JavaScript RegExp Ссылка
❮ Предыдущая Следующая Ссылка ❯
RegExp объект
Регулярное выражение является объектом, который описывает образец символов.
Регулярные выражения используются для выполнения поиска по шаблону и «search-and-replace» функции по тексту.
Синтаксис
/ pattern / modifiers ;
пример
var patt = /w3ii/i
Объяснение примера:
- / w3ii / я является регулярным выражением.
- w3ii является шаблоном (to be used in a search) .
- я модификатор (modifies the search to be case-insensitive) , (modifies the search to be case-insensitive) к (modifies the search to be case-insensitive) .
Для учебника о регулярных выражениях, читайте JavaScript RegExp Учебник .
Модификаторы
Модификаторы используются для выполнения нечувствительны к регистру и глобального поиска:
| Модификатор | Описание |
|---|---|
| i | Выполните регистронезависимое согласование |
| g | Выполнить глобальный матч (find all matches rather than stopping after the first match) , (find all matches rather than stopping after the first match) |
| m | Выполните многострочный согласование |
Кронштейны
Кронштейны используются, чтобы найти диапазон символов:
| выражение | Описание |
|---|---|
| [abc] | Найти любой символ в скобках |
| [^abc] | Найти любой символ НЕ между кронштейнами |
| [0-9] | Найти любую цифру в скобках |
| [^0-9] | Найти любую цифру НЕ в скобках |
| (x|y) | Найти какой-либо из вариантов, указанных |
метасимволов
Метасимволов персонажи с особым смыслом:
| Метасимвол | Описание |
|---|---|
| , | Найти один символ, кроме символа новой строки или конца строки |
| \ ш | Найти слово характер |
| \ W | Найти несловообразующий характер |
| \ d | Найти цифру |
| \ D | Найти нецифры характер |
| \ s | Найти символ пробела |
| \ S | Найти непробельный характер |
| \ б | Найти матч в начале / конце слова |
| \ B | Найти матч не в начале / конце слова |
| \ 0 | Найти символ NUL |
| \ п | Найдите символ новой строки |
| \ е | Найти символ формы подачи |
| \р | Найти символ возврата каретки |
| \ т | Найдите символ табуляции |
| \ v | Найти вертикальной табуляции |
| \ ххх | Найти символ, заданный восьмеричное число ххх |
| \ XDD | Найти символ, заданный шестнадцатеричным числом дд |
| \ ихххх | Найти символ Unicode, заданный шестнадцатеричным числом хххх |
Кванторы
| Квантор | Описание |
|---|---|
| n+ | Соответствует любую строку , которая содержит по меньшей мере один п |
| n* | Соответствует любую строку , которая содержит ноль или более вхождений п |
| n? | Соответствует любую строку , которая содержит ноль или один вхождение п |
| n{X} | Соответствует любую строку , которая содержит последовательность X n «ы |
| n{X,Y} | Соответствует любую строку , которая содержит последовательность X к Y n «ы |
| n{X,} | Соответствует любую строку , которая содержит последовательность , по меньшей мере , Х n «ы |
| n$ | Соответствует любой строке с п в конце этого |
| ^n | Соответствует любой строке с п в начале этого |
| ?=n | Соответствует любой строке , которая сопровождается определенной строки п |
| ?!n | Соответствует любую строку, не следует определенной строка п |
Свойства объекта RegExp
| Имущество | Описание |
|---|---|
| constructor | Возвращает функцию, которая создала прототип объекта типа RegExp |
| global | Проверяет , находится ли «g» установлен модификатор |
| ignoreCase | Проверяет , находится ли «i» модификатор установлен |
| lastIndex | Определяет индекс, с которого начинается следующий матч |
| multiline | Проверяет , находится ли «m» установлен модификатор |
| source | Возвращает текст шаблона RegExp |
Методы объекта RegExp
| метод | Описание |
|---|---|
| compile() | Устаревшие версии 1. 5. Компилирует регулярное выражение 5. Компилирует регулярное выражение |
| exec() | Тесты на матч в строке. Возвращает первый матч |
| test() | Тесты на матч в строке. Возвращает истину или ложь |
| toString() | Возвращает строковое значение регулярного выражения |
❮ Предыдущая Следующая Ссылка ❯
Как, наконец, выучить Regex? | Techrocks
Перевод статьи «Step up your Regex game».
Photo by Madelynn woods on UnsplashИзучение Regex (регулярных выражений) — не фунт изюма. Поначалу это не то чтобы интересно и уж тем более не просто, но это очень важный навык, когда дело касается работы со строками. В этой статье вы найдете советы по изучению Regex, ссылки на руководства и шпаргалки.
