Автоматическое исправление ошибок ASR с помощью sequence-to-sequence моделей / Хабр
Всем привет, я Алсу Вахитова — NLP-разработчица в MTS AI. Вместе с коллегами мы создаем различные алгоритмы обработки текста и извлечения информации из него. Большое количество проектов включает в себя взаимодействие с командами из “соседних” доменов, например, automatic speech recognition (ASR). Одна из таких задач — исправление ошибок в результате работы ASR методов (ASR error correction). В этой статье я приведу теоретический обзор некоторых статей, решающих данную проблему.
Описание проблемы
Автоматическое распознавание речи играет важную роль в современных многоуровневых системах, построенных на основе глубокого обучения. К ним относятся, например, голосовые ассистенты или машинный перевод аудиоданных. К сожалению, довольно часто ASR методы работают с ошибками. Это происходит как из-за внешних факторов (шум, манера речи или акцент говорящего), так и из-за внутренних (недостаток доменного знания у модели).
Типичные недочеты в работе ASR:
Грамматические ошибки из-за плохого качества аудиосигнала:
И этот час дремоты настиг -> И этот час дано династий
Некорректное распознавание фонетически схожих слов:
На картине изображен зеленый луг -> На картине изображен зеленый лук
Недостаток доменного знания:
Ему прописали кумадин -> Ему прописали кумин
Добавление или наоборот “проглатывание” слов:
Опасное задание -> А опасное задание
Мы поедем в Орел -> Мы поедем Орел
Наличие таких ошибок в тексте может препятствовать последующим манипуляциям над распознанным текстом, например, извлечению сущностей.
Постановка задачи
Существуют разные подходы к исправлению ошибок в распознавании речи. Самый очевидный, но далеко не самый простой — улучшить ASR-модель. Также есть различные методы постобработки, они предполагают использование правил и словарей или применение машинного обучения. В этой статье я сосредоточусь на последних.
Самый очевидный, но далеко не самый простой — улучшить ASR-модель. Также есть различные методы постобработки, они предполагают использование правил и словарей или применение машинного обучения. В этой статье я сосредоточусь на последних.
На выходе из ASR-модели получается последовательность слов Х, потенциально содержащая ошибки. При наличии ground truth (оригинального текстового представления произнесенной фразы) T, необходимо найти трансформацию X->T.
Эта постановка очень напоминает задачу машинного перевода с небольшим изменением: вместо языков разных стран есть входной “язык ошибок” и выходной “грамматический правильный язык”. Соответственно, в такой постановке к решению задачи можно применить классические методы машинного перевода (machine translation, MT), а именно sequence-to-sequence модели (seq2seq). Они принимают на вход последовательность элементов (слов, букв, признаков изображения и т.д.) и возвращают другую последовательность элементов.
Таким образом, базовая схема работы методов выглядит состоит из следующих этапов:
ASR-модель получает на вход аудиоданные, распознает их и выводит текст;
Полученный текст передается на вход seq2seq-модели, которая вновь выводит тот же текст, но с исправленными ошибками, если такие находятся.
В следующих блоках я представлю несколько подходов к созданию подобных моделей, которые использую в своей работе. Все эти методы были почерпнуты мной из статей в зарубежных научных изданиях.
Automatic Correction of ASR Outputs by Using Machine Translation
Авторы этой статьи, вышедшей в 2016 году, одни из первых предложили решать задачу исправления ASR ошибок методом машинного перевода. Они используют два датасета: HuRIC (озвученные людьми команды для домашних роботов) и TourSG (вручную расшифрованные диалоги путешественников с турагенствами). Ниже приведена иллюстрация предложенной системы. Пройдемся по всем этапам.
Архитектура предложенной системы (D’Haro and Banchs, 2016)Сперва обратимся к процессу тренировки. Авторы берут аудиофайл и распознают его с помощью Google ASR. На выходе получается список из N лучших гипотез распознанного текста. Далее ко всему списку, а также к референсной транскрипции применяются такие техники обработки текста, как приведение к нижнему регистру и токенизация. На полученных парах тренируется статистическая модель машинного перевода (напоминаю, что это все еще 2016 год).
На полученных парах тренируется статистическая модель машинного перевода (напоминаю, что это все еще 2016 год).
На инференсе обработанный список из N лучших ASR-гипотез отправляется в уже натренированную модель, которая в свою очередь переводит каждый элемент списка на “грамматически правильный” язык. Переведенный список проходит через статистическое ре-ранжирование (Minimum Bayes Risk Decoding). Лучший кандидат из списка считается финальной откорректированной фразой.
В качестве надстройки над основным алгоритмом авторы также предлагают на этапе обработки текста переводить в его в фонетическое представление с помощью алгоритма Dual Metaphone. Таким образом модель машинного перевода обучается не просто на неправильном-правильном языках, а на неправильном-правильном фонетических языках.
Результаты работы алгоритма были подсчитаны с помощью метрики CER (character error rate, процент неправильно предсказанных символов). Ниже приведена таблица с результатами на разных частях двух датасетов.
Видно, что комбинация двух моделей, совместно с ре-ранжированием, дает уменьшение CER везде, кроме тест-части датасета HuRIC.
Я включила эту статью в обзор, потому что бывает полезно вспомнить, какими методами задачи решались в донейронные времена. И как мы видим, проблема исправления ошибок ASR была и остается актуальной.
