95 U2022 # ПУЛЯ
0x96 U2013 # EN DASH
0x97 U2014 # EM DASH
0x98 U00A3 # ЗНАК ФУНТА
0x99 U00B7 # СРЕДНЯЯ ТОЧКА
0x9A U0459 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА LJE
0x9B U203A # ОДИН УГЛОВОЙ УКАЗАТЕЛЬ ВПРАВО ЦИТАТНЫЙ МАРК
0x9C U045A # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА NJE
0x9D U045C # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА KJE
0x9E U045B # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА TSHE
0x9F U045F # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ДЖЕ
0xA0 U00A0 # ПРОБЕЛ БЕЗ ПЕРЕРЫВА
0xA1 U0475 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ИЖИЦА
0xA2 U0463 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА YAT '
0xA3 U0451 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА IO
0xA4 U0454 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА УКРАИНСКИЙ IE
0xA5 U0455 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА DZE
0xA6 U0456 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА БЕЛОРУССКО-УКРАИНСКАЯ I
0xA7 U0457 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА YI
0xA8 U0458 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА JE
0xA9 U00AE # ЗАРЕГИСТРИРОВАННЫЙ ЗНАК
0xAA U2122 # ЗНАК ТОВАРНОЙ МАРКИ
0xAB U00AB # ДВОЙНОЙ УГЛОВОЙ ЦИТАТНЫЙ МАРК, УКАЗАННЫЙ ВЛЕВО
0xAC U0473 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА FITA
0xAD U0491 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА GHE С ПОВОРОТОМ
0xAE U045E # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА КОРОТКАЯ U
0xAF U00B4 # ОСТРЫЙ АКЦЕНТ
0xB0 U00B0 # ЗНАК СТЕПЕНИ
0xB1 U0474 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ИЖИЦА
0xB2 U0462 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА YAT '
0xB3 U0401 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА IO
0xB4 U0404 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА УКРАИНСКИЙ IE
0xB5 U0405 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА DZE
0xB6 U0406 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА БЕЛОРУССКО-УКРАИНСКОЕ I
0xB7 U0407 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА YI
0xB8 U0408 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА JE
0xB9 U2116 # ЗНАК ЧИСЛА
0xBA U00A2 # ЦЕНТРАЛЬНЫЙ ЗНАК
0xBB U00BB # ДВОЙНОЙ УГЛОВОЙ ЦИТАТНЫЙ МАРК, УКАЗАННЫЙ ВПРАВО
0xBC U0472 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА FITA
0xBD U0490 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА GHE С ПОВОРОТОМ
0xBE U040E # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА КОРОТКАЯ U
0xBF U00A9 # ЗНАК АВТОРСКОГО ПРАВА
0xC0 U044E # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА YU
0xC1 U0430 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА A
0xC2 U0431 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА BE
0xC3 U0446 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА TSE
0xC4 U0434 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА DE
0xC5 U0435 # КИРИЛИЧЕСКАЯ СТРОЧНАЯ БУКВА IE
0xC6 U0444 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА EF
0xC7 U0433 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА GHE
0xC8 U0445 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА HA
0xC9 U0438 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА I
0xCA U0439 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА КОРОТКАЯ I
0xCB U043A # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА KA
0xCC U043B # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА EL
0xCD U043C # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА EM
0xCE U043D # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА EN
0xCF U043E # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА O
0xD0 U043F # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА PE
0xD1 U044F # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА YA
0xD2 U0440 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ER
0xD3 U0441 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ES
0xD4 U0442 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА TE
0xD5 U0443 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА U
0xD6 U0436 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ZHE
0xD7 U0432 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА VE
0xD8 U044C # КИРИЛИЧЕСКАЯ СТРОЧНАЯ БУКВА МЯГКИЙ ЗНАК
0xD9 U044B # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА YERU
0xDA U0437 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ZE
0xDB U0448 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА SHA
0xDC U044D # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА E
0xDD U0449 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА ЩА
0xDE U0447 # СТРОЧНАЯ КИРИЛИЧЕСКАЯ БУКВА CHE
0xDF U044A # КИРИЛИЧЕСКАЯ СТРОЧНАЯ БУКВА ЖЕСТКИЙ ЗНАК
0xE0 U042E # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА YU
