Абзац, абзацный отступ (красная строка)
- Абзацы
- Красная строка
Абзацы
Любой текст имеет свою уникальную структуру: книги разделены на части, разделы и главы, газеты и журналы имеет отдельные рубрики и подзаголовки, которые, в свою очередь, включают фрагменты текста, также имеющие собственную структуру: абзацы, отступы и пр.
Текст, размещаемый на веб-страницах, не является исключением, он также должен иметь логическую, понятную каждому пользователю, структуру. Ведь от того, насколько удобно и просто будет восприниматься текст на странице, зависит многое: прежде всего, какое впечатление сложится у посетителя о вашем сайте.
Для создания таких структурных единиц текста, как абзацы, в HTML-документах используется тег <p>, который разделяет фрагменты текста вертикальным отступом (до и после абзаца добавляется пустая строка).
<p>Абзац</p>
Примечание: по умолчанию расстояние между абзацами равно 1em (em — это единица измерения равная высоте шрифта), то есть расстояние между абзацами напрямую зависит от размера шрифта.
Для изменения отступов между абзацами, без изменения размера шрифта, можно воспользоваться CSS свойством margin.
Не забывайте про закрывающий тег
Большинство браузеров будут отображать HTML документ корректно, даже если вы забыли про закрывающий тег.
<p>Абзац <p>Другой абзац</p>
Этот код будет работать в большинстве браузеров, но не полагайтесь на это. Забытый закрывающий тег может привести к непредвиденным результатам или ошибкам.
Красная строка
Что такое красная строка? Согласно определению, это начальная строка абзаца, которую раньше выделяли красным цветом (откуда и пошло название). До того, как было изобретено книгопечатание, книги писали от руки – главу или часть текста, первое слово или букву писали красной краской. Так появилось понятие «писать с красной строки» — это означает начало новой мысли, главы или части.
Однако при создании веб-страниц оформление красной строки используется достаточно редко, несмотря на то, что она позволяет с гораздо большим удобством воспринимать текст в визуальном плане, что для традиционного читателя достаточно важно – не всем удобно читать электронный вариант текста.
Для добавления красной строки к вашим абзацам нужно воспользоваться CSS свойством text-indent, которое позволяет поставить отступ перед первым предложением:
<html>
<head>
<style>
p { text-indent: 25px; }
</style>
<head>
<body>
<p>
Как и в любом настоящем искусстве, в хороших текстах нет мелочей, к которым
некоторые относят и красную строку, считая, что употребление ее не так уж и важно.
Однако надо понимать, что любая запятая несет в себе как эстетическую, так
и смысловую нагрузку, а не только является данью правилам грамматики – это
касается и форматирования.
</p>
</body>
</html>
В примере, приведенном выше, первая строка каждого абзаца на странице будет начинаться с отступа в 25px. Пример, расположенный ниже, демонстрирует, как можно задать красную строку только для определенного абзаца на странице.
<p> Как и в любом настоящем искусстве, в хороших текстах нет мелочей, к которым некоторые относят и красную строку, считая, что употребление ее не так уж и важно. Однако надо понимать, что любая запятая несет в себе как эстетическую, так и смысловую нагрузку, а не только является данью правилам грамматики – это касается и форматирования. </p>Попробовать »
Примечание: не обязательно устанавливать отступ размером в 25px, вы можете выбрать оптимальный размер отступа сами, также с помощью свойства text-indent возможно сделать выступающую над остальным текстом строку, для этого нужно задать отрицательное значение для свойства ( например: -30px).
С этой темой смотрят:
- HTML заголовки, линии и комментарии
- HTML перенос строки
- HTML теги для текста
- Выравнивание текста
- Как изменить шрифт
- Стиль и размер шрифта
Модуль BeautifulSoup4 в Python, разбор HTML.

Извлечение данных из документов HTML и XML.
BeautifulSoup4 (bs4) — это библиотека Python для извлечения данных из файлов HTML и XML. Для естественной навигации, поиска и изменения дерева HTML, модуль BeautifulSoup4, по умолчанию использует встроенный в Python парсер html.parser. BS4 так же поддерживает ряд сторонних парсеров Python, таких как lxml, html5lib и xml (для разбора XML-документов).
Установка BeautifulSoup4 в виртуальное окружение:
# создаем виртуальное окружение, если нет $ python3 -m venv .venv --prompt VirtualEnv # активируем виртуальное окружение $ source .venv/bin/activate # ставим модуль beautifulsoup4 (VirtualEnv):~$ python3 -m pip install -U beautifulsoup4Содержание:
- Выбор парсера для использования в BeautifulSoup4.
- Парсер
lxml. - Парсер
html5lib. - Встроенный в Python парсер
html.parser.
- Парсер
- Основные приемы работы с BeautifulSoup4.

- Навигация по структуре HTML-документа.
- Извлечение URL-адресов.
- Извлечение текста HTML-страницы.
- Поиск тегов по HTML-документу.
- Поиск тегов при помощи CSS селекторов.
- Дочерние элементы.
- Родительские элементы.
- Изменение имен тегов HTML-документа.
- Добавление новых тегов в HTML-документ.
- Удаление и замена тегов в HTML-документе.
- Изменение атрибутов тегов HTML-документа.
Выбор парсера для использования в BeautifulSoup4.
BeautifulSoup4 представляет один интерфейс для разных парсеров, но парсеры неодинаковы. Разные парсеры, анализируя один и того же документ создадут различные деревья HTML. Самые большие различия будут между парсерами HTML и XML. Так же парсеры различаются скоростью разбора HTML документа.
Если дать BeautifulSoup4 идеально оформленный документ HTML, то различий построенного HTML-дерева не будет. Один парсер будет быстрее другого, но все они будут давать структуру, которая выглядит точно так же, как оригинальный документ HTML. Но если документ оформлен с ошибками, то различные парсеры дадут разные результаты.