ASR Error Correction and Domain Adaptation Using Machine Translation
Авторы этой статьи предлагают одно из самых простых решений проблемы: использование рекуррентной сети (кодера-декодера) в комбинации с механизмом внимания для перевода последовательности с ошибками в правильную последовательность. Как и раньше, модели тренируются переводить из “ошибочного” языка ASR модели в “правильный”.
Важно заметить, что в этой статье используются медицинские данные. Это одно из самых сложных направлений в сфере ASR error correction, поскольку именно транскрибация разговоров с/между медиками приводит к наибольшему количеству ошибок из-за большого количества доменной лексики. Авторы не указывают, какой конкретно датасет используется, но описывают его как 288,475 реплик из разговоров пациентов с докторами.
Авторы не указывают, какой конкретно датасет используется, но описывают его как 288,475 реплик из разговоров пациентов с докторами.
Здесь в качестве базовой ASR-модели снова используется Google ASR, а также модель с открытым кодом ASPIRE. Для оценки результатов авторы используют метрику WER (word error rate, процент неправильно предсказанных слов) и стандартную метрику машинного перевода BLEU (грубо говоря, доля правильно предсказанных последовательностей 1-4 слов). Ниже приведена таблица с результатами работы алгоритма.
Результаты распознавания ASR до/после исправления ошибок (Mani et al., 2020)Видно заметное улучшение обеих метрик. Таким образом, данная статья иллюстрирует, как с помощью простой нейронной сети можно адаптировать готовую ASR-модель к доменной лексике.
Remember the Context! ASR Slot Error Correction Through Memorization
Эта статья одна из самых интересных и сложных для понимания, но однозначно стоит потраченного на разбор времени. Авторы предлагают в одной архитектуре объединить текстовые и фонетические репрезентации, а также поиск по хранилищу методом k-ближайших соседей (k-NN, k-nearest neighbors algorithm). Ниже приведена иллюстрация архитектуры, схема создания хранилища и логика инференса.
Авторы предлагают в одной архитектуре объединить текстовые и фонетические репрезентации, а также поиск по хранилищу методом k-ближайших соседей (k-NN, k-nearest neighbors algorithm). Ниже приведена иллюстрация архитектуры, схема создания хранилища и логика инференса.
Начнем с архитектуры модели. Авторы используют Phone Augmented Transformer (PAT, фонетически аугментированный трансформер). Он состоит из двух стандартных трансформерных кодеров — текстового и фонетического. Кодеры принимают на вход соответствующие последовательности и выдают скрытые представления, которые по очереди встраиваются в декодер, последовательно декодирующий выходную последовательность.
На иллюстрации видно, что есть два пути из декодера. Первый — стандартная комбинация линейного слоя и софтмакс функции, позволяющая выбрать наиболее вероятный токен для продолжения выходной последовательности. Второй же путь ведет в еще один механизм внимания с софтмаксом. Это так называемый шаг запоминания, а именно создания вектора-ключа для хранилища. Во время тренировки модели все тренировочные слова проходят через этот шаг запоминания и пара вектор-ключ — слово сохраняется в хранилище.
Второй же путь ведет в еще один механизм внимания с софтмаксом. Это так называемый шаг запоминания, а именно создания вектора-ключа для хранилища. Во время тренировки модели все тренировочные слова проходят через этот шаг запоминания и пара вектор-ключ — слово сохраняется в хранилище.
На этапе инференса входная последовательность снова проходит через два пути в декодере. Первый дает вероятности следующих слов. Второй вновь дает вектор, который на этот раз используется для поиска по хранилищу как вектор-запрос (query). Среди всех векторов-ключей при помощи алгоритма k-NN находятся ближайшие ключи, а их значения становятся потенциальными кандидатами. Далее вероятности, полученные из двух путей, складываются, и лучший токен продолжает декодируемую выходную последовательность.
Таким образом хранилище — еще один способ запомнить соответствие ввода (комбинации текста и фонем) выводу (ground truth тексту). Такая техника дает значительное улучшение метрик, что мы и увидим далее.
Авторы не используют готовый датасет, а синтетически генерируют свой. Для этого названия городов, аэропортов, штатов, улиц и т.д. комбинируются с различными фразовыми паттернами (например, “я лечу из X в Y”), а далее озвучиваются алгоритмом синтеза речи (text-to-speech, TTS) AWS Polly. Авторы не указывают, какая конкретно ASR модель была использована, но называют ее “стандартной”. Тренировка-оценка проходят как на комбинированном датасете, так и на разделенном на разные домены (например, только названия улиц). Для оценки используются WER, precision (точность) и recall (полнота). Ниже приведена таблица с результатами.
Для этого названия городов, аэропортов, штатов, улиц и т.д. комбинируются с различными фразовыми паттернами (например, “я лечу из X в Y”), а далее озвучиваются алгоритмом синтеза речи (text-to-speech, TTS) AWS Polly. Авторы не указывают, какая конкретно ASR модель была использована, но называют ее “стандартной”. Тренировка-оценка проходят как на комбинированном датасете, так и на разделенном на разные домены (например, только названия улиц). Для оценки используются WER, precision (точность) и recall (полнота). Ниже приведена таблица с результатами.
К сожалению, авторы не привели метрики вывода только ASR-модели, остается только предположить, что они хуже. Из таблицы выше видно, что использование k-NN хранилища дало значительное улучшение результатов по всем доменам и всем метрикам. Ниже таблица с конкретными хорошими-плохими примерами работы ASR, PAT и k-PAT.
