Основанные указатели (C++) | Microsoft Learn
Twitter LinkedIn Facebook Адрес электронной почты
- Статья
- Чтение занимает 2 мин
Ключевое __based слово позволяет объявлять указатели на основе указателей (указатели, которые являются смещениями от существующих указателей). Ключевое
Ключевое __based слово зависит от Корпорации Майкрософт.
Синтаксис
type __based( base ) declarator
Указатели, основанные на адресах указателей, являются единственной формой ключевого слова, допустимой __based в 32-разрядных или 64-разрядных компиляциях. В 32-разрядном компиляторе Microsoft C/C++ относительный указатель имеет 32-разрядное смещение от 32-разрядной базы указателя. То же ограничение действует и для 64-разрядных сред, где относительный указатель имеет 64-разрядное смещение от 64-разрядной базы указателя.
Указатели на основе указателей, в частности, используются для постоянных идентификаторов, которые содержат указатели. Связанный список, состоящий из указателей на основе указателей, можно сохранить на диск, а затем перезагрузить в другое место в памяти. При этом все указатели останутся действительными. Пример:
// based_pointers1.cpp
// compile with: /c
void *vpBuffer;
struct llist_t {
void __based( vpBuffer ) *vpData;
struct llist_t __based( vpBuffer ) *llNext;
};
Указателю vpBuffer назначается адрес в памяти, который выделяется на более позднем этапе программы. Связанный список перемещается относительно значения
Связанный список перемещается относительно значения vpBuffer.
Примечание
Сохранение идентификаторов, содержащих указатели, также можно выполнить с помощью сопоставленных в памяти файлов.
Когда выполняется разыменовывание относительных указателей, база должна быть либо явно указана, либо неявно известна из объявления.
Для совместимости с предыдущими версиями _based является синонимом__based, если не указан параметр компилятора /Za (отключить расширения языка).
Пример
В следующем примере демонстрируется изменение относительного указателя путем изменения его базы.
// based_pointers2.cpp
// compile with: /EHsc
#include <iostream>
int a1[] = { 1,2,3 };
int a2[] = { 10,11,12 };
int *pBased;
typedef int __based(pBased) * pBasedPtr;
using namespace std;
int main() {
pBased = &a1[0];
pBasedPtr pb = 0;
cout << *pb << endl;
cout << *(pb+1) << endl;
pBased = &a2[0];
cout << *pb << endl;
cout << *(pb+1) << endl;
}
1 2 10 11
См.
 также раздел
также разделКлючевые слова
alloc_text
Арифметика указателя C++
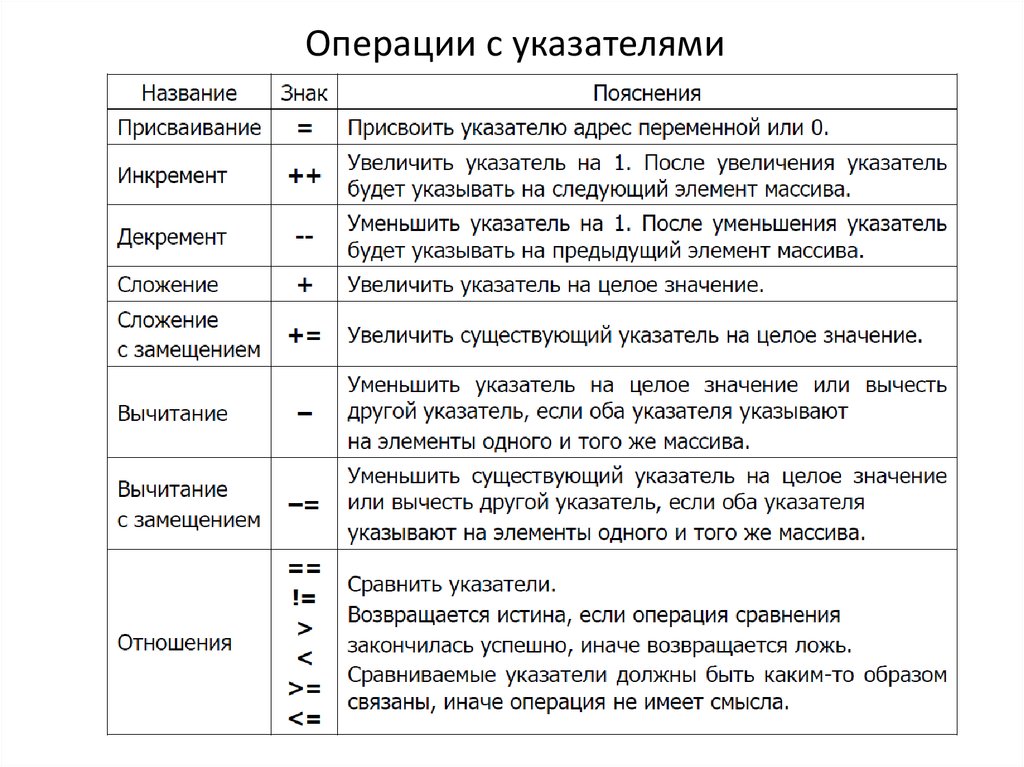