Но если документ оформлен с ошибками, то различные парсеры дадут разные результаты.
Различия в построении HTML-дерева разными парсерами, разберем на короткой HTML-разметке: <a></p>.
Парсер
lxml.Характеристики:
- Для запуска примера, необходимо установить модуль
- Очень быстрый, имеет внешнюю зависимость от языка C.
- Нестрогий.
>>> from bs4 import BeautifulSoup
>>> BeautifulSoup("<a></p>", "lxml")
# <html><body><a></a></body></html>
Обратите внимание, что тег <a> заключен в теги <body> и <html>, а висячий тег </p> просто игнорируется.
Парсер
html5lib.Характеристики:
- Для запуска примера, необходимо установить модуль
html5lib. - Ну очень медленный.
- Разбирает страницы так же, как это делает браузер, создавая валидный HTML5.

>>> from bs4 import BeautifulSoup
>>> BeautifulSoup("<a></p>", "html5lib")
# <html><head></head><body><a><p></p></a></body></html>
Обратите внимание, что парсер html5lib НЕ игнорирует висячий тег </p>, и к тому же добавляет открывающий тег <p>. Также html5lib добавляет пустой тег <head> (lxml этого не сделал).
Встроенный в Python парсер
html.parser.Характеристики:
- Не требует дополнительной установки.
- Приличная скорость, но не такой быстрый, как
lxml. - Более строгий, чем
html5lib.
>>> from bs4 import BeautifulSoup
>>> BeautifulSoup("<a></p>", 'html.parser')
# <a></a>
Как и lxml, встроенный в Python парсер игнорирует закрывающий тег </p>. В отличие от
В отличие от html5lib, этот парсер не делает попытки создать правильно оформленный HTML-документ, добавив теги <body>.
Вывод: Парсер html5lib использует способы, которые являются частью стандарта HTML5, поэтому он может претендовать на то, что его подход самый «правильный«.
Основные приемы работы с BeautifulSoup4.
Чтобы разобрать HTML-документ, необходимо передать его в конструктор класса BeautifulSoup(). Можно передать строку или открытый дескриптор файла:
from bs4 import BeautifulSoup
# передаем объект открытого файла
with open("index.html") as fp:
soup = BeautifulSoup(fp, 'html.parser')
# передаем строку
soup = BeautifulSoup("<html>a web page</html>", 'html.parser')
Первым делом документ конвертируется в Unicode, а HTML-мнемоники конвертируются в символы Unicode:
>>> from bs4 import BeautifulSoup >>> html = "<html><head></head><body>Sacré bleu!</body></html>" >>> parse = BeautifulSoup(html, 'html.parser') >>> print(parse) # <html><head></head><body>Sacré bleu!</body></html>
Дальнейшие примеры будут разбираться на следующей HTML-разметке.
html_doc = """<html><head><title>The Dormouse's story</title></head> <body> <p><b>The Dormouse's story</b></p> <p>Once upon a time there were three little sisters; and their names were <a href="http://example.com/elsie">Elsie</a>, <a href="http://example.com/lacie">Lacie</a> and <a href="http://example.com/tillie">Tillie</a>; and they lived at the bottom of a well.</p> <p>...</p>"""
Передача этого HTML-документа в конструктор класса BeautifulSoup() создает объект, который представляет документ в виде вложенной структуры:
>>> from bs4 import BeautifulSoup >>> soup = BeautifulSoup(html_doc, 'html.parser') >>> print(soup.prettify()) # <html> # <head> # <title> # The Dormouse's story # </title> # </head> # <body> # <p> # <b> # The Dormouse's story # </b> # </p> # <p> # Once upon a time there were three little sisters; and their names were # <a href="http://example.com/elsie"> # Elsie # </a> # , # <a href="http://example.com/lacie"> # Lacie # </a> # and # <a href="http://example.com/tillie"> # Tillie # </a> # ; and they lived at the bottom of a well. # </p> # <p> # ... # </p> # </body> # </html>
Навигация по структуре HTML-документа:
# извлечение тега `title` >>> soup.title # <title>The Dormouse's story</title> # извлечение имя тега >>> soup.title.name # 'title' # извлечение текста тега >>> soup.title.string # 'The Dormouse's story' # извлечение первого тега `<p>` >>> soup.p # <p><b>The Dormouse's story</b></p> # извлечение второго тега `<p>` и # представление его содержимого списком >>> soup.find_all('p')[1].contents # ['Once upon a time there were three little sisters; and their names were\n', # <a href="http://example.com/elsie">Elsie</a>, # ',\n', # <a href="http://example.com/lacie">Lacie</a>, # ' and\n', # <a href="http://example.com/tillie">Tillie</a>, # ';\nand they lived at the bottom of a well.'] # выдаст то же самое, только в виде генератора >>> soup.find_all('p')[1].strings # <generator object Tag._all_strings at 0x7ffa2eb43ac0>
Перемещаться по одному уровню можно при помощи атрибутов .previous_sibling и .next_sibling. Например, в представленном выше HTML, теги <a> обернуты в тег <p> — следовательно они находятся на одном уровне.