Примеры тестовых фраз сгенерированных ASR, PAT и k-PAT (Bekal et al.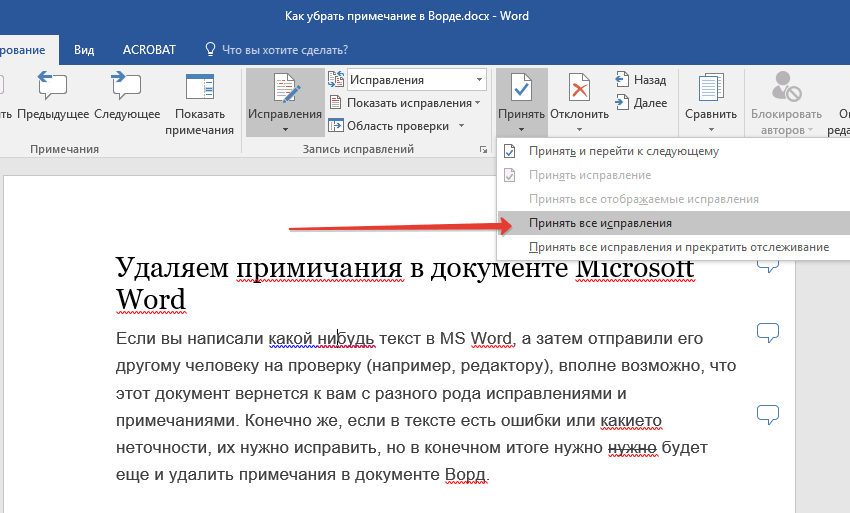 , 2021)
, 2021)Эта статья является хорошим примером сложной архитектуры, сочетающей в себе как глубокое обучение (трансформер), так и алгоритм из классического машинного обучения (k-NN). Предложенная архитектура достаточно сложная как для понимания, так и для реализации, но дает отличные результаты.
Clinical Dialogue Transcription Error Correction using Seq2Seq Models
В этой статье вновь исправляются ошибки в диалогах между пациентами и врачами, или просто между медиками. Однако авторы поставили перед собой интересную и сложную задачу. Они собрали совсем небольшой датасет разговоров на медицинские темы, Gastrointestinal Clinical Dialogue Dataset (GCD), состоящий из всего 329 озвученных реплик. Очевидно, что на таком крохотном наборе данных невозможно что-либо обучить, поэтому авторы пошли на некоторые хитрости.
В качестве sequence-to-sequence моделей были использованы два предобученных трансформера: T5 и BART (в данном обзоре я не буду останавливаться на разборе их архитектур, потому что они и так известны всем, кто занимается задачами в области NLP). За неимением достаточного количества данных для перевода из “ошибочного” языка ASR модели в “правильный” авторы решили файнтюнить модели на трех других задачах: генерация краткого содержания (суммаризация), парафраз и предсказание маскированных слов. Гипотеза авторов состоит в том, что таким образом можно “познакомить” языковые модели с доменной лексикой, что поможет им в исправлении ASR ошибок, хоть они и не были обучены этому напрямую.
За неимением достаточного количества данных для перевода из “ошибочного” языка ASR модели в “правильный” авторы решили файнтюнить модели на трех других задачах: генерация краткого содержания (суммаризация), парафраз и предсказание маскированных слов. Гипотеза авторов состоит в том, что таким образом можно “познакомить” языковые модели с доменной лексикой, что поможет им в исправлении ASR ошибок, хоть они и не были обучены этому напрямую.
Далее авторы собрали заголовки и абстракты статей из базы данных PubMed. Для задачи суммаризации были использованы пары абстракт-заголовок. Для обучения парафразу заголовки прогнали через уже обученный этому отдельный T5, таким образом получив пары заголовок-перефразированный заголовок. Для обучения предсказанию маскированных слов в заголовках четверть слов заменили на маски.
В качестве базовых ASR-систем были использованы четыре коммерческие модели: AWS Transcribe, Microsoft, IBM Watson, Google. Ниже представлены WER-метрики транскрибации GCD датасета каждой из моделей.
Получив транскрипты от ASR-моделей, авторы прогнали их через зафайнтюненные трансформеры. Результаты представлены в таблице ниже.
Сравнение зафайнтюненных моделей (Nanayakkara et al., 2022)Метрики ожидаемо неровные: результат работы Google ASR обеим моделям удалось улучшить, в то время как AWS Transcribe в обоих случаях ухудшился. Несмотря на весьма скромные показатели, в целом эта статья демонстрирует интересный и нестандартный подход к решению проблемы, поэтому я не смогла пройти мимо нее.
Error Correction in ASR using Sequence-to-Sequence Models
Последний подход, про который я расскажу в обзоре, вновь инкорпорирует фонетические данные в seq2seq-модель, а также предлагает техники аугментации данных, которых, как обычно, недостаточно.
Авторы опираются на тот факт, что большое количество ASR-ошибок происходит из-за схожести произношения слов. Поэтому они предложили архитектуру, которая на вход получает не только текстовую репрезентацию, но и фонетическую — RoBART (robust BART — устойчивый BART).
Фонетическая репрезентация вывода ASR-модели создается с помощью grapheme-to-phoneme (G2P) инструмента. Известные слова он находит в словаре, а для незнакомых (OOV, out-of-vocabulary) слов последовательность фонем предсказывается с помощью натренированной нейронной сети. Текстовая и фонетическая последовательности соединяются и направляются на вход в seq2seq-модель.