Мы знаем, что указатели — это адреса переменных в памяти и, как правило, числовые. Вот почему мы можем производить некоторые арифметические вычисления и с указателями. Эти вычисления можно производить так же, как мы делаем с числовыми значениями в математике или программировании. Поэтому мы обсудим некоторые арифметические операции над указателями в нашем учебном руководстве с использованием C ++. Мы использовали систему Ubuntu 20.04, убедившись, что в ней настроен компилятор G ++. Начнем с реализации арифметики указателей в оболочке системного терминала Ubuntu 20.04 с помощью сочетания клавиш Ctrl + Alt + T, используемого на его рабочем столе.
Содержание
- Пример 1
- Пример 2
- Пример 3
- Заключение
Пример 1
Начните первый пример кода C ++, чтобы использовать арифметические операторы «+» для указателей при создании файла. Вы можете создать файл разными способами, но самый простой — использовать «сенсорную» инструкцию. Таким образом, мы попробовали ключевое слово touch вместе с заголовком файла, который нужно сформировать на консоли, и нажали Enter. Файл создается в домашней папке Ubuntu 20.04.
Вы можете создать файл разными способами, но самый простой — использовать «сенсорную» инструкцию. Таким образом, мы попробовали ключевое слово touch вместе с заголовком файла, который нужно сформировать на консоли, и нажали Enter. Файл создается в домашней папке Ubuntu 20.04.
Теперь, чтобы открыть этот только что созданный файл, вы можете использовать любой из встроенных редакторов, поставляемых с Ubuntu 20.04, то есть vim, текстовый редактор или редактор GNU nano. Мы предлагаем вам использовать редактор GNU Nano, поскольку мы использовали его в оболочке, как показано на изображении ниже.
Этот файл «pointer.cc» пока не заблокирован в редакторе. Мы включили заголовочный файл потока ввода-вывода в первую строку, а стандартное пространство имен было использовано во второй строке. Мы инициализировали целочисленную переменную «v» значением 8. В следующей подряд строке мы инициализировали указатель целочисленного типа «p». Этот указатель является адресом переменной «v», поскольку он связан с переменной «v» с помощью знака «&». Это означает, что мы можем изменить адрес изменяемого объекта в любое время. Стандартные операторы cout использовались один за другим. Первый отображает исходный адрес переменной «v», сохраненный как указатель «p».
Это означает, что мы можем изменить адрес изменяемого объекта в любое время. Стандартные операторы cout использовались один за другим. Первый отображает исходный адрес переменной «v», сохраненный как указатель «p».