>>> first_a = soup.a >>> first_a # <a href="http://example.com/elsie">Elsie</a> >>> first_a.previous_sibling # 'Once upon a time there were three little sisters; and their names were\n' >>> next = first_a.next_sibling >>> next # ',\n' >>> next.next_sibling # <a href="http://example.com/lacie">Lacie</a>
Так же можно перебрать одноуровневые элементы данного тега с помощью .next_siblings или .previous_siblings.
for sibling in soup.a.next_siblings:
print(repr(sibling))
# ',\n'
# <a href="http://example.com/lacie">Lacie</a>
# ' and\n'
# <a href="http://example.com/tillie">Tillie</a>
# '; and they lived at the bottom of a well.'
for sibling in soup.find(id="link3").previous_siblings:
print(repr(sibling))
# ' and\n'
# <a href="http://example.com/lacie">Lacie</a>
# ',\n'
# <a href="http://example.com/elsie">Elsie</a>
# 'Once upon a time there were three little sisters; and their names were\n'
Атрибут . строки или HTML-тега указывает на то, что было разобрано непосредственно после него. Это могло бы быть тем же, что и 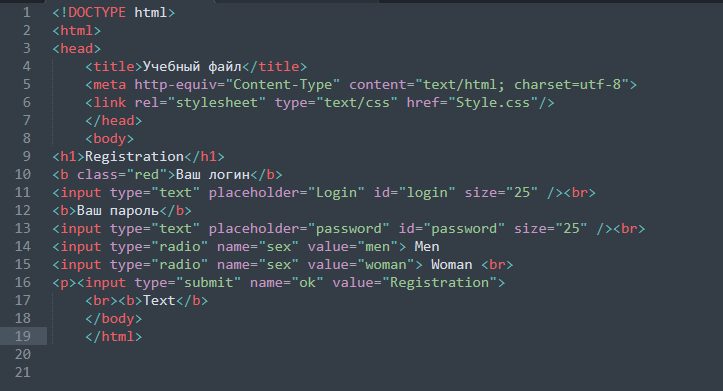 next_element
next_element.next_sibling, но обычно результат резко отличается.
Возьмем последний тег <a>, его .next_sibling является строкой: конец предложения, которое было прервано началом тега <a>:
last_a = soup.find("a",)
last_a
# <a href="http://example.com/tillie">Tillie</a>
last_a.next_sibling
# ';\nand they lived at the bottom of a well.'
Однако .next_element этого тега <a> — это то, что было разобрано сразу после тега <a> — это слово Tillie, а не остальная часть предложения.
last_a_tag.next_element # 'Tillie'
Это потому, что в оригинальной разметке слово Tillie появилось перед точкой с запятой. Парсер обнаружил тег <a>, затем слово Tillie, затем закрывающий тег </a>, затем точку с запятой и оставшуюся часть предложения. Точка с запятой находится на том же уровне, что и тег
Точка с запятой находится на том же уровне, что и тег <a>, но слово Tillie встретилось первым.
Атрибут .previous_element является полной противоположностью .next_element. Он указывает на элемент, который был обнаружен при разборе непосредственно перед текущим:
last_a_tag.previous_element # ' and\n' last_a_tag.previous_element.next_element # <a href="http://example.com/tillie">Tillie</a>
При помощи атрибутов .next_elements и .previous_elements можно получить список элементов, в том порядке, в каком он был разобран парсером.
for element in last_a_tag.next_elements:
print(repr(element))
# 'Tillie'
# ';\nand they lived at the bottom of a well.'
# '\n'
# <p>...</p>
# '...'
# '\n'
Извлечение URL-адресов.
Одна из распространенных задач, это извлечение URL-адресов, найденных на странице в HTML-тегах <a>:
>>> for a in soup.find_all('a'): ... print(a.get('href')) # http://example.com/elsie # http://example.com/lacie # http://example.com/tillie
Извлечение текста HTML-страницы.
Другая распространенная задача — извлечь весь текст со HTML-страницы:
# Весь текст HTML-страницы с разделителями `\n`
>>> soup.get_text('\n', strip='True')
# "The Dormouse's story\nThe Dormouse's story\n
# Once upon a time there were three little sisters; and their names were\n
# Elsie\n,\nLacie\nand\nTillie\n;\nand they lived at the bottom of a well.\n..."
# а можно создать список строк, а потом форматировать как надо
>>> [text for text in soup.stripped_strings]
# ["The Dormouse's story",
# "The Dormouse's story",
# 'Once upon a time there were three little sisters; and their names were',
# 'Elsie',
# ',',
# 'Lacie',
# 'and',
# 'Tillie',
# ';\nand they lived at the bottom of a well.',
# '...']
Поиск тегов по HTML-документу:
Найти первый совпавший HTML-тег можно методом BeautifulSoup., а всех совпавших элементов — 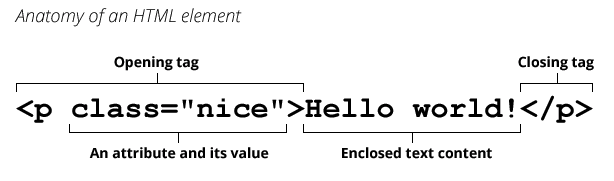 find()
find()BeautifulSoup.find_all().