Когда я впервые увидел Regex, первое, что я сказал, было «Что это, черт побери, такое?» Я сразу понял, что чтобы написать такое выражение правильно, потребуется некоторое время и предельная концентрация, так что решил отложить это дело «на потом». А потом я все откладывал и откладывал, как-то решая задачи без Regex — аж пока вопрос по регулярным выражениям не встретился мне на техническом собеседовании.
А потом я все откладывал и откладывал, как-то решая задачи без Regex — аж пока вопрос по регулярным выражениям не встретился мне на техническом собеседовании.
На самом деле Regex очень важны. Причем не только для решения задач, в которых нужно что-то делать со строками. Они также широко используются в текстовых редакторах, для поиска данных, фильтрации результатов, проверки паролей, email-ов и форм. Решая задачи на CodeWars или HackerRank, вы можете вдвое сократить время решения, применив Regex.
В общем, я осознал, насколько это полезная тема, и решил разобраться в регулярных выражениях досконально. Я ведь хотел быть как можно более эффективным и решать задачи не брутфорс-атакой, а по-умному.
Ниже я перечислил способы изучения регулярных выражений, которые мне показались самыми эффективными. Сразу замечу, что если вы хотите научиться писать регулярные выражения, то нужно постоянно практиковаться, без этого никак.
Первые шаги
Вы поняли, что вам нужно изучить Regex, но не знаете, с чего начать?
Шаг 1 — пройдите какое-нибудь обучающее руководство
Есть достаточное количество сайтов, предлагающих пошаговое обучение регулярным выражениям. Мне особенно нравится, что некоторые из них предлагают задачки в конце.
Мне особенно нравится, что некоторые из них предлагают задачки в конце.
- RegexOne
- Learn Regex
- Tutorial на RegularExpressions.Info
- Mozilla Regular Expressions (Здесь можно посмотреть, как использовать регулярные выражения в коде).
- JS Regex Tutorial на W3Schools
- Regular Expressions на Javascript.info
Шаг 2 — практика на CodeWars или HackerRank
Вам нужно немедленно начать использовать регулярные выражения при решении задач, в которых надо работать со строками. Отправляйтесь на CodeWars и HackerRank и начинайте с самого начала. Когда мне нужно изучить что-то новое или освежить что-то в памяти, я создаю себе новые аккаунты на этих сайтах и начинаю с начала.
Отмечу, что очень помогает, когда вы решаете какие-то знакомые задачи или полезные для вас лично.
Я часто создаю новый Repl.it и решаю задачу там, а затем вставляю решение в редактор на HackerRank или CodeWars. Просто вытащите несколько массивов или данные, которые они используют для тестирования, и запустите на них свое решение.
Конечно, помимо Repl.it есть и другие онлайн-редакторы кода, например JS Bin, PlayCode, JS Fiddle — можно пользоваться любым из них.
Вот несколько примеров задач, достаточно простых для использования в них регулярных выражений:
- CodeWars — Your order, please (нужно выстроить слова в строке по порядку).
- CodeWars — Jaden Casing (нужно сделать так, чтобы каждое слово в строке начиналось с заглавной буквы).
- CodeWars — задачи, связанные со строками.
- HackerRank — Solve Regex (список Regex-задач).
Шаг 3 (опционально) — найдите видео на YouTube, Udemy или других сайтах
Можно подписаться на людей, которые выкладывают материалы по регулярным выражениям. Эти видео будут вас вдохновлять (возможно), а также научат полезным приемам.
Photo by Christina @ wocintechchat.com on UnsplashПоследующие шаги
Итак, вы изучили основы регулярных выражений. Что дальше? Немедленно беритесь за собственные проекты! Единственный способ по-настоящему изучить Regex и впечатать их в память — сразу начать создавать что-нибудь. Причем работать нужно полностью самостоятельно, без руководств и чьей-либо помощи.
Причем работать нужно полностью самостоятельно, без руководств и чьей-либо помощи.
Вот пара идей для первых проектов:
- Создайте инструмент для тестирования регулярных выражений на строке. Пользователь пишет регулярное выражение, а ваш инструмент подсвечивает ту часть строки, которая совпадает с шаблоном. В качестве результата оценки пускай выдается сообщение «Успех!» или «Провал».
- Создайте инструмент поиска с фильтрацией. Возвращаться должны только наборы данных, соответствующие введенной ст роке. Пример — поиск на Netflix или DisneyPlus. Вы вводите слово в окошке поиска и получаете список видео, которые содержат в названии это или похожее слово. Есть тысяча и один способ сделать свой вариант такого функционала.
Полезные инструменты
Продолжайте практиковаться в использовании регулярных выражений. Вот несколько полезных инструментов и ресурсов, которые помогут вам в этом.