В следующей строке оператор cout увеличивает адрес указателя на 1 и отображает его. Следующие две строки использовали указатель и увеличивали его значение на 2 и 3. Увеличенные значения были отображены с помощью оператора cout. Код заканчивается здесь. Давайте сначала сохраним код перед выполнением. Для этого используйте Ctrl + S. Вы должны выйти из редактора GNU Nano, чтобы вернуться к терминалу. Для этого воспользуйтесь сочетанием клавиш «Ctrl + X». Это был простейший код C ++ для увеличения указателя с помощью оператора +.
Вернувшись к оболочке, мы должны сделать наш код безошибочным. Для этого используется компилятор C ++. Ключевое слово компилятора «g ++» было использовано вместе с именем файла, который должен быть скомпилирован, например, «pointer.cc». Компиляция прошла успешно, поскольку вы видите, что она ничего не возвращает. Давайте выполним наш безошибочный код с помощью стандартной команды «./a.out». У нас есть 4 разных адреса для переменной «v».
Компиляция прошла успешно, поскольку вы видите, что она ничего не возвращает. Давайте выполним наш безошибочный код с помощью стандартной команды «./a.out». У нас есть 4 разных адреса для переменной «v».
Первый — это исходный адрес «p» переменной «v». Второй увеличивается на 1, третий увеличивается на значение 2, а последний увеличивается на 3. Каждый раз, когда мы выполняем приращение, последние два символа адреса имеют тенденцию изменяться, как показано ниже.
Пример 2
Приведем еще один пример использования оператора декремента для указателя. Итак, мы использовали все тот же старый файл «pointer.cc». Пространство имен и заголовок ввода-вывода используются так же, как и раньше. Другая постоянная целочисленная переменная «s» инициализируется постоянным значением 5. В методе main () мы использовали массив целочисленного типа с именем «v» размера «s» с 5 элементами в нем. Объявлен целочисленный указатель «p». Указатель был привязан к целочисленному массиву «v» с помощью знака «&».
Размер будет начинаться с адреса s-1. Инициализирован цикл for, который начинается с размера 5 и работает в порядке убывания, каждый раз уменьшаясь на 1. Каждый раз, когда цикл for работает, он отображает адрес памяти номера индекса, повторяемого циклом, и значение в конкретном индексе, а также с использованием стандартного оператора cout. «P» показывает адрес индекса, а * P представляет значение этого конкретного индекса. На каждой итерации указатель уменьшался на 1. На этом заканчивается цикл и основная функция.
Сначала скомпилируйте код с помощью компилятора g ++ языка C ++. Он работает успешно, без ошибок. Выполнение осуществляется командой «./a.out». Мы получили результат, как показано ниже. Как видите, у нас есть каждый адрес памяти для определенного индекса, то есть 5,4,3,2,1 в порядке убывания индексов. С другой стороны, мы также получаем значения в каждом конкретном индексе каждый раз, когда цикл повторяется в порядке убывания до последнего значения.
Пример 3
У нас будет новый экземпляр указателей. В этом примере мы будем сравнивать адреса указателей, а также значения, которые они содержат. Таким образом, документ pointer.cc теперь запускается в редакторе GNU Nano. Функция main () была инициализирована после стандартного пространства имен и заголовка потока «io» в файле кода. Он содержит две переменные строкового типа s1 и s2 с совершенно разными строковыми значениями, то есть «Aqsa» и «Yasin».
В этом примере мы будем сравнивать адреса указателей, а также значения, которые они содержат. Таким образом, документ pointer.cc теперь запускается в редакторе GNU Nano. Функция main () была инициализирована после стандартного пространства имен и заголовка потока «io» в файле кода. Он содержит две переменные строкового типа s1 и s2 с совершенно разными строковыми значениями, то есть «Aqsa» и «Yasin».
После этого мы инициализировали две переменные-указатели строкового типа p1 и p2, ограниченные обеими переменными s1 и s2, с помощью символа «&» после знака «=». Это означает, что указатель p1 — это адрес переменной s1, а p2 — адрес переменной s2.