Базовая ASR-модель была создана с помощью библиотеки ESPnet. В качестве источника тренировочных данных используется датасет CommonVoice, состоящий из ~119 тысяч расшифрованных аудиозаписей (из которых примерно одна пятая была произнесена не американцами — non-US). Авторы также предложили три техники аугментации данных.
На датасете LibriSpeech-960-hr была натренирована дополнительная ASR-модель wav2vec2. Таким образом один и тот же аудиофайл можно было распознавать двумя моделями. Это дало возможность seq2seq-модели выучить ошибки, произведенные разными архитектурами.
Во время тренировки базовой ASR модели была сохранена частично натренированная модель.
 Данный подход авторы назвали Weak ASR (“слабый” ASR). Как и в первом пункте, этот метод аугментации давал альтернативное распознавание аудиофайла. Но в данном подходе ставка делалась на увеличение количества разнообразных ошибок, на которых должна выучиться seq2seq модель.
Данный подход авторы назвали Weak ASR (“слабый” ASR). Как и в первом пункте, этот метод аугментации давал альтернативное распознавание аудиофайла. Но в данном подходе ставка делалась на увеличение количества разнообразных ошибок, на которых должна выучиться seq2seq модель.Третий способ аугментации вообще не предполал использование ASR-модели. Из CommonVoice датасета сразу брались правильные транскрибации аудиозаписей. Далее случайные слова заменялись случайными схожими по произношению словами (Synthetic1 подход) или словами, схожими и по произношению и по написанию (Synthetic2 подход).
В качестве seq2seq-модели использовался натренированный трансформер BART. Далее он файнтюнился с каждой техникой аугментации с/без фонемными репрезентациями. Результаты оценивались с помощью метрики WER. Ниже таблица с результатами.
WER различных конфигураций RoBART (Dutta et al., 2022)BART pretrained — вывод BART без какой-либо дополнительной тренировки. Ph и NPh означают, что входная последовательность в RoBART соответственно была/не была соединена со своей фонетической репрезентацией. Из таблицы можно сделать вывод, что синтетические аугментации не дают эффективного улучшения качества. В то же время, добавление фонетических данных и дополнительных способов распознавания существенно снижают WER.
Ph и NPh означают, что входная последовательность в RoBART соответственно была/не была соединена со своей фонетической репрезентацией. Из таблицы можно сделать вывод, что синтетические аугментации не дают эффективного улучшения качества. В то же время, добавление фонетических данных и дополнительных способов распознавания существенно снижают WER.
Эта статья демонстрирует простой подход к инкорпорации фонетических данных в ввод seq2seq модели, а также предлагает несколько вполне рабочих техник аугментации данных.
Итоги
В данном обзоре представлены несколько разных и интересных способов корректировки ошибок ASR-моделей. Поскольку все они использовали разные данные, сложно оценить, какой метод является самым лучшим. Есть более простые варианты, а есть и многоэтажные архитектуры, с фонетическими данными и без — словом, подходы на любой вкус. Одним из главных факторов, тормозящих их применение и в целом развитие этого направления, является существенный недостаток доменных данных. Авторы материалов по-разному стараются справиться с этой проблемой: генерация искусственных данных, обучение на чисто текстовых данных, использование альтернативных моделей распознавания — и получают, как мы увидели, различные результаты.
Авторы материалов по-разному стараются справиться с этой проблемой: генерация искусственных данных, обучение на чисто текстовых данных, использование альтернативных моделей распознавания — и получают, как мы увидели, различные результаты.
Надеюсь, вам был полезен мой обзор. Делитесь своими подходами к исправлению ASR-ошибок, оставляйте комментарии 🙂
Библиография
[1] D’Haro, L. F. and Rafael E. Banchs. “Automatic Correction of ASR Outputs by Using Machine Translation.” Interspeech (2016).
[2] Mani, Anirudh et al. “ASR Error Correction and Domain Adaptation Using Machine Translation.” ICASSP 2020 — 2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (2020): 6344-6348.
[3] Bekal, Dhanush et al. “Remember the Context! ASR Slot Error Correction Through Memorization.” 2021 IEEE Automatic Speech Recognition and Understanding Workshop (ASRU) (2021): 236-243.
[4] Nanayakkara, Gayani et al. “Clinical Dialogue Transcription Error Correction using Seq2Seq Models. ” ArXiv abs/2205.13572 (2022).
” ArXiv abs/2205.13572 (2022).
[5] Dutta, Samrat et al. “Error Correction in ASR using Sequence-to-Sequence Models.” ArXiv abs/2202.01157 (2022).