Шпаргалки
В шпаргалки можно подглядывать, когда вы занимаетесь своим проектом или решаете задачу и вам нужно быстренько что-то посмотреть.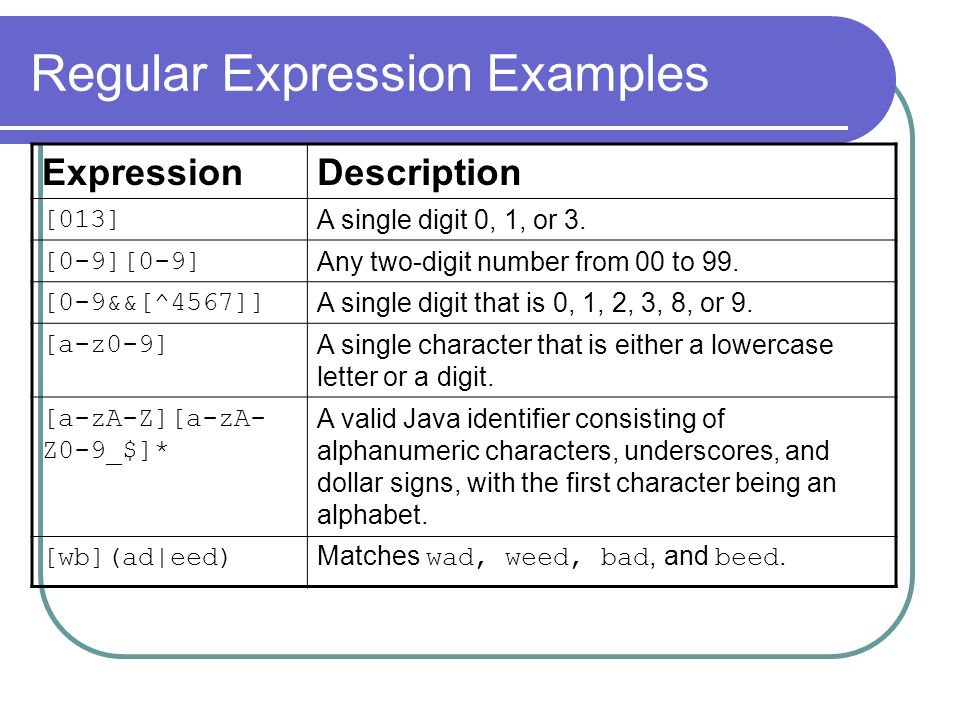
- Regex Tutorial. Шпаргалка с примерами использования регулярных выражений от Джонни Фокса.
- Ultimate Regex Cheatsheet («полная» шпаргалка по регулярным выражениям).
Практика
Практиковаться можно на специальных движках Regex. Они бывают очень полезны, когда нужно написать и проверить регулярное выражение до вставки в код.
- Regexr.com
- Regex101.com
Я надеюсь, что эта статья будет вам полезна. Не забывайте, что если у вас возникают трудности в программировании, решение обязательно есть, и вы сможете его найти. Не сдавайтесь и продолжайте развиваться. Также помните о том, что все люди уникальны, как и их подходы к учебе. Вам нужно лишь найти тот, что подойдет именно вам, и дальше все пойдет, как по маслу!
Regex в JS — как ВЫ можете изучить его и научиться любить его
Я пишу это самому себе из будущего. На самом деле, многие мои статьи обращены к самому себе в будущем, который забыл все о том, как что-то делать.
RegEx, регулярные выражения — действительно мощный инструмент в нашем наборе инструментов. К сожалению, мы называем это черной магией, дьяволом и прочими прелестями. Это не должно быть так. RegEx, конечно, отличается от обычного программирования, но это действительно очень мощное средство. Давайте узнаем, как это работает и как на самом деле использовать и применять к повседневным проблемам, которые вы знаете.
TLDR; Это долго? Да, но он проходит через основные конструкции в RegEx. Кроме того, в конце у меня есть несколько хороших рецептов о том, как делать такие вещи, как RegEx для электронной почты, пароли, преобразования формата даты и как обрабатывать URL-адреса. Если вы никогда раньше не работали с RegEx или вам трудно замечать всю эту странную магию — это для вас. Приятного чтения 😃
Ссылки
Есть несколько замечательных ресурсов для RegEx, к которым я регулярно обращаюсь. Потратьте время, чтобы прочитать их. Иногда они объясняют, как обрабатывается RegEx, и могут объяснить, почему magic случается:
- Информация о регулярных выражениях
Хороший сайт с большим количеством информации о RegEx.
- Страницы документов Mozilla на RegEx Хороший сайт, подробные объяснения с примерами
- Информация о JavaScript Некоторые из лучших объяснений, которые я видел в группах RegEx.