Первое стандартное предложение cout используется для отображения результата сравнения обоих указателей, то есть адресов обеих строковых переменных. Если адреса совпадают, в оболочке будет отображаться 1 как истина, в противном случае 0 как ложь. Второе стандартное предложение cout используется для отображения результата сравнения значений, хранящихся в конкретном адресе указателя. Если значения совпадают, возвращается 1, в противном случае — 0. Программа сравнения на этом заканчивается.
Если значения совпадают, возвращается 1, в противном случае — 0. Программа сравнения на этом заканчивается.
Сначала скомпилируйте свой код C ++ и выполните его. В результате обоих сравнений мы получили 0, т.е. ложь. Это означает, что адреса указателей и значения по этим адресам не совпадают.
Немного изменим код. Откройте тот же файл и обновите строковые значения. Одни и те же строковые переменные s1 и s2 были инициализированы одинаковыми значениями, то есть Aqsa. Остальной код используется без изменений, как и раньше. Сохраните свой код, чтобы получить обновленный результат.
Мы получили 0 как результат сравнения адресов указателей, поскольку обе переменные содержат разные адреса памяти, и 1 как результат сравнения значений, то есть одинаковые значения обеих строк.
Заключение
Мы обсудили арифметические операции, выполняемые над указателями. Также мы использовали арифметические операторы увеличения и уменьшения для указателей. Мы также обсудили бонусные примеры, чтобы проиллюстрировать работу оператора сравнения с двумя разными указателями.
регистров x86
регистров x86Основными инструментами для написания программ на ассемблере x86 являются регистры процессора. Регистры похожи на переменные, встроенные в процессор. Вместо этого используйте регистры памяти для хранения значений делает процесс быстрее и чище. Проблема с серия процессоров x86 заключается в том, что для использования используется мало регистров. Эта секция описывает основное использование каждого регистра и способы их использования. Это в заметку, что описанные здесь правила являются скорее рекомендациями, чем строгими правилами. Некоторые операции Нужны абсолютно какие-то регистры, но большинство из них можно использовать любые из свободных. Вот список доступных регистров на процессорах 386 и выше. В этом списке показаны 32-битные регистры. Большинство из них можно разбить на 16 или даже 8 бит. регистр.
Общие регистры EAX EBX ECX EDX Сегментные регистры CS DS ES FS GS SS Индекс и указатели ESI EDI EBP EIP ESP Индикатор ЭФЛАГСОбщие регистры
Как следует из названия, общий регистр — это тот, который мы используем большую часть времени.
32 бита: EAX EBX ECX EDX 16 бит: AX BX CX DX 8 бит: AH AL BH BL CH CL DH DLСуффиксы «H» и «L» в 8-битных регистрах обозначают старший и младший байты. С этим покончено, давайте посмотрим на их индивидуальное основное использование.
EAX,AX,AH,AL : Вызывается регистром аккумулятора.
Он используется для доступа к порту ввода/вывода, арифметических операций, вызовов прерываний,
так далее...
EBX,BX,BH,BL : Вызывается базовым регистром
Он используется в качестве базового указателя для доступа к памяти.
Получает некоторые возвращаемые значения прерывания
ECX,CX,CH,CL : вызывает регистр счетчика.
Используется как счетчик циклов и для смен
Получает некоторые значения прерывания
EDX,DX,DH,DL: Вызывается регистром данных.
Он используется для доступа к порту ввода-вывода, арифметических операций, некоторых прерываний. звонки.
звонки.
Сегментные регистры Регистры сегментов содержат адреса сегментов различных элементов. Они доступны только в 16 значениях. Они могут быть установлены только общим реестром или специальными инструкциями. Некоторые из них имеют решающее значение для хорошего выполнения программы, и вы можете хотите поиграть с ними, когда будете готовы к многосегментному программированию
CS: Содержит сегмент кода, в котором работает ваша программа.