# ищет все теги `<title>`
>>> soup.find_all("title")
# [<title>The Dormouse's story</title>]
# ищет все теги `<a>` и все теги `<b>`
>>> soup.find_all(["a", "b"])
# [<b>The Dormouse's story</b>,
# <a href="http://example.com/elsie">Elsie</a>,
# <a href="http://example.com/lacie">Lacie</a>,
# <a href="http://example.com/tillie">Tillie</a>]
# ищет все теги `<p>` с CSS классом "title"
>>> soup.find_all("p", "title")
# [<p><b>The Dormouse's story</b></p>]
# ищет все теги с CSS классом, в именах которых встречается "itl"
soup.find_all(class_=re.compile("itl"))
# [<p><b>The Dormouse's story</b></p>]
# ищет все теги с
>>> soup.find_all(id="link2")
# [<a href="http://example.com/lacie">Lacie</a>]
# ищет все теги `<a>`, содержащие указанные атрибуты
>>> soup. b")):
print(tag.name)
# body
# b
# ищет все теги в документе, но не текстовые строки
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
# p
b")):
print(tag.name)
# body
# b
# ищет все теги в документе, но не текстовые строки
for tag in soup.find_all(True):
print(tag.name)
# html
# head
# title
# body
# p
# b
# p
# a
# a
# a
# p
Поиск тегов при помощи CSS селекторов:
>>> soup.select("title")
# [<title>The Dormouse's story</title>]
>>> soup.select("p:nth-of-type(3)")
# [<p>...</p>]
Поиск тега под другими тегами:
>>> soup.select("body a")
# [<a href="http://example.com/elsie">Elsie</a>,
# <a href="http://example.com/lacie" >Lacie</a>,
# <a href="http://example.com/tillie">Tillie</a>]
>>> soup.select("html head title")
# [<title>The Dormouse's story</title>]
Поиск тега непосредственно под другими тегами:
>>> soup.select("head > title")
# [<title>The Dormouse's story</title>]
>>> soup.select("p > a:nth-of-type(2)")
# [<a href="http://example. com/lacie">Lacie</a>]
>>> soup.select("p > #link1")
# [<a href="http://example.com/elsie">Elsie</a>]
com/lacie">Lacie</a>]
>>> soup.select("p > #link1")
# [<a href="http://example.com/elsie">Elsie</a>]
Поиск одноуровневых элементов:
# поиск всех `.sister` в которых нет `#link1`
>>> soup.select("#link1 ~ .sister")
# [<a href="http://example.com/lacie">Lacie</a>,
# <a href="http://example.com/tillie" >Tillie</a>]
# поиск всех `.sister` в которых есть `#link1`
>>> soup.select("#link1 + .sister")
# [<a href="http://example.com/lacie">Lacie</a>]
# поиск всех `<a>` у которых есть сосед `<p>`
Поиск тега по классу CSS:
>>> soup.select(".sister")
# [<a href="http://example.com/elsie">Elsie</a>,
# <a href="http://example.com/lacie">Lacie</a>,
# <a href="http://example.com/tillie">Tillie</a>]
Поиск тега по ID:
>>> soup.select("#link1")
# [<a href="http://example.com/elsie">Elsie</a>]
>>> soup.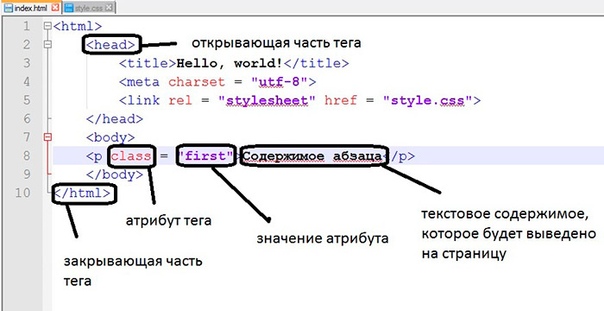 select("a#link2")
# [<a href="http://example.com/lacie">Lacie</a>]
select("a#link2")
# [<a href="http://example.com/lacie">Lacie</a>]
Дочерние элементы.
Извлечение НЕПОСРЕДСТВЕННЫХ дочерних элементов тега. Если посмотреть на HTML-разметку в коде ниже, то, непосредственными дочерними элементами первого <ul> будут являться три тега <li> и тег <ul> со всеми вложенными тегами.
Обратите внимание, что все переводы строк \n и пробелы между тегами, так же будут считаться дочерними элементами. Так что имеет смысл заранее привести исходный HTML к «нормальному виду«, например так: re.sub(r'>\s+<', '><', html.replace('\n', ''))
html = """
<div>
<ul>
<li>текст 1</li>
<li>текст 2</li>
<ul>
<li>текст 2-1</li>
<li>текст 2-2</li>
</ul>
<li>текст 3</li>
</ul>
</div>
"""
>>> from bs4 import BeautifulSoup
>>> root = BeautifulSoup(html, 'html. parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список непосредственных дочерних элементов
# переводы строк `\n` и пробелы между тегами так же
# распознаются как дочерние элементы
>>> first_ul.contents
# ['\n', <li>текст 1</li>, '\n', <li>текст 2</li>, '\n', <ul>
# <li>текст 2-1</li>
# <li>текст 2-2</li>
# </ul>, '\n', <li>текст 3</li>, '\n']
# убираем переводы строк `\n` как из списка, так и из тегов
# лучше конечно сразу убрать переводы строк из исходного HTML
>>> [str(i).replace('\n', '') for i in first_ul.contents if str(i) != '\n']
# ['<li>текст 1</li>',
# '<li>текст 2</li>',
# '<ul><li>текст 2-1</li><li>текст 2-2</li></ul>',
# '<li>текст 3</li>']
# то же самое, что и `first_ul.contents`
# только в виде итератора
>>> first_ul.children
# <list_iterator object at 0x7ffa2eb52460>
parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список непосредственных дочерних элементов
# переводы строк `\n` и пробелы между тегами так же
# распознаются как дочерние элементы
>>> first_ul.contents
# ['\n', <li>текст 1</li>, '\n', <li>текст 2</li>, '\n', <ul>
# <li>текст 2-1</li>
# <li>текст 2-2</li>
# </ul>, '\n', <li>текст 3</li>, '\n']
# убираем переводы строк `\n` как из списка, так и из тегов
# лучше конечно сразу убрать переводы строк из исходного HTML
>>> [str(i).replace('\n', '') for i in first_ul.contents if str(i) != '\n']
# ['<li>текст 1</li>',
# '<li>текст 2</li>',
# '<ul><li>текст 2-1</li><li>текст 2-2</li></ul>',
# '<li>текст 3</li>']
# то же самое, что и `first_ul.contents`
# только в виде итератора
>>> first_ul.children
# <list_iterator object at 0x7ffa2eb52460>
Извлечение ВСЕХ дочерних элементов. Эта операция похожа на рекурсивный обход HTML-дерева в глубину от выбранного тега.
Эта операция похожа на рекурсивный обход HTML-дерева в глубину от выбранного тега.