- Именованные группы
- Документы по регулярным выражениям Несмотря на то, что это руководство по .NET, информация о регулярных выражениях довольно общая и применимая
Практика
Node.js REPL . Если у вас установлен Node.js, я рекомендую просто ввести
nodeв терминале. Это запустит REPL, это отличный способ протестировать шаблоныJavaScript REPL , это расширение VS Code, которое оценивает то, что вы вводите. Вы получите мгновенную обратную связь о результатах
Браузер Отличная среда песочницы. Спасибо за совет Лукаш 😃
Регулярные выражения
Регулярные выражения или RegEx предназначены для сопоставления с образцом.
- URL-адрес , URL-адрес содержит много интересной информации, такой как
имя хоста,маршрут,порт,параметры маршрутаипараметры запроса. Мы хотим иметь возможность извлекать эту информацию, а также проверять ее правильность. - Пароль , чем длиннее пароль, тем лучше, обычно это то, что нам нужно. Есть и другие измерения, такие как сложность. Под сложностью мы подразумеваем, что наш пароль должен содержать, например, цифры, специальные символы и многое другое.
 На самом деле существует целая категория компьютерных программ, посвященных этому, под названием 9.0011 скребки .
На самом деле существует целая категория компьютерных программ, посвященных этому, под названием 9.0011 скребки .
Регулярное выражение создается следующим образом:
/шаблон/
1
Начинается и заканчивается на /.
Или вот так, где мы создаем объект из класса RegEx :
new RegEx(/pattern/)
1
Методы
Существует несколько различных методов, предназначенных для различных типов использования. Важно научиться использовать правильный метод.
-
exec(), Выполняет поиск совпадения в строке. Возвращает массив информацииили нольпри несоответствии. -
test(), проверяет совпадение в строке, отвечаетtrueилиfalse -
match(), возвращает массив, содержащий все совпадения, включая группы захвата, илиnull, если совпадений не найдено.
-
matchAll(), Возвращает итератор, содержащий все совпадения, включая группы захвата. -
search(), Проверяет соответствие в строке. Он возвращает индекс совпадения или -1, если поиск не удался. -
replace(), Выполняет поиск совпадения в строке и заменяет совпадающую подстроку замещающей подстрокой. -
split(), Использует регулярное выражение или фиксированную строку для разбиения строки на массив подстрок.
Давайте покажем несколько примеров с учетом вышеуказанных методов.
тест() , тестовая строка для истинности/ложности Давайте рассмотрим пример с использованием test() :
/\w+/.test('abc123') // true
1
Выше мы проверяем строку abc123 на наличие всех буквенных символов \w+ и отвечаем на вопрос, содержите ли вы буквенные символы.
match() , найти совпадения Рассмотрим пример:'orders/items'.match(/\w+/) // [ 'orders', groups: undefined, index: 0, input ]
1
Приведенный выше ответ массива говорит нам, что мы можем сопоставить заказа с нашим шаблоном \w+ . Мы не захватили ни одной группы, на что указывает groups:undefined , и наше совпадение было найдено по адресу index:0 . Если бы мы хотели сопоставить все буквенные символы в строке, нам пришлось бы использовать флаг g . g указывает глобальное соответствие , например:
'orders/items'.match(/\w+/g) // ['orders', 'items']
1
Группы
У нас также есть понятие групп. Чтобы начать использовать группы, нам нужно заключить наш шаблон в круглые скобки следующим образом:
const matchedGroup = 'orders/114'.match(/(?\d+)/) // [114, 114, groups: { order : 114 }]
1
Использование конструкции ? создает так называемую именованную группу.
Флаги
Есть разные флаги. Перечислим некоторые из них. Все флаги добавляются в конце регулярного выражения. Таким образом, типичное использование выглядит так:
var re = /шаблон/флаги;
1
-
g, вы говорите, что хотите сопоставить всю строку, а не только первое вхождение -
i, это означает, что мы хотим совпадение без учета регистра
- Граница , это для сопоставления элементов в начале и конце слова
- Другие утверждения 9 слово
тест.Обратное будет выглядеть так:
/test$/.test('123test')1
Классы символов
Классы символов относятся к различным типам символов, таким как буквы и цифры. Перечислим некоторые из них:
-
., соответствует любому одиночному символу, кроме разделителей строк, таких как\nили\r -
\d, соответствует цифрам, эквивалентным[0-9[0-9] -
\w, соответствует любому буквенному символу, включая_. Эквивалент
Эквивалент [a-zA-Z0-9_] -
\W, отрицание вышесказанного. Соответствует%например -
\s, соответствует пробельным символам -
\t, соответствует табуляции -
\r, соответствует возврату каретки \n переводу строки 5 -
\, управляющий символ. Его можно использовать для соответствия/вот так\/. Также используется для придания символам специального значения.