Изменение его значения может привести к зависанию компьютера.
DS: содержит сегмент данных, к которому обращается ваша программа.
Изменение его значения может привести к ошибочным данным.
ES,FS,GS: это дополнительные сегментные регистры, доступные для
дальняя адресация указателя, такая как видеопамять и тому подобное.
SS: Содержит сегмент стека, который использует ваша программа.
Иногда имеет то же значение, что и DS.
Изменение его значения может дать непредсказуемые результаты,
в основном связанные с данными.
Индексы и указатели Индексы и указатель и смещенная часть и адрес. Они имеют различное использование но каждый регистр имеет определенную функцию. Они некоторое время использовались с сегментным регистром чтобы указать на дальний адрес (в диапазоне 1 Мб). Регистр с префиксом «Е» может только использоваться в защищенном режиме.
ES:EDI EDI DI : Регистр индекса назначения
Используется для копирования и установки строки, массива памяти и
для дальней адресации указателя с ES
DS:ESI EDI SI : Регистр исходного индекса
Используется для копирования строк и массивов памяти
SS:EBP EBP BP : Регистр указателя базы стека
Содержит базовый адрес стека
SS:ESP ESP SP : Регистр указателя стека
Содержит верхний адрес стека
CS:EIP EIP IP: индексный указатель
Содержит смещение следующей инструкции
Его можно только прочитать
Регистр EFLAGS Регистр EFLAGS хранит состояние процессора. Модифицируется многими инструкциями
и используется для сравнения некоторых параметров, условных циклов и условных переходов.
Каждый бит содержит состояние определенного параметра последней инструкции. Вот список:
Модифицируется многими инструкциями
и используется для сравнения некоторых параметров, условных циклов и условных переходов.
Каждый бит содержит состояние определенного параметра последней инструкции. Вот список:
Метка бита Описание --------------------------- 0 CF Перенести флаг 2 PF Флаг четности 4 Флажок вспомогательного переноса AF 6 Флаг нуля ZF 7 Флажок знака SF 8 Флаг ловушки TF 9IF флаг разрешения прерывания 10 DF Флаг направления 11 OF Флаг переполнения 12-13 Уровень привилегий ввода/вывода IOPL 14 NT Флаг вложенной задачи 16 Флажок возобновления РФ 17 Флаг режима виртуальной машины 8086 18 Флаг проверки выравнивания AC (486+) 19 Флаг виртуального прерывания VIF 20 Флаг ожидания виртуального прерывания VIP 21 ID Идентификационный флаг Те, которые не перечислены, зарезервированы Intel.
На процессорах 80386 и выше имеются регистры, которые недостаточно документированы.
от Intel. Они делятся на регистры управления, регистры отладки, регистры тестирования и
регистры сегментации защищенного режима. Насколько я знаю, контрольные регистры, наряду
с регистрами сегментации, используются в программировании защищенного режима, все эти регистры
доступны на процессорах 80386 и выше, за исключением тестовых регистров, которые были удалены
на пентиуме. Регистры управления — от CR0 до CR4, регистры отладки — от DR0 до DR7, тестовые
регистры — от TR3 до TR7, а регистры сегментации защищенного режима — GDTR (глобальный дескриптор).
регистр таблицы), IDTR (регистр таблицы дескрипторов прерываний), LDTR (локальный DTR) и TR.
Насколько я знаю, контрольные регистры, наряду
с регистрами сегментации, используются в программировании защищенного режима, все эти регистры
доступны на процессорах 80386 и выше, за исключением тестовых регистров, которые были удалены
на пентиуме. Регистры управления — от CR0 до CR4, регистры отладки — от DR0 до DR7, тестовые
регистры — от TR3 до TR7, а регистры сегментации защищенного режима — GDTR (глобальный дескриптор).