>>> import re
# сразу уберем переводы строк из исходного HTML
>>> html = re.sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем в дереве первый тег `<ul>`
>>> first_ul = root.ul
# извлекаем список ВСЕХ дочерних элементов
>>> list(first_ul.descendants)
# [<li>текст 1</li>,
# 'текст 1',
# <li>текст 2</li>,
# 'текст 2',
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
# <li>текст 2-1</li>,
# 'текст 2-1',
# <li>текст 2-2</li>,
# 'текст 2-2',
# <li>текст 3</li>,
# 'текст 3']
Обратите внимание, что простой текст, который находится внутри тега, так же считается дочерним элементом этого тега.
Если внутри тега есть более одного дочернего элемента (как в примерен выше) и необходимо извлечь только текст, то можно использовать атрибут . или генератор  strings
strings.stripped_strings.
Генератор .stripped_strings дополнительно удаляет все переводы строк \n и пробелы между тегами в исходном HTML-документе.
>>> list(first_ul.strings) # ['текст 1', 'текст 2', 'текст 2-1', 'текст 2-2', 'текст 3'] >>> first_ul.stripped_strings # <generator object Tag.stripped_strings at 0x7ffa2eb43ac0> >>> list(first_ul.stripped_strings) # ['текст 1', 'текст 2', 'текст 2-1', 'текст 2-2', 'текст 3']
Родительские элементы.
Что бы получить доступ к родительскому элементу, необходимо использовать атрибут .parent.
html = """
<div>
<ul>
<li>текст 1</li>
<li>текст 2</li>
<ul>
<li>текст 2-1</li>
<li>текст 2-2</li>
</ul>
<li>текст 3</li>
</ul>
</div>
"""
>>> from bs4 import BeautifulSoup
>>> import re
# сразу уберем переводы строк и пробелы
# между тегами из исходного HTML
>>> html = re. sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем теги `<li>` вложенные во второй `<ul>`,
# используя CSS селекторы
>>> child_ul = root.select('ul > ul > li')
>>> child_ul
# [<li>текст 2-1</li>, <li>текст 2-2</li>]
# получаем доступ к родителю
>>> child_li[0].parent
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>
# доступ к родителю родителя
>>> child_li[0].parent.parent.contents
[<li>текст 1</li>,
<li>текст 2</li>,
<ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
<li>текст 3</li>]
sub(r'>\s+<', '><', html.replace('\n', ''))
>>> root = BeautifulSoup(html, 'html.parser')
# найдем теги `<li>` вложенные во второй `<ul>`,
# используя CSS селекторы
>>> child_ul = root.select('ul > ul > li')
>>> child_ul
# [<li>текст 2-1</li>, <li>текст 2-2</li>]
# получаем доступ к родителю
>>> child_li[0].parent
# <ul><li>текст 2-1</li><li>текст 2-2</li></ul>
# доступ к родителю родителя
>>> child_li[0].parent.parent.contents
[<li>текст 1</li>,
<li>текст 2</li>,
<ul><li>текст 2-1</li><li>текст 2-2</li></ul>,
<li>текст 3</li>]
Taк же можно перебрать всех родителей элемента с помощью атрибута .parents.
>>> child_li[0] # <li>текст 2-1</li> >>> [parent.name for parent in child_li[0].parents] # ['ul', 'ul', 'div', '[document]']
Изменение имен тегов HTML-документа:
>>> soup = BeautifulSoup('<p><b>Extremely bold</b></p>', 'html. parser')
>>> tag = soup.b
# присваиваем новое имя тегу
>>> tag.name = "blockquote"
>>> tag
# <blockquote>Extremely bold</blockquote>
>>> soup
# <p><blockquote>Extremely bold</blockquote></p>
parser')
>>> tag = soup.b
# присваиваем новое имя тегу
>>> tag.name = "blockquote"
>>> tag
# <blockquote>Extremely bold</blockquote>
>>> soup
# <p><blockquote>Extremely bold</blockquote></p>
Изменение HTML-тега <p> на тег <div>:
>>> soup = BeautifulSoup('<p><b>Extremely bold</b></p>', 'html.parser')
>>> soup.p.name = 'div'
>>> soup
# <div><b>Extremely bold</b></div>
Добавление новых тегов в HTML-документ.
Добавление нового тега в дерево HTML:
>>> soup = BeautifulSoup("<p><b></b></p>", 'html.parser')
>>> original_tag = soup.b
# создание нового тега `<a>`
>>> new_tag = soup.new_tag("a", href="http://example.com")
# строка нового тега `<a>`
>>> new_tag.string = "Link text"
# добавление тега `<a>` внутрь `<b>`
>>> original_tag. append(new_tag)
>>> original_tag
# <b><a href="http://example.com">Link text.</a></b>
>>> soup
# <p><b><a href="http://example.com">Link text</a></b></p>
append(new_tag)
>>> original_tag
# <b><a href="http://example.com">Link text.</a></b>
>>> soup
# <p><b><a href="http://example.com">Link text</a></b></p>
Добавление новых тегов до/после определенного тега или внутрь тега.
>>> soup = BeautifulSoup("<p><b>leave</b></p>", 'html.parser')
>>> tag = soup.new_tag("i",)
>>> tag.string = "Don't"
# добавление нового тега <i> до тега <b>
>>> soup.b.insert_before(tag)
>>> soup.b
# <p><i>Don't</i><b>leave</b></p>
# добавление нового тега <i> после тега <b>
>>> soup.b.insert_after(tag)
>>> soup
# <p><b>leave</b><i>Don't</i></p>
# добавление нового тега <i> внутрь тега <b>
>>> soup.b.string.insert_before(tag)
>>> soup.b
# <p><b><i>Don't</i>leave</b></p>
Удаление и замена тегов в HTML-документе.