Квантификаторы
Квантификаторы определяют количество совпадающих символов:
-
*, от 0 до многих символов -
+, от 1 до многих символов 90} , совпадение n символов -
{n,}, совпадение >= n символов -
{n,m}, совпадение >= n && =< m символов -
?, нежадное сопоставление
Рассмотрим несколько примеров
/\w*/.
 test('abc123') // true
/\w*/.test('') // верно. * = от 0 до многих
test('abc123') // true
/\w*/.test('') // верно. * = от 0 до многих
1
2В следующем примере мы используем
?:/\/продукты\/?/.test('/products') ///продукты\/?/.test('/products/')1
2?делает окончание/необязательным, когда мы используем этот тип соответствия\/?.DEMO
Хорошо, это много теории, смешанной с некоторыми примерами. Далее давайте рассмотрим некоторые реалистичные сопоставления, сопоставления, которые мы действительно будем использовать в производстве.
Если вы используете JavaScript на бэкенде, вы, вероятно, уже используете какие-то фреймворки, такие как Express, Koa или, возможно, Nest.js. Знаете ли вы, что эти фреймворки делают для вас с точки зрения сопоставления маршрутов, параметров и многого другого? Что ж, пора это выяснить.
Соответствие маршруту
Такой же простой маршрут, как
/products, как нам его сопоставить?. Ну, мы знаем, что наш URL-адрес должен содержать эту часть, поэтому написать регулярное выражение для этого довольно просто. Давайте также учтем, что некоторые будут вводить
Ну, мы знаем, что наш URL-адрес должен содержать эту часть, поэтому написать регулярное выражение для этого довольно просто. Давайте также учтем, что некоторые будут вводить /products, а некоторые другие будут вводить/products/:/\products\/?$/.test('/products')1
Вышеупомянутое регулярное выражение удовлетворяет всем нашим потребностям от сопоставления
/с\/до сопоставления необязательного/в конце с\/?.Хорошо, возьмем аналогичный случай.
/продукты/112. Маршрут/productsс номером в конце. Начнем проверять, соответствует ли входящий маршрут://products\/\d+$/.test('/products/112') // true //продукты\/\d+$/.test('/products/') // ложь1
2Чтобы извлечь параметр маршрута, мы можем ввести следующее:
const [ productId] = '/products/112'.match(/\/products\/(\d+)/) // идентификатор продукта = 112
1
2Хорошо, допустим, у вас есть маршрут, похожий на этот
/orders/113/items/55. Это примерно соответствует заказу с идентификатором
Это примерно соответствует заказу с идентификатором 113и идентификатору позиции заказа55. Сначала мы хотим убедиться, что наш входящий URL-адрес совпадает, поэтому давайте посмотрим на RegEx для этого:/\orders\/\d+\/items\/\d+\/?/.test('/orders/99/items/ 22') // верно1
/orders/[1-n цифр]/items/[1-n цифр][необязательно /]Теперь мы знаем, что можем сопоставить указанный выше маршрут. Давайте возьмем эти параметры дальше. Мы можем сделать это, используя именованные группы:
var { groups: { orderId, itemId } } = '/orders/99/items/22'.match(/(?\d+)\/items\/(? \d+)\/?/) // идентификатор заказа = 99 // элементы = 22 1
2
3Приведенное выше выражение вводит группы путем создания именованных групп
orderIdиitemIdс конструкциями(?и\d+) (?соответственно.\d+)  Шаблон очень похож на тот, который используется с методом
Шаблон очень похож на тот, который используется с методом test().Классификатор маршрутов
Я уверен, вы видели, как маршрут был разделен на несколько частей, таких какпротокол,хост,маршрут,портипараметры запроса.Это очень легко сделать. Предположим, мы смотрим на URL-адрес, который выглядит так:
http://localhost:8000/products?page=1&pageSize=20. Мы хотим разобрать этот URL и в идеале получить что-то удобное для работы, например:{ протокол: 'http', хост: «локальный хост», маршрут: '/products?page=1&pageSize=20', порт: 8000 }1
2
3
4
5
6Как туда добраться? Что ж, то, что вы видите, следует очень предсказуемому шаблону, а RegEx — это Mjolnir of Hammers , когда дело доходит до сопоставления с шаблоном. Давайте сделаем это 😃
var http = 'http://localhost:8000/products?page=1&pageSize=20' .