регистр таблицы), IDTR (регистр таблицы дескрипторов прерываний), LDTR (локальный DTR) и TR.
Указатели -Go 101
Главная новинка!
Go 101
Go Generics 101
Go Details & Tips 101
Go Optimizations 101
Go Quizzes 101
Go HowTo 101
Go Practices 101
Go Agg 101
Go 101 Блог
Go 101 Приложения и библиотеки
Тема: темная/светлая
Три новые книги Go Optimizations 101,
Подробности и советы 101
и Go Generics 101
публикуются сейчас.
Пожалуйста, подпишитесь на аккаунт Go 101 в Твиттере @Go100and1, чтобы получать последние новости о книгах/статьях/приложениях/библиотеках Go 101.
Избегайте ненужных проверок указателя массива nil в цикле
В текущей официальной стандартной реализации компилятора Go (v1.19) есть некоторые недостатки.). Одним из них является то, что некоторые проверки нулевого массива указателей не перемещаются из циклов. Вот пример, показывающий этот недостаток.
// ненужные-checks.go
указатели пакетов
импортировать "тестирование"
константа N = 1000
вар а [N] целое
//идем:нетлайн
функция g0(a *[N]int) {
для я: = диапазон {
a[i] = i // строка 12
}
}
//идем:нетлайн
функция g1(a *[N]int) {
_ = *a // строка 18
для я: = диапазон {
a[i] = i // строка 20
}
}
func Benchmark_g0(b *testing.B) {
для я := 0; я < б.Н; i++ {g0(&a)}
}
func Benchmark_g1(b *testing. B) {
для я := 0; я < б.Н; я++ {g1(&а)}
}
B) {
для я := 0; я < б.Н; я++ {g1(&а)}
}
Запустим бенчмарки с опцией компилятора -S , получим следующие результаты (неинтересующие тексты опущены):
$ go test -bench=. -gcflags=-S ненужные-checks.go ... 0x0004 00004 (ненужные-checks.go:12) TESTB AL, (AX) 0x0006 00006 (ненужные проверки.go:12) MOVQ CX, (AX)(CX*8) ... 0x0000 00000 (ненужные-checks.go:18) TESTB AL, (AX) 0x0002 00002 (ненужные проверки.go:18) XORL CX, CX 0x0004 00004 (ненужные проверки.go:19) JMP 13 0x0006 00006 (ненужные-checks.go:20) MOVQ CX, (AX)(CX*8) ... Benchmark_g0-4 517,6 нс/оп Benchmark_g1-4 398,1 нс/оп
Из выходных данных мы можем сделать вывод, что реализация g1 более производительна, чем реализация g0 ,
даже если реализация g1 содержит еще одну строку кода (строка 18).
Почему? На вопрос отвечает выведенная инструкция по сборке.
В реализации g0 инструкция TESTB генерируется внутри цикла, тогда как в реализации g1 инструкция TESTB генерируется вне цикла.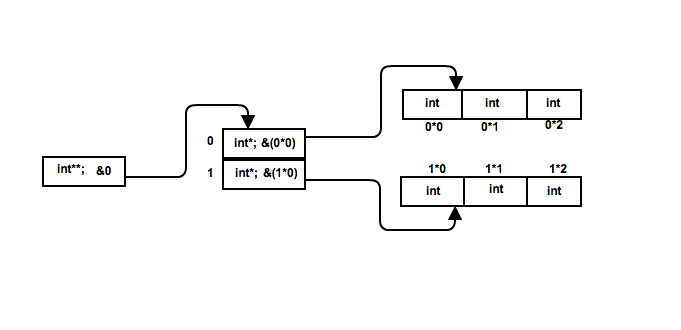 9Инструкция 0101 TESTB используется для проверки того, является ли аргумент
9Инструкция 0101 TESTB используется для проверки того, является ли аргумент a нулевым указателем.