Удаляем тег или строку из дерева HTML:
>>> html = '<a href="http://example.com/">I linked to <i>example.com</i></a>' >>> soup = BeautifulSoup(html, 'html.parser') >>> a_tag = soup.a # удаляем HTML-тег `<i>` с сохранением # в переменной `i_tag` >>> i_tag = soup.i.extract() # смотрим что получилось >>> a_tag # <a href="http://example.com/">I linked to</a> >>> i_tag # <i>example.com</i>
Заменяем тег и/или строку в дереве HTML:
>>> html = '<a href="http://example.com/">I linked to <i>example</i></a>'
>>> soup = BeautifulSoup(html, 'html.parser')
>>> a_tag = soup.a
# создаем новый HTML тег
>>> new_tag = soup.new_tag("b")
>>> new_tag.string = "sample"
# производим замену тега `<i>` внутри тега `<a>`
>>> a_tag.i.replace_with(new_tag)
>>> a_tag
# <a href="http://example. com/">I linked to <b>sample</b></a>
com/">I linked to <b>sample</b></a>
Изменение атрибутов тегов HTML-документа.
У тега может быть любое количество атрибутов. Тег <b id = "boldest"> имеет атрибут id, значение которого равно boldest. Доступ к атрибутам тега можно получить, обращаясь с тегом как со словарем:
>>> soup = BeautifulSoup('<p><b>bolder</b></p>', 'html.parser')
>>> tag = soup.b
>>> tag['id']
# 'boldest'
# доступ к словарю с атрибутами
>>> tag.attrs
# {'id': 'boldest'}
Можно добавлять и изменять атрибуты тега.
# изменяем `id` >>> tag['id'] = 'bold' # добавляем несколько значений в `class` >>> tag['class'] = ['new', 'bold'] # или >>> tag['class'] = 'new bold' >>> tag # <b>bolder</b>
А так же производить их удаление.
>>> del tag['id'] >>> del tag['class'] >>> tag # <b>bolder</b> >>> tag.get('id') # None
День очистки залива – Фонд Чесапикского залива
9:00-12:00
Это короткое трехчасовое ежегодное мероприятие имеет огромный кумулятивный эффект. С момента своего появления в 1989 году в этой традиции Вирджинии приняли участие более 165 500 добровольцев, которые убрали около 7,18 миллиона фунтов мусора с более чем 8 250 миль береговой линии.
Зарегистрируйтесь! Найдите место рядом с вами.
Ежегодно в первую субботу 9 июня0005 тысяч жителей Вирджинии одновременно спускаются по рекам, ручьям и пляжам водораздела Чесапикского залива, чтобы убрать вредный мусор и мусор. День очистки залива был одним из основных мероприятий сообщества Чесапикского залива в Вирджинии с момента его основания более трех десятилетий назад. Настоящая традиция Вирджинии, это ежегодная возможность для отдельных лиц, семей, военных объектов, предприятий, клубов, общественных и церковных групп отдать свои местные водные пути. Посмотрите наше видео, чтобы понять, почему так много людей участвует.
Посмотрите наше видео, чтобы понять, почему так много людей участвует.
Важная информация
Зарегистрироваться в программе Clean the Bay Day очень просто! Просмотрите карту или список очистных сооружений, выберите свой населенный пункт и зарегистрируйтесь или зарегистрируйте свою группу. Оттуда ваша информация отправляется партнеру Clean the Bay Day рядом с вами. Они свяжутся с вами, чтобы назначить вам конкретное место для уборки. Когда вы придете на День уборки залива, будьте готовы помочь убрать мусор и мусор. Все средства для уборки будут предоставлены на месте.
Если вы хотите сделать еще один шаг вперед, станьте капитаном зоны! Капитаны зон — ведущие добровольцы, которые наблюдают за своим участком очистки и другими добровольцами. Они собирают данные (общий вес мусора, количество добровольцев и т. д.), чтобы сообщить об этом своему партнеру по очистке залива. Вы можете добровольно стать капитаном зоны во время регистрации. Мы просим всех новых капитанов зон посетить виртуальную тренировку и помочь продвигать мероприятие, где это возможно. Это легко, и вы получите крутую шапку! Получите более подробную информацию на нашей веб-странице Zone Captain.
Мы просим всех новых капитанов зон посетить виртуальную тренировку и помочь продвигать мероприятие, где это возможно. Это легко, и вы получите крутую шапку! Получите более подробную информацию на нашей веб-странице Zone Captain.
Несмотря на то, что появление мусора легко предотвратить, и любой может собрать его в любое утро, борьба с основными невидимыми угрозами водосборному бассейну залива, такими как утрата мест обитания, загрязнение отложениями и питательными веществами, требует широкой и целенаправленной поддержки. День очистки залива часто выступает в качестве программы-ворота, с помощью которой дети и взрослые одинаково заботятся об окружающей среде своих водных путей. Мы надеемся, что вы поможете нам в нашей миссии по спасению залива, узнав больше о Чесапикском плане чистой воды, нашем лучшем шансе восстановить и защитить залив, его реки и ручьи.
День очистки залива основан на прочных и длительных отношениях между десятками городов и округов, некоммерческими организациями, военными объектами, малыми предприятиями и крупными корпорациями. В День очистки залива мы все собираемся вместе с семьями, отдельными лицами, церковными группами и выборными должностными лицами на местном уровне, уровне штата и на федеральном уровне для общей цели: чистая вода.
В День очистки залива мы все собираемся вместе с семьями, отдельными лицами, церковными группами и выборными должностными лицами на местном уровне, уровне штата и на федеральном уровне для общей цели: чистая вода.
Мы всегда рады новым партнерам и спонсорам, которые разделят с нами внимание! Если вы хотите узнать больше о том, как стать спонсором или партнером программы Clean the Bay Day , отправьте электронное письмо на адрес [email protected] или позвоните по номеру 757-644-4112.