1
2
3
4Давайте разберем приведенное выше и разберем его:
-
(?<протокол>\w+):, это соответствует n количеству буквенных символов, оканчивающихся на 4 :3 . Кроме того, он помещается в именованную группу
протокол -
\/{2}, это просто говорит, что у нас есть//, обычно послеhttp://. -
(?, это соответствует n количеству буквенных символов, заканчивающихся на\w+): :, поэтому в данном случае он соответствуетlocalhost. Кроме того, он помещается в именованную группухост. -
(?, это соответствует некоторым цифрам, которые следуют после хоста, который будет портом. Кроме того, он помещается в именованную группу\d+) порт.
-
(?, наконец, у нас есть сопоставление маршрута, которое просто соответствует любым символам, что гарантирует, что мы получим часть.*) ?page=1&pageSize=20. Кроме того, он помещается в именованную группуroute.
Чтобы проанализировать параметры запроса, нам просто нужно регулярное выражение и один вызов
reduce(), например:const queryMatches = http.groups.route.match(/(\w+=\w+)/g ) // ['page=1', 'pageSize=20'] const queryParams = queryMatches.reduce((acc, curr) => { const [ключ, значение] = curr.split('=') обр[...обр, [ключ]: значение] }, {}) // {страница: 1, размер страницы: 20}1
2
3
4
5
6Выше мы работаем с ответом от нашего первого сопоставления шаблона
http.groups.route. Теперь мы создаем шаблон, который будет соответствовать следующему[любой символ алфавита]=[любой символ алфавита]. Кроме того, поскольку у нас есть глобальное совпадениеg, мы получаем массив ответов.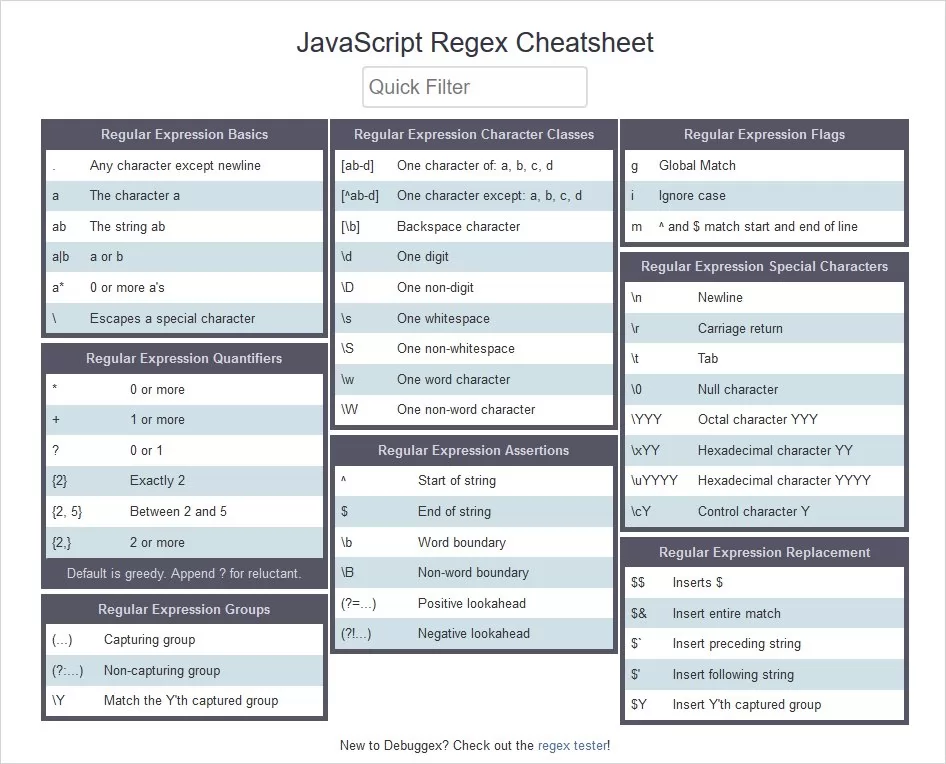 Это соответствует всем параметрам нашего запроса. Наконец, мы вызываем
Это соответствует всем параметрам нашего запроса. Наконец, мы вызываем reduce()и превращаем массив в объект.Сложность пароля
Сложность пароля заключается в том, что он поставляется с различными критериями, такими как:
- длина , он должен быть больше n символов и, возможно, меньше m символов
- цифры , должен содержать число
- специальный символ , должен содержать специальные символы
Тогда мы в безопасности? Что ж, безопаснее, не забывайте о двухфакторной аутентификации в приложении, а не о вашем номере телефона.
Давайте посмотрим на RegEx для этого:
// проверка хотя бы 1 номера var pwd = /\d+/.test('пароль1') // проверка хотя бы на 8 символов var pwdNCharacters = /\w{8,}/.test('пароль1') // проверка хотя бы одного из &, ?, !, - var specialCharacters = /&|\?|\!|\-+/.test('password1-')1
2
3
4
5
6
7
8
9Как видите, каждое требование я строю как сопоставление с собственным образцом.