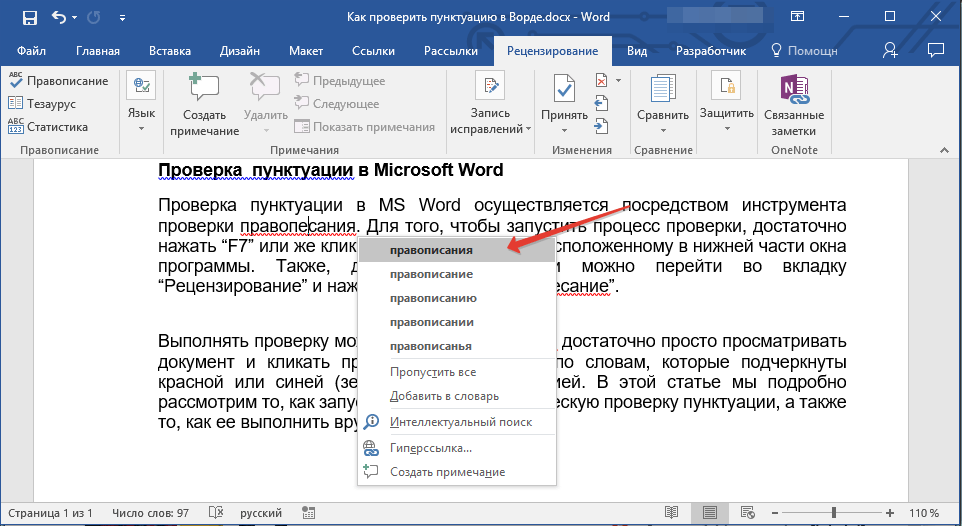
Как включить исправление ошибок и подсказки при вводе в Windows 10
Главная » Уроки и статьи » Windows
В новой операционной системе появилось множество функций. Среди относительно малоизвестных числятся исправление ошибок, а также подсказки. Они позволяют повысить скорость написания текста в различных приложениях. Поэтому рекомендуется подробнее ознакомиться с тем, как включить исправление ошибок и подсказки при вводе в Windows 10.
Активация обеих функций
Справиться с этой задачей сможет любой: какие-либо знания для проведения процедуры не требуются. Более того, она абсолютно безопасна. Чтобы активировать функции, необходимо придерживаться следующей инструкции:
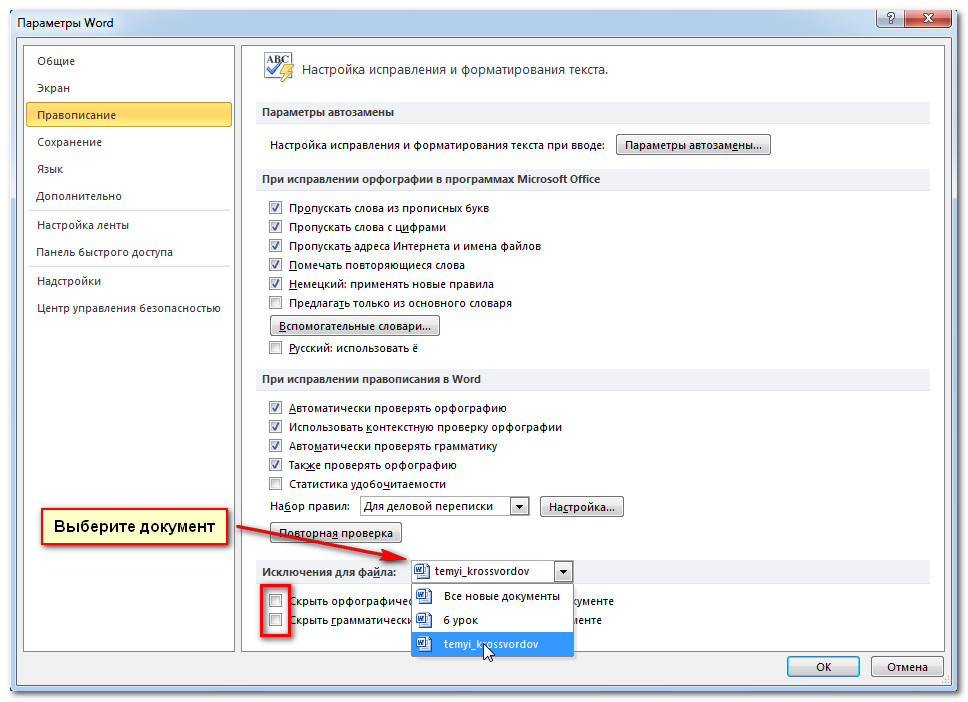
- Открыть «Параметры» ОС. Сделать это можно, одновременно нажав клавиши Win и I.
- Перейти в настройки устройств.

- Нажать на «Ввод» (расположен в левой части окна).
- Прокрутить параметры немного вниз и найти подзаголовок «Аппаратная клавиатура».
- Активировать функции с помощью специальных ползунков.
Перезагрузка после внесения изменений не требуется. Также можно включить функцию, расположенную чуть ниже указанных на скриншоте. Это может быть полезно, если пользователь постоянно пишет на разных языках.
Функции крайне просты в применении. Слова-подсказки будут появляться во время написания. Выглядит это следующим образом:
Почему не работают автоматическое исправление ошибок и подсказки
Нередко люди жалуются на то, что функции не работают как нужно. Особенно это относится к исправлению ошибок. С данной проблемой сталкиваются почти все пользователи, однако у нее нет решения. Поэтому можно считать, что функция исправления ошибок попросту не работает на некоторых версиях операционной системы.
С подсказками у большинства людей не возникает проблем. Если функция все же не работает, можно попробовать включить ее через реестр. Для этого нужно открыть редактор последнего (Win+R, после чего ввести команду «regedit»). После этого перейти по адресу:
Подчеркнутый параметр нужно изменить, дважды кликнув ЛКМ. В поле «Значение» следует поставить 1. После завершения процедуры потребуется перезагрузка компьютера.
Важно учитывать, что подсказки работают далеко не во всех приложениях. Особенно это относится к сторонним программам. Проверить, работает ли функция, можно по стандартному блокноту: в нем она точно должна функционировать корректно.