Мы хотели бы поблагодарить всех волонтеров, партнеров и спонсоров, которые каждый год делают это мероприятие таким звездным. От имени CBF и всех водных путей Вирджинии, ведущих к заливу, спасибо.
Очистите залив
Ваша неделя DIY Way Не можете приехать 3 июня? Присоединяйтесь к нам на Clean the Bay Your Way — части этого ежегодного мероприятия, посвященной «сделай сам». С 4 по 10 июня вы можете самостоятельно проводить уборку на небольших участках, таких как ваша частная собственность, школа, рабочее место или любое другое место, где у вас есть разрешение. Пожалуйста, убедитесь, что вы можете самостоятельно утилизировать собранный мусор. Посетите Чистый залив Ваш веб-сайт Way для получения дополнительной информации.
Пожалуйста, убедитесь, что вы можете самостоятельно утилизировать собранный мусор. Посетите Чистый залив Ваш веб-сайт Way для получения дополнительной информации.
Фотоконкурс
В связи с непредвиденными обстоятельствами фотоконкурс Clean the Bay Day на 2023 год отменен. Следите за новостями в следующем году!
2022 Фотоальбом
Опубликовано Фондом Чесапикского залива в понедельник, 6 июня 2022 г.
Австралия| ИНПЕКС КОРПОРЕЙШН
Основные проекты
- 1. Проект Ichthys LNG
- 2.
 Прелюдия к проекту FLNG (WA-44-L)
Прелюдия к проекту FLNG (WA-44-L) - 3. Баю-Ундан Проект
- Другие
Проект Ichthys LNG и прилегающие разведочные блоки
Ихтис СПГ Проект
| Контрактная площадь (квартал) | Статус проекта | Производственная мощность | Венчурная компания (учреждена) | Доля в собственности ( * Оператор) |
|---|---|---|---|---|
| WA-50-L/ WA-51-L | В производстве | СПГ: примерно 8,9 млн тонн в год СНГ: примерно 1,65 млн тонн в год Конденсат: примерно 100 тысяч баррелей в сутки (в пик) | INPEX Ichthys Pty Ltd (5 апреля 2011 г.  ) ) | INPEX Ichthys Pty Ltd. JERA 0,735% Тохо Газ 0,420% |
В 1998 году INPEX получила разрешение на разведку в блоке, где сейчас расположено газоконденсатное месторождение Ихтис, и после исследований разработки, включая разведку, оценку и предварительные инженерно-технические работы (FEED), INPEX объявила о своем окончательном инвестиционном решении ( FID) в январе 2012 года. После завершения и ввода в эксплуатацию производственных мощностей INPEX начал производство в июле 2018 года, а затем начал отгрузку конденсата, СПГ и сжиженного нефтяного газа (СНГ). Стабильное производство продолжается с момента запуска производства в 2018 году, и в 2021 году с завода было отгружено 117 партий СПГ. Техническое обслуживание, необходимое для безопасной и стабильной работы, будет проводиться примерно в течение одного месяца, с июля по август 2022 года. Отгружено около 10 партий СПГ. грузов в месяц ожидается и в 2022 финансовом году. Мы совершенствуем производственный процесс, чтобы еще больше увеличить текущую производственную мощность СПГ в 8,9 тонн в год.млн тонн и создание основы для стабильных поставок 9,3 млн тонн в год к 2024 году.
Мы совершенствуем производственный процесс, чтобы еще больше увеличить текущую производственную мощность СПГ в 8,9 тонн в год.млн тонн и создание основы для стабильных поставок 9,3 млн тонн в год к 2024 году.
Внедрение CCS
Поддерживая и расширяя производство СПГ, INPEX решает проблему изменения климата, рассматривая проекты CCS для улавливания, подземной закачки и хранения CO 2 , выбрасываемого в результате наших производственных операций. В частности, мы планируем пробурить оценочные скважины в северной Австралии для внедрения CCS. В конце 2020-х годов мы внедрим технологию CCS в Ichthys и постараемся начать закачку 2 млн тонн CO 9 .0150 2 в год в качестве первого шага.
Окружающие разведочные блоки
| Контрактная площадь (блок) | Статус проекта | Венчурная компания (учреждена) | Доля в собственности ( * Оператор) |
|---|---|---|---|
| WA-84-R/WA-85-R/WA-86-R | На стадии разведки (блоки под оценкой на обнаружение газа и конденсата) | INPEX Browse E&P Pty Ltd (21 октября 2013 г.  ) ) | INPEX Обзор E&P Pty Ltd 40% Santos * 60% |
| ВА-56-Р | INPEX Browse E&P Pty Ltd * 60% TotalEnergies 40% | ||
| ВА-80-Р | INPEX Обзор E&P Pty Ltd 26,6064% Сантос * 63,6299% Пляж 9,7637% | ||
| ВА-281-П | INPEX Обзор E&P Pty Ltd 29,5% Santos * 70,5% | ||
| ВА-74-Р/ВА-79-R/WA-81-R | INPEX Обзор E&P Pty Ltd 40% Santos * 60% | ||
| ВА-285-П | В стадии разведки | INPEX Browse E&P Pty Ltd * 62,245% TotalEnergies 30,000% CPC 2,625% Tokyo Gas 1,575% Osaka Gas 1,200% Kansai Electric Power 1,200% JERA 0,735% Тохо Газ 0,420% | |
| WA-532-P/WA-533-P | INPEX Обзор E&P Pty Ltd * 100% | ||
| ВА-343-П | INPEX Обзор E&P Pty Ltd * 100% | ||
| AC/P36 | INPEX Обзор E&P Pty Ltd * 50% Мерфи 50% | ||
| AC/P66 | INPEX Обзор E&P Pty Ltd * 100% | ||
| ЕР(А)318 | INPEX Oil & Gas Australia Pty Ltd (28 февраля 2012 г.  ) ) |
INPEX владеет долями в 16 разведочных блоках вблизи газоконденсатного месторождения Ихтис и обнаружила газ на нескольких из этих блоков. Ожидая различных синергетических эффектов, в том числе эффективного использования существующих мощностей, мы ускорим участие в геологоразведочных работах в районе месторождения Ихтис, а также разработку открытых, но неосвоенных активов для дальнейшего обеспечения устойчивых объемов добычи в долгосрочной перспективе, а затем нацелимся на дальнейшее увеличение объемов производства, визуализирующее расширение Ichthys примерно в 2030 году. Между тем, работа по оценке CCS продолжается в разрешении на оценку хранилища парниковых газов G-7-AP, где ожидается, что проект Ichthys LNG будет использовать возможности улавливания и хранения углерода.