Для указанного случая достаточно один раз проверить.
Еще одна строка кода позволяет избежать недостатка в реализации компилятора.
Существует третья реализация, производительность которой не уступает реализации g1 .
Третья реализация использует срез, полученный из аргумента указателя массива.
//go:noinline
функция g2(x *[N]int) {
а:= х[:]
для я: = диапазон {
а [я] = я
}
}
Обратите внимание, что ошибка может быть исправлена в будущих версиях компилятора.
Обратите внимание, что если три функции реализации будут встроенными, результаты тестов сильно изменятся.
Вот почему здесь используются директивы компилятора //go:noinline .
(До версии Go toolchain v1.18 директивы компилятора //go:noinline здесь фактически не нужны.
Потому что набор инструментов Go v1.18 никогда не встраивает функцию, содержащую цикл for-range . )
)
Случай, когда указатель массива является полем структуры
В случаях, когда указатель массива является полем структуры, все немного сложнее.
Строка _ = *t.a в следующем коде бесполезна, чтобы избежать ошибки компилятора.
Например, в следующем коде разница в производительности между функцией f1 и функцией f0 невелика.
(На самом деле функция f1 может работать еще медленнее, если в ее цикле генерируется инструкция NOP .)
тип T структура {
*[N]инт
}
//идем:нетлайн
функция f0(t *T) {
для я: = диапазон t.a {
т.а [я] = я
}
}
//идем:нетлайн
функция f1(t *T) {
_ = *т.а
для я: = диапазон t.a {
т.а [я] = я
}
}
Чтобы вывести проверки нулевого массива указателей из цикла, мы должны скопировать поле t.a в локальную переменную, а затем применить описанный выше прием:
//go:noinline
функция f3(t *T) {
а := т.а
_ = * а
для я: = диапазон {
а [я] = я
}
}
Или просто получить срез из поля указателя массива:
//go:noinline
функция f4(t *T) {
а := т. а[:]
для я: = диапазон {
а [я] = я
}
}
а[:]
для я: = диапазон {
а [я] = я
}
}
Результаты тестов:
Benchmark_f0-4 622,9 нс/оп Benchmark_f1-4 637,4 нс/оп Benchmark_f2-4 511,3 нс/оп Benchmark_f3-4 390,1 нс/оп Benchmark_f4-4 387,6 нс/оп
Результаты подтверждают наши предыдущие выводы.
Обратите внимание, функция f2 , упомянутая в результатах тестов, объявлена как
//go:noinline
функция f2(t *T) {
а := т.а
для я: = диапазон {
а [я] = я
}
}
Реализация f2 не такая быстрая, как реализации f3 и f4 , но она быстрее, чем реализации f0 и f1 . Впрочем, это уже другая история (извините, ссылка битая,
ибо другая история описана в платной главе).
Если элементы поля указателя массива не изменяются (только читаются) в цикле, то способ f1 так же эффективен, как f3 и f4 путь.
Лично я думаю, что в большинстве случаев мы должны попытаться использовать способ среза (способ f4 ), чтобы получить лучшую производительность,
потому что обычно слайсы оптимизируются лучше, чем массивы, официальным стандартным компилятором Go.
Избегайте ненужных разыменований указателя в цикле
Иногда текущий официальный стандартный компилятор Go (v1.19) недостаточно умен, чтобы генерировать ассемблерные инструкции наиболее оптимизированным способом. Мы должны написать код другим способом, чтобы получить наилучшую производительность. Например, в следующем коде 9Функция 0101 f намного менее эффективна, чем функция g .