 Вам нужно пройти через каждый из паролей, чтобы убедиться, что он действителен.
Вам нужно пройти через каждый из паролей, чтобы убедиться, что он действителен.Идеальное свидание
На моей нынешней работе я сталкиваюсь с коллегами, которые все думают, что их формат даты — тот, который следует использовать всем нам. В настоящее время это означает, что моему бедному мозгу приходится иметь дело с:
// YY/MM/DD , европейский стандарт ISO. // ДД/ММ/ГГ, британский // ММ/ДД/ГГ, Америка, США
1
2
3Итак, вы можете себе представить, что мне нужно знать национальность того, кто прислал мне электронное письмо каждый раз, когда я получаю электронное письмо с датой в нем. Это больно 😃. Итак, давайте создадим регулярное выражение, чтобы мы могли легко менять его по мере необходимости.
Допустим, мы получаем дату в США, например,
ММ/ДД/ГГ. Мы хотим извлечь важные части и поменять местами дату, чтобы кто-то из европейцев/британцев мог это понять. Давайте также предположим, что наш ввод ниже американский:var toBritish = '12/22/20'.
 replace(/(?
replace(/(?\d{2})\/(? \d{2}) \/(?<год>\d{2})/, '$2/$1/$3') var toEuropeanISO = '22/12/20'.replace(/(?<месяц>\д{2})\/(?<день>\д{2})\/(?<год>\д{2} )/, '3 доллара/1 доллар/2 доллара') 1
2Выше мы можем сделать именно это. В нашем первом параметре
replace()мы даем ему наше регулярное выражение. Наш второй параметр — это то, как мы хотим его поменять местами. Для британского свидания мы просто меняем месяц и день, и все счастливы. Для европейской даты нам нужно сделать немного больше, так как мы хотим, чтобы она начиналась с года, затем месяца и дня.Электронная почта
Хорошо, поэтому для электронной почты нам нужно подумать о нескольких вещах
-
@, должен быть@символ где-то посередине -
имя, у людей могут быть длинные имена, с тире/дефисом и без них. Это означает, что людям можно звонить,на,на альбинаи так далее -
фамилия, им нужна фамилия, или электронная почта просто фамилия или имя -
домен, нам нужно внести в белый список несколько доменов, таких как., com
com .gov,.edu
Имея все это в виду, я даю вам регулярное выражение: 9 , это означает, что он начинается с.
-
-
(\w+\-?\w+\.)*, это означает слово с нашим без-так как у нас есть шаблон-?и заканчивая., значитчел.,пер-альбин.. Кроме того, мы заканчиваем*, поэтому 0 для многих из них. -
(\w+){1}, это означает ровно одно слово, например электронное письмо, состоящее только из фамилии или только имени. Это открывается для комбинации 1) + 2), поэтомуper-albin.hanssonилиper.hanssonили 2) отдельно, что соответствует per илиhansson. -
@, нам нужно сопоставить один символ@ -
\w+\., здесь мы сопоставляем имя, оканчивающееся на ., например,Швеция. -
(\w+\., здесь мы открываем несколько поддоменов или никого, учитывая )*
)* *, например sthlm.region. и т. д. -
(edu|gov|com), доменное имя, здесь мы перечисляем разрешенные домены:edu,govилиcom -
$, это означает, что мы гарантируем, что кто-то не введет какую-нибудь чушь после доменного имени Соответствует ли регулярное выражение всей строке?
На этот вопрос можно ответить, построив DFA из регулярное выражение и моделирование ввода в результирующем DFA.
Соответствует ли регулярное выражение подстроке строки?
На этот вопрос можно ответить, добавив префикс к исходному обычному выражение с .* и построение DFA из регулярного выражения и моделирование ввода в результирующий DFA.

Соответствует ли регулярное выражение подстроке строки? Если да, то где?
На этот вопрос можно ответить, добавив префикс к исходному обычному выражение с .* и создание DFA из регулярного выражения и моделирование ввода в результирующий DFA. Затем мы строим обратный DFA и сопоставьте обратный DFA с обратным вводом, начиная с точки, где закончилось совпадение, и проследить где обратный DFA соответствует перевернутой строке.
Соответствует ли это регулярное выражение этой строке? Если да, то где? Где подматчи?
На этот вопрос можно ответить, только построив NFA из регулярное выражение и моделирование ввода в результирующем NFA.
Построение NFA из регулярного выражения с использованием метода Томпсона строительство затраты
O(м), гдемдлина регулярного выражение.