Таким образом, подсказки при вводе включаются очень просто и редко вызывают какие-либо проблемы. Единственный их недостаток – они не везде работают. А вот автоматическое исправление ошибок в большинстве случаев просто не активируется.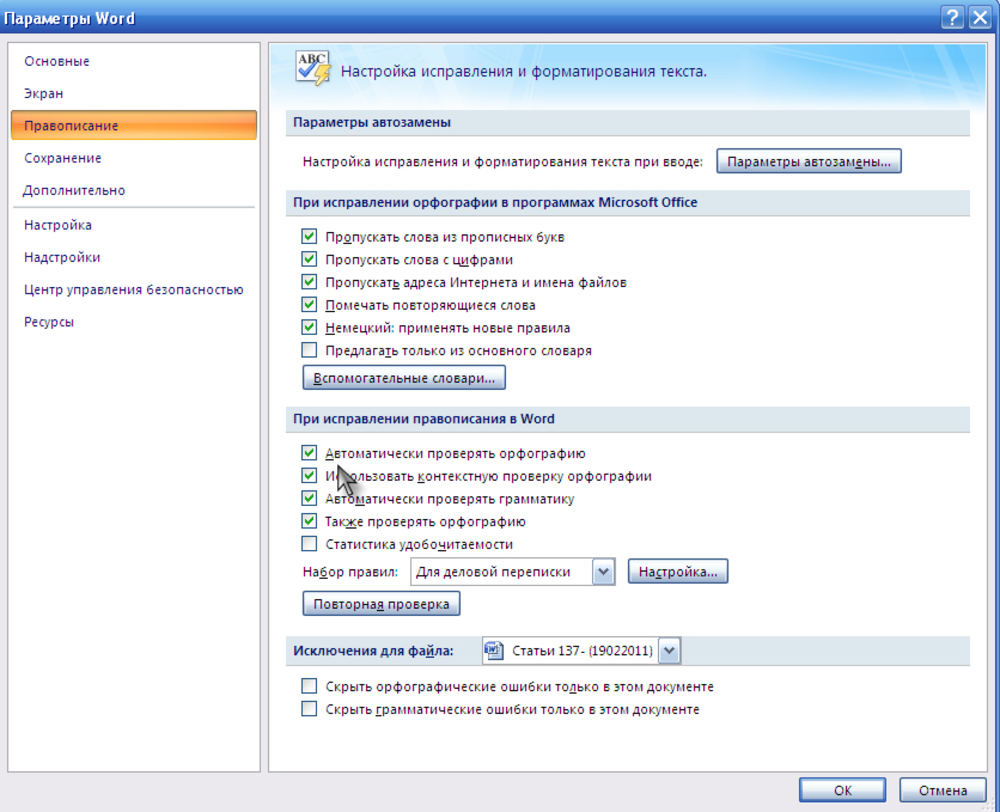
Понравилось? Поделись с друзьями!
Дата: 21.08.2021 Автор/Переводчик: Wolf
Что такое автозамена? – Определение TechTarget
- Кэти Террелл Ханна
- Айви Вигмор
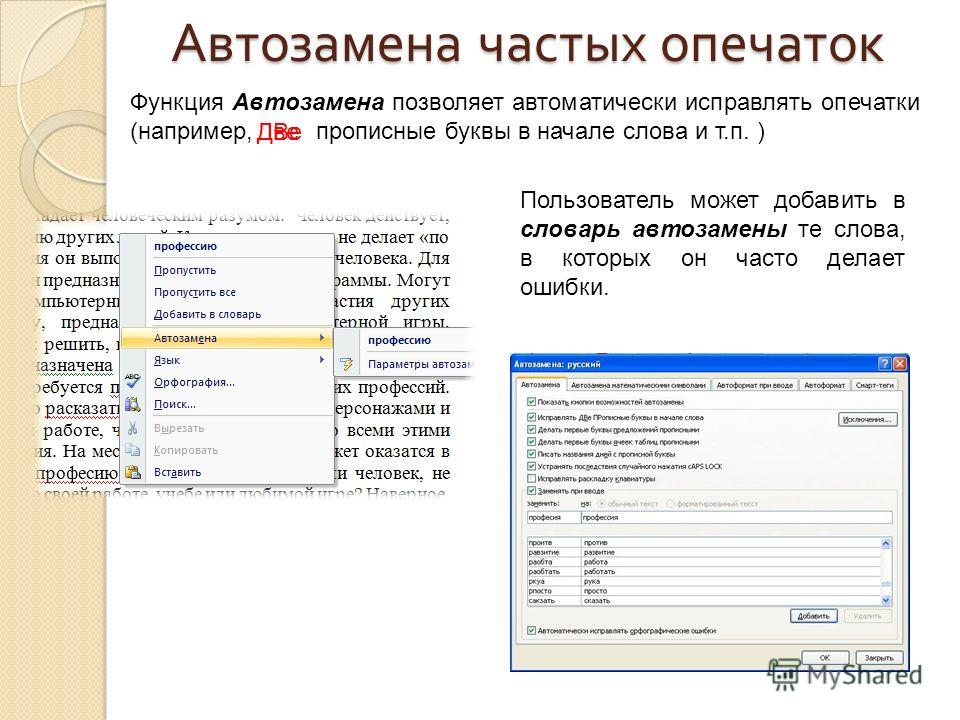
Автозамена — это функция обработки текста, которая идентифицирует слова с ошибками и использует алгоритмы для определения слов, которые, скорее всего, предназначались, и соответствующим образом редактирует текст.