0xE1 U0410 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА A
0xE2 U0411 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА BE
0xE3 U0426 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА TSE
0xE4 U0414 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА DE
0xE5 U0415 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА IE
0xE6 U0424 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА EF
0xE7 U0413 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА GHE
0xE8 U0425 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА HA
0xE9 U0418 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА I
0xEA U0419 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА КОРОТКАЯ I
0xEB U041A # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА KA
0xEC U041B # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА EL
0xED U041C # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА EM
0xEE U041D # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА EN
0xEF U041E # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА O
0xF0 U041F # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА PE
0xF1 U042F # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА YA
0xF2 U0420 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ER
0xF3 U0421 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ES
0xF4 U0422 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА TE
0xF5 U0423 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА U
0xF6 U0416 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ZHE
0xF7 U0412 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА VE
0xF8 U042C # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА МЯГКИЙ ЗНАК
0xF9 U042B # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ЙЕРУ
0xFA U0417 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ZE
0xFB U0428 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА SHA
0xFC U042D # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА E
0xFD U0429 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ЩА
0xFE U0427 # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА CHE
0xFF U042A # КИРИЛИЧЕСКАЯ ЗАГЛАВНАЯ БУКВА ЖЕСТКИЙ ЗНАК
Соображения безопасности
Эта памятка не поднимает известных проблем безопасности.Благодарности
Автор благодарит Маркуса Куна (Computer Science
Лаборатория Кембриджского университета, Великобритания) за помощь в создании
Таблица кодировки KOI8-C.
Рекомендации
[1] Чернов А., «Регистрация набора символов кириллицы», RFC.
1489 г., июль 1993 г.
[2] Украинский набор символов KOI8-U, RFC 2319. 1998.
Адрес автора
Серж Виницки
4 Аризона Тер. # 2
Арлингтон, Массачусетс 02474
США
Инструмент кодирования / декодирования. Анализируйте проблемы и ошибки кодировки символов.
Что такое кодовая страница?
Кодовая страница — это еще одно название для кодировки символов. Он состоит из таблицы значений который описывает набор символов для определенного языка.
Что такое кодировка символов?
Кодировка символов — это процесс кодирования набора символов в соответствии с системой кодирования. Этот процесс обычно объединяет числа с символами для кодирования информации, которая может использоваться компьютером.
Зачем нужно кодировать символы?
Поскольку компьютеры могут интерпретировать только необработанные нули и единицы (например, 01100110), слова и предложения необходимо кодировать при вводе информации в компьютер. Символы в этих словах и предложениях сгруппированы в набор символов, который компьютер может распознать.
Что такое кодировки символов?
Кодировки символов позволяют нам понять кодировку, используемую в компьютерах. Из-за наличия множества кодировок символов могут возникать ошибки при кодировании с помощью одной кодировки символов и декодировании с помощью другой.Вышеупомянутый инструмент можно использовать для моделирования, если возникнут какие-либо ошибки при кодировании с любой кодировкой символов и декодировании с помощью другой.
Типы кодировок символов
Существует множество кодировок, которые можно использовать для кодирования или декодирования строки символов, включая UTF-8, ASCII и ISO 9959-1.
Примеры популярных кодировок символов:
- ASCII: Американский стандартный код для обмена информацией
- ANSI: Американский национальный институт стандартов
- Unicode (внутренние текстовые коды, используемые операционными системами)
- UTF -8 (формат преобразования Unicode, в котором для представления символов используется 1 байт)
- UTF-16 (формат преобразования Unicode, который использует 2 байта для представления символов)
- UTF-32 (формат преобразования Unicode, который использует 4 байта для представления символов)
Хотя это, безусловно, популярные кодировки, которые используются, бывают случаи, когда строки кода кодируются с помощью кодировок, которые не так широко используются, например x-IA5-Norgwegian или DOS-720.