Построение DFA из регулярного выражения включает сначала создание NFA из регулярного выражения, а затем преобразование NFA в DFA. Преобразование затрат NFA в DFA О(2 м ю.ш.), где
мдлина регулярного выражение, аS— количество символов во входных данных алфавит.Сопоставление NFA с
mсостояний со строкой длиныnстоит O(mn). См. Реализация: Моделирование NFA для получения подробной информации о том, как для имитации NFA на входной строке. Требование к дополнительному пространству равно О(м).Сопоставление DFA с
mсостояний по строке длиныnстоит O(n). Дополнительное пространство требуется O (1).Сопоставление NFA с
mсостояний иcгрупп захвата против строки длиныnстоит O(mn log c). Фактор
Фактор log cсвязан с тем, что наборы захвата должны быть обновляется и копируется с одного узла на другой в очереди узлы. Эта копия может быть выполнена с использованием функциональных данных структура используя копирование пути с дополнительным указатель, что позволяет нам поддерживать этот случай, используя O(m) дополнительной памяти, что это то же самое, что сопоставление с использованием NFA без поддержки частичного сопоставления захватывает.
Резюме
. Мы действительно рассмотрели много вопросов по теме RegEx. Надеюсь, теперь вы лучше понимаете, из каких компонентов он состоит. Кроме того, я надеюсь, что примеры из реальной жизни заставили вас понять, что вам может просто не понадобиться устанавливать этот дополнительный модуль node. Надеюсь, после небольшой практики вы почувствуете, что RegEx полезен и действительно может сделать ваш код намного короче, элегантнее и даже читабельнее. Да, я сказал читабельно. RegEx вполне удобочитаем, как только вы поймете, как оцениваются вещи. Вы обнаружите, что чем больше времени вы тратите на это, тем больше оно окупается.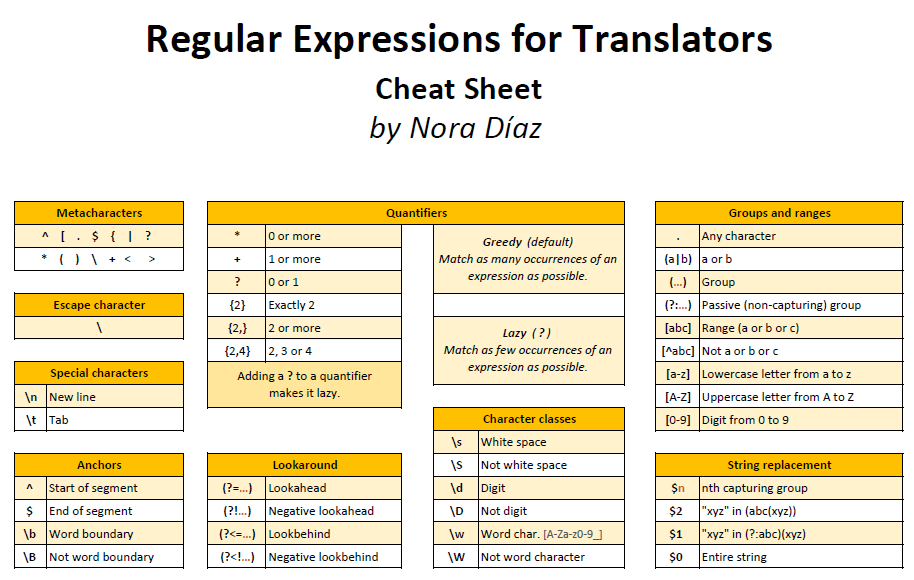 Перестаньте пытаться изгнать его обратно в измерение Демонов и дайте ему шанс 😃
Перестаньте пытаться изгнать его обратно в измерение Демонов и дайте ему шанс 😃
regexp-js/complexity.md на мастере · dhruvbird/regexp-js · GitHub
Это зависит… от того, какой метод сопоставления вы используете и какие операции нужно выполнить при сопоставлении строки с регулярным выражением. Видеть Сопоставление регулярных выражений в дикой природе: сопоставление для возможные вопросы, которые можно задать обработчику регулярных выражений. Больной перечислите их здесь для краткости.
Какова стоимость построения NFA и DFA из регулярного выражения?
Каковы затраты на сопоставление входных данных с NFA и DFA?
Захват подсовпадений
Чтобы захватить подсовпадения, нам нужно создать псевдоузлы в NFA, которые обновить набор захвата и пометить соответствующую группу вложенных совпадений как начавшись/закончившись при достижении этого состояния (обычно при открытии скобка и закрывающая скобка в регулярном выражении видимый).
Мы начинаем с пустого списка (сбалансированное бинарное дерево поиска
с ключом по номеру группы захвата), который представляет набор захвата для
начальный узел в NFA.