Какое программное обеспечение включает функции автозамены?Продукты Apple, Google и Microsoft имеют собственные версии программ автозамены. Функции текстовых сообщений на смартфонах также обычно оснащены автокоррекцией и прогнозированием текста, например, для помощи пользователям.
Некоторые программы, например те, которые используются для кодирования, не будут автоматически исправлять слова, если это не указано пользователем. Это связано с тем, что код часто очень специфичен, и даже небольшое изменение может привести к серьезным ошибкам.
Это связано с тем, что код часто очень специфичен, и даже небольшое изменение может привести к серьезным ошибкам.
Когда набирается слово, которого нет в словаре, программа обычно подчеркивает его красным цветом. Затем пользователь может щелкнуть правой кнопкой мыши слово с ошибкой и выбрать правильное написание из списка предложений. Затем программа запомнит это исправление для использования в будущем.
Автозамена может сэкономить время пользователей, быстро исправляя распространенные орфографические ошибки. Это также может улучшить общение, выявляя ошибки, которые могут изменить смысл того, что кто-то пытается сказать.
Функции автозамены очень хорошо работают с распространенными и прямыми опечатками, такими как «teh» вместо «the». Однако их алгоритмы далеко не безошибочны, особенно программы автозамены на смартфонах.
Эти программы часто предлагают слова, совершенно не относящиеся к введенным. Например, если пользователь набирает «Я иду в магазин», функция автозамены телефона может изменить его на «Я иду к дверям».
Как отключить автозамену?При возникновении этих проблем есть несколько способов отключить или настроить функции автозамены:
- На устройствах iOS пользователи могут перейти к Настройки , а затем Общие перед выбором Клавиатура .
 Оттуда они могут сдвинуть переключатель Автокоррекция на Выкл .
Оттуда они могут сдвинуть переключатель Автокоррекция на Выкл . - Для телефонов Android процесс аналогичен. Перейдите в Настройки , выберите Язык и ввод , а затем найдите параметр Автокоррекция и отключите его.
Некоторые телефоны и компьютеры также позволяют пользователям добавлять свои собственные слова в словарь, который будет использовать автозамена, чтобы избежать предложений, которые совершенно не связаны с тем, что было задумано.
См. также: обработка естественного языка , системное программное обеспечение , текстовый редактор , программное обеспечение для повышения производительности 9 0085 , распознавание речи , шрифт
Последнее обновление: ноябрь 2022 г.
- Написание контента с использованием искусственного интеллекта увеличивает количество публикаций
- Автоматическое распознавание речи может быть лучше, чем вы думаете
- История и эволюция безбумажного офиса
- Microsoft запускает инструмент транскрипции Word
- Производительность и функции Apple Mac повышают привлекательность бизнеса
управление правами на информацию (IRM)
Управление правами на доступ к данным (IRM) — это дисциплина, которая включает в себя управление, контроль и защиту содержимого от нежелательного доступа.
Сеть- CSU/DSU (блок обслуживания канала/блок обслуживания данных)
CSU/DSU (Channel Service Unit/Data Service Unit) — аппаратное устройство размером примерно с модем. Он преобразует цифровые данные …
- потоковая передача данных
Потоковая передача данных — это непрерывная передача данных из одного или нескольких источников с постоянной высокой скоростью для обработки в определенные .

- граница службы безопасного доступа (SASE)
Пограничный сервис безопасного доступа, также известный как SASE и произносится как «дерзкий», представляет собой модель облачной архитектуры, объединяющую сеть и …
- черный список приложений (занесение приложений в черный список)
Занесение приложений в черный список — все чаще называемое занесением в черный список приложений — представляет собой практику сетевого или компьютерного администрирования, используемую …
- идентификация на основе утверждений
Идентификация на основе утверждений — это средство аутентификации конечного пользователя, приложения или устройства в другой системе способом, который абстрагирует …
- Сертифицированный специалист по облачной безопасности (CCSP) Certified Cloud Security Professional (CCSP) — это Международный консорциум по сертификации безопасности информационных систем, или (ISC)2,.
 ..
..
- Общепринятые принципы ведения учета (Принципы)
Общепринятые принципы ведения документации — это основа для управления записями таким образом, чтобы поддерживать …
- система управления обучением (LMS)
Система управления обучением представляет собой программное приложение или веб-технологию, используемую для планирования, реализации и оценки конкретных …
- Информационный век
Информационная эпоха — это идея о том, что доступ к информации и контроль над ней являются определяющими характеристиками нынешней эпохи …
- аутсорсинг процесса подбора персонала (RPO)
Аутсорсинг процесса найма (RPO) — это когда работодатель передает ответственность за поиск потенциальных кандидатов на работу …
- специалист по кадрам (HR)
Специалист по персоналу — это специалист по кадрам, который выполняет повседневные обязанности по управлению талантами, сотрудникам .
 ..
.. - жизненный цикл сотрудника
Жизненный цикл сотрудника — это модель человеческих ресурсов, которая определяет различные этапы, которые работник проходит в своей …
- Платформа Adobe Experience
Adobe Experience Platform — это набор решений Adobe для управления качеством обслуживания клиентов (CXM).