CPF Ichthys ExplorerНаземный завод СПГ- Проект Ихтис СПГ
Проект Prelude FLNG (WA-44-L)
| Контрактная площадь (блок) | Статус проекта | Производственная мощность | Венчурная компания (учреждена) | Доля в собственности ( * Оператор) |
|---|---|---|---|---|
| ВА-44-Л | В производстве | СПГ: примерно 3,6 млн тонн в год СНГ: примерно 400 тысяч тонн в год (в пик) Конденсат: примерно 1,3 млн тонн в год (в пик) | INPEX Oil & Gas Australia Pty Ltd (28 февраля 2012 г.  ) ) | INPEX Oil & Gas Australia 17,5% Shell * 67,5% KOGAS 10,0% OPIC 5,0% |
В июне 2012 года INPEX приобрела 17,5% акций проекта Prelude FLNG (плавучий СПГ) у Shell на стадии разработки проекта. Проект Prelude FLNG предполагает производство примерно 3,6 млн тонн СПГ в год, 400 тысяч тонн СУГ в год в пиковый период и примерно 1,3 млн тонн конденсата в год в пиковый период на газовом месторождении Prelude, расположенном в блоке WA-44-L. , примерно в 475 км к северо-северо-востоку от Брума, у побережья Западной Австралии. Shell как оператор проекта Prelude FLNG объявила об окончательном инвестиционном решении (FID) в мае 2011 года. После завершения и ввода в эксплуатацию производственных объектов в декабре 2018 года началась добыча газа с устья скважины. Первая партия конденсата была отгружена в марте 2019 года.затем последовала первая партия СПГ в июне 2019 года.
объект FLNGПроект Баю-Ундан (PSC-TL-SO-T 19-12 (ранее JPDA03-12))
| Контрактная площадь (блок) | Статус проекта | Объем производства ** | Венчурная компания (учреждена) | Доля в собственности ( * Оператор) |
|---|---|---|---|---|
| PSC-TL-SO-T 19-12 | В производстве | Сырая нефть: 12 тыс. баррелей в сутки баррелей в сутки Природный газ *** : 456 млн куб. футов в сутки СНГ: 6 тыс. баррелей в сутки | ИНПЕКС Сахул, ООО (30 марта 1993 г.) | ИНПЕКС Сахул 19.2458049% Сантос * 64,8404271% SK E&S 15,9137680% |
| Блок Баю-Ундан | INPEX Sahul 11,378120% Santos * 43,437907% SK E&S 25,000000% Eni 10,985973% Tokyo Timor Sea Resources (JERA/Tokyo Gas) 9. 198000% |
- ** Суточный объем добычи по всем месторождениям и среднему показателю финансового года, закончившегося 31 декабря 2021 г.
- *** Не объем на устье, а соответствует объему газа, проданному покупателям
В 1993 году INPEX приобрела долю в бывшем контрактном районе JPDA03-12, которым совместно управляли Австралия и Восточный Тимор. В результате геологоразведочных работ на этой контрактной территории были обнаружены месторождения нефти и газа. Из них исследования показали, что структура Ундан и структура Баю, расположенные в соседней бывшей контрактной зоне JPDA03-13, представляли собой единую структуру. Дольщики объединили оба контрактных участка в один в 1999, которое в настоящее время известно как Баю-Унданское газоконденсатное месторождение и занимается добычей и отгрузкой конденсата, СУГ и СПГ. В результате ратификации договора о морской границе между Австралией и Восточным Тимором в 2019 году с Восточным Тимором был связан новый договор о разделе продукции (PSCTL-SO-T 19-12). В рамках действий по борьбе с изменением климата проект рассматривает проект CCS для улавливания, подземной закачки и хранения CO2, выбрасываемого с газового месторождения Баросса, расположенного в водах к северо-западу от Австралии, и других нефтегазовых месторождений вокруг него, путем повторного использования производственных мощностей газоконденсатного месторождения Баю-Ундан.
В результате геологоразведочных работ на этой контрактной территории были обнаружены месторождения нефти и газа. Из них исследования показали, что структура Ундан и структура Баю, расположенные в соседней бывшей контрактной зоне JPDA03-13, представляли собой единую структуру. Дольщики объединили оба контрактных участка в один в 1999, которое в настоящее время известно как Баю-Унданское газоконденсатное месторождение и занимается добычей и отгрузкой конденсата, СУГ и СПГ. В результате ратификации договора о морской границе между Австралией и Восточным Тимором в 2019 году с Восточным Тимором был связан новый договор о разделе продукции (PSCTL-SO-T 19-12). В рамках действий по борьбе с изменением климата проект рассматривает проект CCS для улавливания, подземной закачки и хранения CO2, выбрасываемого с газового месторождения Баросса, расположенного в водах к северо-западу от Австралии, и других нефтегазовых месторождений вокруг него, путем повторного использования производственных мощностей газоконденсатного месторождения Баю-Ундан.