// избежать-indirects_test.go
указатели пакетов
импортировать "тестирование"
//идем:нетлайн
функция f(сумма *int, s []int) {
for _, v := range s { // строка 8
*сумма += v // строка 9
}
}
//идем:нетлайн
func g(sum *int, s []int) {
переменная n = *сумма
for _, v := range s { // строка 16
n += v // строка 17
}
* сумма = п
}
var s = make([]int, 1024)
вар г целое
func Benchmark_f(b *testing.B) {
для я := 0; я < б.Н; я++ {
f(&r, с)
}
}
func Benchmark_g(b *testing.B) {
для я := 0; я < б.Н; я++ {
g(&r, с)
}
}
Результаты тестов (незаинтересованные тексты опущены):
$ go test -bench=.-gcflags=-S избежать-indirects_test.go ... 0x0009 00009 (avoid-indirects_test.go:9) MOVQ (AX), SI 0x000c 00012 (avoid-indirects_test.go:9) ADDQ (BX)(DX*8), SI 0x0010 00016 (avoid-indirects_test.go:9) MOVQ SI, (AX) 0x0013 00019 (avoid-indirects_test.go:8) INCQ DX 0x0016 00022 (avoid-indirects_test.go:8) CMPQ CX, DX 0x0019 00025 (avoid-indirects_test.go:8) JGT 9 ... 0x000b 00011 (avoid-indirects_test.go:16) MOVQ (BX)(DX*8), DI 0x000f 00015 (avoid-indirects_test.go:16) INCQ DX 0x0012 00018 (avoid-indirects_test.go:17) ADDQ DI, SI 0x0015 00021 (avoid-indirects_test.go:16) CMPQ CX, DX 0x0018 00024 (avoid-indirects_test.go:16) JGT 11 ... Benchmark_f-4 3024 нс/оп Benchmark_g-4 566,6 нс/оп
Выведенные инструкции по сборке показывают, что указатель sum разыменован в цикле в функции f .
Операция разыменования — это операция с памятью.
Для функции g операции разыменования происходят вне цикла,
и инструкции, сгенерированные для цикла, обрабатывают только регистры. Гораздо быстрее позволить инструкциям ЦП обрабатывать регистры, чем обрабатывать память.
вот почему функция
Гораздо быстрее позволить инструкциям ЦП обрабатывать регистры, чем обрабатывать память.
вот почему функция g гораздо более эффективна, чем f функция.
Это не ошибка компилятора. На самом деле функции f и g не эквивалентны
(хотя для большинства случаев использования на практике их результаты совпадают).
Например, если они вызываются, как показано в следующем коде, они возвращают разные результаты.
(спасибо skeeto@reddit за это исправление).
{
переменная с = []целое{1, 1, 1}
сумма переменных = &s[2]
f(сумма, с)
println(*сумма) // 6
}
{
переменная с = []целое{1, 1, 1}
сумма переменных = &s[2]
г (сумма, с)
println(*сумма) // 4
}
Другая эффективная реализация для указанного случая — перемещение параметра указателя из тела функции.
(опять же, это не полностью эквивалентно функции f или g ):
//go:noinline
func h(s []int) int {
переменная п = 0
для _, v := диапазон s {
п += v
}
вернуть н
}
func use_h(s []int) {
сумма переменных = новый (целое число)
*сумма += ч(с)
. ..
}
..
}
Индекс↡
Цифровые версии этой книги доступны в следующих местах:
- магазин Линпаб, $7,99+ (Или купите эту книгу из этого или этого комплекта книг).
- магазин Apple Books, 7,99 $ .
- магазин Amazon Kindle, 7,99 $ .
Тапир, автор Go 101, писал книги из серии Go 101. и поддержка сайта go101.org с июля 2016 года. Новое содержание будет постоянно добавляться в книгу и на веб-сайт время от времени. Tapir также является независимым разработчиком игр. Вы также можете поддержать Go 101, играя в игры Tapir. (сделано как для Android, так и для iPhone/iPad):
- Color Infection (★★★★★), основанная на физике оригинальная казуальная игра-головоломка. 140+ уровней.
- Rectangle Pushers (★★★★★), оригинальная казуальная игра-головоломка. Два режима, 104+ уровней.