- виртуальный помощник (помощник ИИ)
Виртуальный помощник, также называемый помощником ИИ или цифровым помощником, представляет собой прикладную программу, которая понимает естественные …
- входящий маркетинг
Входящий маркетинг — это стратегия, направленная на привлечение клиентов или лидов с помощью созданного компанией интернет-контента, тем самым …
[PDF] Автоматическое исправление грамматических ошибок в неродном английском тексте
- Идентификатор корпуса: 18032765
@inproceedings{Lee2009AutomaticCO,
title={Автоматическое исправление грамматических ошибок в неродном английском тексте},
автор = {Джон Си Юэн Ли},
год = {2009}
} - Дж.
 Ли
Ли - Опубликовано в 2009 г.
- Лингвистика, информатика
Изучение иностранного языка требует много практики за пределами классной комнаты. Компьютерные системы изучения языка могут помочь удовлетворить эту потребность, и одной из желательных возможностей таких систем является автоматическое исправление грамматических ошибок в текстах, написанных не носителями языка. Эта диссертация касается исправления неродных грамматических ошибок в английском тексте и тесно связанной с этим задачи создания тестовых заданий для изучения языка с использованием комбинации статистических и…
View Paper
groups.csail.mit.eduАвтоматическое исправление грамматических ошибок: всесторонний обзор
- С. Рауф, Рамша Саид, Н. С. Хан, Киран Хабиб, Перния Габраил, Фариха Афтаб
- 9002 4 Лингвистика, информатика
- 2018

Статистическая модель исправления ошибок для компьютерных систем обучения языку описан, обучен на только что собранном корпусе языка данные малайзийских учащихся EFL и протестированы на другой группе учащихся из той же группы населения.
Определение родного языка писателя с помощью анализа ошибок
- Э. Кочмар
Лингвистика
- 2011
Эта диссертация является результатом моей собственной работы и не содержит ничего, что является результатом совместной работы, за исключением случаев, специально указанных в тексте. Эта диссертация не…
Метод исправления ошибок в статьях в эссе китайских студентов на английском языке на основе классификации гибридных признаков0005
Информатика

Неконтролируемый подход к обнаружению и исправлению ошибок в тексте
- Мд. Аминул Ислам
Информатика
- 2011
Исправление различных типов ошибок в текстах
- Аминул Ислам, Д. Инкпен
Лингвистика, образование
Канадская конференция по ИИ
- 2011
Письменные грамматические ошибки арабского языка как второго (ASL) Изучающие: оценочное исследование
- Садек Али Саад Аль-Яари, Файза Салех Аль Хаммади, С.
 Альями
Альями Лингвистика, образование
90 003 2013
Фон : В последние годы число не носителей арабского языка увеличилось в геометрической прогрессии. Цели: Это аналитическое исследование направлено на изучение письменных грамматических ошибок, допущенных…
Эффективная проверка грамматики на основе правил с определением последовательности слов
- Кришна Кумар Гири, Раджкумар Текчандани
Компьютерные науки, лингвистика
- 2017
Обнаружение грамматических ошибок с помощью вероятностных синтаксических анализаторов, индуцированных банками деревьев
- Иоахим Вагнер
Информатика, лингвистика
- 2012
 нить.
нить.Идентификация родного языка: исследования и приложения
- С. Малмаси
Информатика
- 2016
Анализ грамматических ошибок в неродной речи на английском языке
В этой статье представлен автоматический метод оценки модели ошибки из корпуса неродного английского языка с упором на артикли и предлоги, а также проводится детальный анализ путем кондиционирования ошибки в уместных словах в контексте.Выявление ошибок в использовании английской статьи не носителями языка
- Н. А-Р А Е Х А Н, М.
 А Р Т И Н Ч О Д О
А Р Т И Н Ч О Д О Лингвистика
- 2006 9001 2
- Кэтлин Ф. Маккой, Кристофер А. Пеннингтон, Линда З. Сури
Компьютерная наука
- 1996
- Джонг К.
 Парк, Марта Палмер, Клэй Уошберн
Парк, Марта Палмер, Клэй Уошберн Лингвистика
ANLP
- 1997
- Чао-Хонг Лю, Чунг-Сянь Ву, Мэтью Харрис
Лингвистика, информатика
2008 6-й Международный симпозиум по обработке разговорного китайского языка
- 2008
- Крис Брокетт, В. Долан, Майкл Гэймон
Лингвистика
ACL
- 2006
- J. Lee, S. Seneff
Информатика, лингвистика
INTERSPEECH
- 2006
- М. Ходоров, Дж. Тетрео, На-Рэ Хан
Лингвистика
ACL 2007
- 2007
- Na-Rae Han, M. Chodorow, C. Leacock
Лингвистика, информатика
LREC
- 2004
Одной из самых сложных проблем, с которыми сталкиваются люди, для которых английский язык не является родным, является овладение системой английских артиклей. Мы обучили классификатор максимальной энтропии выбирать между a/an, the или zero…
English Исправление ошибок: синтаксическая пользовательская модель, основанная на принципиальной оценке «правила неправильности»
Мы обсудим модель пользователя, которая может быть адаптирована к различным типам пользователей, чтобы определить и правильно английский языковые ошибки. Он представлен в контексте системы обучения письменному английскому языку…
Программа проверки грамматики английского языка как вспомогательное средство при письме для изучающих английский как второй язык
Исправление порядка слов для языкового переноса с использованием языкового моделирования относительного положения

Исправление ошибок ESL с помощью фразовых методов SMT
Автоматическая коррекция грамматики для изучающих второй язык

Обнаружение грамматических ошибок в предлогах
Обнаружение ошибок в использовании статей на английском языке с помощью классификатора максимальной энтропии, обученного на большом разнообразном корпусе